文章目录
-
- [1. 理论概述](#1. 理论概述)
- [2. LangChain4J入门](#2. LangChain4J入门)
-
- [2.1 前置准备](#2.1 前置准备)
- [2.2 入门编码](#2.2 入门编码)
- [2.3 多模型共存](#2.3 多模型共存)
- [3. 整合SpringBoot](#3. 整合SpringBoot)
-
- [3.1 简述](#3.1 简述)
- [3.2 编码实现](#3.2 编码实现)
- [4. 低阶和高阶API](#4. 低阶和高阶API)
-
- [4.1 概述](#4.1 概述)
- [4.2 代码案例](#4.2 代码案例)
-
- [4.2.1 低级API案例](#4.2.1 低级API案例)
- [4.2.2 高阶API案例](#4.2.2 高阶API案例)
- [5. 模型参数配置](#5. 模型参数配置)
-
- [5.1 概述](#5.1 概述)
- [5.2 编码实现](#5.2 编码实现)
-
- [5.2.1 日志配置](#5.2.1 日志配置)
- [5.2.2 监控配置(可观测性)](#5.2.2 监控配置(可观测性))
- [5.2.3 重试配置](#5.2.3 重试配置)
- [5.2.4 请求超时](#5.2.4 请求超时)
- [6. 多模态视觉理解](#6. 多模态视觉理解)
-
- [6.1 概述](#6.1 概述)
- [6.2 代码实现](#6.2 代码实现)
- [6.3 文生图](#6.3 文生图)
-
- [6.3.1 概述](#6.3.1 概述)
- [6.3.2 代码实现](#6.3.2 代码实现)
- [7. 流式输出](#7. 流式输出)
-
- [7.1 概述](#7.1 概述)
- [7.2 代码实现](#7.2 代码实现)
- [8. 记忆缓存ChatMemory](#8. 记忆缓存ChatMemory)
-
- [8.1 概述](#8.1 概述)
- [8.2 代码实现](#8.2 代码实现)
- [9. 提示词工程](#9. 提示词工程)
-
- [9.1 概述](#9.1 概述)
- [9.2 代码实现](#9.2 代码实现)
-
- [9.2.1 案例一](#9.2.1 案例一)
- [9.2.2 案例二](#9.2.2 案例二)
- [9.2.3 案例三](#9.2.3 案例三)
- [10. 记忆持久化ChatMemoryStore](#10. 记忆持久化ChatMemoryStore)
-
- [10.1 概述](#10.1 概述)
- [10.2 代码实现](#10.2 代码实现)
- [11. FunctionCalling](#11. FunctionCalling)
-
- [11.1 概述](#11.1 概述)
- [11.2 代码实现](#11.2 代码实现)
-
- [11.2.1 方式一:手动](#11.2.1 方式一:手动)
- [11.2.2 方式二:注解方式](#11.2.2 方式二:注解方式)
- [12. 向量化](#12. 向量化)
-
- [12.1 概述](#12.1 概述)
- [12.2 Qdrant数据库](#12.2 Qdrant数据库)
- [12.3 代码实现](#12.3 代码实现)
- [13. RAG](#13. RAG)
-
- [13.1 概述](#13.1 概述)
- [13.2 代码实现](#13.2 代码实现)
- [14. MCP](#14. MCP)
-
- [14.1 概述](#14.1 概述)
- [14.2 代码实现](#14.2 代码实现)
1. 理论概述
官网文档(中文):https://docs.langchain4j.info/
官网文档(英文):https://docs.langchain4j.dev/
LangChain4J就是LangChain for Java。
注意:LangChain4J最低支持JDK17。
本文档基于JDK21。
在没有LangChain4J之前:
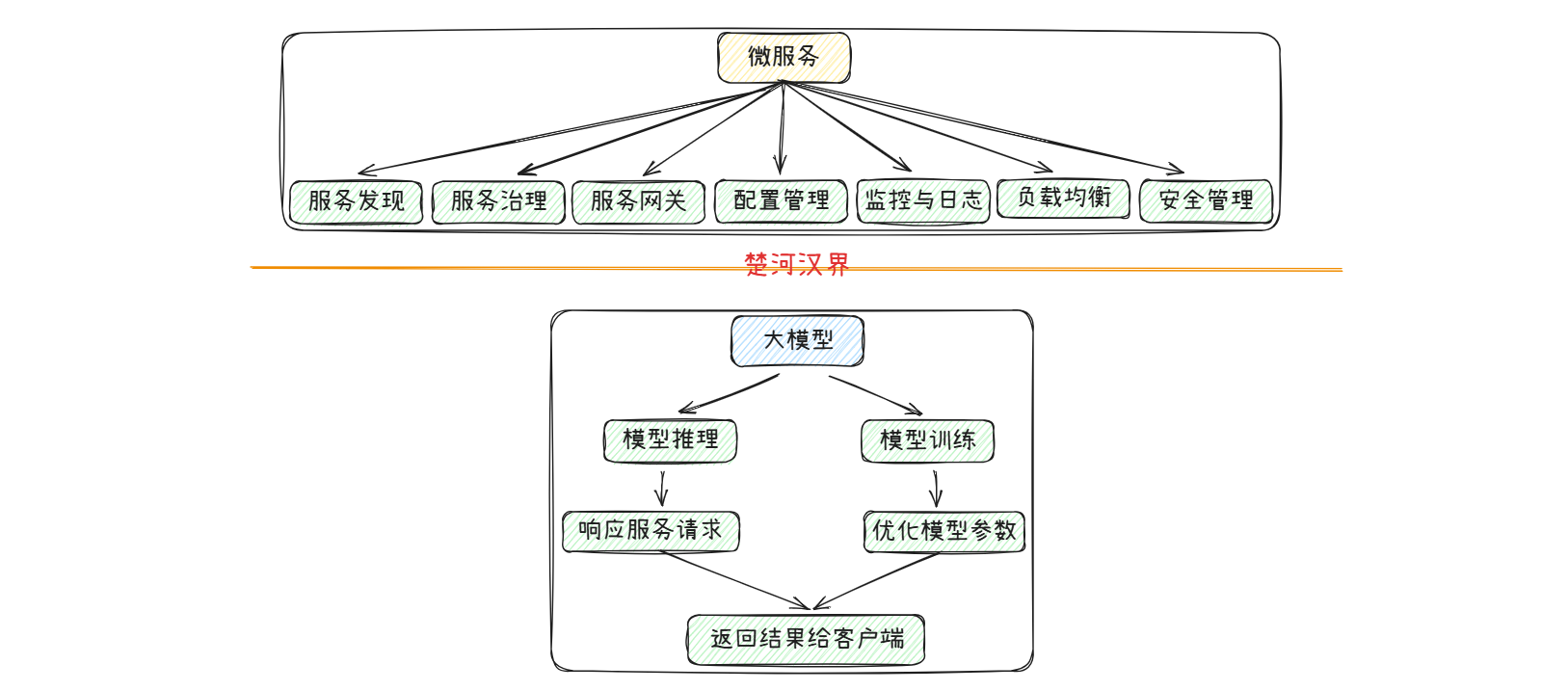
在LangChain4J出现后:
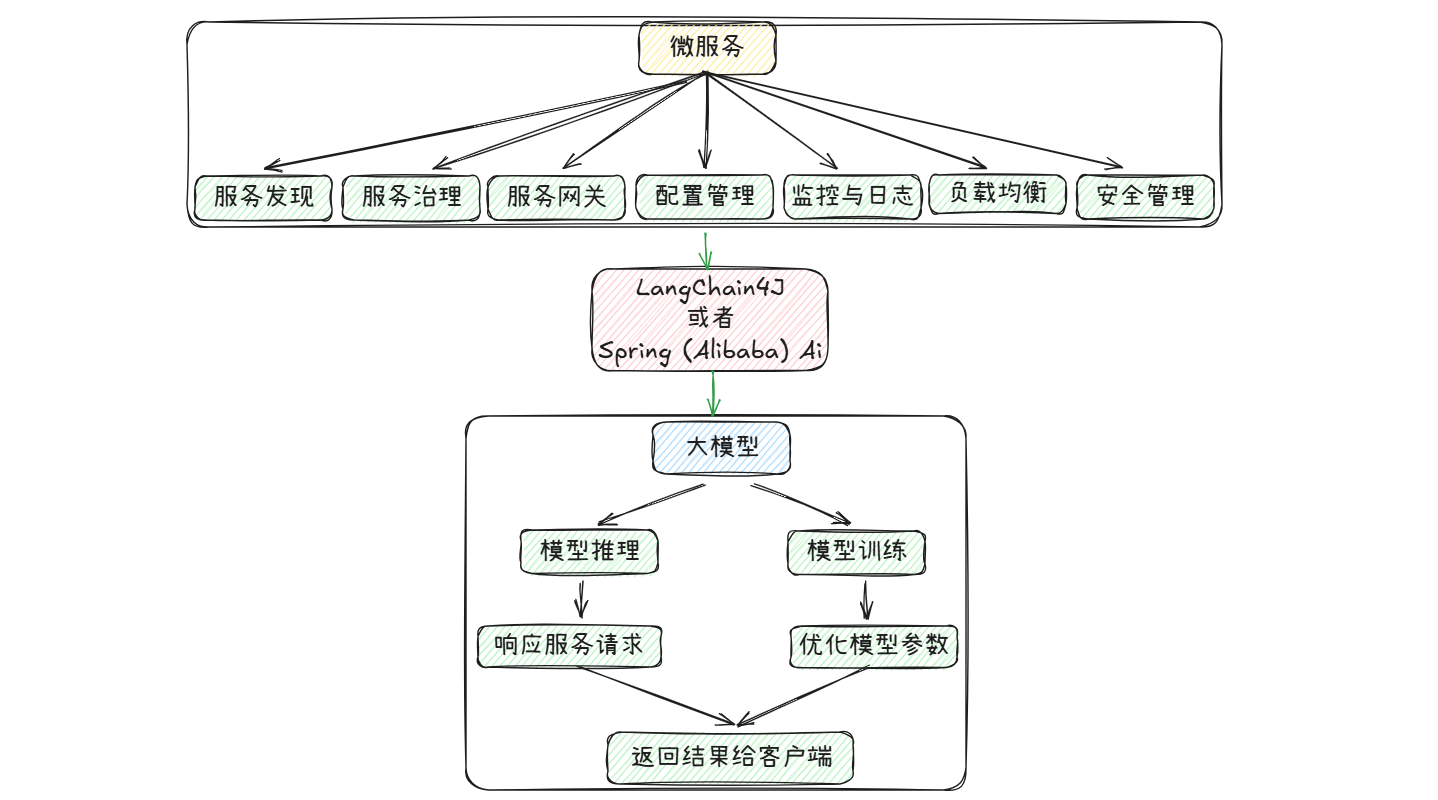
2. LangChain4J入门
2.1 前置准备
LangChain4J支持的各种大语言模型:https://docs.langchain4j.info/integrations/language-models/
如果我们想用的模型不在上诉支持列表中,只要该模型符合OpenAI协议,也是可以调通的。OpenAI协议是比较通用的。
本次学习,以阿里百炼平台(通义千问)为主并辅以七牛云平台(DeepSeek模型)。
后续配置规则,所有调用均基于
OpenAI协议标准或者SpringBoot官方推荐整合规则,实现一致的接口设计与规范,确保多模型切换的便利性,提供高度可扩展的开发支持。
阿里云百炼平台官网:https://bailian.console.aliyun.com/
大模型调用三件套:
- 获得
API-Key - 获得
模型Code - 获得
BaseUrl开发地址
1. 获取API Key
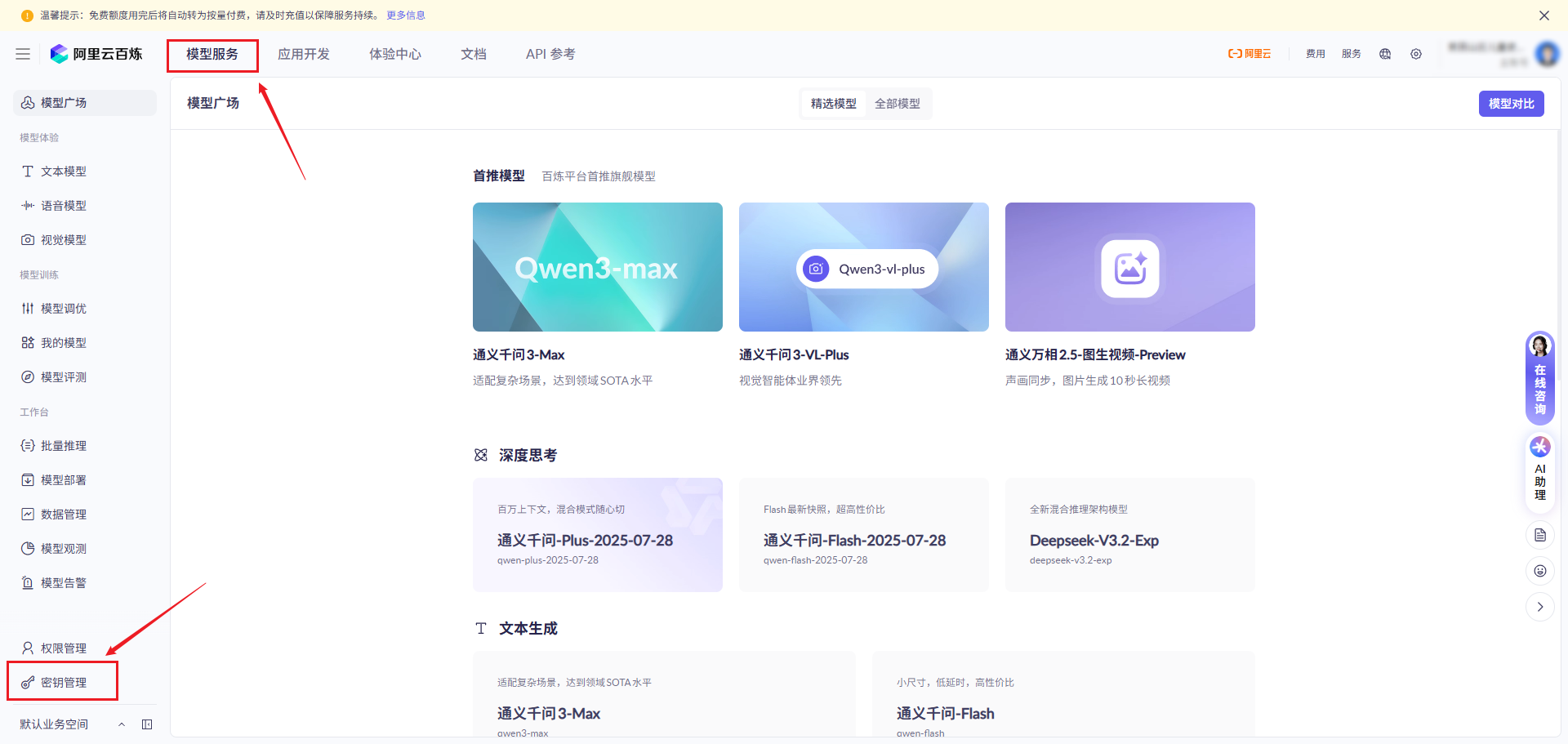
2. 获取模型名
在阿里云百炼平台,选择模型广场后,选择通义千问-plus,查看详情。模型Code为qwen-plus。
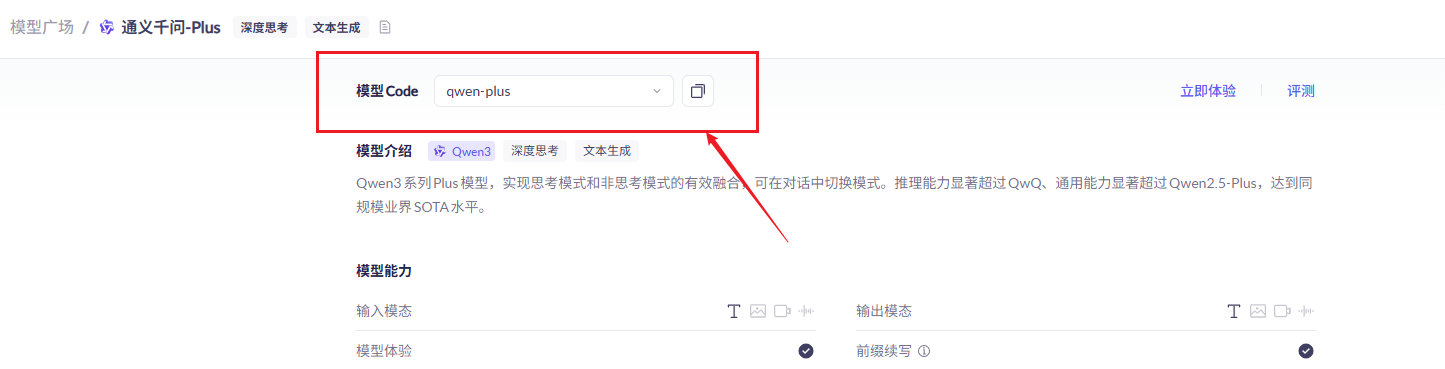
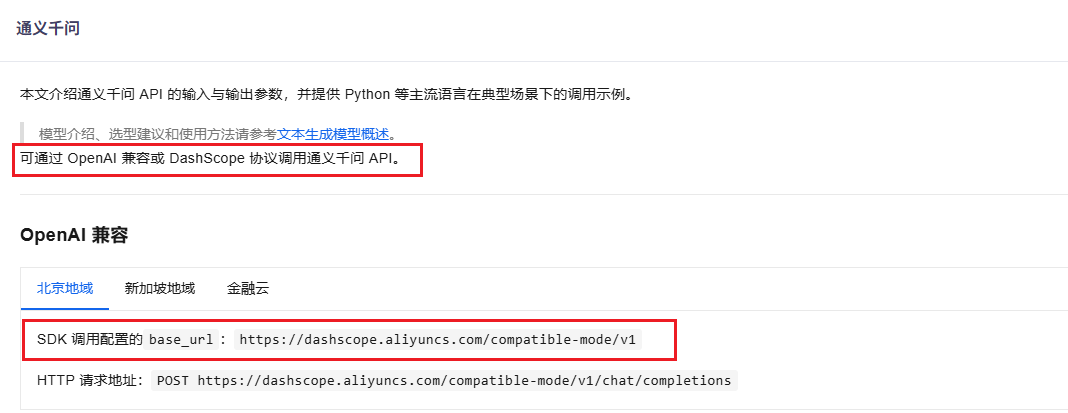
3. 获取BaseUrl开发地址
在阿里云百炼平台,选择模型广场后,选择通义千问-plus,点击查看API参考。BaseUrl为https://dashscope.aliyuncs.com/compatible-mode/v1。
2.2 入门编码
1. 新建Project父工程
项目名称:LangChainStudy。
父工程初始Maven:
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.mango</groupId>
<artifactId>LangChainStudy</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>pom</packaging>
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>21</java.version>
<spring.boot.version>3.5.0</spring.boot.version>
<langchain4j.version>1.0.1</langchain4j.version>
<langchain4j-community.version>1.0.1-beta6</langchain4j-community.version>
<maven-deploy-plugin.version>3.1.1</maven-deploy-plugin.version>
<maven-compiler-plugin.version>3.8.1</maven-compiler-plugin.version>
<flatten-maven-plugin.version>1.3.0</flatten-maven-plugin.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring.boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>${langchain4j-community.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring.boot.version}</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-deploy-plugin</artifactId>
<version>${maven-deploy-plugin.version}</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven-compiler-plugin.version}</version>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>flatten-maven-plugin</artifactId>
<version>${flatten-maven-plugin.version}</version>
<inherited>true</inherited>
<executions>
<execution>
<id>flatten</id>
<phase>process-resources</phase>
<goals>
<goal>flatten</goal>
</goals>
<configuration>
<updatePomFile>true</updatePomFile>
<flattenMode>ossrh</flattenMode>
<pomElements>
<distributionManagement>remove</distributionManagement>
<dependencyManagement>remove</dependencyManagement>
<scm>keep</scm>
<url>keep</url>
<organization>resolve</organization>
</pomElements>
</configuration>
</execution>
<execution>
<id>flatten.clean</id>
<phase>clean</phase>
<goals>
<goal>clean</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
<repository>
<id>aliyunmaven</id>
<name>aliyun</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>public</id>
<name>aliyun nexus</name>
<url>https://maven.aliyun.com/repository/public</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</project>新建子模块
模块名称:langchain4j-hellword
修改pom文件
xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>修改配置文件
yaml
server:
port: 9001
spring:
application:
name: langchain4j-helloword
logging:
level:
com.mango: info启动类
java
@SpringBootApplication
public class HelloLangChain4JApp {
public static void main(String[] args) {
SpringApplication.run(HelloLangChain4JApp.class, args);
}
}编写配置类
ApiKey最好不要明文写入配置文件,建议配置进环境变量。
可以配置到系统环境变量中,也可以在项目启动时配置启动参数。
新建大模型相关配置类LLMConfig
java
@Configuration
public class LLMConfig {
@Value("${qwen-key}")
private String qwenApiKey;
@Bean
public ChatModel qwenChatModel() {
return OpenAiChatModel.builder()
.apiKey(qwenApiKey)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.modelName("qwen-plus")
.build();
}
}在上诉代码中,qwenApiKey是在启动项目时通过--qwen-key="sk-xxxxxx"传入的。
Controller测试
编写一个HelloLangChainController进行测试
java
@Slf4j
@RestController
@RequestMapping("/langchain4j")
public class HelloLangChainController {
@Autowired
private ChatModel chatModel;
@RequestMapping(value = "/hello",method = RequestMethod.GET)
public String chat(@RequestParam("question") String question) {
String result = chatModel.chat(question);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}
}访问http://localhost:9001/langchain4j/hello?question=什么是Java,就可以看到大模型回复了!
2.3 多模型共存
配置使用DeepSeek模型。此处,我们通过七牛云平台来调用DeepSeek模型。
七牛云:https://portal.qiniu.com/ai-inference/model
相应的,获取API Key,模型Code与调用地址。
- API Key:
sk-xxxxxxxxxxxxxxxx - 模型Code:deepseek-v3-0324
- 模型Code:deepseek-r1-0528 (深度思考)
- BaseUrl:
https://api.qnaigc.com/v1
新建子模块
模块名称:langchain4j-multimodel
编写pom配置,此处省略,同上面的pom配置。
编写启动类,此处省略。
编写yaml,同上面的配置,只是修改了端口号为9002。
编写大模型配置类
java
@Configuration
public class LLMConfig {
@Value("${qn-key}")
private String qnApiKey;
@Bean
public ChatModel deepseekr1ChatModel() {
return OpenAiChatModel.builder()
.apiKey(qnApiKey)
.modelName("deepseek-r1-0528")
.baseUrl("https://api.qnaigc.com/v1")
.build();
}
@Bean
public ChatModel deepseekv3ChatModel() {
return OpenAiChatModel.builder()
.apiKey(qnApiKey)
.modelName("deepseek-v3-0324")
.baseUrl("https://api.qnaigc.com/v1")
.build();
}
}在上诉代码中,qnApiKey是在启动项目时通过--qn-key="sk-xxxxxx"传入的。
Controller测试
编写一个MultiModelController进行测试
java
@Slf4j
@RestController
@RequestMapping("/multiModel")
public class MultiModelController {
@Resource(name = "deepseekr1ChatModel")
private ChatModel deepseekr1ChatModel;
@Resource(name = "deepseekv3ChatModel")
private ChatModel deepseekv3ChatModel;
@RequestMapping(value = "/chatWithR1",method = RequestMethod.GET)
public String chatWithR1(@RequestParam("question") String question) {
String result = deepseekr1ChatModel.chat(question);
log.info("问题:{}", question);
log.info("deepseekr1回答:{}",result);
return result;
}
@RequestMapping(value = "/chatWithV3",method = RequestMethod.GET)
public String chatWithV3(@RequestParam("question") String question) {
String result = deepseekv3ChatModel.chat(question);
log.info("问题:{}", question);
log.info("deepseekv3回答:{}",result);
return result;
}
}通过访问http://localhost:9002/multiModel/chatWithR1?question=你是谁和http://localhost:9002/multiModel/chatWithV3?question=你是谁进行测试。
3. 整合SpringBoot
3.1 简述
相关文档:https://docs.langchain4j.info/tutorials/spring-boot-integration
LangChain4J和SpringBoot整合有两种方式:
- 流行的集成(低级API方式),意思为直接使用LangChain4J的原生底层函数接口进行开发。
- 声明式AI服务(高阶API方式),有些像用MybatisPlus的感觉。
使用流行的集成(低级API方式)所需要的依赖,例如基于OpenAI协议的:
Spring Boot 启动器依赖项的命名约定是:langchain4j-{integration-name}-spring-boot-starter。
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.0.0-beta3</version>
</dependency>使用声明式AI服务(高阶API方式)所需要的依赖:
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.0.0-beta3</version>
</dependency>相比于原生的依赖支持,带有SpringBoot启动器的依赖可以支持使用yaml配置LangChain4J,并且可以使用
@AiService等注解。
3.2 编码实现
新建子模块
模块名称:langchain4j-springboot
编写pom文件
xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--langchain4j 低阶-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
</dependency>
<!--langchain4j 高阶-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>编写yaml配置
yaml
server:
port: 9003
spring:
application:
name: langchain4j-springboot
logging:
level:
com.mango: info
langchain4j:
open-ai:
chat-model:
api-key: ${qwen-key}
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
model-name: qwen-plus在上述配置中,qwen-key是在启动项目时,通过参数--qwen-key="sk-xxxxxxxxx"进行传入。
同样的,如果我们不想使用yaml的方式配置,也可以使用配置类。
java
@Configuration
public class ChatConfig {
@Value("${qwen-key}")
private String qwenApiKey;
@Bean
public ChatModel qwenChatModel() {
return OpenAiChatModel.builder()
.apiKey(qwenApiKey)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.modelName("qwen-plus")
.build();
}
}启动类同前面的例子,此处省略。
业务类,第一种:低阶API
新建PolularIntegrationController
java
@Slf4j
@RestController
@RequestMapping("/popular")
public class PopularIntegrationController {
@Autowired
private ChatModel chatModel;
@RequestMapping(value = "/chat",method = RequestMethod.GET)
public String chat(@RequestParam("question") String question) {
String result = chatModel.chat(question);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}
}访问http://localhost:9003/popular/chat?question=你是谁进行测试。
业务类,第二种:高阶API
新建ChatAssistant接口
java
@AiService
public interface ChatAssistant {
String chat(String question);
}新建DeclarativeAiServiceController
java
@Slf4j
@RestController
@RequestMapping("/declarative")
public class DeclarativeAiServiceController {
@Autowired
private ChatAssistant chatAssistant;
@RequestMapping(value = "/chat",method = RequestMethod.GET)
public String chat(@RequestParam("question") String question) {
String result = chatAssistant.chat(question);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}
}访问http://localhost:9003/declarative/chat?question=你是谁进行测试。
4. 低阶和高阶API
4.1 概述
相关文档(低阶):https://docs.langchain4j.info/tutorials/chat-and-language-models
相关文档(高阶):https://docs.langchain4j.info/tutorials/ai-services
1. 低阶API
在这个层次上,拥有最大的自由度和访问所有低级组件的权限,如ChatModel、UserMessage、AiMessage、EmbeddingStore、Embedding 等。 这些是LLM驱动应用程序的"原语"。 我们可以完全控制如何组合它们,但需要编写更多的代码。
2. 高阶API
在这个层次上,我们使用高级 API(如AiService)与 LLM 交互, 它隐藏了所有复杂性和样板代码。 我们仍然可以灵活地调整和微调行为,但是以声明式方式完成。
4.2 代码案例
新建子模块
模块名称:langchain4j-low-high
编写pom文件
xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--引入langchain4j依赖(原生)-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>注意:此处我们引入的LangChain4J依赖,不是springboot版本的,而是原生的。
编写yaml配置
yaml
server:
port: 9004
spring:
application:
name: langchain4j-low-high
logging:
level:
com.mango: info启动类,同前面案例,此处省略。
4.2.1 低级API案例
编写配置类
java
@Configuration
public class LLMConfig {
@Value("${qwen-key}")
private String qwenApiKey;
@Value("${qn-key}")
private String qnApiKey;
@Bean
public ChatModel qwenChatModel() {
return OpenAiChatModel.builder()
.apiKey(qwenApiKey)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.modelName("qwen-plus")
.build();
}
@Bean
public ChatModel deepSeekV3ChatModel() {
return OpenAiChatModel.builder()
.apiKey(qnApiKey)
.baseUrl("https://api.qnaigc.com/v1")
.modelName("deepseek-v3-0324")
.build();
}
}编写Controller测试
java
@Slf4j
@RestController
@RequestMapping("/lower")
public class LowerController {
@Resource(name = "qwenChatModel")
private ChatModel qwenChatModel;
@RequestMapping(value = "/chatWithQwen",method = RequestMethod.GET)
public String chatWithQwen(@RequestParam("question") String question) {
String result = qwenChatModel.chat(question);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}
}访问http://localhost:9004/lower/chatWithQwen?question=你好进行测试。
理解:大模型中的Token
token 是模型用来表示自然语言文本的基本单位,也是我们的计费单元,可以直观的理解为"字"或"词"。
通常1个中文词语、1个英文单词、1个数字或1个符号计为1个 token。
一般情况下模型中 token 和字数的换算比例大致如下:
- 1 个英文字符 ≈ 0.3 个 token。
- 1 个中文字符 ≈ 0.6 个 token。
但因为不同模型的分词不同,所以换算比例也存在差异,每一次实际处理 token 数量以模型返回为准。
我们可以在调用大模型接口时,获取到对应的Token值。
修改LowerController
java
@RequestMapping(value = "/chatWithQwen",method = RequestMethod.GET)
public String chatWithQwen(@RequestParam("question") String question) {
//String result = qwenChatModel.chat(question);
ChatResponse response = qwenChatModel.chat(UserMessage.from(question));
String result = response.aiMessage().text();
Integer inputTokenCount = response.tokenUsage().inputTokenCount();
Integer outputTokenCount = response.tokenUsage().outputTokenCount();
Integer totalTokenCount = response.tokenUsage().totalTokenCount();
log.info("问题:{}", question);
log.info("答案:{}", result);
log.info("输入token数:{}", inputTokenCount);
log.info("输出token数:{}", outputTokenCount);
log.info("总token数:{}", totalTokenCount);
return result;
}4.2.2 高阶API案例
定义接口Assistant
首先,我们定义一个带有单个方法 chat 的接口,该方法接受 String 作为输入并返回 String。
java
public interface ChatAssistant {
String chat(String question);
}编写配置类LLMConfig
在前面,我们在LLMConfig中已经对模型进行了相关的配置。
此处,我们需要在LLMConfig中再增加对ChatAssistant的配置。
java
@Bean
public ChatAssistant qwenChatAssistant(@Qualifier("qwenChatModel") ChatModel chatModel){
return AiServices.create(ChatAssistant.class, chatModel);
}
@Bean
public ChatAssistant deepseekV3ChatAssistant(@Qualifier("deepSeekV3ChatModel") ChatModel chatModel){
return AiServices.create(ChatAssistant.class, chatModel);
}这样,在Controller中,我们就可以通过对应的ChatAssistant来调用其方法。
编写HighController
使用
AiServices.create()指定模型与Service,获得ChatAssistant。
java
@Slf4j
@RestController
@RequestMapping("/high")
public class HighController {
@Resource(name = "qwenChatAssistant")
private ChatAssistant qwenChatAssistant;
@Resource(name = "deepseekV3ChatAssistant")
private ChatAssistant deepseekV3ChatAssistant;
@RequestMapping(value = "/chatWithQwen",method = RequestMethod.GET)
public String chatWithQwen(@RequestParam("question") String question) {
String result = qwenChatAssistant.chat(question);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}
@RequestMapping(value = "/chatWithDeepseekV3",method = RequestMethod.GET)
public String chatWithDeepseekV3(@RequestParam("question") String question) {
String result = deepseekV3ChatAssistant.chat(question);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}
}ChatAssistant(AiService)的返回值类型
AI 服务方法可以返回以下类型之一:
-
String:在这种情况下,LLM 生成的输出将不经任何处理/解析直接返回。 -
结构化输出支持的任何类型:在这种情况下, AI 服务将在返回之前将 LLM 生成的输出解析为所需类型。任何类型都可以额外包装在
Result<T>中,以获取有关 AI 服务调用的额外元数据:-
TokenUsage- AI 服务调用期间使用的令牌总数。如果 AI 服务对 LLM 进行了多次调用 (例如,因为执行了工具),它将汇总所有调用的令牌使用情况。 -
Sources - 在RAG检索期间检索到的
Content -
已执行的工具
-
FinishReason
-
如:
在我们定义的ChatAssistant中
java
public interface ChatAssistant {
String chat(String question);
// 结构化输出
Result<String> chatWithResult(String question);
}在Controller中进行调用
java
@RequestMapping(value = "/chatWithResult",method = RequestMethod.GET)
public String chatWithResult(@RequestParam("question") String question) {
Result result = deepseekV3ChatAssistant.chatWithResult(question);
TokenUsage tokenUsage = result.tokenUsage();
Integer inputTokenCount = tokenUsage.inputTokenCount();
Integer outputTokenCount = tokenUsage.outputTokenCount();
log.info("问题:{}", question);
log.info("答案:{}", result);
log.info("输入token数:{}", inputTokenCount);
log.info("输出token数:{}", outputTokenCount);
return result.content().toString();
}5. 模型参数配置
5.1 概述
在进行模型配置时,除了模型地址,APIkey,模型名称,我们还可以配置其他很多参数。
包括日志监控、重试次数、最大Token值、大模型温度(Temperature)系数等。我们可以对其进行配置。
| 参数 | 描述 | 类型 |
|---|---|---|
modelName |
要使用的模型名称(例如,deepseek-v3-0324、qwen-plus等) | String |
temperature |
使用的采样温度,介于0和2之间。较高的值如0.8会使输出更随机,而较低的值如0.2会使其更集中和确定性。 | Double |
maxTokens |
在聊天完成中可以生成的最大令牌数。 | Integer |
frequencyPenalty |
介于-2.0和2.0之间的数字。正值会根据文本中已有的频率惩罚新令牌,降低模型逐字重复相同行的可能性。 | Double |
| ... | ... | ... |
更加完整的OpenAI协议参数,可参考:
properties
# 必需属性:
langchain4j.open-ai.chat-model.api-key=...
langchain4j.open-ai.chat-model.model-name=...
# 可选属性:
langchain4j.open-ai.chat-model.base-url=...
langchain4j.open-ai.chat-model.custom-headers=...
langchain4j.open-ai.chat-model.frequency-penalty=...
langchain4j.open-ai.chat-model.log-requests=...
langchain4j.open-ai.chat-model.log-responses=...
langchain4j.open-ai.chat-model.logit-bias=...
langchain4j.open-ai.chat-model.max-retries=...
langchain4j.open-ai.chat-model.max-completion-tokens=...
langchain4j.open-ai.chat-model.max-tokens=...
langchain4j.open-ai.chat-model.metadata=...
langchain4j.open-ai.chat-model.organization-id=...
langchain4j.open-ai.chat-model.parallel-tool-calls=...
langchain4j.open-ai.chat-model.presence-penalty=...
langchain4j.open-ai.chat-model.project-id=...
langchain4j.open-ai.chat-model.reasoning-effort=...
langchain4j.open-ai.chat-model.response-format=...
langchain4j.open-ai.chat-model.seed=...
langchain4j.open-ai.chat-model.service-tier=...
langchain4j.open-ai.chat-model.stop=...
langchain4j.open-ai.chat-model.store=...
langchain4j.open-ai.chat-model.strict-schema=...
langchain4j.open-ai.chat-model.strict-tools=...
langchain4j.open-ai.chat-model.supported-capabilities=...
langchain4j.open-ai.chat-model.temperature=...
langchain4j.open-ai.chat-model.timeout=...
langchain4j.open-ai.chat-model.top-p=
langchain4j.open-ai.chat-model.user=...注意:下文中,只写了4个参数配置案例,其他参数配置大同小异。
5.2 编码实现
新建子模块
模块名称:langchain4j-parameters
maven配置与上一案例中maven配置相同,此处省略。
yaml配置
yaml
server:
port: 9005
spring:
application:
name: langchain4j-parameters
logging:
level:
com.mango: info编写ChatAssistant(AiService)
java
public interface ChatAssistant {
String chat(String question);
// 结构化输出
Result<String> chatWithResult(String question);
}编写配置类LLMConfig
保留最基础的配置。
java
@Configuration
public class LLMConfig {
@Value("${qwen-key}")
private String qwenApiKey;
@Bean
public ChatModel qwenChatModel() {
return OpenAiChatModel.builder()
.apiKey(qwenApiKey)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.modelName("qwen-plus")
.build();
}
@Bean
public ChatAssistant qwenChatAssistant(@Qualifier("qwenChatModel") ChatModel chatModel){
return AiServices.create(ChatAssistant.class, chatModel);
}
}编写Controller
java
@Slf4j
@RestController
@RequestMapping("/parameters")
public class ParametersController {
@Resource(name = "qwenChatAssistant")
private ChatAssistant qwenChatAssistant;
@RequestMapping(value = "/chat",method = RequestMethod.GET)
public String chat(String question) {
String result = qwenChatAssistant.chat(question);
log.info("问题:{}", question);
log.info("结果:{}", result);
return result;
}
}到此,我们完成了进行参数配置前的准备工作。下面进行各参数配置的详细说明。
5.2.1 日志配置
LangChain4j 使用SL4J进行日志记录, 允许我们插入任何我们喜欢的日志后端, 例如LogBack或者Log4J)。
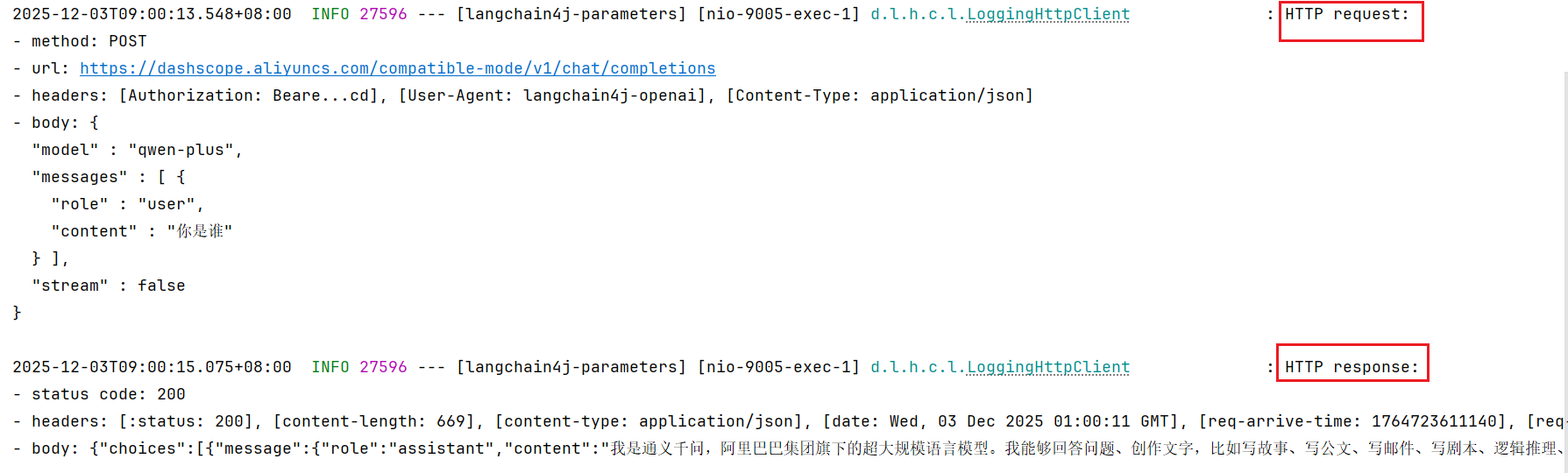
可以通过在创建模型实例时设置 .logRequests(true) 和 .logResponses(true) 来启用对 LLM 的每个请求和响应的日志记录。
代码实现
在LLMConfig中
java
@Bean
public ChatModel qwenChatModel() {
return OpenAiChatModel.builder()
....
.logRequests(true)
.logResponses(true)
.build();
}在application.yaml中,设置日志级别
yaml
logging:
level:
com.mango: info
dev.langchain4j: debug # 配置langchain4j的日志级别注意:只有日志级别调整为debug级别,同时配置以上LangChain日志输出开关,才能有效。
启动项目,访问http://localhost:9005/parameters/chat?question=你好,可以看到控制台的日志输出。
5.2.2 监控配置(可观测性)
某些 ChatModel 和 StreamingChatModel 的实现允许配置 ChatModelListener(多个)来监听事件,例如:
- 向 LLM 发送的请求
- 来自 LLM 的响应
- 错误
这些事件包括各种属性,例如:
- 请求:消息、模型、温度、Top P、最大令牌数、工具、响应格式、等等
- 响应:助手消息、ID、模型、令牌使用情况、完成原因、等等
代码实现
新建一个MyChatListener,继承ChatModelListener
onRequest配置的
K:V键值对,在onResponse阶段可以获取到,上下文传递参数好用
java
@Slf4j
public class MyChatListener implements ChatModelListener {
@Override
public void onRequest(ChatModelRequestContext requestContext) {
// onRequest配置的K:V键值对,在onResponse阶段可以获取到,上下文传递参数好用
String uuid = UUID.randomUUID().toString();
requestContext.attributes().put("TraceID", uuid);
log.info("发送请求:{}-{}", requestContext,uuid);
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
Object traceId = responseContext.attributes().get("TraceID");
log.info("请求响应:{}-{}", responseContext,traceId);
}
@Override
public void onError(ChatModelErrorContext errorContext) {
log.info("请求错误:{}", errorContext);
}
}通过requestContext、responseContext、errorContext,调用其一些方法,可以获取到一些具体的信息,此处不再展开。
在LLMConfig中配置监听器
java
@Bean
public ChatModel qwenChatModel() {
return OpenAiChatModel.builder()
....
.listeners(List.of(new MyChatListener())) // 配置监听器
.build();
}启动项目后,访问http://localhost:9005/parameters/chat?question=你好,可以看到控制台的输出。


5.2.3 重试配置
在网络故障的的情况下,调用大模型接口失败,会自动进行重试调用,默认情况下,会重试3次。
代码实现
在LLMConfig中进行配置
java
@Bean
public ChatModel qwenChatModel() {
return OpenAiChatModel.builder()
....
.maxRetries(3) // 配置最大重试调用次数:3次
.build();
}关闭WIFI,启动项目,访问http://localhost:9005/parameters/chat?question=你好,查看控制台输出。

出现了警告,正在进行尝试进行第2次调用,最大尝试3次。
此外,可以在控制台中看到,我们前面配置的错误(onError)监听器,在重试调用3次后,自动调用了该监听器。并不是每重试失败1次则调用1次,而是全部重试结束后才会进行调用。

5.2.4 请求超时
在指定时间内没有收到响应,该请求将被中断,并报request timeout。
代码实现
在LLMConfig中进行配置
java
@Bean
public ChatModel qwenChatModel() {
return OpenAiChatModel.builder()
....
.timeout(Duration.ofSeconds(1)) // 配置超时时间:1s,在此是为了做演示,一般大模型回复较慢,实际配置根据业务情景
.build();
}为了方便测试,我们这里配置了超时时间为:1s。
因为大模型的响应速度是偏慢的,所以1s会超时。在实际开发中,根据业务需求来确定超时时间。
启动项目,访问http://localhost:9005/parameters/chat?question=你好,查看控制台输出。

可以看到报了TimeoutException异常,超时时间已生效。
并且,由于我们前面配置了重试,在请求超时后,自动进行了3次的请求重试调用。
6. 多模态视觉理解
6.1 概述
UserMessage 不仅可以包含文本,还可以包含其他类型的内容。 UserMessage 包含 List<Content> contents。 Content 是一个接口,有以下实现:
TextContent:文本ImageContent:图像AudioContent:音频VideoContent:视频PdfFileContent:PDF文件
注意:需要查看模型服务提供商的说明,看模型具体支持哪些模态。
相关文档:https://docs.langchain4j.info/integrations/language-models
此处,我们选择qwen3-vl-plus模型进行学习测试。
6.2 代码实现
新建子模块
模块名称:langchain4j-vision
pom依赖配置同前面案例。
上传一张静态图片
在resource/statis/images目录下,上传一张图片,此处,我上传了一张简历图片。
编写yaml配置
yaml
server:
port: 9006
spring:
application:
name: langchain4j-vision
logging:
level:
com.mango: info编写LLMConfig
java
@Configuration
public class LLMConfig {
@Value("${qwen-key}")
private String qwenApiKey;
@Bean
public ChatModel qwenChatModel() {
return OpenAiChatModel.builder()
.apiKey(qwenApiKey)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.modelName("qwen3-vl-plus")
.timeout(Duration.ofMinutes(5)) // 防止模型理解较慢,调大超时时间
.build();
}
}编写Controller进行测试
1.图片转码:通过Base64编码将图片转化为字符串
2.提示词指定:结合ImageContent和TextContent一起发送到模型进行处理。
3.API调用:使用OpenAiChatModel来构建请求,并通过chat()方法调用模型。请求内容包括文本提示和图片,模型会根据输入返回分析结果。
4.解析与输出:从ChatResponse中获取AI大模型的回复。
java
@Slf4j
@RestController
@RequestMapping("/vision")
public class VisionController {
@Autowired
private ChatModel qwenChatModel;
@Value("classpath:static/images/resume.png")
private Resource resource; // org.springframework.core.io.Resource
@RequestMapping(value = "/chat",method = RequestMethod.GET)
public String chat(@RequestParam("question") String question) throws IOException {
// 将图片转换为Base64字符串
byte[] contentAsByteArray = resource.getContentAsByteArray();
String image = Base64.getEncoder().encodeToString(contentAsByteArray);
// 封装UserMessage
UserMessage userMessage = UserMessage.from(
TextContent.from(question),
ImageContent.from(image, "image/png")
);
// 调用chat方法
ChatResponse response = qwenChatModel.chat(userMessage);
// 获取结果
String result = response.aiMessage().text();
log.info("问题:{}", question);
log.info("结果:{}", result);
return result;
}
}启动项目,访问http://localhost:9006/vision/chat?question=提取简历信息,等待比较久的时间后(后续采用流式输出进行解决),得到了大模型回复。

6.3 文生图
6.3.1 概述
在本案例中使用通义万相模型进行实现。
注意:
通义万相模型不支持OpenAI协议,但是其使用的是DashScope协议,所以langchain4j依然可以调用。
使用模型:wanx2.1-t2i-turbo
通义万相-文生图2.0-Turbo,更擅长质感人像和创意设计画作生成,在图像美观度、真实感、艺术性上全面升级,支持最大200万像素生成,支持智能提示词改写等。
当然,我们也可以选择使用通义万相的其他模型,包括文生视频,图生视频等。具体可参考:阿里百炼模型广场
通义万相不支持OpenAI协议,它使用DashScope协议,所以在使用上会有一些略微差别。
具体可参考文档:https://docs.langchain4j.info/integrations/language-models/dashscope
6.3.2 代码实现
本案例在模块langchain4j-vision中继续实现。
修改POM文件
添加依赖
可以选引入依赖langchain4j-community-dashscope(原生)或者langchain4j-community-dashscope-spring-boot-starter(对spring boot的支持),都是可以的。
以下依赖,二者选其一即可。
xml
<!--LangChain4J原生支持-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope</artifactId>
</dependency>
<!--LangChain4J带有SpringBoot启动器的支持-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>修改LLMConfig配置类
添加通义万相模型配置。
由于使用的直接是WanxImageModel,其地址是直接帮我们封装好了的,此处地址可以省略。
更多配置可参考:通义万相文生图v2,例如图片大小等。
java
@Bean
public WanxImageModel qwenWxModel() {
return WanxImageModel.builder()
.apiKey(qwenApiKey)
.modelName("wanx2.1-t2i-turbo")
.build();
}编写Controller进行测试
java
@Autowired
private WanxImageModel wanxImageModel;
@RequestMapping(value = "/chatWithImage",method = RequestMethod.GET)
public String chatWithImage(@RequestParam("question") String question) {
Response<Image> imageResponse = wanxImageModel.generate(question);
log.info(String.valueOf(imageResponse.content().url()));
return imageResponse.content().url().toString();
}启动项目,访问http://localhost:9006/vision/chatWithImage?question=俄罗斯美女,得到了响应结果。

7. 流式输出
7.1 概述
LLM 一次生成一个标记(token),因此许多 LLM 提供商提供了一种方式,可以逐个标记地流式传输响应,而不是等待整个文本生成完毕。 这显著改善了用户体验,因为用户不需要等待未知的时间,几乎可以立即开始阅读响应。
低级API实现参考文档:低阶API流式输出
高阶API实现参考文档:高阶API流式输出
对于 ChatModel 和 LanguageModel 接口,有相应的 StreamingChatModel 和 StreamingLanguageModel 接口。 这些接口有类似的 API,但可以流式传输响应。 它们接受 StreamingChatResponseHandler 接口的实现作为参数。
java
public interface StreamingChatResponseHandler {
void onPartialResponse(String partialResponse);
void onCompleteResponse(ChatResponse completeResponse);
void onError(Throwable error);
}通过实现 StreamingChatResponseHandler,我们可以为以下事件定义操作:
- 当生成下一个部分响应时:调用
onPartialResponse(String partialResponse)。 部分响应可以由单个或多个词语组成。 例如,我们可以在词语可用时立即将其发送到 UI。 - 当 LLM 完成生成时:调用
onCompleteResponse(ChatResponse completeResponse)。ChatResponse对象包含完整的响应(AiMessage)以及ChatResponseMetadata。 - 当发生错误时:调用
onError(Throwable error)。
我们可以使用 Flux<String> 代替 TokenStream。 为此,我们需要导入 langchain4j-reactor 依赖:
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.0.0-beta3</version>
</dependency>7.2 代码实现
前置知识:SpringBoot3响应式编程
新建子模块
模块名称:langchain4j-stream
编写pom
xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--引入langchain4j原生依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>编写yaml配置
yaml
server:
port: 9007
servlet: # 设置字符编码,防止流式输出乱码
encoding:
charset: UTF-8
enabled: true
force: true
spring:
application:
name: langchain4j-stream
logging:
level:
com.mango: info编写StreamChatAssistant接口
java
public interface StreamChatAssistant {
Flux<String> chatFlux(String question);
TokenStream chatTokenStream(String question);
}编写LLMConfig配置类
java
@Configuration
public class LLMConfig {
@Value("${qwen-key}")
private String qwen_key;
@Bean
public StreamingChatModel qwenChatModel() {
return OpenAiStreamingChatModel.builder()
.apiKey(qwen_key)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.modelName("qwen-plus")
.build();
}
@Bean
public StreamChatAssistant qwenStreamChatAssistant(@Qualifier("qwenChatModel") StreamingChatModel qwenChatModel) {
return AiServices.create(StreamChatAssistant.class, qwenChatModel);
}
}编写Controller测试
方式一:采用低级API方式,使用Flux
java
@Slf4j
@RestController
@RequestMapping("/stream")
public class StreamController {
@Autowired
private StreamingChatModel qwenChatModel;
@RequestMapping(value = "/chatByLower",method = RequestMethod.GET)
public Flux<String> chatFluxByLower(@RequestParam("question") String question) {
return Flux.create(fluxSink -> {
qwenChatModel.chat(question, new StreamingChatResponseHandler() {
@Override
public void onPartialResponse(String s) {
// 接收消息
fluxSink.next(s);
}
@Override
public void onCompleteResponse(ChatResponse chatResponse) {
log.info("对话结束..");
log.info("输入Token数:{}", chatResponse.tokenUsage().inputTokenCount());
log.info("输出Token数:{}", chatResponse.tokenUsage().outputTokenCount());
}
@Override
public void onError(Throwable throwable) {
log.error("对话异常:{}", throwable.getMessage());
}
});
});
}
}启动项目,访问http://localhost:9007/stream/chatByLower?question=你好,可以看到输出已经变成了流式。
方式二:采用低级API方式,不使用Flux
返回值类型为
void这种方式下,前端不会有任何的返回值,但是后端会得到大模型的回答。
java
@RequestMapping(value = "/chatByLowerNoFlux",method = RequestMethod.GET)
public void chatByLowerNoFlux(@RequestParam("question") String question) {
qwenChatModel.chat(question, new StreamingChatResponseHandler() {
@Override
public void onPartialResponse(String s) {
log.info("返回结果:{}",s);
}
@Override
public void onCompleteResponse(ChatResponse chatResponse) {
log.info("对话结束..");
log.info("输入Token数:{}", chatResponse.tokenUsage().inputTokenCount());
log.info("输出Token数:{}", chatResponse.tokenUsage().outputTokenCount());
}
@Override
public void onError(Throwable throwable) {
log.error("对话异常:{}", throwable.getMessage());
}
});
}
方式三:采用高级API方式,使用Flux
注意:在这种方式下,好像功能有限,无法做到对话的监控,比如获取Token。一般还是采用低级API的方式,功能更加强大。
java
@Autowired
private StreamChatAssistant streamChatAssistant;
@RequestMapping(value = "/chatByHigh",method = RequestMethod.GET)
public Flux<String> chatFluxByHigh(@RequestParam("question") String question) {
return streamChatAssistant.chatFlux(question);
}方式四:采用高级API,使用TokenStream
java
@RequestMapping(value = "/chatFluxByHighWithTokenStream", method = RequestMethod.GET)
public Flux<String> chatFluxByHighWithTokenStream(@RequestParam("question") String question) {
TokenStream tokenStream = streamChatAssistant.chatTokenStream(question);
return Flux.create(fluxSink -> {
tokenStream.onPartialResponse(token -> {
log.info("{}", token);
fluxSink.next(token);
});
tokenStream.onCompleteResponse(chatResponse -> {
log.info("输入Token数:{}", chatResponse.tokenUsage().inputTokenCount());
log.info("输出Token数:{}", chatResponse.tokenUsage().outputTokenCount());
fluxSink.complete();
});
tokenStream.onError(throwable -> {
log.error("流处理出错", throwable);
fluxSink.error(throwable);
});
// 启动流
tokenStream.start();
});
}8. 记忆缓存ChatMemory
8.1 概述
本节案例是基于高阶API的方式。
记忆缓存是聊天系统中的一个重要组件,用于存储和管理对话的上下文信息。它的主要作用是让AI助手能够"记住"之前的对话内容,从而提供连贯和个性化的回复。
记忆与历史
请注意,"记忆"和"历史"是相似但不同的概念。
- 历史保持用户和AI之间的所有消息完整无缺。历史是用户在UI中看到的内容。它代表实际对话内容。
- 记忆保存一些信息,这些信息呈现给LLM,使其表现得好像"记住"了对话。 记忆与历史有很大不同。根据使用的记忆算法,它可以以各种方式修改历史: 淘汰一些消息,总结多条消息,总结单独的消息,从消息中删除不重要的细节, 向消息中注入额外信息(例如,用于RAG)或指令(例如,用于结构化输出)等等。
LangChain4j目前只提供"记忆",而不是"历史"。如果需要保存完整的历史记录,需手动进行(保存至数据库)。
淘汰策略
淘汰策略是必要的,原因如下:
- 为了适应LLM的上下文窗口。LLM一次可以处理的令牌数量是有上限的。 在某些时候,对话可能会超过这个限制。在这种情况下,应该淘汰一些消息。 通常,最旧的消息会被淘汰,但如果需要,可以实现更复杂的算法。
- 控制成本。每个令牌都有成本,使每次调用LLM的费用逐渐增加。 淘汰不必要的消息可以降低成本。
- 控制延迟。发送给LLM的令牌越多,处理它们所需的时间就越长。
目前,LangChain4j提供了2种开箱即用的实现:
- 较简单的一种,
MessageWindowChatMemory,作为滑动窗口运行, 保留最近的N条消息,并淘汰不再适合的旧消息。 然而,由于每条消息可能包含不同数量的令牌,MessageWindowChatMemory主要用于快速原型设计。 - 更复杂的选项是
TokenWindowChatMemory, 它也作为滑动窗口运行,但专注于保留最近的N个令牌 , 根据需要淘汰旧消息。 消息是不可分割的。如果一条消息不适合,它会被完全淘汰。TokenWindowChatMemory需要一个Tokenizer来计算每个ChatMessage中的令牌数。
8.2 代码实现
新建子模块
模块名称:langchain4j-chatmemory
pom文件与上一案例保持一致。
编写yaml文件
yaml
server:
port: 9008
servlet:
encoding:
charset: utf-8
force: true
enabled: true
spring:
application:
name: langchain4j-chatmemory
logging:
level:
com.mango: info编写ChatAssistantWithMemory(AiService)
使用@MemoryId注解标注记忆的ID,用于表示这是哪个会话/用户的。
使用@UserMessage注解标注用户的输入消息。
java
public interface ChatAssistantWithMemory {
String chat(@MemoryId Long userId, @UserMessage String question);
}编写LLMConfig配置类
java
@Configuration
public class LLMConfig {
@Value("${qwen-key}")
private String qwenKey;
@Bean
public ChatModel qwenChatModel() {
return OpenAiChatModel.builder()
.apiKey(qwenKey)
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
}
// 按照消息message的方式
@Bean("chatAssistantMessageWindowMemory")
public ChatAssistantWithMemory chatAssistantMessageWindowMemory(@Qualifier("qwenChatModel") ChatModel chatModel) {
return AiServices.builder(ChatAssistantWithMemory.class)
.chatModel(chatModel)
// 按照MemoryId创建一个ChatMemory
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.withMaxMessages(10))
.build();
}
// 按照Token的方式
@Bean
public ChatAssistantWithMemory chatAssistantTokenWindowMemory(@Qualifier("qwenChatModel") ChatModel chatModel) {
// TokenCountEstimator默认的token分词器,需要结合Tokenizer计算ChatMessage的Token数量
OpenAiTokenCountEstimator tokenCountEstimator = new OpenAiTokenCountEstimator("gpt-4");
return AiServices.builder(ChatAssistantWithMemory.class)
.chatModel(chatModel)
.chatMemoryProvider(memoryId -> TokenWindowChatMemory.withMaxTokens(1000,tokenCountEstimator))
.build();
}
}编写Controller进行测试
java
@Slf4j
@RestController
@RequestMapping("/memory")
public class MemoryController {
@Resource(name = "chatAssistantMessageWindowMemory")
private ChatAssistantWithMemory chatAssistantMessageWindowMemory;
@Resource(name = "chatAssistantTokenWindowMemory")
private ChatAssistantWithMemory chatAssistantTokenWindowMemory;
// 定义用户Id
private Long userId = 1001L;
// 消息窗口缓存
@RequestMapping(value = "/chatWithMessageWindowMemory",method = RequestMethod.GET)
public String chatWithMessageWindowMemory(@RequestParam("question") String question) {
String result = chatAssistantMessageWindowMemory.chat(userId, question);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}
// Token窗口缓存
@RequestMapping(value = "/chatWithTokenWindowMemory",method = RequestMethod.GET)
public String chatWithTokenWindowMemory(@RequestParam("question")String question) {
String result = chatAssistantTokenWindowMemory.chat(userId, question);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}
}访问http://localhost:9008/memory/chatWithMessageWindowMemory?question=你好,我叫张三,进行测试。然后继续询问大模型,提问:我的名字是什么?。

同样,基于Token的方式也是如此测试,访问成功。
9. 提示词工程
9.1 概述
参考文档:https://docs.langchain4j.info/tutorials/chat-and-language-models
参考文档:https://docs.langchain4j.info/tutorials/ai-services#systemmessage
目前有五种类型的聊天消息,每种对应消息的一个"来源":
-
UserMessage
来自用户的消息。 用户可以是应用程序的最终用户(人类)或应用程序本身。 根据 LLM 支持的模态,
UserMessage可以只包含文本(String), 或包含其他模态。 -
AiMessage
由 AI 生成的消息,通常是对
UserMessage的回应。 我们可能已经注意到的,generate方法返回一个包装在Response中的AiMessage。AiMessage可以包含文本响应(String)或执行工具的请求(ToolExecutionRequest)。 我们将在后续探讨工具。 -
ToolExecutionResultMessage
ToolExecutionRequest的结果。 -
SystemMessage
来自系统的消息,作为开发人员应该定义此消息的内容。 通常,会在这里写入关于 LLM 角色是什么、它应该如何行为、以什么风格回答等指令。 LLM 被训练为比其他类型的消息更加关注
SystemMessage, 所以要小心,最好不要让最终用户自由定义或在SystemMessage中注入一些输入。 通常,它位于对话的开始。 -
CustomMessage
一个可以包含任意属性的自定义消息。这种消息类型只能由支持它的
ChatModel实现使用(目前只有 Ollama)。
使用提示次,可以用来打造专业的、限定能力范围和作用边界的AI助手。
Prompt提示词的演化
-
简单纯字符串提问问题:最初的Prompt只是简单的文本字符串。
-
占位符:引入占位符如(如
{it})以动态插入内容。 -
多角色消息:将消息分为不同的角色(如用户、助手、系统等),设置功能边界,增强交互的复杂性和上下文感知能力。
9.2 代码实现
9.2.1 案例一
设计
- 使用
SystemMessage明确定义助手的角色和能力范围,将其限定在法律咨询领域。在Langchain4J中,我们主要利用SystemMessage来实现这一点,SystemMessage具有高优先级,能有效的指导模型的整体行为。 - 利用提示词模板(
@UserMessage、@V)精确控制输入和期望的输出格式,确保问题被正确理解和回答。
新建子模块
模块名称:langchain4j-prompt
pom配置与前面案例相同。
编写yaml配置
yaml
server:
port: 9009
servlet:
encoding:
charset: UTF-8
force: true
enabled: true
spring:
application:
name: langchain4j-prompt
logging:
level:
com.mango: info编辑LawAssistant(AiService)
java
public interface LawAssistant {
@SystemMessage("你是一个北京大学法律博士教授,你是国内外知名的法律专家,你只需要回答你专业领域的问题,对于其他问题,直接返回:'抱歉,我只能回答法律相关问题。'")
@UserMessage("请回答以下法律问题:{{question}},字数控制在{{length}}以内")
String chat(@V("question") String question,@V("length") Integer length);
}编辑LLMConfig配置
java
@Configuration
public class LLMConfig {
@Value("${qwen-key}")
private String qwenKey;
@Bean
public ChatModel qwenModel() {
return OpenAiChatModel.builder()
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.apiKey(qwenKey)
.build();
}
@Bean
public LawAssistant lawAssistant(@Qualifier("qwenModel") ChatModel qwenModel) {
return AiServices.create(LawAssistant.class, qwenModel);
}
}编写Controller进行测试
java
@Slf4j
@RestController
@RequestMapping("/prompt")
public class PromptController {
@Autowired
private LawAssistant lawAssistant;
@RequestMapping(value = "/chat",method = RequestMethod.GET)
public String chat(@RequestParam("question") String question) {
String result = lawAssistant.chat(question, 2000);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}
}
9.2.2 案例二
新建带有@StructuredPrompt的实体类
java
@Data
@StructuredPrompt("根据{{legal}}法律,解答以下问题:{{question}}")
public class LawPrompt {
private String legal;
private String question;
}修改LawAssistant接口
java
public interface LawAssistant {
@SystemMessage("你是一个法律博士教授,你是国内外知名的法律专家,你只需要回答你专业领域的问题,对于其他问题,直接返回:'抱歉,我只能回答法律相关问题。'")
String chat(LawPrompt lawPrompt);
}修改Controller
java
@RequestMapping(value = "/chat2",method = RequestMethod.GET)
public String chat2(@RequestParam("legal") String legal, @RequestParam("question") String question) {
LawPrompt lawPrompt = new LawPrompt();
lawPrompt.setLegal(legal);
lawPrompt.setQuestion(question);
String result = lawAssistant.chat(lawPrompt);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}

9.2.3 案例三
在LangChain4J中有两个对象:PromptTemplate和Prompt用来实现提示词相关功能。
对于单个参数,可以使用{``{it}}占位符或者{``{参数名}},如果为其他字符,系统不能自动识别会报错。
此案例采用低阶API的方式。
修改Controller
java
@Autowired
private ChatModel chatModel;
@RequestMapping(value = "/chat3",method = RequestMethod.GET)
public String chat3(@RequestParam("role") String role, @RequestParam("question") String question) {
PromptTemplate template = PromptTemplate.from("你是一个{{it}}助手,请回答问题:{{question}}");
Prompt prompt = template.apply(Map.of("it", role, "question", question));
UserMessage userMessage = prompt.toUserMessage();
ChatResponse response = chatModel.chat(userMessage);
String result = response.aiMessage().text();
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}10. 记忆持久化ChatMemoryStore
10.1 概述
默认情况下,ChatMemory实现在内存中存储ChatMessage。
如果需要持久化,可以实现自定义的ChatMemoryStore, 将ChatMessage存储在我们选择的任何持久化存储中。
10.2 代码实现
将客户和大模型的对话问答保存进Redis进行持久化记忆留存。
新建子模块
模块名称:langchain4j-memorystore
编写pom
在前面案例pom配置的基础上,增加依赖:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>编写yaml配置
yaml
server:
port: 9010
servlet:
encoding:
enabled: true
charset: UTF-8
force: true
spring:
application:
name: langchain4j-memorystore
data:
redis:
host: localhost
port: 6379
database: 0
logging:
level:
com.mango: info编写RedisConfig配置
Redis序列化配置
java
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}编写持久化配置MyChatMemoryStore,实现ChatMemoryStore接口
java
@Component
public class RedisChatMemoryStore implements ChatMemoryStore {
private static final String CHAT_MEMORY_KEY_PREFIX = "chat:memory:";
@Autowired
private RedisTemplate<String,String> redisTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
String value = redisTemplate.opsForValue().get(CHAT_MEMORY_KEY_PREFIX + memoryId);
// 反序列化
List<ChatMessage> chatMessages = ChatMessageDeserializer.messagesFromJson(value);
return chatMessages;
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
// 序列化
String messageJson = ChatMessageSerializer.messagesToJson(messages);
redisTemplate.opsForValue().set(CHAT_MEMORY_KEY_PREFIX + memoryId,messageJson);
}
@Override
public void deleteMessages(Object memoryId) {
redisTemplate.delete(CHAT_MEMORY_KEY_PREFIX + memoryId);
}
}编写ChatAssistant(AiService)
java
public interface ChatAssistant {
String chat(@MemoryId Long sessionId,@UserMessage String question);
}编写LLMConfig配置
java
@Configuration
public class LLMConfig {
@Value("${qwen-key}")
private String qwenKey;
@Autowired
private RedisChatMemoryStore redisChatMemoryStore;
@Bean
public ChatModel chatModel() {
return OpenAiChatModel.builder()
.apiKey(qwenKey)
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
}
@Bean
public ChatAssistant qwenChatAssistant(@Qualifier("chatModel") ChatModel chatModel) {
ChatMemoryProvider chatMemoryProvider = memoryId -> MessageWindowChatMemory.builder()
.maxMessages(10)
.chatMemoryStore(redisChatMemoryStore)
.id(memoryId)
.build();
return AiServices.builder(ChatAssistant.class)
.chatModel(chatModel)
.chatMemoryProvider(chatMemoryProvider)
.build();
}
}编写Controller进行测试
java
@Slf4j
@RestController
@RequestMapping("/store")
public class MemoryStoreController {
@Autowired
private ChatAssistant chatAssistant;
@RequestMapping(value = "/chat",method = RequestMethod.GET)
public String chat(@RequestParam("sessionId") Long sessionId, @RequestParam("question") String question){
String result = chatAssistant.chat(sessionId, question);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}
}启动项目后测试。

在Redis中查看数据:

11. FunctionCalling
11.1 概述
相关文档:https://docs.langchain4j.info/tutorials/tools
有一个被称为"工具"或"函数调用"的概念。 它允许 LLM 在必要时调用一个或多个可用的工具,通常由开发者定义。
工具可以是任何东西:网络搜索、调用外部 API 或执行特定代码片段等。 LLM 实际上不能自己调用工具。相反,它们在响应中表达调用特定工具的意图(而不是以纯文本形式响应)。 作为开发者,我们应该使用提供的参数执行这个工具,并将工具执行的结果反馈回来。
例如,我们知道 LLM 本身在数学计算方面并不擅长。 如果我们的用例涉及偶尔的数学计算,我们可能希望为 LLM 提供一个"数学工具"。 通过在请求中向 LLM 声明一个或多个工具, 如果它认为合适,它可以决定调用其中一个工具。 给定一个数学问题和一组数学工具,LLM 可能会决定为了正确回答问题, 它应该首先调用提供的数学工具之一。
LangChain4j 提供了两个抽象级别来使用工具:
- 低阶API,使用
ChatModel和ToolSpecificationAPI。 - 高阶API,使用
AiService和带有@Tool注解的 Java 方法。
11.2 代码实现
在本案例中,我们采用DeepSeek R1模型,其具备工具调用功能,通过七牛云平台进行调用。
11.2.1 方式一:手动
新建子模块
模块名称:langchain4j-tools
编写Pom文件配置
其他依赖同前面案例,新增如下依赖:
xml
<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
<version>5.5</version>
</dependency>编写yaml配置
yaml
server:
port: 9011
servlet:
encoding:
force: true
charset: UTF-8
enabled: true
spring:
application:
name: langchain4j-tools
logging:
level:
com.mango: info编写FunctionChatAssistant(AiService)
java
public interface FunctionChatAssistant {
String chat(String question);
}编写LLMConfig配置
java
@Slf4j
@Configuration
public class LLMConfig {
@Value("${qn-key}")
private String qnKey;
@Bean
public ChatModel chatModel() {
return OpenAiChatModel.builder()
.apiKey(qnKey)
.modelName("deepseek-r1")
.baseUrl("https://api.qnaigc.com/v1")
.build();
}
@Bean
public FunctionChatAssistant functionChatAssistant(@Qualifier("chatModel") ChatModel chatModel) {
ToolSpecification toolSpecification = ToolSpecification.builder()
.name("开发票助手")
.description("根据用户提交的开票信息,开具发票")
.parameters(JsonObjectSchema.builder()
.addStringProperty("companyName", "公司名称")
.addStringProperty("dutyNumber", "税号序列")
.addStringProperty("amount", "开票金额,保留两位有效数字")
.build())
.build();
ToolExecutor toolExecutor = (toolExecutionRequest, memoryId)-> {
log.info("工具ID:{}",toolExecutionRequest.id());
log.info("执行工具:{}", toolExecutionRequest.name());
log.info("参数:{}", toolExecutionRequest.arguments());
log.info("memoryId:{}", memoryId);
return "开票成功";
};
return AiServices.builder(FunctionChatAssistant.class)
.chatModel(chatModel)
.tools(Map.of(toolSpecification,toolExecutor))
.build();
}
}编写Controller测试
java
@Slf4j
@RestController
@RequestMapping("/tools")
public class ToolsController {
@Autowired
private FunctionChatAssistant functionChatAssistant;
@RequestMapping(value = "/chat",method = RequestMethod.GET)
public String chat(@RequestParam("question") String question) {
return functionChatAssistant.chat(question);
}
}访问http://localhost:9011/tools/chat?question=开张发票,公司:张三公司,税号:zs123,金额:889.66进行测试。
11.2.2 方式二:注解方式
在本案例中,我们实现天气查询的工具调用。使用和风天气平台。
和风平台:https://dev.qweather.com/docs/api/
在和平台上获取请求的url、apikey。
使用注解@Tool,可以更方便地集成函数调用,只需要将Java方法标注为@Tool,LangChain4j就会自动将其转换为ToolSpecification。
当 LLM 决定调用工具时,AI 服务将自动执行相应的方法, 并将方法的返回值(如果有)发送回 LLM。 可以在 DefaultToolExecutor 中找到实现细节。
带有 @Tool 注解的方法:
- 可以是静态或非静态的
- 可以有任何可见性(public、private 等)。
带有 @Tool 注解的方法可以接受各种类型的任意数量参数:
-
基本类型:
int、double等 -
对象类型:
String、Integer、Double等 -
自定义 POJO(可以包含嵌套 POJO)
-
enum(枚举) -
List<T>/Set<T>,其中T是上述类型之一 -
Map<K,V>(您需要在参数描述中使用@P手动指定K和V的类型) -
也支持没有参数的方法。
默认情况下,所有工具方法参数都被视必需的。 这意味着 LLM 必须为这样的参数生成一个值。 可以通过使用 @P(required = false) 注解使参数成为可选的。复杂参数的字段和子字段默认也被视为必需的。 可以通过使用 @JsonProperty(required = false) 注解使字段成为可选的。
@P注解有 2 个字段:value:参数描述。必填字段。required:参数是否必需,默认为true。可选字段。@Description:类和字段的描述。@Tool:2 个可选字段,name:工具名称。如果未提供,方法名将作为工具名称。value:工具描述。@ToolMemoryId:如果我们的 AI 服务方法有一个带有@MemoryId注解的参数, 可以使用@ToolMemoryId注解@Tool方法的参数。 提供给 AI 服务方法的值将自动传递给@Tool方法。 如果有多个用户和/或每个用户有多个聊天/记忆, 并希望在@Tool方法内区分它们,这个功能很有用。
编写天气查询业务类
java
@Service
public class WeatherService {
@Value("${hf-key}")
private String hfApiKey;
private static final String API_URL = "https://mj7dn7hb9w.re.qweatherapi.com/v7/weather/now?location=%s";
public JsonNode getWeather(String city) {
String url = String.format(API_URL, city);
CloseableHttpClient client = HttpClients.createDefault();
HttpComponentsClientHttpRequestFactory factory = new HttpComponentsClientHttpRequestFactory(client);
RestTemplate restTemplate = new RestTemplate(factory);
HttpHeaders headers = new HttpHeaders();
headers.set("X-QW-Api-Key",hfApiKey);
HttpEntity<String> entity = new HttpEntity<>(headers);
ResponseEntity<String> response = restTemplate.exchange(url, HttpMethod.GET, entity, String.class);
JsonNode jsonNode = null;
try {
jsonNode = new ObjectMapper().readTree(response.getBody());
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
return jsonNode;
}
}编写天气工具类
java
@Slf4j
@Component
public class WeatherTool {
@Autowired
private WeatherService weatherService;
@Tool("根据城市查询当前的天气信息")
public JsonNode getWeather(@P("城市编号") String city) {
JsonNode weather = weatherService.getWeather(city);
return weather;
}
}修改LLMConfig
java
@Autowired
private WeatherTool weatherTool;
@Bean("functionChatAssistantByHigh")
public FunctionChatAssistant functionChatAssistantByHigh(@Qualifier("chatModel") ChatModel chatModel){
return AiServices.builder(FunctionChatAssistant.class)
.chatModel(chatModel)
.tools(weatherTool)
.build();
}修改Controller进行测试
java
@Resource(name = "functionChatAssistantByHigh")
private FunctionChatAssistant functionChatAssistantByHigh;
@RequestMapping(value = "/getWeatherByHigh",method = RequestMethod.GET)
public String getWeatherByHigh(@RequestParam("question") String question) {
String result = functionChatAssistantByHigh.chat(question);
log.info("问题:{}",question);
log.info("答案:{}",result);
return result;
}12. 向量化
12.1 概述
Vector是向量或矢量的意思,向量是数学里的概念,而矢量是物理里的概念,但二者描述的是同一件事。
向量是用于表示具有大小和方向的量。
在本章的案例中,我们使用
Qdrant作为向量数据库。
维度 Diemensions
每个数值向量都有x和y坐标(或者在多维系统中是x、y、z、...)。x、y、z...是这个向量空间的轴,称为维度。想要表示向量的一些非数值实体,首先需要决定这些维度,并为每个实体在每个维度上分配一个值。
例如,在一个交通工具数据集中,我们可以定义四个维度:轮子数量、是否有发动机、是否可以在地上开动和最大乘客数量。
向量的每个维度代表数据的不同特性,维度越多对事务的描述越精确。
LangChain4j向量化三件套:
Embedding ModelEmbedding StoreEmbedding SearchRequest
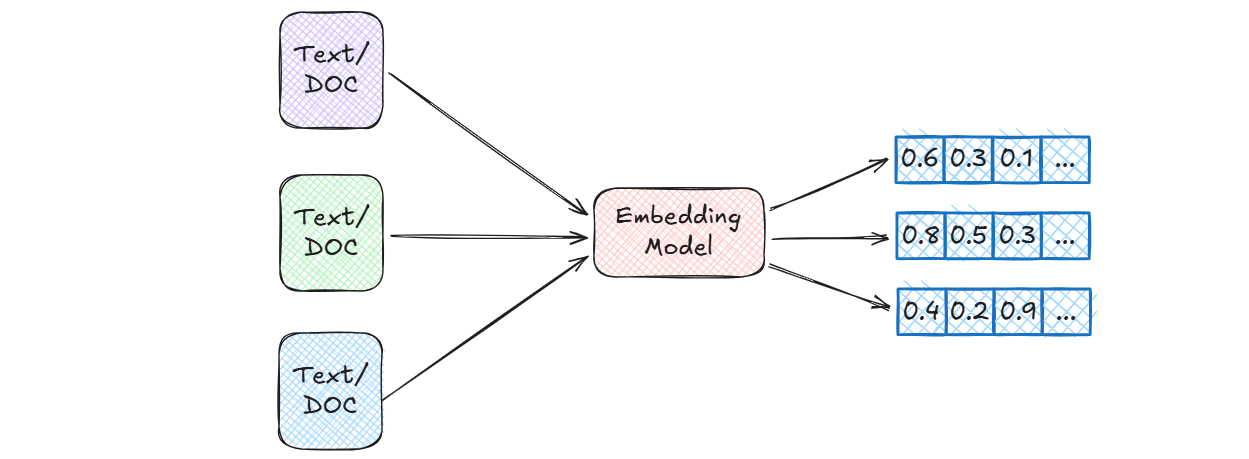
Embedding Model
参考文档:https://docs.langchain4j.info/tutorials/rag#embedding-model
EmbeddingModel 接口表示一种特殊类型的模型,将文本转换为 Embedding。
相关方法
java
EmbeddingModel.embed(String); // 嵌入给定的文本
EmbeddingModel.embed(TextSegment) 嵌入给定的; // TextSegment
EmbeddingModel.embedAll(List<TextSegment>); // 嵌入所有给定的 TextSegment
EmbeddingModel.dimension(); // 返回此模型产生的 Embedding 的维度Embedding Store
EmbeddingStore 接口表示一个用于存储 Embedding 的仓库,也称为向量数据库。它支持存储和高效搜索相似(在嵌入空间中接近)的 Embedding。
目前支持的嵌入存储库可在此处找到。
EmbeddingStore 可以单独存储 Embedding,也可以与对应的 TextSegment 一起存储:
- 它可以仅按 ID 存储 Embedding。原始嵌入数据可以存储在其他位置,并通过 ID 进行关联。
- 它可以同时存储 Embedding 和被嵌入的原始数据(通常是 TextSegment)。
向量存储是一种用于存储和检索高维向量数据的数据库或存储解决方案,它特别适用于处理那些经过嵌入模型转化后的数据。在VectorStore中,查询与传统关系数据库不同。它们指定相似性搜索,而不是精确匹配。当给定一个向量作为查询时,VectorStore返回与查询向量"相似"的向量。
Embedding SearchRequest
EmbeddingSearchRequest 表示在 EmbeddingStore 中进行搜索的请求。它具有以下属性:
Embedding queryEmbedding:用作参考的嵌入向量。int maxResults:返回结果的最大数量。这是一个可选参数,默认值为 3。double minScore:最小得分,范围从 0 到 1(包含)。只有得分大于等于minScore的嵌入向量才会被返回。这是一个可选参数,默认值为 0。Filter filter:在搜索过程中应用于Metadata的过滤器。仅当TextSegment的Metadata匹配该Filter时,才会返回结果。
Filter 允许在执行向量搜索时根据 Metadata 条目进行过滤。
目前支持以下 Filter 类型/操作:IsEqualTo、IsNotEqualTo、IsGreaterThan、IsGreaterThanOrEqualTo、IsLessThan、IsLessThanOrEqualTo、IsIn、IsNotIn、ContainsString、And、Not、Or。
注意:并非所有的嵌入存储(embedding stores)都支持通过
Metadata进行过滤,
将文本、图像和视频转换为称为向量的浮点数数组在VectorStore中,查询与传统关系数据库不同。他们执行相似性搜索,而不是精确匹配,当给定一个向量作为查询时,VectorStore返回与查询向量"相似"的向量。
指征特点:
- 捕捉负责的词汇关系(如语义相似性、同义词、多义词)
- 超越传统词袋模型的简单计数方式
- 动态嵌入模型(如BERT)可根据上下文生成不同的词向量
- 向量嵌入为现代搜索和检索增强生成(RAG)应用程序提供支持
使用向量数据库可以实现:
- 文本搜索
- 推荐电影
- 匹配图片和标题
- 将相似项目归类
12.2 Qdrant数据库
Qdrant是一个高性能的向量数据库,用于存储嵌入并进行快速的向量搜索。
使用Docker运行Qdrant:
shell
docker pull qdrant/qdrant
docker run -d --name="qdrant" -p 6333:6333 -p 6334:6334 qdrant/qdrant端口:6333,用于HTTP API,浏览器web界面
端口:6334,用于gRPC API
访问localhost:6333,出现下面内容,说明qdrant运行成功:

访问:localhost:6333/dashboard#/collections,显示为Qdrant的UI界面。
12.3 代码实现
在本案例中,我们选择使用文本向量模型
text-embedding-v3。
新建子模块
模块名称:langchain4j-embedding
编写pom配置
在前面案例pom文件的基础上,增加依赖:
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-qdrant</artifactId>
</dependency>编写yaml配置
yaml
server:
port: 9012
servlet:
encoding:
enabled: true
charset: UTF-8
force: true
spring:
application:
name: langchain4j-embedding
logging:
level:
com.mango: info编写LLMConfig配置
java
@Configuration
public class LLMConfig {
@Value("${qwen-key}")
private String qwenKey;
@Bean
public EmbeddingModel embeddingModel() {
return OpenAiEmbeddingModel.builder()
.apiKey(qwenKey)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.modelName("text-embedding-v3")
.build();
}
@Bean
public QdrantClient qdrantClient() {
QdrantGrpcClient grpcClient = QdrantGrpcClient.newBuilder("127.0.0.1", 6334, false).build();
return new QdrantClient(grpcClient);
}
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
return QdrantEmbeddingStore.builder()
.host("127.0.0.1")
.port(6334)
.collectionName("test-qdrant")
.build();
}
}编写Controller进行测试
java
@Slf4j
@RestController
@RequestMapping("/embedding")
public class EmbeddingController {
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private QdrantClient qdrantClient;
@Autowired
private EmbeddingStore<TextSegment> embeddingStore;
// 文本向量化测试,看看形成向量后的文本
@RequestMapping(value = "/embedding",method = RequestMethod.GET)
public String embedding(String text) {
Response<Embedding> embed = embeddingModel.embed(text);
log.info("embedding:{}",embed);
return embed.content().toString();
}
}
修改Controller,新增创建向量数据库索引方法
java
// 新建向量数据库实例和索引:test-qdrant
@RequestMapping(value = "/createCollection",method = RequestMethod.GET)
public void createCollection() {
Collections.VectorParams vectorParams = Collections.VectorParams.newBuilder()
.setDistance(Collections.Distance.Cosine) // 余弦相似度
.setSize(1024)
.build();
qdrantClient.createCollectionAsync("test-qdrant", vectorParams);
}
修改Controller,往向量数据库增加数据,查询数据
java
// 往向量数据库新增文本记录
@RequestMapping(value = "/add",method = RequestMethod.GET)
public String add(@RequestParam("prompt") String prompt) {
TextSegment segment = TextSegment.from(prompt);
segment.metadata().put("userId","123");
Embedding embedding = embeddingModel.embed(segment).content();
String result = embeddingStore.add(embedding, segment);
log.info("result:{}",result);
return result;
}
// 查询向量数据库
@RequestMapping(value = "/query",method = RequestMethod.GET)
public String query(@RequestParam("prompt") String prompt) {
Embedding embedding = embeddingModel.embed(prompt).content();
EmbeddingSearchRequest request = EmbeddingSearchRequest.builder()
.queryEmbedding(embedding)
.maxResults(1)
.build();
EmbeddingSearchResult<TextSegment> search = embeddingStore.search(request);
String result = search.matches().get(0).embedded().text();
log.info("search:{}",result);
return result;
}访问localhost:9012/embedding/add?prompt=Java 是一种面向对象的编程语言,由 Sun Microsystems 公司于 1995 年推出。
再访问localhost:9012/embedding/query?prompt=Java进行测试。

13. RAG
13.1 概述
参考文档:https://docs.langchain4j.info/tutorials/rag
LLM 的知识仅限于它已经训练过的数据。 如果想让 LLM 了解特定领域的知识或专有数据,可以:
- 使用 RAG
- 用数据微调 LLM
- 结合RAG和数据微调
简单来说,RAG 是一种在发送给 LLM 之前,从数据中找到并注入相关信息片段到提示中的方法。 这样 LLM 将获得(希望是)相关信息,并能够使用这些信息回复, 这应该会降低产生幻觉的概率。
相关信息片段可以使用各种信息检索方法找到。 最流行的方法有:
- 全文(关键词)搜索。这种方法使用 TF-IDF 和 BM25 等技术, 通过匹配查询(例如,用户提问的内容)中的关键词与文档数据库进行搜索。 它根据每个文档中这些关键词的频率和相关性对结果进行排名。
- 向量搜索,也称为"语义搜索"。 文本文档使用嵌入模型转换为数字向量。 然后根据查询向量和文档向量之间的余弦相似度 或其他相似度/距离度量找到并排序文档, 从而捕捉更深层次的语义含义。
- 混合搜索。结合多种搜索方法(例如,全文 + 向量)通常可以提高搜索的有效性。
RAG流程分为两个不同的阶段:索引(Index)和检索(Retrieval)。
索引
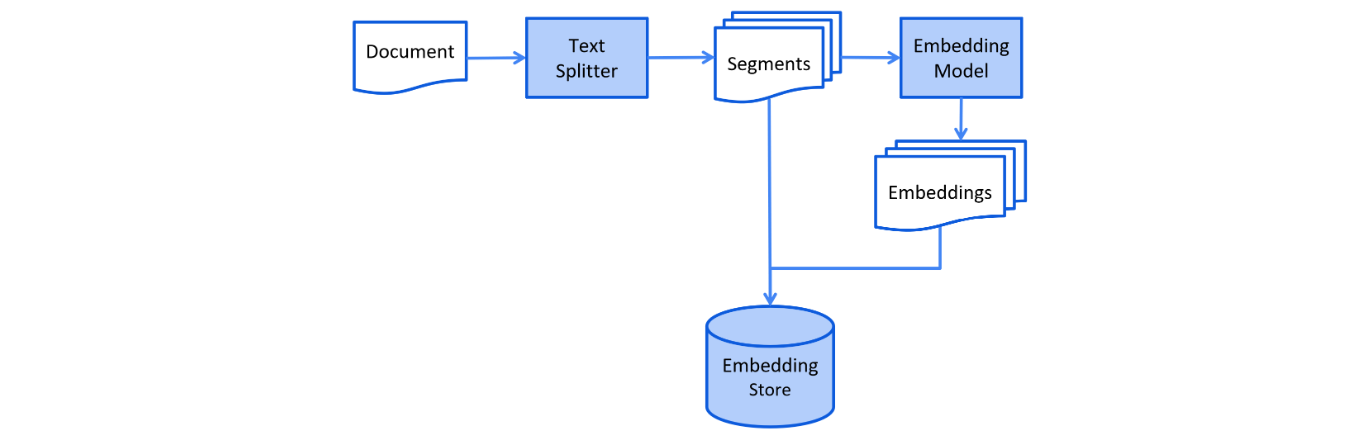
在索引阶段,文档会被预处理,以便在检索阶段进行高效搜索。
这个过程可能因使用的信息检索方法而异。 对于向量搜索,这通常涉及清理文档、用额外数据和元数据丰富文档、 将文档分割成更小的片段(也称为分块)、嵌入这些片段,最后将它们存储在嵌入存储(也称为向量数据库)中。索引阶段通常是离线进行的,这意味着最终用户不需要等待其完成。然而,在某些情况下,最终用户可能希望上传自己的自定义文档,使 LLM 能够访问这些文档。 在这种情况下,索引应该在线进行,并成为主应用程序的一部分。
检索
检索阶段通常在线进行,当用户提交一个应该使用索引文档回答的问题时。
这个过程可能因使用的信息检索方法而异。 对于向量搜索,这通常涉及嵌入用户的查询(问题) 并在嵌入存储中执行相似度搜索。 然后将相关片段(原始文档的片段)注入到提示中并发送给 LLM。
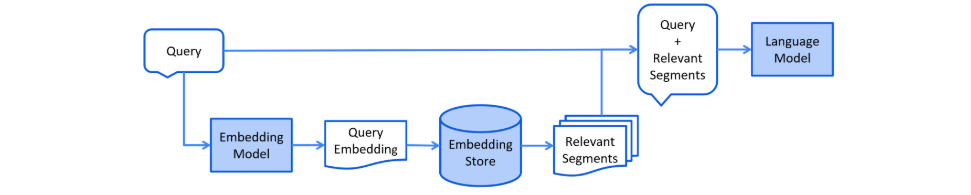
核心API
参考文档:https://docs.langchain4j.dev/tutorials/rag/#core-rag-apis
- Embedding Store Ingesotr组织结构分析
- Document Loader 文档加载器
- Document Parser 文档解析器
- Document Transformer 文档转换器
- Document Splitter 文档拆分器
使用LangChain4J构建RAG的一般步骤
- 加载文档:使用适当的DoucmentLoader和DocumentParser加载文档
- 转换文档:使用DocumentTransformer清理或增强文档(可选)
- 拆分文档:使用DocumentSplitter将文档拆分为更小的片段(可选)
- 嵌入文档:使用EmbeddingModel将文档片段转换为嵌入向量
- 存储嵌入:使用EmbeddingStoreIngestor存储嵌入向量
- 检索相关内容:根据用户查询,从EmbeddingStore检索最相关的文档片段
- 生成相应:将检索到的相关内容与用户查询一起提供给语言模型,生成最终相应
13.2 代码实现
需求说明
某系统涉及后续自动化维护,需要根据响应码让大模型启动自迭代/自维护模型。将阿里巴巴Java开发手册(黄山版)投喂给大模型。
在本案例中使用Easy RAG。
新建子模块
模块名称:langchain4j-rag
编写pom文件
在前面案例的pom文件基础上,增加依赖:
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>编写yaml配置
yaml
server:
port: 9013
servlet:
encoding:
force: true
charset: UTF-8
enabled: true
spring:
application:
name: langchain4j-rag
logging:
level:
com.mango: info编写ChatAssistant(AiService)
java
public interface ChatAssistant {
String chat(String question);
}编写LLMConfig
java
@Configuration
public class LLMConfig {
@Value("${qwen-key}")
private String qwenKey;
@Bean
public ChatModel qwenModel() {
return OpenAiChatModel.builder()
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.apiKey(qwenKey)
.build();
}
@Bean
public InMemoryEmbeddingStore<TextSegment> embeddingStore() {
return new InMemoryEmbeddingStore<>();
}
@Bean
public ChatAssistant chatAssistant(@Qualifier("qwenModel") ChatModel chatModel, EmbeddingStore<TextSegment> embeddingStore) {
return AiServices.builder(ChatAssistant.class)
.chatModel(chatModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
}
}编写Controller
java
@Slf4j
@RestController
@RequestMapping("/rag")
public class RagController {
@Resource
private ChatAssistant chatAssistant;
@Resource
private EmbeddingStore<TextSegment> embeddingStore;
@RequestMapping(value = "/chat",method = RequestMethod.GET)
public String testAdd(@RequestParam("question") String question) throws FileNotFoundException {
FileInputStream fileInputStream = new FileInputStream("D:\\Java.pdf");
Document document = new ApacheTikaDocumentParser().parse(fileInputStream);
EmbeddingStoreIngestor.ingest(document,embeddingStore);
String result = chatAssistant.chat(question);
log.info("问题:{}", question);
log.info("答案:{}", result);
return result;
}
}
14. MCP
14.1 概述
MCP和工具调用FunctionCall异曲同工,现在逐渐都迁移使用MCP。可以将FunctionCall理解为MCP的前身。
MCP协议官网:https://modelcontextprotocol.io/docs/getting-started/intro
中文文档:https://mcp-docs.cn/introduction
MCP服务器与客户端资源:https://mcp.so/zh
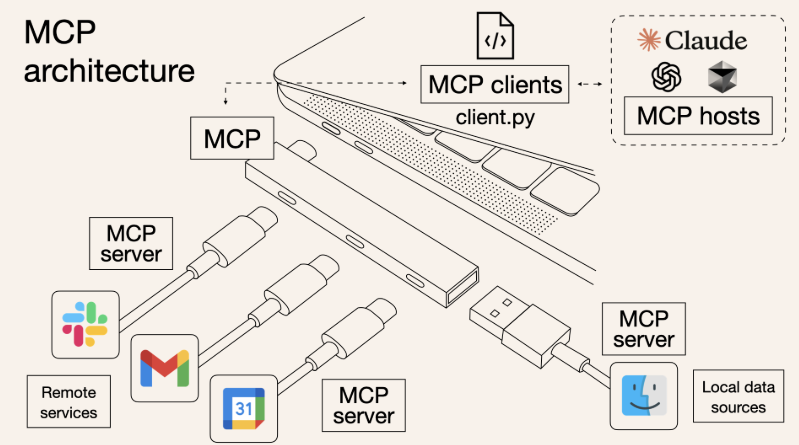
MCP(模型上下文协议,Model Context Protocol)是一种用于将 AI 应用连接到外部系统的开源标准。
通过 MCP,像 Claude 或 ChatGPT 这样的 AI 应用可以连接到数据源(例如本地文件、数据库)、工具(例如搜索引擎、计算器)以及工作流(例如专用提示模板),从而获取关键信息并执行任务。可以把 MCP 想象成 AI 应用的"USB-C 接口":正如 USB-C 为电子设备提供了一种标准化的连接方式,MCP 也为 AI 应用与外部系统之间的连接提供了标准化的方法。
LangChain4j 支持模型上下文协议 (MCP),用于与符合 MCP 的服务器通信,这些服务器可以提供和执行工具。
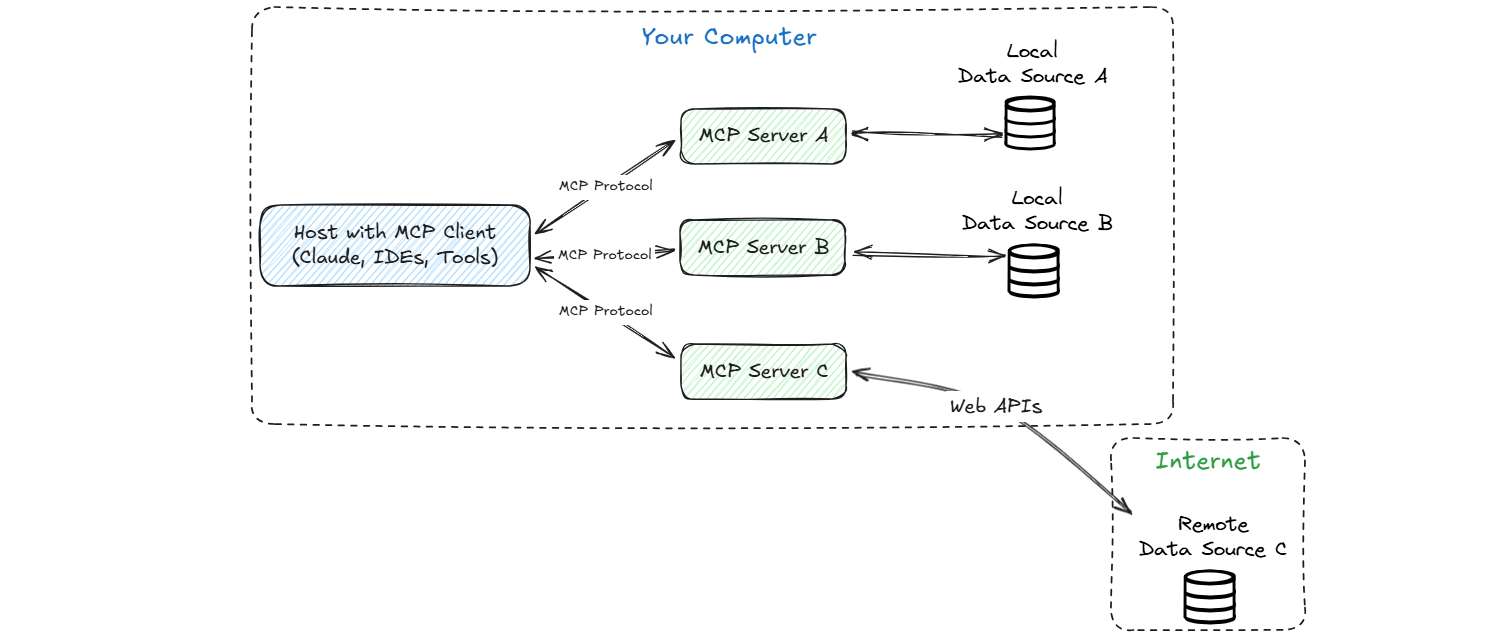
该协议指定了两种传输类型,两种都受支持:
HTTP:客户端请求一个 SSE 通道来接收来自服务器的事件,然后通过 HTTP POST 请求发送命令。stdio:客户端可以将 MCP 服务器作为本地子进程运行,并通过标准输入/输出直接与其通信。
| 特性 | SSE | STDIO |
|---|---|---|
| 传输协议 | HTTP(长连接) | 操作系统级文件描述符号 |
| 方向 | 服务器->客户端(单向推送) | 双向流(stdin,stdout) |
| 保持连接 | 长连接(Connection:keep-alive) | 不保证长时间打开,取决于进程生命周期 |
| 数据格式 | 文本流(EventStream格式) | 原始字节流 |
| 异常处理 | 可通过HTTP状态码或重连机制 | 进程退出或管道断裂 |
要让聊天模型或 AI 服务运行 MCP 服务器提供的工具,需要创建一个 MCP 工具提供者实例。
MCP用于大模型之间的通讯,是实现智能体Agent的基础。
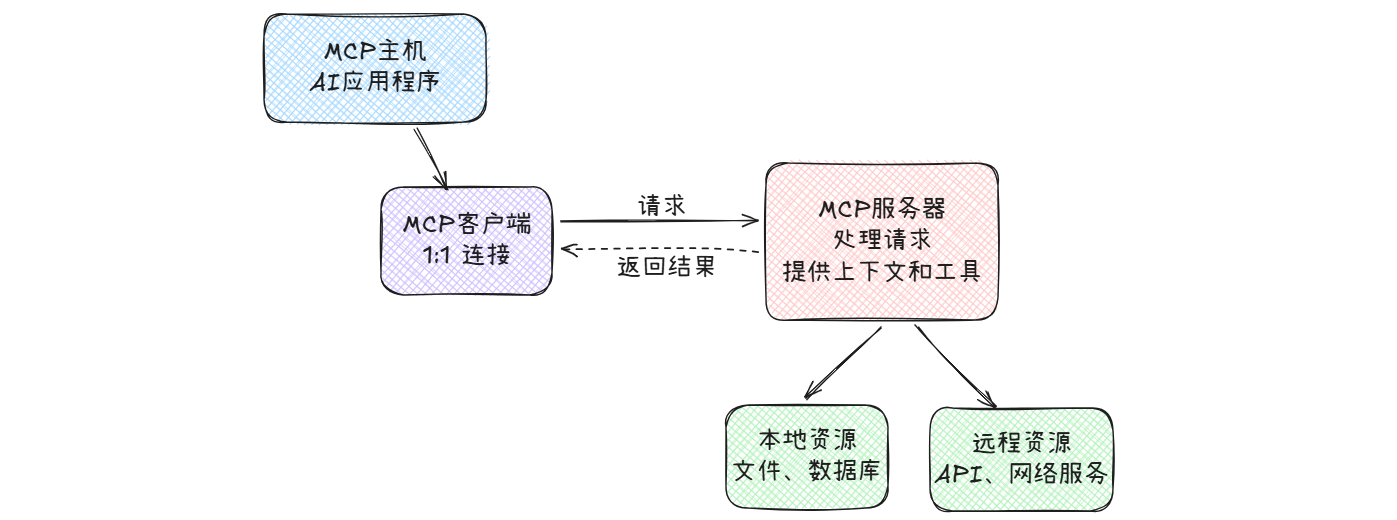
MCP遵循客户端服务器架构,具体如下:
MCP主要包含以下几个核心部分:
- MCP主机(MCP Hosts):如 Claude Desktop、IDE 或 AI 工具,希望通过 MCP 访问数据的程序
- MCP客户端(MCP Clients):维护与服务器一对一连接的协议客户端
- MCP服务器(MCP Servers):轻量级程序,通过标准的 Model Context Protocol 提供特定能力
- 本地资源(Local Resources):MCP 服务器可安全访问的计算机文件、数据库和服务
- 远程资源(Remote Resources):MCP 服务器可连接的互联网上的外部系统(如通过 APIs)
14.2 代码实现
需求说明
本地调用MCP Server百度地图。
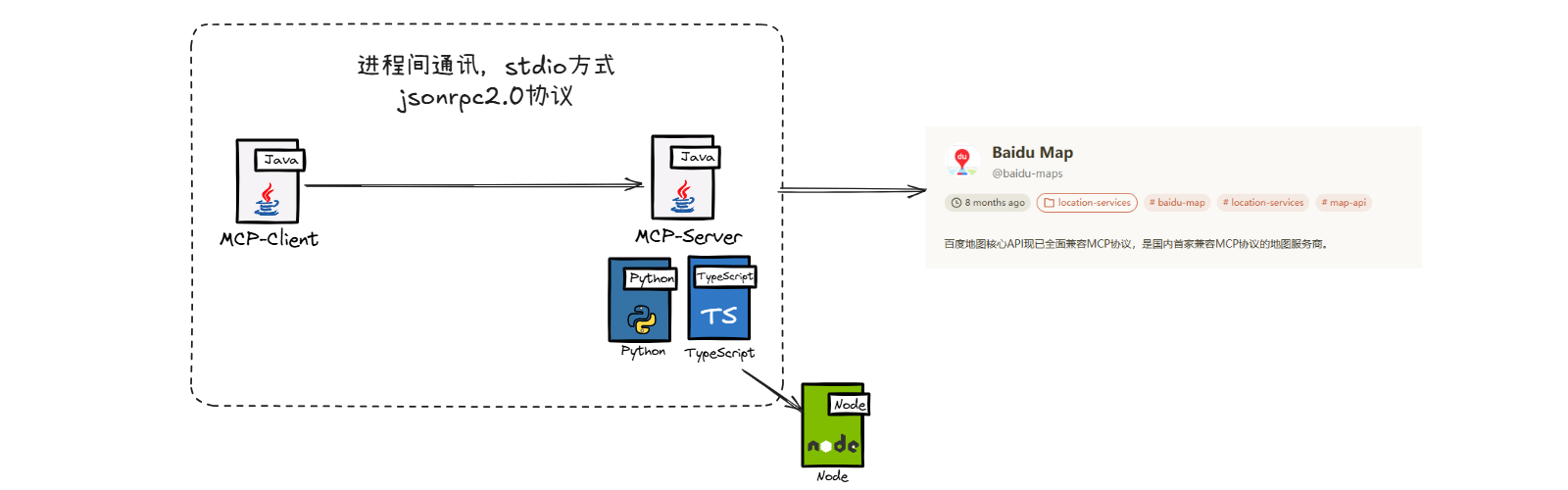
环境配置
使用百度地图MCP Server主要通过两种形式:Python和TypeScript。
在本案例中,使用TypeScript环境。
在本地配置nodejs环境。
在百度地图开放平台注册百度地图账号,并申请API Key。
新建子模块
模块名称:langchain4j-mcp
编写pom文件
xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--引入langchain4j依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-mcp</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>编写yaml配置
yaml
server:
port: 8080
servlet:
encoding:
enabled: true
charset: UTF-8
force: true
spring:
application:
name: langchain4j-mcp
langchain4j:
community:
dashscope:
streaming-chat-model:
api-key: ${qwen-key}
model-name: qwen-plus
chat-model:
api-key: ${qwen-key}
model-name: qwen-plus
logging:
level:
com.mango: info编写ChatAssistant(AiService)接口
java
public interface ChatAssistant {
Flux<String> chat(String question);
}编写Controller
java
@Slf4j
@RestController
@RequestMapping("/mcp")
public class McpController {
@Autowired
private StreamingChatModel chatModel;
@Value("${bd-key}")
private String bdKey;
@RequestMapping(value = "/chat",method = RequestMethod.GET)
public Flux<String> chat(@RequestParam("question") String question) {
// 1. 构建MCP Transport协议
McpTransport transport = new StdioMcpTransport.Builder()
.command(List.of("cmd", "/c", "npx", "-y", "@baidumap/mcp-server-baidu-map"))
.environment(Map.of("BAIDU_MAP_API_KEY", bdKey))
.build();
// 2. 构建McpClient客户端
McpClient mcpClient = new DefaultMcpClient.Builder()
.transport(transport)
.build();
// 3. 构建工具集,和原生FunctionCalling相似
ToolProvider toolProvider = McpToolProvider.builder()
.mcpClients(mcpClient)
.build();
// 4. 通过AiServices给我们自定义接口ChatAssistant构建实现类并将工具集和大模型赋值给AiService
ChatAssistant chatAssistant = AiServices.builder(ChatAssistant.class)
.streamingChatModel(chatModel)
.toolProvider(toolProvider)
.build();
return chatAssistant.chat(question);
}
}访问http://localhost:9014/mcp/chat?question=青岛邮轮母港到五四广场的路线规进行测试。