文章目录
- [一、Requests 与 lxml 实现数据爬取](#一、Requests 与 lxml 实现数据爬取)
-
- [1 环境准备与基础设置](#1 环境准备与基础设置)
- [2 网页爬取与数据解析](#2 网页爬取与数据解析)
- [3 其他爬取示例](#3 其他爬取示例)
- [二、Selenium 浏览器自动化](#二、Selenium 浏览器自动化)
-
- [1 浏览器配置与启动](#1 浏览器配置与启动)
- [2 网页访问与操作](#2 网页访问与操作)
一、Requests 与 lxml 实现数据爬取
- 使用 Requests 库直接发送 HTTP 请求,结合 lxml 解析 HTML 内容,实现更高效的数据爬取。
1 环境准备与基础设置
- 使用之前需要导入必要的库并设置基础环境:
python
import fake_useragent
import requests
from lxml import etree
import os
import re
n = 0
def count():
global n
n += 1
return n
if not os.path.exists(r"./Picture"):
os.mkdir(r"./Picture")- 这里定义了一个计数器函数 count(),用于为下载的图片生成序号,同时创建了用于存储图片的目录。
2 网页爬取与数据解析
- 以下代码展示了如何爬取壁纸网站的图片数据:
python
head = {
"User-Agent": fake_useragent.UserAgent().random
}
for i in range(1, 3):
url = f"https://10wallpaper.com/List_wallpapers/page/{i}"
resp = requests.get(url, headers=head)
result = resp.text
tree = etree.HTML(result)
p_list = tree.xpath("//div[@id='pics-list']/p")
for p in p_list:
ima_url = p.xpath("./a/img/@src")[0]
ima_url1 = "https://10wallpaper.com" + ima_url
print(ima_url1)
img_name = count()
print(img_name)
img_resp = requests.get(ima_url1, headers=head)
img_content = img_resp.content
with open(f"./Picture/{img_name}.jpg","wb") as f:
f.write(img_resp.content)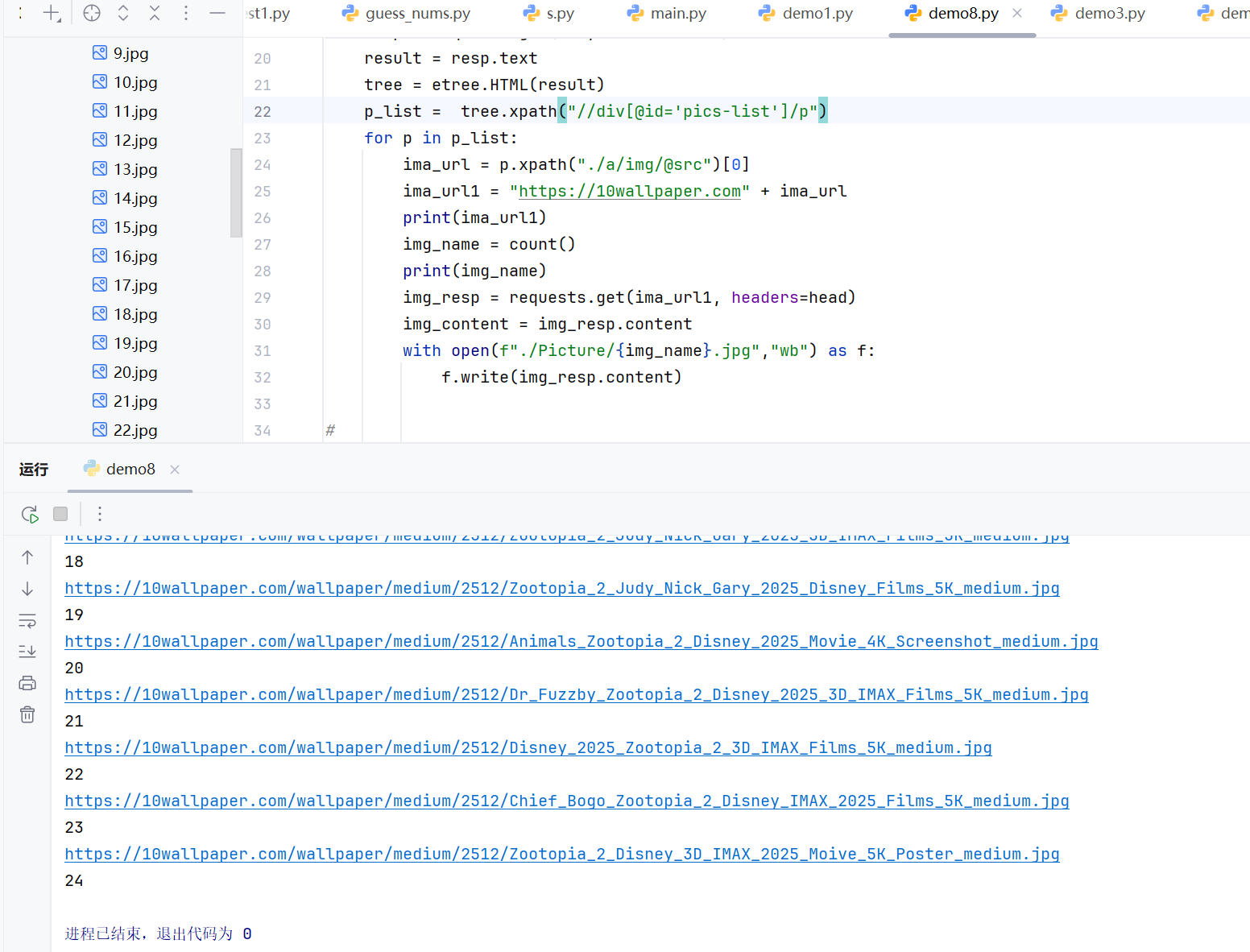
- 代码通过循环遍历多个页面,使用 XPath 定位到图片元素,提取图片链接并下载保存。fake_useragent 库用于生成随机的 User-Agent,帮助避免被网站反爬机制识别。
3 其他爬取示例
- 爬取虎扑热点话题和豆瓣电影信息示例:
python
# 爬取虎扑热点话题
r = requests.get("https://m.hupu.com/hot")
tree = etree.HTML(r.text)
topics = tree.xpath('//div[@class="hot_hot-page-item-title__HL2kw"]/text()')
for i, j in enumerate(topics):
print(f"热点第{i + 1}话题:{j}")
# 爬取豆瓣电影信息
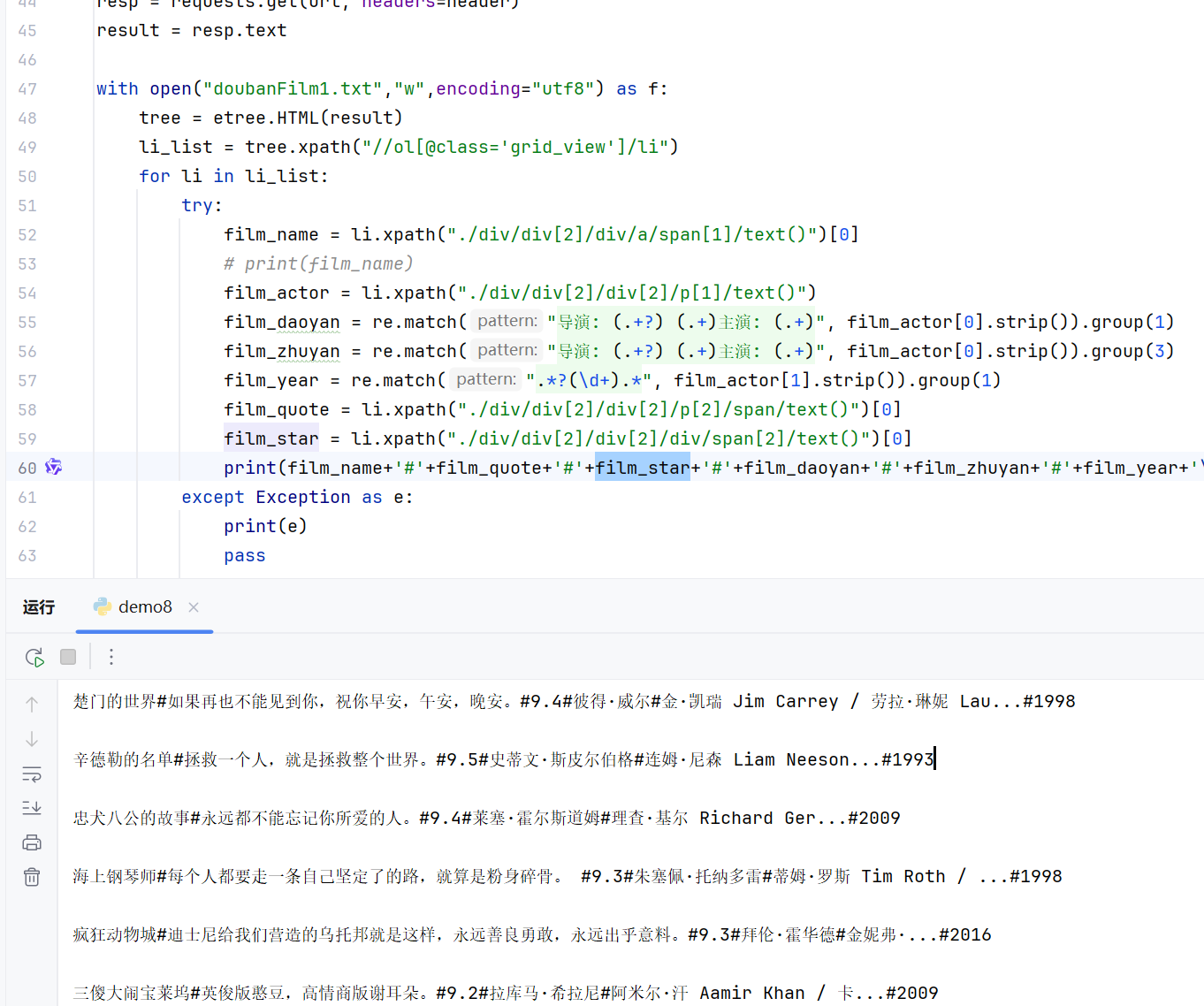
url = r"https://movie.douban.com/top250"
header = {"User-Agent": fake_useragent.UserAgent().random}
resp = requests.get(url, headers=header)
result = resp.text
with open("doubanFilm1.txt","w",encoding="utf8") as f:
tree = etree.HTML(result)
li_list = tree.xpath("//ol[@class='grid_view']/li")
for li in li_list:
try:
film_name = li.xpath("./div/div[2]/div/a/span[1]/text()")[0]
film_actor = li.xpath("./div/div[2]/div[2]/p[1]/text()")
film_daoyan = re.match("导演: (.+?) (.+)主演: (.+)", film_actor[0].strip()).group(1)
film_zhuyan = re.match("导演: (.+?) (.+)主演: (.+)", film_actor[0].strip()).group(3)
film_year = re.match(".*?(\d+).*", film_actor[1].strip()).group(1)
film_quote = li.xpath("./div/div[2]/div[2]/p[2]/span/text()")[0]
film_star = li.xpath("./div/div[2]/div[2]/div/span[2]/text()")[0]
print(film_name+'#'+film_quote+'#'+film_star+'#'+film_daoyan+'#'+film_zhuyan+'#'+film_year+'\n')
except Exception as e:
print(e)
pass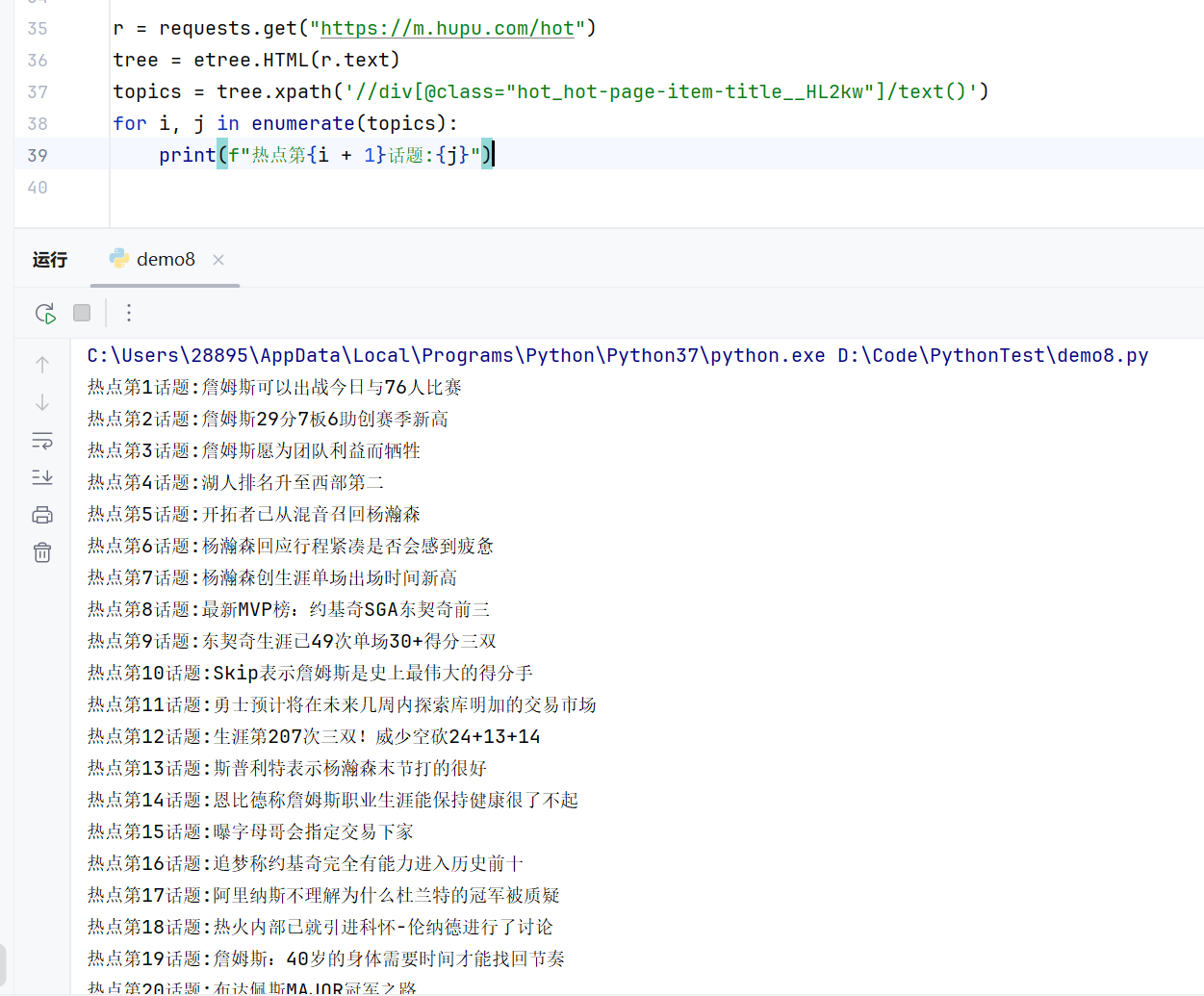
二、Selenium 浏览器自动化
- Selenium 是一个强大的工具,可以模拟用户在浏览器中的真实操作,实现自动化测试和数据采集。
1 浏览器配置与启动
- 使用之前需要配置浏览器驱动。以下代码展示了如何使用 Selenium 配置 Microsoft Edge 浏览器:
python
from selenium import webdriver
from selenium.webdriver.edge.options import Options as eo
# from selenium.webdriver.chrome.options import Options as co
import time
edge_options = eo()
# chrome_options = co()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
# chrome_options.binary_location = r"C:\Program Files\Google\Chrome\Application\chrome.exe"
driver = webdriver.Edge(options=edge_options)
# driver = webdriver.Chrome(options=chrome_options)- 这段代码展示了如何配置两种主流浏览器。这里我们启用了 Edge 浏览器,而 Chrome 浏览器的配置也被包含在内,可以根据需要切换使用。
2 网页访问与操作
- 启动浏览器后,我们可以访问目标网页并执行相关操作:
python
driver.get("https://www.gamewallpapers.com/index.php?start=0&page=")
# 在新标签页中打开其他网页
driver.execute_script("window.open('https://www.bilibili.com/','_blank');")
print(driver.page_source)
time.sleep(10)
- 通过 driver.get() 方法可以加载指定网页,而 driver.page_source 则能获取当前页面的完整 HTML 源码。这里还演示了如何使用 JavaScript 的 window.open() 方法在新标签页中打开链接,time.sleep(10) 用来来保持浏览器窗口打开10秒,方便观察结果。