Anthropic 这家"AI 后期之秀"擅长在 Agent 工程领域"整活"。除了大家熟知的MCP(模型上下文协议)外,前两个月抛出了两个新概念:Skills (技能)与 程序化工具调用(PTC),并在自身的Claude开发平台落地支持。
虽然目前 Skills 、PTC主要在 Claude 生态中可用,但从它们的设计理念来看,不排除未来会成为各大Agent框架的"标配"。本文将带你聚焦拆解:MCP + PTC、Skills 与 Subagents 三者的定位、联系与应用,相信可以拓展你构建Agent系统的思维方式。
本文内容:
-
MCP+PTC:会"连招"的Agent工具箱
-
Skills:给Agent配备的"知识胶囊"
-
Subagents:"分而治之"的Agent架构
-
联系、区别与协同
001
MCP + PTC:会"连招"的Agent工具箱
时至今日,MCP 已经可以说是 Agent 开发领域最重要的开放协议之一,甚至可能是"最"重要的那个。它由 Anthropic 在 2024 年底提出,目前已经完成了两次规范的版本迭代,可见其在生态中的地位。
【MCP再回顾】
在 MCP 出现之前,如果你希望让 AI 访问你的本地文件、企业数据库或者第三方API,你需要为每个外部资源写"胶水代码"。这就像以前手机充电器接口各异,极难通用。
而 MCP 就是 AI 时代的 "USB-C":
它标准化了 AI 与外部世界的连接方式。
开发者可以把数据库、业务系统、API等访问等封装成一个 MCP Server,一次暴露,多处复用。任意一个具备 MCP 客户端能力的 Agent,都可以直接接入并使用这些能力,无需再次开发。
MCP的核心架构与能力用下图总结:

【PTC:程序化工具调用】
有了MCP,你可以给Agent"插上"大量工具,但是新的问题来了:在一次复杂的任务中,流程很容易变成这样:
LLM推理->工具调用->结果塞入上下文->LLM再推理->下一个工具调用...
这种反复来回的"乒乓球效应",带来的缺陷主要是:
- 高延迟:大量的网络往返与LLM推理,可能让响应从几秒变成几分钟
- 高成本:大量中间结果被塞入上下文,占Token,还影响推理质量
Anthropic 对此的解法是:一种新的工具调用方式 --- 程序化工具调用(PTC, Programmatic Tool Calling),用来优化上述场景中的问题。
其核心理念是:
让LLM编写一段完整的Python代码,并在安全的沙箱环境中运行,代码中直接包含了对多次MCP 工具的调用、逻辑循环、条件判断以及数学计算等。即:Agent通过编写程序来调用工具,而不是通过对话逐步推理出来。

举个简单例子:
"使用工具A从数据库查询所有订单,再用工具B生成分析图表"
如果通过传统方式,LLM 需要先拿到工具 A 的结果(大量订单记录),塞进上下文,再思考要不要调用 B --- 又慢又贵。而在PTC模式下:
orders = await toolA.query_orders()
chart = await toolB.generate_chart(orders)
return chart沙箱一次性执行完,由于少了中间结果的反复,响应与Tokens成本大大降低。
【MCP+PTC:工具调用的"连招"】
如果说MCP工具是招式,那么PTC就是一口气打出多个"连招":
-
MCP提供了"原子化"的工具能力(查询、读写文件、API调用)
-
PTC提供了基于代码的"粘合剂"(工具调用、循环、条件判断、过滤)
但,PTC 本质上是"自动写代码",适合执行确定性强、流程相对固定的任务,但不是所有的任务都适合PTC。特别是:当工具调用结果需要依赖LLM来进行推理、理解以判断下一步行为时,PTC可能就不适合。比如:
"帮我分析这份商务合同,如果有严重风险,生成一份免责说明;否则给出修改建议。"
由于这里需要LLM作语义判断以推理风险等级,这是一个典型的"LLM决策点",无法用PTC代码来直接写死,因此更适合经典的Agent循环模式。
002
Skills:给Agent的"知识胶囊"
在理想世界里,我们希望Agent什么都会。但现实是(特别是在专业领域),Agent往往缺乏足够的"知识"来知道"怎么做",比如操作流程、应该使用的Python模块、采用的模板等。而且你无法把所有的经验与指南都塞入上下文 --- 毕竟空间有限。
【Skills:模块化的"知识胶囊"】
Skills是一种用来以模块化方式给 LLM 注入专业技能的机制。它在物理上是一个"文件夹",里面包含:
-
一个核心说明文件 SKILL.md
-
相关的脚本/代码
-
其他资源文件(文档、模板、示例等)
这些内容告诉LLM:"遇到这类任务时该怎么做"。这是一个官方处理PDF文件的技能目录:

当用户输入任务"请把我上传的PDF文件提取成文本"时,LLM 会自动匹配到这个Skill,阅读其中的指南,然后根据其中的说明编写代码或调用工具、运行并获得结果。
在整个过程中,操作细节不是靠LLM自行"猜",而是由Skill中的文档给出指示。
【Skills核心机制:"渐进式披露"】
那么LLM是如何知道用哪个Skill的?难道要把所有Skill资料一股脑塞进上下文?显然不是。这涉及到Skills的核心理念:渐进式披露(Progressive Disclosure),即:LLM对Skills的了解是一种"渐进式"的方式。
这种方式的出发点仍然来自于"上下文危机":在复杂Agent运行时,由于不断注入大量的专业知识、工具信息、调用结果、对话历史等。你可能会面临:
- 上下文爆炸,有用信息被挤出
- Tokens成本飙升,且存在浪费
- 信息被稀释,LLM推理出错概率增大
- 性能下降,Agent响应延迟
想象下,如果你需要把上百个MCP Server中的工具说明、流程指引等加载进上下文,Agent将会"记忆过载"。
当前应对上下文危机的主要方法是借助上下文工程的长期Memory方案。
Skills采用的策略是:
让Agent可以访问大量技能,但不会一次性"灌输式"教学,而是"按需加载"。
这种渐进式披露的运作机制如下:
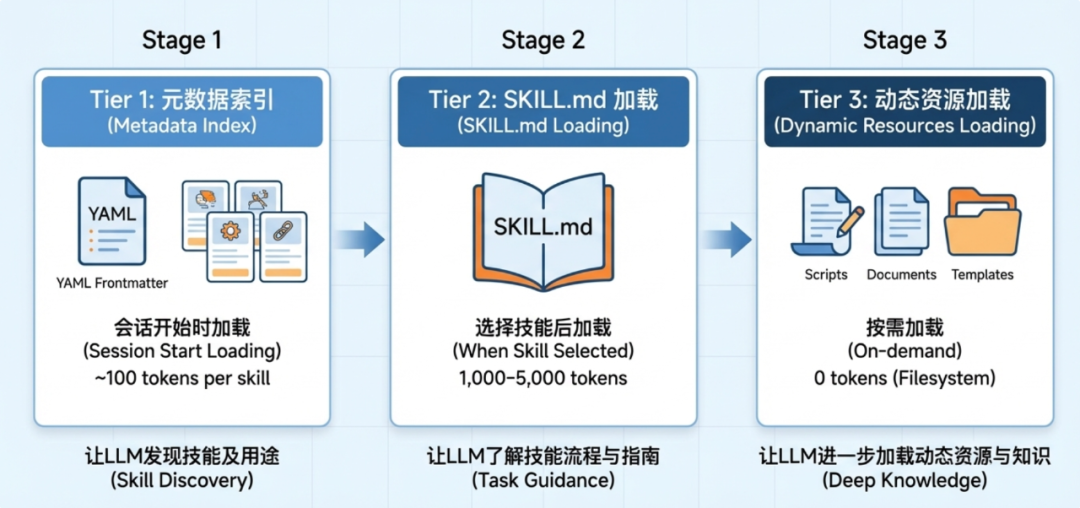
第一层:技能发现
会话开始时从SKILL.md文件的元数据区域加载名称与描述,用于发现技能。具体来说就是把name和description注入系统Prompt。
第二层:技能理解
当LLM识别需要使用某个Skill时,会加载该技能的完整SKILL.md,以了解真正的技能指南。
第三层:资源按需加载
在使用技能时,如果发现有额外的动态资源需要读取(文档、模板、脚本等),则按需加载对应资源。
以下是官方的PDF技能在每个阶段被注入到上下文的内容:

注意到,对于需要编程处理的任务,开发者可以在Skill目录放置 Python 脚本。当Agent使用该Skill时,可以加载这些代码在安全沙盒中执行,这样比让LLM生成代码更高效、更可控。
003
Subagents:"分而治之"的Agent架构
当面对一个复杂的任务 --- 比如"对整份文档做全面审核并给出修复建议"时,单一的Agent(即使配备 MCP+Skills)会遇到麻烦:
- 角色混乱 :一个 System Prompt 同时包含"专业的创作者"和"严苛的审核员"两种截然不同的人设,容易造成混乱。
- 上下文污染:各种任务指令、文档内容、工具说明、调用结果等挤在同一个上下文里,LLM可能会忘记最初目标。
【Subagents:"分而治之"】
Claude开发平台的Subagents就是旨在通过"分而治之"的策略来解决上述问题:
把复杂任务拆成几个可控的子任务,由不同的 Agent 专家分别处理,各司其职,互不干扰。

Subagents本质是多智能体系统的一种实现,并非Claude独有。其好处是:
- 上下文隔离:每个 Subagent 都在独立环境中运行。主Agent将子任务指派给 Subagent,Subagent 可能会开展大量的中间处理。但最终只会向主Agent返回一个"精炼"结果,主Agent上下文不会被"污染"。子Agent之间也不会相互干扰 --- AI"测试员"的几千条错误日志不会塞满AI"架构师"的思考空间。
- 专业化配置:每个 Subagent 可以拥有自己独立的 System Prompt、模型选择、可用工具,Skills等。
- 独立权限控制:你可以创建给不同的Subagent只赋予其某些工具权限,从而最大限度降低误操作风险 。
下面是定义两个Subagents的例子:
......
subagents_config = {
# 子智能体 1:安全审计专家
'security-auditor': AgentDefinition(
description='Expert in identifying security vulnerabilities (OWASP Top 10). Use this agent for code review.',
prompt='You are a rigorous security auditor. Focus ONLY on SQL injection, XSS, and auth bypass. Be extremely critical.',
tools=['read_file', 'grep'], # 限制工具:只读,不可修改代码
model='claude-3-5-sonnet-20240620'# 使用最强模型进行深度分析
),
# 子智能体 2:测试运行员
'test-runner': AgentDefinition(
description='Executes test suites and reports results. Use this agent after code changes.',
prompt='You are a QA engineer. Your job is to run tests, analyze failure logs, and report pass/fail rates.',
tools=['bash', 'read_file'], # 允许运行 bash 命令
model='claude-3-haiku-20240307'# 使用快速模型处理简单执行任务
)
}最新LangChain的DeepAgents框架中也有用来完成子任务的Subagent机制。
004
联系、区别与协同
现在我们来总结这三种不同的Agent机制。
【MCP+PTC:连接层机制】
它们更多的是一种基础设施。它给Agent提供了更简洁与丰富的访问外部资源的能力,并通过 PTC 提高执行效率。后续的Skills 和 Subagents 都可以依赖 MCP/PTC/工具调用之上来实现。
当需要让LLM访问某个外部数据/API,应优先想到MCP。
比如:我要让AI查询公司的CRM数据库。
【Skills:认知层机制】
Skills用来告诉LLM在面对某类问题"怎么做",其定位在于提供标准、可复用的"知识胶囊"。很适合特定领域内的单一、明确、通用、可复用的小任务,比如转换文档、生成模板报告、规范化代码等这类任务。
当希望为Agent注入特定任务的知识时,可以编写Skill。
比如:我要让AI了解如何创建规范的React项目结构。
【Subagents:组织层机制】
该机制让Agent从独立工作的个人过渡到带领团队工作。适合复杂、多步骤、多子任务/子流程、大 context 或需要角色分工 (比如"代码审查专家"、"数据分析专家"、"研究专家") 的任务。
当发现Agent承担了太多的职责而难以管理时,考虑Subagents。
比如:我要构建一个开发智能体,既能做架构、又能写代码、还能做测试。
表格总结如下:

【Subagent + Skill + MCP/PTC 的协同】
最后,我们用三者间的一个协同场景来结束本文:
-
主 Agent 接到一个复杂任务 ( "给这个项目生成完整报告 + 做代码审查 + 更新文档 + 汇总结果")。
-
主 Agent 将"代码审查"子任务交给 Review Subagent --- 它用独立 Context +专属工具去分析代码库,不污染主 Context,也能并行处理多个文件。
-
子任务里若需要格式化 /转换 /模板生成 (例如把分析结果生成 Markdown 报告),Subagent 内部可以使用一个 Skill来完成。
-
若子任务还需访问公司数据库 / APIs 获取数据 (例如Bug跟踪, 提交历史),Subagent (或 Skill) 通过 MCP 工具/PTC 来获得这些数据。
-
子代理处理完,把最终结果以简洁总结形式返回给主 Agent。主 Agent 收集多个 Subagent 的结果,整合 / 合成最终输出给用户。
这种组合方式将 分工 (Subagent) 、 领域技能 (Skill) 和 工具 (MCP +PTC) 三层有机结合,既保证效率、可维护性,也保证系统灵活与扩展性。