首先,拍快照.确保Hadoop和zookeeper已经启动成功!!!!
start-all.sh --启动Hadoop
zkServer.sh start --启动zookeeper
Jps查看,若出现
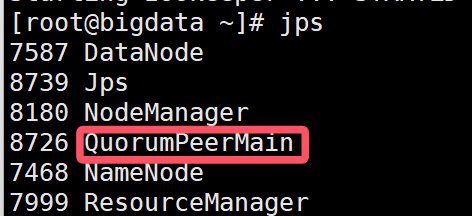
在启动zookeeper后,输入jps,若没有出现Quorum Peer Main,而是出现already running
则需要先停止zookeeper启动,再重新启动
先zkServer.sh stop
再zkServer.sh start
开始实验:
1.切换到install目录
cd /opt/install
2.上传spark安装包

3.解压文件
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C ../soft

4.切换到soft目录,改文件名
cd /opt/soft
mv spark-3.1.2-bin-hadoop3.2 /spark312


- 切换当前工作目录到/spark312
把/spark312这个文件夹移动到/opt/soft/目录下
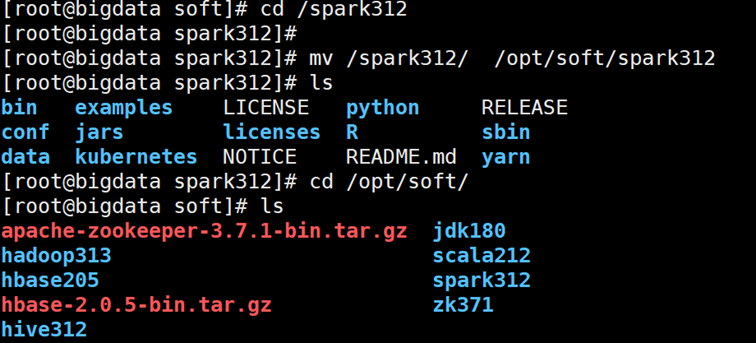
6.进入当前目录下spark312文件夹里的conf子目录
cd ./spark312/conf
7.复制spark-env.sh.template模板文件,生成实际生效的spark-env.sh配置文件(用于设置 Spark 环境变量)。
cp spark-env.sh.template spark-env.sh
8.复制workers.template模板文件,生成workers配置文件
cp workers.template workers

9. 开系统全局环境变量配置文件
vi /etc/profile
添加以下内容:

让刚修改的/etc/profile 配置立即生效(无需重启终端)
source /etc/profile
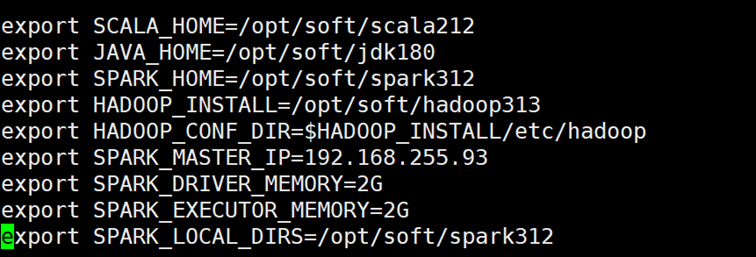
vi ./spark-env.sh
添加以下内容:
export SCALA_HOME=/opt/soft/scala212
export JAVA_HOME=/opt/soft/jdk180
export SPARK_HOME=/opt/soft/spark312
export HADOOP_INSTALL=/opt/soft/hadoop313
export HADOOP_CONF_DIR=$HADOOP_INSTALL/etc/hadoop
export SPARK_MASTER_IP=192.168.119.142
export SPARK_DRIVER_MEMORY=2G
export SPARK_EXECUTOR_MEMORY=2G
export SPARK_LOCAL_DIRS=/opt/soft/spark312
再次执行source /etc/profile
11. 测试
推出目录
cd ..
进去bin 目录
cd bin/
进行测试
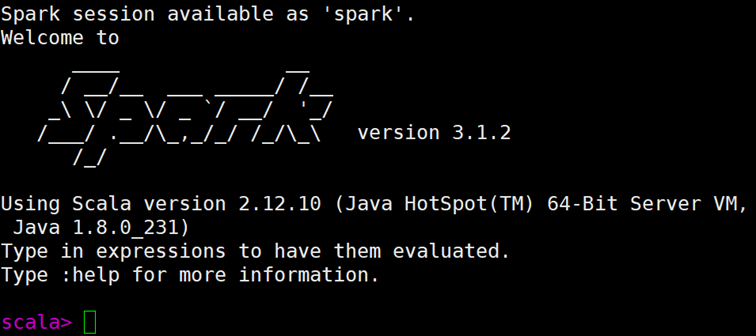
./spark-shell
出现以下内容则成功