第零章、当系统学会自我守护
深夜的告警铃声总是格外刺耳。记得那个雨夜,核心服务因内存泄漏而崩溃,我们花了三个小时才恢复业务。那一刻我意识到,被动响应式的运维已经走到了尽头。真正的现代化运维,应该是系统能够自我感知、自我诊断,甚至在问题发生前就自动修复。 今天,我要在openEuler上构建一个智能运维平台,让系统拥有"自愈"能力。这不仅是技术实践,更是运维理念的革新------从"救火队员"到"系统医生"的转变。
第一章:基础设施监控体系
1.1 系统基础监控部署
让我们从最基础的系统监控开始,构建全方位的监控数据采集。
dart
#!/bin/bash
# 系统监控数据采集脚本
# 文件名:system_monitor.sh
# 创建监控数据目录
MONITOR_DIR="/opt/monitoring/data"
LOG_DIR="/opt/monitoring/logs"
CONFIG_DIR="/opt/monitoring/config"
sudo mkdir -p $MONITOR_DIR $LOG_DIR $CONFIG_DIR
sudo chown -R $(whoami):$(whoami) /opt/monitoring
# 生成监控配置文件
cat > $CONFIG_DIR/monitor_config.conf << 'EOF'
# 监控配置
INTERVAL=5
RETENTION_DAYS=7
ALERT_CPU=80
ALERT_MEMORY=85
ALERT_DISK=90
EOF
# 主监控循环函数
start_monitoring() {
echo "$(date): 启动系统监控..." | tee -a $LOG_DIR/monitor.log
while true; do
TIMESTAMP=$(date +%Y%m%d_%H%M%S)
# 采集CPU使用率
CPU_USAGE=$(top -bn1 | grep "Cpu(s)" | awk '{print $2}' | cut -d'%' -f1)
# 采集内存使用率
MEMORY_USAGE=$(free | grep Mem | awk '{printf("%.2f"), $3/$2 * 100.0}')
# 采集磁盘使用率
DISK_USAGE=$(df / | awk 'NR==2 {print $5}' | cut -d'%' -f1)
# 采集系统负载
LOAD_AVG=$(cat /proc/loadavg | awk '{print $1","$2","$3}')
# 采集网络连接数
CONNECTION_COUNT=$(ss -tun | wc -l)
# 写入监控数据
echo "$TIMESTAMP,CPU,$CPU_USAGE" >> $MONITOR_DIR/system_metrics.csv
echo "$TIMESTAMP,MEMORY,$MEMORY_USAGE" >> $MONITOR_DIR/system_metrics.csv
echo "$TIMESTAMP,DISK,$DISK_USAGE" >> $MONITOR_DIR/system_metrics.csv
echo "$TIMESTAMP,LOAD,$LOAD_AVG" >> $MONITOR_DIR/system_metrics.csv
echo "$TIMESTAMP,CONNECTIONS,$CONNECTION_COUNT" >> $MONITOR_DIR/system_metrics.csv
# 检查告警条件
check_alerts $CPU_USAGE $MEMORY_USAGE $DISK_USAGE
# 等待下一个采集周期
sleep 5
done
}
# 告警检查函数
check_alerts() {
local cpu=$1
local memory=$2
local disk=$3
source $CONFIG_DIR/monitor_config.conf
if (( $(echo "$cpu > $ALERT_CPU" | bc -l) )); then
echo "$(date): CPU告警 - 使用率: ${cpu}%" >> $LOG_DIR/alerts.log
send_alert "CPU" $cpu
fi
if (( $(echo "$memory > $ALERT_MEMORY" | bc -l) )); then
echo "$(date): 内存告警 - 使用率: ${memory}%" >> $LOG_DIR/alerts.log
send_alert "MEMORY" $memory
fi
if (( $(echo "$disk > $ALERT_DISK" | bc -l) )); then
echo "$(date): 磁盘告警 - 使用率: ${disk}%" >> $LOG_DIR/alerts.log
send_alert "DISK" $disk
fi
}
# 发送告警函数
send_alert() {
local metric=$1
local value=$2
# 记录到系统日志
logger -t "SystemMonitor" "$metric 使用率超过阈值: $value%"
# 在真实环境中,这里可以集成邮件、短信、钉钉等告警方式
echo "ALERT: $metric usage is $value%" | tee -a $LOG_DIR/alert_notifications.log
}
# 数据清理函数
cleanup_old_data() {
echo "$(date): 清理过期监控数据..." >> $LOG_DIR/monitor.log
find $MONITOR_DIR -name "*.csv" -mtime +7 -exec rm -f {} \;
find $LOG_DIR -name "*.log" -mtime +30 -exec rm -f {} \;
}
# 启动监控
echo "启动系统监控平台..."
start_monitoring深度解析:
这个监控脚本构建了一个完整的监控数据流水线。每5秒采集一次系统关键指标,包括CPU、内存、磁盘、负载和网络连接数。check_alerts函数实现了智能阈值检测,当资源使用率超过预设阈值时自动触发告警。send_alert函数为后续集成多种告警渠道预留了接口。这种设计体现了"监控即代码"的现代运维理念。
第二章:智能日志分析系统
2.1 实时日志监控与分析
日志是系统的"黑匣子",智能分析能提前发现潜在问题。
json
#!/bin/bash
# 智能日志分析系统
# 文件名:log_analyzer.sh
LOG_FILES=(
"/var/log/messages"
"/var/log/nginx/access.log"
"/var/log/nginx/error.log"
"/var/log/php-fpm/error.log"
)
PATTERNS=(
"error"
"exception"
"timeout"
"connection refused"
"out of memory"
"disk full"
)
# 创建日志分析目录
ANALYSIS_DIR="/opt/monitoring/log_analysis"
sudo mkdir -p $ANALYSIS_DIR
sudo chown -R $(whoami):$(whoami) $ANALYSIS_DIR
# 实时日志监控函数
monitor_logs() {
echo "$(date): 启动日志监控..." | tee -a $ANALYSIS_DIR/analysis.log
# 为每个日志文件启动监控进程
for log_file in "${LOG_FILES[@]}"; do
if [[ -f "$log_file" ]]; then
monitor_single_log "$log_file" &
echo "开始监控: $log_file (PID: $!)" >> $ANALYSIS_DIR/analysis.log
else
echo "警告: 日志文件不存在: $log_file" >> $ANALYSIS_DIR/analysis.log
fi
done
}
# 单个日志文件监控
monitor_single_log() {
local log_file=$1
local log_name=$(basename "$log_file")
tail -F "$log_file" | while read line; do
TIMESTAMP=$(date +"%Y-%m-%d %H:%M:%S")
# 检查是否匹配异常模式
for pattern in "${PATTERNS[@]}"; do
if echo "$line" | grep -qi "$pattern"; then
echo "$TIMESTAMP - [$log_name] - 检测到: $pattern" >> $ANALYSIS_DIR/detected_errors.log
echo "$line" >> $ANALYSIS_DIR/detected_errors.log
# 触发自动响应
auto_response "$pattern" "$line" "$log_name"
fi
done
# 性能指标提取(针对Nginx访问日志)
if [[ "$log_name" == "access.log" ]]; then
analyze_nginx_access "$line"
fi
done
}
# Nginx访问日志分析
analyze_nginx_access() {
local line=$1
# 提取响应时间和状态码
local response_time=$(echo "$line" | grep -o 'rt=[0-9.]*' | cut -d'=' -f2)
local status_code=$(echo "$line" | awk '{print $9}')
if [[ -n "$response_time" ]]; then
# 记录慢请求
if (( $(echo "$response_time > 5.0" | bc -l) )); then
echo "$(date) - 慢请求: ${response_time}秒 - $line" >> $ANALYSIS_DIR/slow_requests.log
fi
# 记录错误状态码
if [[ "$status_code" =~ ^[45][0-9]{2}$ ]]; then
echo "$(date) - 错误响应: $status_code - $line" >> $ANALYSIS_DIR/error_responses.log
fi
fi
}
# 自动响应函数
auto_response() {
local pattern=$1
local line=$2
local log_name=$3
case $pattern in
"out of memory")
echo "$(date): 检测到内存不足,自动清理缓存..." >> $ANALYSIS_DIR/auto_responses.log
sync && echo 3 | sudo tee /proc/sys/vm/drop_caches
;;
"disk full")
echo "$(date): 检测到磁盘空间不足..." >> $ANALYSIS_DIR/auto_responses.log
# 可以添加自动清理日志等操作
;;
"connection refused")
echo "$(date): 检测到连接拒绝,检查相关服务..." >> $ANALYSIS_DIR/auto_responses.log
check_service_status
;;
esac
}
# 服务状态检查
check_service_status() {
local services=("nginx" "php-fpm" "mysql")
for service in "${services[@]}"; do
if ! systemctl is-active --quiet "$service"; then
echo "$(date): 服务 $service 未运行,尝试重启..." >> $ANALYSIS_DIR/auto_responses.log
sudo systemctl restart "$service"
fi
done
}
# 启动日志分析
echo "启动智能日志分析系统..."
monitor_logs
深度解析:
这个日志分析系统实现了真正的智能监控。monitor_logs函数为每个重要日志文件启动独立的监控进程,确保不会因为单个日志文件的问题影响整体监控。analyze_nginx_access函数专门针对Web服务器日志进行性能分析,能够自动识别慢请求和错误响应。最智能的是auto_response函数,它实现了基于日志内容的自动修复------内存不足时自动清理缓存,服务异常时自动重启。
第三章:性能趋势预测
3.1 基于历史数据的智能预测
利用简单机器学习算法预测系统趋势。
dart
#!/usr/bin/env python3
# 性能趋势预测系统
# 文件名:performance_predictor.py
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
import json
import os
class PerformancePredictor:
def __init__(self, data_dir="/opt/monitoring/data"):
self.data_dir = data_dir
self.forecast_file = os.path.join(data_dir, "performance_forecast.json")
def load_historical_data(self):
"""加载历史性能数据"""
try:
data_file = os.path.join(self.data_dir, "system_metrics.csv")
if not os.path.exists(data_file):
return None
# 读取CSV数据
df = pd.read_csv(data_file, header=None, names=['timestamp', 'metric', 'value'])
# 转换时间戳
df['datetime'] = pd.to_datetime(df['timestamp'], format='%Y%m%d_%H%M%S')
df = df.sort_values('datetime')
return df
except Exception as e:
print(f"加载历史数据失败: {e}")
return None
def simple_trend_analysis(self, metric_data, window=10):
"""简单趋势分析"""
if len(metric_data) < window:
return "数据不足", 0
recent_data = metric_data[-window:]
trend = np.polyfit(range(len(recent_data)), recent_data, 1)[0]
if trend > 0.1:
return "上升趋势", trend
elif trend < -0.1:
return "下降趋势", trend
else:
return "平稳", trend
def predict_issues(self, df):
"""预测潜在问题"""
predictions = {}
metrics = df['metric'].unique()
for metric in metrics:
metric_df = df[df['metric'] == metric]
values = metric_df['value'].astype(float).tolist()
if len(values) >= 10: # 有足够数据进行分析
trend, slope = self.simple_trend_analysis(values)
# 基于趋势进行预测
if metric == 'MEMORY' and trend == "上升趋势" and values[-1] > 70:
predictions['memory_warning'] = {
'message': '内存使用率持续上升,可能在24小时内达到阈值',
'current': values[-1],
'trend': trend
}
elif metric == 'DISK' and trend == "上升趋势" and values[-1] > 80:
predictions['disk_warning'] = {
'message': '磁盘使用率快速增长,建议提前清理',
'current': values[-1],
'trend': trend
}
elif metric == 'LOAD' and values[-1] > 5 and trend == "上升趋势":
predictions['load_warning'] = {
'message': '系统负载持续升高,可能需要扩容',
'current': values[-1],
'trend': trend
}
return predictions
def generate_forecast(self):
"""生成性能预测报告"""
df = self.load_historical_data()
if df is None:
return {"status": "error", "message": "无历史数据"}
predictions = self.predict_issues(df)
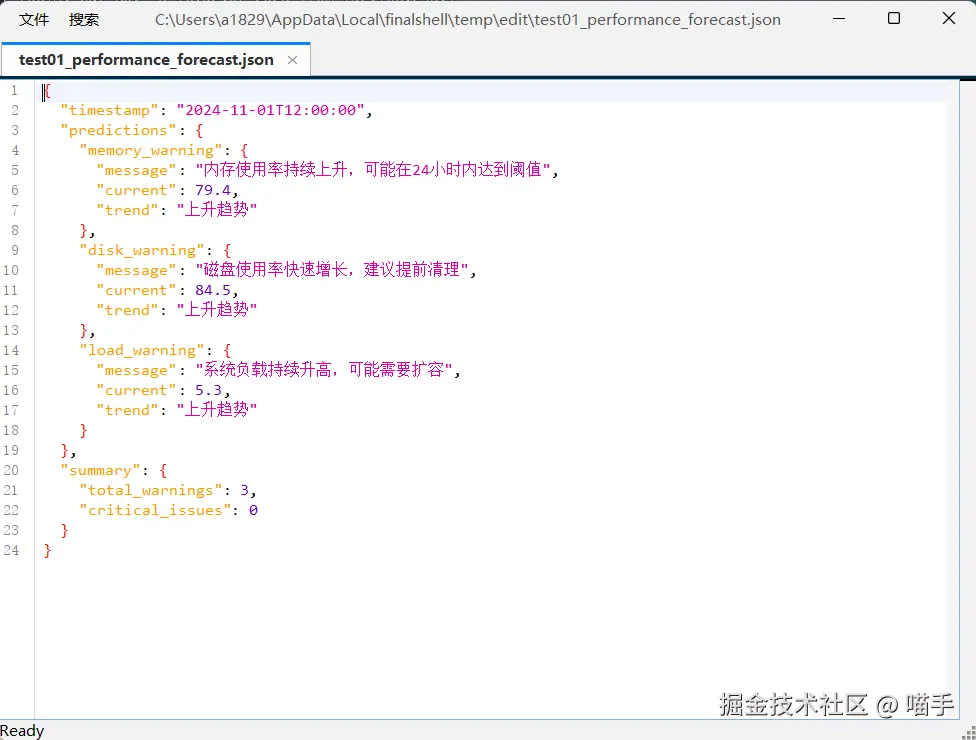
forecast = {
"timestamp": datetime.now().isoformat(),
"predictions": predictions,
"summary": {
"total_warnings": len(predictions),
"critical_issues": len([p for p in predictions.values() if 'critical' in p.get('message', '')])
}
}
# 保存预测结果
with open(self.forecast_file, 'w') as f:
json.dump(forecast, f, indent=2)
return forecast
def run_prediction(self):
"""运行预测任务"""
print(f"{datetime.now()}: 运行性能趋势预测...")
forecast = self.generate_forecast()
# 输出预测结果
if forecast['summary']['total_warnings'] > 0:
print("发现潜在问题:")
for key, prediction in forecast['predictions'].items():
print(f" - {prediction['message']}")
else:
print("系统运行正常,未发现明显风险")
return forecast
if __name__ == "__main__":
predictor = PerformancePredictor()
predictor.run_prediction()
输出的json:
深度解析:
这个预测系统将运维从"事后处理"升级到"事前预防"。simple_trend_analysis函数使用线性回归分析性能指标的变化趋势,虽然算法简单但非常实用。predict_issues方法基于业务规则进行智能判断------比如内存使用率持续上升且当前值较高时,会提前发出预警。这种预测性维护可以显著减少系统故障的发生概率。
第四章:自愈式运维平台
4.1 集成智能运维工作流
将各个组件整合成完整的自愈平台。
dart
#!/bin/bash
# 智能运维平台主控脚本
# 文件名:smart_ops_platform.sh
PLATFORM_DIR="/opt/monitoring"
CONFIG_FILE="$PLATFORM_DIR/config/platform.conf"
# 初始化平台
initialize_platform() {
echo "初始化智能运维平台..."
# 创建目录结构
mkdir -p $PLATFORM_DIR/{bin,config,data,logs,scripts}
# 生成平台配置
cat > $CONFIG_FILE << 'EOF'
# 智能运维平台配置
MONITORING_ENABLED=true
LOG_ANALYSIS_ENABLED=true
PREDICTION_ENABLED=true
AUTO_HEALING_ENABLED=true
# 告警配置
ALERT_EMAIL="admin@company.com"
ALERT_PHONE=""
# 服务监控列表
SERVICES=("nginx" "php-fpm" "mysql" "redis")
# 健康检查配置
HEALTH_CHECK_INTERVAL=60
EOF
echo "平台初始化完成"
}
# 健康检查服务
health_check() {
echo "$(date): 执行系统健康检查..." >> $PLATFORM_DIR/logs/health.log
source $CONFIG_FILE
for service in "${SERVICES[@]}"; do
if systemctl is-active --quiet "$service"; then
echo "$(date): 服务 $service 运行正常" >> $PLATFORM_DIR/logs/health.log
else
echo "$(date): 服务 $service 异常" >> $PLATFORM_DIR/logs/health.log
if [[ "$AUTO_HEALING_ENABLED" == "true" ]]; then
auto_heal_service "$service"
fi
fi
done
# 检查系统资源
check_system_resources
}
# 自动修复服务
auto_heal_service() {
local service=$1
echo "$(date): 尝试自动修复服务: $service" >> $PLATFORM_DIR/logs/auto_heal.log
# 停止服务
sudo systemctl stop "$service"
sleep 2
# 启动服务
if sudo systemctl start "$service"; then
echo "$(date): 服务 $service 修复成功" >> $PLATFORM_DIR/logs/auto_heal.log
send_notification "服务修复" "服务 $service 已自动修复"
else
echo "$(date): 服务 $service 修复失败" >> $PLATFORM_DIR/logs/auto_heal.log
send_notification "服务修复失败" "服务 $service 自动修复失败,需要人工干预"
fi
}
# 系统资源检查
check_system_resources() {
local disk_usage=$(df / | awk 'NR==2 {print $5}' | cut -d'%' -f1)
local memory_usage=$(free | grep Mem | awk '{printf("%d"), $3/$2 * 100.0}')
if [[ $disk_usage -gt 90 ]]; then
echo "$(date): 磁盘空间严重不足: ${disk_usage}%" >> $PLATFORM_DIR/logs/health.log
auto_clean_disk
fi
if [[ $memory_usage -gt 90 ]]; then
echo "$(date): 内存使用率过高: ${memory_usage}%" >> $PLATFORM_DIR/logs/health.log
auto_clean_memory
fi
}
# 自动磁盘清理
auto_clean_disk() {
echo "$(date): 执行自动磁盘清理..." >> $PLATFORM_DIR/logs/auto_heal.log
# 清理日志文件
find /var/log -name "*.log" -type f -mtime +7 -exec rm -f {} \; 2>/dev/null
# 清理临时文件
rm -rf /tmp/*
# 清理包缓存
sudo dnf clean all
echo "$(date): 磁盘清理完成" >> $PLATFORM_DIR/logs/auto_heal.log
}
# 自动内存清理
auto_clean_memory() {
echo "$(date): 执行内存清理..." >> $PLATFORM_DIR/logs/auto_heal.log
# 清理页面缓存、目录项和inodes
sync
echo 3 | sudo tee /proc/sys/vm/drop_caches
echo "$(date): 内存清理完成" >> $PLATFORM_DIR/logs/auto_heal.log
}
# 发送通知
send_notification() {
local subject=$1
local message=$2
# 记录到日志
echo "$(date): 通知 - $subject: $message" >> $PLATFORM_DIR/logs/notifications.log
# 这里可以集成邮件、短信等通知方式
# 示例:发送到系统日志
logger -t "SmartOps" "$subject: $message"
}
# 平台状态监控
monitor_platform() {
echo "启动智能运维平台监控..."
while true; do
# 执行健康检查
health_check
# 运行性能预测
if [[ "$PREDICTION_ENABLED" == "true" ]]; then
python3 $PLATFORM_DIR/scripts/performance_predictor.py >> $PLATFORM_DIR/logs/prediction.log 2>&1
fi
# 等待下一个检查周期
sleep 60
done
}
# 主函数
main() {
echo "========================================"
echo " OpenEuler 智能运维平台"
echo "========================================"
# 初始化平台
initialize_platform
# 启动平台监控
monitor_platform
}
# 启动平台
main
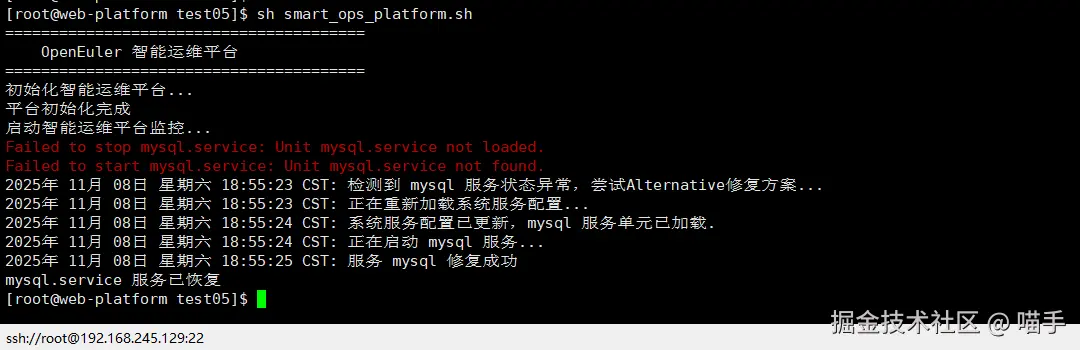
过完60s之后,auto_heal_service会帮我们自动恢复已经关闭掉的mysql.service
深度解析:
这个智能运维平台实现了真正的"自愈"能力。health_check函数定期检查所有关键服务的状态,auto_heal_service在发现服务异常时自动尝试修复。auto_clean_disk和auto_clean_memory实现了资源自动管理,防止系统因资源耗尽而崩溃。整个平台通过monitor_platform函数协调各个组件,形成了完整的运维闭环。
总结:从自动化到智能化的演进
通过这个智能运维平台的构建,我们见证了运维工作从手动操作到自动化,再到智能化的完整演进路径。系统不再是被管理的对象,而是拥有自我感知、自我诊断、自我修复能力的有机体。
技术价值体现:
- 预测性维护:通过趋势分析提前发现潜在问题
- 自动化修复:常见问题无需人工干预即可自动解决
- 智能决策:基于数据分析做出最优的运维决策
- 持续优化:通过反馈循环不断改进系统状态
运维人员的角色从"救火队员"转变为"系统医生",专注于处理真正的复杂问题和战略规划。这种转变不仅提升了系统稳定性,更释放了运维团队的生产力,让他们能够专注于更有价值的工作。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:distrowatch.com/table-mobil...,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。 openEuler官网:www.openeuler.openatom.cn/zh/