目录
机器学习的库scikit-learn(简称sklearn))
机器学习定义
利用数学公式总结出数据中的规律来解决实际问题。
机器学习过程
机器学习过程:收集数据,建立数学模型训练,预测
机器学习的库scikit-learn(简称sklearn)
sklearn库作为专注机器学习的库,是依赖于numpy,pandas,matplotlib,scipy等库实现对数据的基本处理。前面我们讲了numpy等库的具体用法,接下来正式进入机器学习算法的学习。
机器学习的本质是依据数学公式挖掘出数据中的规律来解决实际问题,但是这些数学上的问题,具体公式如何去使用(建立数学模型)不需要我们去考虑,因为前辈们已经把他们封装好了,就是sklearn库。我们需要掌握的就是经典的算法模型基于sklearn如何使用。
怎么学习机器学习
对我们而言,机器学习就是选择合适的算法(数学公式构成),根据实际数据求出算法的参数,然后对需要的值进行预测。
我们需要学习掌握机器学习中的十大经典算法。
KNN算法
knn全称 K-Nearest Neighbors(K - 最近邻)。
解决的问题:
knn算法主要解决两类问题:
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|
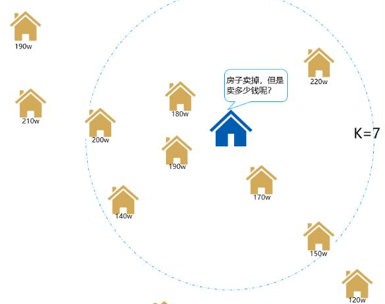
1、连续型数据的回归计算:如基于附近的房价预测目标房价
取一个数量k,计算距离最近的k栋房子的均值,以均值作为房价的预测
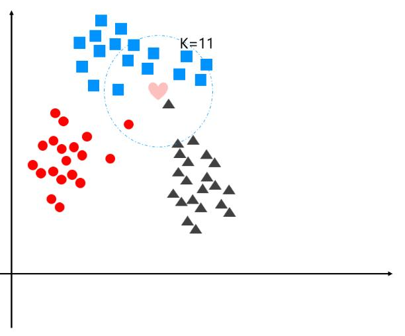
2、离散型数据的分类:分类对象一定距离中哪一种类别最多
取一个数量k,统计最近距离的k个数据各个类别的数量,数量最多的类别就是,被预测对象的类别
原理:
最近邻方法背后的原理是找到在距离上离新样本最近的一些样本, 并且从这些样本中预测标签。最近邻的样本数可以是用户定义的常数(k-最近邻),也可以根据不同的点的局部密度(基于半径的近邻学习)确定。一般来说,距离可以用任意来度量:标准的欧氏距离是最常见的选择。基于邻居的方法被称为非泛化机器学习方法,因为它们只是"记住"它的所有训练数据(可能转换成一个快速的索引结构,比如Ball树或KD树)。
案例1:
我们通过一个案例来演示如何运用knn算法。
目标:
数据文件(部分):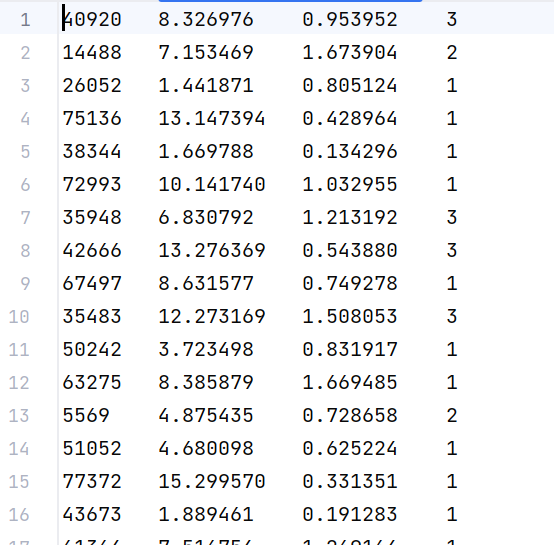
分析:
这是一个分类问题,我们需要基于往届学生的数据,建立一个分类模型,实现输入前三项信息,输出学生所属的类别(爱不爱学习)。
解决过程:
1、查看sklearn官网,找到我们需要使用的KNN算法中用于实现分类的类:浏览器搜索scikit-learn,进入官网查看:
进入最邻近(KNN)页面:
2、找到我们需要的方法:KNeighborsClassifier
3、在API界面查看KNeighborsClassifier的用法:

4、编写代码
python
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
date=np.loadtxt("datingTestSet2.txt") #numpy库中loadtxt读取数据,返回数组类型
x=date[:,:-1] #取第一列到最后一列,不包含最后一列的数组作为特征x
y=date[:,-1] #取最后一列数组作为标签y
neigh=KNeighborsClassifier(n_neighbors=6) #获得类的对象
neigh.fit(x,y) #fit方法实现参数计算
print(neigh.predict([[13455,2,1.3]])) #预测输入数据的标签在 Python 机器学习(尤其是scikit-learn)中,fit()、predict()、score()是分类 / 回归模型的核心方法,三者构成了 "训练→预测→评估" 的完整流程,基本上每个类都用这些方法。
5、执行: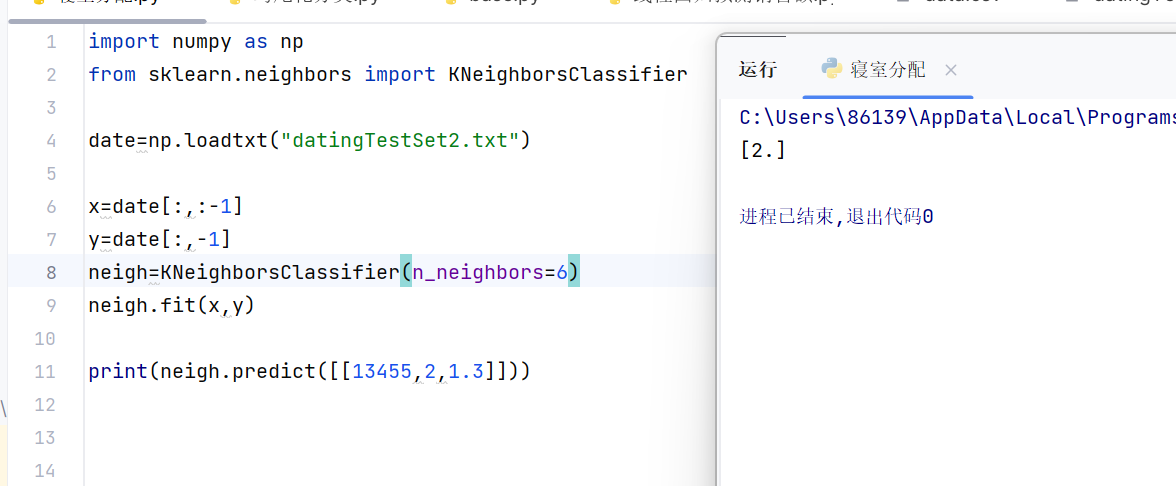
案例2:
目标:
实现鸢尾花的分类
excel表格中的本分数据: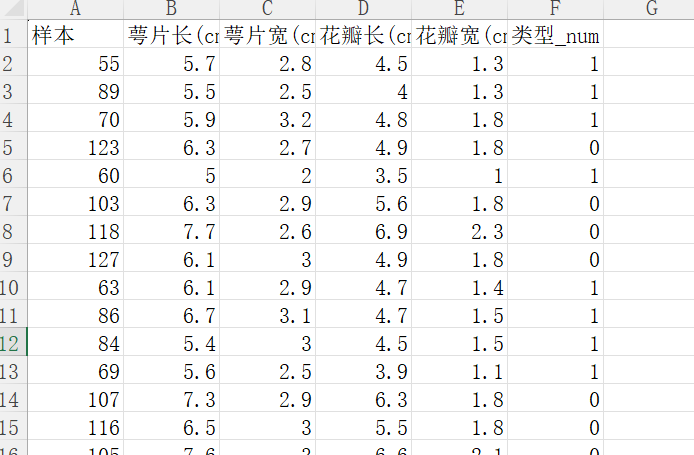
分析:
显然依旧是分类问题,我们还是采用knn最近邻算法中的最邻近分类KNeighborsClassifier。样本列数据不属于判断分类的特征,因此不需要考虑,把BCDE列作为分类的特征,F列作为分类的标签。获取特征数据和标签数据通过fit训练后,就可以使用predict进行预测。其实knn算法的fit并不是真的训练,他其实是把数据存储在内存中,当我们predict传入一个数据,会使用我们之前提到的原理进行计算,然后返回结果。
这里还要补充另一个知识点,不知道大家有没有注意第一个案例的特征数据集有什么特点,可以回头观察一下,不错,特征数据集的第一列数据中的值远远大于其他特征列里面的值!这回导致什么结果呢?
我们刚才说knn算法的训练fit本质是把我们的训练数据集存入内存中,不妨来可视化一下第一个数据集是怎么存储的: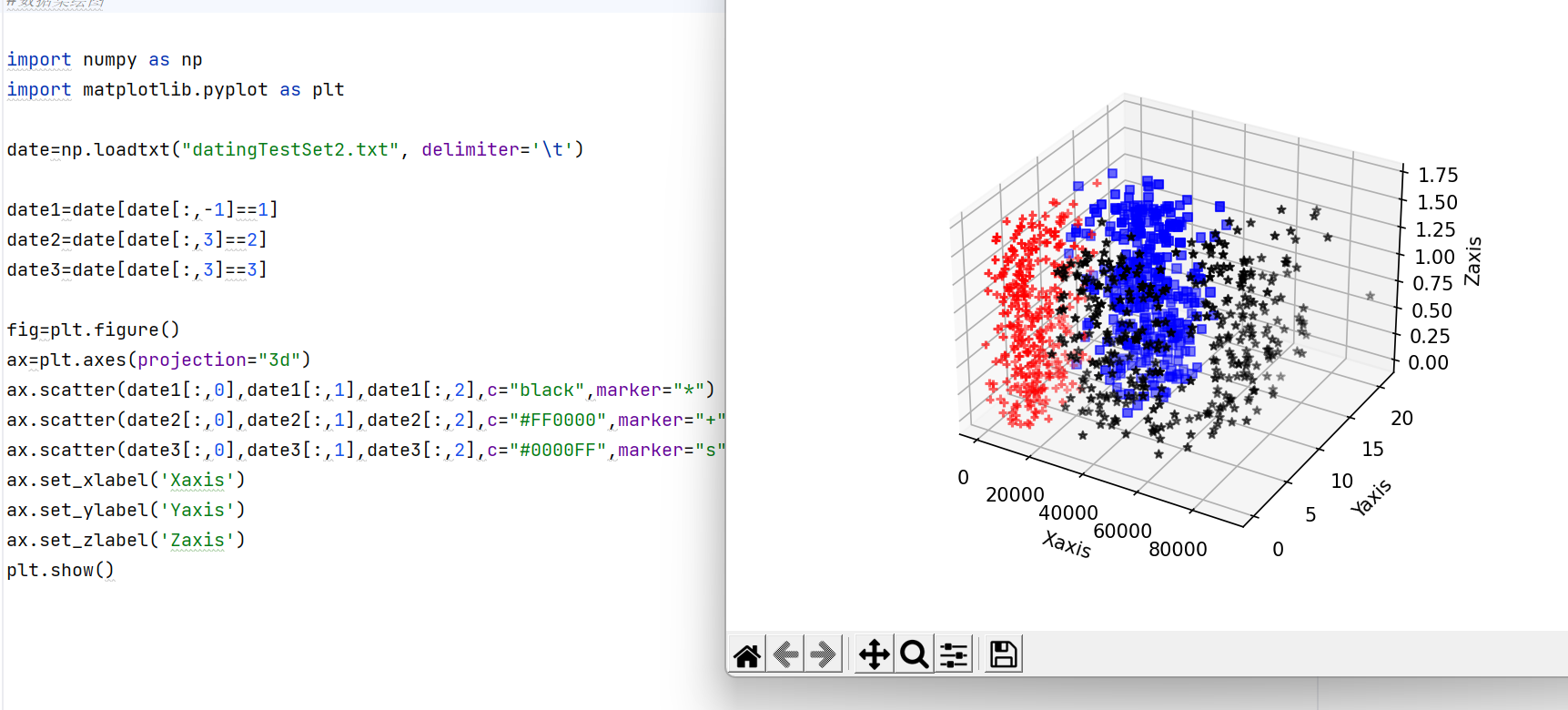
再回到我们的问题:第一列特征数据的值远远大于其他特征列的影响:
没错,我们这里knn算法的原理是通过统计最近距离附近各个标签的数量决定分类,如果第一列值很大,根据两点之间的距离公式我们知道,此时的距离完全由第一列决定,那么其他特征列的值还有什么意义呢?
聪明的你是否已经想到了解决方法呢:
归一化处理,我们通过归一化处理,去除列中元素数值上的大小,保留值的特征------大小由权重来替代。
两种归一化方法:
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|
因此我们这次采用标准化数据集实现鸢尾花的分类。
代码:
python
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
from sklearn.preprocessing import scale #导入标准化的库
df1 = pd.read_excel("鸢尾花训练数据.xlsx")
df2=pd.read_excel("鸢尾花测试数据.xlsx") #返回 Pandas 的 DataFrame 对象(二维表格型数据结构)
y=df1["类型_num"]
y1=df2["类型_num"] #获取标签数据的列
#标准化数据
data = pd.DataFrame()#空的表格数据对象
data['萼片长标准化']= scale(df1['萼片长(cm)'])#S!
data['萼片宽标准化']= scale(df1['萼片宽(cm)'])
data['花瓣长标准化']= scale(df1['花瓣长(cm)'])
data['花瓣宽标准化']= scale(df1['花瓣宽(cm)'])
data1 = pd.DataFrame()#空的表格数据对象
data1['萼片长标准化']= scale(df2['萼片长(cm)'])#S!
data1['萼片宽标准化']= scale(df2['萼片宽(cm)'])
data1['花瓣长标准化']= scale(df2['花瓣长(cm)'])
data1['花瓣宽标准化']= scale(df2['花瓣宽(cm)'])
#创建类的对象,训练fit,预测predict,得分score
neigh=KNeighborsClassifier(n_neighbors=3)
neigh.fit(data,y)
train_predicted = neigh.predict(data1)#,
score= neigh.score(data1,y1)#最点
print(score)运行: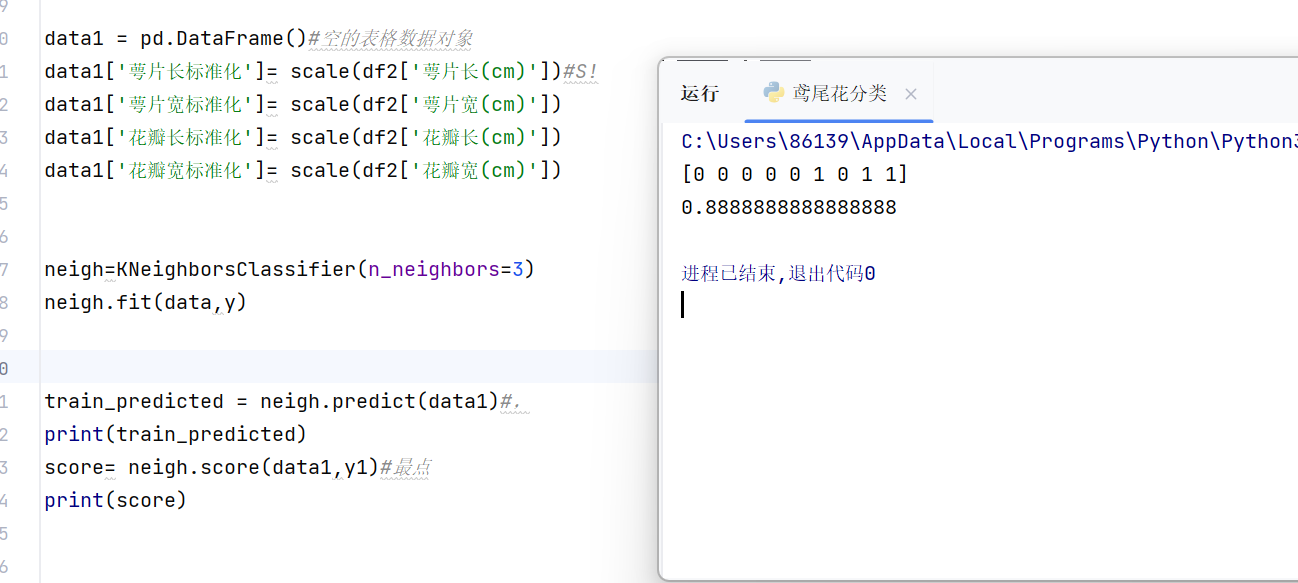
补充:其实这里的标准化处理存在一个小问题,就是测试数据集是完全基于自己的数据集进行标准化,我们应该基于训练数据集的均值方差来进行测试数据集的标准化,因为我们标准化本质是不改变数据本身分布的特点,就是说数据中大大小小的值的比例不变,但是如果测试数据集用自己的均值方差来进行标准化,有没有可能特点和鸢尾花相似但是大小和鸢尾花相差很多的花朵,在我们的算法中被误判成鸢尾花呢。
线性模型
下面介绍第二个算法,线性模型中的最小二乘法:
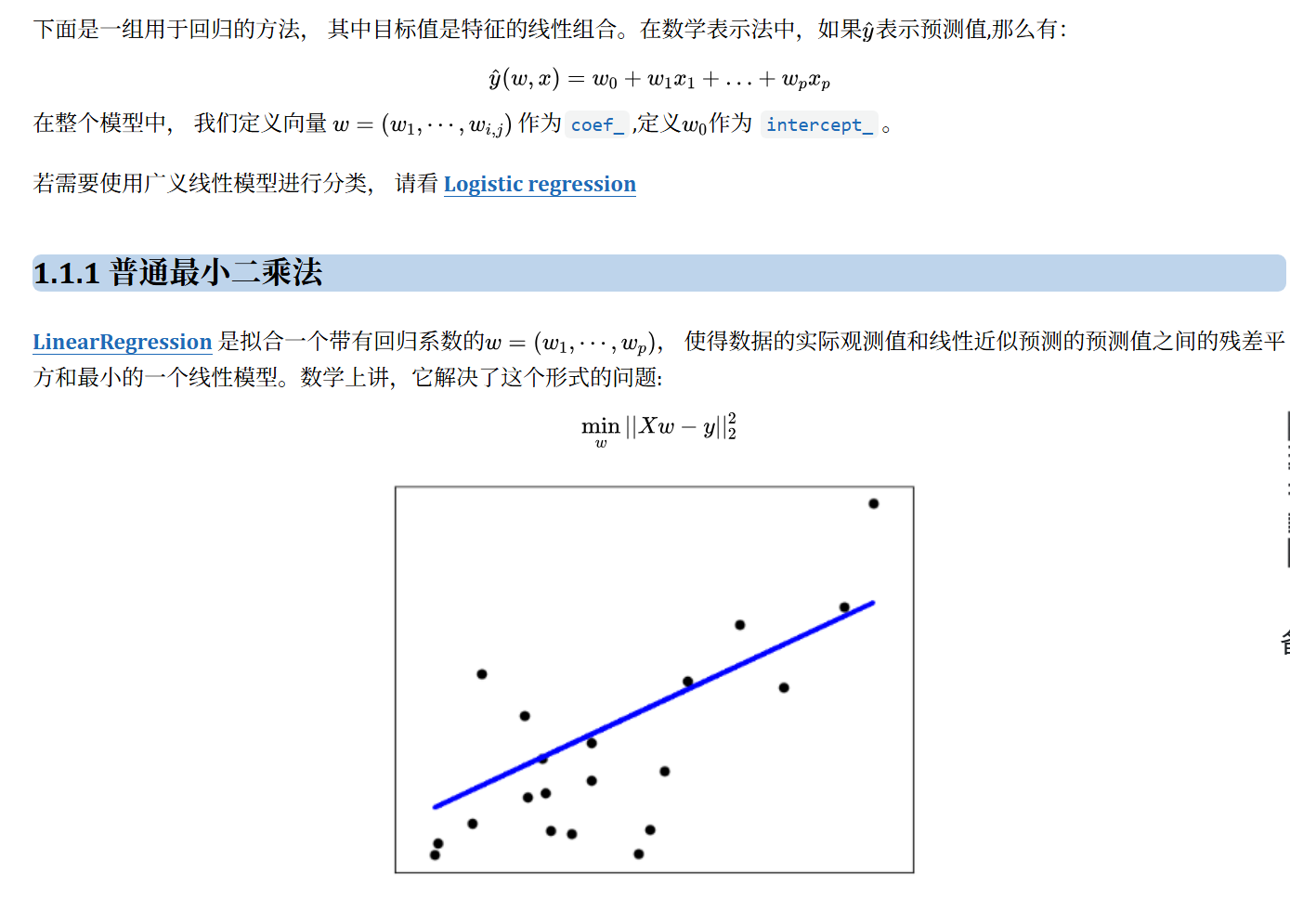
原理拆解:
线性模型本身就是用一条直线去近似拟合数据,从而做出基于特征对标签的预测。数学原理是极大似然估计:
我们要找到一条直线使得,所有数据点到直线的距离的标准差最小。那么现在假设我们找到了这条直线,此时就会有所有数据点到直线的标准差最小,也就是说绝大部分的数据点是距离直线很近的,只有极少数的数据点会离直线的距离比较远,不知道大家能不能想到概率论中的随机变量分布的某个模型,没错正是我们的正态分布。
既然数据点到直线的距离满足正态分布,也就是说每个数据点有一个对应的概率p,而且根据正态分布的概率函数,我们知道这个概率可以用到直线的距离表示,到直线的距离又可以用回归的直线方程表示,即每个数据点对应的概率可以用x,y来表示,那么所有点的概率都可以,把这些概率连乘的结果就是此时呈现在图数据点分布情况的概率。这些数据点呈现出来分布的频率应该是这些点按照概率的分布,因此我们连乘积取得最大值时就是图中的分布。也就是说我们对连乘积的式子(关于x,y以及系数的表达式)进行求导,令导数为0的(图中分布的最大可能),此时带入数据集的x,y,所求出的系数就是距离所有数据点距离方差最小回归方程的系数。
通过这种数学推到我们就得到了计算回归方程稀疏的方法。
补充一点:这种有特征到标签(自变量到因变量)的算法,我们称之为有监督学习。
完全由特征数据进行分类、总结规律的算法我们称之为无监督学习。
还有其他类型算法如:半监督学习,强化学习。
案例:
目标:
建立回归模型预测广告投入对应的销售额

找对应的sklearn中对应的看模块与类:
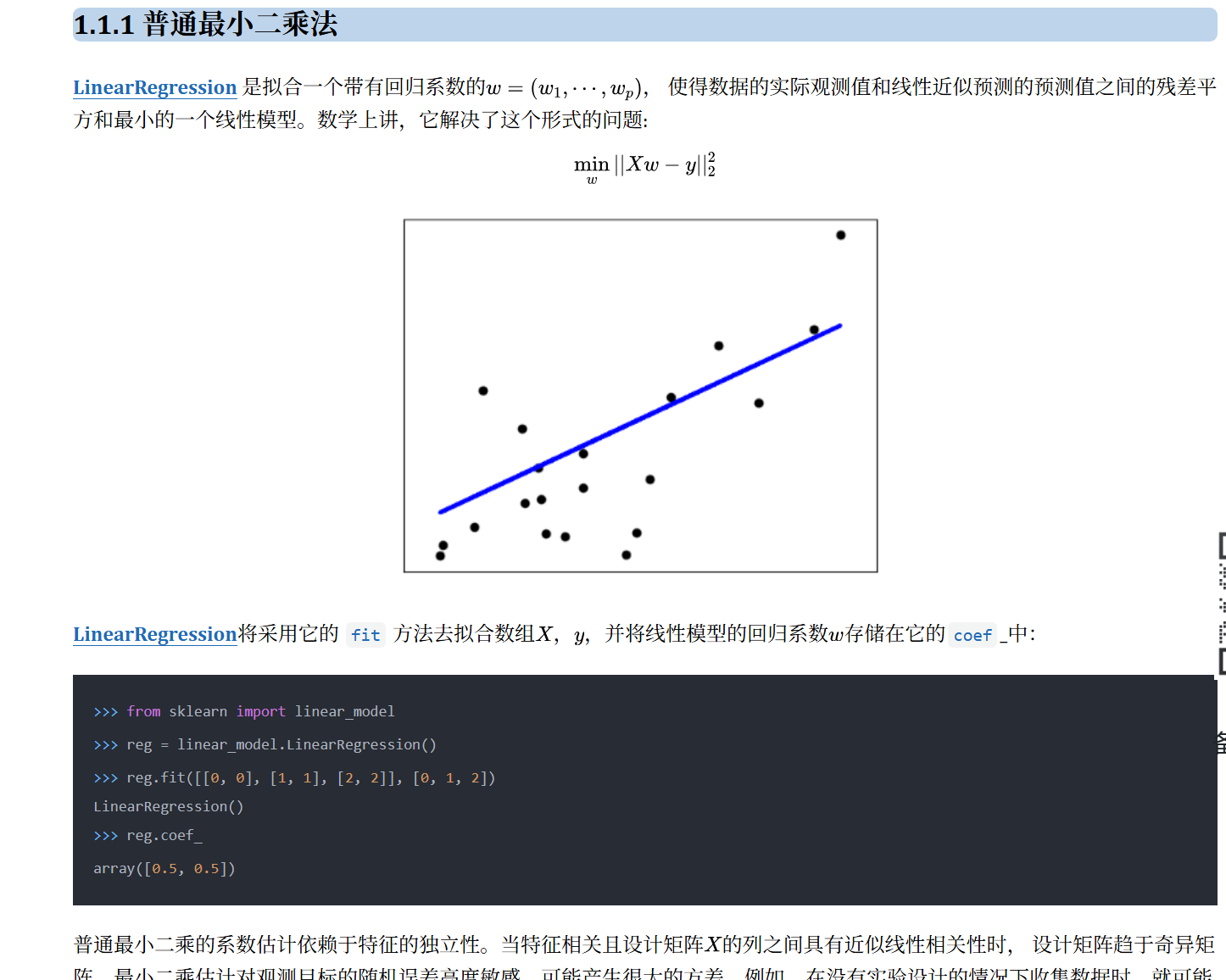
代码:
python
from sklearn import linear_model
import pandas as pd
df=pd.read_csv("data.csv",encoding="utf-8") #返回二维数据表格
x=df["广告投入"].values.reshape(-1,1) #线性回归方法必须接收二维的特征数据,因此这里用reshape将x变成二维
y=df["销售额"]
reg = linear_model.LinearRegression()
reg.fit(x,y)
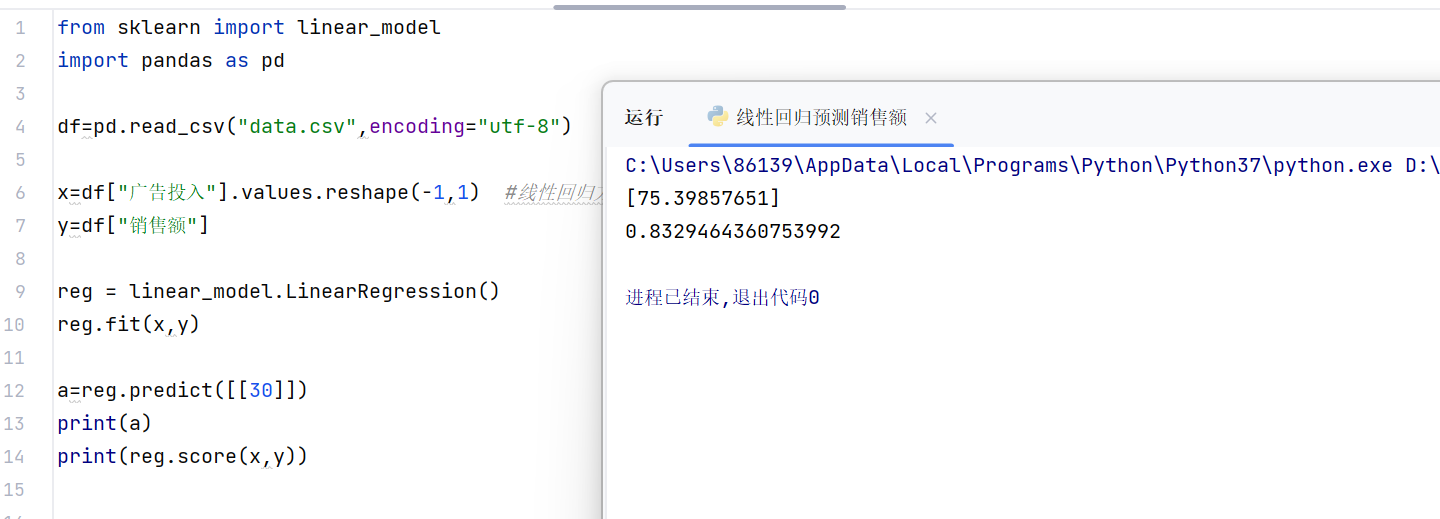
a=reg.predict([[30]])
print(a)
print(reg.score(x,y))执行结果: