在Linux系统启动的早期阶段,initrd.img(初始内存磁盘)扮演着关键角色。它作为一个临时的根文件系统,承载了加载真实根文件系统所需的一切驱动和工具。然而,当这个微型系统意外缺失关键命令时(如awk),整个安装或启动过程可能突然中断。本文将深入解析dracut------这一现代initrd构建工具的底层设计,并系统化地探讨如何在模块化框架中可靠地添加所需命令。
一、dracut的底层设计原理
dracut的设计哲学可以概括为"事件驱动的模块化 "和"层次化的初始化"。
1.1 事件驱动的模块化框架
与传统的静态initrd不同,dracut将初始化过程分解为一系列事件(Events)。每个事件对应启动过程中的一个特定阶段,例如:
cmdline:解析内核命令行参数pre-mount:挂载根文件系统之前mount:挂载根文件系统pre-pivot:切换到真实根文件系统之前
dracut模块通过钩子函数 (Hooks)响应这些事件。每个模块目录中的module-setup.sh脚本通过install()函数向initrd中注入文件,通过check()函数决定是否启用该模块,并通过钩子函数在特定事件中执行操作。
1.2 数字编号的层次化模块系统
观察dracut的模块目录结构,会发现清晰的层次设计:
00bash → 99squash (数字递增)这种设计具有明确的工程意图:
- 基础服务层(00-09) :如
00systemd、00bash,提供最基础的运行时环境 - 核心功能层(10-89) :如
90lvm、90crypt,处理存储、网络等核心功能 - 硬件适配层(90-99) :如
95zfcp、95nvmf,处理特定硬件或复杂场景
二、dracut模块管理原则
2.1 模块的自包含原则
每个dracut模块都应尽可能自包含,这是模块化设计的核心。在module-setup.sh中,模块需要:
- 声明依赖 :通过
depends()函数声明依赖的其他模块 - 明确安装 :通过
install()函数声明需要打包的所有文件 - 提供钩子 :通过钩子函数(如
installhook())定义执行逻辑
示例:lvm模块的部分实现
bash
# 在/usr/lib/dracut/modules.d/90lvm/module-setup.sh中
install() {
inst_multiple lvm dd vgscan vgchange
# 模块应包含其需要的所有命令
# 如果lvm操作需要awk,应在此添加
}2.2 依赖的最小化原则
dracut遵循"最小必要"原则,每个模块应仅包含其核心功能必需的文件。这通过两方面实现:
- 静态分析:dracut会分析二进制文件的库依赖
- 动态追踪 :通过
strace等工具追踪模块在测试环境中实际调用的命令
但是,当某个命令(如awk)被脚本通过$(command)间接调用时,这种检测可能失效,导致"幽灵依赖"问题。
2.3 配置的层次化覆盖原则
dracut的配置系统具有明确的优先级:
/etc/dracut.conf → /etc/dracut.conf.d/*.conf → 命令行参数这种设计允许:全局默认配置 → 发行版定制 → 产品特定配置 → 临时调整的多级控制,为不同层级的定制提供了清晰路径。
三、向initrd添加命令的工程实践
假设我们需要添加的命令xx来自已安装的软件包XX,以下是完整的技术决策框架。
3.1 方法选择:模块归属决策流程图
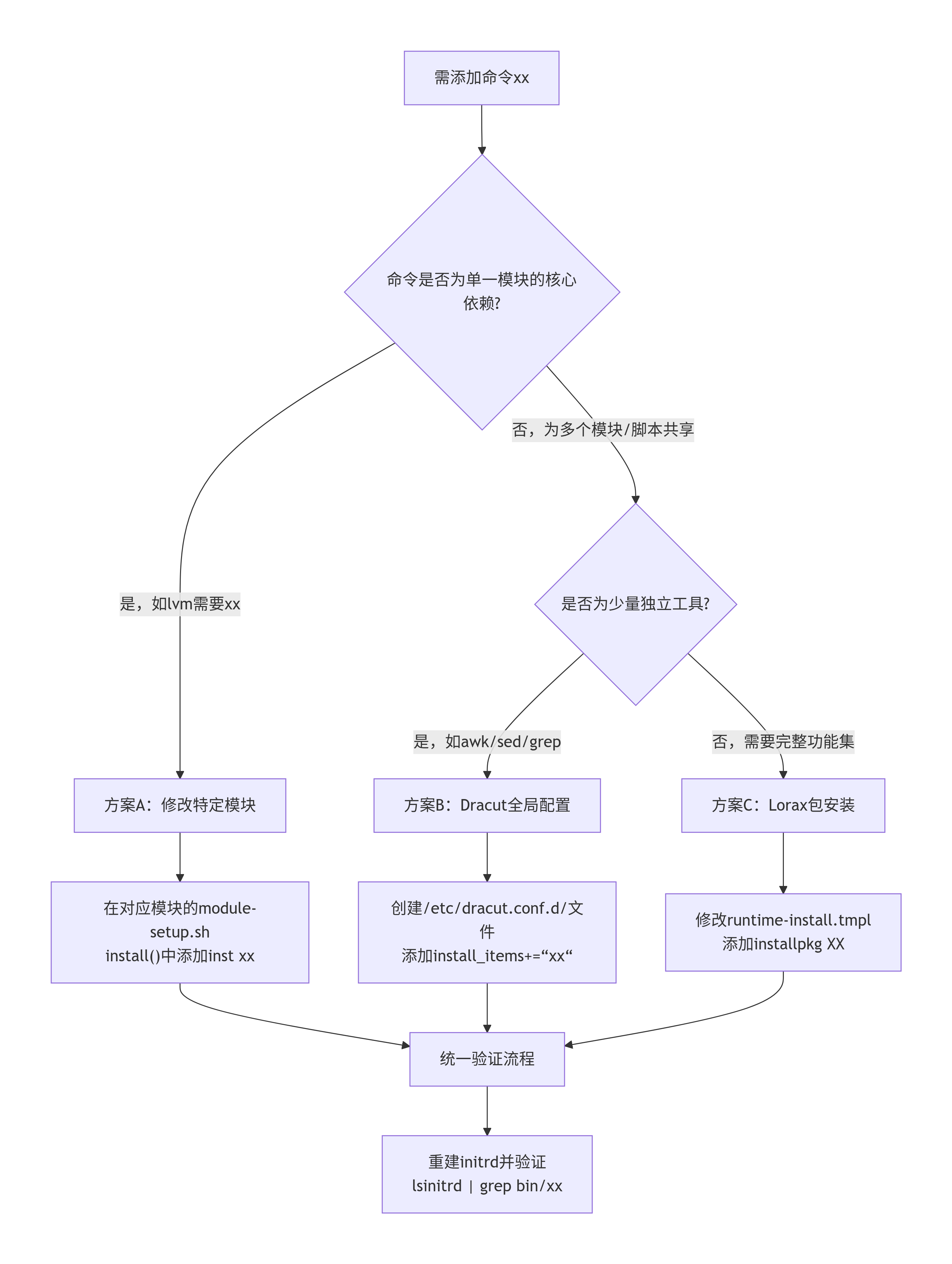
3.2 方案详解与实施
方案A:修改特定模块(精准定位)
当命令xx明确服务于某个dracut模块时,修改该模块是最符合架构的设计。
实施步骤:
-
定位模块 :确定使用
xx的模块,如90lvm -
修改安装函数 :
bash# 编辑 /usr/lib/dracut/modules.d/90lvm/module-setup.sh install() { # 原有内容... inst_multiple lvm vgchange pvdisplay # 新增命令xx inst /usr/bin/xx } -
验证修改:检查语法并确保模块仍能正常加载
适用场景:
- 命令是模块功能的核心组件
- 希望保持依赖关系的高度内聚
- 可以向模块的上游提交修改
方案B:Dracut全局配置(灵活集成)
对于awk这类共享工具,或产品特定的增强需求,全局配置是最佳选择。
实施步骤:
-
创建配置文件 :
bash# /etc/dracut.conf.d/99-product-specific.conf # 添加产品所需的额外命令 install_items+=" /usr/bin/xx /usr/bin/yy " -
层级化管理 :可以按功能创建多个配置文件
99-base-tools.conf # 基础工具如awk/sed 99-storage-extra.conf # 存储相关增强 99-debug-tools.conf # 调试工具 -
确保加载:在构建脚本中确保配置目录被正确包含
最佳实践:
- 为配置文件提供有意义的命名
- 在配置文件中添加注释说明添加原因
- 将配置文件纳入版本控制系统
方案C:Lorax包安装(基础保障)
当需要完整功能集或不确定具体需要哪些文件时。
实施步骤:
bash
# 在 lorax 模板文件中
# 例如:/usr/share/lorax/templates.d/99-custom/runtime-install.tmpl
installpkg XX
# 或更精确地
installpkg XX-minimal # 如果存在子包3.3 验证体系:确保可靠性
无论使用哪种方案,必须建立完整的验证链:
-
构建时验证:
bash# 检查命令是否被包含 lsinitrd /path/to/new-initrd.img | grep -E "bin/xx|bin/awk" # 完整文件列表对比 lsinitrd initrd-old.img > list-old.txt lsinitrd initrd-new.img > list-new.txt diff -u list-old.txt list-new.txt -
运行时验证:
bash# 解压initrd实际测试 mkdir test-initrd && cd test-initrd zcat ../initrd.img | cpio -idm chroot . /usr/bin/xx --version -
自动化集成:将验证步骤加入CI/CD流水线,确保每次构建都进行initrd完备性检查。
四、工程管理建议
4.1 建立initrd组件清单
维护一个产品级的initrd组件清单,明确:
- 必需基础工具 :如
awk、grep、sed - 模块依赖映射:每个模块明确声明其命令依赖
- 配置变更日志:所有对dracut配置的修改都应有记录
4.2 分层责任模型
建立清晰的责任划分:
- 模块开发者:确保模块自包含其核心依赖
- 集成工程师:通过配置添加产品特定需求
- 质量保证:验证initrd的完整性和功能性
4.3 问题诊断流程
当initrd出现命令缺失时,遵循系统化诊断路径:
- 重现问题:确认缺失的命令及触发场景
- 定位根源:检查是模块缺失、配置未加载还是包未安装
- 选择修复层级:根据命令使用范围选择修改方案
- 验证修复:确保修复不引入新问题
五、总结
dracut的模块化设计是现代Linux初始化系统的典范,它将复杂的启动过程分解为可管理、可重用的组件。然而,这种模块化也带来了依赖管理的复杂性。
在initrd中添加命令的决策本质上是架构决策:是应该修改模块内部实现(方案A),还是在集成层添加配置(方案B),抑或在构建层保证供应(方案C)?
对于像awk这样的基础工具,它们虽不属于任何一个特定模块,但却是整个初始化脚本生态的"共享基础设施 "。对于这类命令,采用全局配置方案(方案B) 是最具工程合理性的选择。它在保持各模块纯净性的同时,为产品集成提供了必要的灵活性。
最终,可靠initrd的构建不仅依赖于技术方案的正确选择,更依赖于完善的验证体系、清晰的职责划分和系统化的工程管理。只有这样,我们才能确保这个微型的启动世界,能够稳定、可靠地完成它连接硬件与操作系统的关键使命。