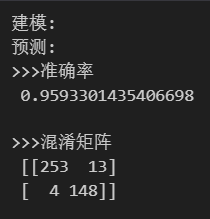
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.neural_network import MLPRegressor
import math
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.neural_network import MLPClassifier
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
#读入训练集和测试集及其标签:
train_data = pd.read_csv('mytrain.csv', lineterminator='\n')
test_data=pd.read_csv('mytest.csv', lineterminator='\n')
test_Lable=pd.read_csv('mygender.csv', lineterminator='\n')
testLable=list(map(int,test_Lable['Survived']))
#print(train_data.columns)
#训练集有缺失的都是坏数据,删了:
train_data.dropna(axis=0,inplace=True)
trainLen=len(train_data)
testLen=len(test_data)
#训练集标签特征分离:
trainLable= list(map(int,train_data['Survived']))
train_data=train_data.drop(['Survived'],axis=1)
print(train_data.columns)
#处理一下测试集里的缺失值,测试集的缺失数据不能删
#处理Fare,先看一下分布,发现明显有个众数非常突出,且训练集和测试集众数接近:
test_data['Fare']=test_data['Fare'].fillna(test_data['Fare'].dropna().mode()[0])
#把训练集和测试集合起来编码:
combineData = pd.concat([train_data, test_data], ignore_index=True)
#先编码后拆分:
def getReview(data,changeColumns):
ResultReview=[]
listReview=data
le = LabelEncoder()
for column in changeColumns:
listData=[]
for review in data[column]:
listData.append(review)
listReview[column]=le.fit_transform(listData)
#向量化(需要一个个的append):
for i in range(len(data)):
rowVec=[]
for j in range(0,len(data.columns)):
rowVec.append(listReview.iloc[i,j])
ResultReview.append(rowVec)
return ResultReview
changeColumns=['Sex','Embarked']
combine_Review=np.array(getReview(combineData,changeColumns))
scl = MinMaxScaler()
combineReview=scl.fit_transform(combine_Review)
trainReview=combineReview[0:trainLen]
testReview=combineReview[trainLen:trainLen+testLen]
python复制代码
#处理Age缺失值:
#获取空元素下标:
isNull = test_data['Age'].isnull().values
listAgeTrain=[]
listAgeTest=[]
for elem in trainReview:listAgeTrain.append(elem)
for i in range(0,len(isNull)):
if isNull[i]==False:listAgeTrain.append(testReview[i])
else: listAgeTest.append(testReview[i])
ageTrain = np.array(listAgeTrain)
ageTest=np.array(listAgeTest)
ageLable=ageTrain[:,2]
ageTrain=np.delete(ageTrain,2,axis=1)
ageTest=np.delete(ageTest,2,axis=1)
#预测Age:
print('预测测试集Age:')
model1 = GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.03, loss='huber', max_depth=15,
max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_samples_leaf=10, min_samples_split=40,
min_weight_fraction_leaf=0.0, n_estimators=300,
random_state=10, subsample=0.8, verbose=0,
warm_start=False) # 删除了 min_impurity_split 和 presort 参数
model2=MLPRegressor(activation='tanh', learning_rate='adaptive')
age_sum = []
for i in range(0,3):
print(i,'th training:')
model1.fit(ageTrain,ageLable)#模型训练
age_model1 = model1.predict(ageTest)#模型预测
model2.fit(ageTrain,ageLable)#模型训练
age_model2 = model2.predict(ageTest)#模型预测
age_sum.append(age_model1*0.5+age_model2*0.5)
age_model=[]
for i in range(len(ageTest)):
asum=0
for j in range(0,3):
asum=asum+age_sum[j][i]
age_model.append(asum/3)
print(age_model)
#把求出来的age填回去:
#先把空值的位置找出来:
nullIndex=[]
for i in range(0,len(isNull)):
if isNull[i]==True:nullIndex.append(i)
for i in range(0,len(nullIndex)):
testReview[nullIndex[i],2]=age_model[i]
#去除离群点:
rowLen=trainReview.shape[1]
shallDel=[]
for i in range(0,len(trainReview)):shallDel.append(0)
for j in range(0,rowLen):
min=np.percentile(trainReview[:,j],6)
max = np.percentile(trainReview[:, j], 94)
for i in range(0, len(trainReview)):
if (trainReview[i,j]<min) or (trainReview[i,j]>max):shallDel[i]=1
for i in range(len(trainReview)-1,-1,-1):
if shallDel[i]==1:
trainReview=np.delete(trainReview,i,axis=0)
trainLable = np.delete(trainLable, i, axis=0)