目录
[1. 索引类型](#1. 索引类型)
[1.1 按物理存储分类](#1.1 按物理存储分类)
[a. 聚集索引](#a. 聚集索引)
[b. 非聚集索引(二级索引)](#b. 非聚集索引(二级索引))
[1.2 按逻辑功能分类](#1.2 按逻辑功能分类)
[a. 主键索引](#a. 主键索引)
[b. 唯一索引](#b. 唯一索引)
[c. 普通索引【没有外键索引】](#c. 普通索引【没有外键索引】)
[d. 复合索引](#d. 复合索引)
[e. 全文索引](#e. 全文索引)
[2. 索引覆盖与回表查询](#2. 索引覆盖与回表查询)
[3. 索引的创建](#3. 索引的创建)
[&& 查看索引 &&](#&& 查看索引 &&)
[3.0 会自动创建的索引](#3.0 会自动创建的索引)
[3.2 主键索引](#3.2 主键索引)
[3.3 唯一索引](#3.3 唯一索引)
[3.4 普通索引](#3.4 普通索引)
[3.5 复合索引](#3.5 复合索引)
[4. 删除索引](#4. 删除索引)
[4.1 删除主键索引](#4.1 删除主键索引)
[4.2 删除其他索引](#4.2 删除其他索引)
1. 索引类型
1.1 按物理存储分类
按索引与数据的存储关系划分,可以划分出聚集索引(聚簇索引) 和非聚集索引(非聚簇索引)。
a. 聚集索引
- InnoDB 特有,索引叶子节点直接存储真实表的整行数据,真实表直接存放在B+树的叶子节点当中 。(索引即数据)
- 每张表仅能有 1 个聚集索引 ,默认使用表主键作为索引树的存储键。
- 如果没有主键,则选 unique 且 not null的表级约束(单列或复合均可)作为聚集索引并自动生成索引树。
- 如果都没有合适的列作为聚集索引,那么会隐式生成。插入数据时,InnoDB会为插入的数据行添加上一个 6 字节的 ROW_ID 字段作为隐式主键,并以该隐式主键构造聚集索引树。【在查询时,ROW_ID 字段被隐藏起来,用户无法查到】
【只有InnoDB存储引擎会把真实数据存放到索引树中,其他存储引擎(如 MyISAM)会++把真实表单独存储,与索引分离++】
b. 非聚集索引(二级索引)
- 特点:索引与数据分离 ,索引叶子节点不存储整行数据。
- 在 MyISAM 中,非聚集索引存储的是键值+指向真实数据行的指针 。在 InnoDB 中非聚集索引存储的只有键值。
补充:非聚集索引也叫作二级索引 ,InnoDB 专属叫法,特指 "除聚簇索引外的所有索引"(因为聚簇索引是 "一级索引")。
1.2 按逻辑功能分类
a. 主键索引
- 当在⼀个表上定义⼀个主键 PRIMARY KEY 时,InnoDB使⽤它作为聚集索引。
- 推荐为每个表定义⼀个主键。如果没有逻辑上唯⼀且⾮空的列或列集可以使⽤主键,则添加⼀个⾃增列。
补充:自增约束会隐含 NOT NULL ,所以在没有主键的情况下,拥有**唯一约束 + 自增约束的列(满足UNIQUE + NOT NULL)**也可以被 InnoDB 选为聚簇索引。
b. 唯一索引
- 当在⼀个表上定义⼀个唯⼀键 UNQUE 时,自动创建唯⼀索引 。(注意,自动创建的唯一索引 与 自动创建的聚集索引是两棵不同的索引树)
- 与普通索引类似,但区别在于唯⼀索引的列不允许有重复值。
c. 普通索引【没有外键索引】
- 最基础的索引,无唯一性约束,仅加速查询。
MySQL 中没有 "外键索引" 这个官方专属术语 ,如果使用外键作为索引,那它只是一个由外键列组成的普通索引。
但有一个关键规则:
InnoDB 会自动为外键列创建普通单列索引。(MyISAM 不支持外键,也不会自动创建)
d. 复合索引
- 复合索引也叫联合索引, 是使用多个字段共同创建的 B + 树索引。
- 使用的字段可以是普通列也可以是受约束的特殊列,只要使用的列数 >= 2即可。
- 指定复合索引的字段后,构造索引树时会按照用户的指定进行排序。例如,创建的复合索引是index (age, name) ,那么每个节点都会先按
age排序、age相同则再按name排序。
【单列索引 中(如单列主键索引、单列普通索引),索引树的页数据行只会用一个字段 作为存储键;复合索引 中,索引树的页数据行会用多个字段存储键值作为存储键。】
如果大家不了解页的概念,可以前往这篇《索引 (上) ------ 索引的定义与数据结构、MySQL的页》文章学习了解。
e. 全文索引
- 仅可以对文本类型(如:CHAR、VARCHAR 或 TEXT)创建的索引,用于全文搜索和文本内容的分词检索。
- 基于倒排索引。
- 在MySQL数据库中仅 MyISAM 和 InnoDB 引擎⽀持。
【MySQL不太建议使用全文索引,有专门的文本型数据库实现了更好的全文索引】
2. 索引覆盖与回表查询
回表查询:
- 首先,回表查询是 InnoDB 特有的行为,且只发生在非聚集索引。
- select查询时,如果查询所需的所有字段(包括where筛选条件字段、查询列表字段)不含或不止有主键列时,会先使用用户创建的非聚集索引进行查询。
- 回表查询的定义:InnoDB 非聚集索引的叶子节点仅存储 "索引列值"(可能是单列或复合的多列) ;若select查询字段超出该非聚集索引的覆盖范围,需用++去聚集索引树中查找完整数据++ ,这一步"通过聚簇索引补全字段"就是回表查询
补充:
在MyISAM引擎中,索引树的叶子节点只存 "索引键值 + 指向真实数据物理地址的指针", 必须接着通过指针找到整行真实数据 。此处需要额外的一次查找操作,但是该操作并不是回表查询。
无论是哪种引擎的行为,第一次查询 O(logN) + 指针读数据O(1) \| 回表查询O(logN) ,它们的总耗时都要比 全表扫描 O(N) 要少**。** 所以尽量要使用索引,这样能提升查询效率。
索引覆盖:
定义:查询所需的所有字段(包括筛选条件字段、查询列表),都完全包含在某一个索引(单列 / 复合索引)中,无需额外****读取数据文件(MyISAM)或聚簇索引(InnoDB),直接从索引中就能获取全部查询结果。
索引覆盖现象拥有最高的查询效率,两种引擎(InnoDB/MyISAM)都存在索引覆盖,时间复杂度仅O(logN)。
3. 索引的创建
&& 查看索引 &&
语法:
show index \| keys from 表名;
- show index 和 show keys 都表示:显示表的所有索引信息。
- index关键字是官方标准术语,在所有数据库都能使用。
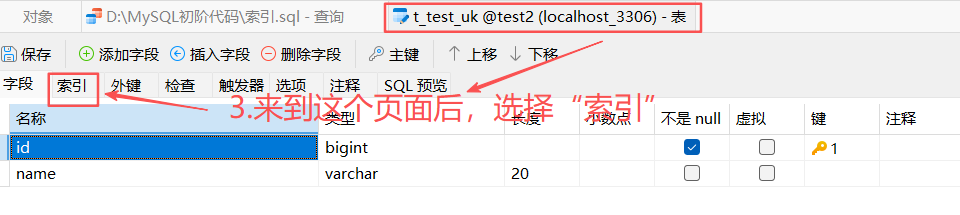
示例:下图是查看t_test_pk表索引的结果


下面是对各字段含义的解释:(红色的要重点理解)
| 字段名 | 含义 |
|---|---|
| Table | 索引所属的表名 ,这里对应表 t_test_pk |
| Non_unique | 索引是否为 "非唯一索引": - 0 = 唯一索引(截图中的是主键,主键是唯一的,所以值为 0) - 1 = 非唯一索引 |
| Key_name | 索引的名称: 截图中是 PRIMARY,这是主键索引的默认名称;普通索引会显示自定义的索引名(如 idx_sno) |
| Seq_in_index | 列在索引中的位置: 你的截图是单列主键索引,所以值为 1;++如果是复合索引(如 index(a,b)),a 对应 1、b 对应 2++ |
| Column_name | 索引对应的列名 ,你的截图中是主键列 id |
| Collation | 索引列的排序方向: - A = 升序(Ascending,MySQL 索引默认升序,截图中的是主键升序) - NULL = 无排序(如空间索引、哈希索引) - D = 降序 |
| Cardinality | 索引列中唯一值的估算数量: 截图中的值为 0,是因为表还没有数据;若表有数据,主键的 Cardinality 会接近表的总行数(主键值全唯一) |
| Sub_part | 是否是 "列的前缀索引": NULL = 整个列作为索引(截图中的是完整的 id 列);若写 10,表示取列的前 10 个字符做索引 |
| Packed | 索引是否压缩: NULL = 未压缩(MySQL 大部分场景不使用压缩索引) |
| Null | 索引列是否允许为空: 截图中为空(主键列强制 NOT NULL,所以这里无值);若列允许空,会显示 YES |
| Index_type | 索引的类型: 截图中是 BTREE,这是 InnoDB 默认的 B + 树 (MySQL 工具中统一显示为 BTREE) |
| Comment | 索引的注释(自定义备注) |
| Index_comment | 索引的专用注释(和 Comment 功能类似) |
| Visible | 索引是否对 MySQL 优化器 "可见": YES = 可见(优化器会考虑使用该索引); NO = 隐藏索引(也会进行增删操作,仅维护不被优化器使用) |
| Expression | 表示是否是 "表达式索引": NULL = 不是(你的截图是普通列索引); 若为表达式(如 index((a+b))),会显示表达式内容 |
除了使用SQL语句,在图形化界面中,我们对选定的表点击右键 --> 选择"设计表" --> 在"设计表"页面中选项栏选择"索引"
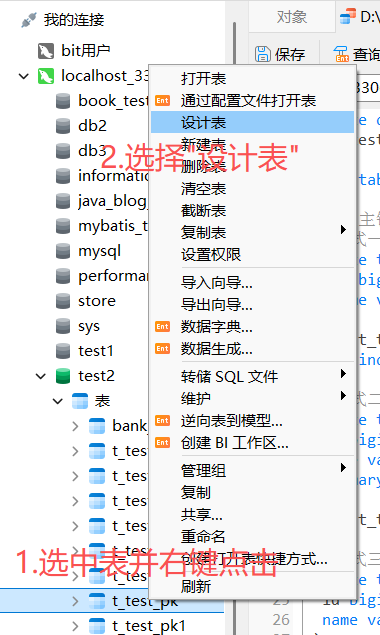

【这里看到的 BTREE 其实是MySQL 的表述习惯 ------MySQL 中显示的 "B 树",实际底层用的是 B + 树。只是 MySQL 文档 / 工具里常把 B + 树简称为 B 树】
3.0 会自动创建的索引
当我们为⼀张表加主键约束(Primarykey) ,外键约束(ForeignKey) ,**唯⼀约束(Unique)**时, MySQL会为对应的的列自动创建⼀个索引。
在InnoDB中,主键索引一定是聚簇索引。
表没有显式定义主键 且 表中没有任何非NULL的唯一索引时,InnoDB会使用隐式ROW_ID字段作为主键 ++自动创建聚簇索引++。
3.2 主键索引
3种创建方式:
方式一:定义列时添加主键约束
sqlcreate table t_test_pk ( id bigint primary key auto_increment, # 主键+自增约束 name varchar(20) );方式二:创建表时单独指定主键列
sqlcreate table t_test_pk1 ( id bigint auto_increment, # 自增约束 name varchar(20), primary key (id) # 指定主键 );方式三:用alter语句修改表中的列为主键索引
sqlcreate table t_test_pk2 ( id bigint, name varchar(20) ); alter table t_test_pk2 add primary key (id); # 指定主键约束 alter table t_test_pk2 modify id bigint auto_increment; # 添加自增约束modify可以用于增加新的属性,但如果新属性与旧属性冲突时,会被修改成新的属性。
主键约束与自增约束并不冲突,所以此处的modify表示"添加"。
- 方式一与方式都是自动创建主键索引。
- 方式三是手动创建主键索引。在未执行 "alter table t_test_pk2 add primary key (id)" 时,数据库创建一个隐式聚簇索引;执行该SQL语句后,数据库会额外创建一个主键索引树,然后用该主键索引作为新的聚簇索引 ,原本的隐式聚簇索引树会被回收。
- 在 MySQL 中,主键索引的名字是固定的PRIMARY ,无法手动自定义。
- 聚簇索引的选择优先级是主键 > 非空唯一键 > 隐式主键。
-- 查看t_test_pk2表的属性与主键索引:
sql
desc t_test_pk2;
show keys from t_test_pk2; 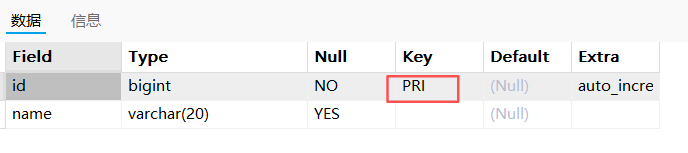

3.3 唯一索引
3种创建方式:
方式一:定义列时添加唯一约束
sqlcreate table t_test_uk ( id bigint primary key auto_increment, name varchar(20) unique # 唯一约束 );方式二:创建表时单独指定唯一列
sqlcreate table t_test_uk1 ( id bigint primary key auto_increment, name varchar(20), unique un_name1 (name) #指定索引名为un_name1 );方式三:用alter语句修改表中的列为唯一索引
sql#方式三,修改表中的列为唯一索引(alter) create table t_test_uk2 ( id bigint primary key auto_increment, name varchar(20) ); alter table t_test_uk2 add unique un_name2 (name); #指定索引名为un_name2
- 方式一和方式二是自动创建唯一索引**(即使方式二我们为索引命名了,它依然算是自动创建)**,方式三是手动创建索引。
- 方式一不能给索引起名字,自动创建的索引会++以索引键列的名称命名++。
- 方式二和方式三可以给索引起名字,格式:unique 索引名 (索引键列表)。
-- 1. 查看t_test_uk表的属性与索引:
sql
desc t_test_uk;
show keys from t_test_uk; 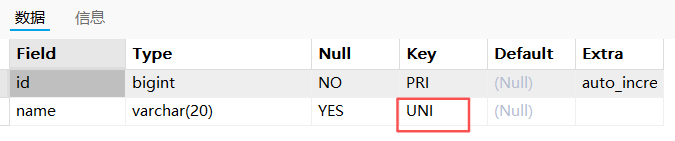

-- 2. 查看t_test_uk2表的属性与索引:
sql
desc t_test_uk2;
show index from t_test_uk2;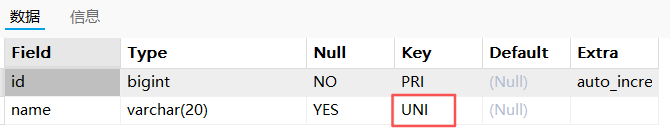

3.4 普通索引
3种创建方式:
#方式一:创建表时指定索引列
sqlcreate table t_test_index ( id bigint primary key auto_increment, name varchar(20) unique, sno varchar(10), index idx_sno1 (sno) #指定索引名为idx_sno1 );#方式二:使用alter语句修改表中的列为普通索引
sqlcreate table t_test_index1 ( id bigint primary key auto_increment, name varchar(20), sno varchar(10) ); alter table t_test_index1 add index idx_sno2 (sno); #指定索引名为idx_sno2#方式三:单独使用create index创建索引
sqlcreate table t_test_index2 ( id bigint primary key auto_increment, name varchar(20), sno varchar(10) ); create index idx_sno3 on t_test_index2(sno); #指定索引名为idx_sno3语法:create index 索引名 on 表名(表中的列);
- 省略索引名的话,会以索引键的列名作为索引名。
- 这三种方式都使用了index关键字,所以都是手动创建索引。
- 只有在表中含有外键约束列 ,且表内表外都没有对该外键约束列创建过索引 的情况下,才会++为外键约束列自动创建普通索引++。
- 例如,student表的class_id列是外键约束列,student表的name是唯一约束列,但是之前在创建唯一索引时使用了unique(class_id, name),那么此时InnoDB不会为class_id自动创建普通索引。
-- 查看t_test_index2表的属性与索引:
sql
desc t_test_index2;
show index from t_test_index2;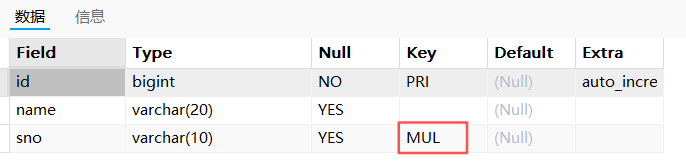

MUL 的全称是Multiple(意为 "可重复的"),用来表示该列对应的索引是非唯一索引。
3.5 复合索引
3种创建方式:
#方式一,创建表时指定索引列
sqlcreate table t_test_index4 ( id bigint primary key auto_increment, name varchar(20), sno varchar(10), class_id bigint, index 复合1 (sno, class_id) );#方式二,通过alter修改表中的列为复合索引
sqlcreate table t_test_index5 ( id bigint primary key auto_increment, name varchar(20), sno varchar(10), class_id bigint ); alter table t_test_index5 add index 复合2 (sno, class_id);#方式三,单独使用create index创建索引
sqlcreate table t_test_index6 ( id bigint primary key auto_increment, name varchar(20), sno varchar(10), class_id bigint ); create index 复合3 on t_test_index6 (sno, class_id);
-- 查看t_test_index6表的属性与索引:
sql
desc t_test_index6;
show index from t_test_index6;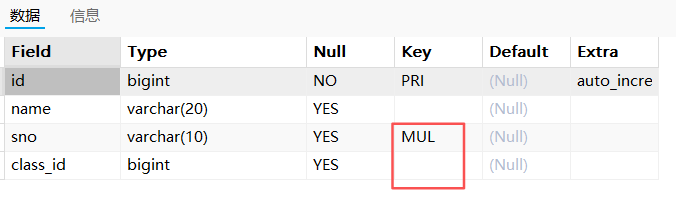
解释:desc中 Key 列的标记规则是:仅对 "索引的第一个列(即复合索引的前缀列)" 进行标记 ,后续列哪怕属于复合索引的一部分,也不会显示 MUL。【unique和index的复合都会显示第一列MUL,但primary key会显示所以的PRI列】

除了index关键字,primary key和unique也是可以创建复合索引的。
例如:
- 在表外使用alter table 表名 add primary key 索引名 (列1,列2,...),这属于手动创建索引。
- 在表内 (create table语句内) 使用 unique 索引名 (列1,列2,...),这会自动创建索引。
注意事项:
1. 主键复合索引的要求:
- 整个列组合 必须唯一;
- 组合中的每一列都必须是
NOT NULL。2. 唯一复合索引的要求:
- 整个列组合 必须唯一;
- 组合中的列允许为 NULL。
3. 普通复合索引:
- 无唯一性、非空的强制约束,仅用于加速查询。(无数据完整性约束)
-- 例1:自动创建的主键复合索引
sql
create table t_test_pk3 (
id bigint,
name varchar(20),
sno varchar(10),
primary key (id, name)
);
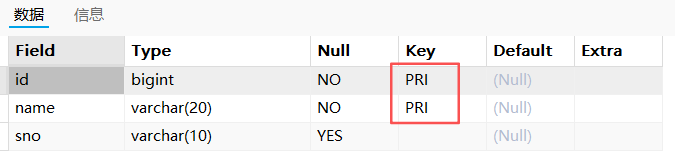
desc t_test_pk3;
show index from t_test_pk3;复合主键中的两个列都显示PRI:

-- 例2:手动创建的唯一复合索引
sql
create table t_test_uk3 (
id bigint,
name varchar(20),
sno varchar(10)
);
alter table t_test_uk3 add unique 复合唯一索引 (id, name, sno);
desc t_test_uk3;
show index from t_test_uk3;复合唯一键中,只有第一个列标记为MUL:
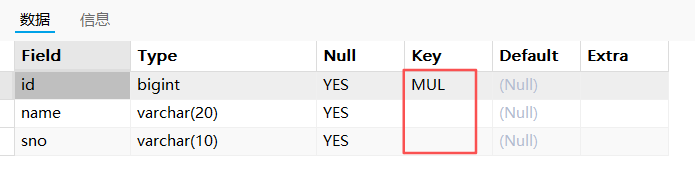

4. 删除索引
主键索引的删除和其他索引的删除是不一样的。
4.1 删除主键索引
语法:
alter table 表名 drop primary key;
- 这同时会把主键约束也删除掉。
- 如果某一个主键列含有自增约束,必须先使用modify把自增约束去除,去除后才能删除主键索引。
- 主键索引被删除后,InnoDB 会重新构建一个聚簇索引。因此删除主键时要谨慎!!!
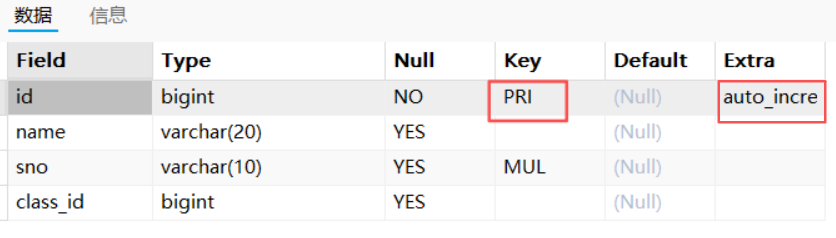
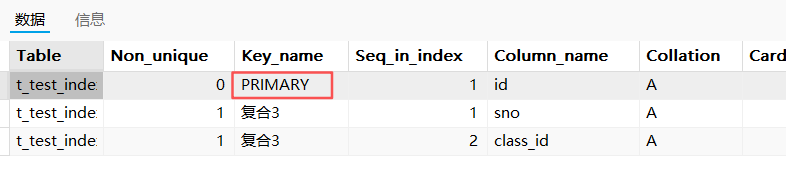
-- 删除 t_test_index6 表中的主键索引
删除前:
【desc】
【show index】
在没有去除自增约束的情况下尝试删除主键:
sqlalter table t_test_index6 drop primary key;去除自增约束后,再删除主键:
sqlalter table t_test_index6 modify id bigint; desc t_test_index6;

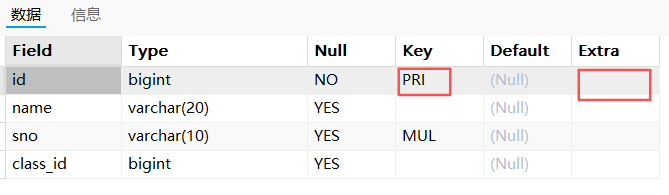
表结构显示此时的id列不再是自增列。可以删除主键了:
sql
alter table t_test_index6 drop primary key; # 成功删除主键索引
desc t_test_index6;
show keys from t_test_index6;id列已经不再是主键列:
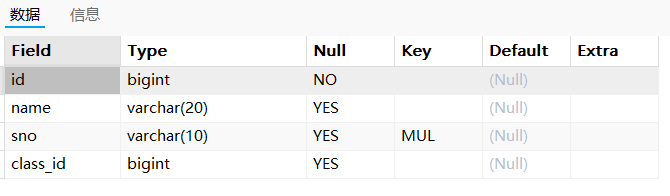
已经没有主键索引了:

4.2 删除其他索引
语法:
alter table 表名 drop index 索引名;
alter table 可以被省略。
无论是 普通索引 还是 唯一索引(包括复合的),都是使用 index 关键字。
如果删除的是唯一索引,那么唯一约束也会被删除掉。
-- 删除t_test_uk 表中的唯一索引
查看索引名称:
sql
desc t_test_uk;
show index from t_test_uk; 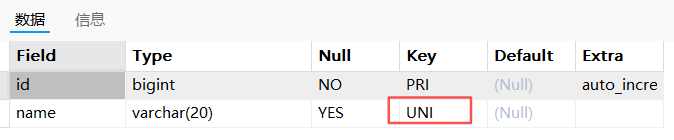

删除唯一索引
sql
alter table t_test_uk drop index name;
desc t_test_uk;
show index from t_test_uk;唯一约束和索引都不存在了:


本期分享完毕,感谢大家的支持Thanks♪(・ω・)ノ
