最近在复盘一些深度学习相关的概念。组里做GNN的朋友也比较多,自然想到了半监督学习。这里就简单介绍一下半监督学习,整理一下相关的内容,以便后续科研使用。
什么是半监督学习?
半监督学习(Semi-Supervised Learning, SSL)利用少量的标记样本和大量的未标记样本来改善模型的学习能力,可以被看作是监督学习与无监督学习的"混合体"或"中间立场"。
我们可以把它想象成一个老师带学生"的过程:
- 监督学习:像是老师手把手教学生,每道题(数据)都有标准答案(标签)。
- 无监督学习:像是让学生自己在图书馆看书,没人告诉答案,全靠自己发现书里的规律。
- 半监督学习:像是老师先给学生讲几道典型例题(少量带标签数据 ),然后让学生自己去读大量的课外书(大量未标签数据 ),并尝试总结规律。学生读完后,把认为的答案(伪标签 )拿给老师批改,从而学得更好。
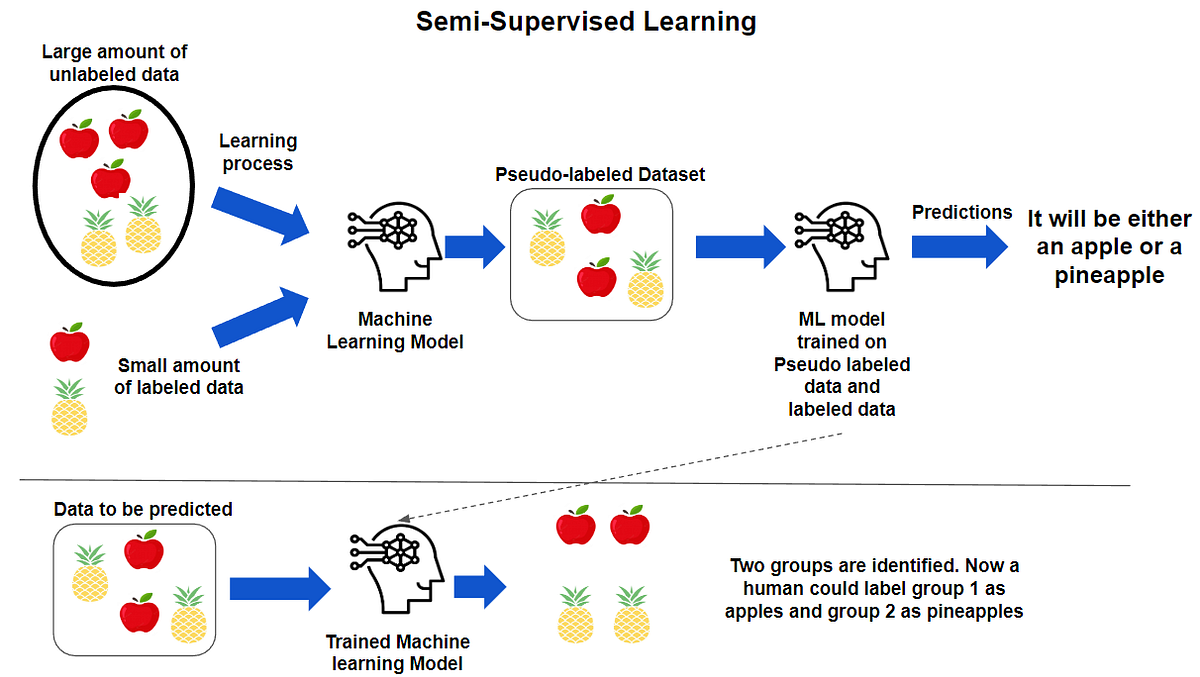
常见的半监督学习算法流程设计如下:
- Step 1:准备数据
有标签数据 L=(xi,yi)L={(x_i,y_i)}L=(xi,yi)(数量少)
无标签数据 U=xjU={x_j}U=xj(数量多) - Step 2:初始化模型
用 L 预训练模型,或随机初始化 - Step 3:联合训练(核心)
同时优化两类损失:
(1)监督损失:在 L 上计算(如交叉熵)
(2)无监督损失:在 U 上施加约束,常见方式包括:
一致性正则化(增强前后预测一致);伪标签(高置信度预测作为目标);熵最小化(鼓励对无标签样本做出确定性预测)
L=1∣L∣∑(x,y)∈LH(y,fθ(x))⏟临督损失 +1∣U′∣∑xu∈U′H(y^,fθ(A(xu)))⏟伪标签一致性损失 \mathcal{L}=\underbrace{\frac{1}{|L|} \sum_{(x, y) \in L} H\left(y, f_\theta(x)\right)}{\text {临督损失 }}+\underbrace{\frac{1}{\left|U^{\prime}\right|} \sum{x_u \in U^{\prime}} H\left(\hat{y}, f_\theta\left(A\left(x_u\right)\right)\right)}_{\text {伪标签一致性损失 }} L=临督损失 ∣L∣1(x,y)∈L∑H(y,fθ(x))+伪标签一致性损失 ∣U′∣1xu∈U′∑H(y^,fθ(A(xu))) - Step 4:评估模型
在独立、带真实标签的测试集上计算标准指标(如准确率)。
很自然会有一些问题,如下:
-
Q1:为什么需要半监督学习?与自监督学习对比,有什么优势?
A1 :半监督学习在标注成本高 + 数据量大的现实约束下,提供了一种高效利用资源的折中方案:用少量标注数据 + 大量未标注数据 → 训练出高性能模型。对比没有使用标签数据的自监督学习,半监督学习更容易实现端到端优化,更合适应用于数据规模中等、算力有限的场景。自监督学习则往往需要大规模预训练(如BERT、MAE)。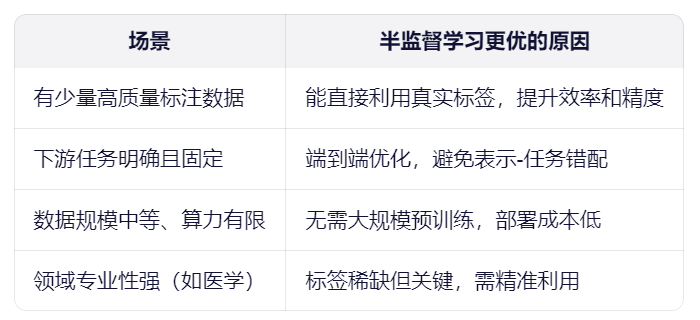
-
Q2:对于没有标签的数据,测试结果要如何评估?
A2:无法直接评估无标签数据的单个预测结果,但我们可以通过"借来的标准"和"侧面观察"来间接评估。这就好比老师(评估者)并没有看过学生的课外读物(未标签数据),但老师可以通过以下方式来判断学生自学的效果:
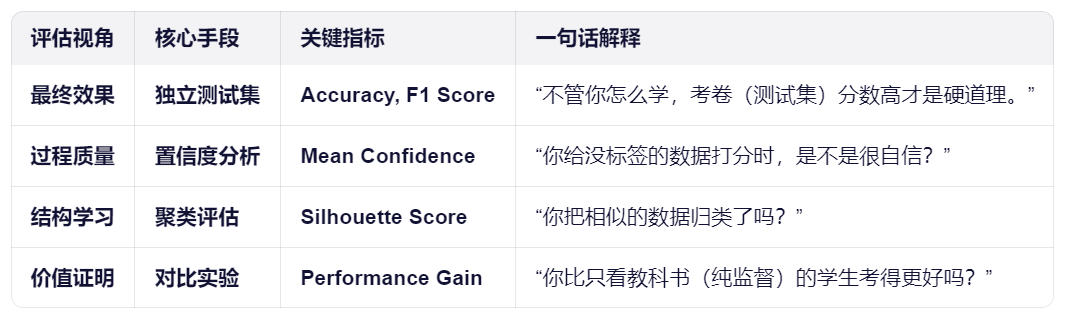 半监督学习的评估本身并不复杂------它仍依赖标准的、基于真实标签的测试指标。关键在于:严格隔离训练(含无标签)与测试,确保评估公正、可复现,并通过标签效率分析体现其"用更少标签达到更好性能"的核心价值。
半监督学习的评估本身并不复杂------它仍依赖标准的、基于真实标签的测试指标。关键在于:严格隔离训练(含无标签)与测试,确保评估公正、可复现,并通过标签效率分析体现其"用更少标签达到更好性能"的核心价值。
半监督学习的初步示例
示例一:鸢尾花数据集(仅有 10% 标签数据的情况)
python
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.semi_supervised import SelfTrainingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# --- 1. 准备数据 ---
# 加载鸢尾花数据集
data = load_iris()
X, y = data.data, data.target
# --- 2. 制造"半监督"场景 ---
# 假设我们只有 10% 的数据有标签,90% 的数据没有标签
# 这里用 -1 来表示"无标签"
rng = np.random.RandomState(42)
random_unlabeled_points = rng.rand(len(y)) < 0.9 # 90% 设为无标签
y_semisup = np.copy(y)
y_semisup[random_unlabeled_points] = -1 # 核心步骤:将大部分标签抹去
# --- 3. 模型定义 ---
# 基础分类器(这里用随机森林)
base_classifier = RandomForestClassifier(random_state=42)
# 包装成自训练分类器
# 这个包装器会自动给高置信度的无标签数据打上伪标签
self_training_model = SelfTrainingClassifier(
base_classifier,
threshold=0.9, # 置信度阈值,只有概率>90%才打伪标签
verbose=True # 显示打标签的过程
)
# --- 4. 训练模型 ---
# 注意:这里传入的 y_semisup 包含了大量的 -1 (无标签)
self_training_model.fit(X, y_semisup)
# --- 5. 预测与评估 ---
# 预测所有数据(实际上我们通常会划分测试集,这里为了简单演示)
predictions = self_training_model.predict(X)
accuracy = accuracy_score(y, predictions) # 这里用真实标签 y 来评估(实际中用测试集)
print(f"\n最终模型准确率: {accuracy:.2%}")
# --- 6. 对比:纯监督学习的效果 ---
# 假设纯监督学习只能用那 10% 的真实标签数据
# 找出有标签的数据点
labeled_indices = y_semisup != -1
# 仅用有标签的数据训练一个普通模型
pure_supervised_model = RandomForestClassifier(random_state=42)
pure_supervised_model.fit(X[labeled_indices], y[labeled_indices])
# 在全量数据上预测(仅用于对比)
pure_predictions = pure_supervised_model.predict(X)
pure_accuracy = accuracy_score(y, pure_predictions)
print(f"仅用10%标签数据(纯监督)的准确率: {pure_accuracy:.2%}")输出结果:
End of iteration 1, added 59 new labels.
End of iteration 2, added 19 new labels.
End of iteration 3, added 14 new labels.
End of iteration 4, added 15 new labels.
最终模型准确率: 96.00%
仅用10%标签数据(纯监督)的准确率: 89.33%
输出结果清晰地展示了自训练(Self-Training)在半监督学习中的有效性。
示例二: Fashion-MNIST 数据集
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import numpy as np
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.manual_seed(42)
np.random.seed(42)
# ----------------------------
# 1. 加载 train 和 test
# ----------------------------
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x.view(-1))
])
train_dataset = torchvision.datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)
X_train = torch.stack([d[0] for d in train_dataset]).numpy()
y_train = np.array([d[1] for d in train_dataset])
X_test = torch.stack([d[0] for d in test_dataset]).numpy()
y_test = np.array([d[1] for d in test_dataset])
# 标准化(仅用 train 统计量)
X_mean, X_std = X_train.mean(axis=0), X_train.std(axis=0)
X_std[X_std == 0] = 1
X_train_scaled = (X_train - X_mean) / X_std
X_test_scaled = (X_test - X_mean) / X_std
# ----------------------------
# 2. 构造极稀疏且有偏的训练标签
# ----------------------------
labeled_indices = []
for cls in range(10):
idxs = np.where(y_train == cls)[0]
# 故意选难例:Pullover/Coat/Shirt 选最模糊的
if cls in [2, 4, 6]:
imgs = X_train[idxs].reshape(-1, 28, 28)
variances = imgs.var(axis=(1, 2))
hardest = idxs[np.argmin(variances)]
labeled_indices.append(hardest)
else:
labeled_indices.append(idxs[0])
labeled_indices = np.array(labeled_indices)
y_train_semi = np.full(len(y_train), -1)
y_train_semi[labeled_indices] = y_train[labeled_indices]
# 👉 关键:故意翻转一个标签,制造系统性错误!
y_train_semi[labeled_indices[2]] = 6 # 把真实的 Pullover (2) 错标为 Shirt (6)
print("初始标签(含1个错误):", y_train_semi[labeled_indices])
# ----------------------------
# 3. 模型与训练函数
# ----------------------------
class LinearModel(nn.Module):
def __init__(self): super().__init__(); self.linear = nn.Linear(784, 10)
def forward(self, x): return self.linear(x)
def train_model(model, X, y, epochs=200, lr=1.0):
model.train()
opt = optim.SGD(model.parameters(), lr=lr)
crit = nn.CrossEntropyLoss()
X_t = torch.tensor(X, dtype=torch.float32).to(device)
y_t = torch.tensor(y, dtype=torch.long).to(device)
for _ in range(epochs):
opt.zero_grad()
loss = crit(model(X_t), y_t)
loss.backward()
opt.step()
def predict(model, X):
model.eval()
with torch.no_grad():
X_t = torch.tensor(X, dtype=torch.float32).to(device)
probs = torch.softmax(model(X_t), dim=1)
conf, pred = torch.max(probs, dim=1)
return pred.cpu().numpy(), conf.cpu().numpy()
# ----------------------------
# 4. 纯监督(仅10个含错标签)
# ----------------------------
model_sup = LinearModel().to(device)
train_model(model_sup, X_train_scaled[labeled_indices], y_train_semi[labeled_indices])
pred_sup = predict(model_sup, X_test_scaled)[0]
acc_sup = accuracy_score(y_test, pred_sup)
print(f"✅ 纯监督(10个含错标签)测试准确率: {acc_sup:.2%}")
# ----------------------------
# 5. 自训练(在 train 上,评估在 test 上)
# ----------------------------
current_idx = labeled_indices.copy()
current_y = y_train_semi[labeled_indices].copy()
threshold = 0.7
for it in range(5):
model = LinearModel().to(device)
train_model(model, X_train_scaled[current_idx], current_y)
pred_all, conf_all = predict(model, X_train_scaled)
unlabeled = np.ones(len(y_train), dtype=bool)
unlabeled[current_idx] = False
high_conf = (conf_all > threshold) & unlabeled
new_idx = np.where(high_conf)[0]
new_y = pred_all[new_idx]
print(f"Iter {it+1}: 新增 {len(new_idx)} 伪标签")
if len(new_idx) == 0: break
current_idx = np.concatenate([current_idx, new_idx])
current_y = np.concatenate([current_y, new_y])
# 在 TEST SET 上评估!
final_pred = predict(model, X_test_scaled)[0]
acc_self = accuracy_score(y_test, final_pred)
print(f"⚠️ 自训练测试准确率: {acc_self:.2%}")
# ----------------------------
# 6. 结果
# ----------------------------
if acc_self < acc_sup:
print("\n🚨 半监督失败!自训练比纯监督更差(在独立测试集上)")
else:
print("\n💡 未恶化")输出结果:
初始标签(含1个错误): 0 1 6 3 4 5 6 7 8 9
✅ 纯监督(10个含错标签)测试准确率: 31.68%
Iter 1: 新增 56925 伪标签
Iter 2: 新增 1590 伪标签
Iter 3: 新增 934 伪标签
Iter 4: 新增 264 伪标签
Iter 5: 新增 88 伪标签
⚠️ 自训练测试准确率: 31.23%
🚨 半监督失败!自训练比纯监督更差(在独立测试集上)
虽然差距看似不大,但在统计显著且评估公正的前提下,任何下降都说明方法引入了有害信息。当初始监督信号存在偏差或错误时,自训练会通过伪标签将错误系统性放大,导致泛化性能下降。Garbage in, gospel out.
示例三:GNN+半监督学习
在GNN研究爆发的早期,半监督学习是其最经典、最主流的应用范式。很多著名的论文和模型(如 GCN)最初的登场方式就是解决半监督问题。图数据天然具有"邻居相似"的假设(同质性) ,这为半监督学习提供了理论基础------可以用结构信息弥补标签的缺失。此外,GNN 的核心是"消息传递",它可以把珍贵的标签信息,扩散到整个图中。
示例代码如下:
python
import torch
import torch.nn.functional as F
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import GCNConv
# 1. 加载数据集(Cora)
dataset = Planetoid(root='/tmp/Cora', name='Cora')
data = dataset[0] # Cora 只有一个图
# 查看数据结构
print("节点数:", data.num_nodes)
print("边数:", data.edge_index.size(1))
print("特征维度:", data.num_node_features)
print("类别数:", dataset.num_classes)
print("训练集节点数:", data.train_mask.sum().item())
# 2. 定义两层 GCN 模型
class GCN(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super().__init__()
self.conv1 = GCNConv(in_channels, hidden_channels)
self.conv2 = GCNConv(hidden_channels, out_channels)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
# 3. 初始化模型、优化器
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN(dataset.num_node_features, 16, dataset.num_classes).to(device)
data = data.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
# 4. 训练函数
def train():
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss.item()
# 5. 测试函数
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
accs = []
for mask in [data.train_mask, data.val_mask, data.test_mask]:
correct = pred[mask] == data.y[mask]
acc = int(correct.sum()) / int(mask.sum())
accs.append(acc)
return accs # train_acc, val_acc, test_acc
# 6. 训练循环
for epoch in range(1, 201):
loss = train()
train_acc, val_acc, test_acc = test()
if epoch % 20 == 0:
print(f'Epoch {epoch:03d}, Loss: {loss:.4f}, '
f'Train Acc: {train_acc:.4f}, Val Acc: {val_acc:.4f}, Test Acc: {test_acc:.4f}')输出结果:
节点数: 2708
边数: 10556
特征维度: 1433
类别数: 7
训练集节点数: 140
Epoch 020, Loss: 0.2714, Train Acc: 0.9929, Val Acc: 0.7880, Test Acc: 0.7970
Epoch 040, Loss: 0.0673, Train Acc: 1.0000, Val Acc: 0.7820, Test Acc: 0.7890
Epoch 060, Loss: 0.0509, Train Acc: 1.0000, Val Acc: 0.7620, Test Acc: 0.7800
Epoch 080, Loss: 0.0326, Train Acc: 1.0000, Val Acc: 0.7740, Test Acc: 0.7890
Epoch 100, Loss: 0.0368, Train Acc: 1.0000, Val Acc: 0.7760, Test Acc: 0.7950
Epoch 120, Loss: 0.0606, Train Acc: 1.0000, Val Acc: 0.7640, Test Acc: 0.7940
Epoch 140, Loss: 0.0381, Train Acc: 1.0000, Val Acc: 0.7640, Test Acc: 0.7960
Epoch 160, Loss: 0.0292, Train Acc: 1.0000, Val Acc: 0.7720, Test Acc: 0.8100
Epoch 180, Loss: 0.0359, Train Acc: 1.0000, Val Acc: 0.7720, Test Acc: 0.8070
Epoch 200, Loss: 0.0225, Train Acc: 1.0000, Val Acc: 0.7760, Test Acc: 0.8160
这是很经典的示例了,随便找本教科书都有的。GCN的各种变体也是层出不穷。
关于深度学习上的自监督学习,这个方向发展也比较成熟了,现在有一些的综述论文可以参考:
- 《A Survey on Deep Semi-supervised Learning》,不新,但是看着概述得比较全。
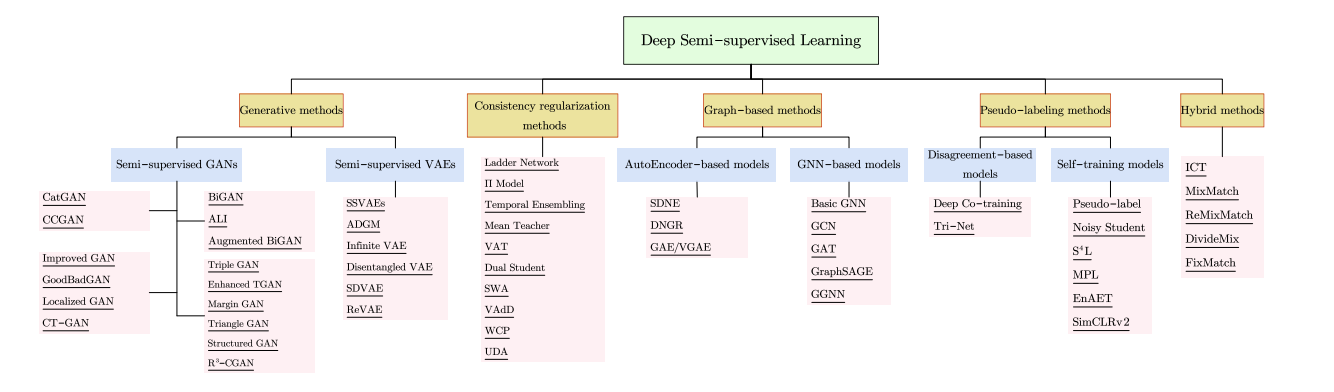
- 《Graph-based Semi-supervised Learning: A Comprehensive Review》,GNN+半监督学习的综述。
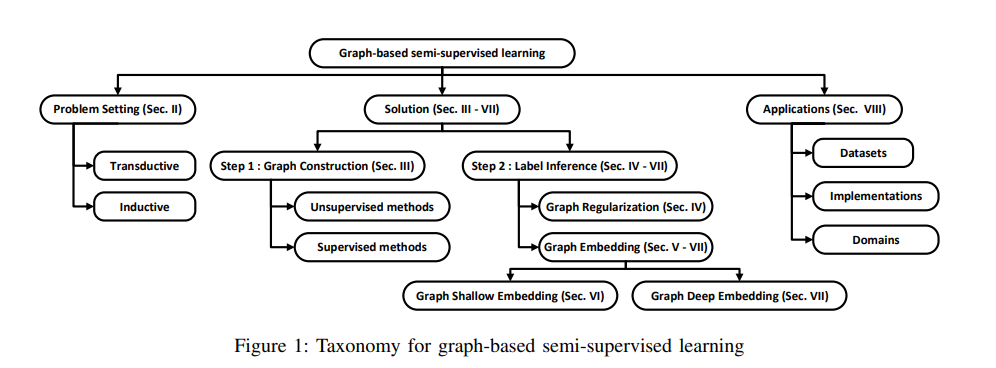
不同领域+半监督学习也有不少综述了。从这个角度上看,这个方向做得人挺多的,尤其是GNN+半监督学习。
半监督学习的失败案例
半监督学习并非总是"灵丹妙药"。实际上,如果使用不当,它不仅不会提升模型性能,反而会严重拖累模型,导致"越学越退步"的尴尬局面。
-
类别分布不匹配(Class Distribution Mismatch)
案例背景:(1)标注数据只包含常见类别(如"猫""狗"),而无标注数据中混入大量未知类别(如"狐狸""浣熊")。
(2)模型误将这些新类别当作已知类别的变体,强行打上伪标签。
失败表现:(1)伪标签污染训练集,导致模型混淆。
(2)性能下降可达 10--30%,甚至不如仅用少量标注数据训练的基线。
典型场景 :(1)医疗影像:训练集只有肺癌和正常肺,但真实数据中混入结核、纤维化等未见病灶。
(2)自动驾驶:训练城市为北京,部署到乡村道路出现大量未见过的障碍物(如拖拉机、牲畜)。
-
领域偏移(Domain Shift)
案例背景 :(1)标注数据来自一个分布(如晴天白天的街景),无标注数据来自另一个分布(如雨夜或雪地)。
(2)半监督方法假设所有数据来自同一分布,但现实常违反此前提。
失败表现 :(1)模型在无标注数据上预测置信度高但错误率高。
(2)一致性正则化(如Mean Teacher、UDA)反而强化了错误模式。
实际案例 :Google 的糖尿病视网膜病变 AI 在美国/印度数据上训练,部署到泰国后性能骤降。
-
伪标签噪声累积(Error Propagation in Pseudo-Labeling)
案例背景 :(1)初期模型弱(因标注数据太少),对无标注数据预测不准。
(2)高置信度样本中仍包含大量错误标签("自信的错误")。
失败表现:(1)错误标签被反复加入训练集,形成"滚雪球效应"。
(2)模型收敛到局部最优,且难以恢复。
-
数据不满足聚类/流形假设
案例背景 :(1)半监督依赖"同类样本聚集"或"流形结构"。
(2)但在高噪声、高重叠或均匀分布的数据中,这些假设不成立。
失败表现 :(1)Label Propagation 将标签错误扩散到异类样本。
(2)图方法(如GNN-based SSL)在稀疏图或弱连接图上失效。
示例 :(1)金融反欺诈:欺诈与正常交易在特征空间高度重叠,无明显聚类结构。
(2)文本情感分析:中性语句夹杂在正负情感之间,边界模糊。
⚠️一句话忠告:半监督不是魔法,它放大信号的同时也会放大噪声。用之前,请先确认你的数据'值得被半监督'。
半监督学习优缺点
- SSL的优势:
- 降低成本:大幅减少了对昂贵人工标注数据的依赖。
- 提升性能:在标签数据稀缺的情况下,往往比纯监督学习效果更好。
- SSL的挑战:
- 敏感性:如果初始的少量标签数据质量不高,或者模型产生了错误的"伪标签",可能会导致模型"越学越错"。
- 复杂性:相比纯监督学习,理解和调试半监督模型的难度更大。
四类方法的对比:
| 方法 | 主要优点 | 主要缺点 |
|---|---|---|
| 监督学习 | 性能高、目标明确、方法成熟 | 依赖大量标注、成本高、泛化受限 |
| 无监督学习 | 无需标签、可挖掘隐藏结构 | 无明确目标、难评估、难用于预测 |
| 半监督学习 | 节省标注成本、利用无标签数据 | 依赖数据假设、伪标签噪声风险 |
| 自监督学习 | 无标签预训练、通用表示强、适合大模型 | 计算成本高、任务设计敏感、微调仍需标签 |
LLM时代下的半监督学习
SSL火起来是在GNN发展鼎盛的时期。在LLM时代下,半监督学习还能发挥什么作用?经过初步调研,我发现半监督学习依然非常重要,并与 LLM 形成互补:
- LLM 可以自动生成高质量的伪标签,用于训练分类、NER 等任务,大幅减少人工标注成本。
- 新方法如 R.E.D. 算法 利用 LLM 递归优化多类别少样本问题,在电商、客服等场景效果显著。
- 半监督学习结合 LLM 能提升模型安全性,例如识别恶意输入,仅需少量标注数据。
- 在新领域冷启动(如新业务、新市场)中,用少量标签 + 大量无标签数据 + LLM 语义能力,可快速构建有效模型。
- 通过先用 LLM 打标、再训练轻量模型的方式,能显著降低推理成本和延迟,适合实际部署。
以下表格列出部分2023-2025年研究,展示SSL在LLM时代的应用(基于arXiv和会议论文)。
| 工作标题 | 核心方法 | 作用与益处 | 来源 |
|---|---|---|---|
| LLM-Informed Semi-Supervised Learning for Text Classification | LLM生成预测指导SSL伪标签,一致性学习融合 | 在6个基准上优于纯SSL和few-shot LLM,提升低标签场景性能 | openreview.net openreview.net |
| Semi-Supervised Learning for LLM Safety and Content Moderation | FixMatch/MultiMatch + LLM增强 | 用200标注样本提升F1 4-8%,降低安全标注成本 | arxiv.org arxiv.org |
| Rethinking Semi-Supervised Learning with Language Models | TAPT vs ST比较 | TAPT更鲁棒,适用于领域转移,SSL改进大于纯监督 | arxiv.org arxiv.org |
| SSL with Pseudo-Labeling for Regulatory Sequence Prediction | 跨物种伪标签 + Noisy Student变体 | 小模型匹敌大LLM,AUPR提升至7倍,数据高效 | pmc.ncbi.nlm.nih.gov pmc.ncbi.nlm.nih.gov |
| Revisiting SSL in the Era of Foundation Models | 基础模型下SSL评估 | SSL仍有效,尤其在少数据时补充LLM | openreview.net reddit.com |
总之,SSL在LLM时代不仅未过时,反而通过与LLM的协同(如生成辅助或预训练扩展),在资源受限、隐私敏感或新兴应用中大放异彩。它帮助桥接"数据鸿沟",推动AI向更可持续的方向发展。
上述内容仅供参考,欢迎关注、交流~
个人邮箱:mingzhang23@mails.jlu.edu.cn