一、网络爬虫的介绍
1、网络爬虫库
网络爬虫通俗来讲就是使用代码将HTML网页的内容下载到本地的过程。爬虫网页主要是为了获取网页中的关键信息。python语言中提供了多个具有爬虫功能的库
1)urllib库
是python自带的标准库,不用下载。含有大量爬虫功能,但其代码编写比较复制
2)requests库
是python的第三方库,需要下载。由于requests库是在urllib库的基础上建立的,它包含urllib库的功能,所以使用此库会更简洁
3)scrapy库
是python的第三方库,需要下载,是适用于专业应用程序开发的网络爬虫库
4)selenium库
是python的第三方库,需要下载,可用于驱动计算机中的浏览器执行相关命令,无须用户手动操作
本篇主要介绍requests库和selenium库
2、robots.txt
不是所有的网站都允许被爬取,在大部分网站的根目录中存在一个robot.txt文件,用于声明此网站中禁止访问的url和可以访问的url。在这里就不详细介绍了,想要了解里面内容可以去网上查找
二、获取网页资源
requests库具有获取网页内容和向网页中提交信息的功能
1、get()函数
在requests库中获取HTML网内容的方法是使用get()函数形式如下:
get(url,params=None,**kwargs)
参数url;表示需要获取的HTML网址
参数params:表示可选参数,以字典的形式发送信息,当需要向网页中提交查询信息时使用
参数**kwargs:表示请求采用的可选参数
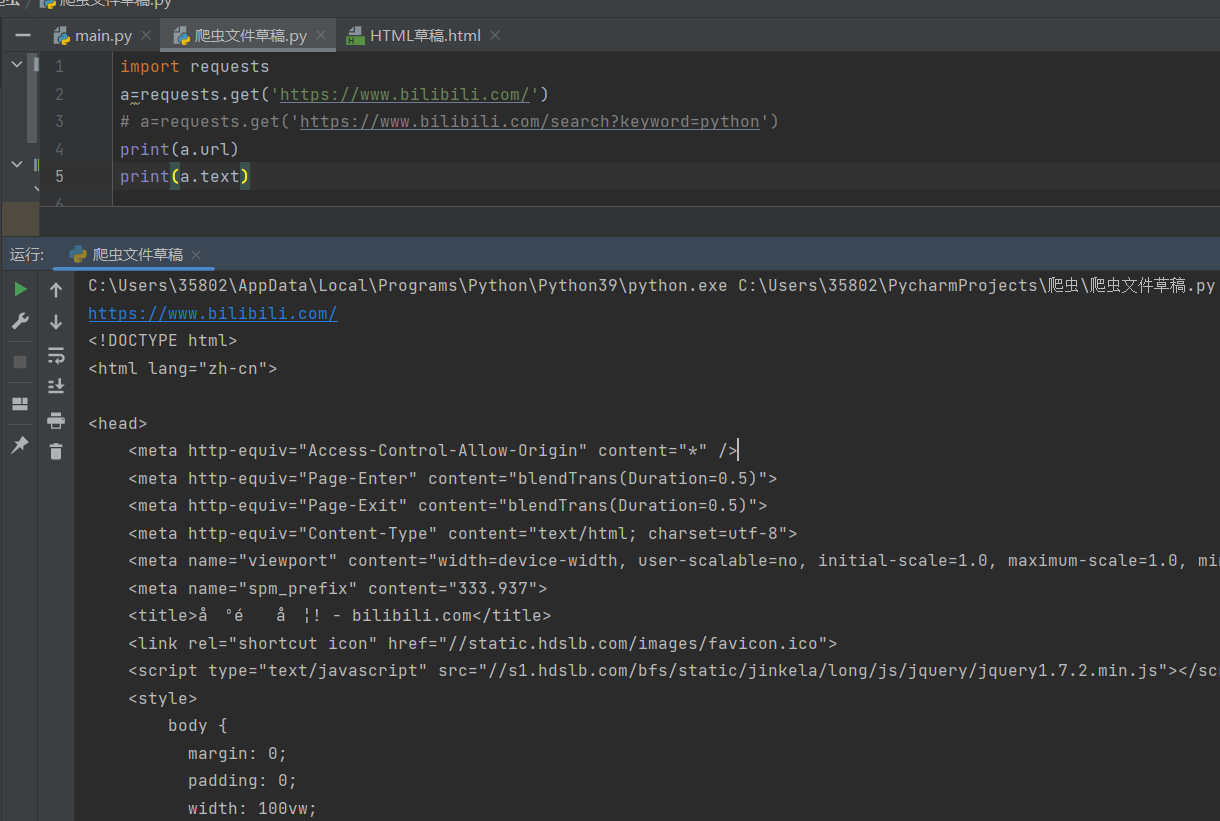
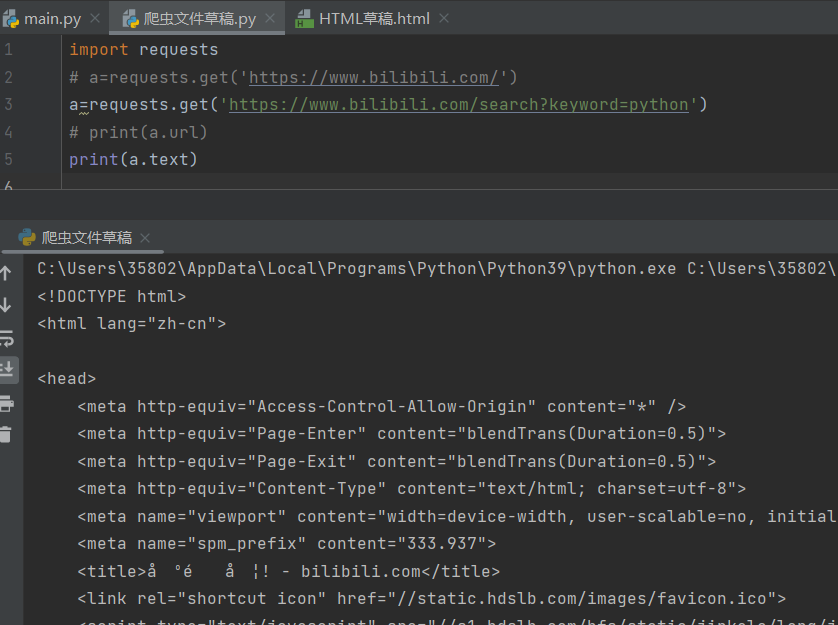
2、get()搜索信息
在网页搜索bilibili中,输入关键字python,可以看到下图的信息
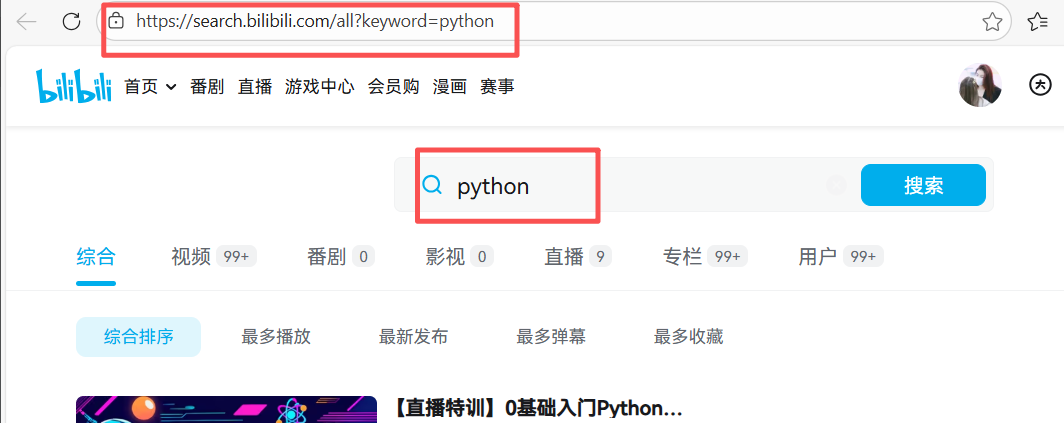
在搜索结果网页中可以看到当前页面的网址为https://www.bilibili.com/search?keyword=python,其中https://www.bilibili.com/为官网主页,search表示搜索,keyword表示搜索的关键字,这里值为python表示需要搜索的关键词是'python'
在requests库中可以充分利用以上方法实现获取网页中的资源
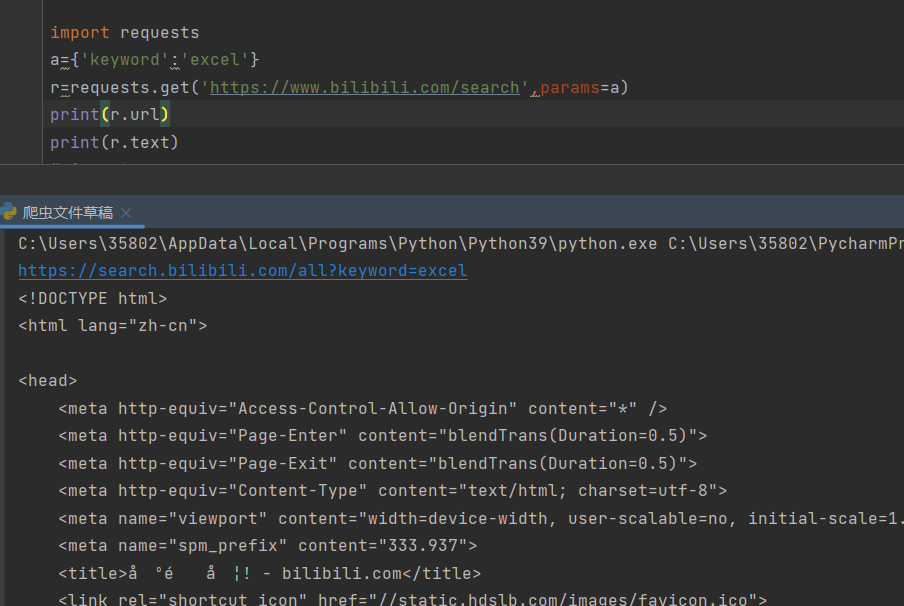
3、get()添加信息
get()函数中第二个参数params会以字典的形式在url后自动添加信息,需要提取将params定义为字典
三、项目案例:实现处理获取的网页信息
项目描述
使用get()函数获取HTML网页源代码的目的在于让获取的信息为用户所用
项目任务
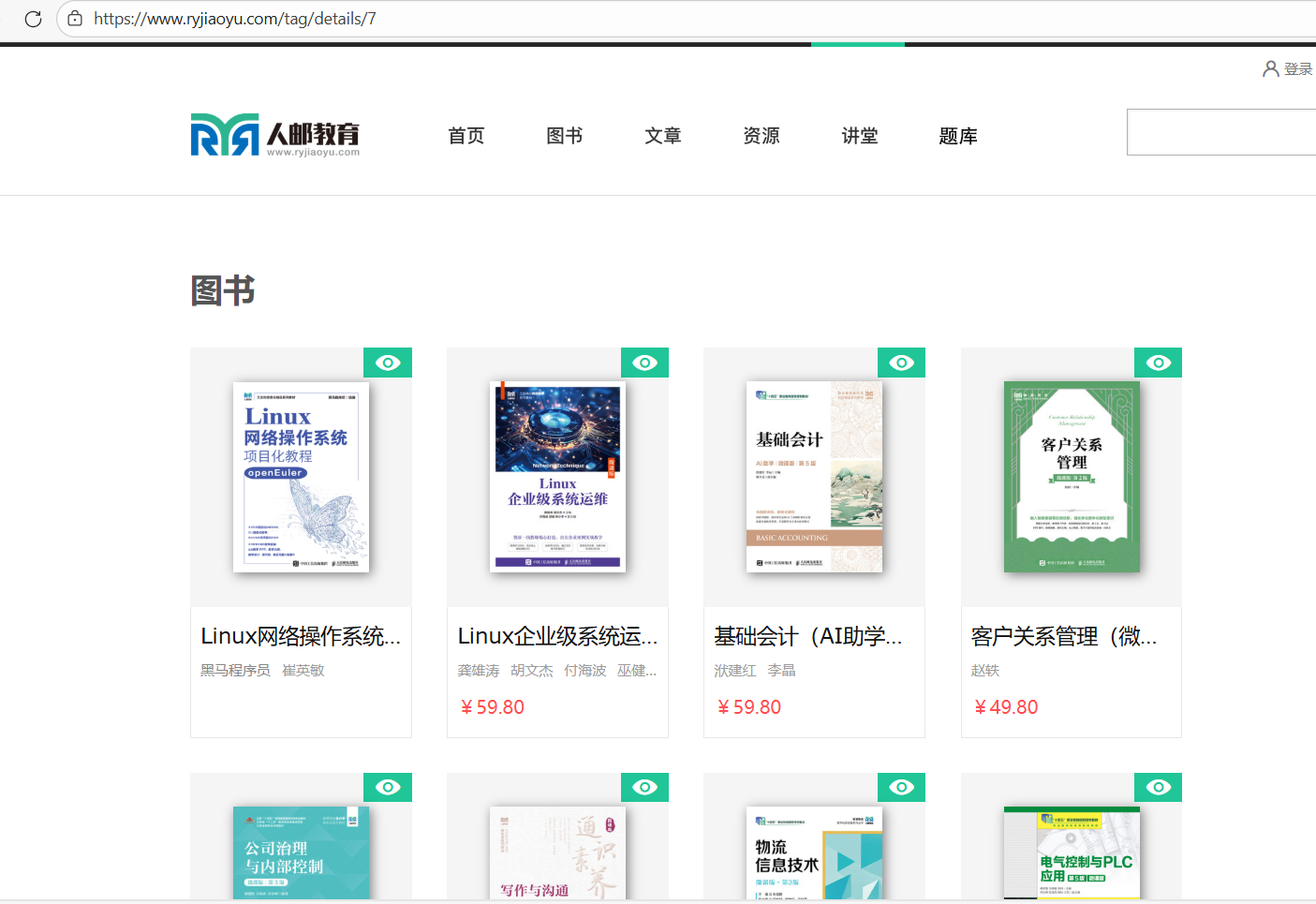
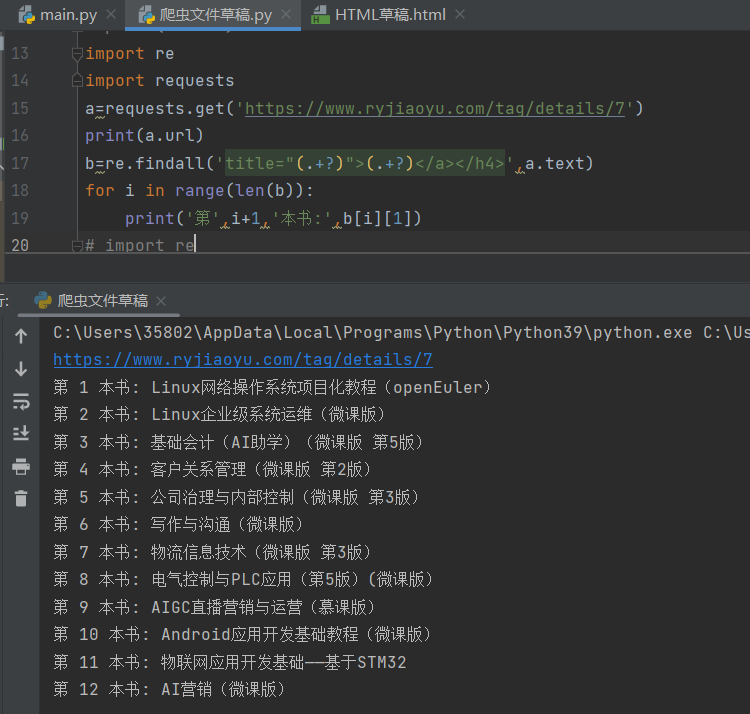
"新书快递-人邮教育社区"网页中上架了新书,现需要使用requests库爬取当前网页中所有新书的书名,如图,一共12本