一、引言
1.1 背景与挑战:从内核瓶颈到用户态的突围
随着云计算、大数据、5G 以及物联网技术的爆发式增长,现代数据中心和网络边缘节点的流量呈现出指数级上升的趋势。在 10GbE、40GbE 乃至 100GbE 网卡逐渐普及的今天,传统的基于操作系统内核(Kernel)的网络数据包处理模式正面临着前所未有的挑战。
在传统的 Linux 网络协议栈中,数据包的收发严重依赖于中断机制、系统调用以及内核态与用户态之间的数据拷贝。当面对海量的小包高并发流量时,频繁的上下文切换(Context Switch)和中断风暴(Interrupt Storm)会导致 CPU 的大量时钟周期被消耗在系统开销上,而非实际的业务逻辑处理中。这使得通用操作系统在处理高速网络流量时,往往成为性能的瓶颈所在。
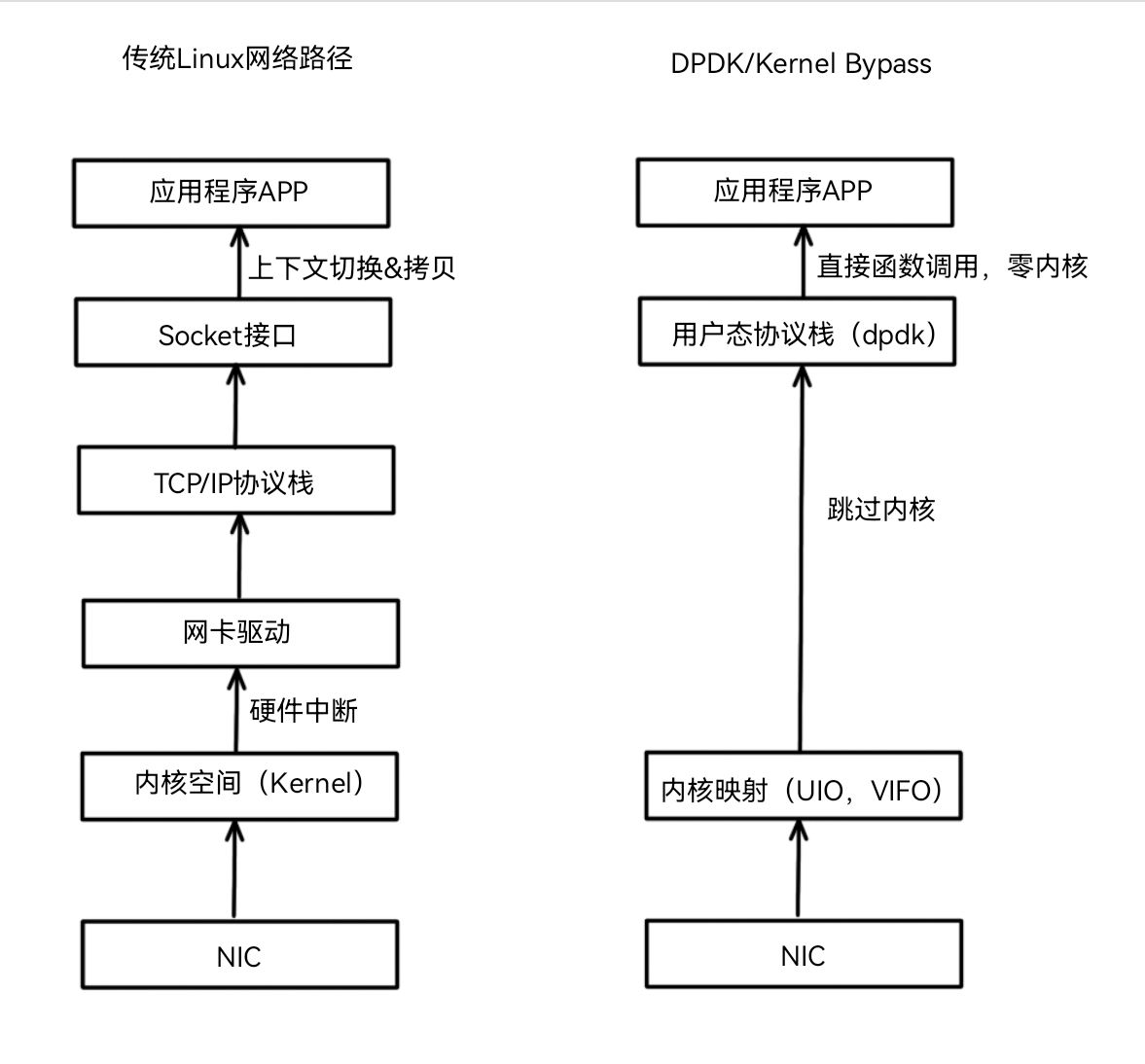
为了解决这一核心矛盾,"内核旁路(Kernel Bypass) "技术应运而生,而用户态协议栈正是这一技术路径下的集大成者。通过将网络协议的处理逻辑从内核空间移至用户空间,应用程序可以直接控制网卡收发数据,从而极大地降低系统延迟,提升吞吐量,如下图所示。这种架构广泛应用于高性能防火墙、DDoS 防御清洗、软件定义网络(SDN)、网络功能虚拟化(NFV)以及高频交易系统等对性能极其敏感的场景。
1.2 DPDK:数据平面开发的基石
在众多实现用户态高性能网络处理的方案中,Intel 推出的 DPDK(Data Plane Development Kit) 无疑是目前生态最成熟、应用最广泛的开源框架。DPDK 并非一个现成的网络协议栈,而是一套包含库函数和驱动程序的工具集,专为快速数据包处理而设计。
DPDK 的核心哲学在于"轮询"代替"中断",利用大页内存(Hugepages)、无锁环形队列(Ring Buffer)、CPU 亲和性(CPU Affinity)以及 SIMD 指令集优化等技术,成功地将数据包处理效率提升到了线速(Line Rate)水平。它为开发者提供了一个直接接管底层硬件能力的平台,使得在通用 x86 架构服务器上实现电信级的网络性能成为可能。
二、传统协议栈与用户态协议栈的对比
在深入了解 DPDK 之前,我们必须先回答一个关键问题:为什么久经考验的 Linux 内核协议栈在高速网络下会显得力不从心? 理解了"旧制度"的弊端,才能真正体会到"新变革"的价值。
2.1 传统操作系统内核协议栈的瓶颈
Linux 内核协议栈设计之初,是为了通用性、稳定性和多任务隔离而优化的,而非极致的 IO 性能。在 1Gbps 时代,这种设计游刃有余;但在 10Gbps、40Gbps 乃至更高的速率下,以下几个机制成为了难以逾越的性能墙:
-
频繁的中断处理与上下文切换 (Interrupts & Context Switches)
-
传统模式下,网卡收到数据包会触发硬件中断,CPU 需要暂停当前任务,保存上下文,跳转到中断处理程序,然后再恢复上下文。
-
即使有 NAPI(New API)的中断合并机制,在高并发小包场景下(如 64 字节包),每秒百万级的数据包(Mpps)仍会引发"中断风暴",导致 CPU 大量时间消耗在模式切换(用户态 ↔ 内核态)上,而非处理数据。
-
-
昂贵的内存拷贝 (Memory Copy)
-
数据包从网卡进入内存后,通常先由 DMA 写入内核空间的缓冲区 (如
sk_buff),应用程序要读取数据,必须通过系统调用将数据从内核空间拷贝到用户空间缓冲区。 -
这种"网卡 -> 内核 -> 用户"的拷贝路径,在高吞吐量下会占用大量的内存带宽(Memory Bandwidth)和 CPU 周期。
-
-
系统调用开销 (System Call Overhead)
- 标准的
socket编程模型(recv,send)都需要发起系统调用。系统调用不仅涉及特权级的切换,还伴随着参数检查、锁竞争等隐性开销。
- 标准的
-
缓存失效 (Cache Misses)
- 内核协议栈路径长、逻辑复杂,数据包的处理跨越多个层级,极易导致 CPU Cache(L1/L2/L3)的抖动和失效,极大地降低了 CPU 的指令执行效率。
2.2 用户态协议栈的优势
用户态协议栈的核心思想是 "Kernel Bypass"(内核旁路),即绕过 Linux 内核的网络协议栈,直接在用户空间接管网卡硬件。其主要优势包括:
-
消除上下文切换 :应用直接在用户态操作网卡 ,不再需要在用户态和内核态之间反复横跳。
-
零拷贝 (Zero Copy):网卡直接通过 DMA 将数据包写入用户态进程可见的内存区域,应用程序直接"原地"处理数据,消除了内核到用户的内存拷贝。
-
更高的灵活性与定制化:开发者可以根据业务需求(如专用的 UDP 协议、极简的 TCP 逻辑)裁剪协议栈,去除不必要的防火墙、QoS 等通用功能,实现极致轻量化。
-
便于调试与迭代:协议栈代码即应用代码,崩溃不会导致操作系统死机(Kernel Panic),调试和更新也无需重新编译内核或重启机器。
2.3 DPDK 如何有效解决性能问题
DPDK 提供了一整套软硬件结合的优化方案,精准打击上述瓶颈:
-
轮询模式驱动 (Poll Mode Driver, PMD)
-
解决痛点:中断开销。
-
原理 :DPDK 放弃了被动的中断通知,改用 CPU 主动轮询网卡接收队列 。虽然这会让 CPU 使用率显示为 100%,但它消除了中断唤醒的延迟,保证了数据包到达即被处理,实现了最低的延迟和最高的吞吐。
-
-
用户态驱动 (UIO / VFIO)
-
解决痛点:系统调用与上下文切换。
-
原理 :利用 Linux 的 UIO (Userspace I/O) 或 VFIO 机制,将网卡的 PCI 寄存器映射到用户空间,使得用户进程可以直接向网卡发送指令,完全绕过内核驱动。
-
-
大页内存 (Hugepages)
-
解决痛点:TLB (Translation Lookaside Buffer) 未命中。
-
原理:Linux 默认页大小为 4KB,而 DPDK 推荐使用 2MB 或 1GB 的大页。这大幅减少了页表项的数量,降低了 TLB Miss 的概率,显著提升了内存访问效率。
-
-
内存池与无锁队列 (Mempool & Ring Buffer)
-
解决痛点:内存分配与锁竞争。
-
原理 :DPDK 预先分配好固定大小的内存池(Mempool),避免运行时频繁的
malloc/free。同时,核心组件rte_ring实现了无锁的生产者-消费者模型,极大提升了多核间的数据传递效率。
-
| 特性 | 传统内核协议栈 | DPDK 用户态协议栈 |
|---|---|---|
| 运行空间 | 内核态 | 用户态 |
| 数据路径 | 内核网络协议处理 | 直接绕过内核,用户态直接访问网卡 |
| 性能 | 中等,受系统调用、内核上下文切换影响 | 高,低延迟、高吞吐量 |
| 延迟 | 较高(微秒级以上) | 较低(亚微秒至几微秒) |
| 吞吐量 | 受限于内核网络栈和上下文切换 | 可充分利用多核,提升线速转发能力 |
| 开发复杂度 | 较低,使用标准套接字接口 | 较高,需要直接操作网卡和内存管理 |
| 内存管理 | 内核管理缓冲区,受系统调度影响 | 应用管理大页内存和环形缓冲区,减少拷贝 |
| 灵活性 | 协议栈固定,扩展协议需修改内核 | 协议栈可定制化,便于实现高性能网络功能 |
| 系统依赖 | 高度依赖操作系统内核版本和实现 | 相对独立,只依赖 DPDK 库和驱动 |
| 适用场景 | 通用网络应用,如 Web 服务、数据库 | 高性能网络应用,如 NFV、软件交换机、金融交易系统 |
三、DPDK 核心架构详解
DPDK 之所以能实现单核千万级 PPS(Packet Per Second)的转发性能,并非依赖单一技术的突破,而是从驱动层、内存管理到并发模型进行的全方位重构。它摒弃了通用操作系统对"公平性"和"通用性"的妥协,转而追求极致的"吞吐量"和"低延迟"。
1. 内存管理:Hugepages 与 Ring Buffer 的结合优化
DPDK最大程度地发挥硬件性能,离不开对内存管理的深度优化。传统系统中的内存页通常为 4KB,在高速收发数据包时,频繁的页表切换和内存分配会带来额外开销。DPDK利用**Hugepages(大页内存)技术,将页大小提升到 2MB 或 1GB,从而显著减少TLB(Translation Lookaside Buffer)缺失的概率,提升内存访问效率。
在内存组织上,DPDK引入环形缓冲队列(Ring Buffer)**作为线程之间、模块之间的无锁通信机制,每个Ring内部通过环形数组和读写指针实现FIFO队列,减少了线程间锁竞争。结合Hugepages的物理连续性,数据在内存中的布局更紧凑,有助于DMA(Direct Memory Access)发挥最大效能。
2. 轮询机制:Poll Mode Driver(PMD)取代中断驱动
DPDK采用的是轮询模式驱动(Poll Mode Driver, PMD),核心思想是在用户态的主循环中直接读取网卡收发队列(RX/TX queue)的内容,而不是依赖网卡产生中断唤醒内核驱动。这种方式避免了在高流量场景下的中断风暴,消除了上下文切换带来的抖动,使得数据包处理延迟更加稳定、可预测。
PMD通常与**零拷贝(Zero-Copy)**设计配合,通过直接访问映射到用户态的网卡缓冲区,实现数据从网卡到应用数据处理逻辑之间完全不经过多余的拷贝操作,从而提升吞吐率和降低延迟。
3. 多核支持与CPU核心亲和性(Core Affinity)
DPDK在设计时就针对多核服务器进行了优化。它鼓励通过核心亲和性 将不同的收发队列(RX/TX queue)或处理线程绑定到特定的CPU核心上。这样一来,每个核心独立处理各自的流量,避免了多核间缓存一致性(Cache Coherency)的冲突。
结合NUMA(Non-Uniform Memory Access)架构,DPDK可以将数据和线程绑定到最接近其物理内存的CPU节点,从而减少跨节点访问带来的延迟。这种绑定策略在电信级应用或高频交易系统中尤为重要,因为它有助于实现"每核绑定一队列"的极高并行度。
4. 数据包缓冲管理:mbuf结构的核心作用
在DPDK中,所有数据包都通过统一的**mbuf(Memory Buffer)**结构进行管理。mbuf不仅保存了数据包的有效载荷指针,还包含了元数据,例如长度、偏移量、引用计数、时间戳等。这种统一的数据结构使包处理逻辑更加模块化,方便在不同环节对数据包进行解析、修改或转发。
mbuf的内存分配通常基于预分配的内存池(mempool),避免了运行时的频繁malloc/free导致的性能抖动。同时,mbuf通过实现缓存友好的布局,减少了内存访问的随机性,使得CPU能够高效地批量处理数据包。
5. 驱动模型:用户态驱动直接操控硬件
传统网卡驱动通常运行在内核态,通过内核网络栈向应用层提供Socket API。而DPDK的用户态驱动 (通常基于UIO或VFIO接口)直接映射网卡寄存器和缓冲区到用户空间,使应用程序无需经过内核协议栈,便可以使用PMD直接与硬件交互。
这种模式绕过了内核中冗余的协议处理、拷贝和队列操作,使开发者能够在用户态完全接管数据平面逻辑,并针对特定场景定制优化,例如批量收发、定制化协议栈等。这也是DPDK性能优势的根本来源之一。
四、DPDK工作原理
4.1 DPDK关键组件
DPDK(Data Plane Development Kit)的工作原理可以理解为一套专门为高性能网络数据包处理设计的用户态机制,它通过绕过传统操作系统内核网络栈,实现低延迟、高吞吐的数据包收发。在传统网络栈中,数据包需要经历内核中断处理、内核缓冲区、上下文切换和系统调用等步骤,这些过程在高流量场景下会显著降低处理效率。DPDK 的核心思想是让 CPU 核心在用户态直接与网卡交互,从而最大限度地减少中间开销。
DPDK 的第一大核心机制是用户态轮询(Poll Mode Driver, PMD)。不同于传统网络依赖中断通知,PMD 驱动会让 CPU 核心持续轮询网卡的接收队列(RX 队列),检测是否有新数据包到达。当网卡通过 DMA(Direct Memory Access)将数据写入用户态分配的内存缓冲区时,轮询的 CPU 核心立即读取并处理这些数据包。由于省去了中断处理和内核态切换的步骤,数据包处理的延迟显著降低,同时吞吐量得以大幅提升。这种机制虽然会占用 CPU,但在高性能网络应用中是可接受的。
零拷贝和 DMA 是 DPDK 提高性能的另一个关键手段。网卡在接收到数据包后,利用 DMA 直接将数据写入用户态预先分配的内存,而不需要经过内核网络栈的缓冲或复制。用户态应用可以直接访问这些数据包并进行处理,这种方式几乎消除了数据拷贝的开销,使 CPU 能够专注于数据包的处理逻辑,而不是搬运数据,从而提升了整体处理效率。
为了进一步优化内存访问,DPDK 使用了巨页内存(Hugepages)。巨页通常大小为 2MB 或 1GB,相比普通 4KB 小页,其连续性更高,有效减少了 TLB(Translation Lookaside Buffer)未命中带来的开销。mbuf,即 DPDK 用于存储单个数据包的内存结构,通常分配在巨页中。mbuf 不仅存储数据包内容,还包含数据长度、端口信息、时间戳等元数据,并支持链式结构,便于处理大数据包或分片数据包。这种设计保证了数据访问的局部性和连续性,为高性能处理提供了基础。
DPDK 的多核优化也是其性能的重要来源。它允许将不同的网卡队列绑定到不同的 CPU 核心,实现负载均衡和并行处理。每个核心独立轮询自己的 RX 队列并处理数据包,核心之间可以通过高性能环形队列(ring)交换数据。环形队列是一种固定大小的循环缓冲区,通过缓存行对齐和原子操作保证多线程安全。它支持单生产者/多消费者或多生产者/多消费者模式,使数据包在核心间传递时既高效又安全。结合批量处理策略,即一次读取和发送多个数据包,DPDK 可以进一步减少函数调用和缓存未命中的开销,从而提升吞吐量和 CPU 利用率。
内存管理方面,DPDK 通过 mempool 管理 mbuf。mempool 在初始化时一次性分配固定数量的 mbuf,并维护空闲队列以便快速分配和回收。这种方式避免了传统动态内存分配可能带来的性能波动,同时保证了内存访问的局部性,为数据包处理提供稳定的基础。
整体来看,DPDK 的工作原理是多个优化机制的组合:通过用户态轮询和 DMA 直接访问网卡,消除内核干预;通过巨页内存和高效的数据结构减少内存访问延迟;通过多核分工、环形队列和批量处理实现高吞吐和并行处理。这些设计共同实现了用户态高速数据包处理,使 DPDK 在 NFV(网络功能虚拟化)、高性能路由、负载均衡器、防火墙以及金融高频交易等对延迟敏感的场景中广泛应用。
4.2 DPDK的数据流处理流程
4.2.1 环境初始化
DPDK 应用启动时,首先会调用 EAL(Environment Abstraction Layer) 进行初始化。EAL 的作用是抽象操作系统环境,为用户态高性能数据包处理提供统一接口。初始化过程中,应用会绑定 CPU 核心,设置核心亲和性,分配巨页内存,并初始化 NUMA 节点配置。巨页内存为 mbuf 的存储提供连续、低延迟的内存区域,而核心绑定保证每个 CPU 核心固定处理特定队列,从而减少缓存抖动和跨核心访问开销。通过这些操作,DPDK 为后续高速数据包处理打下了基础。
4.2.2 网卡和队列初始化
完成环境初始化后,应用会初始化网卡驱动。DPDK 使用 Poll Mode Driver(PMD) 与网卡直接通信,而不依赖操作系统内核网络栈。在初始化阶段,应用会为每个网卡端口分配接收队列(RX Queue)和发送队列(TX Queue),并为每个队列创建 mbuf 内存池(mempool),用于存储接收或待发送的数据包。每个队列通常绑定到一个 CPU 核心,确保队列数据局部性和多核并行处理能力。
4.2.3 数据包接收
数据包到达网卡时,网卡通过 DMA 将数据直接写入 RX 队列对应的 mbuf。CPU 核心通过 PMD 持续轮询 RX 队列,检测新数据包是否到达。当核心发现 mbuf 中存在数据时,它会立即读取数据包内容,同时获取元数据(如端口号、长度、时间戳等)。这种轮询模式消除了中断触发和内核态切换,保证了数据包接收的低延迟和稳定吞吐量。
4.2.4 数据包处理
读取数据包后,CPU 核心在用户态直接对数据包进行处理。处理逻辑可以非常灵活,包括报文解析、过滤、修改、负载均衡、转发或统计等操作。由于数据包已经位于用户态内存中,应用无需通过内核复制或系统调用即可访问数据,这就是零拷贝机制。DPDK 的 mbuf 结构支持链式数据包,便于处理分片或大型数据包,同时支持批量操作,通过一次处理多个 mbuf 进一步提高 CPU 利用率。
4.2.5 数据包发送
处理完成后,数据包被放入 TX 队列等待发送。CPU 核心通过 PMD 将数据包从 mbuf 队列发送到网卡,网卡再通过 DMA 将数据发送到网络。DPDK 支持批量发送,这不仅减少函数调用次数,还提升了缓存命中率,从而进一步提高吞吐量。发送完成后,mbuf 会被回收到 mempool,供后续数据包重用,保证内存管理高效而稳定。
4.2.6 核心间协作
在多核处理场景下,CPU 核心之间可能需要交换数据包。例如,一个核心接收数据包后,需要将数据分发给另一个核心进行处理或转发。DPDK 提供高性能 环形队列(ring) 来完成这一任务。环形队列是固定大小的循环缓冲区,支持多生产者/多消费者模式,通过缓存行对齐和原子操作保证高效和线程安全。核心可以批量写入或读取数据包,实现多核间高效协作。
4.2.7 循环执行
DPDK 的数据流处理是一个持续循环的过程。每个 CPU 核心不断轮询 RX 队列接收数据包,处理后放入 TX 队列发送,同时与其他核心通过环形队列协作。批量处理和零拷贝机制贯穿整个循环,确保每个核心在处理数据时最大限度地利用 CPU 和内存带宽。整个流程的设计使得 DPDK 能够在高流量场景下保持稳定低延迟,同时提供百万级甚至千万级每秒的数据包处理能力。
总的来说,DPDK 的数据流处理流程可以概括为:初始化环境 → 初始化网卡与队列 → 接收数据包 → 用户态处理 → 发送数据包 → 核心间协作 → 循环执行。每一个环节都经过精心设计,确保用户态高速处理、内存访问局部性、多核并行和批量优化,实现了传统网络栈难以达到的吞吐和低延迟性能。