联表查询:
sql
-- 查询参加了考试的同学(学号,姓名,科目编号,分数) student result 两个表的交点是StudentNo
/*
1,分析需求 要查的字段来自哪些表
2,确定交叉点 判断条件
*/
SELECT s.StudentNo,StudentName,SubjectNo,StudentResult
FROM student AS s
INNER JOIN result AS r
WHERE s.studentNo = r.studentNo

自连接及联表查询:
自己的表和自己的表连接 核心:一张表拆为两张一样的表
sql
SELECT a.categoryName '父栏目' , b.categoryName '子栏目'
FROM category a, category b
WHERE a.categoryid = b.pid分页(limit)和排序(order by):
排序: 升序ASC,降序DESC
sql
SELECT s.StudentNO,studentname,subjectname,studentresult
FROM student s
INNER JOIN `result` r
ON s.studentNO = r.studentNO
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname= '高等数学-1'
ORDER BY studentresult ASC为什么要分页?
缓解数据库压力,给人的体验更好,
-- 分页,每页只显示五条数据
-- 语法 limit 起始值,页面大小
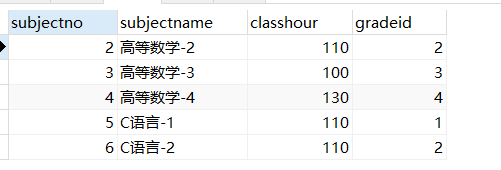
SELECT * FROM subject
LIMIT 1,5 //第一页 LIMIT 0,5 .第二页 LIMIT 5,5 第三页:LIMIT 10,5
规律 :第n页 LIMIT(n-1)*pagesize,pagesize
子查询:
where(这个值是计算出来的)
本质:在WHERE 语句中嵌套一个查询 where(SELECT)
MYSQL函数:
不太常用的,随便写点
sql
-- 绝对值
SELECT ABS(-8)
-- 向上取整
SELECT CEILING(5.4)
-- 向下取整
SELECT FLOOR(9.4)
-- 返回一个0-1的随机数
SELECT RAND()
-- 返回参数的符号 负数返回-1 正数返回1
SELECT SIGN(10)
-- 字符串长度
SELECT CHAR_LENGTH('你好世界')
--拼接字符串
SELECT CONCAT('我','爱你们')聚合函数(常用):
sql
SELECT COUNT(studentname) FROM student -- COUNT(字段),会忽略所有NULL值
SELECT COUNT(*) FROM `subject` -- COUNT(*) 不会忽略所有NULL值
SELECT COUNT(1) FROM `subject` -- COUNT(1) 不会忽略所有NULL值
sql
SELECT SUM(studentresult) AS 总分 FROM result -- 总和
SELECT AVG(studentresult) AS 平均分 FROM result -- 平均分
SELECT MAX(studentresult) AS 最高分 FROM result -- 最高分
SELECT MIN(studentresult) AS 最低分 FROM result -- 最低分事务:
什么是事务:
要么都成功,要么都失败 将一组SQL放在一次批次去执行
A1000 B 200
-
SQL执行 A给B转账200
-
SQL执行 B收到A的钱
A800 B 400
事务原则(acid): 原子性 一致性 隔离性 持久性
原子性:要么都成功,要么都失败 将一组SQL放在一次批次去执行
一致性:针对一个事务操作前与操作后的状态一致 无论怎么转 A和B一共1200
持久性: 数据不丢失

隔离性: 针对多个用户同时操作,排除其他用户对当前操作的影响

执行事务: mysql是默认开启事务自动提交的
sql
--手动处理事务
SET AUTOCOMMIT = 0 -- 关闭自动提交
-- 事务开启
START TRANSACTION -- 标记一个事务开始,从这之后的sql都在同一个事务内
INSERT XX
INSERT XX
-- 提交: 持久化 成功
COMMIT
-- 回滚: 回到原阿里的样子 失败
-- 事务结束
SET AUTOCOMMIT = 1 -- 开启自动提交索引:
MYSOL官方对索引的定义为:索引(Index)是帮助MYSQL高效获取数据的数据结构。
提取句子主干,就可以得到索引的本质:索引是数据结构。
索引的分类:
- 主键索引 PRIMARY KEY :唯一标识 主键不可重复
- 唯一索引 UNIQUE KEY :避免重复的列出现,可以重复,多个列可以标识为唯一索引
- 常规索引 KEY : 默认的,index,key关键字来设置
- 全文索引 FULLTRX: 在特定的数据库引擎下才
sql
-- 索引的使用
-- 1.在创建表的时候增加索引
-- 2,在创建完毕后,增加索引
-- 显示所有的索引信息
show index from student
-- 增加一个全文索引 `索引名` (列名)
ALTER TABLE school.student ADD FULLTEXT INDEX `StudentName`(`studentname`)
-- EXPLAIN 分析sql执行的状况
EXPLAIN SELECT * FROM student -- 非全文索引 数据量太少无法用全文索引
-- 全文索引
EXPLAIN SELECT * FROM student WHERE MATCH(studentname) AGAINST('刘');数据库备份:
保证重要的数据不丢失
数据转移
备份方式:
1 直接拷贝物理文件
2 直接可视化导出
3 使用命令行导出 mysqldump
数据库的三大范式:
为什么需要数据规范化?
避免 信息重复,更新异常,插入异常,删除异常
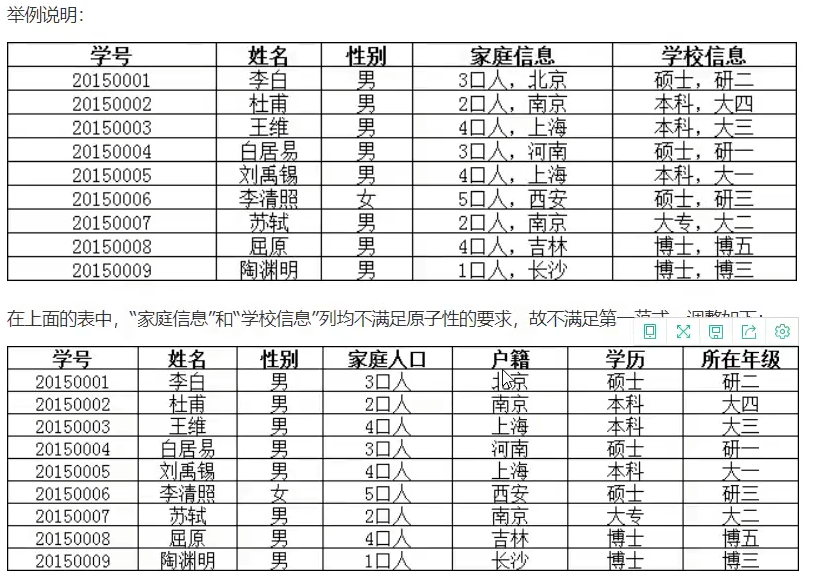
第一范式:
要求数据库的每一列都是不可分割的原子数据项
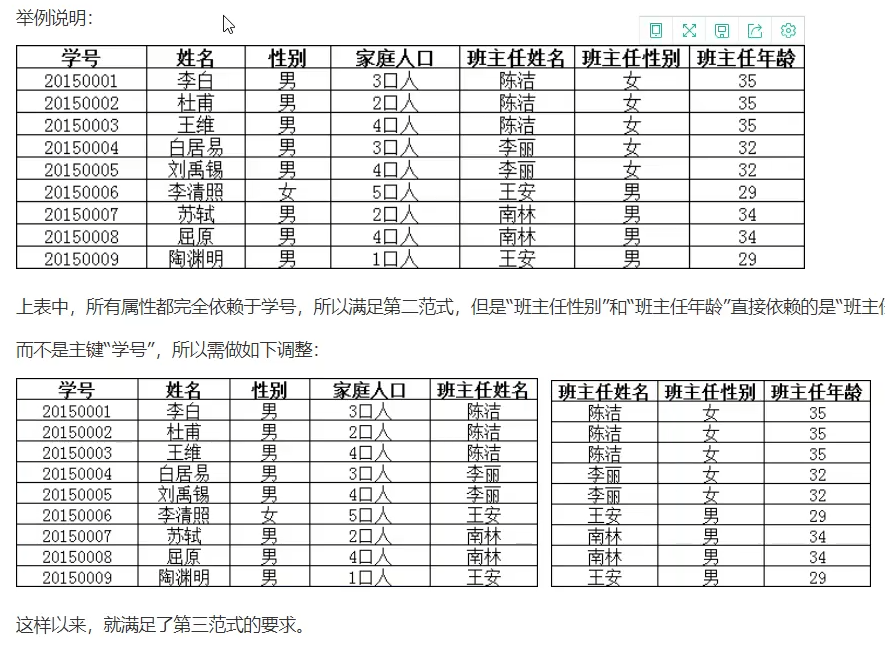
第二范式:
在1NF的基础上,每张表只描述一件事
第三范式:
属性完全依赖于主键,每一列与主键直接相关
规范性和性能的问题:
关联查询的表不得超过三张表
- 考虑商业化的需求和目标,(成本和用户体验)数据库的性能更加重要
- 在规范性能的问题的时候,适当的考虑规范性
- 故意给某些表增加一些冗余的字段。(从多表查询变为单表查询)
- 故意增加一些计算列(从大数据量降低为小数据量的查询:索引)