京东今年的薪资太香了!根据网上已经爆出的薪资来看,下面是京东科技和零售后端岗位今年已经开奖的薪资情况:
- 后端:24k * 20,北京,科技,白菜
- 后端:28k * 20,北京,科技,SP
- 后端:26k * 20,北京,零售,白菜
- 后端:(30~32)k * 20,北京,零售,SP
- 后端:(31~32)k * 20,北京,零售,SSP
零售开的一般要比科技高一些,科技开的白菜价可能还要比我上面提到的 24k 低一些。
科技和零售都是 20 薪,其中 14 薪是 100%能拿到的,剩下 6 薪是看绩效,HR 说,70%的人能拿满 20。
高薪对应的是高强度,京东现在的工作强度真的挺大的,尤其是涨薪之后。
看到这里,肯定有同学要问了,这京东的研发岗到底怎么样?值不值得冲?别急,今天我就来跟大家分享一位读者的京东研发岗校招面经,希望能帮到大家!
项目拷打
介绍一下你做的项目
作为求职者,我们可以从哪些方案去准备项目经历的回答:
- 梳理项目全貌 :
- 一句话概括项目:用简洁的语言说清楚这个项目是做什么的(核心业务/目标)以及为什么要做(项目背景、要解决什么痛点)。
- 核心功能与亮点:介绍项目的主要功能模块,特别是那些技术含量高或业务价值大的部分。
- 技术架构与选型:能清晰地说明项目的整体技术架构(比如是微服务、单体?用了哪些中间件?),并解释为什么选择这些技术(技术选型的考量)。准备好可能被要求画简要架构图或解释关键模块设计。
- 明确你的角色与贡献 :
- 你的角色:清楚说明你在项目中担任的角色(比如核心开发者、模块负责人、项目经理等)。
- 具体职责:你具体负责了哪些模块或任务?
- 关键贡献(重中之重!):用 STAR 法则 (Situation, Task, Action, Result) 来准备几个实际案例。重点突出你通过具体行动取得了可量化的成果或解决了关键问题,一定要具体场景,而非罗列技术。例如,"负责优化 XX 接口,通过 A、B、C 措施,将响应时间从 X 降低到 Y,提升了 Z% 的用户体验"。
- 准备解决问题的亮点案例 :
- 挖掘挑战:回忆项目中遇到的最棘手的技术难题、性能瓶颈、或者复杂的业务逻辑实现。这个在面试中很可能会问到,例如面试官会问你:"面试中遇到了什么困难?如何解决的?"。
- 展现思路:详细说明你是如何分析问题(用了什么工具?怎么定位的?)、思考解决方案(考虑了哪些方案?为什么选择最终方案?)、最终如何解决的,以及结果如何。
- 提炼收获:从解决这个问题的过程中,你学到了什么?技术上有什么成长?或者对业务有了更深的理解?
- 深入理解关键技术:吃透你在这个项目中用到的技术(举个例子,你的项目经历使用了 Seata 来做分布式事务,那 Seata 相关的问题你要提前准备一下吧,比如说 Seata 支持哪些配置中心、Seata 的事务分组是怎么做的、Seata 支持哪些事务模式,怎么选择?)。
为什么用 JWT?
JWT 相较于 Session 认证,主要有以下优势:
- 无状态: 服务端无需存储 Session 信息,减轻服务器压力,提高可用性和伸缩性。但也因此存在 JWT 失效不可控的缺点,需要额外处理。
- 防 CSRF 攻击: JWT 通常存储在 localStorage 中,不依赖 Cookie,避免了 CSRF 攻击。但需注意 XSS 攻击风险,可通过过滤可疑字符串等方式防范。
- 适合移动端: JWT 可被客户端存储,且可跨语言使用,解决了 Session 认证在移动端状态管理、兼容性和安全性上的问题。
- 单点登录友好: JWT 保存在客户端,避免了 Session 认证中 Cookie 跨域等问题,更易实现单点登录。
关于JWT的详细介绍,强烈推荐看看我写的这两篇文章:
项目用 Redis 有什么用?
Redis 除了可以用来缓存高频访问的数据之外,还以用来实现:
- 分布式锁 :通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:如何基于 Redis 实现分布式锁?。
- 限流 :一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的
RRateLimiter来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。 - 消息队列:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
- 延时队列:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
- 分布式 Session :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
- 复杂业务场景:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
面试中,根据你项目的实际情况去回答即可!
更多 Redis 高频知识点和面试题总结,可以阅读笔者写的这几篇文章:
- Redis 常见面试题总结(上)(Redis 基础、应用、数据类型、持久化机制、线程模型等)
- Redis 常见面试题总结(下)(Redis 事务、性能优化、生产问题、集群、使用规范等)
引入 Sentinel 的意义是?
Sentinel(哨兵) 只是 Redis 的一种运行模式 ,不提供读写服务,默认运行在 26379 端口上,依赖于 Redis 工作。Redis Sentinel 的稳定版本是在 Redis 2.8 之后发布的。
Redis Sentinel 实现 Redis 集群高可用,只是在主从复制实现集群的基础下,多了一个 Sentinel 角色来帮助我们监控 Redis 节点的运行状态并自动实现故障转移。
当 master 节点出现故障的时候, Sentinel 会帮助我们实现故障转移,自动根据一定的规则选出一个 slave 升级为 master,确保整个 Redis 系统的可用性。整个过程完全自动,不需要人工介入。

MySQL 同步 ES 的实现
使用 Canal 可以做到业务代码完全解耦,API 完全解耦,零代码实现准实时同步, Canal 通过解析 MySQL 的 binlog 日志文件进行数据同步。
Canal 的原理本质上是 模拟了 MySQL 的主从复制协议 :
- 伪装成从库 (Slave): Canal Server 会向 MySQL Master 发送和标准 MySQL Slave 完全一样的握手包,将自己伪装成一个从库。
- 订阅 Binlog: MySQL Master 验证通过后,就会把它当成一个真正的从库。从 Canal 指定的位点(Position 或 GTID)开始,持续地、流式地把二进制日志(Binlog)推送给 Canal。Binlog 记录了数据库中所有的数据变更操作(INSERT, UPDATE, DELETE)。
- 解析与投递: Canal 接收到这些原始的二进制日志流后,会在内部进行解析,将它们转换成结构化的、易于消费的数据格式(比如JSON)。最后,再将这些结构化的变更事件投递出去,通常是投递到像 Kafka 或 RocketMQ 这样的消息队列中,由下游的消费程序(比如我们的同步服务)订阅并写入到 Elasticsearch。
不过,Canal 仅仅支持增量同步。实际项目中,可以借助全量导入工具实现全量同步,例如 Datax ,后续再通过 Canal 实现增量同步,相对比较麻烦。
为了进一步提高系统性能和可维护性,我们通常会引入消息队列 (MQ) 作为中间层,解耦 Canal 和 Elasticsearch,
引入 MQ 的优势:
- 异步处理: Canal 将数据变更消息发送到 MQ 后,无需等待 ES 处理完成即可返回,提高 Canal 的吞吐量。
- 流量控制: MQ 作为缓冲区,可以削峰填谷,避免 Elasticsearch 瞬时写入压力过大。
- 数据处理: 可以在消费 MQ 消息的过程中进行数据清洗、转换等操作,例如数据格式化、字段映射等。
- 系统解耦: Canal 和 Elasticsearch 之间不再直接依赖,提高系统的可扩展性和可维护性。
引入 MQ 后,MySQL 数据同步到 Elasticsearch 的流程如下:

- 监听解析: Canal 读取 binlog,解析变更事件。
- 发送消息: Canal 将事件封装成消息发送到 MQ。
- 消费消息: 消费端监听 MQ,获取变更消息。
- 同步数据: 消费端处理消息,更新 Elasticsearch 索引。
Canal 从 1.1.1 版本开始,默认支持将接收到的 binlog 数据直接投递到 MQ,简化了集成流程。 你只需要配置 Canal 连接 MQ 的相关信息,即可实现 Canal 与 MQ 的联动。
项目难点是什么?
STAR 法则 是介绍项目经验的黄金法则:
- Situation (背景): "我参与的项目是 X(比如,一个电商秒杀系统/一个内容推荐平台/一个内部管理系统)。这个项目的主要目标是解决 Y 问题(比如,应对高并发抢购/提升用户点击率/提高管理效率)。"
- Task (任务): "我在其中主要负责 Z 模块(比如,订单处理模块/推荐算法实现/权限管理部分)的开发和维护。"
- Action (行动 - 重点讲难点和解决): "项目中遇到的一个主要挑战是 A(比如,秒杀场景下的库存超卖问题/推荐接口响应时间过长/复杂的权限校验逻辑)。为了解决这个问题,我/我们采取了以下措施:1.(比如,引入 Redis 分布式锁控制库存扣减的原子性);2.(比如,对推荐算法进行优化,并使用缓存减少计算量);3.(比如,设计了基于角色的访问控制模型 RBAC,并进行了细粒度的权限设计)。我具体做了 B(比如,负责锁方案的调研和编码实现/优化了部分算法逻辑/设计并实现了权限校验的核心代码)。"
- Result (结果): "通过这些努力,我们成功解决了 A 问题,最终效果是 C(比如,秒杀成功率提升了 X%,接口 RT 降低了 Y ms,系统安全性得到了保障),项目也顺利上线/达到了预期目标。通过这个项目,我深入学习了 D 技术(比如,分布式锁的应用/性能调优方法/复杂业务逻辑的设计),也提升了 E 能力(比如,解决复杂问题的能力/团队协作能力)。"
针对自己简历上的每个项目,至少准备 1-2 个有技术含量或业务复杂度的难点,想清楚解决过程和结果。不要只说功能实现,要突出技术选型、优化思路和遇到的挑战。
Java
为什么要用线程池?
池化技术想必大家已经屡见不鲜了,线程池、数据库连接池、HTTP 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。
线程池提供了一种限制和管理资源(包括执行一个任务)的方式。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。使用线程池主要带来以下几个好处:
- 降低资源消耗:线程池里的线程是可以重复利用的。一旦线程完成了某个任务,它不会立即销毁,而是回到池子里等待下一个任务。这就避免了频繁创建和销毁线程带来的开销。
- 提高响应速度:因为线程池里通常会维护一定数量的核心线程(或者说"常驻工人"),任务来了之后,可以直接交给这些已经存在的、空闲的线程去执行,省去了创建线程的时间,任务能够更快地得到处理。
- 提高线程的可管理性:线程池允许我们统一管理池中的线程。我们可以配置线程池的大小(核心线程数、最大线程数)、任务队列的类型和大小、拒绝策略等。这样就能控制并发线程的总量,防止资源耗尽,保证系统的稳定性。同时,线程池通常也提供了监控接口,方便我们了解线程池的运行状态(比如有多少活跃线程、多少任务在排队等),便于调优。
内置线程池用过吗?
在《阿里巴巴 Java 开发手册》"并发处理"这一章节,明确指出线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
为什么呢?
使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源开销,解决资源不足的问题。如果不使用线程池,有可能会造成系统创建大量同类线程而导致消耗完内存或者"过度切换"的问题。
另外,《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 构造函数的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
Executors 返回线程池对象的弊端如下(后文会详细介绍到):
FixedThreadPool和SingleThreadExecutor:使用的是阻塞队列LinkedBlockingQueue,任务队列最大长度为Integer.MAX_VALUE,可以看作是无界的,可能堆积大量的请求,从而导致 OOM。CachedThreadPool:使用的是同步队列SynchronousQueue, 允许创建的线程数量为Integer.MAX_VALUE,如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致 OOM。ScheduledThreadPool和SingleThreadScheduledExecutor:使用的无界的延迟阻塞队列DelayedWorkQueue,任务队列最大长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。
java
public static ExecutorService newFixedThreadPool(int nThreads) {
// LinkedBlockingQueue 的默认长度为 Integer.MAX_VALUE,可以看作是无界的
return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
// LinkedBlockingQueue 的默认长度为 Integer.MAX_VALUE,可以看作是无界的
return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));
}
// 同步队列 SynchronousQueue,没有容量,最大线程数是 Integer.MAX_VALUE`
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}
// DelayedWorkQueue(延迟阻塞队列)
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}线程池处理任务的流程是?

- 如果当前运行的线程数小于核心线程数,那么就会新建一个线程来执行任务。
- 如果当前运行的线程数等于或大于核心线程数,但是小于最大线程数,那么就把该任务放入到任务队列里等待执行。
- 如果向任务队列投放任务失败(任务队列已经满了),但是当前运行的线程数是小于最大线程数的,就新建一个线程来执行任务。
- 如果当前运行的线程数已经等同于最大线程数了,新建线程将会使当前运行的线程超出最大线程数,那么当前任务会被拒绝,拒绝策略会调用
RejectedExecutionHandler.rejectedExecution()方法。
再提一个有意思的小问题:线程池在提交任务前,可以提前创建线程吗?
答案是可以的!ThreadPoolExecutor 提供了两个方法帮助我们在提交任务之前,完成核心线程的创建,从而实现线程池预热的效果:
prestartCoreThread():启动一个线程,等待任务,如果已达到核心线程数,这个方法返回 false,否则返回 true;prestartAllCoreThreads():启动所有的核心线程,并返回启动成功的核心线程数。
如何跨线程传递 ThreadLocal 的值?
由于 ThreadLocal 的变量值存放在 Thread 里,而父子线程属于不同的 Thread 的。因此在异步场景下,父子线程的 ThreadLocal 值无法进行传递。
如果想要在异步场景下传递 ThreadLocal 值,有两种解决方案:
InheritableThreadLocal:InheritableThreadLocal是 JDK1.2 提供的工具,继承自ThreadLocal。使用InheritableThreadLocal时,会在创建子线程时,令子线程继承父线程中的ThreadLocal值,但是无法支持线程池场景下的ThreadLocal值传递。TransmittableThreadLocal:TransmittableThreadLocal(简称 TTL) 是阿里巴巴开源的工具类,继承并加强了InheritableThreadLocal类,可以在线程池的场景下支持ThreadLocal值传递。项目地址:github.com/alibaba/tra...
InheritableThreadLocal 原理
InheritableThreadLocal 实现了创建异步线程时,继承父线程 ThreadLocal 值的功能。该类是 JDK 团队提供的,通过改造 JDK 源码包中的 Thread 类来实现创建线程时,ThreadLocal 值的传递。
InheritableThreadLocal 的值存储在哪里?
在 Thread 类中添加了一个新的 ThreadLocalMap ,命名为 inheritableThreadLocals ,该变量用于存储需要跨线程传递的 ThreadLocal 值。如下:
JAVA
class Thread implements Runnable {
ThreadLocal.ThreadLocalMap threadLocals = null;
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
}如何完成 ThreadLocal 值的传递?
通过改造 Thread 类的构造方法来实现,在创建 Thread 线程时,拿到父线程的 inheritableThreadLocals 变量赋值给子线程即可。相关代码如下:
JAVA
// Thread 的构造方法会调用 init() 方法
private void init(/* ... */) {
// 1、获取父线程
Thread parent = currentThread();
// 2、将父线程的 inheritableThreadLocals 赋值给子线程
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
}TransmittableThreadLocal 原理
JDK 默认没有支持线程池场景下 ThreadLocal 值传递的功能,因此阿里巴巴开源了一套工具 TransmittableThreadLocal 来实现该功能。
阿里巴巴无法改动 JDK 的源码,因此他内部通过 装饰器模式 在原有的功能上做增强,以此来实现线程池场景下的 ThreadLocal 值传递。
TTL 改造的地方有两处:
- 实现自定义的
Thread,在run()方法内部做ThreadLocal变量的赋值操作。 - 基于 线程池 进行装饰,在
execute()方法中,不提交 JDK 内部的Thread,而是提交自定义的Thread。
如果想要查看相关源码,可以引入 Maven 依赖进行下载。
XML
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>transmittable-thread-local</artifactId>
<version>2.12.0</version>
</dependency>应用场景
- 压测流量标记 : 在压测场景中,使用
ThreadLocal存储压测标记,用于区分压测流量和真实流量。如果标记丢失,可能导致压测流量被错误地当成线上流量处理。 - 上下文传递:在分布式系统中,传递链路追踪信息(如 Trace ID)或用户上下文信息。
更多 Java 高频知识点和面试题,可以阅读笔者写的这几篇文章:
- Java并发常见面试题总结(上)(多线程基础知识,例如线程和进程的概念、死锁)
- Java并发常见面试题总结(中)(各种锁,例如乐观锁和悲观锁、
synchronized关键字、ReentrantLock) - Java并发常见面试题总结(下)(
ThreadLocal、线程池、Future、AQS、虚拟线程等)
列举你知道的垃圾收集器
Serial、Serial Old、ParNew、Parallel Scavenge、Parallel Old、CMS、G1、ZGC。
ZGC 是默认的吗?
ZGC 在 Java11 中引入,处于试验阶段。经过多个版本的迭代,不断的完善和修复问题,ZGC 在 Java15 已经可以正式使用了。
不过,默认的垃圾回收器依然是 G1。你可以通过下面的参数启用 ZGC:
bash
java -XX:+UseZGC className在 Java21 中,引入了分代 ZGC,暂停时间可以缩短到 1 毫秒以内。
你可以通过下面的参数启用分代 ZGC:
bash
java -XX:+UseZGC -XX:+ZGenerational classNameMySQL
不可重复读
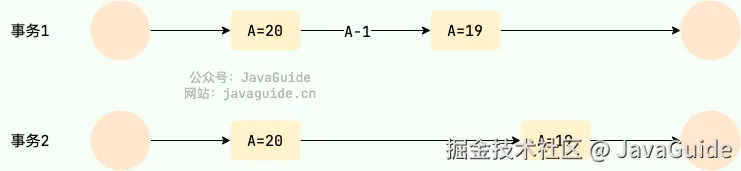
不可重复读(Unrepeatable read)指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 修改 A=A-1,事务 2 再次读取 A =19,此时读取的结果和第一次读取的结果不同。
不可重复读和幻读有什么区别?
- 不可重复读的重点是内容修改或者记录减少比如多次读取一条记录发现其中某些记录的值被修改;
- 幻读的重点在于记录新增比如多次执行同一条查询语句(DQL)时,发现查到的记录增加了。
幻读其实可以看作是不可重复读的一种特殊情况,单独把幻读区分出来的原因主要是解决幻读和不可重复读的方案不一样。
举个例子:执行 delete 和 update 操作的时候,可以直接对记录加锁,保证事务安全。而执行 insert 操作的时候,由于记录锁(Record Lock)只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁(Gap Lock)。也就是说执行 insert 操作的时候需要依赖 Next-Key Lock(Record Lock+Gap Lock) 进行加锁来保证不出现幻读。
InnoDB 的 REPEATABLE READ 隔离级别能解决幻读吗?
标准的 SQL 隔离级别定义里,REPEATABLE READ 是无法防止幻读的。但 InnoDB 的实现通过以下机制很大程度上避免了幻读:
- 快照读 (Snapshot Read) :普通的 SELECT 语句,通过 MVCC 机制实现。事务启动时创建一个数据快照,后续的快照读都读取这个版本的数据,从而避免了看到其他事务新插入的行(幻读)或修改的行(不可重复读)。
- 当前读 (Current Read) :像
SELECT ... FOR UPDATE,SELECT ... LOCK IN SHARE MODE,INSERT,UPDATE,DELETE这些操作。InnoDB 使用 Next-Key Lock 来锁定扫描到的索引记录及其间的范围(间隙),防止其他事务在这个范围内插入新的记录,从而避免幻读。Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的组合。
如何分析 SQL 性能?
我们可以使用 EXPLAIN 命令来分析 SQL 的 执行计划 。执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式。
EXPLAIN 并不会真的去执行相关的语句,而是通过 查询优化器 对语句进行分析,找出最优的查询方案,并显示对应的信息。
EXPLAIN 适用于 SELECT, DELETE, INSERT, REPLACE, 和 UPDATE语句,我们一般分析 SELECT 查询较多。
我们这里简单来演示一下 EXPLAIN 的使用。
EXPLAIN 的输出格式如下:
sql
mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | SIMPLE | cus_order | NULL | ALL | NULL | NULL | NULL | NULL | 997572 | 100.00 | Using filesort |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
1 row in set, 1 warning (0.00 sec)各个字段的含义如下:
| 列名 | 含义 |
|---|---|
| id | SELECT 查询的序列标识符 |
| select_type | SELECT 关键字对应的查询类型 |
| table | 用到的表名 |
| partitions | 匹配的分区,对于未分区的表,值为 NULL |
| type | 表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际用到的索引 |
| key_len | 所选索引的长度 |
| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
| rows | 预计要读取的行数 |
| filtered | 按表条件过滤后,留存的记录数的百分比 |
| Extra | 附加信息 |
更多 MySQL 高频知识点和面试题总结,可以阅读笔者写的这篇文章:MySQL 常见面试题总结。