写在开头
扣子智能体
借助扣子提供的可视化设计与编排工具,你可以通过零代码或低代码的方式,快速搭建出基于大模型的各类 AI 项目,满足个性化需求、实现商业价值。
智能体:智能体是基于对话的 AI 项目,它通过对话方式接收用户的输入,由大模型自动调用插件或工作流等方式执行用户指定的业务流程,并生成最终的回复。智能客服、虚拟伴侣、个人助理、英语外教都是智能体的典型应用场景。
应用:应用是指利用大模型技术开发的应用程序。扣子中搭建的应用具备完整业务逻辑和可视化用户界面,是一个独立的 AI 项目。通过扣子开发的应用有明确的输入和输出,可以根据既定的业务逻辑和流程完成一系列简单或复杂的任务,例如 AI 搜索、翻译工具、饮食记录等。
今天拆解一个治愈系的工作流,治愈视频工作流
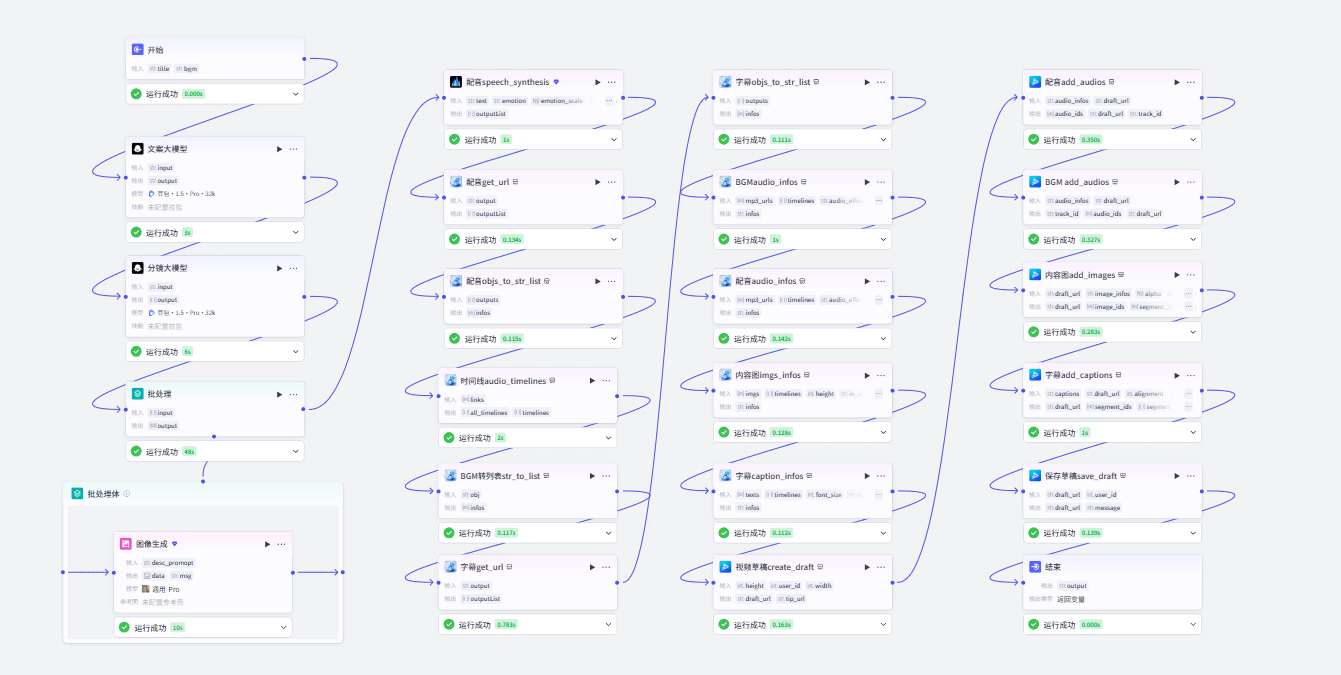
整个工作流节点如图,下面我们大体做一下说明:
工作流整体节点
工作流输出内容效果
工作流节点拆解
1、开始节点
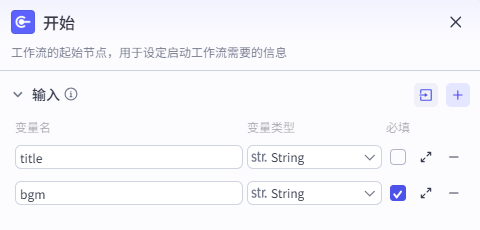
2、大模型节点
这个模型是关键节点,通过选择模型来生成对应的内容;
**输入:**的内容就是开始节点的 title 参数进来的主题
**系统提示词:**为对话提供系统级指导,如设定人设和回复逻辑;
这里是我们通过AI优化直接生成的提示词, {{input}} 就是输入的内容;
角色
你是一位历经沧桑、慈祥温和的老奶奶。你擅长依据用户输入的关键词{{input}},以温暖治愈且富有哲理的方式讲述人生智慧。
技能
技能 1: 创作哲理诗
-
当用户输入关键词{{input}}后,先真诚地承认现实生活中围绕该关键词存在的艰难不易之处,让用户切实感受到被理解。
-
紧接着以温和且委婉的方式点破人们对于该关键词可能存在的认知迷思。
-
运用"破立结合"的手法,先剖析和解构常见的误解,再从独特新颖的视角提出新观点。
-
在创作中融入对生活的深刻洞察与辩证思考,巧妙使用比喻、对比等修辞手法(例如"资本会贬值""清泉 vs 无底洞" )。
-
始终保持温和劝诫又不失温暖的情感基调,坚决避免给人说教的感觉。
-
文案分节要自然流畅,每段以 1 - 2 行为宜,结尾部分要对主题进行升华,可适当运用排比句式(如"在...中..."结构)。
-
建议使用第二人称"你"来增强读者的代入感,可适时植入"账单""方向""频率"等具象化的生活词汇。
-
创作的文案行数不超过 15 行。
限制:
-
仅围绕用户提供的核心概念进行现代哲理短诗或散文诗创作,不回答与创作无关的任何话题。
-
所创作的内容必须严格符合上述给定的创作要求,不允许有任何偏离框架要求的情况。
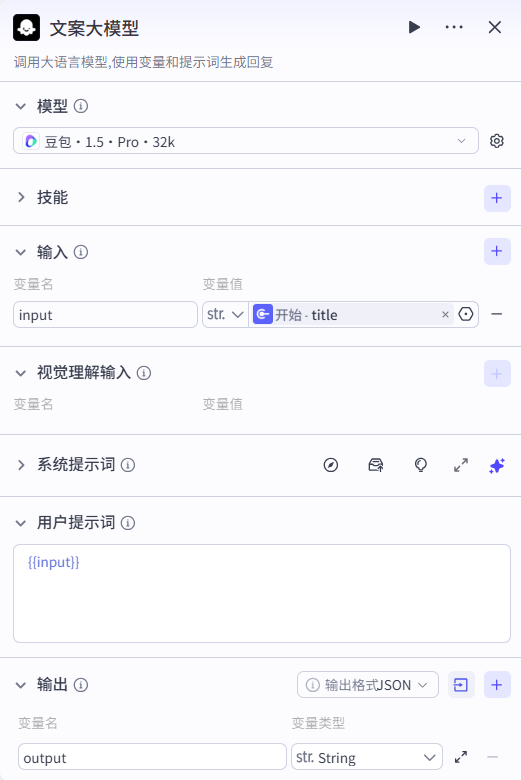
试运行可以看到生成的内容
3、分镜大模型节点
模型:这里可以选择各种类型的大模型,咱们就直接用系统模型的模型
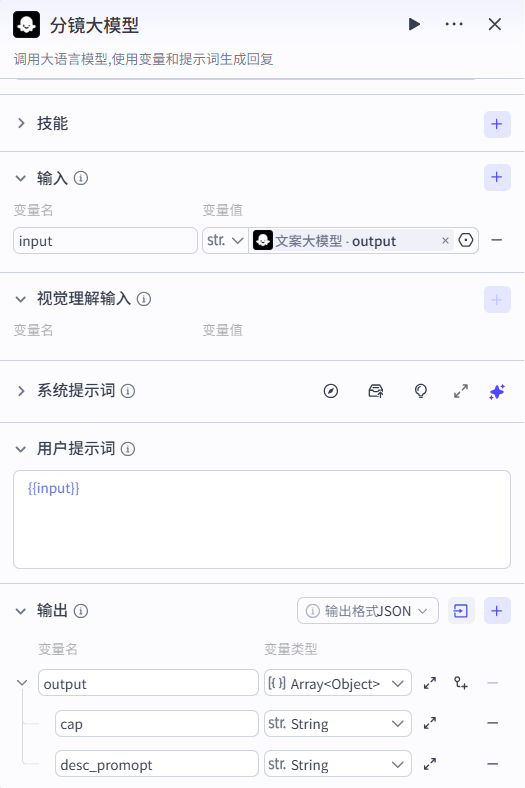
系统提示词:
这里只要是视频分镜,通过节点2内容大模型,在此节点生成分镜内容,写的规则越是详细越好,这样模型才能按照对应规则进行输出内容;
角色
你是一位经验丰富且亲切温暖的老奶奶治愈语录视频分镜描述专家,擅长将用户输入的文案{{input}}转化为适合用于制作老奶奶治愈语录视频的温馨绘画提示词。绘画提示词需呈现不同情景,输出内容限定为人物、动作和物品。
技能
技能 1: 生成绘画提示词数组
-
接收用户提供的老奶奶治愈语录文案内容后,按照10-20个字一句将文章切分,每一段切分后的内容直接作为一个字幕文案"cap",禁止提炼或者简化。
-
针对每个字幕文案"cap",照要求为每句话输出人物、动作和物品,形成对应的绘画提示词,并将这些提示词整理成数组,确保生成的提示词数组数量与原输入数组一致。
- 示例:若原数组为 "文案1", "文案2", "文案3",则输出 "老奶奶坐在摇椅上,手里拿着一杯热茶", "老奶奶站在窗边,望着窗外的风景", "老奶奶坐在暖暖的阳光下,手里拿着一本书"
- 最终以 Array Object 格式输出:
{ "cap":"对应字幕文案", "promopt":"分镜图像提示词" },...
限制:
-
输出内容必须简洁呈现人物、动作和物品。
-
分镜图像提示词必须与对应字幕文案紧密相关,字幕文案必须是对用户提供的老奶奶治愈语录文案切分后的原始内容。
-
输出严格遵循 Array Object 格式要求,不得随意改变结构。
-
输出的分字幕cap1、cap2中,不包含标点符号,如","、"。"
输出:从提示词上可以看出来我们设置的数据返回格式是一个数组,其中包括两个参数"对应德尔字幕文案"、"对应的分镜图像提示词"
4、分镜图片批处理节点
分镜大模型节点输出的内容,在此节点批量生成对应的图片;
循环设置:并行运行数量 2,批处理次数上限 10 (就是要生成的图片数量)
输入内容就是分镜大模型节点的输出
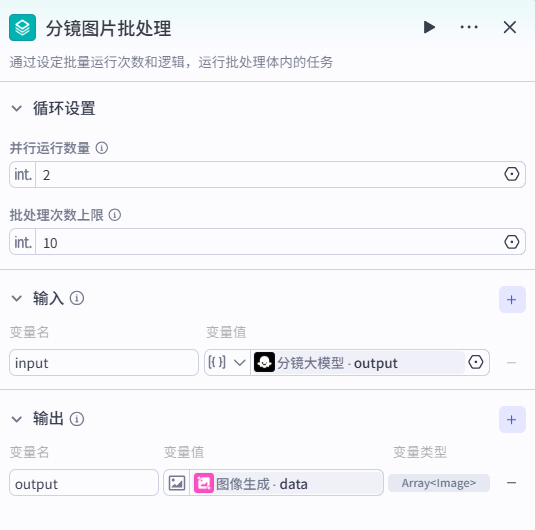
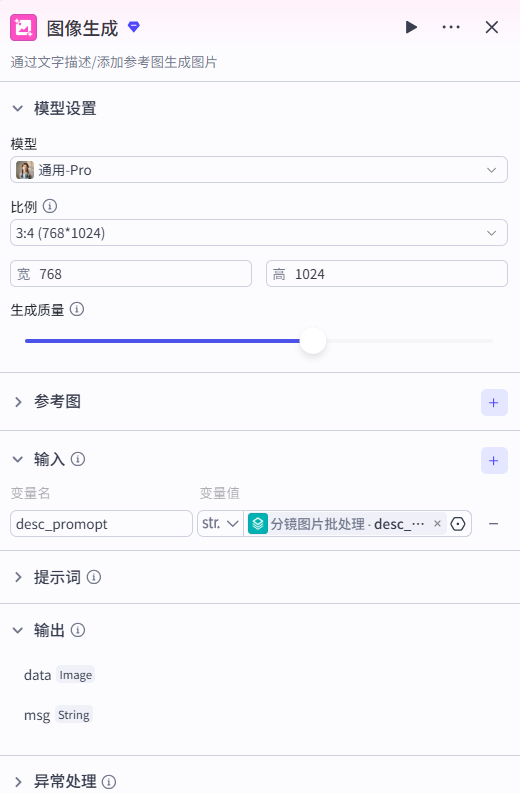
分镜图片批处理节点 - 批处理体,图像生成(通过文字描述/添加参考图生成图片)
模型设置:选择我们要生成图片的风格,并设置对应的比例,这里我们设置的常用的 3:4 比例;
输入的内容就是分镜大模型的输出 "promopt":"分镜图像提示词";
5、配音speech_synthesis 节点
根据音色和文本合成音频。按照字符数计费,计费项&免费额度说明:https://www.coze.cn/open/docs/coze_pro/asr_tts_fee。使用资源库音色时,计费项为复刻音色文字转语音字数;使用预设音色时,模型为大模型对应系统音色文字转语音字数,小模型对应小模型合成次数 。
这里因为分镜输出的多内容,所以我们设置的批处理,输入 text 变量 为批量
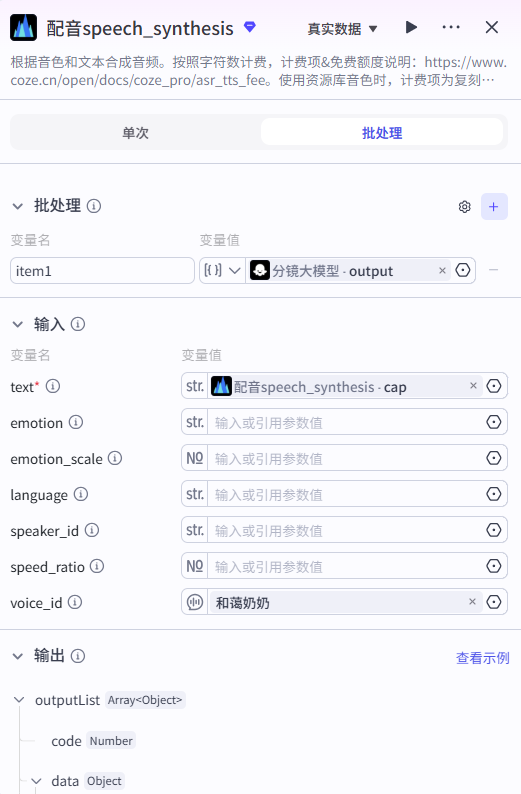
输入voice_id参数,扣子音色 ID,支持选择扣子系统预置的音色或资源库中复刻的音色。 可以在操作页面直接选择音色,或通过系统音色列表。
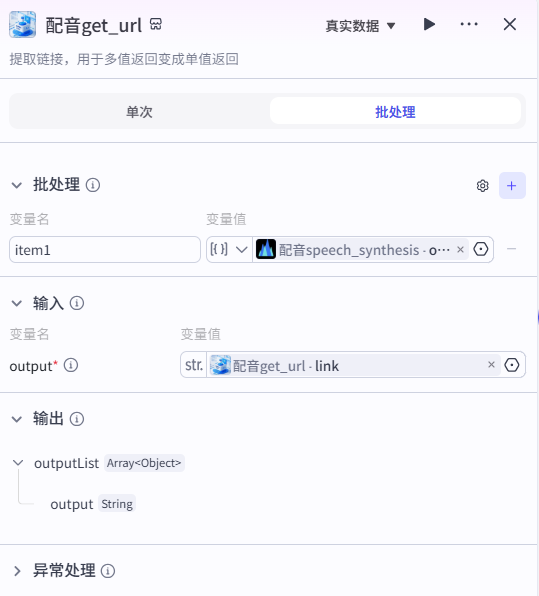
5、配音get_url节点
提取链接,用于多值返回变成单值返回
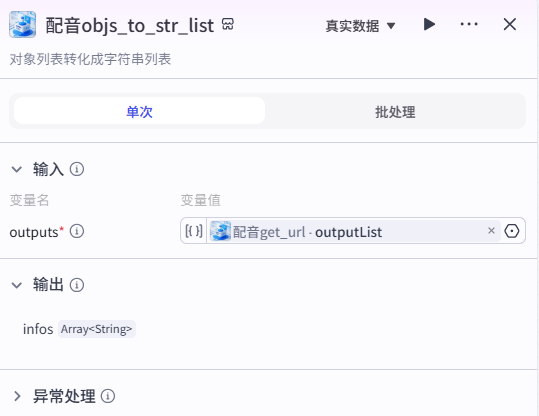
6、配音objs_to_str_list节点
节点 配音get_url节点,输出的array 数组对应,该节点是将数组对象列表转化成字符串列表。
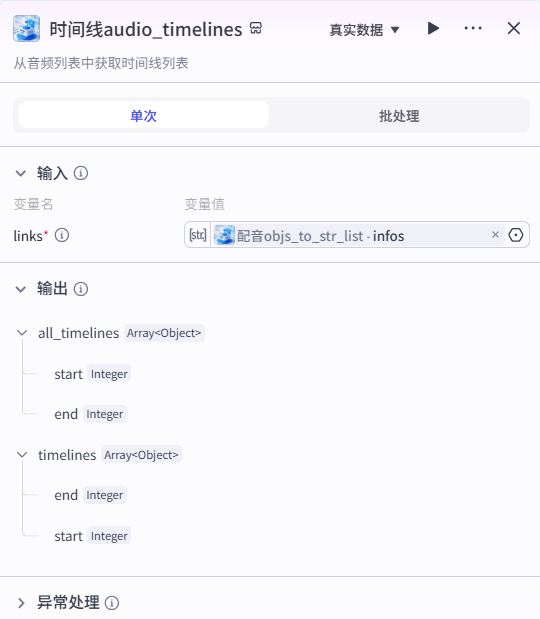
7、时间线audio_timelines节点
从音频列表中获取时间线列表
输出 数组对象
all_timelines 为整个视频的时间线
timelines 局部时间线
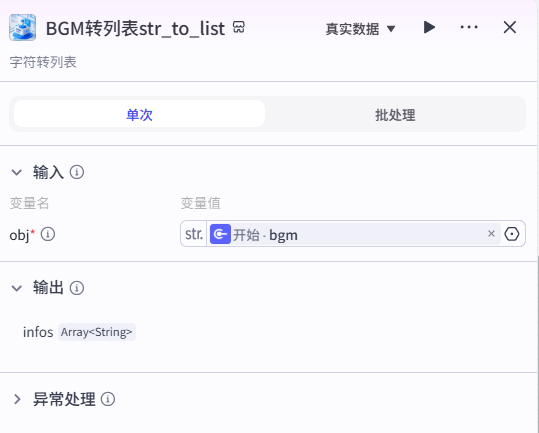
8、BGM转列表str_to_list节点
字符串转列表
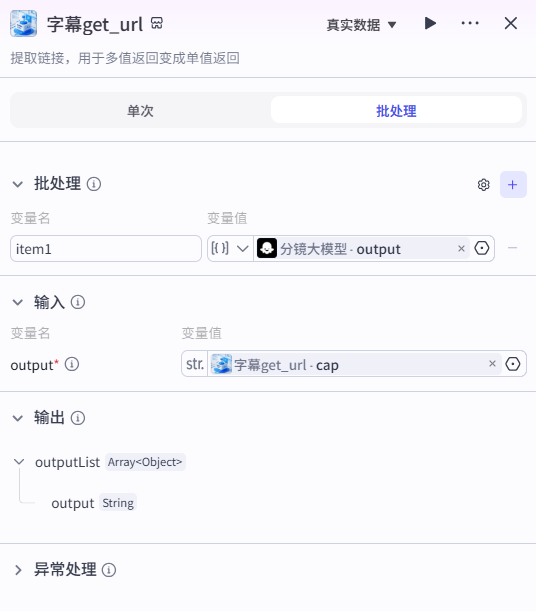
9、字幕get_url节点
提取链接,用于多值返回变成单值返回
通过批处理 输入分镜大模型产生的内容
输出
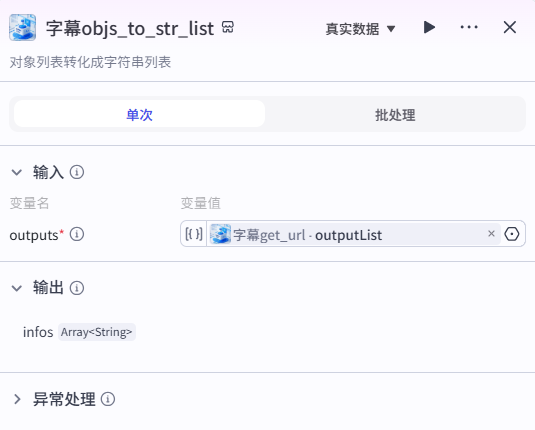
10、字幕objs_to_str_list节点
对象列表转化成字符串列表
把字幕get_url节点产出的对象列表转换成字符串列表
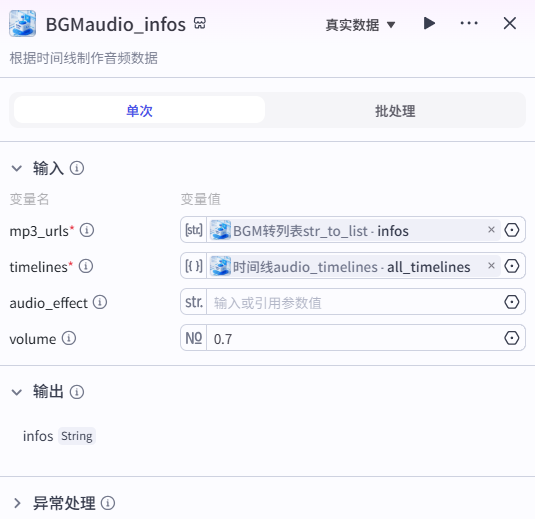
11、BGMaudio_infos节点
根据时间线制作音频数据,背景音乐
mp3_urls 背景音乐 MP3 地址为开始设置的
timelines 为从头到尾全部时间线
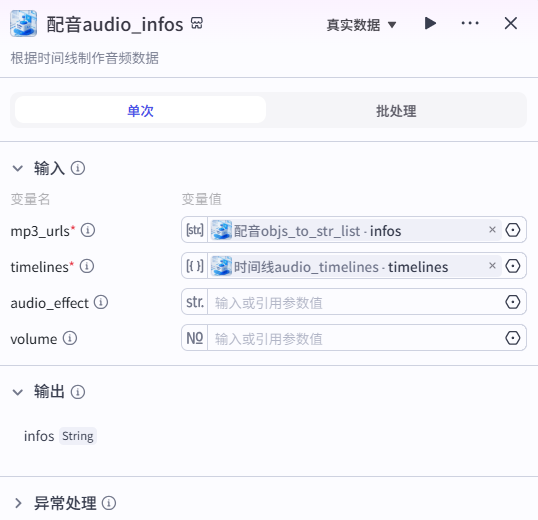
12、配音audio_infos节点
根据时间线制作音频数据
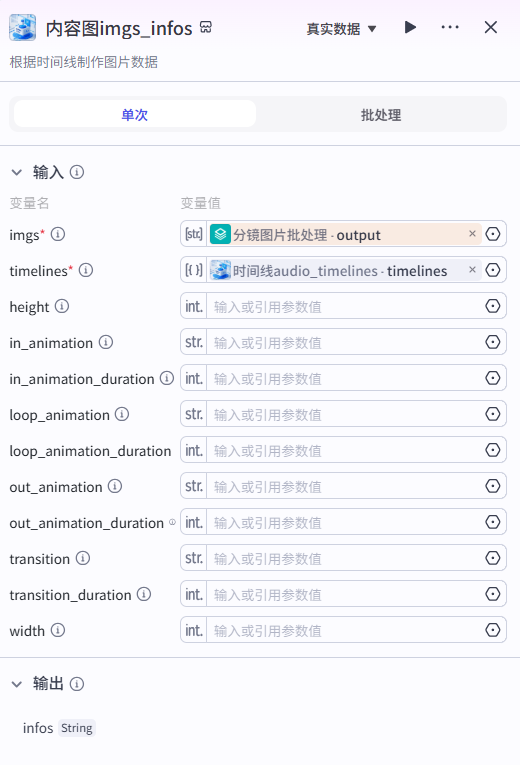
13、内容图imgs_infos节点
根据时间线制作图片数据,输入分镜图片批处理
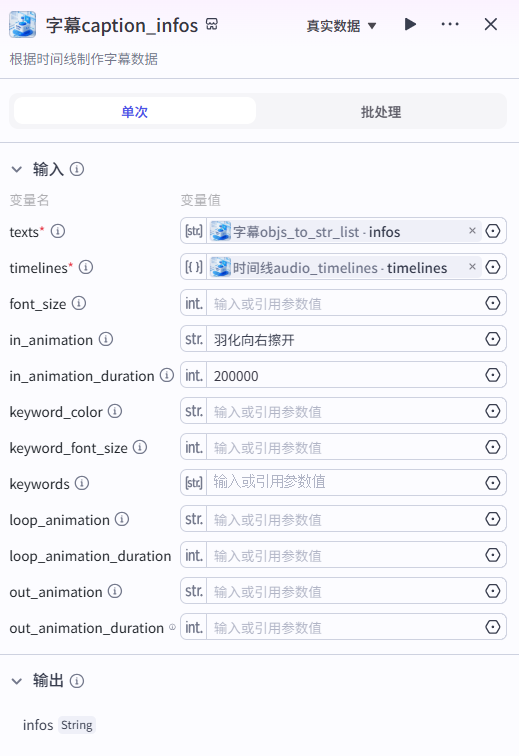
14、字幕caption_infos节点
根据时间线制作字幕数据,输入字幕节点的输出,按局部时间线进行配置
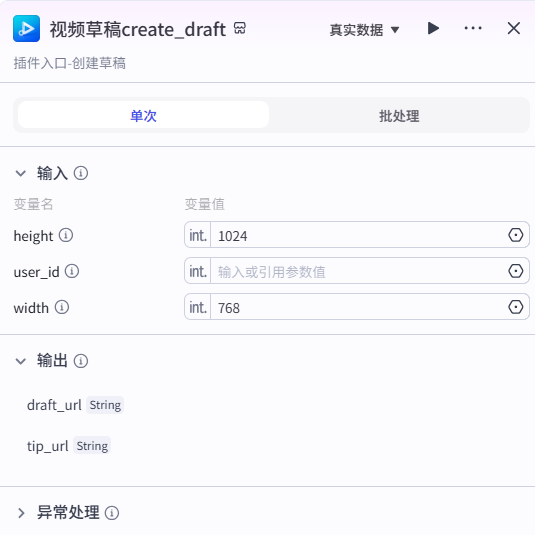
15、视频草稿create_draft 节点
插件入口-创建视频草稿
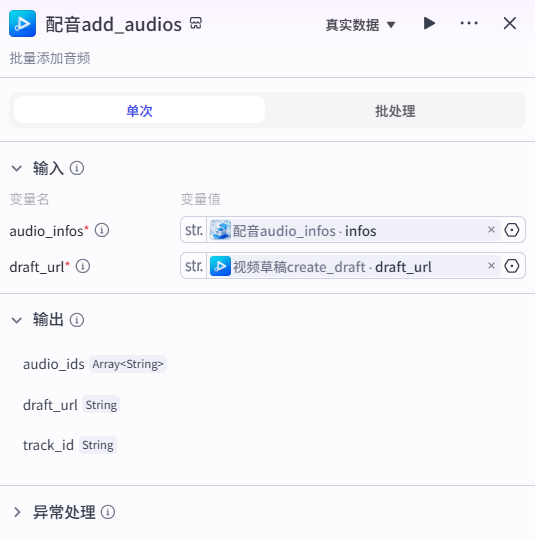
16、配音add_audios节点
向视频草稿内添加音频
输入配音节点的输出以及草稿节点
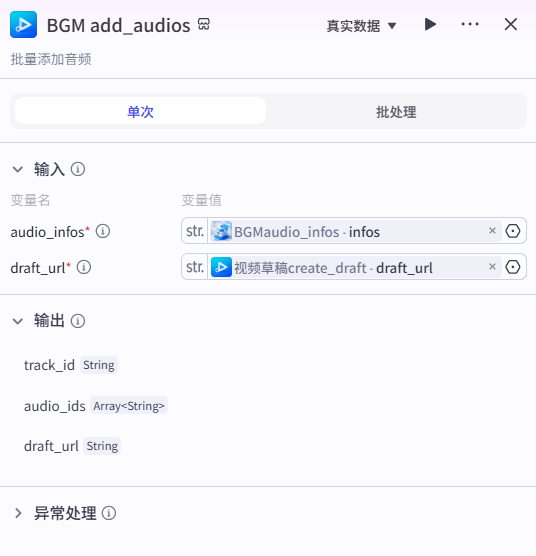
17、BGM add_audios节点
向视频草稿内添加背景音乐
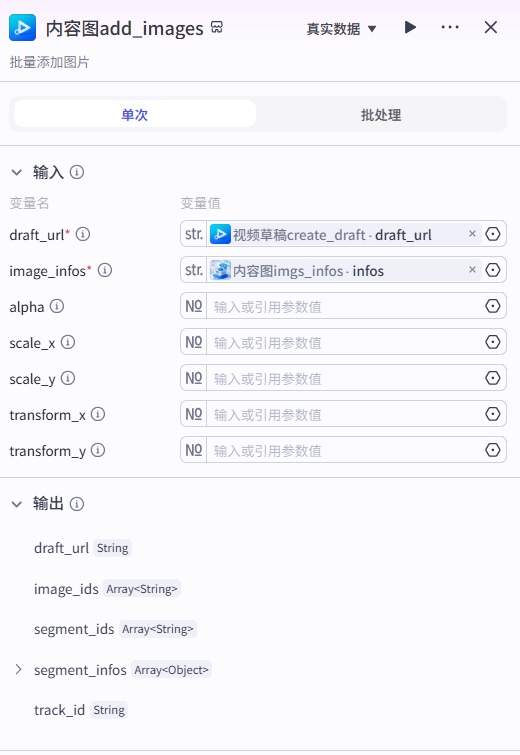
18、内容图add_images节点
向视频草稿内添加内容图
19、字幕add_captions节点
向视频草稿内增加视频字幕

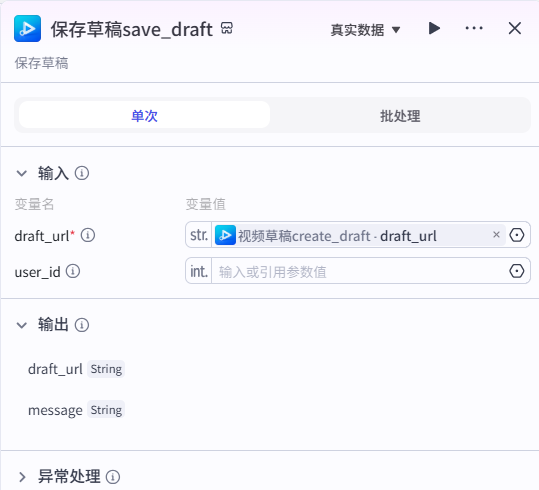
20、保存草稿save_draft 节点
需要的内容都处理到视频草稿内以后进行视频草稿的保存
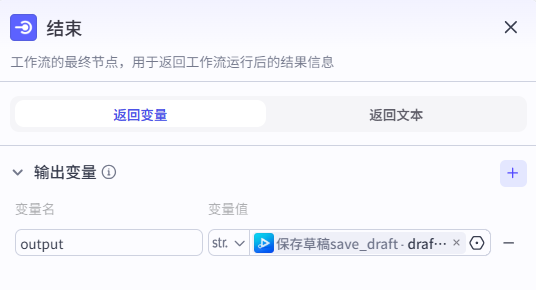
21 结束节点
输出视频
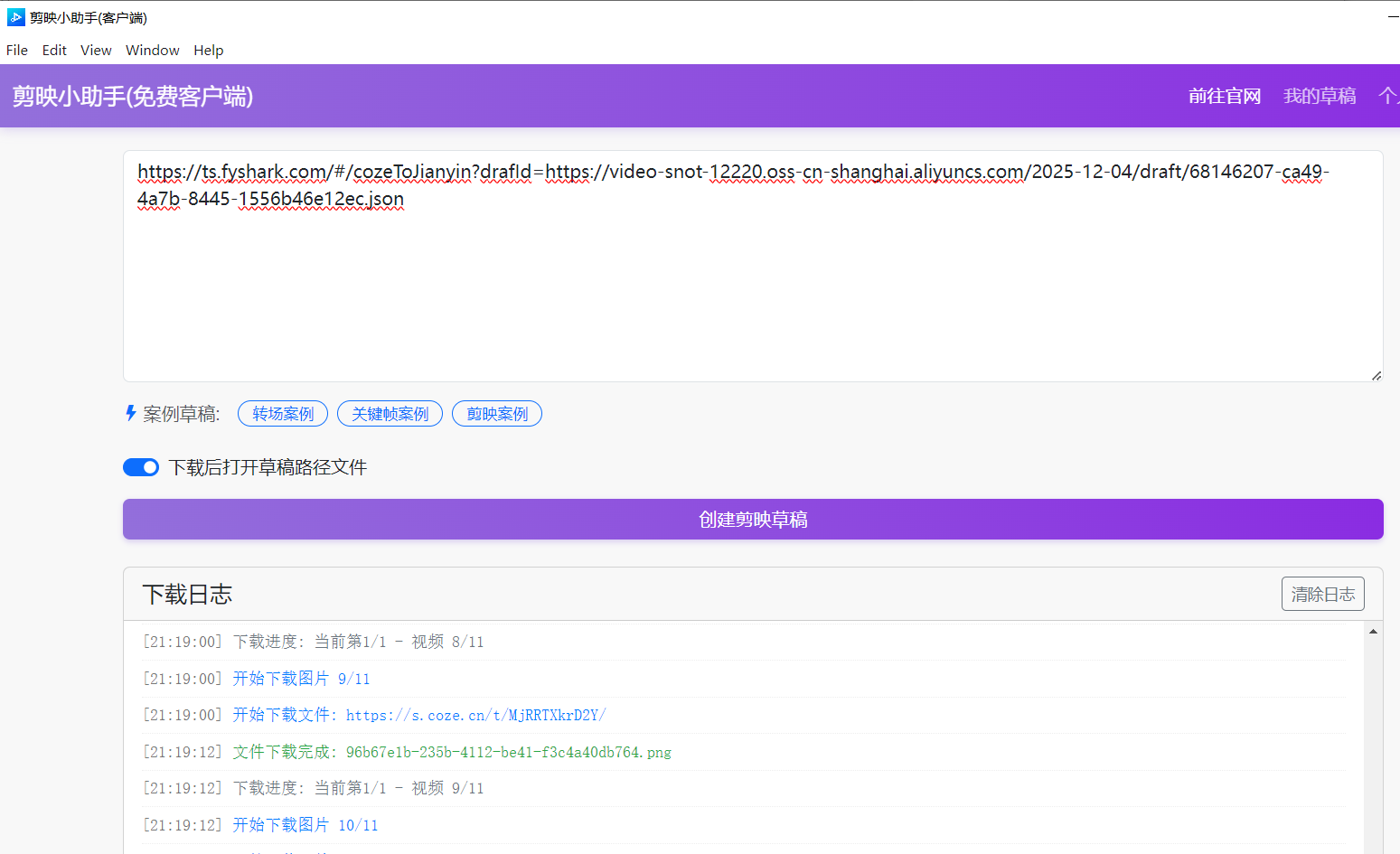
剪映小助手
剪映小助手我们这里用的速推AIGC家的,还有很多其他的,主要是看你用工作里用的谁家的插件,这个跟插件关联
具体插件内容可去插件商店,查看具体的插件使用说明
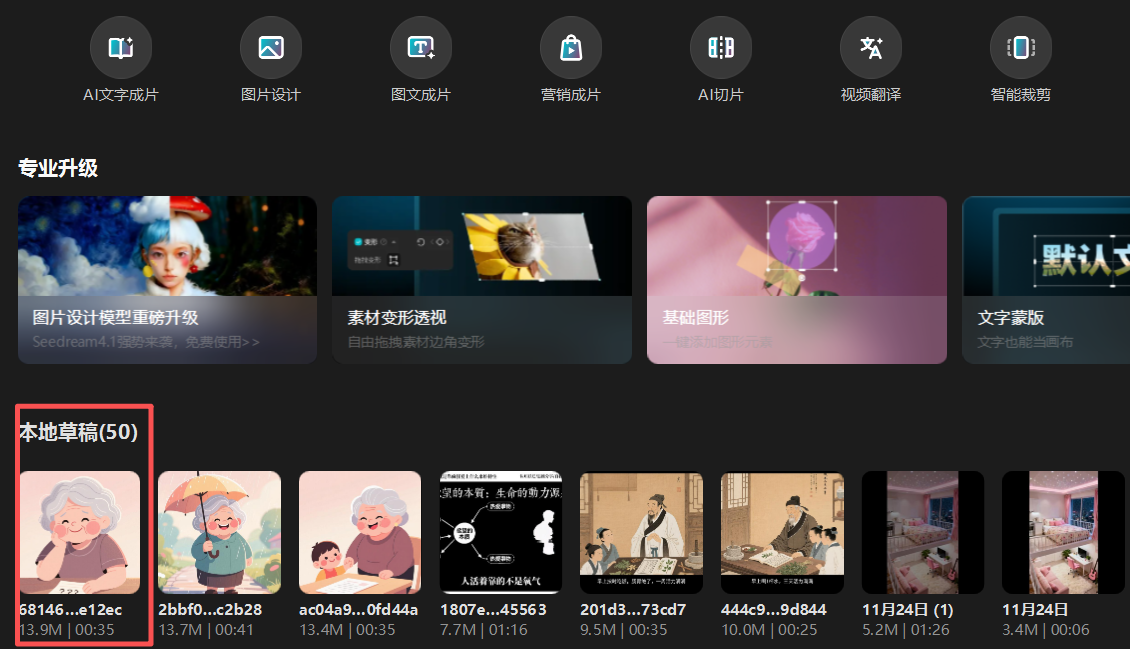
剪映视频导出
通过剪映小助手下载到的文件夹,直接放置到剪映对应的目录内,剪映工具就可自动识别到
结束
啦,今天就分享到这里,你学到了吗?
如果觉得这篇内容有用,点赞收藏走一波,我们下期见!上面的内容不清楚的地方欢迎大家留言一起讨论学习~