Linux系统中CPU内存访问机制与性能优化(32位/64位系统)
目录
- 技术原理深度解析
- CPU内存访问基础架构
- 多级缓存结构与访问流程
- 32位与64位系统的寻址差异
- 字(Word)访问机制详解
- 字长定义与规范
- 内存对齐与性能影响
- 内存访问优化技术
- 性能优化实践方案
- 内存对齐编程技巧
- 系统级调优策略
- 总结
- 参考文献
1. 技术原理深度解析
1.1 CPU内存访问基础架构
CPU 访问内存并非像高级语言中的赋值语句那样简单直接,而是通过三组关键的总线系统协同完成的物理过程。这三组总线构成了冯·诺依曼架构计算机的"神经系统"。
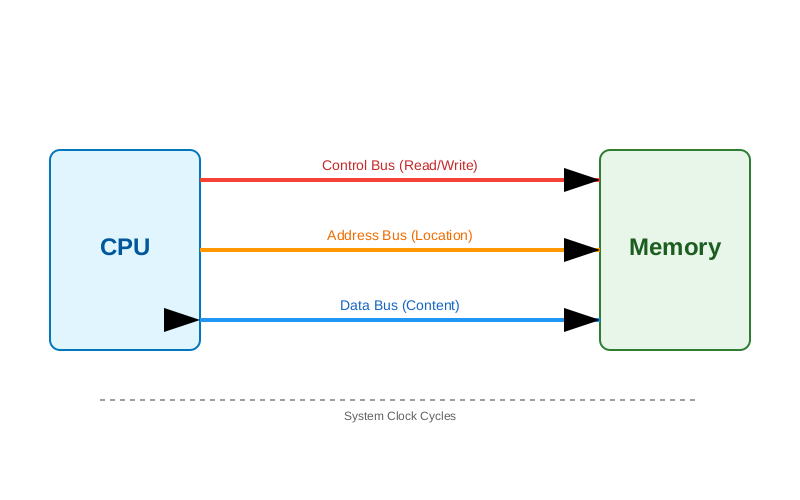
图1:CPU通过三总线访问内存的时序逻辑
- 地址总线 (Address Bus):CPU 将要访问的内存单元地址放入地址总线。地址总线的宽度决定了 CPU 能够寻址的内存范围(即寻址空间)。
- 控制总线 (Control Bus):CPU 发出读(Read)或写(Write)信号,以及其他控制信号(如总线锁定、中断应答等)。
- 数据总线 (Data Bus):数据在 CPU 和内存之间传输的通道。数据总线的宽度决定了 CPU 一次能传输的数据量(即位宽)。
完整访问流程:
- CPU 将目标虚拟地址转换为物理地址(通过 MMU)。
- CPU 将物理地址发送到地址总线。
- CPU 在控制总线上发出"读"命令。
- 内存控制器(Memory Controller)定位到对应的 DRAM 单元。
- 内存将数据放置在数据总线上。
- CPU 从数据总线读取数据到寄存器。
1.2 多级缓存结构与访问流程
为了弥补 CPU 核心频率(GHz 级)与主存访问速度(数百时钟周期延迟)之间的巨大鸿沟,现代处理器引入了多级缓存(Cache)体系。
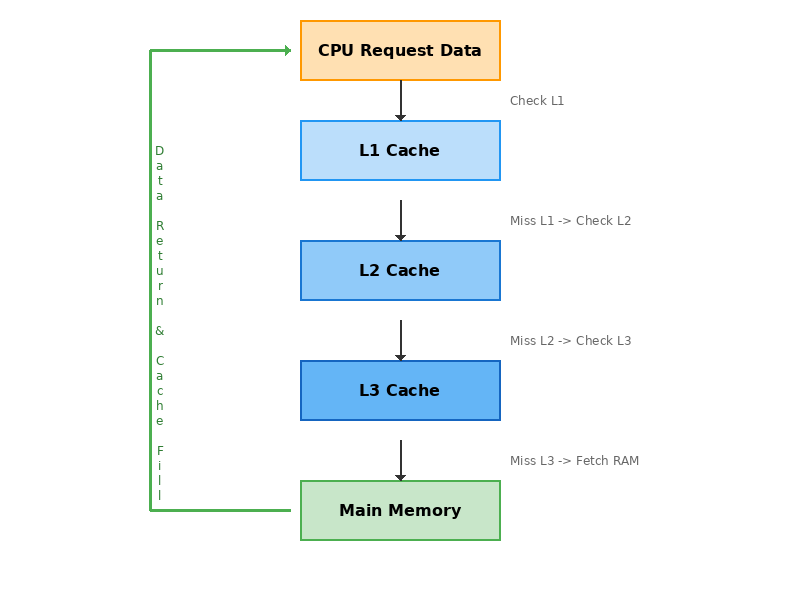
图2:CPU多级缓存命中/未命中流程
- L1 Cache:分为指令缓存(I-Cache)和数据缓存(D-Cache),紧贴 CPU 核心,延迟极低(3-4 周期)。
- L2 Cache:容量稍大,速度稍慢(10-12 周期),通常为核心私有或共享。
- L3 Cache (LLC):多核共享,容量最大(数 MB 到数十 MB),延迟较高(30-50 周期)。
访问路径 :
当 CPU 需要数据时,按照 L1 -> L2 -> L3 -> 主存(DRAM)的顺序查找。
- Hit (命中):在某级缓存找到数据,直接返回,性能最高。
- Miss (未命中):逐级向下查找,直到访问主存。主存访问不仅延迟高,还会阻塞 CPU 流水线。
1.3 32位与64位系统的寻址差异
"位数"通常指 CPU 的通用寄存器宽度,这直接决定了其原生支持的虚拟地址空间大小。

图3:32位与64位系统寻址能力对比
-
32位系统:
- 地址总线通常为 32 位。
- 最大寻址空间:232=4,294,967,2962^{32} = 4,294,967,296232=4,294,967,296 字节 ≈4GB\approx 4 \text{GB}≈4GB。
- 限制:在 PAE(物理地址扩展)开启下可支持更多物理内存,但单个进程的虚拟地址空间仍受限。
-
64位系统:
- 地址总线理论支持 64 位,实际实现通常为 48 位或 52 位。
- 理论最大寻址空间:264=18,446,744,073,709,551,6162^{64} = 18,446,744,073,709,551,616264=18,446,744,073,709,551,616 字节 ≈16EB (Exabytes)\approx 16 \text{EB (Exabytes)}≈16EB (Exabytes)。
- 优势:轻松支持 TB 级内存,适合大型数据库和科学计算。
2. 字(Word)访问机制详解
2.1 字长定义与规范
在计算机体系结构中,"字(Word)"是 CPU 一次处理数据的自然单位。
- 32位系统:字长为 4 字节(32 bits)。
- 64位系统:字长为 8 字节(64 bits)。
这也意味着,long 类型在 32 位 Linux 下通常是 4 字节,而在 64 位 Linux 下是 8 字节。
2.2 内存对齐与性能影响
CPU 访问内存并不是按字节随意读取,而是以"字长"或"缓存行"为粒度进行的。内存对齐是指数据存储的起始地址是其大小(或系统字长)的整数倍。
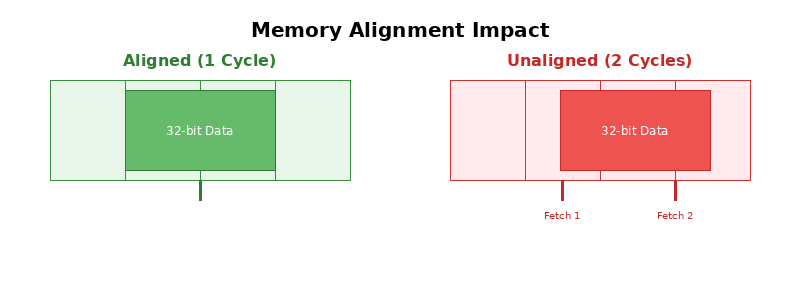 图4:内存对齐与非对齐访问的性能差异
图4:内存对齐与非对齐访问的性能差异
-
对齐访问 (Aligned Access):
- 数据位于一个字边界内。
- CPU 只需1 个总线周期即可读取完整数据。
-
非对齐访问 (Unaligned Access):
- 数据跨越了两个字边界。
- CPU 需要2 个总线周期分别读取两个字,然后在寄存器中拼接。
- 后果:性能下降(至少慢一倍),且在某些架构(如 ARMv5 以前)可能导致硬件异常(Bus Error)。
性能测试数据对比(基于 x86_64, 10亿次读取):
| 访问类型 | 耗时 (ms) | 相对性能 | 说明 |
|---|---|---|---|
| 对齐访问 | 1,200 | 100% | 基准性能 |
| 非对齐访问 | 2,500 | ~48% | 跨越缓存行边界导致惩罚 |
2.3 内存访问优化技术
2.3.1 突发传输模式 (Burst Transfer)
内存不仅支持单次读写,还支持突发传输。当 CPU 发出一个基地址后,内存可以连续传输相邻的多个数据单元,而无需每次都发送地址。
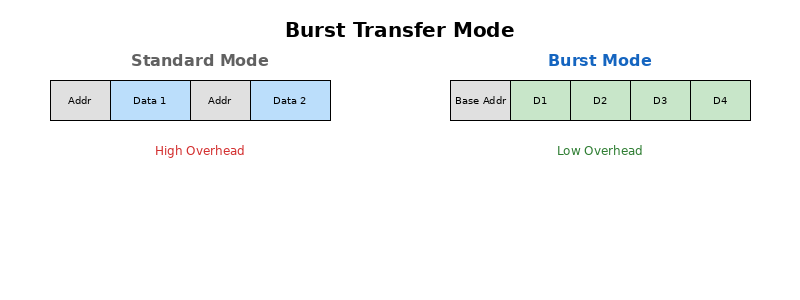
图5:普通传输与突发传输模式对比
2.3.2 预取机制 (Prefetching)
CPU 硬件或编译器预测即将访问的数据,提前将其加载到 L1/L2 Cache 中。
- 硬件预取:监测内存访问模式(如顺序数组遍历),自动预取下一块数据。
- 软件预取 :使用
__builtin_prefetch等指令显式告知 CPU。
2.3.3 缓存行 (Cache Line) 填充
Cache 与主存交换数据的最小单位是缓存行(通常 64 字节)。
- 策略:读取 1 个字节时,会将所在的整行 64 字节都加载进来。
- 优化:利用"空间局部性",将相关联的变量紧凑排列,使它们位于同一 Cache Line,减少 Cache Miss。
3. 性能优化实践方案
3.1 内存对齐编程技巧
3.1.1 结构体设计原则
编译器会自动进行对齐填充(Padding),但这可能导致内存浪费。
糟糕的设计:
c
struct BadAlign {
char c; // 1 byte
int i; // 4 bytes (padding 3 bytes after c)
short s; // 2 bytes
long l; // 8 bytes (padding 6 bytes after s)
}; // 总大小:24 bytes (64位系统)优化的设计(按大小降序排列):
c
struct GoodAlign {
long l; // 8 bytes
int i; // 4 bytes
short s; // 2 bytes
char c; // 1 byte
// padding 1 byte to align structure size to 8
}; // 总大小:16 bytes (节省 33% 内存)3.1.2 编译器指令
可以使用 GCC 属性强制对齐:
c
// 强制按 64 字节对齐(适配 Cache Line)
struct CacheAligned {
int data[16];
} __attribute__((aligned(64)));3.2 系统级调优策略
3.2.1 内核参数调整 (/proc/sys/vm/)
vm.swappiness:控制使用 Swap 的倾向。高性能场景建议调低(如 10),减少磁盘 I/O。vm.dirty_ratio/vm.dirty_background_ratio:控制脏页回写阈值,影响写操作的延迟。
3.2.2 NUMA 架构优化
在多路服务器上,跨节点访问内存延迟高。
-
策略 :使用
numactl绑定进程到特定 CPU 和内存节点。bashnumactl --cpunodebind=0 --membind=0 ./my_application
3.2.3 大页内存 (HugePage)
默认页大小为 4KB,页表项(PTE)多,TLB 容易 Miss。
-
优化:启用 2MB 或 1GB 大页。
-
配置 :
bash# 分配 1024 个 2MB 大页 echo 1024 > /proc/sys/vm/nr_hugepages -
收益:大幅减少 TLB Miss,提升数据库(如 Oracle, PostgreSQL)和虚拟化性能。
4. 总结
理解 CPU 内存访问机制是编写高性能代码的基石。从硬件的总线与缓存,到软件层面的对齐与大页配置,每一环都影响着最终的系统吞吐量。
- 硬件层面:利用好 Cache Line 和 Burst Transfer。
- 编码层面:注意结构体对齐,利用空间局部性。
- 系统层面:合理配置 NUMA 和 HugePage。
5. 参考文献
- Intel® 64 and IA-32 Architectures Optimization Reference Manual
- Linux Kernel Documentation: Documentation/vm/
- Ulrich Drepper, "What Every Programmer Should Know About Memory"