2025 注定是要被载入 AI 史册的一年,大模型扎堆发布、开源生态空前繁荣...
但技术突破的喧嚣之外,真实世界究竟发生了什么?
大家好,欢迎来到 code秘密花园,我是花园老师(ConardLi)。

最近,OpenRouter 发布了一份非常硬核的 AI 技术报告,它通过分析海量的 LLM 请求调用记录(超过 100 万亿 Token),能看到全球用户到底在用什么模型、干什么事儿、愿意花多少钱,并且试图绘制出一张最真实的 '全球 AI 地形图'。如果你还认为开源模型只是陪跑、降价就能换来用户、或者北美依然垄断一切,那么这篇报告将彻底重塑你的世界观。
这份报告非常长,下面是我总结的一些关键重点内容,让我们一起来学习一下。
一、开源和闭源模型
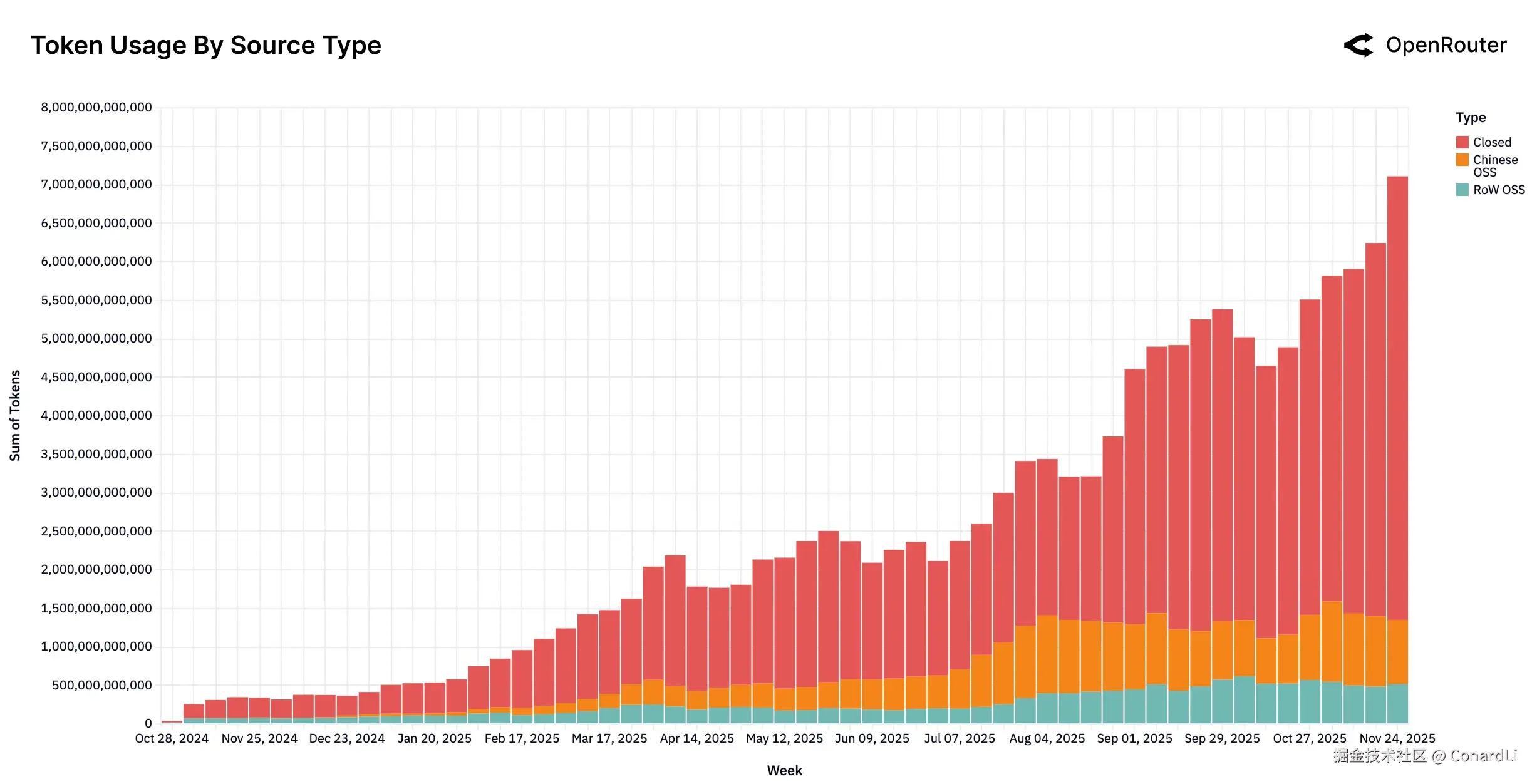
-
尽管来自北美大厂的闭源模型依然占据主导地位(平均约占 70% 的份额),但开源模型的使用量在 2025 年稳步增长,到了年底已经拿下了约三分之一的市场份额,形成了一种相对稳定的平衡。
-
开源模型的增长的主要动力来自中国开发的模型。从 2024 年底微不足道的 1.2% 起步,中国开源模型凭借快速的迭代周期和过硬的质量(如 Qwen 和 DeepSeek 系列),迅速抢占市场,在某些时段甚至贡献了近 30% 的总使用量。
-
数据的飙升往往紧随重磅模型的发布(如 DeepSeek V3、Kimi K2 等),但关键在于,这些增长在发布热度退去后依然得以保持。这说明用户不仅仅是在尝鲜,而是真正将这些开源模型投入到了长期的生产环境中。
二、开源模型从"一家独大"走向"百花齐放"
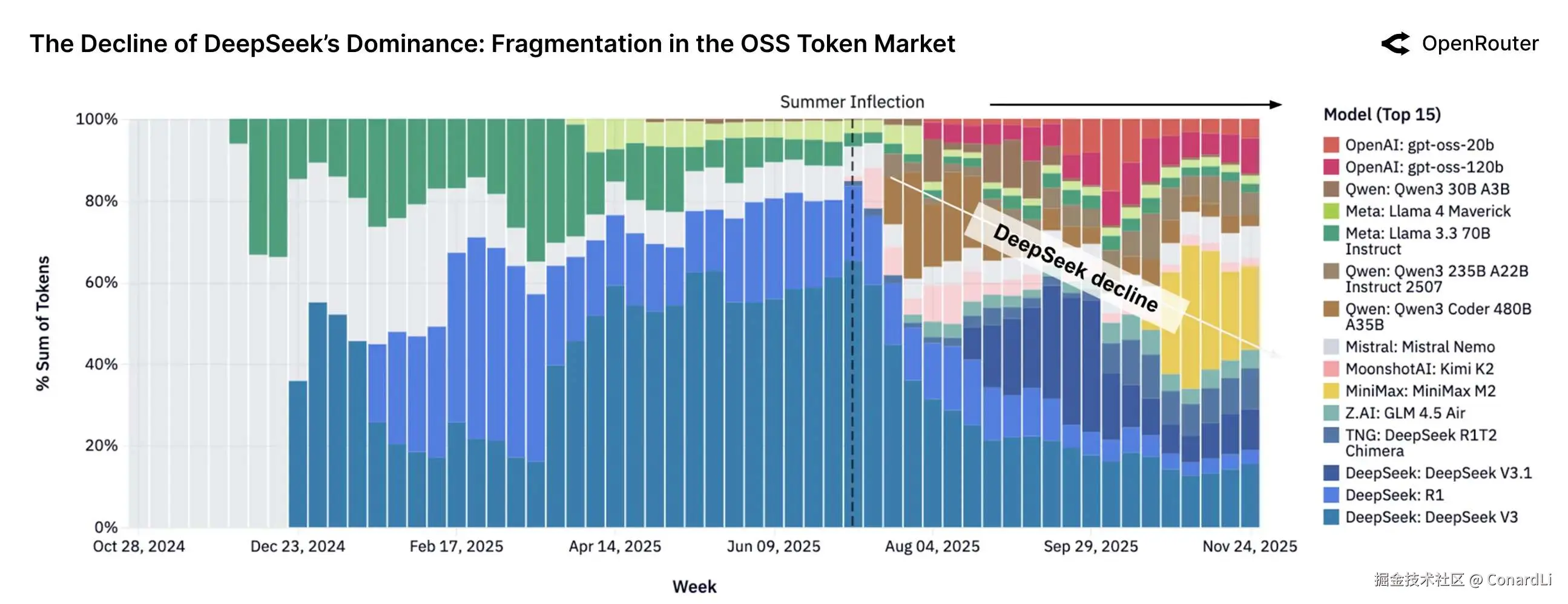
-
开源模型市场在过去一年发生了剧变。虽然 DeepSeek 在总流量上依然领先,但它曾经占据"半壁江山"(超过 50%)的统治地位已被打破。到了 2025 年底,没有任何单一模型能独占超过
25%的份额,前几名的差距正在缩小,市场变得更加均衡。 -
新晋"黑马"上位神速 用户切换模型的门槛很低,且非常乐意尝鲜。像
Qwen、MiniMax、Kimi以及GPT-OSS等新模型,一经发布就能在几周内迅速抢占大量市场份额。这说明只要模型在能力或效率上有突破,就能立刻获得社区的认可。 -
持续迭代是生存的关键,在这个竞争激烈的生态里,"吃老本" 行不通。
DeepSeek之所以能在新秀辈出的环境下依然保持头部地位,全靠不断推出新版本。反之,那些停止更新或迭代缓慢的模型,其市场份额很快就会被更勤奋的竞争对手瓜分。
三、开源模型尺寸新风向:"中型"崛起,"小型"失宠
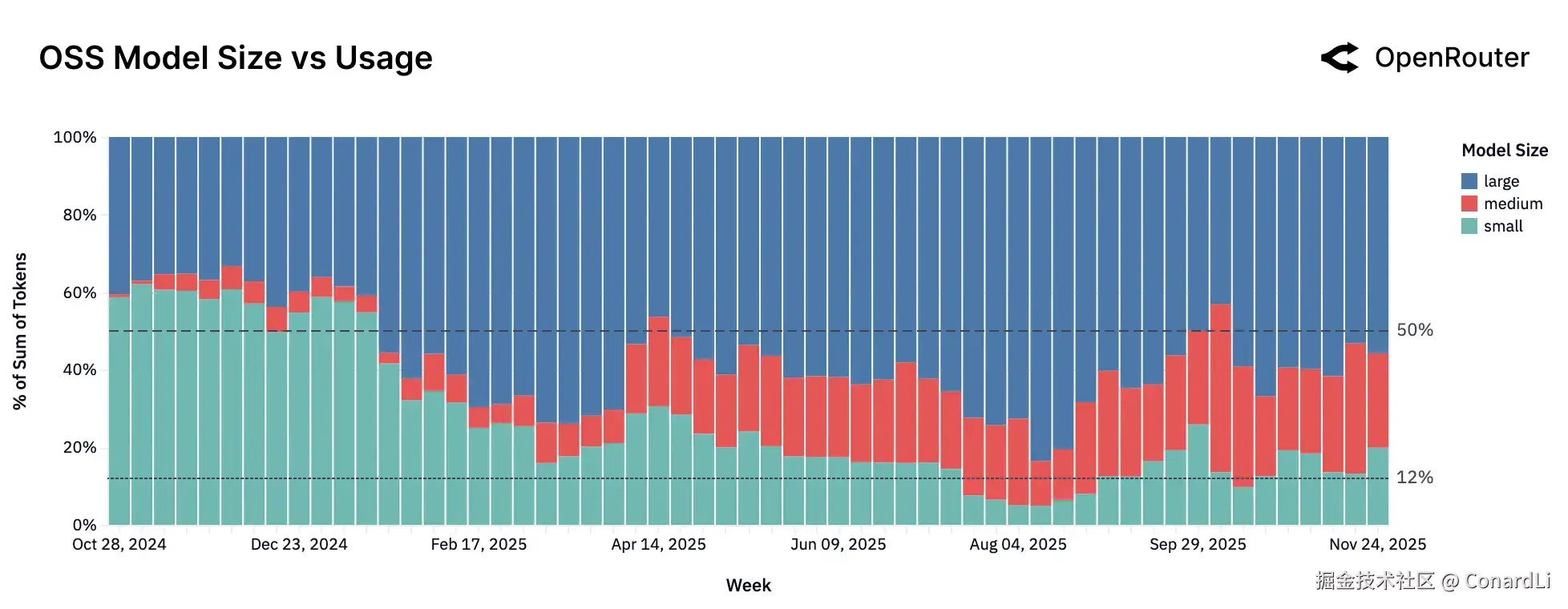
-
虽然市面上不断涌现新的小模型(15B 参数以下),但它们的使用份额反而在下降。这个赛道极其拥挤,用户忠诚度很低,总是在不断尝试新出的模型(如 Google Gemma 3 等),导致没有任何一个小模型能长期坐稳位置。
-
"中型模型"(15B 到 70B 参数)成了市场的新宠。自从 Qwen2.5 Coder 32B 证明了这个量级的潜力后,Mistral 和 GPT-OSS 等后续跟进者迅速扩大了这一市场。用户发现,这类模型在能力 和运行效率之间找到了完美的平衡,性价比极高。
-
在大模型(70B 参数以上)领域,不再是某一个模型"赢家通吃"。现在的趋势是百花齐放,用户会同时使用和评估多个顶级模型(如 Qwen3、GLM 4.5、GPT-OSS-120B 等),根据实际表现灵活切换,而不是死守单一标准。
简单来说,小模型主导开源生态的时代可能已经结束了。现在的市场正在分化:用户要么转向更稳健的中型模型 以求平衡,要么直接上大模型以求极致性能。
四、开源模型的主要用途与应用趋势
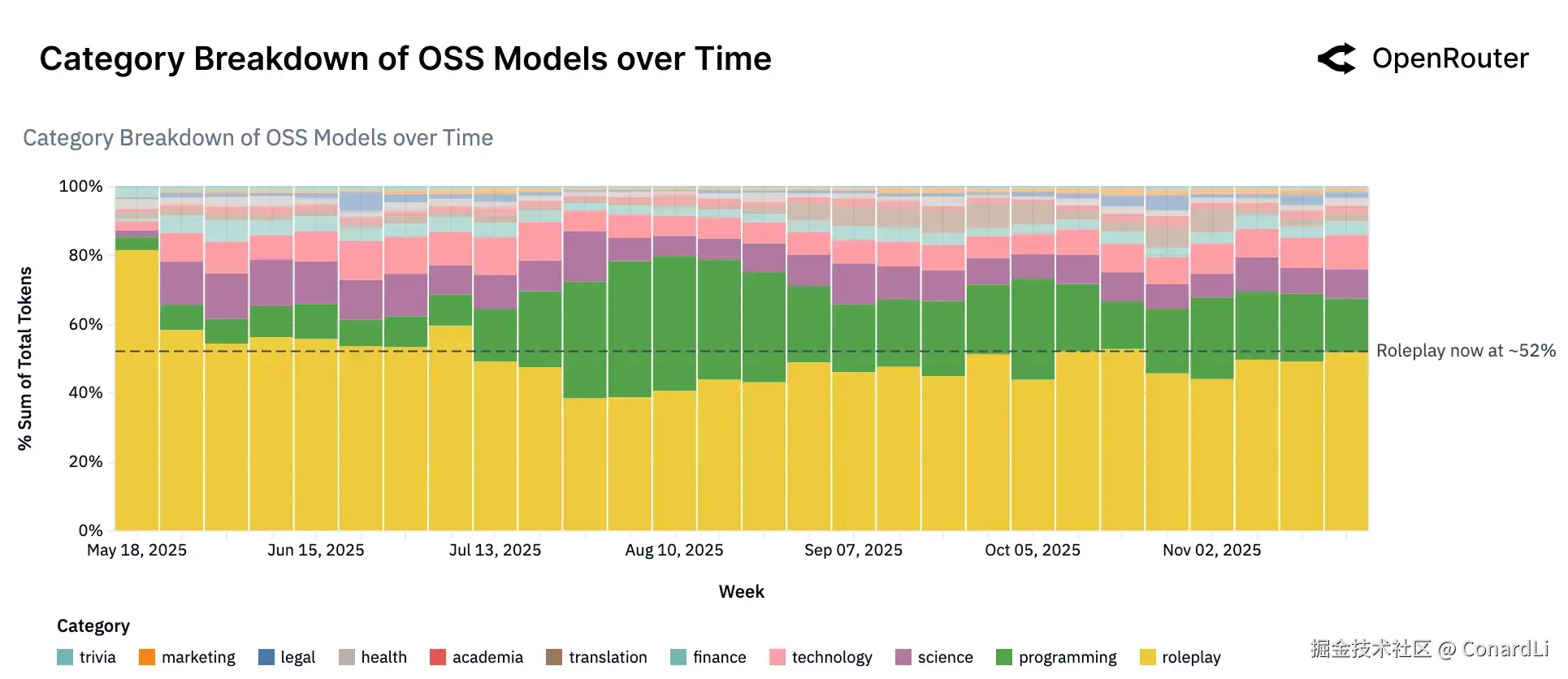
-
目前的开源模型并非雨露均沾,而是集中在角色扮演(Roleplay)和编程辅助这两个领域。这两类任务占据了绝大多数的 Token 用量。尤其是角色扮演,占据了总流量的半壁江山(超过 50%),这主要是因为开源模型通常受到的内容审查限制较少,更适合需要创意、情感互动或个性化定制的娱乐场景。
-
如果把目光聚焦在中国开发的开源模型(如 Qwen 和 DeepSeek)上,会发现它们的使用结构有所不同。虽然角色扮演仍是第一大类,但编程和技术类任务的合计占比(约 39%)显著高于全球平均水平。这说明国产开源模型正越来越多地被用于实际的代码生成和生产力工具中,而不仅仅是娱乐。
-
在写代码这件事上,虽然闭源模型(如 Claude)依然占据整体主导地位,但在开源领域内部,竞争非常动态。开发者非常务实,"谁强用谁" ------ 流量曾在 2025 年中期向国产模型倾斜,随后又因西方模型(如 LLaMA 系列)的更新而回流。这表明开源编程助手的市场份额对模型质量的反应极其敏感。
五、智能体推理的崛起
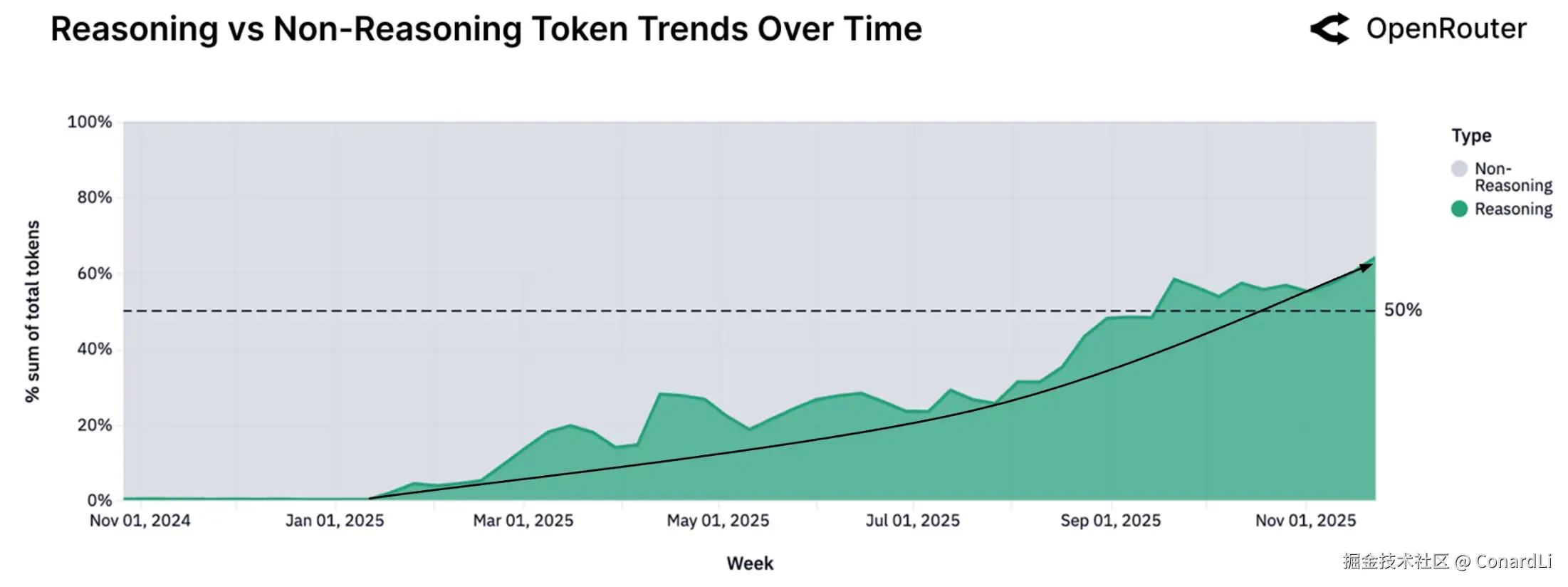
-
模型不再仅仅用于简单的单轮文本生成或补全,而是越来越多地被用于执行多步骤规划、工具调用以及复杂的逻辑推理任务。这标志着 AI 从单纯的"聊天机器人"向能解决复杂问题的"智能体"进化。
-
自 2025 年初以来,流经"推理优化型模型"的 Token 份额急剧上升,目前已超过总流量的 50%。这得益于供给侧(GPT-5、Claude 4.5、Gemini 3 等强力模型的发布)和需求侧(用户对处理复杂状态和逻辑的需求增加)的双重推动。
六、工具调用加速普及
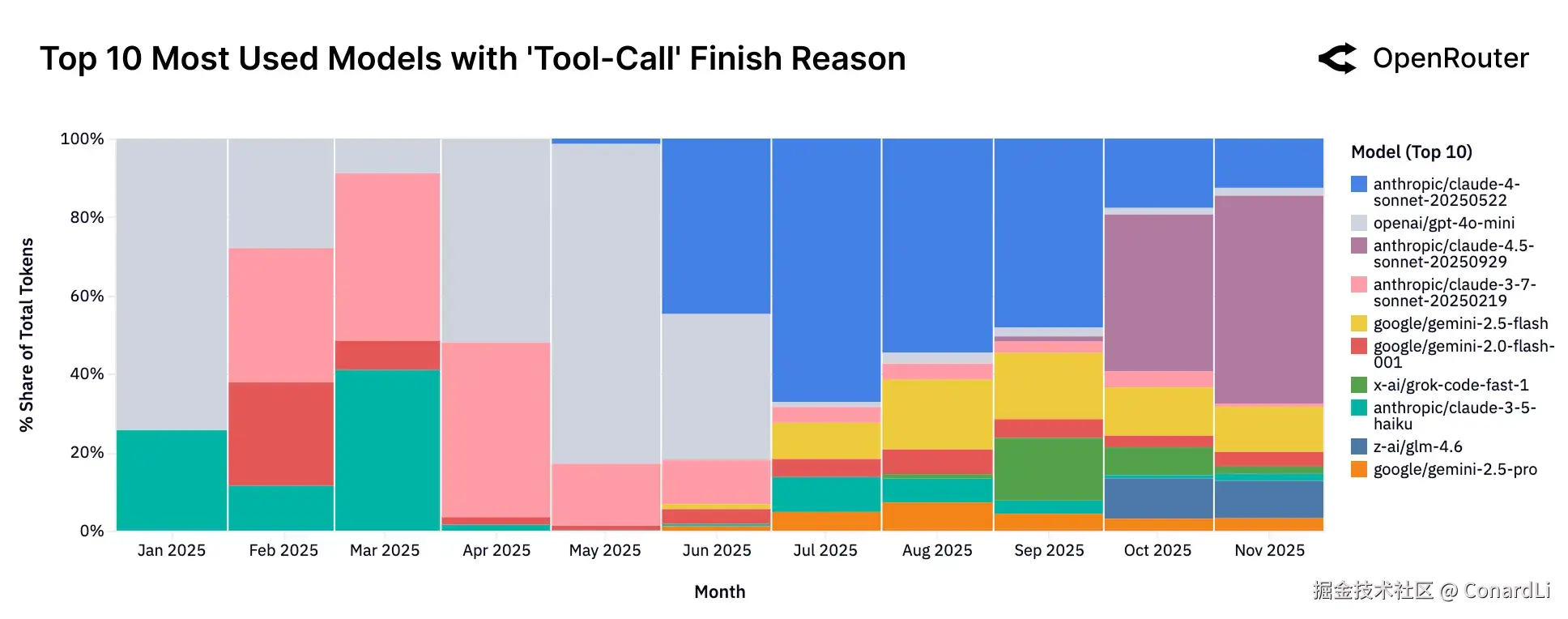
-
数据显示,全年的"工具实际调用量"(即模型真正执行了外部工具操作,而非仅仅是具备该功能)呈现出持续、稳步的上升趋势。除去 5 月份因个别大户造成的短暂数据异常外,整体趋势非常明确:AI 正在从单纯的对话者,转变为能干活的执行者。
-
在 2025 年初,工具调用领域基本被 OpenAI(gpt-4o-mini)和 Anthropic(Claude 3.5/3.7 系列)垄断。但到了下半年,局面发生了显著变化:Claude 4.5 Sonnet 迅速抢占市场份额,同时 Grok Code Fast 和 GLM 4.5 等新模型也强势入局。这表明支持 Agent 能力的底层模型选择变得更加丰富了。
-
对于开发者和企业而言,结论非常残酷且直接:支持稳定的工具调用已不再是锦上添花,而是必须项。 在高价值的复杂工作流中,如果模型缺乏可靠的工具接口能力,将在企业级采用和自动化编排中迅速掉队。
七、模型输入长度显著增长
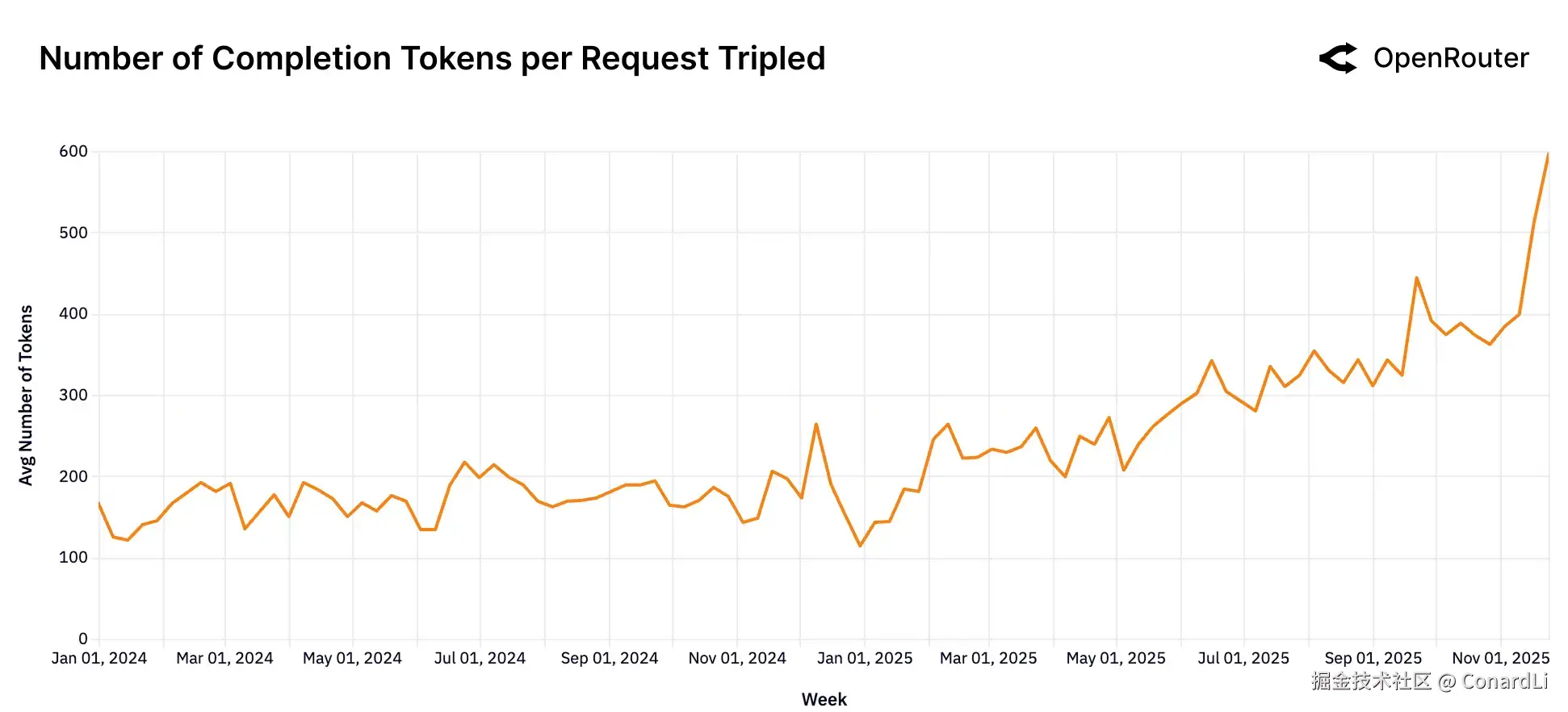
-
过去一年,用户输入的提示词(Prompt)平均长度 翻了近 4 倍(从约 1.5k 涨至 6k token),而模型输出的长度虽然也增加了 3 倍(主要归因于推理过程),但绝对值依然较小。这说明现在的交互模式是"喂给模型大量信息,换取精炼的高价值洞察"。
-
这种数据形态的变化反映了模型角色的根本性转移。AI 不再只是凭空"写作文"的生成器,而是进化成了分析引擎。现在的典型用法是丢给模型大量的代码库、文档或长对话记录,让它在这些庞大的上下文中进行推理和提炼。
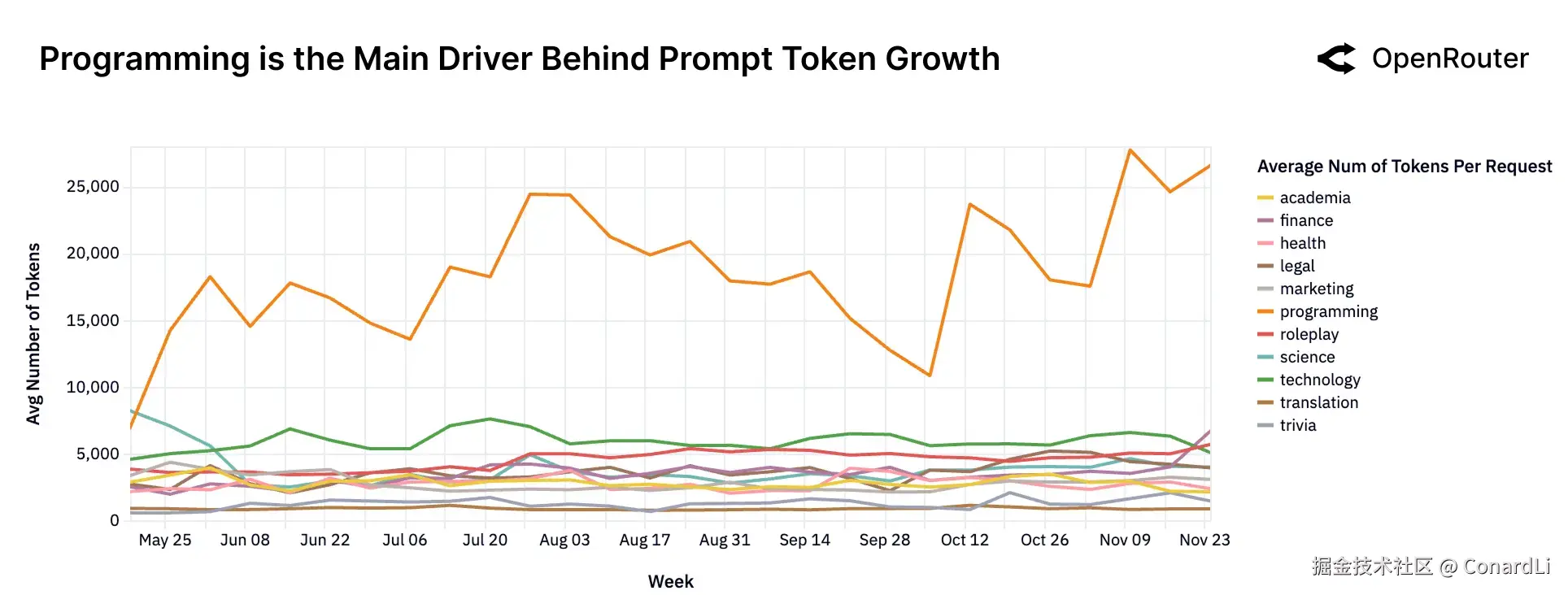
- 输入长度的暴涨并非全行业的普遍现象,而是呈现出极度的不均衡性。编程类任务(如代码理解、调试)是推高输入长度的绝对核心驱动力,其请求往往需要处理超过 2 万个 Token 的上下文。相比之下,其他领域的输入长度则保持相对平稳。
八、LLM 编程任务的爆发式增长
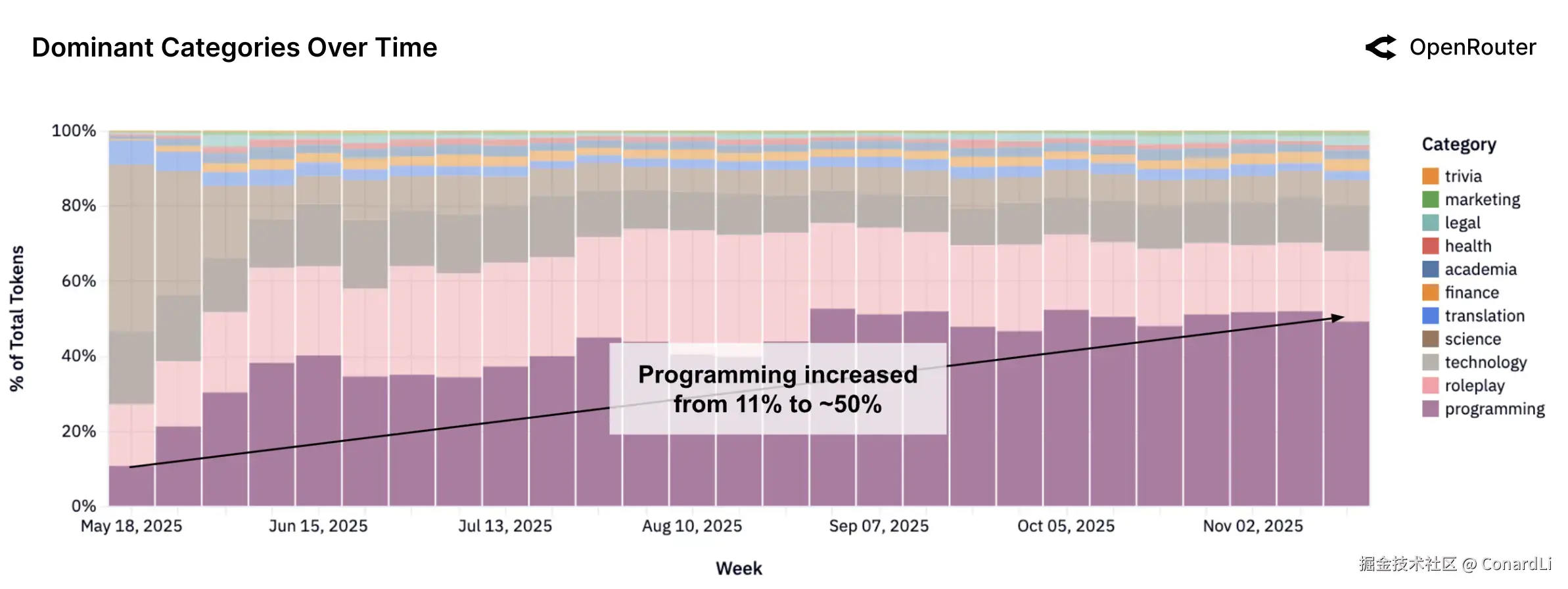
-
如果把视野从开源模型扩大到所有 LLM(包含闭源),编程无疑是增长最快且最具统治力的类别。从 2025 年初仅占约 11% 的份额,飙升至最近的超过 50%。这说明 AI 已经深度嵌入到写代码、调试等开发流程中,不再只是陪聊,而是实打实的生产力工具。
-
在编程辅助领域,Anthropic 的 Claude 系列 具有绝对的统治力,长期把持着超过 60% 的市场份额。不过,这一地位近期有所松动(首次跌破 60%),显示出市场竞争正在加剧。
-
竞争格局正在发生微妙变化:OpenAI 的份额从 2% 缓慢回升至 8%,Google 稳定在 15% 左右。值得注意的是,MiniMax 等新兴厂商以及 Qwen、Mistral 等开源力量正在迅速崛起,抢占了部分开发者的注意力。
编程类任务是目前争夺最激烈、战略意义最重要的领域。开发者对模型质量极其敏感,微小的性能或延迟差异就能导致市场份额的快速转移。这倒逼所有模型厂商必须持续加强代码训练数据和逻辑推理能力,谁慢一步就会掉队。
九、LLM 其他任务的细分趋势
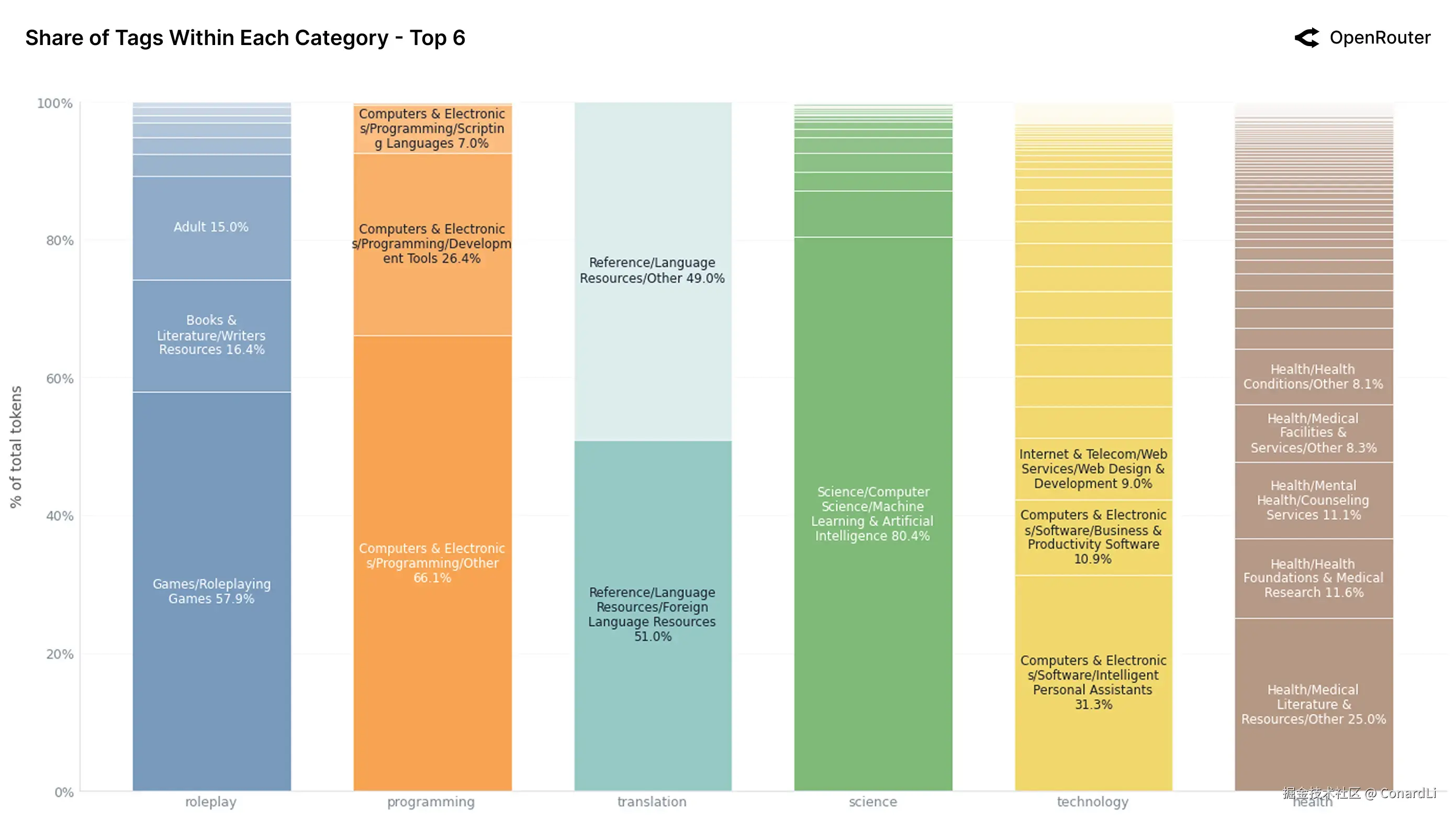
-
大多数应用类别内部并非"雨露均沾",而是呈现出明显的头部集中效应。用户的使用习惯非常固定,通常聚焦在每个大类下的某这一两个特定细分场景中,这说明真实的市场需求其实是非常具体且有迹可循的。
-
角色扮演(Roleplay): 绝非简单的闲聊。近 60% 的流量集中在游戏与跑团(Games/RPG),加上成人内容和写作资源,说明用户是在把 LLM 当作一个结构化的故事引擎或互动游戏机来用。
-
一个有趣的现象是,在"科学(Science)"这个大类下,竟然有 80.4% 的内容是关于 "机器学习与 AI" 的。这说明目前用户用 AI 聊科学,主要还是为了研究 AI 技术本身(套娃了),而不是去探索物理、生物等传统基础学科。
-
相比于编程的成熟,医疗、金融和法律等专业领域的应用显得非常分散(碎片化)。在这些领域中,没有任何单一的细分用途能占据主导地位。这既反映了专业领域需求的复杂性,也暗示了目前的通用模型还没能为这些行业提供一套标准化的、杀手级的工作流,未来优化潜力巨大。
十、模型厂商的生态画像
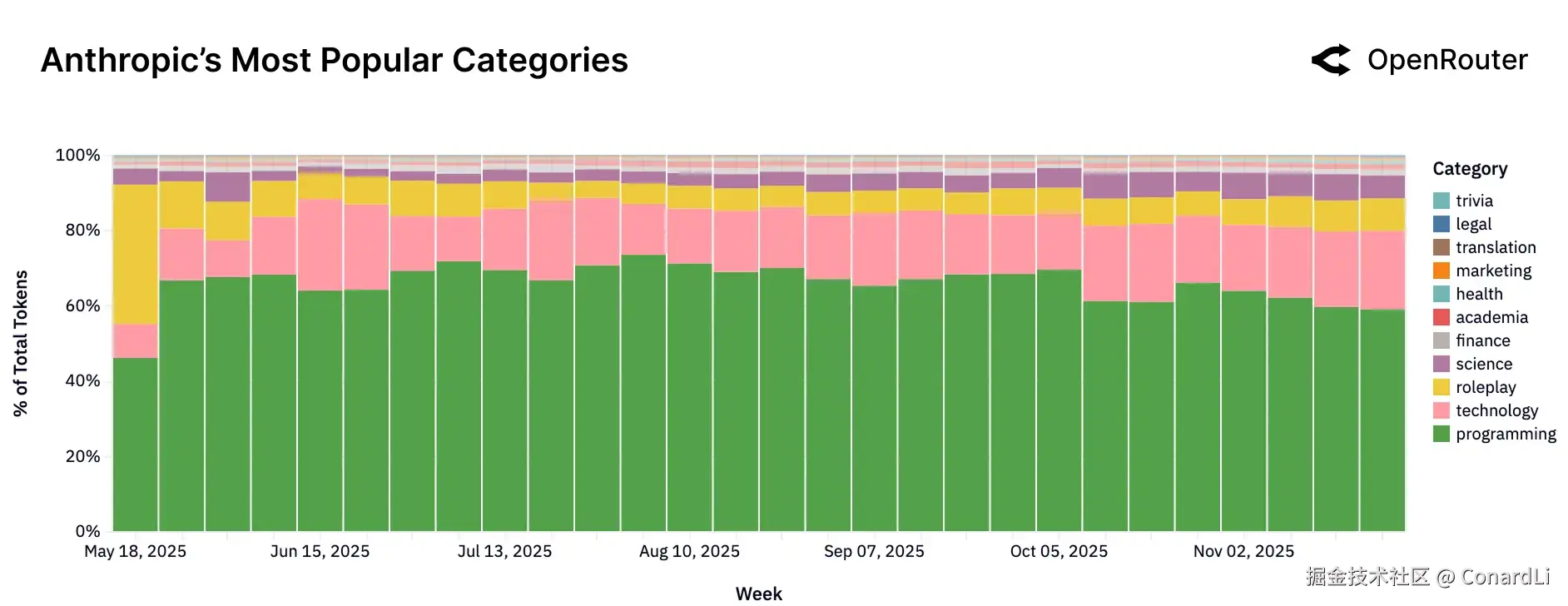
- Anthropic (Claude):极致的"偏科生" Claude 的定位非常清晰且硬核------它就是生产力工具。超过 80% 的流量都集中在编程和技术任务上,用来闲聊或角色扮演的比例微乎其微。在开发者和企业眼中,它是解决复杂逻辑和写代码的首选。
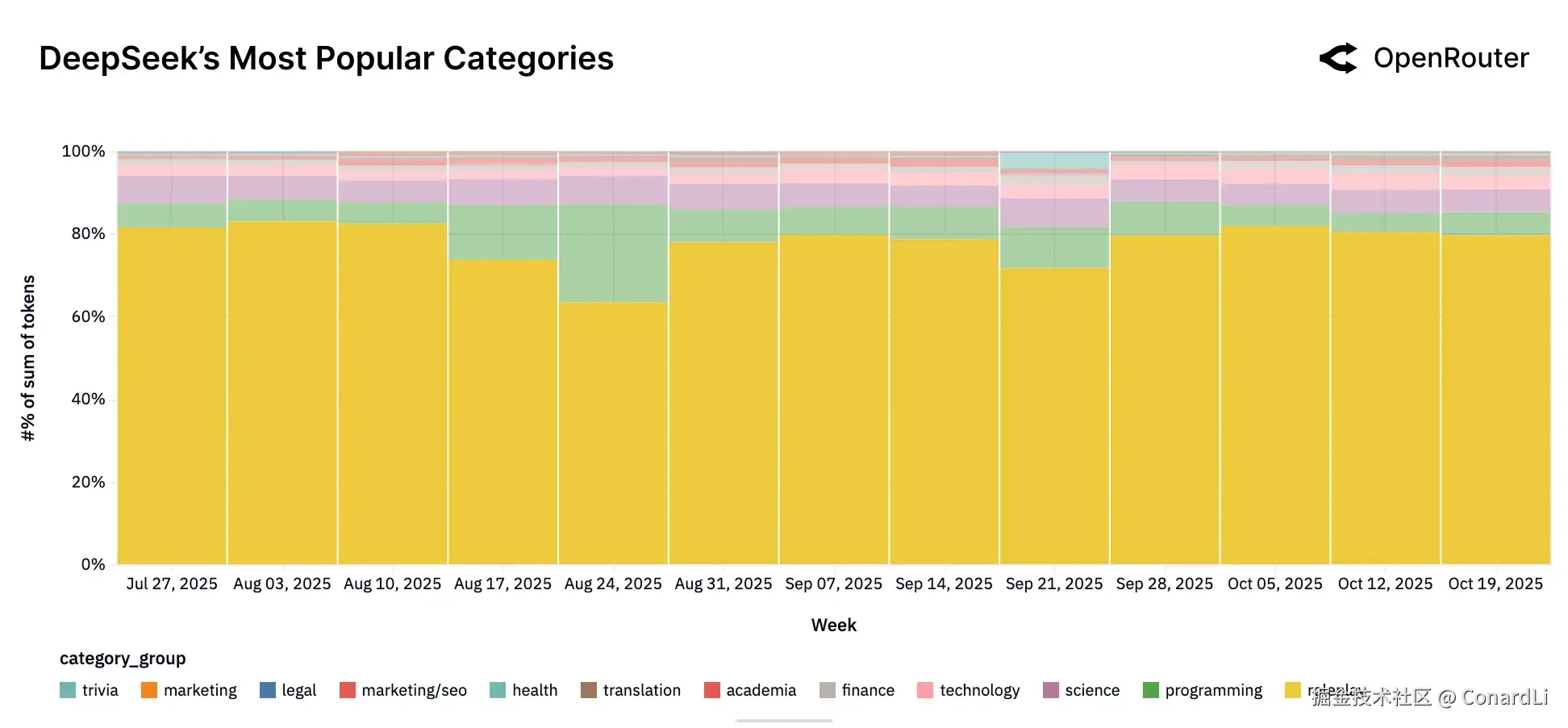
- DeepSeek vs. Qwen 虽然都是国产开源之光,但两者的用法截然不同:
- DeepSeek :超过三分之二的流量都用于角色扮演和休闲聊天,主打高频互动的 C 端场景。
- Qwen (通义千问) 画像更像 Anthropic,40%-60% 的流量都是编程任务,显示其在技术开发群体中有很强的渗透率。
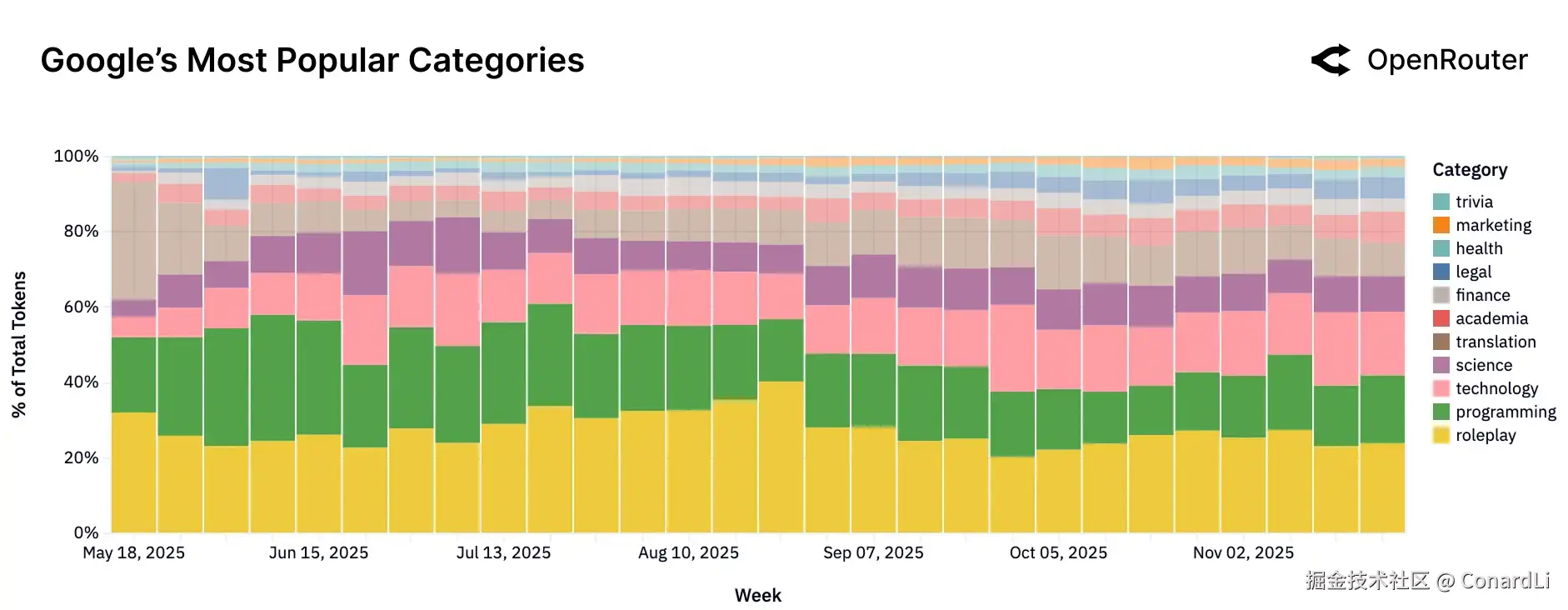
- Google 模型的用途最杂、最宽泛。它涵盖了法律、科学、翻译等各种长尾需求,更像是一个综合信息引擎。值得注意的是,Google 的编程份额反而在下降(跌至约 18%),说明用户更倾向于用它查资料而非写代码。
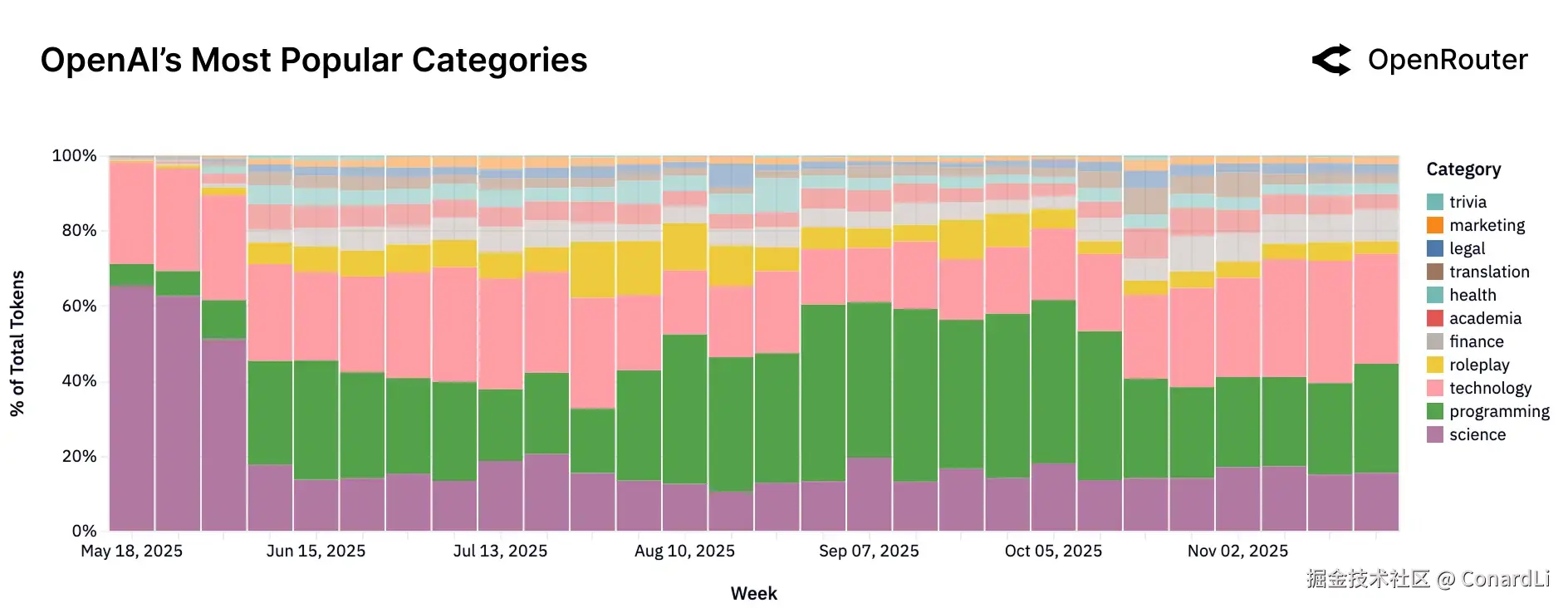
- OpenAI 与 xAI:正在转型"
- OpenAI 正在从早期的"科学问答"向"实干"转型,目前编程和技术任务已占半壁江山,介于 Claude 的专精和 Google 的博学之间。
- xAI 则经历了一次有趣的突变:原本是纯粹的代码工具(编程占比曾超 80%),但随着免费消费级应用的推广,技术、角色扮演和学术类流量突然涌入,用户群正在从纯极客向大众泛化。
数据证明,目前的市场已经高度分化。用户非常聪明,会根据任务选模型:写代码找 Claude/Qwen,聊天找 DeepSeek,查资料找 Google。这对开发者意味着,未来不再是单一模型的天下,而是 多模型协作 的时代。
十一、LLM 全球市场的区域份额与语言分布
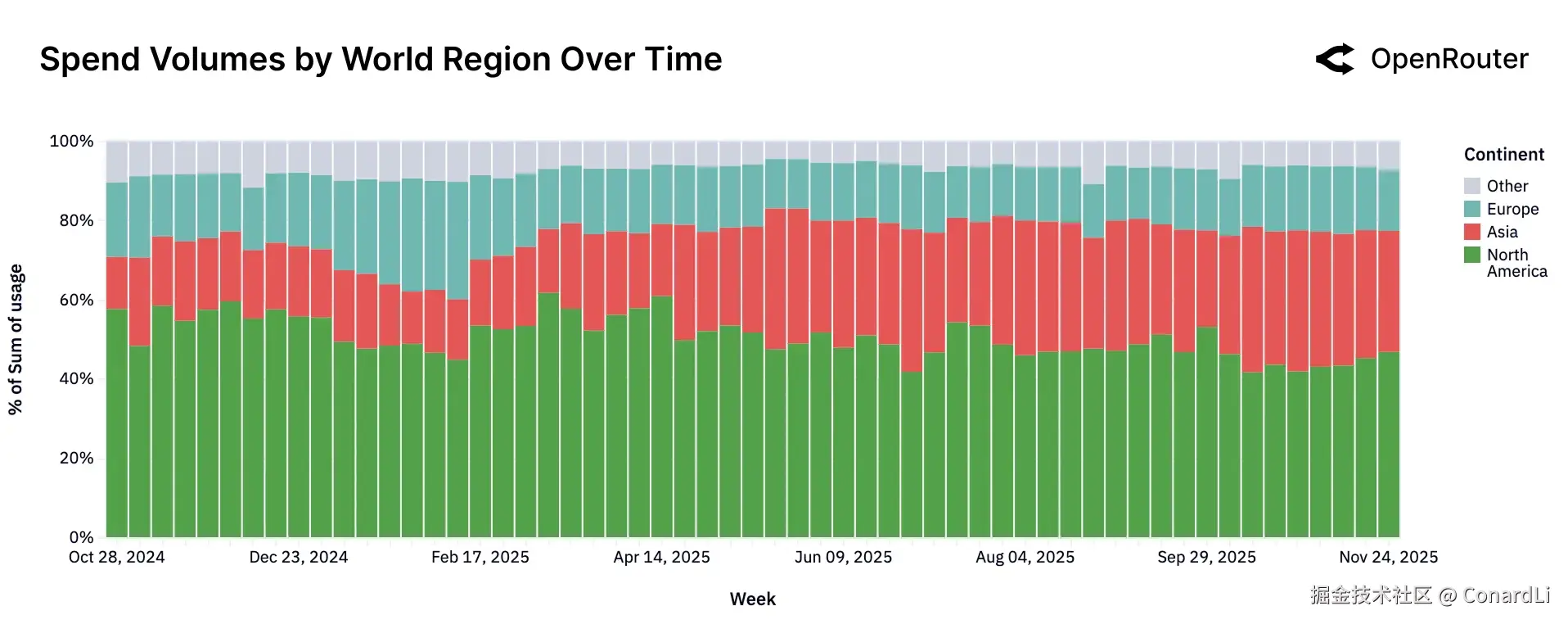
-
北美不再"一家独大",亚洲消费力翻倍 虽然北美依然是全球最大的 AI 消费市场(约占 47%),但其份额已不足全球总支出的一半。最引人注目的是亚洲的崛起 :亚洲不仅是模型的生产地,更是迅猛增长的消费地,其市场份额从最初的 13% 飙升至 31%,实现了翻倍增长。
-
新加坡成"意外黑马" 在具体国家的流量排名中,出现了一个有趣的现象:新加坡 以 9.21% 的份额超越了德国(7.51%)和中国(6.01%),高居全球第二,仅次于美国。这可能反映了其作为区域数据中心枢纽或高科技企业聚集地的特殊地位。
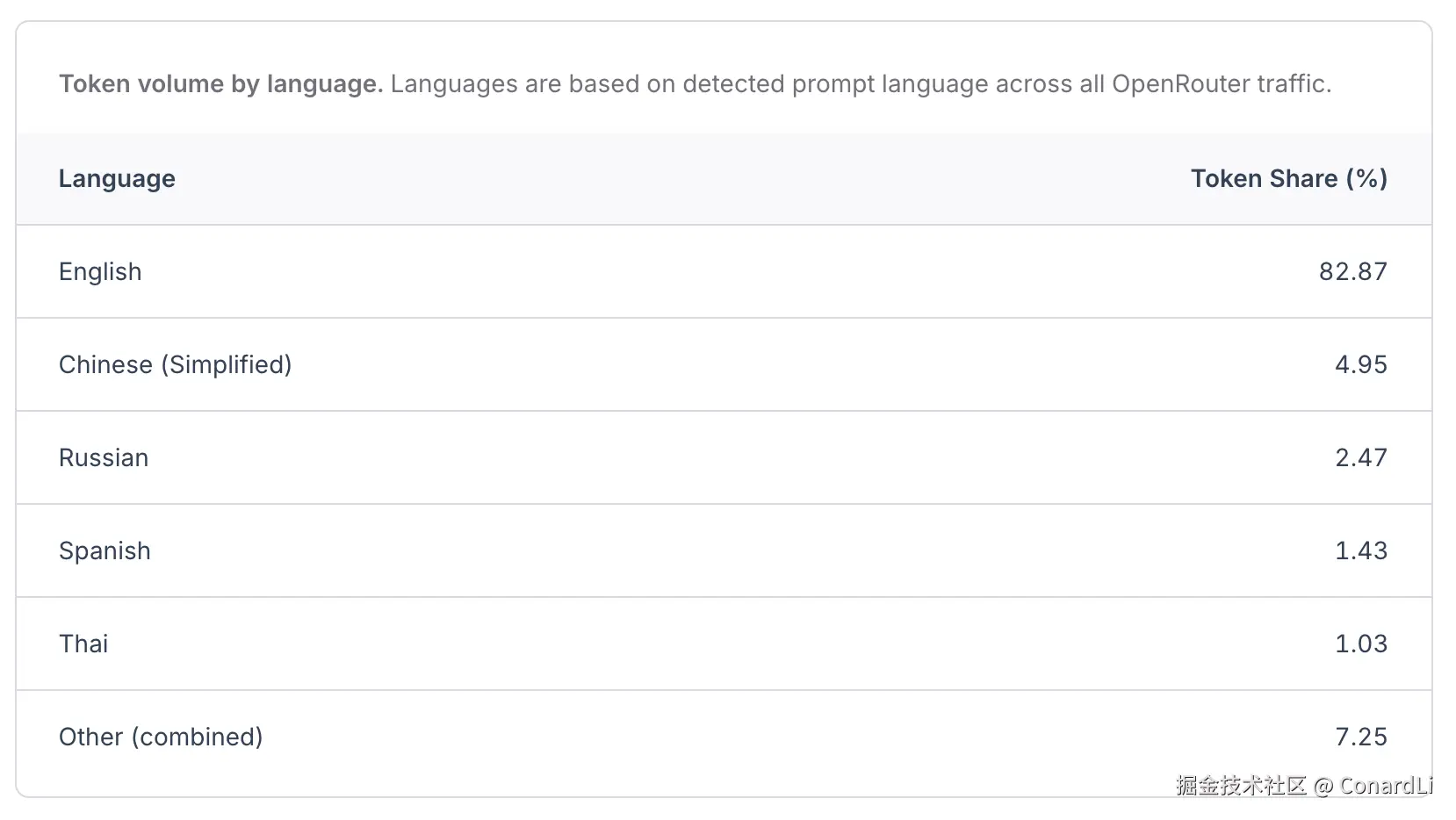
- 英语绝对主导,中文稳居第二 在语言分布上,英语依然具有压倒性优势,占据了超过 80% 的 Token 流量。简体中文以约 5% 的份额位居第二,这主要得益于 DeepSeek、Qwen 等国产开源模型的广泛应用。其余如俄语、西班牙语等虽然占比不高,但也构成了重要的长尾市场。
对于模型厂商和基础设施运营商来说,仅关注单一市场已不够。面对这种全球化但又高度本地化(不同语言、不同合规要求)的使用习惯,跨区域的服务能力已成为竞争的基本门槛。
十二、用户留存:从"尝鲜"到"依赖"
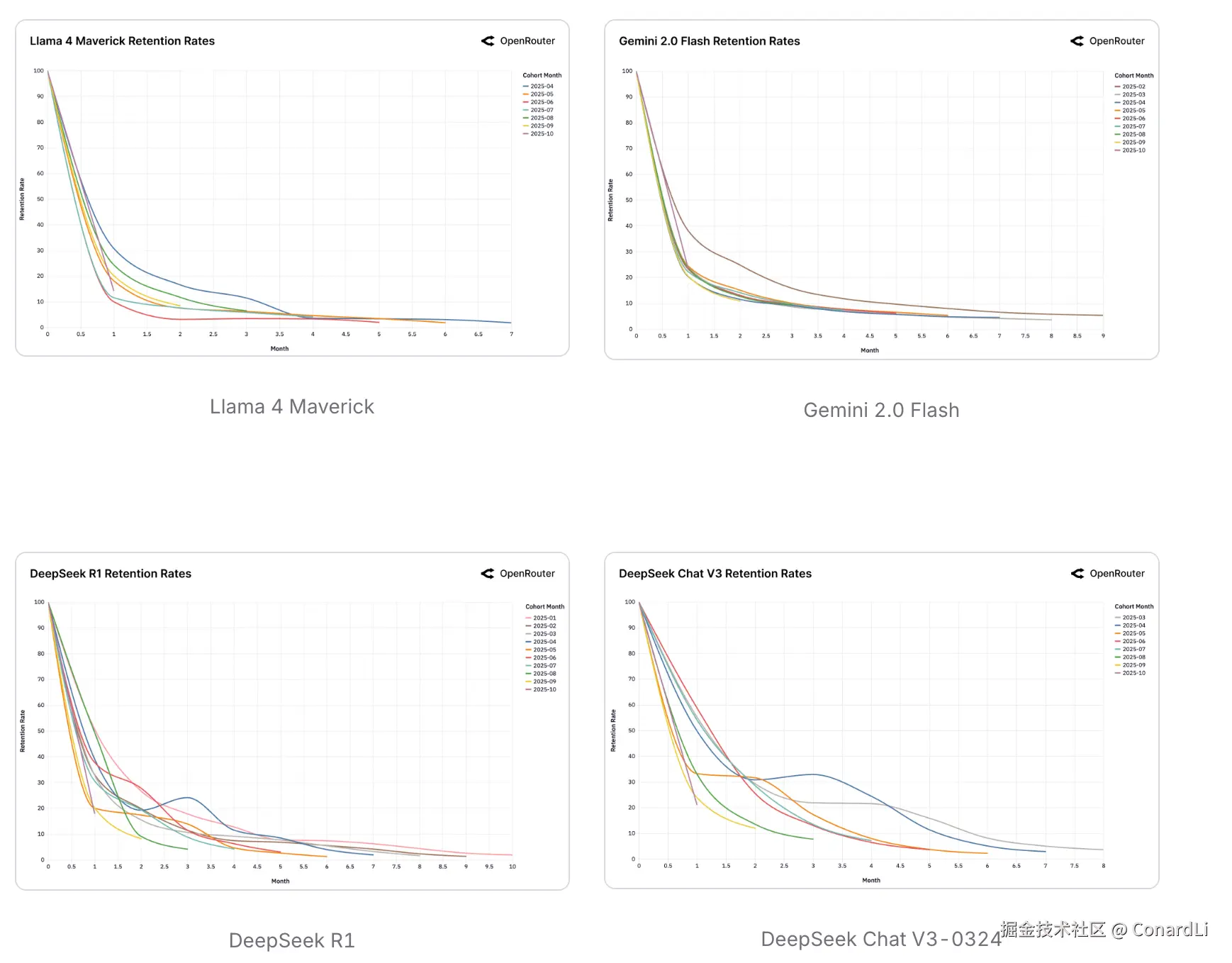
-
只有解决痛点,才能"锁死"用户 数据揭示了一个残酷的规律:用户不仅仅是来"玩玩"的。只有当一个新模型完美解决了用户之前解决不了的具体难题(无论是技术突破还是成本极低),用户才会真正长期留下来。一旦业务跑通,用户为了稳定,基本不会再换模型。
-
先发优势就是一切 真正忠诚的用户,往往是模型刚发布时最早进来的那一批。因为模型最早帮这批人解决了问题,他们把系统和代码都基于这个模型搭好了,迁移成本很高。后来的模型即使性能差不多,也很难再把这批人抢走。
-
平庸的模型留不住人 如果一个模型发布时只是"还行"、"够用",而没有在某一方面做到顶尖(比如 Gemini 2.0 Flash 和 Llama 4),结果就是灾难性的:用户试一下就全跑了,完全无法形成稳定的核心用户群。
-
DeepSeek 的"回头客"现象 DeepSeek 有个非常独特的数据特征:很多用户一开始流失了,但过了一两个月又回来了。这说明用户在对比了一圈其他竞品后,发现 DeepSeek 在性价比或特定能力上依然是市面上最好的选择,只能乖乖回来继续用。
十三、各类 AI 任务的成本与用量分布
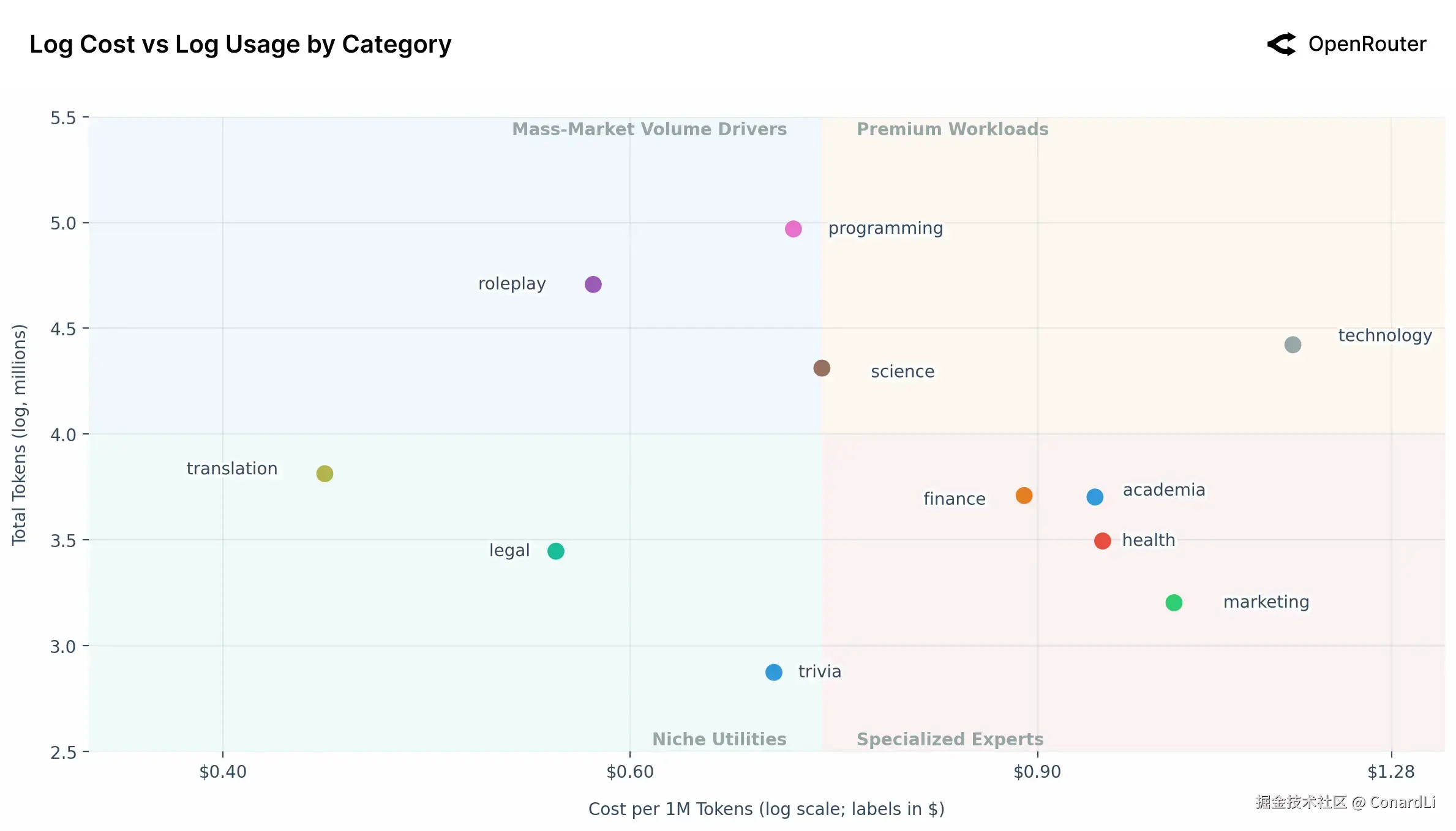
-
编程和角色扮演:量大且便宜 这是目前 AI 最大的两个流量池。它们的特点是:总使用量巨大,但平均单价很低(通常低于中位数 0.73 美元/百万 token)。这说明这两个领域已经非常成熟且普及,用户对价格敏感,倾向于使用经过优化的低成本模型(比如开源模型)。
-
"技术类"任务:又贵又有人用 数据中有一个非常显眼的异常值------"技术(Technology)"类任务(指系统架构、复杂技术方案设计等)。它的单价极高 ,远超其他类别,但使用量依然很大。这说明用户为了解决复杂的硬核技术问题,非常愿意支付高价。对模型厂商来说,这是利润最丰厚的一块肥肉。
-
金融和医疗:低频但高价 金融、学术、医疗等专业领域的特点是**"用的少,但给钱多"**。用户不会像写代码那样天天问,但因为对准确性和专业度要求极高,一旦需要使用,他们愿意为昂贵的高端模型付费。
-
翻译和法律:低价且低频 翻译、法律常识和冷知识问答属于低成本、低流量区域。这说明这类任务已经被"商品化"了,技术门槛不高,用户觉得用便宜的模型随便跑跑就够用了,不需要花大价钱。
十四、价格与用量的关系:便宜未必有人买,贵也有人抢
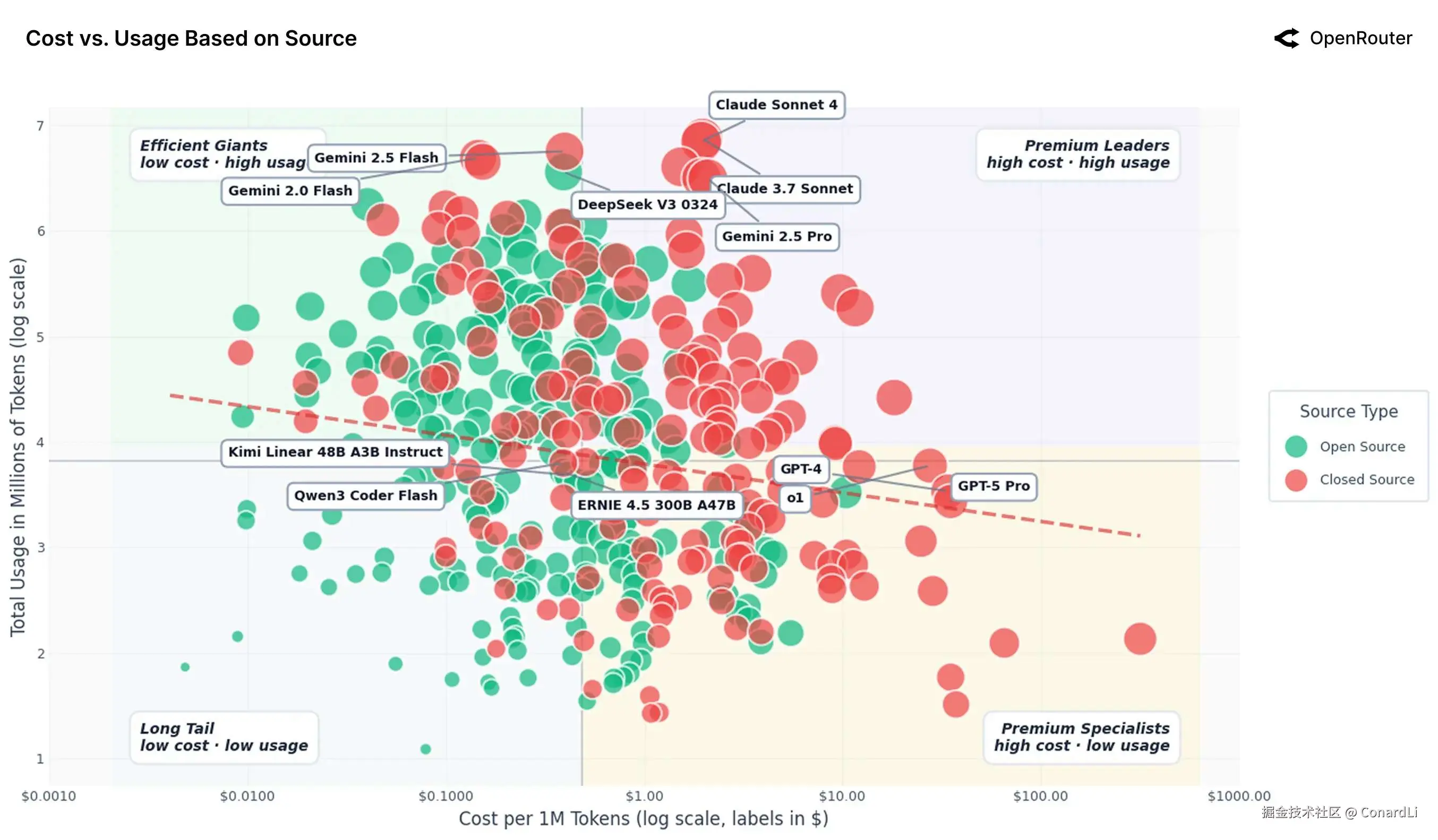
-
降价换不来销量 数据显示,模型市场的需求对价格非常不敏感。整体来看,价格降低 10%,用量才增加不到 1%。这说明大家选模型主要看"能不能干成事",而不是单纯图便宜。
-
市场分成了四类
- 高价爆款(Premium Leaders): 比如 Claude Sonnet 系列。虽然价格不菲(约 $2/百万 token),但用量巨大。说明只要模型足够好、足够稳,用户是愿意掏钱的。
- 性价比巨头(Efficient Giants): 比如 DeepSeek V3 和 Gemini Flash。价格便宜(不到 $0.4)且能力强,是目前跑大批量任务的默认首选。
- 顶级专家(Premium Specialists): 比如 GPT-5 Pro。极贵(约 $35),用量不大。只有在处理最难、最关键、绝对不能出错的任务时,大家才舍得用它。
- 廉价长尾(Long Tail): 很多小模型虽然便宜到几乎白送,但依然没人用。因为能力不行或不好集成,再便宜也是浪费时间。
-
只有"便宜"是没用的 数据狠狠打脸了"价格战"策略。单纯把价格做到极低并不能吸引用户。模型必须先达到"好用"的及格线,便宜才有意义。如果能力不够,开发者根本不敢把它集成到产品里。
-
闭源做"难事",开源做"杂事" 目前形成了一个明显的格局:闭源模型(如 OpenAI, Anthropic)虽然贵,但大家用它来处理高价值、高难度的核心任务;开源模型(如 DeepSeek, Qwen)因为便宜,大家用它来处理那些对精度要求没那么高、但数据量巨大的日常任务。
最后
关注《code秘密花园》从此学习 AI 不迷路,相关链接:
- 本报告原文 PDF:pan.quark.cn/s/897885724...
- AI 教程完整汇总:rncg5jvpme.feishu.cn/wiki/U9rYwR...
- 相关学习资源汇总在:github.com/ConardLi/ea...
如果本期对你有所帮助,希望得到一个免费的三连,感谢大家支持