一.list的介绍和使用
1.1 list的介绍
1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。
2. list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向 其前一个元素和后一个元素。
3. list与forward_list非常相似:最主要的不同在于forward_list是单链表,只能朝前迭代,已让其更简单高 效。
4. 与其他的序列式容器相比(array,vector,deque),list通常在任意位置进行插入、移除元素的执行效率更好。
5. 与其他序列式容器相比,list和forward_list最大的缺陷是不支持任意位置的随机访问,比如:要访问list的第6个元素,必须从已知的位置(比如头部或者尾部)迭代到该位置,在这段位置上迭代需要线性的时间
开销;list还需要一些额外的空间,以保存每个节点的相关联信息(对于存储类型较小元素的大list来说这可能是一个重要的因素
1.2 list的重要接口
构造函数

迭代器
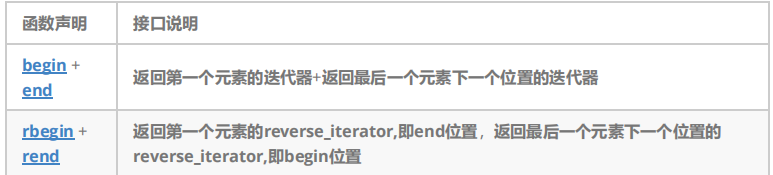
增删
其他函数



1.3 迭代器失效
前面我们知道vector为什么会迭代器失效,是因为扩容,而扩容是干嘛就是开一块新空间,然后把老空间的内容搬到新空间内容上面,但是迭代器指向的是老空间,因此会触发迭代器失效,关于删除它是可能会影响到迭代器因此这两类函数都需要注意迭代器问题。
但是链表会存在这种问题吗?
实际上,链表的物理存储空间是分散的,每个节点都拥有独立的迭代器。因此,在添加元素时,链表只需新增一个节点(即新增一个迭代器),不会导致现有迭代器失效。然而,删除操作确实会引发迭代器失效问题,但仅限于被删除节点的迭代器。由于每个节点都对应特定的迭代器,删除操作不会影响其他节点的迭代器。关键注意事项是:一旦节点被删除,其对应的迭代器就不可再使用。
二.析构和构造函数
cpp
template<class T>
class Node//节点属性
{
public:
Node(const T& data = T())
:_data(data)
,_next(nullptr)
,_prev(nullptr)
{}
public:
T _data;//节点的数据
Node<T>* _next;//下一个节点
Node<T>* _prev;//上一个节点
};首先这部分是节点的信息
cpp
template<class T>
class List
{
public:
List()//无参构造
:_head(new Node)
,_sz(0)
{
//首尾相连,符合双链表的形态
_head->_next = _head;
_head->_prev = _head;
}
List(const List<T>& lt)
{
//首尾相连,符合双链表的形态
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
for (auto& e : lt)
{
push_back(e);
}
}
~List()
{
clear();//清除
delete _head;
_head = nullptr;
_sz = 0;
}
private:
Node* _head;//哨兵位头节点
size_t _sz;//统计链表上节点的个数
};关于构造函数我带来的首先是无参构造和拷贝构造。
cpp
List()//无参构造
:_head(new Node)
,_sz(0)
{
//首尾相连,符合双链表的形态
_head->_next = _head;
_head->_prev = _head;
}先说说无参构造需要注意什么吧,首先无参构造应该先对List的成员对象进行初始化,首先我们知道List它的链表属于的是带头双向循环列表,而这个头节点我们一般又叫它哨兵位,因此我们需要先开一个空间给头节点即可!
然后第二步就是实现双向循环(头尾互连)
cpp
List(const List<T>& lt)
{
//首尾相连,符合双链表的形态
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
for (auto& e : lt)
{
push_back(e);
}
}然后讲的是拷贝构造,首先一样是先创建哨兵位,然后是头尾互连,然后再把数据一个个尾插到该链表即可!
cpp
~List()
{
clear();//清除
delete _head;
_head = nullptr;
_sz = 0;
}最后是这部分代码,首先先清除(即把哨兵位以外的节点都析构)然后我们只需要在处理哨兵位节点即可!
三.增删
cpp
void push_back(const T& data = T())
{
Node* newNode = new Node(data);//创建一个节点
Node* tailNode = _head->_prev;
//构建新节点和尾节点的链接
newNode->_prev = tailNode;
tailNode->_next = newNode;
//构建新节点和头节点的链接
newNode->_next = _head;
_head->_prev = newNode;
_sz++;
}
void pop_back()
{
assert(!empty());//不能为空
Node* tailNode = _head->_prev;//尾节点
Node* tailPrevNode = tailNode->_prev;//尾节点的上一个节点
//构建尾节点的上一个节点和头节点的链接
tailPrevNode->_next = _head;
_head->_prev = tailPrevNode;
delete tailNode;//删除尾节点
_sz--;
}
void push_front(const T& data = T())
{
Node* newNode = new Node(data);
Node* firstNode = _head->_next;//第一个节点
//构建第一个节点和新节点的链接
newNode->_next = firstNode;
firstNode->_prev = newNode;
//构建新节点和头节点的链接
_head->_next = newNode;
newNode->_prev = _head;
_sz++;
}
void pop_front()
{
assert(!empty());//不能为空
Node* firstNode = _head->_next;
Node* secondNode = firstNode->_next;//第二个节点
//构建第二个节点和头节点的关系
secondNode->_prev = _head;
_head->_next = secondNode;
_sz--;
delete firstNode;
}
iterator insert(iterator pos, const T& data = T())
{
Node* cur = pos._node;//要插入节点的位置
Node* prev = cur->_prev;//要插入节点的上一个位置
Node* newNode = new Node(data);
//构建新节点和要插入节点的位置链接
newNode->_next = cur;
cur->_prev = newNode;
//构建新节点和要插入节点的上一个位置链接
newNode->_prev = prev;
prev->_next = newNode;
_sz++;
return iterator(newNode);//返回插入节点的迭代器
}
iterator erase(iterator pos)
{
assert(!empty());//不能为空
assert(pos != end());//不能删哨兵位节点
Node* cur = pos._node;//要删除节点的位置
Node* next = cur->_next;//要删除节点的下一个位置
Node* prev = cur->_prev;//要删除节点的上一个位置
//构建下一个位置和上一个位置的链接
prev->_next = next;
next->_prev = prev;
delete cur;
_sz--;
return iterator(next);//返回删除节点的下一个位置
}
cpp
void push_back(const T& data = T())
{
Node* newNode = new Node(data);//创建一个节点
Node* tailNode = _head->_prev;
//构建新节点和尾节点的链接
newNode->_prev = tailNode;
tailNode->_next = newNode;
//构建新节点和头节点的链接
newNode->_next = _head;
_head->_prev = newNode;
_sz++;
}首先我们讲的是为尾插,关于尾插其实很简单, 就是创建一个节点,然后构建该节点和上一个节点和尾节点的关系即可!
其实我要讲的是关于大家认知这部分,就是当如果链表为空链表,那么该节点的上一个节点和下一个节点都是哨兵位节点,然后上面的两个链接其实只有一个是有效的,因为我当初就是关于这部分有所思考,因此我想要和大家分析的是这个方面。
cpp
void push_front(const T& data = T())
{
Node* newNode = new Node(data);
Node* firstNode = _head->_next;//第一个节点
//构建第一个节点和新节点的链接
newNode->_next = firstNode;
firstNode->_prev = newNode;
//构建新节点和头节点的链接
_head->_next = newNode;
newNode->_prev = _head;
_sz++;
}然后带来的是头插,其实关于这部分代码其实和尾插难度其实差不多,关于增删这部分都是对双链表的了解,因此再做增删这部分你应该先对双链表有理解,然后在做增删这部分就可以加深你对带头双向链表的认识!
cpp
void pop_back()
{
assert(!empty());//不能为空
Node* tailNode = _head->_prev;//尾节点
Node* tailPrevNode = tailNode->_prev;//尾节点的上一个节点
//构建尾节点的上一个节点和头节点的链接
tailPrevNode->_next = _head;
_head->_prev = tailPrevNode;
delete tailNode;//删除尾节点
_sz--;
}
void pop_front()
{
assert(!empty());//不能为空
Node* firstNode = _head->_next;
Node* secondNode = firstNode->_next;//第二个节点
//构建第二个节点和头节点的关系
secondNode->_prev = _head;
_head->_next = secondNode;
_sz--;
delete firstNode;
}然后关于删的这部分,我就不和大家讲解了,大家只要搞懂了增肯定就能理解删了,要是不会私信我,我也可以帮忙解决!
cpp
iterator insert(iterator pos, const T& data = T())
{
Node* cur = pos._node;//要插入节点的位置
Node* prev = cur->_prev;//要插入节点的上一个位置
Node* newNode = new Node(data);
//构建新节点和要插入节点的位置链接
newNode->_next = cur;
cur->_prev = newNode;
//构建新节点和要插入节点的上一个位置链接
newNode->_prev = prev;
prev->_next = newNode;
_sz++;
return iterator(newNode);//返回插入节点的迭代器
}关于insert我主要讲的就只有一点,就是为什么这个不需要判断是否"越界",因为在list中就没有越界这个概念,越界的概念是出现在连续数据的容器当中的。然后就是insert获取的迭代器是从begin和end得到的,而这个只可能获得普通节点和哨兵位节点!
cpp
iterator erase(iterator pos)
{
assert(!empty());//不能为空
assert(pos != end());//不能删哨兵位节点
Node* cur = pos._node;//要删除节点的位置
Node* next = cur->_next;//要删除节点的下一个位置
Node* prev = cur->_prev;//要删除节点的上一个位置
//构建下一个位置和上一个位置的链接
prev->_next = next;
next->_prev = prev;
delete cur;
_sz--;
return iterator(next);//返回删除节点的下一个位置
}在insert我们讲到了迭代器的获取是从begin和end得到的,获得的是普通节点和哨兵位节点。然后关于erase我也只说一点就是哨兵位节点只能被析构函数释放,其他的都不能对其进行释放。
四.其余函数
cpp
bool empty()const//判断链表是否为空
{
return _sz == 0;
}
size_t size()const
{
return _sz;
}
void clear()//清楚链表上的所有节点
{
Node* cur = _head->_next;
while (cur != _head)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
//首尾相连,符合双链表的形态
_head->_next = _head;
_head->_prev = _head;
_sz = 0;
}
void swap(List<T>& lt)
{
if (< == this)//比的是地址避免自赋
return;
std::swap(_head, lt._head);
std::swap(_sz, lt._sz);
}
List<T>& operator=(List<T> lt)
{
swap(lt);
return *this;
}
cpp
void clear()//清楚链表上的所有节点
{
Node* cur = _head->_next;
while (cur != _head)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
//首尾相连,符合双链表的形态
_head->_next = _head;
_head->_prev = _head;
_sz = 0;
}关于clear同样只要讲一点,就是clear它清除的是链表上的节点,因此它不能处理哨兵位,只要知道这个后面的就很简单了!
cpp
void swap(List<T>& lt)
{
if (< == this)//比的是地址避免自赋
return;
std::swap(_head, lt._head);
std::swap(_sz, lt._sz);
}关于swap,我用图帮助大家分析一下即可
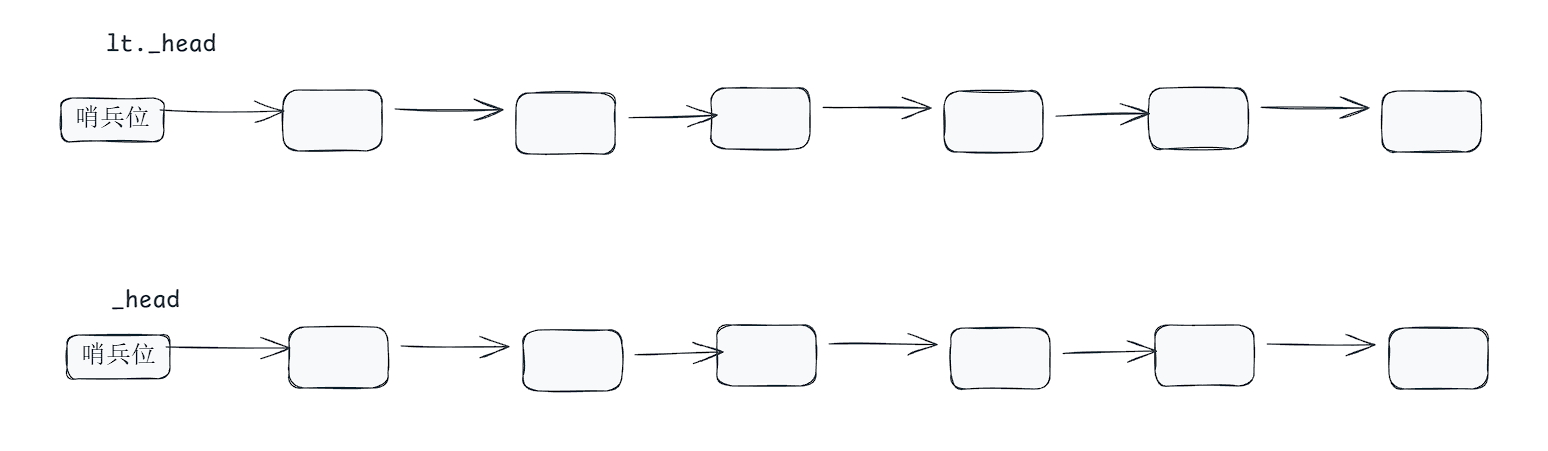
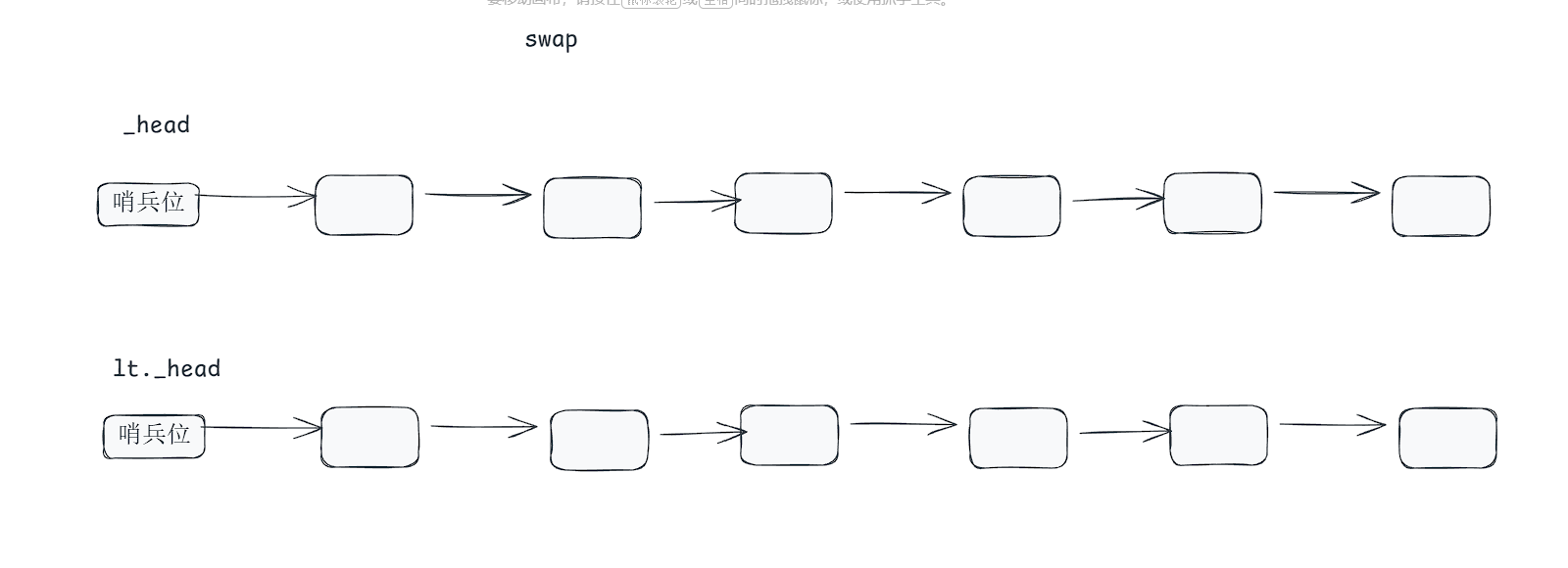
大家看到,我只需要交换哨兵位,我就能看到剩余的节点,因此交换只需要交换哨兵位即可!
cpp
List<T>& operator=(List<T> lt)
{
swap(lt);
return *this;
}我重点要讲的是这个,为什么呢?
你在第一眼看的时候,可能你会觉得哪里不对劲,就是你这个operator是不是只能处理非const对象,但是这个其实是可以处理const对象的。
首先我lt是传值调用,而传值调用是会调用拷贝构造,而刚好拷贝构造可以处理const对象,然通过拷贝构造就创造了一个新的非const对象,然后就可以进行交换了!
cpp
const对象 lst1(只读,不可修改)
↓ (赋值运算符传值调用,触发拷贝构造)
拷贝构造(参数const List<T>&)→ 合法接收lst1
↓ (深拷贝生成新对象)
非const临时对象 lt(可修改,swap的"合法操作对象")
↓ (调用swap(lt))
swap交换lst2和lt的_head/_sz → 完成赋值关于这部分内容就到这里,后面带来的是正向迭代器和反向迭代器,关于今天讲的内容其实部分内容只要明白了带头双向链表的特性就能解决,难点其实就是在理解这个operator=上面,关于这部分一定要理解,我们要变强就要攻克一个一个的难点!