1.Introduction
本文主要探索了再没有使用有监督数据的情况下,对模型直接进行pure RL 训练以提升模型的推理能力。
DeepSeek-R1-Zero: 以DeepSeek-V3作为Base model,进行Pure RL训练,作者发现虽然推理能力具有显著效果,但是也会有一些缺点: 可读性差、语言混乱等问题。
DeepSeek-R1: 为了解决这些问题和进一步提升模型的推理能力,作者又在R1-Zero的基础上进行了冷启动和多阶段训练等步骤。
最后作者又探索了使用推理能力强的R1蒸馏到小模型上,对小模型的推理能力是否有提升。
2.Approach
2.1 DeepSeek-R1-Zero

采用了GRPO算法。
Reward Modeling
此处作者没有使用神经网络模型和结果级奖励模型 作为Reward model。

此处不使用这两个模型的原因有两个:
- Reward Hacking:Reward模型的训练目标是最大化奖励分值,而不是提高生成质量。如果reward model训练的不好,模型容易钻空子,欺骗神经网络去获得高分,而不是去真正提升能力。
- 需要不断的训练Reward model,训练资源和工程复杂度较高。
因此,采用了基于规则的奖励模型,由两部分奖励组成: - Accuracy Reward : 评估模型的回答是否正确。
- Format Reward : 训练了一个模型用来强制要求模型回答的格式符合要求。
因此,此阶段的主要训练数据是具有确定性的答案。比如数学题和代码题。必须拥有客观的,可自动验证的标准答案。
缺点: 也就是R1-Zero的局限性。由于使用的基于规则的奖励,在确定性任务上表现很强,但在开放性任务上能力严重退化。

DeepSeek-R1
R1设计了一个四阶段的流水线。
先利用 R1-Zero 验证出的"纯 RL 路线"产生强大的推理能力,再通过 SFT(监督微调)将这种能力"格式化"并泛化到通用任务,最后再进行一轮 RL 对齐。
第一阶段 :冷启动SFT。
目的: 教会模型使用 <think> 和 <answer> 格式,并输出条理清晰、人类可读的思维链。
作者探索了集中方式用来收集数据:使用 long CoT 作为 example 的 few-shot 提示;通过 prompt 让模型生成包含反思(reflection)和验证(verification)的详细答案;收集 DeepSeek-R1-Zero 的可读格式输出,并通过人工标注后处理来完善结果。

评价指标:交叉熵损失,让模型预测next token。
第二阶段:以推理为导向的强化学习
此阶段本质上是R1-Zero的复刻,但是经过了SFT,模型起点更高。
同时,为了解决语言混合的问题, 引入了语言一致性奖励损失 ,计算方式为目标语言在COT中占的比例。虽然这会使模型表现下降一些。
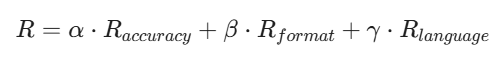
第三阶段:拒绝采样和SFT

第四阶段:全场景强化学习 (All-Scenario RL)
