深入解析MySQL事务与锁:构建高并发数据系统的基石
引言:为什么事务和锁如此重要?
在现代高并发系统中,数据库的事务和锁机制是确保数据一致性、可靠性和并发性能的核心。无论是电商秒杀、金融交易还是社交应用,都离不开对这些机制的深入理解和正确使用。本文将从基础概念到实战应用,全面解析MySQL的事务隔离级别、MVCC实现原理和锁机制。
一、事务的ACID特性:数据库可靠性的基石
MySQL通过多种技术手段实现事务的ACID特性:
| 特性 | 中文 | 实现机制 | 作用 |
|---|---|---|---|
| Atomicity | 原子性 | Undo Log(回滚日志) | 保证事务要么全部完成,要么全部回滚 |
| Consistency | 一致性 | 原子性、隔离性、持久性共同保证 | 确保数据库从一个一致性状态转换到另一个一致性状态 |
| Isolation | 隔离性 | MVCC + 锁机制 | 控制并发事务间的相互影响 |
| Durability | 持久性 | Redo Log(重做日志) | 已提交的事务修改永久保存 |
关键点:
- Undo Log用于事务回滚和数据的多版本管理
- Redo Log通过WAL(Write-Ahead Logging)机制保证数据持久性
- MVCC(多版本并发控制)实现了读写不阻塞的高并发访问
二、并发事务的三大问题
理解并发问题是选择正确隔离级别的前提:
1. 脏读(Dirty Read)
场景:事务A修改了数据但未提交,事务B读取到了这个未提交的数据,随后事务A回滚。
问题:事务B读取到了"不存在"的数据。
2. 不可重复读(Non-repeatable Read)
场景:事务A两次读取同一数据,在两次读取之间,事务B修改了该数据并提交。
问题:同一事务内多次读取同一数据结果不一致。
3. 幻读(Phantom Read)
场景:事务A两次执行相同的范围查询,在两次查询之间,事务B插入或删除了符合查询条件的数据。
问题:同一事务内多次范围查询的结果集不一致。
三、事务隔离级别详解
MySQL提供了四种标准隔离级别,隔离强度递增,但并发性能递减:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 实现机制 | 适用场景 |
|---|---|---|---|---|---|
| 读未提交 (RU) | ❌ 可能发生 | ❌ 可能发生 | ❌ 可能发生 | 无MVCC,直接读取最新数据 | 对数据一致性要求极低,需要最高并发 |
| 读已提交 (RC) | ✅ 避免 | ❌ 可能发生 | ❌ 可能发生 | 每次SELECT创建新Read View | OLTP系统主流选择,平衡性能与一致性 |
| 可重复读 (RR) | ✅ 避免 | ✅ 避免 | ⚠️ 大部分避免* | 事务开始时创建Read View | MySQL默认级别,适合大多数场景 |
| 串行化 (SERIALIZABLE) | ✅ 避免 | ✅ 避免 | ✅ 避免 | 所有读操作加共享锁 | 对数据一致性要求极高的金融交易 |
*注:RR级别在特定条件下(当前读)仍可能出现幻读,需要通过Next-Key Lock完全避免。
四、MVCC:实现高并发的核心技术
MVCC与锁的职责划分
| 机制 | 主要职责 | 解决的问题 | 特点 |
|---|---|---|---|
| MVCC | 处理读并发 | 实现读不阻塞写,写不阻塞读 | 通过多版本实现非阻塞的快照读 |
| 锁 | 处理写并发 | 保证写操作有序进行 | 防止多个事务同时修改同一数据 |
MVCC实现原理
MVCC通过以下组件协同工作:
1. 隐藏字段
每行记录包含两个隐藏字段:
trx_id:最近修改该记录的事务IDroll_pointer:指向该记录上一个版本的Undo Log指针
2. Read View(读视图)
Read View决定了事务能看到哪些版本的数据,包含四个关键字段:
kotlin
class ReadView {
List<Long> m_ids; // 创建时活跃的事务ID列表
Long min_trx_id; // 活跃事务中的最小ID
Long max_trx_id; // 下一个将要分配的事务ID
Long creator_trx_id; // 创建该Read View的事务ID
}3. 可见性判断规则
判断记录版本对当前事务是否可见:
-
如果
trx_id < min_trx_id:该版本在Read View创建前已提交,可见 -
如果
trx_id >= max_trx_id:该版本在Read View创建后才开始,不可见 -
如果
min_trx_id ≤ trx_id < max_trx_id:- 如果
trx_id在m_ids中:事务仍在活跃,不可见 - 否则:事务已提交,可见
- 如果
各隔离级别的实现差异
- RU:直接读取最新数据,不创建Read View
- RC:每次SELECT创建新的Read View
- RR:事务开始时创建Read View,整个事务复用
- SERIALIZABLE:读操作也加共享锁,不使用MVCC
五、RC与RR的锁行为对比
示例分析
sql
-- 表结构:users(id INT PRIMARY KEY, status INT)
-- 现有数据:id=1,3,5
-- 事务A执行
UPDATE users SET status = 1 WHERE id > 2;RC级别的锁行为:
- 对
id=3和id=5加记录锁 - 不会对间隙加锁
- 其他事务可以插入
id=2、id=4等数据
RR级别的锁行为:
- 对
id=3和id=5加记录锁 - 对间隙
(1,3)、(3,5)、(5, +∞)加间隙锁 - 防止其他事务插入
id>2的新数据
RC vs RR 选择建议
| 考量维度 | 读已提交 (RC) | 可重复读 (RR) |
|---|---|---|
| 并发性能 | 更高(锁冲突少) | 较低(锁范围大) |
| 幻读风险 | 存在 | 基本避免 |
| 死锁概率 | 较低 | 较高 |
| binlog格式 | 必须为ROW | 支持STATEMENT |
| 适用场景 | 高并发OLTP,可接受幻读 | 需要强一致性,如报表、统计 |
很多互联网公司选择RC级别,通过应用层逻辑处理幻读,换取更高的并发性能。
六、锁机制深度解析
1. 全局锁
sql
-- 全库只读,用于备份
FLUSH TABLES WITH READ LOCK;
-- 备份完成后释放
UNLOCK TABLES;2. 表级锁
- 表锁 :
LOCK TABLES table_name READ/WRITE - 元数据锁(MDL) :自动管理,CRUD加读锁,DDL加写锁
- 意向锁:行锁的表级标记,提高锁冲突检测效率
3. 行级锁(InnoDB核心)

| 锁类型 | 描述 | 兼容性 | 使用场景 |
|---|---|---|---|
| 记录锁 | 锁定单行记录 | 共享锁之间兼容,排他锁互斥 | 精确匹配的等值查询 |
| 间隙锁 | 锁定索引记录间的间隙 | 间隙锁之间兼容 | RR级别防止幻读 |
| 临键锁 | 记录锁+间隙锁 | 与插入意向锁冲突 | RR级别的范围查询 |
| 插入意向锁 | 插入操作前的间隙锁 | 特殊的间隙锁 | INSERT操作时添加 |
七、实战场景与死锁处理
常见锁场景分析
场景1:索引对锁的影响
sql
-- id无索引的情况
UPDATE users SET status = 1 WHERE age > 20;
-- 会锁全表(RR级别下为临键锁)
-- id有索引的情况
UPDATE users SET status = 1 WHERE id = 8;
-- 只锁定id=8的记录核心原理:无索引的WHERE条件会导致全表扫描,进而锁定所有记录。
场景2:死锁产生与避免
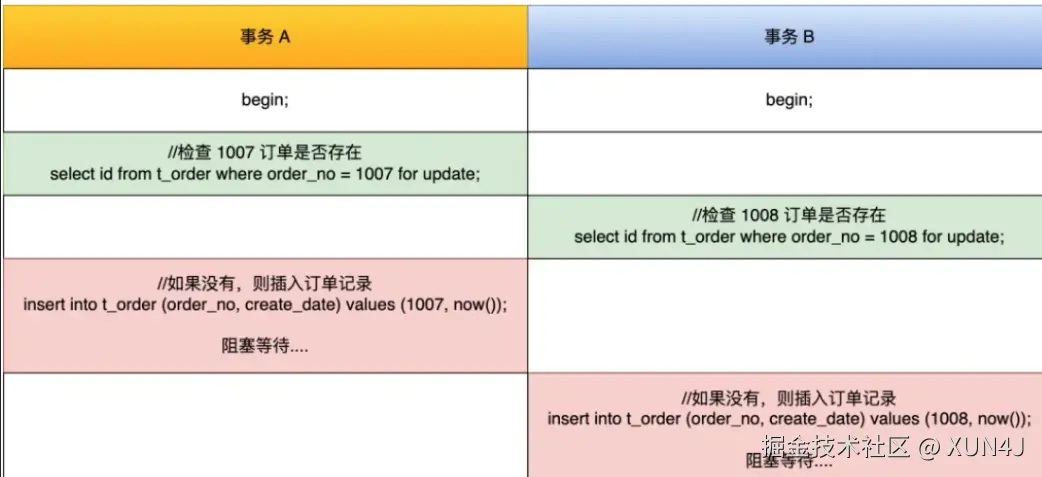
sql
-- 事务A
BEGIN;
SELECT * FROM users WHERE id > 10 FOR UPDATE; -- 加临键锁
INSERT INTO users (id, name) VALUES (12, 'Alice');
-- 事务B
BEGIN;
SELECT * FROM users WHERE id > 10 FOR UPDATE; -- 等待事务A
INSERT INTO users (id, name) VALUES (11, 'Bob'); -- 死锁!死锁解决策略:
-
设置锁等待超时:
iniSET innodb_lock_wait_timeout = 50; -- 50秒超时 -
开启死锁检测(默认开启):
sqlSHOW VARIABLES LIKE 'innodb_deadlock_detect'; -- 查看状态 -
应用层优化:
- 保持事务短小
- 按固定顺序访问资源
- 使用较低的隔离级别
字节面试题解析
sql
-- 事务A
UPDATE t SET name = 'A' WHERE id = 1;
UPDATE t SET name = 'B' WHERE id = 2;
-- 事务B
UPDATE t SET name = 'B' WHERE id = 2;
UPDATE t SET name = 'A' WHERE id = 1;分析:两个事务以相反顺序获取锁,形成循环等待,导致死锁。
八、最佳实践与调优建议
1. 事务设计原则
- 短事务优先:尽快提交,减少锁持有时间
- 更新后置:将UPDATE/DELETE语句放在事务末尾
- 避免长查询:大查询使用分页或游标
2. 索引优化
sql
-- 为WHERE条件、JOIN条件、ORDER BY字段建立合适索引
CREATE INDEX idx_age_name ON users(age, name);
-- 避免索引失效场景
-- ❌ 函数操作
SELECT * FROM users WHERE YEAR(create_time) = 2024;
-- ✅ 范围查询
SELECT * FROM users WHERE create_time >= '2024-01-01' AND create_time < '2025-01-01';3. 隔离级别选择
- 默认使用RR:大部分场景适用
- 高并发写场景考虑RC:减少锁冲突
- 财务系统使用SERIALIZABLE:最高一致性要求
4. 监控与诊断
sql
-- 查看当前锁信息
SHOW ENGINE INNODB STATUS\G
-- 监控锁等待
SELECT * FROM information_schema.INNODB_LOCKS;
SELECT * FROM information_schema.INNODB_LOCK_WAITS;
-- 查看长事务
SELECT * FROM information_schema.INNODB_TRX
WHERE TIME_TO_SEC(TIMEDIFF(NOW(), trx_started)) > 60;九、总结
MySQL的事务和锁机制是一个精心设计的平衡系统,在数据一致性、隔离性和并发性能之间寻找最佳平衡点。理解这些机制需要掌握:
- MVCC实现非阻塞读:通过Undo Log链和Read View实现
- 锁保证写有序:通过行锁、间隙锁、临键锁协同工作
- 隔离级别的权衡:根据业务需求在一致性和性能间选择
- 死锁的预防与处理:通过超时、检测和应用层设计避免
实际应用中,建议:
- 从默认的RR级别开始,遇到性能瓶颈再考虑调整
- 为所有查询条件添加合适索引
- 监控长事务和锁等待,及时发现瓶颈
- 在应用层考虑并发控制,不完全依赖数据库
事务和锁的深入理解是成为MySQL专家的必经之路,只有掌握了这些底层原理,才能设计出既高效又可靠的数据系统。
扩展阅读推荐:
- 《高性能MySQL》第6章:查询性能优化
- 《MySQL技术内幕:InnoDB存储引擎》第6章:锁
- 官方文档:InnoDB Locking and Transaction Model