引言:为什么我们总在寻找"关键"?
想象一下,你正试图预测明天是否会下雨。
你手头有成百上千条信息:
- 今天的温度、湿度、气压
- 过去一周的天气记录
- 风向、云层类型
- 天空的颜色
- 你家猫咪今天打呼噜的次数
- 邻居家花园里蒲公英的数量
- 股市今天的收盘指数
面对如此庞杂的信息,你会如何下手?你可能会本能地觉得,温度、湿度、气压和云层类型这些信息很重要,而猫咪打呼噜和蒲公英的数量似乎与下雨没什么关系。你的这种"直觉",本质上就是在进行"特征筛选"------从所有可用的信息中,找出那些对预测目标(明天下雨与否)真正有用的"关键特征"。
在人工智能和机器学习的世界里,这个过程被赋予了更专业的名字------特征选择(Feature Selection)。它是数据科学项目中至关ings的一环,甚至可以说是决定模型成败的关键。一个优秀的特征选择过程,能让简单的模型表现卓越;而糟糕的特征集合,则会让最复杂的模型也束手无策,甚至得出荒谬的结论。
那么,究竟什么是特征?为什么要筛选它们?又有哪些方法可以帮我们找到这些"关键先生"?本文将用最平实的语言,为你一一揭晓。
第一章:认识我们的主角------什么是"特征"?
在深入探讨方法之前,我们必须先认识我们的主角。在机器学习的世界里,"特征"是一个核心概念。
1.1 特征的通俗定义
简单来说,特征(Feature)就是我们用来描述一个事物的某个方面的"属性"或"度量"。你可以把它想象成一张表格的"列"。
举个最经典的例子:我们想根据一个人的信息来预测他/她是否能获得银行贷款。
| 年龄 | 年收入(万元) | 工作年限 | 房产数量 | 信用评分 | 能否获得贷款 |
|---|---|---|---|---|---|
| 28 | 15 | 3 | 0 | 680 | 否 |
| 42 | 35 | 15 | 2 | 820 | 是 |
| 35 | 22 | 8 | 1 | 750 | 是 |
在这个表格里:
- "年龄"、"年收入"、"工作年限"、"房产数量"、"信用评分"就是特征(Features)。
- "能否获得贷款"是我们要预测的目标,通常被称为目标变量(Target Variable) 或 标签(Label)。
- 表格中的每一行,代表一个样本(Sample) 或 观测值(Observation),比如某一个具体的贷款申请人。
因此,整个机器学习的过程,就是学习"特征"与"目标变量"之间的映射关系或规律。模型通过学习成千上万个这样的样本,来掌握"什么样的特征组合"通常对应"是"或"否"的答案。
1.2 特征的类型
特征并非千篇一律,它们有不同的"性格":
- 数值型特征(Numerical Features) :可以用数字表示,并且数字之间可以进行数学运算。比如年龄、收入、温度。数值型特征又可以细分为:
- 连续型:可以在一个区间内取任意值,如身高、体重。
- 离散型:只能取特定的整数值,如子女数量、购买次数。
- 类别型特征(Categorical Features) :用来表示不同的类别或标签,没有天然的大小顺序。比如:
- 名义型(Nominal):类别之间完全平等,没有顺序。如血型(A, B, AB, O)、城市(北京、上海、广州)。
- 有序型(Ordinal):类别之间有明确的等级或顺序。如教育程度(小学、中学、大学)、满意度评分(1-5星)。
理解特征的类型至关重要,因为不同的特征类型决定了我们后续如何处理和分析它们。
1.3 "维"与"诅咒":为什么特征不能太多?
回到我们预测下雨的例子。如果我们把所有能想到的信息都塞给模型,会发生什么?
这引出了一个著名的概念:"维度灾难(Curse of Dimensionality)"。
想象一个二维的平面(比如一张纸),上面有100个点,它们分布得比较均匀。现在,我们升级到三维空间(比如一个房间),要让100个点在空间里也保持和二维平面上同样的"均匀"密度,我们需要的点数量会急剧增加。维度越高,数据变得越稀疏。
在机器学习中,这意味着:
- 数据稀疏:随着特征数量的增加,为了覆盖所有可能的特征组合,我们需要的数据量呈指数级增长。现实中,我们往往没有这么多数据。
- 模型过拟合:模型会记住训练数据中那些不重要的、甚至是噪声的细节(比如"蒲公英数量为7时,第二天没下雨"),导致在新数据上表现极差。
- 计算成本高昂:特征越多,模型训练和预测所需的时间和计算资源就越多。
- 可解释性差:一个包含成百上千个特征的模型,就像一个黑盒子,没人能说清楚它到底是根据什么做出的判断。
因此,盲目地增加特征数量,不仅不会让模型变聪明,反而会让它变得"愚蠢"、"迟钝"且"不可信"。特征选择的目标,就是"做减法",用最少的、最有信息量的特征,达到最好的预测效果。
第二章:特征选择的三大策略------过滤、包装与嵌入
面对成百上千的特征,我们如何系统性地进行筛选?数据科学家们总结出了三大类核心策略,它们各有千秋,适用于不同的场景。我们可以将它们想象成三种不同的"侦探":
- 过滤法(Filter Methods):像一个冷静的分析员,独立于任何具体模型,仅根据特征与目标变量之间的统计关系来打分和筛选。
- 包装法(Wrapper Methods):像一个严谨的实验员,通过反复训练和测试一个具体的模型,来评估特征子集的好坏。
- 嵌入法(Embedded Methods):像一个聪明的学习者,在模型训练的过程中,自然而然地完成了特征选择。
接下来,我们将逐一揭开这三位"侦探"的面纱。
第三章:侦探一号------"冷静的分析员"过滤法(Filter Methods)
过滤法是特征选择中最基础、最快速的方法。它的核心思想非常简单:在将数据送入任何机器学习模型之前,先通过一些统计指标,对每个特征进行"打分",然后根据分数高低进行排序和筛选。
过滤法的优点在于:
- 计算速度快:因为它不需要训练模型,只做数学计算。
- 通用性强:计算出的分数与后续使用的模型无关。
- 能有效去除明显无用的特征。
它的缺点也很明显:
- 忽略了特征之间的相互作用:它只看单个特征与目标的关系,没考虑特征A和特征B组合起来可能会产生新的信息。
- 可能不够精准:因为它不依赖于具体模型,选出的特征集可能不是特定模型的最佳选择。
现在,让我们来看看过滤法常用的几种"打分"武器。
3.1 皮尔逊相关系数(Pearson Correlation Coefficient)
适用场景 :目标变量是连续型 (回归问题),特征也是连续型。
这是最广为人知的相关性度量方法。它衡量的是两个连续变量之间线性相关 的程度。相关系数的值域在 [-1, 1] 之间:
- 1:完全正相关(一个变量增加,另一个也严格增加)。
- -1:完全负相关(一个变量增加,另一个严格减少)。
- 0:无线性相关性。
实践 :
假设我们要预测房价(连续目标变量)。我们计算"房屋面积"与"房价"的皮尔逊相关系数,可能会得到一个接近0.8的高正值,说明面积越大,房价越高,这是一个强正相关。而"房间墙壁的颜色"与"房价"的相关系数可能接近0,说明它们几乎没有线性关系,可以考虑剔除。
代码演示(Python):
python
import pandas as pd
import numpy as np
from scipy.stats import pearsonr
# 假设我们有一个房价数据集
# data = pd.read_csv('house_prices.csv')
# features = data[['area', 'bedrooms', 'age']]
# target = data['price']
# 为了演示,我们创建一些模拟数据
np.random.seed(42)
area = np.random.normal(100, 30, 1000)
price = area * 0.5 + np.random.normal(0, 10, 1000) # 价格与面积强相关
wall_color = np.random.randint(1, 5, 1000) # 墙壁颜色(1-4),与价格无关
# 计算相关系数
corr_area, _ = pearsonr(area, price)
corr_color, _ = pearsonr(wall_color, price)
print(f"'面积'与'房价'的相关系数: {corr_area:.3f}") # 输出应接近0.8
print(f"'墙壁颜色'与'房价'的相关系数: {corr_color:.3f}") # 输出应接近0'面积'与'房价'的相关系数: 0.820
'墙壁颜色'与'房价'的相关系数: -0.0473.2 方差分析(ANOVA)F值
适用场景 :目标变量是类别型 (分类问题),特征是连续型。
当我们的目标是分类(比如"是/否"、"猫/狗/鸟")时,皮尔逊相关系数就不太适用了。这时,我们可以用方差分析(ANOVA)。
ANOVA的核心思想是:一个好的特征,应该在不同类别下的取值有显著差异。比如,在"贷款审批"问题中,能获得贷款的人群和不能获得贷款的人群,他们的"年收入"平均值应该有显著不同。如果两个群体的收入分布几乎一样,那么"年收入"这个特征对分类就没啥用。
F值就是衡量这种组间差异是否显著的统计量。F值越大,说明该特征与目标类别越相关。
3.3 卡方检验(Chi-Square Test)
适用场景 :目标变量和特征都是类别型。
卡方检验用于检验两个类别变量之间是否独立。如果两个变量独立,那么知道其中一个变量的值,对预测另一个变量毫无帮助。
实践 :
在"电影推荐"系统中,我们想知道"用户的性别"(男/女)和"用户喜欢的电影类型"(动作/爱情/科幻)是否有关联。如果卡方检验显示它们不独立(即p值很小),那么"性别"就是一个有用的关键特征。
3.4 互信息(Mutual Information)
互信息是一个更通用、更强大的工具。它来源于信息论,衡量的是知道一个变量的信息后,能减少另一个变量多少不确定性。
互信息的优点在于:
- 不局限于线性关系:它能捕捉到非线性的、更复杂的关系。
- 适用于各种类型:可以处理连续-连续、连续-离散、离散-离散等各种组合。
互信息值越高,说明两个变量之间的依赖性越强,该特征也就越重要。
第四章:侦探二号------"严谨的实验员"包装法(Wrapper Methods)
如果说过滤法是"纸上谈兵",那么包装法就是"实战演练"。包装法将特征选择过程看作一个搜索问题 :在所有可能的特征子集(2^N种可能,N是特征总数)中,找到那个能让特定模型表现最好的子集。
包装法的优点:
- 效果通常最好:因为它直接以模型的性能为优化目标。
- 考虑了特征间的交互作用。
包装法的缺点:
- 计算成本极高:对于有100个特征的数据集,要评估2^100个子集,这是一个天文数字。
- 容易过拟合:尤其是在数据量小的时候,选出的特征子集可能只是在当前数据集上表现好。
为了在可接受的时间内找到近似最优解,我们通常采用一些启发式的搜索策略。
4.1 递归特征消除(Recursive Feature Elimination, RFE)
RFE是一种非常流行的包装法。它的工作流程如下:
- 使用所有特征训练一个模型(通常是像线性回归、逻辑回归或SVM这样能给出特征权重的模型)。
- 根据模型的特征权重(或重要性),找出最不重要的特征(比如权重绝对值最小的那个)。
- 将这个最不重要的特征从特征集中移除。
- 用剩下的特征重复步骤1-3,直到达到预设的特征数量。
RFE就像一个"优胜劣汰"的淘汰赛,通过反复训练模型来逐步剔除弱者。
4.2 前向选择(Forward Selection)
这是一种"加法"策略:
- 从一个空的特征集合开始。
- 尝试将每一个未被选中的特征单独加入当前集合。
- 用加入新特征后的集合训练模型,并评估性能(比如用交叉验证的准确率)。
- 选择那个能让模型性能提升最多的特征,正式加入集合。
- 重复步骤2-4,直到加入新特征不再能显著提升模型性能,或者达到预设的特征数量。
前向选择从零开始,一点一点地构建最优特征集。
4.3 后向消除(Backward Elimination)
这与前向选择正好相反,是一种"减法"策略:
- 从包含所有特征的集合开始。
- 尝试逐一移除集合中的每一个特征。
- 用移除特征后的集合训练模型,并评估性能。
- 如果移除某个特征后,模型性能没有显著下降(甚至可能上升),那么就正式移除它。
- 重复步骤2-4,直到移除任何特征都会导致性能显著下降。
后向消除从全集开始,一点一点地剔除冗余特征。
总结:包装法虽然强大,但也昂贵。在特征数量不多(比如少于50个)且计算资源充足的情况下,它往往是获得最佳性能的首选。但对于高维数据(如文本、图像),通常需要先用过滤法进行大规模的初步筛选,再用包装法在小规模特征集上做精细优化。
第五章:侦探三号------"聪明的学习者"嵌入法(Embedded Methods)
嵌入法将特征选择巧妙地融入到模型的训练过程中。模型在学习如何做出预测的同时,也学习到了哪些特征是重要的,哪些是不重要的。这就像一个学生在解题时,自然而然地就知道了题目中的哪些条件是关键信息。
嵌入法结合了过滤法的效率和包装法的效果,通常是一个非常理想的折中方案。
5.1 基于正则化的特征选择
这是嵌入法中最核心、应用最广泛的技术。正则化是一种在模型的损失函数中增加惩罚项的技术,目的是为了防止模型过拟合。
L1正则化(Lasso回归):
- 核心思想 :在损失函数中,加上所有特征权重的绝对值之和作为惩罚项。
- 神奇效果 :L1正则化倾向于将不重要特征的权重直接压缩到0。
- 结果:训练完成后,那些权重为0的特征就被自动剔除了,剩下的特征就是模型认为的关键特征。
Lasso回归就像一个严格的编辑,会毫不犹豫地删掉所有他认为是"废话"的词。
L2正则化(Ridge回归):
- 核心思想 :在损失函数中,加上所有特征权重的平方和作为惩罚项。
- 效果 :L2正则化会将所有特征的权重都向0靠近,但很少会让权重精确地等于0。
- 结果:它不能直接进行特征选择,但能有效降低不重要特征的影响,防止过拟合。
Lasso和Ridge的不同,可以看作是"删除"和"降权"的区别。
Elastic Net(弹性网络) :
Elastic Net是Lasso和Ridge的结合体,它同时包含了L1和L2惩罚项。它在处理特征高度相关(多重共线性)的数据集时,表现尤为出色。
5.2 基于树模型的特征重要性
决策树、随机森林、梯度提升树(如XGBoost, LightGBM)等树模型,在构建过程中会自然地对特征进行评估。
核心思想:在决策树的每一个分裂节点,模型都会选择那个能最好地将数据分开(比如让子节点的纯度最高)的特征。一个特征被用来做分裂的次数越多,或者每次分裂带来的信息增益(或基尼不纯度的减少)越大,那么这个特征就越重要。
在训练完一个随机森林模型后,我们通常可以直接调用.feature_importances_属性来获取每个特征的重要性得分,并据此进行排序和筛选。
代码演示(Python - 随机森林):
python
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# 加载经典的鸢尾花数据集
data = load_iris()
X, y = data.data, data.target
# 训练一个随机森林模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)
# 获取特征重要性
importances = rf.feature_importances_
feature_names = data.feature_names
# 可视化
plt.figure(figsize=(10, 6))
plt.barh(feature_names, importances)
plt.xlabel('Feature Importance')
plt.title('Random Forest Feature Importances')
plt.show()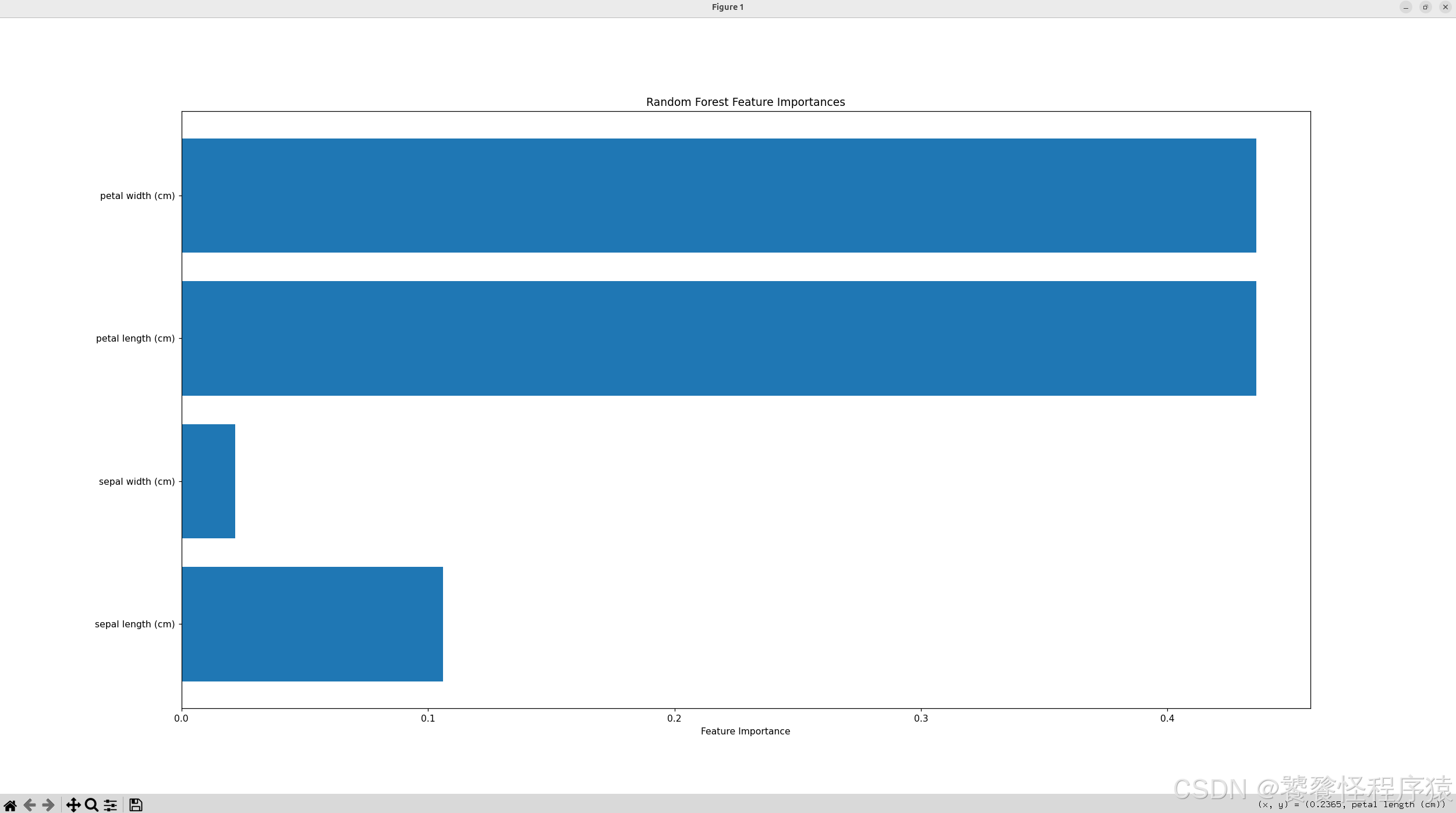
通过这张图,你可以一目了然地看到,在鸢尾花分类问题中,"花瓣长度"和"花瓣宽度"是比"花萼"相关的特征更重要的关键特征。
第六章:特征工程------让特征变得"更聪明"
在筛选特征之前,我们往往还需要对原始特征进行一些处理和转换,这个过程叫做特征工程(Feature Engineering)。好的特征工程能创造出信息量更丰富的特征,从而让特征选择事半功倍。
6.1 处理缺失值
真实世界的数据很少是完美的,经常会出现缺失值(比如某个人的收入未填写)。处理缺失值是特征工程的第一步。
- 删除:如果某个特征缺失比例过高(比如>70%),或者缺失样本太多,可以直接删除该特征或样本。
- 填充 :
- 数值型:用均值、中位数或众数填充。
- 类别型:用众数填充,或创建一个新的"未知"类别。
6.2 编码类别型特征
机器学习模型通常只能处理数字。因此,我们需要将类别型特征转换为数值。
- 独热编码(One-Hot Encoding) :为每个类别创建一个新的二元(0/1)特征。例如,"颜色"有三个类别(红、绿、蓝),独热编码后会变成三个新特征:
is_red,is_green,is_blue。这是最常用的方法,能避免引入虚假的顺序关系。 - 标签编码(Label Encoding) :直接将类别映射为整数(如红=0, 绿=1, 蓝=2)。这种方法仅适用于有序型特征,否则会误导模型认为类别之间存在大小关系。
6.3 特征缩放
不同特征的数值范围可能差异巨大(如"收入"可能是几万到几十万,而"年龄"是0-100)。为了让模型能公平地对待所有特征,我们需要进行缩放。
- 标准化(Standardization) :将特征转换为均值为0,标准差为1的分布。公式:
z = (x - μ) / σ。 - 归一化(Normalization) :将特征缩放到一个固定的范围,如0, 1。公式:
x' = (x - x_min) / (x_max - x_min)。
6.4 创造新特征(特征构造)
有时候,原始特征本身信息量有限,但它们的组合可能蕴含着关键信息。
- 多项式特征:将特征进行乘方或交叉相乘。例如,在房价预测中,"面积"和"房间数"都是特征,但"面积/房间数"(即每个房间的平均面积)可能是一个更有意义的新特征。
- 分箱(Binning):将连续特征离散化。例如,将"年龄"划分为"青年(0-30)"、"中年(31-60)"、"老年(61+)"。这有助于捕捉非线性关系。
- 基于领域知识的构造:这是最高级的特征工程。比如在金融风控中,专家可能会构造"负债收入比"这样的指标,这往往比单独看"负债"和"收入"要有用得多。
第七章:如何评估特征选择的效果?
完成了特征选择后,我们如何知道它是否成功?答案是:用模型的性能说话。
- 对于分类问题 ,我们可以关注:
- 准确率(Accuracy)
- 精确率(Precision) 、召回率(Recall)
- F1分数(F1-Score)(精确率和召回率的调和平均)
- AUC值(ROC曲线下面积,衡量模型区分正负样本的能力)
- 对于回归问题 ,我们可以关注:
- 均方误差(MSE)
- 平均绝对误差(MAE)
- R²分数(决定系数,越接近1越好)
评估流程:
- 基线模型:使用所有原始特征(或经过基础处理的特征)训练一个模型,记录其性能作为基线。
- 特征选择:应用你选择的特征选择方法,得到一个精简的特征子集。
- 对比模型 :用这个精简的特征子集训练同一个模型,再次评估性能。
- 分析:如果新模型的性能(在验证集或测试集上)与基线模型相当甚至更好,同时特征数量大大减少,那么这次特征选择就是成功的!
此外,我们还可以观察模型的训练时间 和预测速度 是否有所提升,以及模型的可解释性是否变得更好。
第八章:实战案例------从混乱到清晰
让我们通过一个虚构但贴近现实的案例,来完整走一遍特征选择的流程。
场景:某电商公司希望预测用户是否会购买一款新上架的高端耳机。
原始数据集包含以下特征:
user_id(用户ID)age(年龄)gender(性别:男/女)city_tier(城市等级:1/2/3/4/5)total_visits(历史总访问次数)last_visit_days_ago(距离上次访问多少天)total_spent(历史总消费金额)fav_category(最喜爱的商品类别:手机/电脑/服装/...)page_views_headphone(本次会话中浏览耳机页面的次数)time_on_headphone_page(本次会话中在耳机页面停留的总时长)added_to_cart(是否将耳机加入购物车:是/否)...(还有很多其他看似相关的特征)
目标 :purchase (是否购买:是/否)
步骤1:数据探索与预处理
- 加载数据,检查缺失值、异常值。
- 将
gender,city_tier,fav_category等类别型特征进行独热编码。 - 对
age,total_spent等数值型特征进行标准化。 user_id是唯一标识符,对预测无用,直接删除。
步骤2:初步筛选(过滤法)
- 由于目标是分类问题,我们对数值型特征使用ANOVA F值 ,对类别型特征使用卡方检验。
- 计算每个特征的分数,并绘制条形图。我们可能会发现,
page_views_headphone,time_on_headphone_page,added_to_cart这几个特征的分数遥遥领先,而total_visits和fav_category中的一些类别分数很低。
步骤3:精炼特征(嵌入法)
- 选择一个强大的模型,比如XGBoost。
- 用初步筛选后的特征训练XGBoost模型。
- 获取XGBoost给出的
feature_importances。 - 选择重要性排名前10的特征。
步骤4:验证效果
- 用这10个关键特征训练一个逻辑回归模型作为最终模型(因为逻辑回归简单、可解释性强)。
- 在测试集上评估,发现AUC达到了0.92,而使用全部原始特征(50+个)的逻辑回归模型AUC只有0.85。
- 结论:通过特征选择,我们不仅将模型性能提升了,还将特征数量从50+减少到10个,大大简化了模型,并且可以向业务方清晰地解释:"用户的购买决策主要受'是否加入购物车'、'在耳机页面的停留时长'等10个关键行为的影响。"
第九章:总结与展望
寻找关键特征,是机器学习从"能用"走向"好用"、"可信"的必经之路。它不仅仅是技术活,更是一门艺术,需要结合统计学知识、对模型的理解以及对业务领域的深刻洞察。
- 初学者 可以从过滤法入手,快速理解特征与目标之间的基本关系。
- 进阶者 可以尝试包装法,在计算资源允许的情况下挖掘特征间的深层交互。
- 实战派 则会大量依赖嵌入法,尤其是基于树模型和L1正则化的方法,因为它们高效且效果出众。
请记住,没有放之四海而皆准的最佳方法。最好的策略往往是将这三种方法结合起来使用:先用过滤法快速去掉大量明显无用的特征,再用嵌入法或包装法在剩下的特征中精挑细选。
最后,特征选择的终点,是构建一个简单、高效、可解释的模型。在AI日益渗透我们生活的今天,一个能被人类理解的模型,其价值远超过一个性能略高但无法解释的"黑盒子"。