C 程序相关的 2 个环境
C 语言标准定义了 2 个和 C 程序相关的环境(详细内容可以参考 C23 标准的5 Environment ,5.1 Introduction章节或早期标准的相关章节):
- 编译器在翻译环境(Translation Environment) 中编译文本格式的 C 程序;
- 编译好的 C 程序可以在执行环境(Execution Environment) 中进行执行;
这两个环境可以相同也可以不同,使用 GCC 编译 C 源码时,默认会生成适用于当前机器的目标代码,此时 2 个环境实际上就是同一个。但通过 交叉编译,GCC 也能产生适用于其他机器的目标代码(参考 GCC 的 -march 选项 ),此时 2 个环境就是不同的。支持交叉编译是为了允许"生成代码的地方"和"运行代码的地方"可以不同,从而实现可移植性、灵活的开发部署和更广泛的硬件覆盖。
这种翻译与执行环境分离的情况,并不仅限于 C 语言,而是不少编译型语言都会面临的问题,比如:
- Rust 语言在编译时可以通过 rustc的 --target选项来指定目标平台;
- Go 语言在编译时可以通过环境变量 GOOS 和 GOARCH 来指定目标平台;
不过并非所有的编译型语言都需要处理这个问题,比如:
- Java 程序被编译为字节码,直接运行在JVM 中;
- C# 程序被编译为中间语言,运行在 .NET 框架的 CLR 中;
C 程序翻译的 8 个阶段
C 语言标准将 C 程序的翻译过程分解为以下 8 个阶段(详细内容可以参考 C23 标准的 5.2.1.2 Translation phases章节或早期标准的相关章节):
阶段 1,转换源码字符集
比如将源代码文件中表示换行的字符统一转换为**\n** :Windows 平台通常使用**\r\n** 两个字符来换行,Unix/Linux 平台通常使用**\n** 表示换行,Mac 平台通常使用 \r 表示换行;
再比如将**三联符(Trigraph Sequence)**替换为对应的单字节字符(不过你应该鲜有遇见这种奇怪的三联符,它已经是过去式了,随着 ASCII 和 Unicode 字符集的广泛支持,C23 开始不再支持三联符):
|----------|----------|----------|----------|---------|----------|
| 三联符 | 对应字符 | 三联符 | 对应字符 | 三联符 | 对应字符 |
| ??( | ** | **??)** | ** | ??' | ^ |
| ??< | { | ??> | } | ??! | ∣ |
| ??/ | \ | ??= | # | ??- | ~ |
阶段 2,合并物理行
紧邻在换行符前的反斜杠字符 **\**会被删除,从而将物理行拼接成逻辑行。
cpp
#include <stdio.h>
int main ( void )
{
printf("Merge Line\n"); /* (1) */
printf("Merge \
Line\n"); /* (2) */
printf("Merge \
Line\n"); /* (3) */
return 0;
}上述代码片段中语句(1)和(2)是完全等价的,但它们区别于语句(3),因为Line\n 之前的空格也会被保留。
这里再给出一个思考题,如下程序输出的结果是什么?
cpp
#include <stdio.h>
#define X \
#define Y 100
int main ( void )
{
printf("Y is" X
"%d\n", Y);
return 0;
}(💀 如果你的答案是 Y is 100 的话,不妨自行编译运行一下)
阶段 3,生成预处理标记
对源代码进行词法分析 ,将其中的文本解析为预处理标记(Preprocessing Token)和空白,并且代码中的注释会被替换为一个空格字符;
阶段 4,预处理
执行 #include、#error、#define、#define、#warning、#embed 等各种预处理指令,并且展开宏调用。
阶段 5,映射源码字符集
源码字符集 中的字符会被转换为执行字符集 中的字符。比如源代码文件可能是使用 GBK 编码的,但可以将其转换为 UTF-8 编码,这样在执行环境中使用的各种输出信息就是 UTF-8 的(GCC 编译器提供的**-finput-charset** 和 -fexec-charset 选项就是用于指定源码字符集和执行字符集)。
阶段 6,合并字符串
相邻的字符串常量会被合并为单个字符串。
利用这一点就可以将较长的字符串常量书写在多行中,以保证良好的编码风格,比如:
cpp
printf("This is the first part"
" and this is the second part"
" and this is the last part\n"
);在输出软件版本号等信息时,也可以利用这一特性,比如:
cpp
#define PROGRAM_NAME "Foo"
#define MAJOR_VER "13"
#define MINOR_VER "10"
#define PATCH_VER "23"
int main ( void )
{
printf(PROGRAM_NAME " " MAJOR_VER "." MINOR_VER "." PATCH_VER "\n");
return 0;
}值得注意的是,上述程序可以工作的一个容易忽视但重要的原因是 "预处理" 阶段早于 "合并字符串" 阶段。
阶段 7,语法和语义分析
预处理标记 被转换为标记(Token),转换后的所有标记构成了一个翻译单元,编译器会继续从语法和语义层面对其进行分析和翻译,最终生成目标代码。
比如关键字、标识符就是一种标记,但 include、define、ifdef 等预处理指令却不是标记,甚至它们都不是关键字,因为它们在预处理阶段之后就已然不存在了,更不用说它们还具有何种语义了。
阶段 8,链接其他库
不严谨的说,不同源文件的编译是相互独立的,如果 file1.c 中的函数调用了 file2.c 中的函数,那么这两个文件编译后的目标文件需要被合并在一起,最终生成一个可执行程序或者库文件。
所以这个阶段的目的就是解析源码中各种外部对象和函数的引用,只有引用的对象或函数的确存在,才能成功链接。
小结

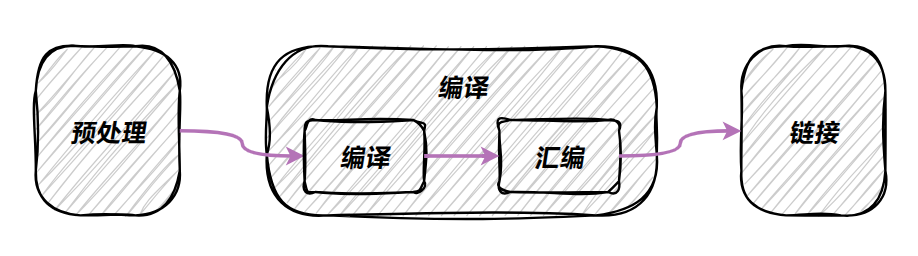
对于上述 8 个阶段,通常步骤 1-4 被称为**"预处理"** ,步骤 5-7 被称为**"编译",步骤 8 被称为"链接"**,其中 ++编译++ 通常会被进一步的处理为 ++编译++ 和 ++汇编++ 2 个子阶段。
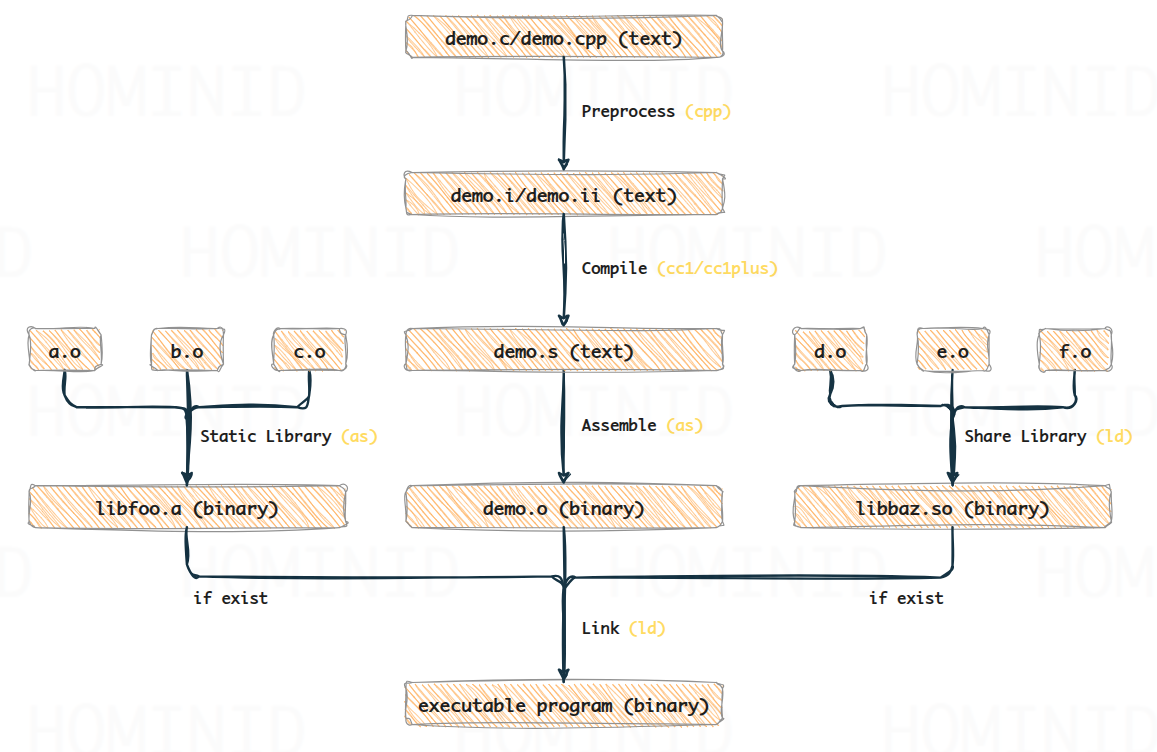
GCC 的编译流程及选项
概述

GCC 就是 GNU 开发的编译器,最初就是由 Richard Stallman 编写的,如果你对 Richard Stallman 以及他所追求的自由不熟悉的话,可以阅读 《自由软件和开源软件》 。
使用 gcc 进行编译时,通常会经历 预处理 、 编译 、 汇编 和 链接 这 4 个阶段。它实际上是通过调用 预处理器 、 编译器 、 汇编器 以及 链接器 来实现这些步骤,所以 gcc 本质上是一个驱动程序(可以通过 gcc -### no-exist-file.c 来查看编译器、汇编器和链接器的子命令);
g++ 则是 GNU 的 C++ 编译器,但无论是 gcc 还是 g++ 都可以编译 C/C++ 的代码:
- 编译 C 源文件 或 指定 -x c选项时, gcc 和 g++ 会按照 C 语言语法进行编译;
- 编译 C++ 源文件 或 指定 **-x c++**选项时, gcc 和 g++ 会按照 C++ 语言语法进行编译;
- g++ 会调用 gcc 并且自动链接 C++ 相关的库,而 gcc 不会自动链接;
- __cplusplus 宏:实际上,这个宏只是标志着编译器将会把代码按 C 还是 C++ 语法来解释,与使用 gcc 还是 g++ 无直接关系;
除非使用了 -E 、 -S 、 -c 选项或编译错误,否则 GCC 总是执行到最后的步骤(即生成可执行程序)。以下描述虽然是针对 C 语言的,但同样适用于 C++ 语言。
C 标准并没有规定各个阶段文件的扩展名,以下是 Unix/Linux 平台下 C 各个编译阶段的文件扩展名:
| 文件 | 所需处理 | 扩展名 |
|---|---|---|
| 头文件 | 不编译,被源文件包含 | h |
| 源文件 | 预处理、编译、汇编、链接 | c |
| 预处理文件 | 编译、汇编、链接 | i |
| 汇编文件 | 汇编、链接 | s |
| 目标文件 | 链接 | o |
| 静态库 | 链接 | a |
| 共享库 | 链接 | so |
预处理(-E)
预处理相当于根据预处理指令生成新的 C/C++ 源代码,预处理会产生一个没有宏定义,没有条件编译指令,没有特殊符号的输出文件,这个文件的含义同原本的文件无异,只是内容上有所不同。
gcc 和 g++ 通过调用预处理器 cpp 来实现预处理,经过预处理后的 预处理文件 依然是文本文件(注意这里的 cpp 并不是指 C++,而是指 c preprocessor)。
bash
gcc -E <FILE.c> -o <FILE.i> # 等价于执行 cpp <FILE.c> -o <FILE.i>gcc 预处理阶段的其他部分选项:
- -P:和 -E 一起使用,让预处理器不插入额外的行(这些额外的行用来记录源文件和行数,允许编译器参考这些信息来报错,这些行并不会影响程序本身);
- -C:和 -E 一起使用,让预处理器不要丢弃注释;
- -I DIR:表示在头文件的搜索路径列表中添加 DIR 目录;
- --include FILE:指定额外包含的头文件;
- -D FOO=VAL:表示定义 FOO 宏,且值为 VAL;
- -U FOO:表示取消宏 FOO 的定义;
编译(-S)
编译是将预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后,产生相应的汇编文件。
gcc 和 g++ 通过调用编译器cc1/cc1plus 来实现编译,经过编译后的 汇编文件 依然是文本文件 (注意是 cc1 而不是 ccl,操作系统通常没有配置 cc1/cc1plus 的路径) ;
bash
gcc -S <FILE.i> # 等价于执行 cc1 <FILE.i> -o <FILE.s>gcc 编译阶段的其他部分选项:
- -finput-charset:指定源文件的编码,如果 locale 未指定或者 GCC 无法从中获取地域信息,则默认 UTF-8;
- -fexec-charset:指定执行字符集,默认是 UTF-8;
- -march=TYPE:表示生成适用于指定 CPU 类型的指令;
- -m32/-m64:生成 32/64 位的代码,链接时需要相关的 32/64 位的库和目标文件存在;
- -std=STD:该选项用于指定编译 C/C++ 时遵循的标准(也可以用于预处理阶段,比如指定 -std=c89 时,不支持单行注释);
- -pedantic:表示对程序进行更严格的检查,要求程序严格遵循 ISO C/C++ 标准,对于不复合标准的特性以及扩展的特性给出警告;
- -fhosted:表示目标环境是一个宿主环境;
- -ffreestanding:表示目标环境是一个独立环境;
汇编(-c)
汇编是将编译完的汇编代码文件翻译成机器指令,并生成可重定位目标文件。每条汇编语句几乎都对应一条机器指令,所以汇编器的汇编过程相对于编译器来讲比较简单,它没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译即可。
gcc 和 g++ 通过调用汇编器as 来实现汇编,经过汇编后的 目标文件 是二进制文件;
bash
gcc -c <FILE.s> # 等价于执行 as <FILE.s> -o <FILE.o>gcc 汇编阶段的其他部分选项:
- -Wa:将选项传递给汇编器,多个参数使用逗号分隔;
- -Xassembler:和 -Wa 类似,但一次只能传递一个参数;
链接
将若干个目标文件(可能还有库文件)链接在一起生成一个完整的可执行程序,即解决多个文件之间符号引用的问题:比如某个源文件可能引用了另一个源文件中定义的符号,还可能调用了某个库文件中的函数等。链接器的主要工作就是将有关的目标文件彼此相连接,即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够被操作系统装入执行的统一整体。
gcc 和 g++ 通过调用链接器 collect2 来实现链接的 (但它是通过调用ld实现链接的) ,链接后的 可执行程序是二进制文件。
链接选项非常复杂,从来都不需要用户输入,以下是一种参考:
bash
ld ld-linux.so.2 crt1.o crti.o crtbegin.o <USER_OBJECTS> <SYSTEM_LIBRARIES> crtend.o crtn.ogcc 链接阶段的其他部分选项:
- -l FOO:表示链接名为 FOO 的库文件,本质上就是依据指定的 FOO 参数,查找文件名为 libFOO.a 或 libFOO.so 的库 (链接器只识别不带版本号的库名) ;
- -L DIR:表示在库文件的搜索路径列表中添加 DIR 目录(即搜索 -l 指定的库时,优先在该目录下查找);
- -Wl:将选项传递给链接器,多个参数使用逗号分隔;
- -Xlinker:和 -Wl 类似,但一次只能传递一个参数;
小结