文章目录
这里是@那我掉的头发算什么
刷到我,你的博客算是养成了😁😁😁

流
java中针对文件内容的操作,主要是通过一组流对象来实现的。

因此,计算机中针对读写文件,也是使用流(Stream)这一词语。
流是操作系统层面的词语,与编程语言无关,任何编程语言操作文件,都叫流。
输入输出
输入:数据的流向:硬盘-》cpu
输出:数据的流向:cpu-》硬盘(文件就是存储在硬盘中)
文件内容的读写--数据流
java提供了一组类表示流。这一组类总的来说分为两大类:字节流和字符流
字节流读写文件是以字节为单位的,针对二进制文件。主要涉及的类是InputStream(输入-从文件读数据),OutputStream(输出-向文件写数据)。
字符流读写文件是以字符为单位的,针对文本文件。主要涉及的类是Reader(输入-从文件读数据),Writer(输出-向文件写数据)。
Java中其他的流对象都是直接/间接继承这几个类。
这四个类其实都是抽象类,不能进行实例化,使用时需要搭配他们的子类使用。


InputStream -- FileInputStream
java
public static void main(String[] args) throws FileNotFoundException {
InputStream input = new FileInputStream("./test.txt");
}这里的创建流操作,相当于打开文件的操作:进程会在其对应的文件描述符表(固定长度的顺序表)中申请一个表项,用于关联目标文件的硬盘资源(类似 C 语言的fopen操作)。
有了打开就要有关闭,若只打开文件而不关闭,文件描述符表的表项会被耗尽,后续文件打开操作会失败,这种问题称为 "文件资源泄露"(类似内存泄露但针对文件资源)。
但是如果进程因为异常导致关闭操作没有执行,就会产生问题,所以我们需要优化一下代码。
java
public static void main(String[] args) throws IOException {
InputStream input = null;
try{
input = new FileInputStream("./test.txt");
}finally {
input.close();
}
}但是此时还是有可能发生input.close()时空指针异常,我们可以采用try-with-resources方法。
try-with-resources
java
public static void main(String[] args) throws IOException {
try(InputStream input = new FileInputStream("./test.txt");){
}
}这个代码的逻辑就是,只要出了try代码块,就会自动执行input.close()。
确实这个办法很好用,咱们前面介绍过ReentranLock锁,这里可不可以同样使用呢?
不行,想要拥有这个特性,要求必须实现了Closable接口。

接下来就可以开始读取文件了。

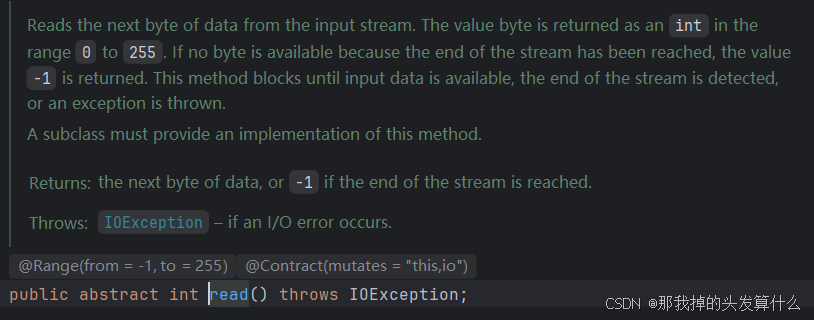
read的实际输出是0-255之间的一个数字,此处使用int作为返回值的原因是可以使用-1表示读取完毕,而且byte类型范围有限,只能表示-128 - 127,并且java中没有类似于无符号类型的东西。
java
public static void main(String[] args) throws IOException {
try(InputStream input = new FileInputStream("./test.txt");){
while(true){
int result = input.read();
if(result == -1){
break;
}
System.out.println(result);
}
}
}当我们实际读取的时候,读取出来的将会是一些带有特殊含义的数字:
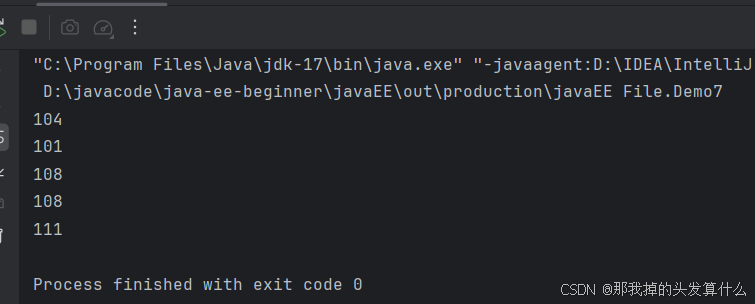
这些数字其实对应着的是ascii码,翻译过来是英文hello。
此时我们将test.txt文件中的内容修改成中文"你好",此时的输出结果是:

因为我们是utf8编码集,一个汉字占三个字节,没毛病。但是这些字符是啥意思呢?我们可以查阅相关资料来查明。
http://mytju.com/classcode/tools/encode_utf8.asp
查看utf8编码集的网站

我们默认的输出是十进制,但是将三个字节分别输出为十进制没有意义,我们可以将输出改为16进制,这样就可以直观的分析结果了。
java
System.out.printf("0x%x\n",result);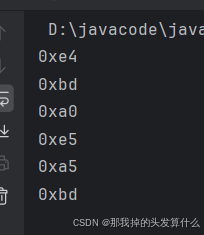
与编码集结果相同。
输出型参数
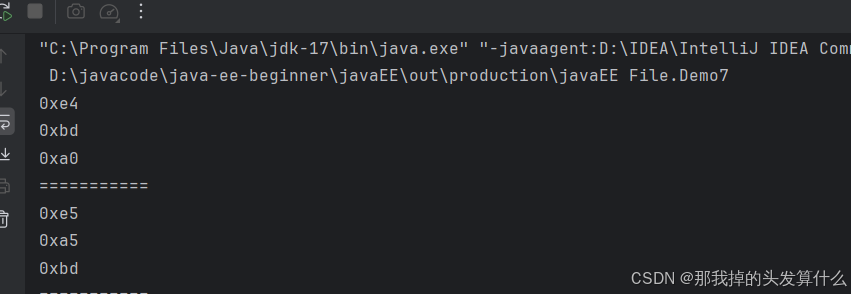
java
while(true){
byte[] data = new byte[3];
int n = input.read(data);
if(n==-1){
break;
}
for (int i = 0; i < n; i++) {
System.out.printf("0x%x\n",data[i]);
}
System.out.println("===========");
}
输出型参数的定义
通常方法的逻辑是 "参数(原材料)→返回值(产品)",但当需要返回多个数据时,部分语言(如 Java、C++)因 "一个方法仅支持一个返回值" 的限制,会将参数作为 "容器" 承载其中一个输出结果,这类参数即为 "输出型参数"。
Java 中输出型参数的特点需用引用类型:只有引用类型(如数组、对象)的参数能作为输出型参数 ------ 因为引用类型传递的是地址,方法内部修改对象内容会同步影响方法外部;基本类型是值传递,无法实现此效果。
示例(FileInputStream 的 read 方法):
byte\[\] data = new byte1024; // 作为输出型参数的数组(容器)
int n = inputStream.read(data); // 方法将读取的内容存入data,同时返回实际读取长度n
这里data是输出型参数(承载 "读取的内容"),n是返回值(承载 "实际长度"),实现了 "一个方法返回两个结果" 的效果。
我们仔细看一下read方法,发现除了第一个方法返回值是int之外,其他的方法居然也都是int?正常来说,第一个方法读取一个字节并且返回,很合理,那其他的方法是何意味呢?这就用到了上面讲的输出型参数。此时read方法的逻辑就是:传入一个字节数组,调用read方法后,返回的值是数组中有效的位数(满了就返回数组长度)。这么做有什么好处呢?(我分一下段落来讲)
首先,一般来说我们给出的数组就算很大,也很难一下子把所有的数据读出来,况且数组大还会有一些代价。一般在使用read时,我们都会搭配循环使用,每一次读取一部分的数据以便后面进行处理。怎么判断读完了?那就是返回值是-1的时候。并且,最后一次读取时,数组可能没被填满,此时返回的值代表的有效数据数就很有价值了。
OutputStream -- FileOutputStream
java
public static void main(String[] args) {
try(OutputStream outputStream = new FileOutputStream("./out.txt")){
outputStream.write(97);
outputStream.write(98);
outputStream.write(99);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
对于OutputStream来说,默认情况下会创建不存在的文件。
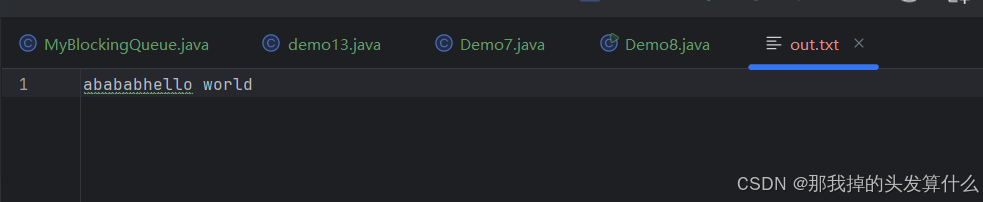
如果我们多次运行程序,out.txt文件中仍然是abc,说明,写文件时并不是向文件中直接写入数据,而是先将原来的数据清除,再写入新的数据。此时是覆盖模式。
我们构造FileOutputStream对象时其实还可以传入第二个参数boolean append,不传参默认为false,不可追加,覆盖模式,写入数据时先清空原数据再写入新数据,如果设置为true,写入数据时写到文件末尾,如果文件是空的,先创建再写入。
如果写入文本数据,需要显式指定编码:
java
public static void main(String[] args) {
try(OutputStream outputStream = new FileOutputStream("./out.txt",true)){
// outputStream.write(97);
// outputStream.write(98);
String content = "hello world";
byte[] bytes = content.getBytes("UTF-8");
outputStream.write(bytes);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
Reader -- FileReader
java
public static void main(String[] args) {
try(Reader reader = new FileReader("./test.txt")){
while(true){
char[] cbuf = new char[1024];
int n = reader.read(cbuf);
if(n == -1){
break;
}
for (int i = 0; i < n; i++) {
System.out.println(cbuf[i]);
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
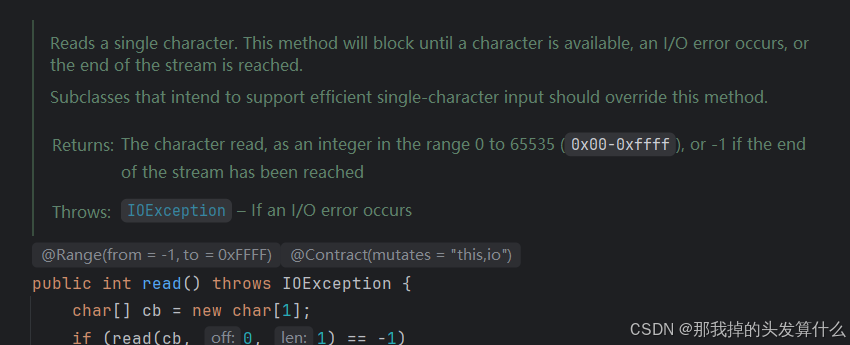
(read方法无参数时输出的是2个字节的数据 0x0000-0xffff)
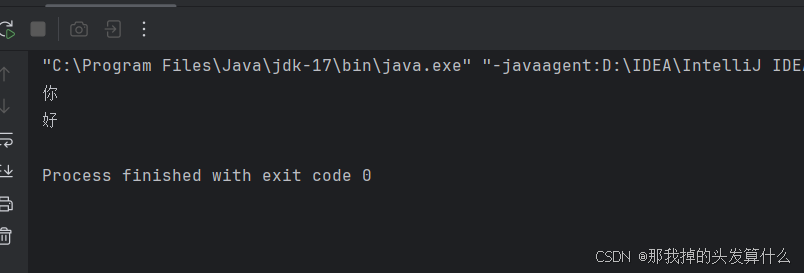
使用方法与字节流没什么太大的区别,但是对于这个输出结果,大家可能会有异议:
我们之前一直说,UTF-8中一个汉字占3个字节,但是此处的read方法输出的应该是char类型的两个字节的数据,为什么把你好两个字完整地输出了出来呢?
首先,你好在UTF-8编码下,保存在硬盘上就是6个字节,一个汉字三个字节。字节流读取时读取的是原数据,三个字节。但是字符流在读取的时候会根据文件内容进行解析,首先根据UTF-8一次读三个字节,然后将三个字节在UTF中查一下得到"你",继而在unicode这个码表查一次,得到unicode编码值。最终把这个编码值返回到char变量中,就是两个字节。
转码原因
Java 字符类型的底层定义
Java 中的 char 类型、String 类,本质上都是以 Unicode 的 UTF-16 编码形式 存储的 (char 本身就是 2 字节,对应 UTF-16 的基本字符单元)。所以无论外部文件用什么编码(UTF-8、GBK 等),字符流读取时必须先将外部编码转成 Unicode,才能存入 Java 的字符 / 字符串变量中。
统一内部字符处理逻辑 不同外部文件可能用不同编码(比如有的用 UTF-8、有的用 GBK),如果 Java 内部不统一编码,处理字符时就要频繁适配各种外部编码,会导致跨平台、跨编码的字符操作(比如字符比较、拼接、正则匹配)变得混乱且复杂。而统一用 Unicode,就能让 Java 内部的字符操作 "无视外部编码差异",保证逻辑一致、跨环境兼容。
简单说:外部编码(如 UTF-8)是 "存储 / 传输时的格式",而 Unicode 是 "Java 内部处理字符的统一格式",所以字符流读取外部数据后,必须转成 Unicode 才能在 Java 中使用。
不过,这样的转码肯定是有性能开销的,实际情况字节流比字符流快也是毋庸置疑的。但是比如我想读取文件中的第二个字符,这个操作用字符流很简单,用字节流的话很麻烦,首先需要搞清楚源文件的编码方式并且需要手动转码。
Writer -- FileWriter + BufferedWriter "缓冲区"

java
public static void main(String[] args) {
try(Writer writer = new FileWriter("./writer.txt")) {
writer.write("hello world");
BufferedWriter bufferedWriter = new BufferedWriter(writer);
bufferedWriter.write("Hello World");
//bufferedWriter.flush();
bufferedWriter.close();
} catch (IOException e) {
throw new RuntimeException(e);
} ;
}直接写入文件的方法与字节流类似,不过我们可以直接写入字符串了。
此外,还有一种BufferedWriter类,BufferedWriter的核心作用是提升写入性能------ 因为磁盘 IO(和文件的实际交互)是比较耗时的操作,BufferedWriter通过 "缓冲" 减少了实际 IO 的次数。
直接用FileWriter的问题
FileWriter是无缓冲的字节流包装类,它的write方法默认是写一次数据,就触发一次磁盘 IO(比如写 "Hello World" 这 11 个字符,会直接把这 11 个字符对应的字节写到磁盘)。
如果是频繁写入小数据(比如循环写 1000 次 "Hello"),就会触发 1000 次磁盘 IO,性能会很低(磁盘 IO 的速度远慢于内存操作)。
BufferedWriter的作用:内存缓冲,减少 IO 次数
BufferedWriter内部维护了一个内存缓冲区(默认大小是 8192 字节,即 8KB):
调用write时,数据会先写到内存缓冲区里;
当缓冲区被写满,或者主动调用flush()/close()时,才会把缓冲区里的所有数据一次性写入磁盘。
比如同样写 1000 次 "Hello",BufferedWriter会把这些数据先存到内存缓冲区,攒够 8KB 再写一次磁盘,实际 IO 次数会从 1000 次降到几次,性能提升非常明显。
flush()是不释放资源,直接将缓冲区数据写入,close是释放资源,自动调用flush将缓冲区数据写入。注意:flush之后仍然需要close。
小总结
1.流对象的使用
先打开再使用,最后要关闭
2.应该使用哪个流对象
先区分是二进制文件还是文本文件,再区分是读操作还是写操作
案例练习
扫描指定⽬录,并找到名称中包含指定字符的所有普通⽂件(不包含⽬录),并且后续询问⽤⼾是否要删除该⽂件
java
package File;
import java.io.File;
import java.util.Scanner;
public class Demo11 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要搜索的目录");
String rootDir = scanner.next();
File rootFile = new File(rootDir);
if(!rootFile.isDirectory()){
System.out.println("输入的不是目录");
return ;
}
System.out.println("请输入要删除的关键字");
String keyword = scanner.next();
scanDir(rootFile,keyword);
}
private static void scanDir(File rootFile, String keyword) {
File[] files = rootFile.listFiles();
if(files == null){
return;
}
for(File file : files){
System.out.println("遍历目录&文件: " + file.getAbsolutePath());
if(file.isDirectory()){
scanDir(file,keyword);
}else{
dealFile(file,keyword);
}
}
}
private static void dealFile(File file, String keyword) {
if(file.getName().contains(keyword)){
System.out.println("发现文件"+ file.getName() + "包含关键字" + keyword + "是否删除?y/n");
Scanner scanner = new Scanner(System.in);
String input = scanner.next();
if(input.equals("y")){
System.out.println("文件" + file.getName()+ "已删除");
file.delete();
}
}
}
}进⾏普通⽂件的复制
java
package File;
import java.io.*;
import java.util.Scanner;
public class Demo12 {
public static void main(String[] args) {
System.out.println("请输入源文件路径");
Scanner scanner = new Scanner(System.in);
String srcPath = scanner.next();
System.out.println("请输入目标文件路径");
String destPath = scanner.next();
File srcFile = new File(srcPath);
File destFile = new File(destPath);
if(!srcFile.isFile()){
System.out.println("源文件不存在或者不是一个文件");
return;
}
if(!destFile.getParentFile().isDirectory()){
System.out.println("目标文件所在的目录不存在");
return;
}
copyFile(srcFile,destFile);
System.out.println("复制成功");
}
private static void copyFile(File srcFile, File destFile) {
try(InputStream inputStream = new FileInputStream(srcFile);
OutputStream outputStream = new FileOutputStream(destFile)){
while(true){
byte[] bytes = new byte[1024];
int n = inputStream.read(bytes);
if(n == -1){
break;
}
outputStream.write(bytes,0,n);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}扫描指定⽬录,并找到名称或者内容中包含指定字符的所有普通⽂件(不包含⽬录)
java
package File;
import java.io.*;
import java.util.Scanner;
public class Demo13 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要扫描的目录");
String rootDirPath = scanner.next();
File rootDir = new File(rootDirPath);
if(!rootDir.isDirectory()){
System.out.println("输入的不是目录或者目录不存在");
}
System.out.println("请输入要删除的字符");
String keyWord = scanner.next();
scanDir(rootDir,keyWord);
}
private static void scanDir(File rootDir, String keyWord) {
File[] files = rootDir.listFiles();
if(files == null){
return;
}
for(File file:files){
System.out.println("正在检查文件: " + file.getAbsolutePath());
if(file.isDirectory()){
scanDir(file,keyWord);
}else{
if(file.getName().contains(keyWord)){
System.out.println("找到文件" + file.getName() + "文件名中包含" + keyWord + "关键字");
}else{
scanFile(file,keyWord);
}
}
}
}
private static void scanFile(File file, String keyWord) {
StringBuffer stringBuffer = new StringBuffer();
try(Reader reader = new FileReader(file)){
while(true){
char[] chars = new char[1024];
int n = reader.read(chars);
if(n == -1){
break;
}
stringBuffer.append(chars,0,n);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
if(stringBuffer.indexOf(keyWord) >= 0){
System.out.println("找到文件" + file.getName() + "文件内容中包含" + keyWord + "关键字");
}
}
}总结
Java文件流是Java中用于实现硬盘与内存间数据传输的核心机制,主要分为字节流和字符流两大体系:字节流以字节为操作单位,通过InputStream/OutputStream系列类适配二进制文件(如图片、视频),无编码转换且性能高效;字符流以字符为操作单位,通过Reader/Writer系列类适配文本文件,能自动完成外部编码(如UTF-8)与Java内部Unicode编码的转换,简化文本处理。使用时需遵循"打开-使用-关闭"的生命周期,优先采用try-with-resources语法实现资源自动关闭,避免文件资源泄露,同时可搭配缓冲流(Buffered系列)减少磁盘IO次数以提升性能。无论是文件读写、复制、搜索还是关键字匹配等实战场景,均可根据文件类型(二进制/文本)和操作需求(性能/便捷性)选择合适的流对象,实现高效、安全的文件操作。