Linux系统中CPU访问内存的完整机制深度解析
摘要
在现代计算机系统中,CPU访问内存并非简单的"读取-写入"操作,而是一个涉及硬件缓存、MMU地址转换、操作系统页表管理以及NUMA架构调度的复杂协同过程。本文将从硬件架构到底层内核实现,深入剖析Linux系统中CPU访问内存的完整机制,涵盖Cache体系、MMU工作原理、TLB加速、页表遍历(Page Table Walk)及NUMA特性,并结合Linux内核源码(以v4.4为蓝本)展示关键数据结构,最后提供针对性的性能优化策略。
1. 概述:从虚拟地址到物理数据的旅程
当CPU执行一条内存访问指令(如 MOV EAX, [0x12345678])时,看似简单的操作背后隐藏着复杂的硬件与软件交互。整个流程大致可分为以下几个阶段:
- 虚拟地址生成:CPU核心产生虚拟地址(Virtual Address, VA)。
- TLB查找:MMU首先在TLB(Translation Lookaside Buffer)中查找该VA对应的物理地址(Physical Address, PA)。
- 页表遍历(Page Table Walk):若TLB未命中(TLB Miss),MMU硬件(或软件助手)将遍历内存中的多级页表,找到物理页框号。
- 缓存访问:获取PA后,CPU查询L1/L2/L3 Cache。
- 内存存取:若Cache未命中(Cache Miss),内存控制器(IMC)将请求发送至主存(DRAM),在NUMA架构下可能涉及跨节点访问。
下图展示了这一宏观流程:
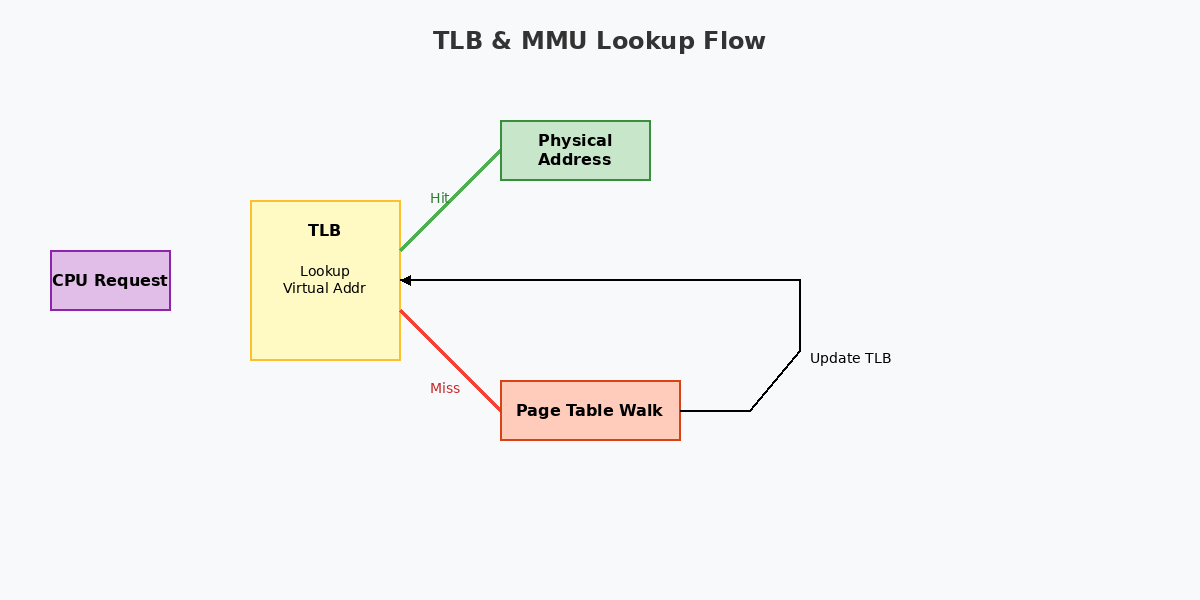
图1:CPU内存访问的宏观流程(TLB/MMU/Cache协同)
2. 硬件层面的CPU缓存体系
现代CPU为了弥补处理器速度与内存速度之间的巨大鸿沟(Memory Wall),引入了多级缓存体系。
2.1 缓存层级结构(L1/L2/L3)
典型的x86或ARM架构处理器通常包含三级缓存:
- L1 Cache (一级缓存) :
- 位置:紧贴CPU核心。
- 特点:速度最快(约3-4个时钟周期),容量最小(通常32KB-64KB)。
- 结构 :通常分为指令缓存(I-Cache)和数据缓存(D-Cache),即哈佛架构,避免指令流水线冲突。
- L2 Cache (二级缓存) :
- 位置:每个核心私有或共享(视架构而定)。
- 特点:速度次之(约10-12个时钟周期),容量较大(256KB-1MB)。
- 结构:统一存储指令和数据。
- L3 Cache (三级缓存/LLC) :
- 位置:多核心共享。
- 特点:速度较慢(约30-40个时钟周期),容量巨大(几MB到几十MB)。
- 作用:作为最后一级防线,减少访问主存的概率。
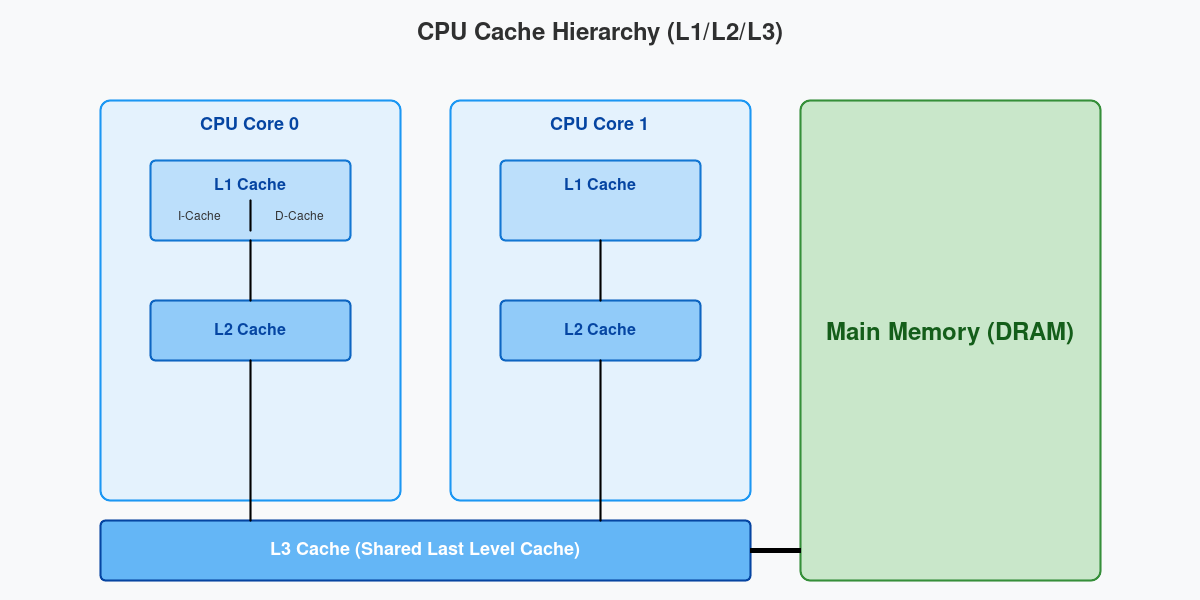
图2:多核CPU的L1/L2/L3缓存层级结构
2.2 缓存行(Cache Line)与映射
缓存并不是按字节存储,而是以**缓存行(Cache Line)**为单位,通常为64字节。这就引出了两个关键概念:
- 空间局部性:读取一个字节,会将相邻的64字节一起加载,利于顺序访问。
- 缓存一致性:多核环境下,需通过MESI等协议保证不同核心Cache中数据的一致性。
3. MMU与地址转换核心机制
Linux内核运行在虚拟地址空间,而硬件只能通过物理地址寻址。MMU(Memory Management Unit)是连接两者的桥梁。
3.1 MMU工作原理
MMU的主要职责是虚拟地址到物理地址的转换 以及内存权限检查。
- 转换:将VA映射到PA。
- 保护:检查当前进程是否有权限读/写/执行目标页面(例如,用户态进程不能访问内核空间)。
3.2 TLB(转换后备缓冲器)
TLB是MMU内部的一块高速缓存,专门存储"页表项(PTE)"的副本。
- 全相联/组相联:TLB通常采用高组相联结构以提高命中率。
- TLB Miss代价:一旦TLB Miss,CPU必须等待MMU访问内存中的页表,这会产生数十到数百个周期的延迟。
- TLB Shootdown :在多核系统中,当一个核心修改了页表(如
munmap),必须通知其他核心刷新TLB,这是昂贵的核间同步操作。
3.3 页表遍历(Page Table Walk)
当TLB未命中时,MMU硬件会自动遍历内存中的多级页表。Linux通常采用4级页表(在x86_64架构下):
- PGD (Page Global Directory):全局页目录,CR3寄存器指向其基址。
- PUD (Page Upper Directory):上层页目录。
- PMD (Page Middle Directory):中间页目录。
- PTE (Page Table Entry):页表项,指向最终的物理页(Page Frame)。

图3:四级页表(PGD -> PUD -> PMD -> PTE)遍历过程
内核数据结构解析
在Linux内核(v4.4)中,页表项定义在架构相关的头文件中。以下是x86架构下的关键定义:
c
/* linux/arch/x86/include/asm/pgtable_types.h */
typedef struct { pteval_t pte; } pte_t;
typedef struct { pmdval_t pmd; } pmd_t;
typedef struct { pudval_t pud; } pud_t;
typedef struct { pgdval_t pgd; } pgd_t;
/* 典型的页表标志位 */
#define _PAGE_BIT_PRESENT 0 /* 页面存在内存中 */
#define _PAGE_BIT_RW 1 /* 可读写 */
#define _PAGE_BIT_USER 2 /* 用户态可访问 */
#define _PAGE_BIT_ACCESSED 5 /* 页面被访问过(由CPU设置) */
#define _PAGE_BIT_DIRTY 6 /* 页面被写入过(由CPU设置) */
#define _PAGE_BIT_NX 63 /* 禁止执行(No Execute) */mm_struct 是描述进程内存空间的核心结构体:
c
/* linux/include/linux/mm_types.h */
struct mm_struct {
struct vm_area_struct *mmap; /* VMA链表 */
struct rb_root mm_rb; /* VMA红黑树 */
pgd_t * pgd; /* 指向顶级页表PGD的指针 */
atomic_t mm_users; /* 用户空间引用计数 */
atomic_t mm_count; /* 结构体引用计数 */
/* ... */
spinlock_t page_table_lock; /* 保护页表的自旋锁 */
/* ... */
};4. NUMA架构下的内存访问
在非一致性内存访问(NUMA)架构中,内存被划分到不同的节点(Node),每个CPU都有自己的本地内存(Local Memory)。
- 本地访问:CPU访问连接在同一总线/控制器上的内存,延迟最低。
- 远程访问:CPU访问其他节点的内存(通过QPI/UPI互联总线),延迟较高且带宽受限。
Linux内核通过libnuma和内核调度器尽量保证进程在分配内存的节点上运行(CPU Affinity),以减少远程内存访问。
5. 性能优化策略
理解了底层机制后,我们可以针对性地进行软件优化。
5.1 提升缓存命中率 (Cache Locality)
- 数据紧凑布局:使用结构体对齐(Struct Alignment)和数据压缩,使频繁访问的数据位于同一Cache Line中。
- 顺序访问:优先使用数组而非链表,利用硬件预取(Hardware Prefetching)机制。
- False Sharing避免 :多线程下,避免多个线程频繁写入处于同一Cache Line的不同变量。可以使用
__attribute__((aligned(64)))进行填充隔离。
5.2 减少TLB Miss
- Huge Pages (大页) :默认页面大小为4KB,使用2MB或1GB的大页可以大幅减少PTE数量,从而显著降低TLB Miss率。
- 内核开启:
Transparent Huge Pages (THP)。 - 应用层:使用
mmap的MAP_HUGETLB标志。
- 内核开启:
5.3 避免TLB抖动
- 减少上下文切换:进程切换会导致用户态TLB刷新(PCID特性可缓解),高频切换会严重影响性能。
5.4 NUMA感知优化
- 内存绑定 :使用
numactl --cpunodebind=0 --membind=0 ./app将进程绑定到特定节点。 - First-touch策略:Linux默认在第一次写入时分配物理页,因此初始化内存的线程应与处理该数据的线程位于同一节点。
6. 总结
CPU访问内存的过程是一个精密的接力赛:
- MMU 负责将虚拟世界的请求翻译成物理世界的坐标。
- TLB 作为翻译的"快查字典",极大加速了这一过程。
- Cache 体系作为数据的"高速缓冲",抵消了主存的慢速。
- Linux内核 通过页表管理和NUMA调度,指挥这套硬件高效运转。
对于开发者而言,编写对Cache友好(Cache-Friendly)和TLB友好(TLB-Friendly)的代码,是榨干硬件性能的关键所在。
参考文献
- Intel® 64 and IA-32 Architectures Software Developer's Manual
- Linux Kernel Source Code (v4.4.94)
- Ulrich Drepper, "What Every Programmer Should Know About Memory"