U-Net 图像分割算法:从零开始的完全指南
一篇写给小白的深度学习图像分割入门文章
📚 目录
- 引言:为什么需要图像分割
- [什么是 U-Net](#什么是 U-Net)
- [U-Net 的诞生背景](#U-Net 的诞生背景)
- [U-Net 架构详解](#U-Net 架构详解)
- 核心概念深入理解
- 代码实现示例
- 实际应用场景
- 优势与局限
- 总结与展望
引言:为什么需要图像分割
想象一下,你是一位医生,需要从 CT 扫描图像中精确识别出肿瘤的位置和形状。或者你是自动驾驶工程师,需要让汽车"看懂"道路上的每一个物体------行人、车辆、交通标志。
这些任务有一个共同点:不仅要识别图像中有什么,还要知道它们在哪里,是什么形状。
这就是**图像分割(Image Segmentation)**要解决的问题。
图像分割 vs 图像分类
让我们用一个简单的类比来��解:
-
图像分类:这是一张猫的照片吗?(回答:是/否)
-
目标检测:照片里哪里有猫?(回答:在矩形框内)
-
图像分割:照片中每一个像素是不是猫的一部分?(回答:像素级别的精确标注)
图像分类: 目标检测: 图像分割:
🖼️ 📦🖼️ 🎨🖼️
"有猫" "猫在这个框里" "精确描绘猫的轮廓"
什么是 U-Net
U-Net 是一种专门为图��分割设计的卷积神经网络架构,于 2015 年由德国弗莱堡大学的 Olaf Ronneberger、Philipp Fischer 和 Thomas Brox 提出。
名字的由来
U-Net 得名于其独特的**"U"型网络结构**:
输入 输出
↓ ↑
[图像] → 编码器(下采样) → [压缩特征] → 解码器(上采样) → [分割图]
↓ ↑
└────��─────── 跳跃连接 ─────────────────┘从侧面看,这个网络结构就像字母"U"。
核心思想:一句话概括
先压缩提取特征,再还原恢复细节,同时用跳跃连接保留空间信息。
U-Net 的诞生背景
医学图像分割的挑战
2015 年之前,医学图像分割面临几个关键问题:
- 数据稀缺:医学标注数据获取困难且昂贵
- 精度要求高:需要像素级别的精确分割
- 边界模糊:细胞、器官的边界往往不清晰
- 计算效率:需要能快速处理大量图像
U-Net 的突破
U-Net 的论文标题是:"U-Net: Convolutional Networks for Biomedical Image Segmentation"
它在 ISBI(国际生物医学成像研讨会)的细胞分割挑战赛中取得了压倒性优势,仅用30 张训练图像就超越了之前的所有方法。
这在深度学习时代是一个惊人的成就------要知道,深度学习通常被认为是"数据饥渴"的。
U-Net 架构详解
整体结构:U 型对称设计
U-Net 由三个主要部分组成:
收缩路径 扩张路径
(Contracting Path) (Expanding Path)
编码器 解码器
↓ ↑
输入 (572×572×1) 输出 (388×388×2)
↓ ↑
[Conv+ReLU] [UpConv+Concat]
↓ → ↑
[MaxPool] 跳跃连接 [Conv+ReLU]
↓ → ↑
[Conv+ReLU] [UpConv+Concat]
↓ → ↑
[...] [...]架构可视化图
下图展示了 U-Net 的完整架构,包括编码器、解码器、瓶颈层和跳跃连接的详细结构:
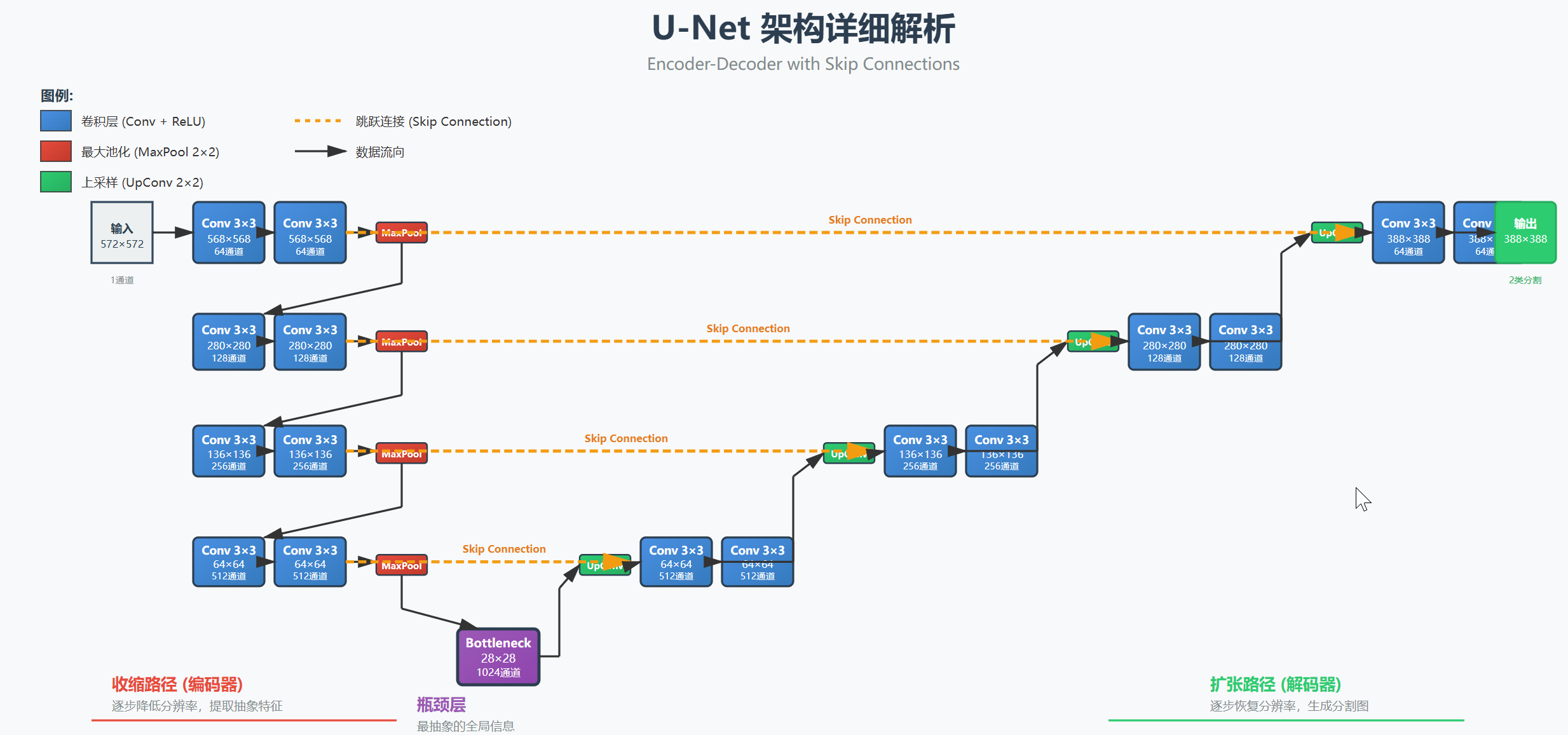
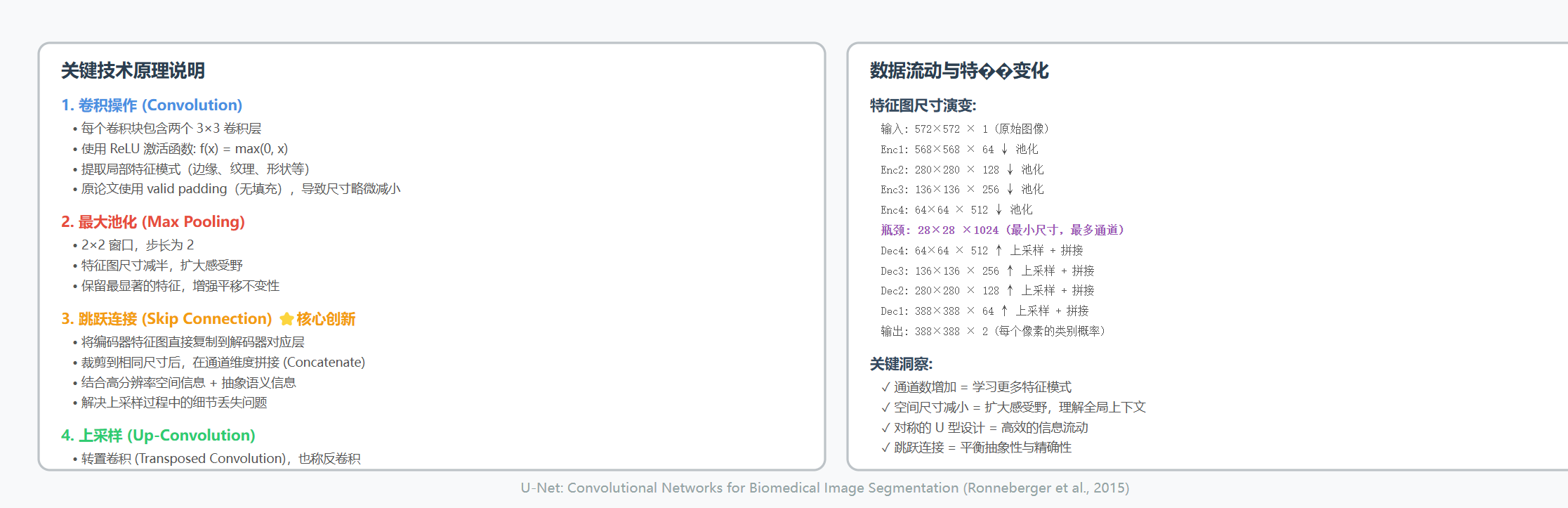
图1:U-Net 完整架构图 - 展示了从输入到输出的完整数据流,包括各层的尺寸和通道数变化
1. 收缩路径(左侧,编码器)
作用:提取图像的抽象特征
过程:
- 重复执行:
3×3 卷积 → ReLU 激活 → 3×3 卷积 → ReLU 激活 → 2×2 最大池化 - 每次池化后,特征图尺寸减半
- 每次池化后,通道数翻倍(64 → 128 → 256 → 512 → 1024)
形象理解:
就像站在山顶看风景,站得越高(越深的网络层),看到的范围越大(感受野越大),但细节越模糊(分辨率越低)。
层级 尺寸 特征
输入 572×572×1 原始图像
层1 568×568×64 低级特征(边缘、纹理)
↓ 池化
层2 280×280×128 中级特征(形状、部分)
↓ 池化
层3 136×136×256 高级特征(对象、语义)
↓ 池化
层4 64×64×512 抽象特征
↓ 池化
瓶颈 28×28×1024 最抽象的全局信息2. 瓶颈层(底部)
位置:U 型结构的最底部
特点:
- 分辨率最低(尺寸最小)
- 通道数最多(特征最丰富)
- 包含最抽象的全局语义信息
3. 扩张路径(右侧,解码器)
作用:将抽象特征还原为高分辨率的分割图
过程:
- 重复执行:
2×2 上采样 → 连接对应编码器层 → 3×3 卷积 → ReLU 激活 - 每次上采样后,特征图尺寸翻倍
- 每次上采样后,通道数减半
形象理解:
就像从山顶走下来,逐渐看清地面的细节,但需要有人告诉你之前在山脚看到的具体信息(跳跃连接)。
层级 上采样 + 连接 卷积后
瓶颈 28×28×1024 ↓
UpConv
56×56×512 + 跳跃连接 → 56×56×512
UpConv
104×104×256 + 跳跃连接 → 104×104×256
UpConv
200×200×128 + 跳跃连接 → 200×200×128
UpConv
392×392×64 + 跳跃连接 → 388×388×64
↓
1×1 卷积
↓
输出 388×388×2 (每个像素的分类)4. 跳跃连接(Skip Connections)
这是 U-Net 最关键的创新!
问题:为什么需要跳跃连接?
想象一下这个过程:
- 编码器把图像从 572×572 压缩到 28×28
- 解码器再从 28×28 恢复到 388×388
在这个过程中,大量的空间细节信息已经丢失了!就像把一张高清照片压缩成缩略图,再放大回去,细节无法完美恢复。
解决方案:跳跃连接
编码器层3 (136×136×256) ──复制并裁剪──┐
├→ 连接(Concatenate) → 解码器层3
解码器上采样 (136×136×256) ───────────┘操��步骤:
- 从编码器对应层复制特征图
- 将其裁剪到与解码器层相同的尺寸
- 在通道维度上连接(Concatenate)
效果:
- 解码器不仅能获得抽象的语义信息(从下层传来)
- 还能直接获得高分辨率的空间细节(从编码器跳跃连接)
形象比喻:
就像画家作画:先用大笔勾勒整体轮廓(编码器),再用小笔添加细节(解码器),但同时要参考原始照片的细节(跳跃连接)。
核心概念深入理解
核心操作可视化
下图详细展示了 U-Net 中四个核心操作的工作原理:

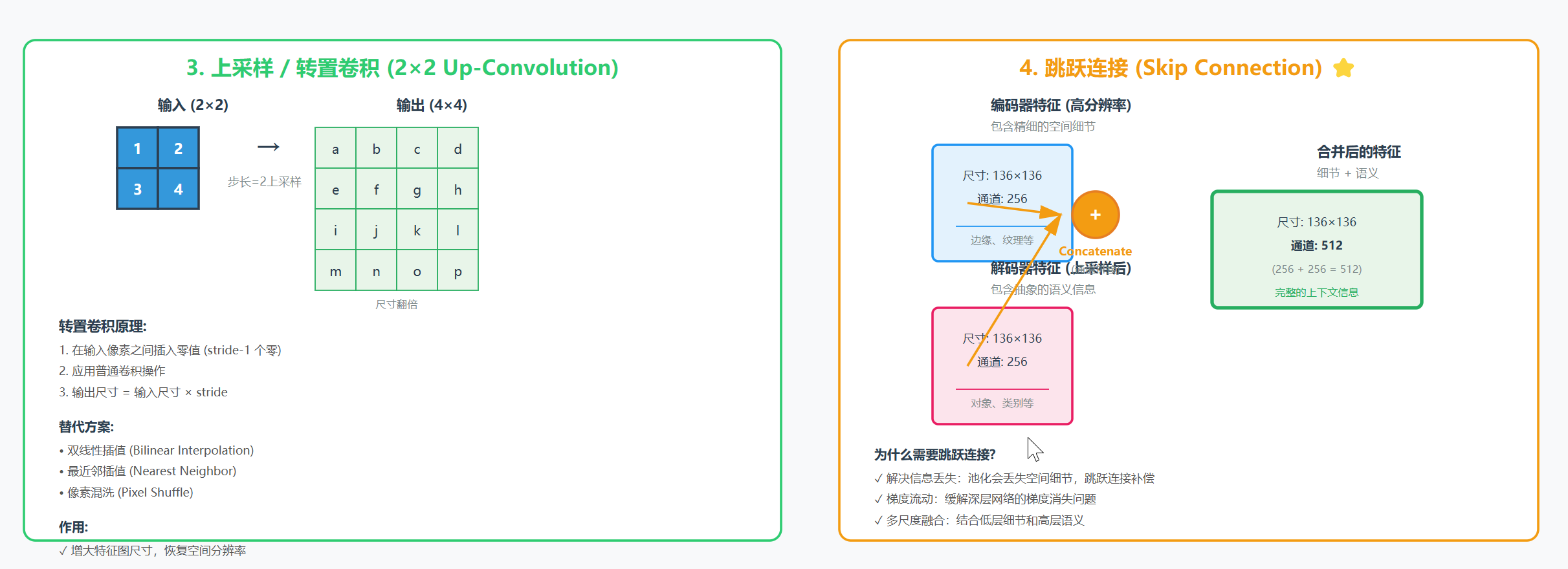
图2:U-Net 核心操作详解 - 包括卷积、池化、上采样和跳跃连接的详细计算过程
1. 感受野(Receptive Field)
定义:网络中某一层的一个神经元能"看到"的输入图像区域。
输入层 第1层卷积 第2层卷�� 第3层卷积
■■■ ■ · ·
■■■ → ■■■ → ■■■ → ■■■
■■■ ■ · ·
3×3像素 3×3→5×5 5×5→7×7 7×7→更大在 U-Net 中:
- 通过多次池化,网络能够看到越来越大的区域
- 这对于理解上下文信息至关重要
2. 特征图通道数的变化
为什么编码器通道数越来越多?
64 → 128 → 256 → 512 → 1024
因为:
- 分辨率降低后,空间信息减少
- 需要更多通道来存储丰富的语义信息
- 就像从"详细地图"变成"多维度抽象概念"3. 上采样(Upsampling)方法
原始 U-Net 使用:转置卷积(Transposed Convolution)
输入 2×2 输出 4×4
[1 2] [1 0 2 0]
[3 4] → [0 0 0 0]
[3 0 4 0]
[0 0 0 0]现代变体也使用:
- 双线性插值(Bilinear Interpolation)
- 最近邻插值(Nearest Neighbor)
4. 数据增强(Data Augmentation)
U-Net 论文的一个重要贡献是弹性形变(Elastic Deformation):
原始图像 旋转 翻转 弹性形变
┌─┐ ┌─┐ ┌─┐ ┌─┐
│○│ → │○│ → │○│ → │◐│
└─┘ └─┘ └─┘ └─┘
(扭曲)这对于医学图��特别有效,因为生物组织本身就有形变。
代码实现示例
PyTorch 实现(简化版)
python
import torch
import torch.nn as nn
class UNet(nn.Module):
def __init__(self, in_channels=1, out_channels=2):
super(UNet, self).__init__()
# 编码器(收缩路径)
self.enc1 = self.conv_block(in_channels, 64)
self.enc2 = self.conv_block(64, 128)
self.enc3 = self.conv_block(128, 256)
self.enc4 = self.conv_block(256, 512)
# 瓶颈层
self.bottleneck = self.conv_block(512, 1024)
# 解码器(扩张路径)
self.upconv4 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2)
self.dec4 = self.conv_block(1024, 512) # 1024 = 512(upconv) + 512(skip)
self.upconv3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)
self.dec3 = self.conv_block(512, 256)
self.upconv2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.dec2 = self.conv_block(256, 128)
self.upconv1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec1 = self.conv_block(128, 64)
# 最终输出层
self.out = nn.Conv2d(64, out_channels, kernel_size=1)
# 池化层
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def conv_block(self, in_channels, out_channels):
"""双层卷积块:Conv → ReLU → Conv → ReLU"""
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
# 编码器路径
enc1 = self.enc1(x) # 第1层
enc2 = self.enc2(self.pool(enc1)) # 第2层
enc3 = self.enc3(self.pool(enc2)) # 第3层
enc4 = self.enc4(self.pool(enc3)) # 第4层
# 瓶颈层
bottleneck = self.bottleneck(self.pool(enc4))
# 解码器路径 + 跳跃连接
dec4 = self.upconv4(bottleneck)
dec4 = torch.cat([dec4, enc4], dim=1) # 跳跃连接
dec4 = self.dec4(dec4)
dec3 = self.upconv3(dec4)
dec3 = torch.cat([dec3, enc3], dim=1) # 跳跃连接
dec3 = self.dec3(dec3)
dec2 = self.upconv2(dec3)
dec2 = torch.cat([dec2, enc2], dim=1) # 跳跃连接
dec2 = self.dec2(dec2)
dec1 = self.upconv1(dec2)
dec1 = torch.cat([dec1, enc1], dim=1) # 跳跃连接
dec1 = self.dec1(dec1)
# 输出
return self.out(dec1)
# 使用示例
model = UNet(in_channels=3, out_channels=2) # RGB输入,2类分割
x = torch.randn(1, 3, 256, 256) # 批量=1, 通道=3, 尺寸=256×256
output = model(x)
print(f"输入形状: {x.shape}")
print(f"输出形状: {output.shape}") # torch.Size([1, 2, 256, 256])训练代码示例
python
import torch.optim as optim
from torch.utils.data import DataLoader
# 损失函数:常用交叉熵或 Dice Loss
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# 训练循环
def train_one_epoch(model, dataloader, criterion, optimizer, device):
model.train()
total_loss = 0
for images, masks in dataloader:
images = images.to(device)
masks = masks.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, masks)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
# 训练
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
for epoch in range(100):
loss = train_one_epoch(model, train_loader, criterion, optimizer, device)
print(f'Epoch {epoch+1}/100, Loss: {loss:.4f}')TensorFlow/Keras 实现(简化版)
python
from tensorflow import keras
from tensorflow.keras import layers
def unet_model(input_size=(256, 256, 3), num_classes=2):
inputs = keras.Input(shape=input_size)
# 编码器
c1 = layers.Conv2D(64, 3, activation='relu', padding='same')(inputs)
c1 = layers.Conv2D(64, 3, activation='relu', padding='same')(c1)
p1 = layers.MaxPooling2D(2)(c1)
c2 = layers.Conv2D(128, 3, activation='relu', padding='same')(p1)
c2 = layers.Conv2D(128, 3, activation='relu', padding='same')(c2)
p2 = layers.MaxPooling2D(2)(c2)
c3 = layers.Conv2D(256, 3, activation='relu', padding='same')(p2)
c3 = layers.Conv2D(256, 3, activation='relu', padding='same')(c3)
p3 = layers.MaxPooling2D(2)(c3)
c4 = layers.Conv2D(512, 3, activation='relu', padding='same')(p3)
c4 = layers.Conv2D(512, 3, activation='relu', padding='same')(c4)
p4 = layers.MaxPooling2D(2)(c4)
# 瓶颈层
c5 = layers.Conv2D(1024, 3, activation='relu', padding='same')(p4)
c5 = layers.Conv2D(1024, 3, activation='relu', padding='same')(c5)
# 解码器
u6 = layers.Conv2DTranspose(512, 2, strides=2, padding='same')(c5)
u6 = layers.concatenate([u6, c4]) # 跳跃连接
c6 = layers.Conv2D(512, 3, activation='relu', padding='same')(u6)
c6 = layers.Conv2D(512, 3, activation='relu', padding='same')(c6)
u7 = layers.Conv2DTranspose(256, 2, strides=2, padding='same')(c6)
u7 = layers.concatenate([u7, c3])
c7 = layers.Conv2D(256, 3, activation='relu', padding='same')(u7)
c7 = layers.Conv2D(256, 3, activation='relu', padding='same')(c7)
u8 = layers.Conv2DTranspose(128, 2, strides=2, padding='same')(c7)
u8 = layers.concatenate([u8, c2])
c8 = layers.Conv2D(128, 3, activation='relu', padding='same')(u8)
c8 = layers.Conv2D(128, 3, activation='relu', padding='same')(c8)
u9 = layers.Conv2DTranspose(64, 2, strides=2, padding='same')(c8)
u9 = layers.concatenate([u9, c1])
c9 = layers.Conv2D(64, 3, activation='relu', padding='same')(u9)
c9 = layers.Conv2D(64, 3, activation='relu', padding='same')(c9)
# 输出层
outputs = layers.Conv2D(num_classes, 1, activation='softmax')(c9)
model = keras.Model(inputs=[inputs], outputs=[outputs])
return model
# 创建模型
model = unet_model(input_size=(256, 256, 3), num_classes=2)
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()实际应用场景
1. 医学图像分析
应用实例:
- 肿瘤检测:从 MRI 或 CT 扫描中分割出肿瘤区域
- 器官分割:自动识别肝脏、肾脏、心脏等器官
- 细胞分割:显微镜图像中的细胞边界检测
- 血管分割:视网膜图像中的血管网络识别
案例:
输入:脑部 MRI 扫描
处理:U-Net 模型
输出:精确标注的脑肿瘤区域
医生可以:
✓ 快速定位病变
✓ 准确测量肿瘤体积
✓ 制定精准治疗方案2. 自动驾驶
应用:道路场景理解
输入图像:前方道路视角
天空
─────────────
│ 🚗 │ 🚶 │
─────────────
道路
U-Net 输出(像素级分类):
- 蓝色区域:天空
- 灰色区域:道路
- 红色区域:车辆
- 绿色区域:行人
- 黄色区域:交通标志3. 卫星图像分析
应用:
- 土地利用分类
- 建筑物提取
- 农作物监测
- 森林砍伐检测
4. 工业质检
应用:产品表面缺陷检测
输入:工业零件图像
U-Net:识别缺陷区域(划痕、裂纹、污渍)
输出:缺陷掩码 + 质量评级5. 图像编辑与处理
应用:
- 人像抠图(背景分离)
- 图像修复
- 艺术风格迁移的辅助
- 视频背景替换
优势与局限
✅ 优势
1. 小数据集表现优异
传统深度学习:需要数万张图像
U-Net:几十到几百张即可训练出好模型
原因:数据增强 + 高效的架构设计2. 精确的边界定位
- 跳跃连接保留了空间细节
- 像素级分割精度高
3. 端到端训练
输入原始图像 → 直接输出分割结果
无需手动特征工程4. 灵活性强
- 可处理任意尺寸的输入(通过调整)
- 易于修改和扩展
- 可用于多类别分割
5. 训练速度快
- 相比全连接网络,参数量更少
- 可在单个 GPU 上训练
❌ 局限
1. 内存消耗大
问题:跳跃连接需要存储编码器的所有特征图
解决:使用 U-Net++ 等改进版本2. 小目标分割困难
- 经过多次池化,小目标信息可能丢失
- 改进:使用空洞卷积(Dilated Convolution)
3. 上下文信息有限
- 感受野受网络深度限制
- 改进:Attention U-Net 引入注意力机制
4. 计算成本高
- 对于高分辨率图像(如 4K),计算量巨大
- 改进:使用分块处理或轻量级网络
5. 类别不平衡敏感
问题:如果背景占 95%,前景只占 5%
现象:模型倾向于预测所有像素为背景
解决:使用 Focal Loss 或加权损失函数U-Net 变体与改进
1. U-Net++(嵌套 U-Net)
特点:在编码器和解码器之间增加密集的跳跃连接
效果:提升分割精度,特别是复杂边界2. Attention U-Net
特点:在跳跃连接处加入注意力机制
效果:自动关注重要区域,抑制无关信息3. Residual U-Net
特点:将残差块(ResNet)融入 U-Net
效果:训练更深的网络,提升性能4. 3D U-Net
特点:将 2D 卷积替换为 3D 卷积
应用:医学体数据(CT、MRI 体积)分割5. U-Net with Transformers
特点:用 Transformer 替换部分卷积层
代表:TransUNet, Swin-UNet
效果:捕获更长距离的依赖关系性能评估指标
1. Dice 系数(Dice Coefficient)
Dice = 2 × |A ∩ B| / (|A| + |B|)
其中:
A = 预测的分割区域
B = 真实标注区域
取值范围:[0, 1]
1 = 完美分割
0 = 完全不重合代码实现:
python
def dice_coefficient(pred, target):
smooth = 1e-5 # 避免除零
intersection = (pred * target).sum()
return (2. * intersection + smooth) / (pred.sum() + target.sum() + smooth)2. IoU(Intersection over Union)
IoU = |A ∩ B| / |A ∪ B|
取值范围:[0, 1]
通常 IoU > 0.5 被认为是良好的分割3. 像素准确率(Pixel Accuracy)
Accuracy = 正确分类的像素数 / 总像素数4. 精确率和召回率
Precision = TP / (TP + FP)
Recall = TP / (TP + FN)
其中:
TP = 正确预测为前景的像素
FP = 错误预测为前景的像素(实际是背景)
FN = 错误预测为背景的像素(实际是前景)实战技巧
1. 数据预处理
python
# 归一化
images = images / 255.0
# 标准化
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
images = (images - mean) / std
# 尺寸调整(建议使用 2 的幂次)
target_size = (256, 256) # 或 512×5122. 数据增强策略
python
import albumentations as A
transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.RandomRotate90(p=0.5),
A.ShiftScaleRotate(shift_limit=0.1, scale_limit=0.1, rotate_limit=45, p=0.5),
A.ElasticTransform(alpha=1, sigma=50, alpha_affine=50, p=0.3),
A.RandomBrightnessContrast(p=0.3),
])3. 损失函数选择
python
# 1. 交叉熵(适合类别均衡)
loss = nn.CrossEntropyLoss()
# 2. Dice Loss(适合类别不均衡)
def dice_loss(pred, target):
return 1 - dice_coefficient(pred, target)
# 3. 组合损失
def combined_loss(pred, target):
return 0.5 * nn.CrossEntropyLoss()(pred, target) + 0.5 * dice_loss(pred, target)4. 学习率调度
python
# 余弦退火
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=100)
# 在验证损失不下降时降低学习率
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=5)5. 模型集成
python
# 训练多个模型,预测时取平均
predictions = []
for model in models:
pred = model(image)
predictions.append(pred)
final_prediction = torch.mean(torch.stack(predictions), dim=0)学习资源推荐
📄 经典论文
- 原始论文 :U-Net: Convolutional Networks for Biomedical Image Segmentation
- 3D U-Net :3D U-Net: Learning Dense Volumetric Segmentation
- Attention U-Net :Attention U-Net: Learning Where to Look
💻 代码仓库
📚 教程与课程
🎮 实践项目
-
Kaggle 竞赛:
-
开源数据集:
总结与展望
核心要点回顾
-
U-Net 的本质
- 对称的 U 型编码器-解码器架构
- 跳跃连接是核心创新
- 专为小数据集图像分割设计
-
关键优势
- 少量数据即可训练
- 精确的像素级分割
- 快速训练与推理
-
适用场景
- 医学图像分析
- 自动驾驶场景理解
- 卫星图像处理
- 任何需要精确分割的任务
未来发展方向
1. 与 Transformer 融合
趋势:将视觉 Transformer 的全局建模能力与 U-Net 结合
代表:TransUNet, Swin-UNet, SegFormer2. 轻量化网络
目标:在移动设备和边缘计算上部署
方法:知识蒸馏、剪枝、量化
代表:MobileNet-UNet, EfficientNet-UNet3. 无监督/半监督学习
挑战:医学图像标注成本极高
方向:利用未标注数据,减少标注需求
方法:对比学习、自监督预训练4. 多模态融合
应用:结合 CT、MRI、PET 等多种影像
效果:更全面的诊断信息5. 可解释性增强
需求:医疗等领域需要可解释的 AI
方法:注意力可视化、特征归因分析结语
U-Net 虽然发表于 2015 年,但至今仍是图像分割领域的基石。它的设计哲学------简洁、高效、实用------为无数后续研究提供了灵感。
作为初学者,理解 U-Net 不仅能让你掌握一个强大的工具,更能帮你建立对深度学习网络设计的直觉:
- 如何平衡抽象和细节
- 如何设计有效的信息流
- 如何用有限的数据解决实际问题
希望这篇文章能帮助你开启图像分割的学习之旅!
附录:常见问题 FAQ
Q1: U-Net 能处理多大的图像?
A: 理论上无限制,但实际受 GPU 内存限制。常见做法:
- 小图像(<512×512):直接输入
- 大图像:分块处理(patch-based)或使用渐进式训练
Q2: U-Net 只能用于二分类分割吗?
A: 不是。修改最后一层输出通道数即可:
python
# 二分类:前景/背景
output = nn.Conv2d(64, 2, kernel_size=1)
# 多分类:如城市场景(道路、建筑、车辆等)
output = nn.Conv2d(64, num_classes, kernel_size=1)Q3: 训练 U-Net 需要多少数据?
A: 取决于任务复杂度:
- 简单任务(如细胞分割):30-100 张
- 复杂任务(如多器官分割):数百到数千张
- 建议:充分利用数据增强
Q4: 为什么我的模型预测全是背景?
A: 常见原因:
- 类别不平衡 → 使用加权损失或 Focal Loss
- 学习率过高 → 降低学习率
- 初始化不当 → 使用 He 初始化
Q5: U-Net 训练需要多久?
A:
- 数据量:100 张图像
- GPU:NVIDIA RTX 3090
- 训练时间:通常 1-3 小时
- 根据数据量和图像尺寸有所不同
Q6: 如何加速 U-Net 推理?
A:
- 使用混合精度(FP16)
- 模型剪枝和量化
- TensorRT 或 ONNX 优化
- 批处理多张图像
感谢阅读!如有问题,欢迎讨论交流。