2017年,一篇名为《Attention is All You Need》的论文悄然问世,当时没人预料到,它将成为改变AI发展轨迹的革命性架构------这就是Transformer。
想象一下,当你读到句子"猫很擅长捉老鼠,因为它很敏捷"时,你会立刻明白"它"指的是猫而不是老鼠。这种理解能力对人类来说轻而易举,但对机器来说却曾是个巨大挑战。
在Transformer出现之前,机器处理语言的方式就像是一个人排着长队传话------每个人只能听到前一个人说的话,再添加自己的理解继续传递。这种方式效率低下,且容易丢失重要信息。
直到Transformer架构的诞生,机器才真正获得了同时理解全局的能力。今天,就让我们通过一个具体例子,揭开GPT、BERT等大模型底层魔法的神秘面纱。
一、从一个例子开始:机器如何理解"它"指代什么?
让我们沿用"猫很擅长捉老鼠,因为它很敏捷"这个例子,看看Transformer是如何一步步理解指代关系的。
步骤1:将词语转化为向量
首先,模型将每个词转换为数字向量(词嵌入)。也就是说,"猫"、"捉"、"老鼠"、"因为"、"它"、"敏捷"都变成了512维的向量(在原始论文中)。
步骤2:创建查询(Q)、键(K)和值(V)
接着,模型为每个词生成三组向量:
- 查询(Q):代表**"我想要什么"**。它是当前词语(比如句子中的"它")发出的询问,表达了它想从其他词语那里获取什么样的信息。
- 键(K):代表**"我是谁"**。序列中的每个词语都会生成一个Key,它就像是每个词语的"身份证"或"标签",用于和Query进行匹配。
- 值(V) :代表**"我真正有用的信息"**。Value包含了每个词语的深层、核心的语义信息。当Query通过Key找到匹配对象后,真正被取用的是对应的Value。
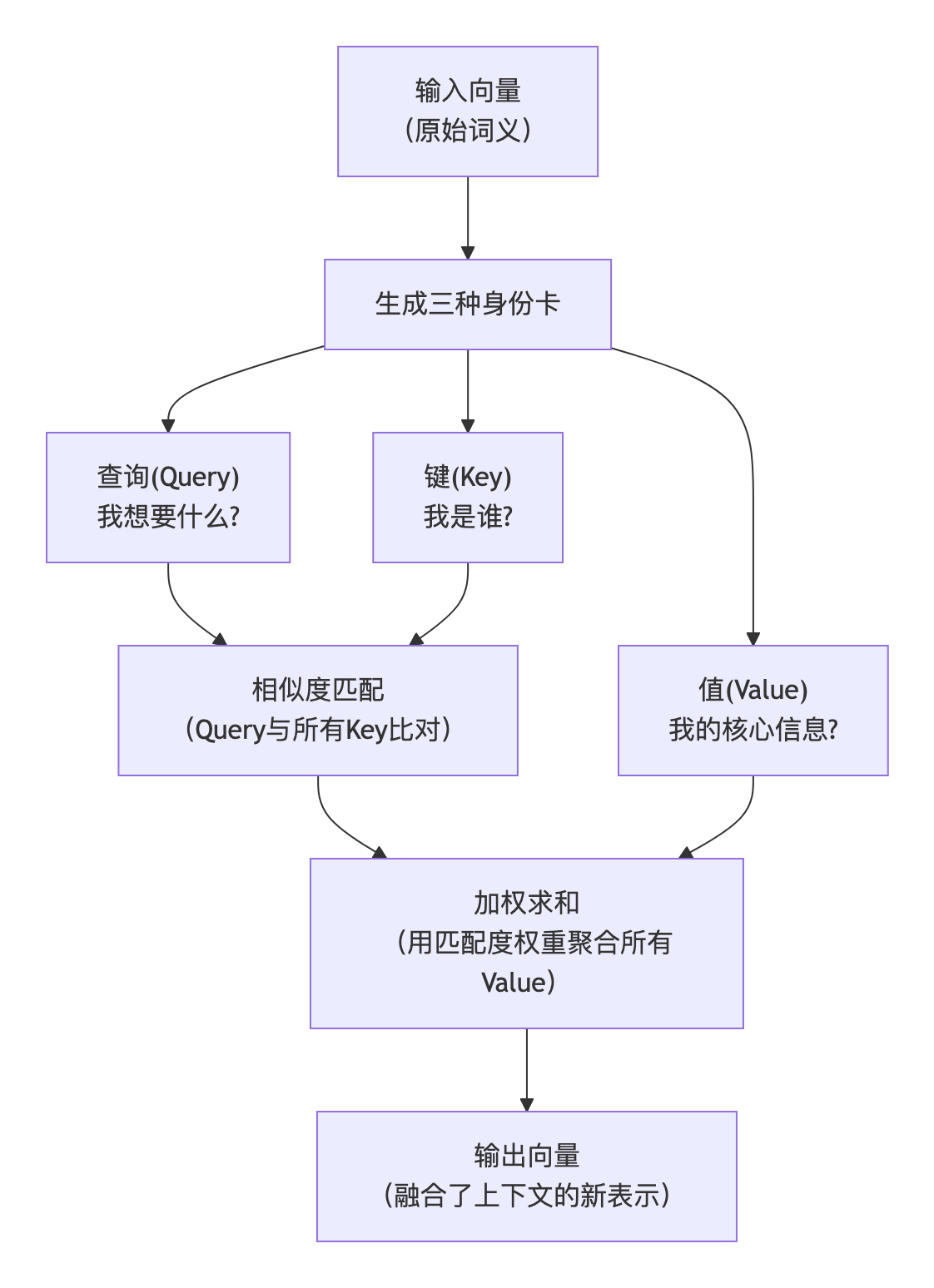
步骤3:计算注意力分数
当模型处理"它"这个词时,会用"它"的查询向量 去和句子中所有词的键向量计算相似度。这就像"它"在询问:"我和谁最相关?"
计算结果可能是:
- 与"猫"的相似度得分:8.0(很高)
- 与"老鼠"的相似度得分:7.0(高)
- 与"敏捷"的相似度得分:1.0(低)
- 与"捉"的相似度得分:0.5(很低)
步骤4:转化为注意力权重
通过Softmax函数将这些分数转换为百分比权重,确保所有权重之和为1:
- "猫"的权重:55%
- "老鼠"的权重:35%
- "它"自身的权重:5%
- 其他词共享剩余5%
步骤5:加权求和生成新表示
最后,模型用这些权重对所有词的值向量进行加权求和,生成"它"的新表示:
"它"的新向量 = 0.55 × V_猫 + 0.35 × V_老鼠 + 0.05 × V_它 + ...这样,"它"的向量就融合了"猫"和"老鼠"的特征,但明显更偏向"猫"。
当后面出现"敏捷"一词时,模型会进一步调整权重,因为"敏捷"更符合猫的特征。最终,模型确信"它"指的就是"猫"。
二、Transformer的核心组件
1. 自注意力机制:全局视野的源泉
自注意力机制是Transformer的核心创新,它允许模型在处理每个词时同时查看序列中的所有其他词,并动态地决定应该关注哪些词。
这与传统的循环神经网络形成鲜明对比:RNN像是一个只能前向传递信息的队伍,而自注意力机制像是整个团队同时坐在一起开会,每个成员都能直接与所有其他成员交流。
2. 多头注意力:多角度的专家会诊
如果自注意力机制已经很强大了,为什么还需要"多头"呢?想象一下,如果只派一名记者去报道国际会议,他可能只关注领导人的发言。
Transformer采用多头注意力机制,就像是派遣多个专家组成团队:
- 有的关注语法结构
- 有的关注指代关系
- 有的关注语义角色
- 有的关注逻辑连接
每个"头"学习关注不同的关系模式,最后将所有头的输出整合,得到更全面、更丰富的表示。
3. 位置编码:注入顺序信息
自注意力机制有一个先天缺陷:它本身是无序的。打乱输入词的顺序,自注意力机制的计算结果不会改变。但显然,"狗追猫"和"猫追狗"意思完全不同。
为了解决这个问题,Transformer引入了位置编码------为每个位置生成一个独特的向量,与词向量相加。这样,模型就能知道每个词在序列中的位置了。
位置编码通常使用正弦和余弦函数生成,这样模型不仅能知道绝对位置,还能理解相对距离(比如位置1和3的距离与位置2和4的距离相同)。
4. 残差连接与层归一化:训练深度网络的关键
Transformer通常有多层(原始论文中编码器和解码器各6层)。为了训练这么深的网络,需要一些技巧防止梯度消失或爆炸。
残差连接让信息可以"跳过"某些层,确保梯度能够有效回传。
层归一化则保持每层输入的稳定性,加速训练过程。
三、编码器-解码器结构
Transformer整体采用编码器-解码器结构:
编码器负责理解输入信息,由多个相同的层组成(每层包含自注意力机制和前馈神经网络)。
解码器负责生成输出,比编码器多了一个"编码器-解码器注意力"层,用于关注输入的相关部分。
在训练时,解码器使用掩码自注意力,确保每个位置只能关注之前的位置,而不能"偷看"未来的答案。
四、Transformer的革命性影响
Transformer的出现彻底改变了自然语言处理领域,其主要优势包括:
-
强大的并行能力:不同于RNN的顺序处理,Transformer可以同时处理整个序列,大幅提升训练速度。
-
强大的长距离依赖建模:传统RNN难以处理长距离依赖,而Transformer中任意两个词的距离都是1,轻松捕捉长远关系。
-
可扩展性强:Transformer的架构适合构建深层网络,为大规模预训练模型奠定基础。
从GPT系列到BERT,从机器翻译到蛋白质结构预测,Transformer架构已成为当代AI大模型的基石。它不仅在NLP领域大放异彩,还逐步扩展到计算机视觉、语音识别等多个领域。
结语
回到我们开头的例子,现在你应该理解了Transformer是如何通过自注意力机制智能地理解指代关系的。这种模仿人类注意力分配机制的设计,让机器在语言理解方面迈出了巨大的一步。
Transformer的成功证明了一点:有时,突破不在于增加复杂度,而在于找到更优雅、更本质的解决方案。自注意力机制正是这样一种简洁而强大的思想,它让我们向真正理解语言的机器又迈进了一大步。
本文通过具体例子剖析了Transformer的核心机制。实际上,GPT等大模型通常仅使用Transformer的解码器部分,而BERT等模型则使用编码器部分,这些变体在不同任务中各展所长。