0.Overview
难度相当大的一个环节,同时也是自由度相当高的一个 project;在本次 project 中,我们要为数据库编写一个存储在磁盘上、基于 page 结构的 B+ Tree 索引。
本次 project 有 4 个 Task:
- B+ Tree Pages
- B+ Tree Insertion, Deletion and Point Search
- Index Iterator
- Concurrency Control
但 Task#4 的并发控制(Concurrency Control)是依靠 project#1 的 page guard 实现的,如果前一个 project 写的好的话,project#2 中其实不需要担心这一个任务。
由于任务的自由度相当大(所有辅助函数都要我们自己设计),同时设计的难度也很高,我们先分析一下代码中的 BPlusTree 在数据库中发挥的作用。
首先我们知道,传统的关系型数据库会采用表格(table)组织数据,每个表格都有相应的数据行以及属性列;因此,一个表格需要有一组元数据,用于描述其中有哪些数据行和属性列。
在 BusTub 中,这个元数据可以对应 Schema 类型(src/include/catalog/schema.h),该类型持有了一组表示属性列信息的类型 Column(src/include/catalog/column.h)。其中,Column 存储了某列的列名 column_name_、列数据类型 column_type_、列数据长度 length_ 以及该列在一个数据行中的所在位置 column_offset_。
Schema 和 Column 作为一张表的元信息,它们是独一无二且不会重复创建的,而且每次增删查改时数据库都会去访问它们,以找到所需的数据位置;并且每个 Schema 都由 TableInfo(src/include/catalog/catalog.h)类型管理。
因为数据库需要持久化存储所有数据,所以 TableInfo 使用了一个 TableHeap(src/include/storage/table/tuple_heap.h)类型,将一张表上的所有数据存储在若干 page 当中。
BusTub 在存储数据时,采用的是经典的行优先策略;也就是说一个数据行会像 in-memory 的数组行一样被完整地存储,而不会按列拆分。
显然每个数据行包含了多个不同的属性列,这些属性列的拼接使得数据行更像一个元组结构,因此 BusTub 使用了 Tuple(src/include/storage/table/tuple.h)类型表示每个数据行。
Tuple 的内容同样要放到不同 page 当中,为了管理分散在 page 中的 tuple,BusTub 使用了 TablePage(src/include/storage/page/table_page.h)作为每个存储了 tuple 的 page 的 header,这个 header 能够指示当前 page 中哪些部分到哪些部分有什么 tuple。
其中,在代码内随处可见的 RID(src/include/common/rid.h)类型就是用来在 TablePage 当中找到对应 tuple 的物理索引符。
我们要实现的 B+ 树,是由 GenericKey(src/include/storage/index/generic_key.h)模板类型作为键、RID 作为值组成的一个关联"容器";此处可以将 GenericKey 理解为一般数据库中的主键。
而 B+ 树的实际结点,BPlusInternalPage 和 BPlusTreeLeafPage 分别继承自 BPlusTreePage,这表明每个结点各自独占一整个数据页面,因此它们是固定内存布局类型。
如果需要在 BPlusInternalPage 或 BPlusTreeLeafPage 当中添加额外数据成员,那么一定要仔细审查字节填充和成员扩充是否会导致类型大小超出 BUSTUB_PAGE_SIZE 的范围,违反了这一约束会导致运行期出现 heap-use-overflow。
实际上不是很建议添加额外数据成员。
最后不得不说的是,其实在 BusTub 的代码设计中有非常多的坏味道,或者说涉及到了 UB(undefined behaviour)。
以下是 language lawyer 环节🤓☝
首先比较搞笑的是,在 BusTub 中,BPlusTree 的模板参数 ValueType 固定就是非模板类型 RID,而 BPlusInternalPage 的 ValueType 也是固定的非模板类型 page_id_t;BusTub 坚持将 BPlusTree 的键值类型全都设计为模板参数是很脱裤子放屁的,这就纯粹在玩模板 cosplay。
更不用提模板类型应该全部写在头文件中,而不是像 BusTub 一样分离声明和实现,然后在实现文件(.cpp)中重新显式实例化要用到的所有特化模板。
虽然这确实可以利用增量编译极大加速项目构建。
而且,TablePage 作为一个直接二进制序列化的类型,其上所有数据类型(包括它本身)都应该也必须满足 std::is_standard_layout。但由于 BusTub 在其中使用了一个编译期扩展,即零长数组,实际该类型并不满足这一约束,因此对 TablePage 的二进制序列化/反序列化严格意义上来说是一种未定义行为。
同样的,本次 project 要实现的 BPlusTreeInternalPage 和 BPlusTreeLeafPage 也是一个 on-disk 类型,而且极其明显的是,我们要用 page guard 提供的 reinterpret_cast 从字节数组中直接提取对应类型的对象。
虽然这两个类型满足了二进制序列化的必要条件:std::is_standard_layout,但问题在于:此处的 reinterpret_cast 试图无中生有出一个对象,而且还让这个对象"悄无声息"地消失,显然这违反了 C++ 的对象生命周期要求。
在 C++23 之后,标准允许满足了 std::is_trivially_destructible 和以下三种性质中任意一种的类型,在不调用构造函数的情况下直接开启对象的生命周期:
std::is_trivially_default_constructiblestd::is_trivially_copyable_constructiblestd::is_trivially_move_constructible
这种类型称为具有 implicit-lifetime 的类类型。
由于 BusTub 显式标注了基类 BPlusTreePage 的默认构造函数、拷贝构造函数以及析构函数为 delete,因此 BPlusTreeInternalPage 和 BPlusTreeLeafPage 显然不具有隐式生命周期,而且这种标注也使得 BPlusTreePage 不再是 trivial 类类型,所以直接重解释字节数组实际上也是未定义行为。
但因为 BusTub 使用的语言标准是 C++17,此时的标准根本没有这种隐式生命周期概念,最接近的也是 std::is_trivial 约束(满足 trivial 的情况下,standard layout 类型也是 POD 类型),所以这种操作在 C++17 下倒也不一定是未定义行为,更应该是一种未被标准考虑在内的边界情况。
顺便一提,C++17 有一个 std::launder 工具,它很适合用在一些需要 reinterpret_cast 的地方;但 std::launder 必须作用在一个已经存在某个对象的原始内存块上,对于 BusTub 这种对象生命周期都没开始的情况也是不适用的。
其实可以自己手动注释掉这几个
delete标注,这样这些类型就满足POD性质,反正代码都交给我们自己写了。
当然了,如果真的要完美满足 C++17 标准的话,代码写起来其实很尴尬也很繁琐,因此假装这个问题不存在也挺合适的。
毕竟 it just works。
1.Task#1 - B+ Tree Pages
我们被要求补充 BPlusTreePage、BPlusTreeInternalPage 和 BPlusTreeLeafPage 的代码实现。其实也就是写好结点类型判断、键值对数量的获取和修改、以及 MaxSize、MinSize 的获取。
关于键值对数量,根据 instruction 要求,Internal Node 的关键字个数会比子树个数少 1;但检查 BPlusTreeInternalPage::ToString() 函数的实现不难发现,BusTub 期望的 Size 是指 internal node 中存储的子树数量。
因此无论是哪种结点类型,GetSize() 方法返回的都应该是当前结点存储的所有键值对数量(包括 Internal Node 的第一个无效 key,即 key_array_[0])。
按照 B+ 树的定义,除了根结点之外的结点 的 MinSize 等于 ⌈ M 2 ⌉ \lceil \frac{M}{2} \rceil ⌈2M⌉,其中 M M M 是结点持有的键值对数量,也就是子树数量。
但在根结点中,Internal Node 的 MinSize 只能等于 2,Leaf Node 的 MinSize 只能等于 1。
在 src/include/storage/page/b_plus_tree_page.h 中,有一个枚举类型 IndexPageType,它用于指示当前结点具体是什么类型。为了能够识别一个结点是否是根结点,从而返回正确的 MinSize 大小,建议在 IndexPageType 后面追加两个枚举量 LEAF_ROOT_PAGE 和 LEAF_INTERNAL_PAGE。
另外,instruction 中关于分裂操作的建议是:
- 对于 Leaf Node,如果插入后 Size == MaxSize,那么此次插入将导致分裂
- 对于 Internal Node,如果插入后 Size > MaxSize,那么此次插入将导致分裂
所以推荐在 BPlusTreePage 中添加以下三个方法:
cpp
// 检查结点是否有可能下溢(即导致合并/重平衡)
auto MayUnderflow() const -> bool;
// 检查结点是否有可能上溢(即导致分裂)
auto MayOverflow() const -> bool;
// 检查结点是否已经下溢
auto Underflow() const -> bool;
// 由于当结点 overflow 时会越界写入,所以结点不应该存在 Overflow 状态
// 但当 Underflow 时结点依然可以存在(总不可能存在越界删除)
// 因此唯独不定义 Overflow() 方法由于我们定义了 Size 的大小是键值对的数量(即子树数量),所以 BPlusTree 的成员 internal_max_size 的值必须大于等于 3,否则 B+ 树会退化为一个二叉搜索树(BST),或者干脆不再属于 B 族树,而且分裂和合并操作将不再适用。
2.Task#2 - B+ Tree Operations
插入、删除和查找操作其实都写在了教科书里,这里没什么好深入讨论的,最多分析一下怎么在 BusTub 里实现 B+ 树的增删查。
BPlusTree 用了整整一个页面,仅用于存放 BPlusTreeHeaderPage 类型以及根结点所在页面,不得不说有点奢侈;但这样一来就不需要额外的并发原语同步不同线程访问 header 的顺序,而且未来还可以在 header 中存放若干有关 B+ 树的元数据或纠错信息。
BusTub 提供了 Context 类型,用于辅助我们自顶向下遍历 B+ 树时的路径追踪。如果实现正确的话,Context::write_set_ 会按访问顺序存储遍历时持有且未释放的所有结点的 WritePageGuard。
美中不足的是,默认提供的 Context::header_page_ 是 std::optional<WritePageGuard> 类型,它不能表达只读操作语义。不过也可以像我一样改成下面这样:
cpp
std::variant<std::monostate, ReadPageGuard, WritePageGuard> header_page_;
// 需要释放 header 锁时,执行以下代码:
header_page_.emplace<std::monostate>();
// 需要构造并访问 header page 时,可以:
auto header = header_page_.emplace<WritePageGuard>(bpm_->WritePage(/*page id*/)).AsMut<BPlusTreeHeaderPage>();2.1 Point Search
搜索实现起来相当简单,按照 latch crabbing 规则自上而下使用二分检索找到对应 leaf node 即可。
STL 其实有两个二分查找算法:std::lower_bound 和 std::upper_bound,建议是不要为难自己、徒增维护复杂度,直接使用 STL 的两个算法模板即可。
std::lower_bound 能返回第一个大于或等于给定元素的迭代器,在理想条件下它会直接返回我们想要的元素。
为了适配 std::lower_bound,而且 instruction 要求升序存储键值对,我们定义 Internal Node 的 key_array_ 里,任意两个连续键 K e y 1 Key_1 Key1 和 K e y 2 Key_2 Key2 构成左闭右开区间,并且 K e y 1 < K e y 2 Key_1 \lt Key_2 Key1<Key2 始终成立。
给定一个待查 K K K,假设 K e y 1 Key_1 Key1 对应 key_array_[1], K e y 2 Key_2 Key2 对应 key_array_[2],Internal Node 只有三个键值对,则有:
- 如果满足: K < K e y 1 K \lt Key_1 K<Key1,那么我们访问
page_id_array_[0] - 如果满足: K e y 1 ≤ K < K e y 2 Key_1 \le K \lt Key_2 Key1≤K<Key2,那么我们访问
page_id_array_[1] - 如果满足: K e y 2 ≤ K Key_2 \le K Key2≤K,那么我们访问
page_id_array_[2]
定义左闭右开区间的好处是方便删除元素,而且也有助于结点分裂和键值对的 redistribution。
由此,我们可以在 BPlusInternalPage 中添加这样一个二分查找算法:
cpp
/** Return the position of the sub-tree with the given key. */
[[nodiscard]] auto RouteTo(const KeyType &navi, const KeyComparator &comparator) const -> size_t;根据拿到的返回值,调用 ValueAt() 函数获取实际的子树 page id 即可。
2.2 Insertion
插入操作要遵循一种乐观的 latch crabbing 策略:一路获取父结点读锁直到来到 leaf 结点,然后拿到 leaf 的写锁。
如果插入不导致分裂,那么直接插入,否则释放所有锁,转入悲观的 latch crabbing。
悲观策略是这样的:自顶向下获取每个结点的写锁,在持有了当前结点写锁和下一结点写锁的情况下,检查下一结点是否安全(也就是是否满足 !MayOverflow());如果安全,那么释放持有的所有祖先结点,然后对下一结点进行重复操作,否则持续持有父结点写锁并继续下探。
这可以通过一个简单的 while 循环实现:
cpp
Context ctx;
/// 假定我们已经持有一个指向根结点的 node,以及 header page 的写锁
if (!node->MayOverflow()) {
ctx.header_page_.emplace<std::monostate>();
}
if (node->IsLeafPage()) {
/// 根结点是 leaf 时需要特殊处理
}
do {
const auto internal = static_cast<InternalPage *>(node);
const auto page_pos = internal->RouteTo(key, comparator_);
// 推荐将 page_pos 保存到 Context::write_set_ 当中
auto writter = bpm_->WritePage(internal->ValueAt(page_pos));
node = write.template AsMut<BPlusTreePage>()
if (/*node is safe*/) {
ctx.write_set_.clear();
}
ctx.write_set_.emplace_back(std::move(writer));
} while (!node->IsLeafPage());
// 区间的二分查找保证了我们一定能定位到一个 leaf 结点如果插入会导致结点分裂,那么分裂操作可以遵循以下逻辑:
因为 B+ 树的所有 leaf 结点共同构成一个单链表,所以我们必须总是向右分裂以维护这一性质。
对于 Leaf Node:计算分割点 pivot = MaxSize / 2,假设新 kv 的插入点为 lb;如果 lb < pivot,那么先递减 pivot,然后将区间 [ p i v o t , S i z e ) [pivot, Size) [pivot,Size) 的数据分裂出去,再在 lb 处插入新键值对;否则同样将区间 [ p i v o t , S i z e ) [pivot, Size) [pivot,Size) 分裂出去,然后在新结点中对应 lb的位置插入新的 kv 键。
对于 Internal Node,虽然不存在单链表,但向右分裂更简单,因为我们总是移动数组尾部的元素。分裂步骤和 leaf node 相同:先计算分割点 pivot,如果插入点 lb 满足 lb < pivot,那么递减 pivot 再移动元素,否则移动元素后直接插入新键值对。
递减
pivot是为了保证原结点和分裂后的新结点,各自的 Size 都至少大于 1(对于 Internal Node 来说是大于 2)。
向上分裂时,虽然名义上叫做递归分裂,但实际只需要逆向遍历 ctx.write_set_ 中存储的 page guard 即可,而且每个结点分裂完毕后可以立即释放。
特别值得一提的是,如果严格遵循 latch crabbing 策略访问结点,那么 ctx.write_set_ 中存储的首元素有一个特点:如果这个元素所指向的 node 不安全(可能上/下溢出),那么它一定是 root 结点,而且此时我们一定持有了 header page 的写锁。
2.3 Deletion
删除操作相比插入而言复杂的多得多,这是因为我们必须支持结点之间关键字的 redistribution。
如果不支持 redistribution 而总是合并下溢的结点,这个下溢结点的左右兄弟不一定有足够空间存储关键字,此时会发生合并时的结点分裂;但如果支持 redistribution,当左右兄弟都无法依靠关键字的转移实现结点平衡时,显然左右兄弟都不安全,这时合并操作一定保证了不会产生一个比 MaxSize 还大的违法结点。
注意:删除操作完成后,没有必要递归更新父结点的区间最小 key,不更新完全不影响后续的插入和查找。
在转移关键字时,由于我们采用了左闭右开区间、升序存储 key,所以左兄弟内所有元素都小于当前结点,右兄弟内所有元素都大于当前结点;为了实现起来更加简单,我们可以令关键字的流动方向总是遵循从右向左,而且合并操作也是自右向左,这被称为左结合顺序。
左结合有一个好处:当根结点是一个 Internal Node 时(MinSize 等于 2),因为子结点之间的合并操作导致了这个结点发生下溢,由于合并的左结合性,剩下的那个有效结点一定被放在了 page_id_array_[0] 上。
关键字的流动方向也被设计为左结合,纯粹是这样设计起来更简单:因为我们可以定义两个不同名字的方法,而不是加上 left/right 后缀以示区分:
cpp
/**
* @brief 从 sibling 处窃取关键字,sibling 必须是右兄弟
* @return 返回 sibling 的新的最小 key
*/
[[nodiscard]] auto TryStealFrom(BPlusTreeInternalPage &sibling, KeyType &&separator) -> std::optional<KeyType>;
/**
* @brief 将自己的关键字派发给 sibling,sibling 必须是右兄弟
* @return 返回 sibling 的新的最小 key
*/
[[nodiscard]] auto TryRedistributeTo(BPlusTreeInternalPage &sibling, KeyType &&separator) -> std::optional<KeyType>;
/** 将 sibling 的关键字转移到自己身上 */
void Coalesce(BPlusTreeInternalPage &sibling, KeyType separator);和代码展示的一样,Internal Node 的重平衡以及合并操作需要从父结点中拉取对应的关键字,将这个关键字作为右兄弟缺失的 key_array_[0] 填补到对应位置上,并且返回操作后右兄弟中新的最小 key,用于替换被拉取下来的关键字。
合并时不需要获取最小 key,因为右兄弟结点需要被整个删除。
Leaf Node 的删除操作会比较特殊一点。如果实现了墓碑机制,根据测试代码来看,墓碑内被标记为已经删除的元素同样必须参与 Size 表达,也就是说 GetSize() 必须返回包含了被登记在 tombstones_ 当中的元素,而有效关键字数量应该用 GetSize() - num_tombstones_ 计算。
根据 instruction 要求,tombstones_ 必须严格按照 FIFO 顺序存储被删除的键值对下标,而且不能在关键字转移的过程中将它们覆写。
这里也推荐定义一个返回逻辑元素大小的 Count() 方法。
cpp
// 返回剔除被删除元素后,实际的元素数量
auto Count() const noexcept -> size_t;显然如果墓碑数量足够大,例如恰好等于 MinSize,一个 Leaf Node 自诞生后一定不会发生合并或关键字重平衡;这进一步可以导致 Internal Node 也不会发生合并或重平衡。
但如果墓碑数量过大,在使用默认 max size 参数时会迅速提升每个结点的分裂次数(因为墓碑挤占了本可以用于存储键值对的空间)。
除此之外,Leaf Node 的关键字转移,以及结点合并操作与 Internal Node 基本相同:
cpp
/**
* @brief 从 sibling 处窃取关键字,sibling 必须是右兄弟
* @return 返回 sibling 的新的最小 key,窃取失败返回 nullptr
*/
[[nodiscard]] auto TryStealFrom(BPlusTreeLeafPage &sibling) -> const KeyType *;
/**
* @brief 将自己的关键字派发给 sibling,sibling 必须是右兄弟
* @return 返回 sibling 的新的最小 key,派发失败返回 nullptr
*/
[[nodiscard]] auto TryRedistributeTo(BPlusTreeLeafPage &sibling) -> const KeyType *;
/** 将 sibling 的关键字转移到自己身上 */
void Coalesce(BPlusTreeLeafPage &sibling);不过有一点值得补充:虽然 instruction 不要求 Task#3 中实现的 IndexIterator 支持并发访问,但想要做到其实很简单;关键在于执行删除操作时,Leaf Node 发生下溢后,访问左右兄弟的顺序。
根据 BPlusLeafPage 的定义,所有叶子结点都有一个 next_page_id_,这个成员指向了当前结点的右兄弟,从而将所有 Leaf Node 串成了一个单链表。
而 IndexIterator 是工作在这条单链表上、自左向右横向移动的迭代器,所以如果我们访问 Leaf Node 的左右兄弟时,总是从左边开始,就能保证 IndexIterator 的访问也是线程安全的。
因此,当一个 Leaf Node 即将下溢时,我们可以尝试以下步骤:
- 获取 Leaf Node 的右兄弟,若存在,那么尝试从右兄弟窃取关键字,无法窃取则直接与右兄弟合并
- 若右兄弟不存在,则释放 Leaf Node 后获取左兄弟,拿到左兄弟之后重新获取 Leaf Node 自身,再先后尝试关键字转移与结点合并
由于 B+ 树的 Internal Node 至少包含 2 个键值对,因此对于任意一个 Leaf Node 一定有左兄弟或右兄弟,上述过程始终能够成立。
3.Task#3 - Index Iterator
IndexIterator 其实是 GetValue() 函数的变种,本质上它们都是下探获取 Leaf Node 的读锁,但不同之处在于 IndexIterator 需要支持哨兵值 IsEnd() 以及向右移动。
一个合格的迭代器应该能支持默认构造,所以 IndexIterator 的 IsEnd() 在两种情况下都为 true:默认构造的对象,或者一个指向 B+ 树最后一个结点的最后一个关键字的对象。
但由于这个迭代器类型不满足 std::is_copy_constructible 和 std::is_copy_assignable(因为需要持有一个 ReadPageGuard),所以 IndexIterator 不满足 LegacyIterator,也就是说在 C++20 之前,它不属于标准库能够识别的迭代器类型。
当构造了一个 IndexIterator,根据测试代码要求,这个迭代器必须指向一个有效元素。如果启用了墓碑机制,这个迭代器必须跳过所有被登记在墓碑当中的键值对,否则只需要指向下探过程中找到的最合适的那个键值对。
特别要注意的是,如果启用了墓碑机制,那么是有可能存在空的 Leaf Node 的,换言之这个 Leaf Node 的所有关键字都被登记在墓碑当中,此时迭代器必须跳过整个空的 Leaf。
为了兼容墓碑机制,我们可以用 SFINAE 设计一个这样的辅助类型:
cpp
template <ssize_t NumTombs, typename = void>
class OrderedTombs {
protected:
OrderedTombs() = default;
template <typename Leaf>
void Reset([[maybe_unused]] const Leaf &leaf) noexcept {}
[[nodiscard]] auto InitialAlive(size_t pos = 0) const noexcept -> size_t { return pos; }
[[nodiscard]] auto NextAlive(size_t pos) const noexcept -> size_t { return pos + 1; }
};
template <ssize_t NumTombs>
class OrderedTombs<NumTombs, std::enable_if_t<(NumTombs != 0)>> {
// 由于 NumTombs 取负数时,表示墓碑大小由我们自己决定,所以此处只能限制当 NumTombs 显式为 0 时不记录 tombstones
std::unique_ptr<size_t[]> tombstones_;
size_t num_tombstones_{0};
protected:
OrderedTombs() = default;
template <typename Leaf>
void Reset(const Leaf &leaf) {
auto tomb_info = leaf.Tombstones();
// Tombstones() 返回 tombstones_ 首地址以及 num_tombstones_
if (num_tombstones_ < tomb_info.second) {
tombstones_ = std::make_unique<size_t[]>(tomb_info.second);
}
num_tombstones_ = tomb_info.second;
std::copy(tomb_info.first, tomb_info.first + tomb_info.second, tombstones_.get());
std::sort(tombstones_.get(), tombstones_.get() + num_tombstones_);
}
[[nodiscard]] auto InitialAlive(size_t pos = 0) const noexcept -> size_t {
const auto sentinel = tombstones_.get() + num_tombstones_;
auto lb = std::lower_bound(tombstones_.get(), sentinel, pos);
while (lb != sentinel && *lb == pos) {
++pos;
++lb;
}
return pos;
}
[[nodiscard]] auto NextAlive(size_t pos) const noexcept -> size_t { return InitialAlive(pos + 1); }
};然后 IndexIterator 继承这个类型即可。
在实现 operator++ 时要注意一点,在使用迭代器时,我们必须递增迭代器后才能知道是否指向了哨兵值,也就是这样:
cpp
/* BPlusTree */ btree;
for (auto iter = btree.Begin(); iter != btree.End(); ++iter) {
// ...
}
// 或者是:
for (auto iter = btree.Begin(); !iter.IsEnd(); ++iter) {
// ...
}所以我们必须保证:当迭代器已经指向哨兵值的情况下,继续调用 operator++ 是合法安全且不改变迭代器指向的(即无副作用)。
4.Task#4 以及 Bugs
最后一个任务其实不需要做过多考虑,因为 project1 已经完成了这一部分的内容;而且如果 project1 写的好的话我们是不需要在本次任务中担心并发问题的。
如果实际测试过程中还是出现了一些并发问题,那么应该回到上一次实验检查代码实现。
如果是树结构本身不正常,那么可以用项目提供的 b_plus_tree_printer + gdb 调用栈分析具体是哪里出了问题。
我自己在提交代码时遇到了 autograder 中 DeleteTest2/DeleteTest3NoIterator 无法通过的情况,这里要感谢 Discord@Yotta 的提示:
As spec described: We recommend (but do not require) that you to follow this rule when implementing split: split a leaf node when the number of values reaches max_size after insertion, and split an internal node when number of values reaches max_size before insertion. This will ensure that an insertion to a leaf node will never cause a page data overflow when you do something like InsertIntoLeaf and then redistribute; it will also prevent an internal node with only one child.
也就是说这两个测试专门检查结点的 borrow(关键字重平衡)实现是否正确,如果无法通过的话可以尝试检查自己的重平衡部分代码实现是否有问题。
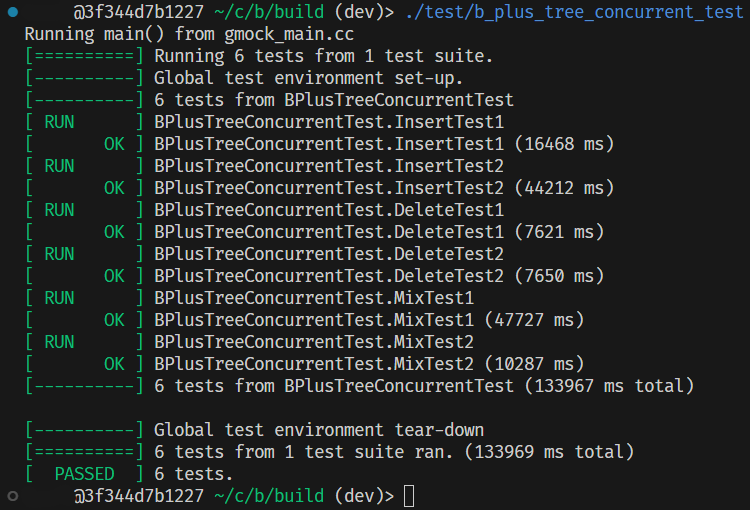
5.测试
本地的几个测试实际上已经足够检查问题了,如果还有什么顾虑的话可以自己额外补充一些测试。
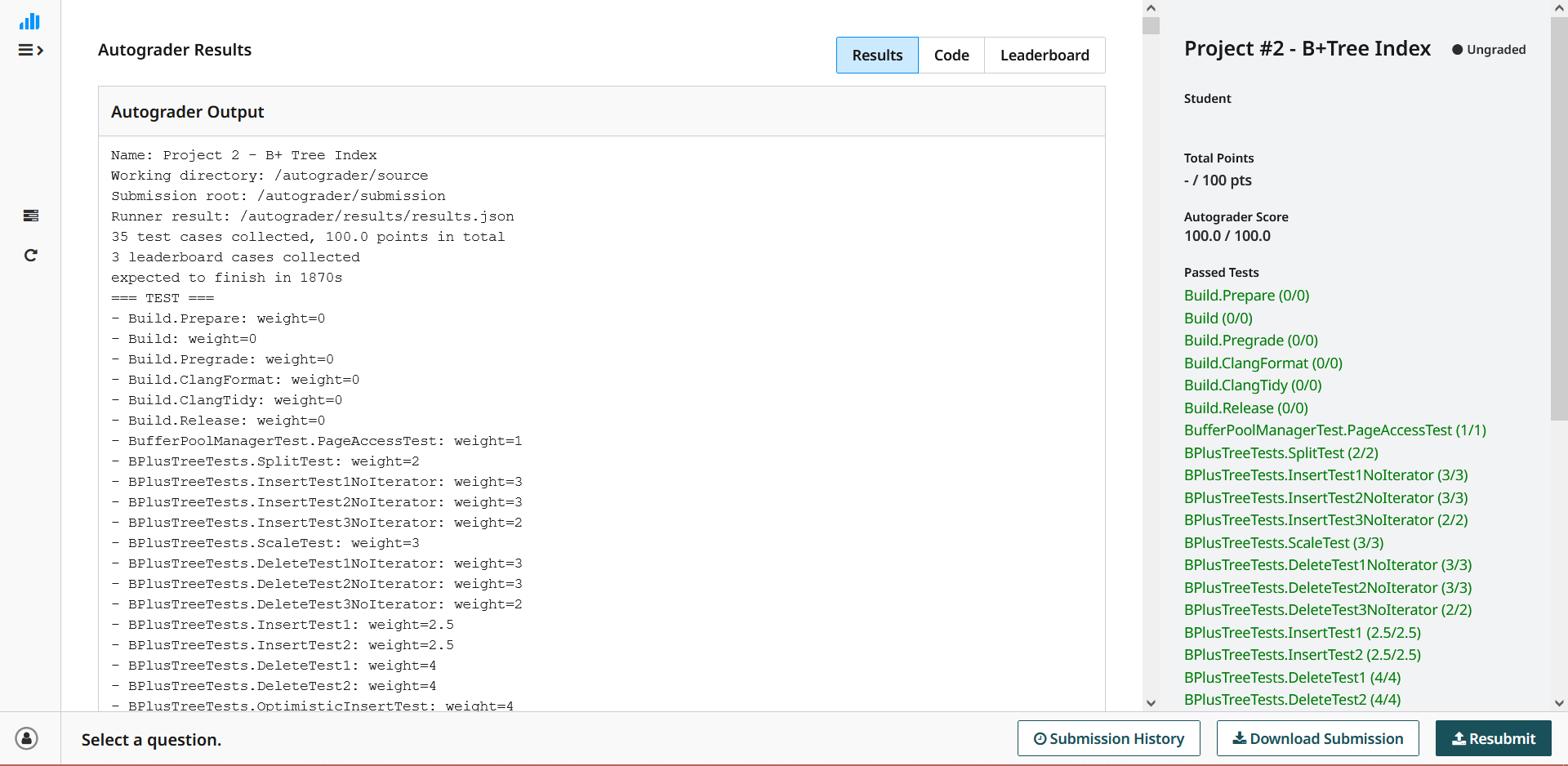
6.提交
最后提交到 gradescope 上查看所有测试的检查结果:
相同的,本轮实验也有一个性能评估环节:
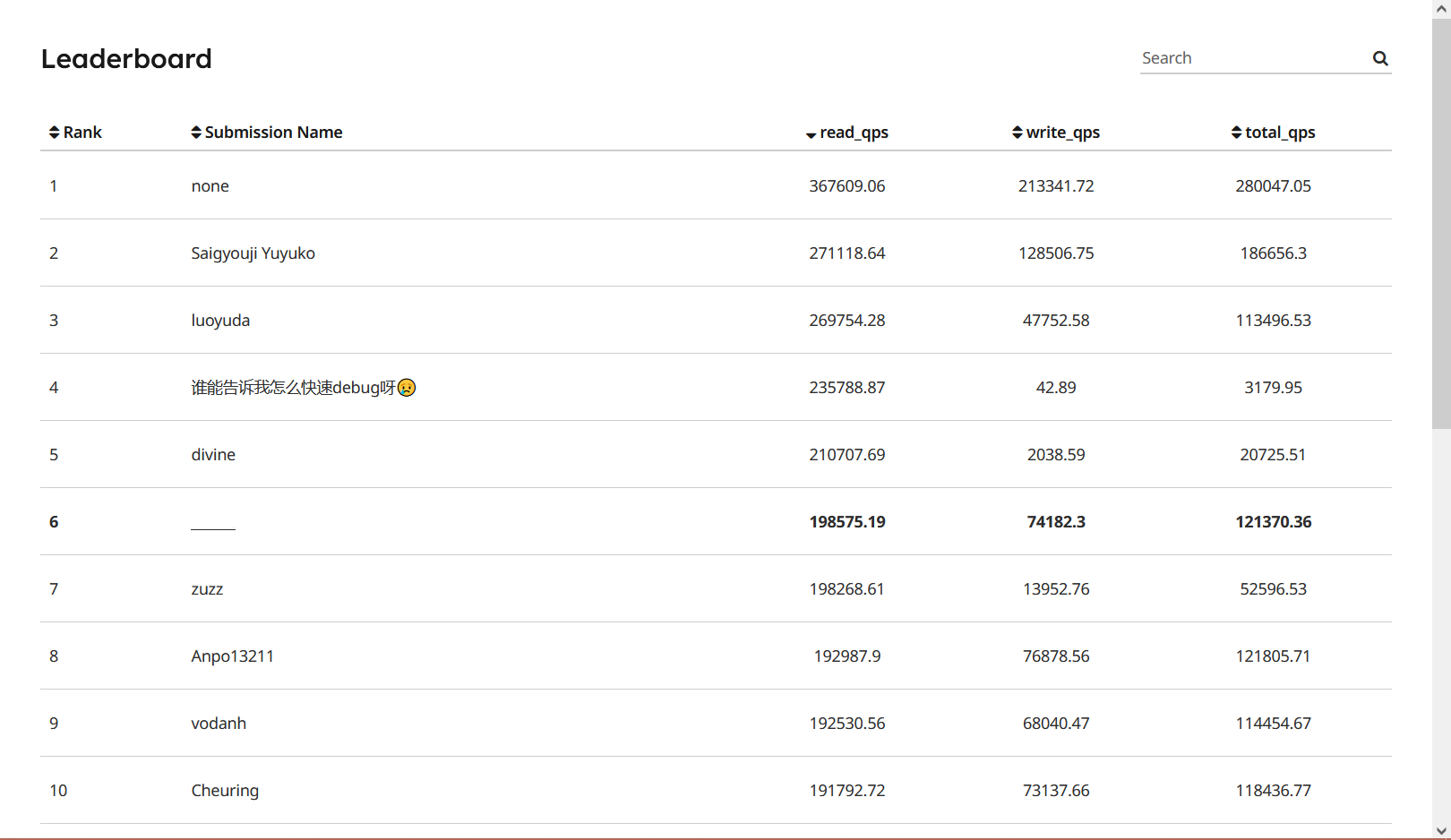
写 B+ 树已经很累了...性能优化的话随缘吧,后续跑个火焰图看看哪里是瓶颈。
7.总结
因为一开始没有思路所以卡了很久(可能是我根本没看 lecture 直接上手代码导致的👉👈),结果就是花在这一节实验上的时间远远超出预估时间。