引言
随着企业数据量的快速增长,数据分析已经成为业务决策的重要工具。openEuler 作为稳定的开源操作系统,不仅在企业环境中表现出色,还对各种开源软件库提供了良好支持。本文以 Python 数据分析库 Pandas 为例,展示如何在 openEuler 上完成从环境搭建、数据处理到可视化的完整数据分析流程。
接下来我来带大家在openEuler上使用Python的数据分析库 Pandas,来体验一下openEuler的强大吧。
一、环境搭建
在 openEuler 上进行数据分析,首先需要安装 Python 3 及数据分析所需库。openEuler 使用 dnf 包管理器,可轻松安装 Python 环境。
bash
# 更新系统软件包
sudo dnf update -y
# 安装 Python3
sudo dnf install -y python3 python3-pip
# 安装数据分析库
pip3 install pandas matplotlib seaborn

安装完成后,我会第一时间验证安装是否成功,以确保环境完全可用。验证方法非常简单,我通过执行以下 Python 命令来检查 Pandas、Matplotlib 和 Seaborn 是否能够正常导入,并输出 Pandas 的版本号:
假如说这一步你都不去验证的话,那后面出现了问题我们也不知道是哪里出现了问题,所以说每一步我们都必须要验证清楚。
Bash
python3 -c "import pandas as pd; import matplotlib.pyplot as plt; import seaborn as sns; print(pd.__version__)"
二、准备数据
为了演示完整的数据分析流程,我选择使用一个简单的销售数据 CSV 文件 sales.csv。这个文件记录了企业某段时间内的每日销售情况,包括三个字段:日期 (date)、产品名称 (product) 和销售额 (sales)。虽然数据量不大,但涵盖了典型的业务分析需求,例如按日期统计每日销售趋势、按产品汇总总销售额,以及分析不同产品的销售贡献比例。
Plain
date,product,sales
2025-01-01,Keyboard,100
2025-01-01,Mouse,150
2025-01-02,Keyboard,120
2025-01-02,Mouse,130
2025-01-03,Keyboard,90
2025-01-03,Mouse,160将 CSV 文件放在 /home/user/projects/data/ 目录下,后续 Python 程序即可读取。

三、数据分析流程
在我的数据分析实践中,我将整个流程分为四个核心环节:数据读取、数据清洗、数据处理和数据可视化。每一个环节都是保证分析结果准确和可用的重要步骤。在 openEuler 上,我使用 Pandas 完成了这一整套流程。
1. 读取数据
创建 analyze.py 文件,首先读取 CSV 数据:
python
import pandas as pd
# 读取 CSV 文件
df = pd.read_csv('/home/user/projects/data/sales.csv')
# 查看前几行
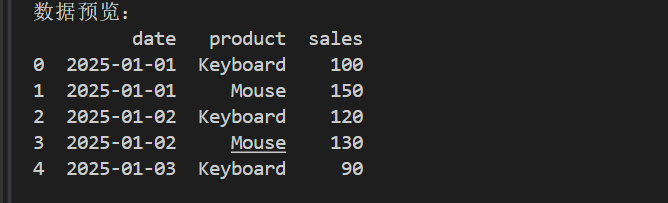
print(df.head())输出示例:
Plain
date product sales
0 2025-01-01 Keyboard 100
1 2025-01-01 Mouse 150
2 2025-01-02 Keyboard 120
3 2025-01-02 Mouse 130
4 2025-01-03 Keyboard 90这样,我们就将 CSV 数据加载到了 Pandas 的 DataFrame 中。
2. 数据清洗
在实际项目中,CSV 数据可能存在缺失值或格式错误。Pandas 提供了简单而高效的处理方法:
python
# 检查缺失值
print(df.isnull().sum())
# 填充缺失值(示例:销售额缺失填充为0)
df['sales'] = df['sales'].fillna(0)通过这一操作,可以保证后续统计和可视化不受数据缺失影响。

3. 数据处理与统计
3.1 按产品统计总销售额
python
# 按产品分组统计销售总额
summary = df.groupby('product')['sales'].sum()
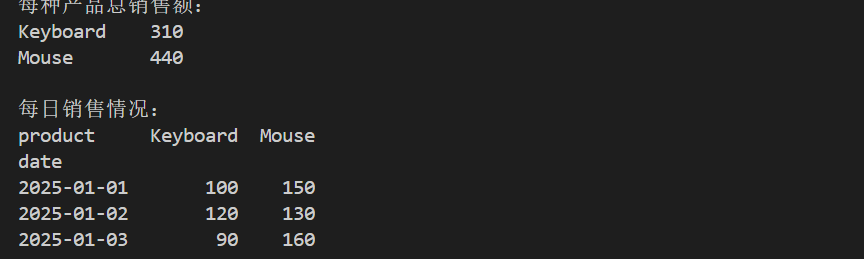
print(summary)输出:
Plain
product
Keyboard 310
Mouse 440
Name: sales, dtype: int643.2 每天各产品销售情况
python
# 将数据透视为每天各产品销售额
daily_sales = df.pivot(index='date', columns='product', values='sales')
print(daily_sales)输出:
Plain
product Keyboard Mouse
date
2025-01-01 100 150
2025-01-02 120 130
2025-01-03 90 160通过透视表,可以更直观地分析每日销售情况,为可视化做准备。
4. 可视化分析
可视化是数据分析的重要环节,Pandas 与 Matplotlib、Seaborn 配合可以轻松实现。
python
import matplotlib.pyplot as plt
import seaborn as sns
# 设置 Seaborn 风格
sns.set(style="whitegrid")
# 4.1 绘制总销售额柱状图
plt.figure(figsize=(6,4))
summary.plot(kind='bar', color=['skyblue','salmon'])
plt.title('Total Sales by Product')
plt.xlabel('Product')
plt.ylabel('Sales')
plt.savefig('sales_summary.png')
plt.show()
# 4.2 绘制每日销售趋势折线图
plt.figure(figsize=(8,5))
daily_sales.plot(marker='o')
plt.title('Daily Sales Trend')
plt.xlabel('Date')
plt.ylabel('Sales')
plt.xticks(rotation=45)
plt.grid(True)
plt.savefig('daily_sales_trend.png')
plt.show()运行:
Bash
python3 analyze.py程序会生成两张图表:
1.sales_summary.png:显示每种产品总销售额;
2.daily_sales_trend.png:展示每日销售趋势。
在 openEuler 上使用 Pandas,我们可以进一步扩展数据分析功能:
•统计分析:计算平均值、最大值、最小值等指标。
•复杂数据处理:合并多个 CSV、处理时间序列数据。
•高级可视化:使用 Seaborn 绘制热力图、箱线图等。
•自动化分析:结合 Cron 定时任务,实现每天自动生成报告。
比如说:计算每日平均销售额并绘制折线图:
python
daily_avg = df.groupby('date')['sales'].mean()
plt.figure(figsize=(8,5))
daily_avg.plot(marker='o', color='green')
plt.title('Daily Average Sales')
plt.xlabel('Date')
plt.ylabel('Average Sales')
plt.grid(True)
plt.savefig('daily_avg_sales.png')
plt.show()四、总结
在这次实践中,我在 openEuler 上完整体验了从环境搭建到数据分析、再到可视化的整个流程。通过这次案例,我有几个深刻的感受:
1.环境搭建非常简便 。openEuler 提供了稳定的系统管理工具和包管理机制,使得 Python3 和常用数据分析库可以快速安装并使用,无需复杂配置。这让我能够迅速进入数据分析的实际工作,而不被环境问题拖延。
2.数据处理效率显著提升 。Pandas 提供了强大的数据读取、清洗和处理功能,让我能够轻松处理业务 CSV 数据、统计分析和生成汇总结果。即使面对多源数据或时间序列数据,也能快速完成统计和汇总,节省了大量手动处理的时间。
3.可视化直观清晰 。通过 Matplotlib 和 Seaborn,我能够将分析结果快速转化为易于理解的图表,让数据趋势和关键指标一目了然。这在业务汇报和决策分析中非常有帮助,提升了分析结果的可读性和价值。
4.开源生态的优势非常明显。在 openEuler 上,我能够自由使用 Pandas、Matplotlib、Seaborn 等开源库,结合自身业务需求灵活扩展分析能力。无论是处理大数据量、统计分析,还是生成专业图表,都能够得到充分支持。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/