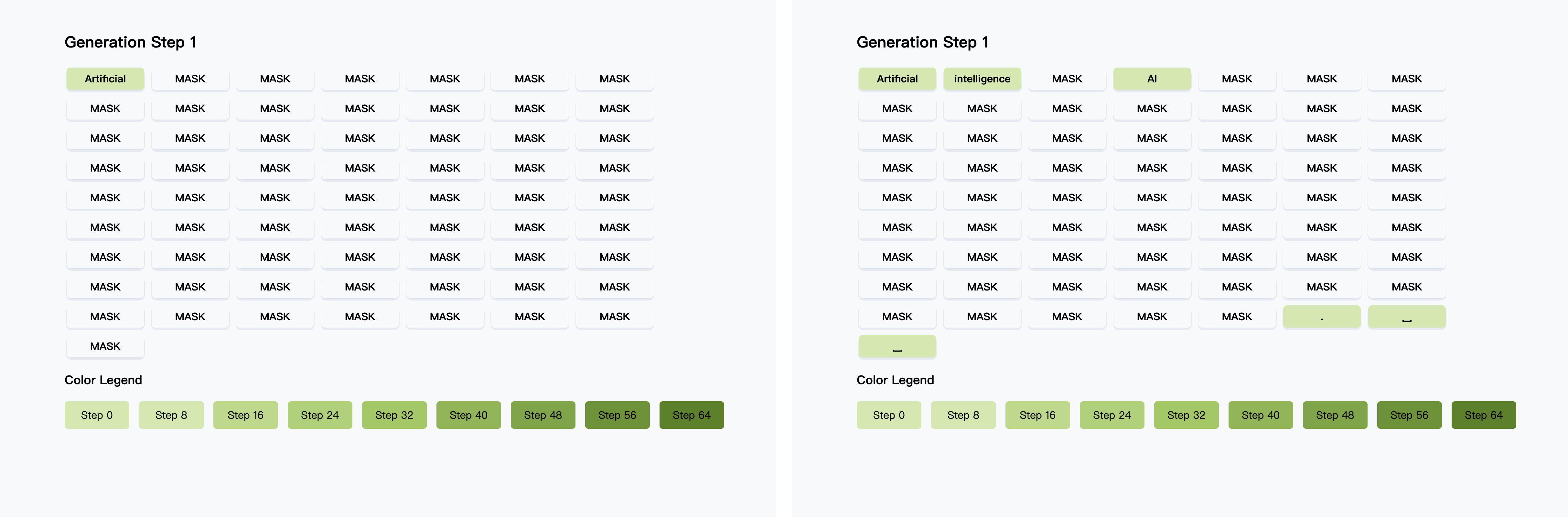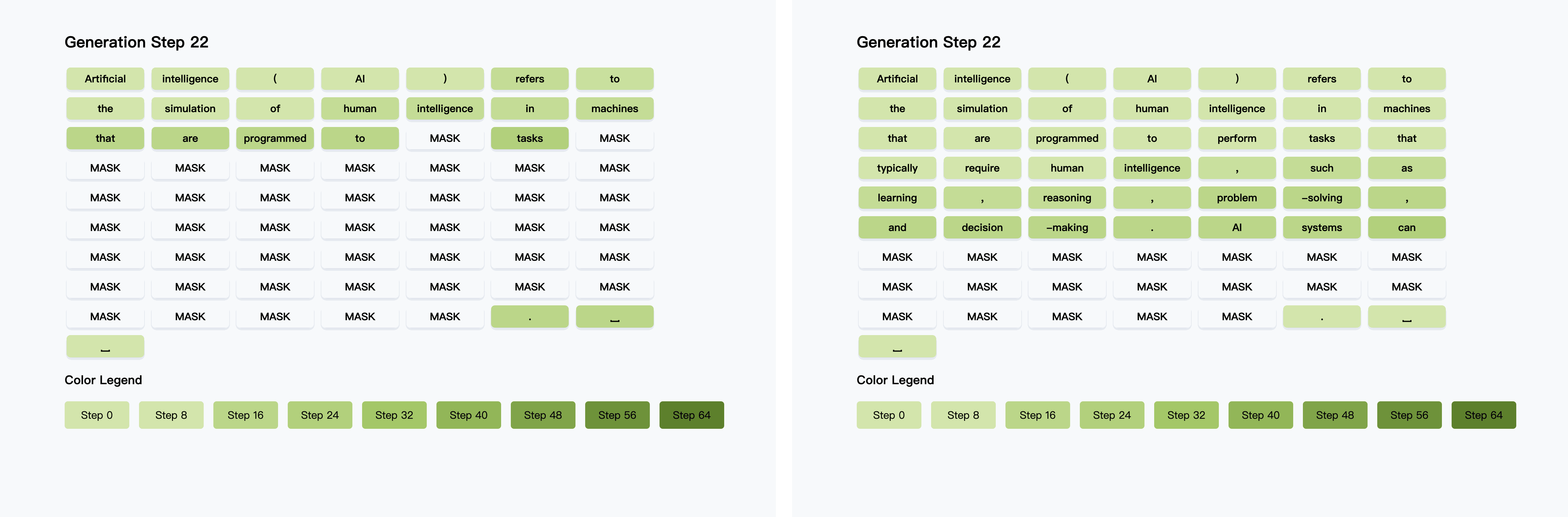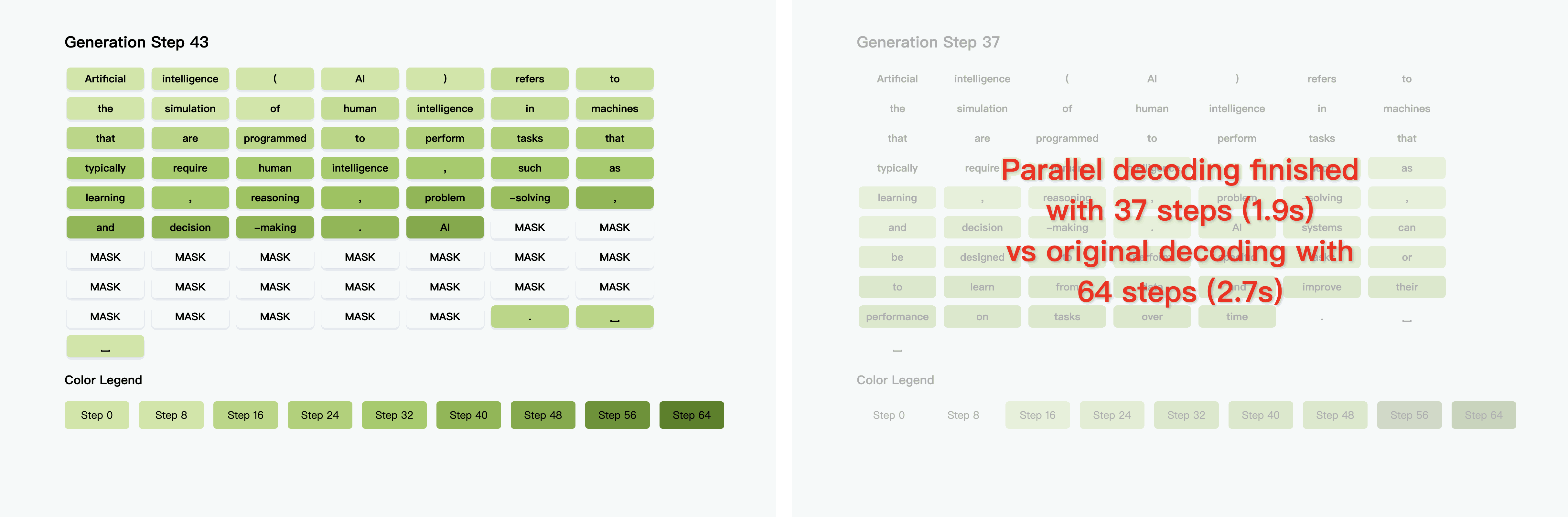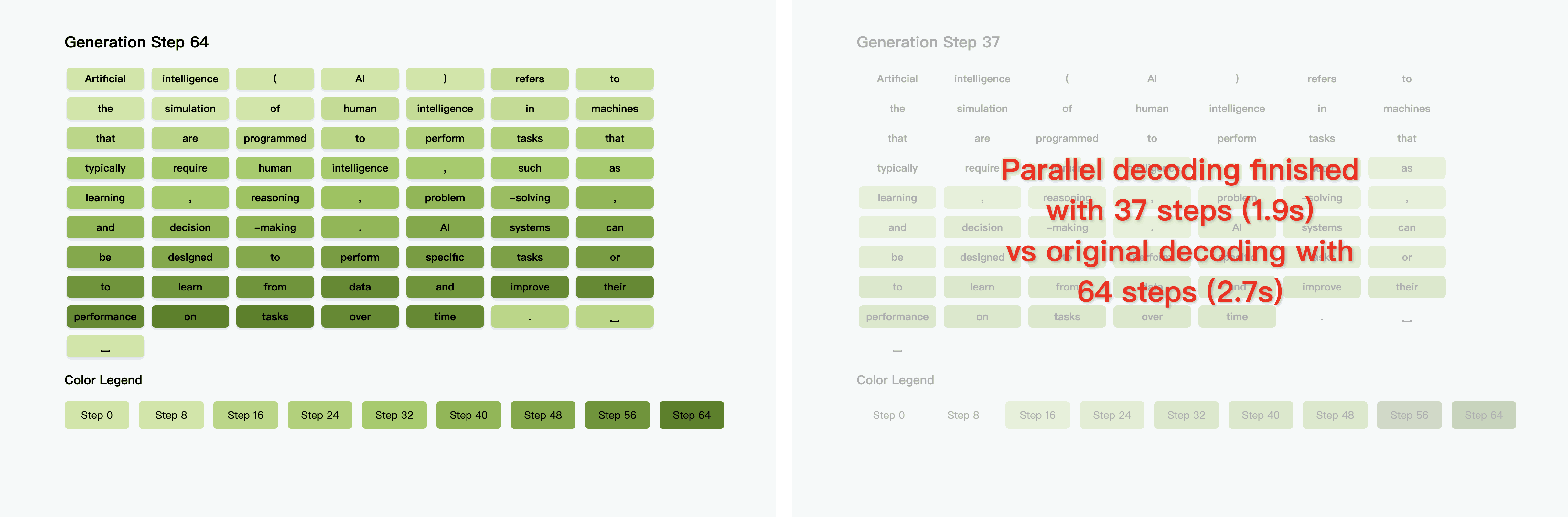
在往期的 #青稞Talk 中,香港大学MMLab博士生吴成岳,曾直播分享过Fast-dLLM!Fast-dLLM 是 NVIDIA 联合香港大学、MIT等机构推出的扩散大语言模型推理加速方案。
关于 Fast-dLLM 的介绍可以参考:
港大&NV&MIT开源Fast-dLLM:无需重新训练模型,直接提升扩散语言模型的推理效率
直播分享!Fast-dLLM技术解析:分块KV缓存与置信度感知并行解码技术
现在,Fast-dLLM v2来了!
Fast-dLLM v2 旨在通过高效块扩散架构突破大模型推理的速度瓶颈。
论文:https://arxiv.org/abs/2509.26328
代码:https://github.com/NVlabs/Fast-dLLM尽管现有 AR 模型生成质量优异,但逐 token 串行解码导致推理 latency 居高不下,而同类并行生成方案又面临数据需求大、兼容性差的问题。

Fast-dLLM v2 创新采用块内并行解码与块间因果关联设计,仅需 10 亿 token 微调即可无损适配预训练 AR 模型,数据量较同类减少 500 倍,搭配分层缓存机制实现最高 2.5 倍端到端加速。

实验表明,该模型在保持甚至超越 AR 模型生成质量的同时,显著降低部署成本,为大模型高效落地提供务实路径。


12月9日(周二)晚8点 ,青稞Talk 第95期,香港大学MMLab博士生吴成岳,将再次分享《Fast-dLLM v2:高效训练推理的块扩散大语言模型框架》。
分享嘉宾
吴成岳,研究领域包括多模态基础模型和大语言模型。迄今已在CVPR、ACL、ICML、NeurlPS 等国际顶会发表论文十余篇,六篇为第一作者,累计引用1500余次,相关开源项目在GitHub上获得超1.8万星标。
主导研发了统一的多模态理解框架Janus,在DeepSeek提出视觉编码解耦的新范式;在NVIDIA实习期间,作为Fast-dLLM 项目核心成员,提出理论驱动的解码算法,使扩散语言模型生成效率提升了 10 倍,后续迭代版本Fast-dLLM v2 进一步实现2-3倍加速。
主题提纲
Fast-dLLM v2:高效训练推理的块扩散大语言模型框架
1、自回归(AR)模型 vs 扩散 LLM(dLLM)
2、块扩散大语言模型框 Fast-dLLM v2
-
块内并行解码与块间因果关联
-
分层缓存机制
3、AMA (Ask Me Anything)环节
直播时间
12月9日20:00 - 21:00
如何观看
Talk 将在青稞社区【视频号:青稞AI 、Bilibili:青稞AI】上进行直播,欢迎预约观看!!!