简介
OCR(Optical Character Recognition):光学字符识别,是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后由Google进行改进、修改bug、优化,重新发布。
声明
本文仅适用于Tesseract-OCR5.0的环境;字库训练包含传统字库训练和LSTM训练。
下载与安装
1、Tesseract-OCR的Windows版本下载地址:https://tesseract-ocr.github.io/tessdoc/Downloads.html,选择 UBMannheim 5.0.0.Alpha安装,我用的版本是tesseract-ocr-w64-setup-v5.2.0-alpha.20220712.exe。
注意:安装完成之后,需要把安装目录(通常是:C:\Program Files\Tesseract-OCR)加入Path环境变量之中,以方便后面执行命令行工具。
注意:Tesseract-OCR4.0安装之后,需要设置TESSDATA_PREFIX环境变量,指向C:\Program Files (x86)\Tesseract-OCR\tessdata;Tesseract-OCR5.0,64位版本则不需要此操作。
2、各版本对应字库下载地址:https://github.com/tesseract-ocr/tessdata_best,要识别简体中文需要下载chi_sim.traindata字库。
注意:一定要用从上述链接中下载.traineddata文件;如果从原有tesseract-OCR中的.traineddata文件提取.lstm文件,会造成无法进行训练。我这里下载的是eng.traineddata,因为我不用它来识别中文。
3、下载工具jTessBoxEditor,地址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/,将之解压缩到C盘某个目录,这个工具是用来训练样本用的。
注意 :该工具是用JAVA开发的,需要安装Jre环境,jdk-8u201-windows-x64.exe地址: https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html。
注意:带FX的版本才支持中文。
初步测试
假定工作目录为:C:\Users\60939\Desktop\testlang ,在此目录里面有一张测试图片:1.png;假定Tesseract-OCR安装目录为:C:\Program Files\Tesseract-OCR,已经将此目录加入到Path环境变量中。
打开命令行工具(我是以管理员身份打开的,没试过其它方式),切换到工作目录, 执行:**tesseract 1.png result -l eng ,**识别结果在工作目录下的result.txt。
注意:-l 参数表明用何种语言包;如果是eng,则可以省略;如果使用多种语言"+"连接 ,
例:tesseract 1.png result -l eng+chi_sim
传统训练
步骤一、首先,准备足够多的训练图片
将这些图片存放到工作目录\orgin子目录,本文全部为PNG格式的图片。
步骤二,通过jTessBoxEditor,把这些图片转换为TIF格式
打开jTessBoxEditor解压缩目录,双击执行jTessBoxEditorFX.jar或者train.bat;窗口打开之后,单击:Tools->Merge Tiff ,按住Shift键选择_工作目录\orgin_下面需要训练的图片,并把合并生成的TIF文件放到工作目录中,重新命名。我这里命名为:smecs.font.exp3.tif,保存完之后,原先的PNG图片已经无效,可以删除。
tif文件命名格式:lang.fontname.expnum.tif
tif命名规则:lang为语言名称,fontname为字体名称,num为图片序号;
步骤三、生成box文件(命令行+工具 自由选择)
通过命令行生成box:
切换到工作目录下执行:tesseract smecs.font.exp3.tif smecs.font.exp3 -l eng batch.nochop makebox 生成box文件
Make Box File的命令格式:tesseract lang.fontname.expnum.tif lang.fontname.expnum batch.nochop makebox
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
注意 :t if文件名必须与box文件名保持一致,且位于同一个目录。这么理解吧:TIF文件用来保存图像(可以保存多张图片,用Page来分页);BOX文件用来保存图像中文字的位置信息(每个字符的X、Y坐标,宽度、高度)。
通过jTessBoxEditor生成box文件:
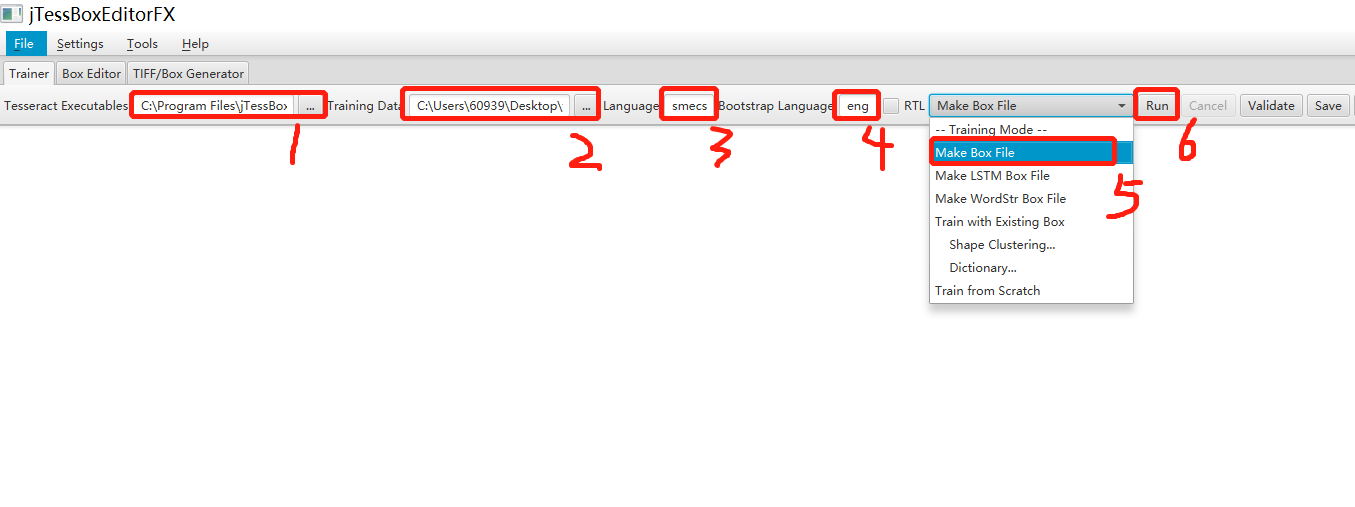
①选择Tesseract.exe执行程序
②tif图片文件所在的文件夹路径
③必填,制作新字库的name,制作box不适用该项
④制作box时指定的字库去识别;如果想用中文库就填写chi_sim
⑤制作传统box文件选择此项
⑥执行生成box(生成box同图片文件在相同目录)
步骤四、文字校正(逐一字符修正)
运行jTessBoxEditor工具(如果已经打开,切换过去),点击Box Editor->Open,打开smecs.font.exp3.tif文件,需要对每张图片中识别错误的字符进行校正。
窗口下方有翻页按钮;通过工具栏右上角的微调按钮,修正每个字符的X、Y坐标,宽度、高度。不需要的点(Delete),增加有用的点(Split、Insert)。
校正完成,保存即可,建议每页修改完毕都按一次保存按钮,避免意外。至此,jTessBoxEditorg工具的使命完成。
步骤五、利用.tif和.box文件生成训练字库
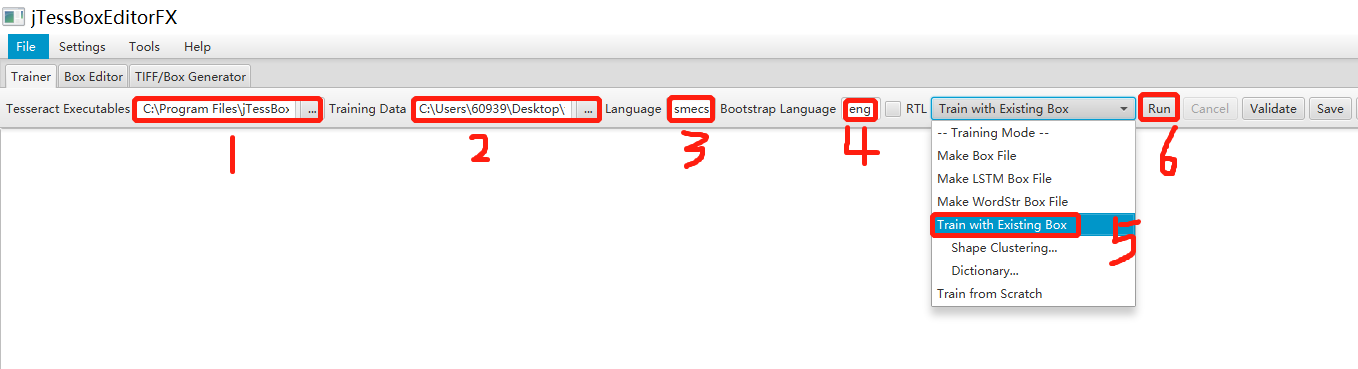
①选择Tesseract.exe执行程序
②tif图片文件所在的文件夹路径
③必填,制作新字库的name,制作box不适用该项
④制作box时指定的字库去识别;如果想用中文库就填写chi_sim
⑤训练字库时选择此项
⑥执行生成新字库(生成字库文件在工作目录下的tessdata子目录中)
将生成的字库复制到Tesseract-ocr安装路径的\tessdata字库目录下,然后就可以使用该字库
LSTM训练
步骤一、首先,准备足够多的训练图片
将这些图片存放到_工作目录\orgin_子目录,本文全部为PNG格式的图片。
步骤二、通过jTessBoxEditor,将这些TIF合并成一个文件
打开jTessBoxEditor解压缩目录,双击执行jTessBoxEditorFX.jar或者train.bat;窗口打开之后,单击:Tools->Merge Tiff ,按住Shift键选择_工作目录\orgin_下面需要训练的图片,并把合并生成的TIF文件放到工作目录中,重新命名。我这里命名为:smecs.font.exp5.tif,保存完之后,原先的PNG图片已经无效,可以删除。
tif文件命名格式:lang.fontname.expnum.tif
tif命名规则:lang为语言名称,fontname为字体名称,num为图片序号;
步骤三、生成box文件
通过命令行生成box:
切换到工作目录下执行:tesseract smecs.font.exp5.tif smecs.font.exp5 -l eng lstmbox 生成box文件
Make Box File的命令格式:tesseract lang.fontname.expnum.tif lang.fontname.expnum batch.nochop makebox
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
注意 :tif文件名必须与box文件名保持一致,且位于同一个目录。这么理解吧:TIF文件用来保存图像(可以保存多张图片,用Page来分页);BOX文件用来保存图像中文字的位置信息(每个字符的X、Y坐标,宽度、高度)。
通过工具生成box:
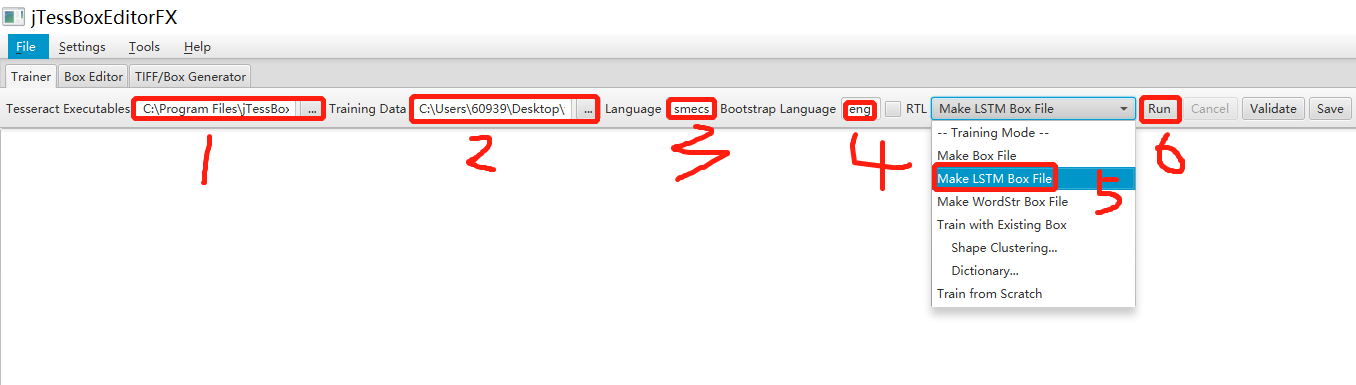
①选择Tesseract.exe执行程序
②tif图片文件所在的文件夹路径
③必填,制作新字库的name,制作box不适用该项
④制作box时指定的字库去识别;如果想用中文库就填写chi_sim
⑤制作LSTM Box文件时选择此项
⑥执行生成新字库(生成字库文件在工作目录下的tessdata子目录中)
步骤四、文字校正(逐行字符修正)
运行jTessBoxEditor工具(如果已经打开,切换过去),点击Box Editor->Open,打开smecs.font.exp3.tif文件,需要对每张图片中识别错误的字符进行校正。
窗口下方有翻页按钮;通过工具栏右上角的微调按钮,修正每个字符的X、Y坐标,宽度、高度。不需要的点(Delete),增加有用的点(Split、Insert)。
校正完成,保存即可,建议每页修改完毕都按一次保存按钮,避免意外。至此,jTessBoxEditorg工具的使命完成。
**注意:**lstm训练模式下,box只接受一整行的数据,而不是把一整行数据拆成一个个的框。所以只需要将属于一行的数据,它们的box坐标框的范围从单个文字改成一整行,并且还需要用一个\t结尾。
步骤五、利用.tif和.box文件生成.lstmf文件用于lstm训练
切换至工作目录,命令行工具执行:tesseract smecs.font.exp5.tif smecs.font.exp5 -l eng --psm 6 lstm.train
参数含义:
smecs.font.exp5.tif 上一步生成的.tif 格式的文件
smecs.font.exp5 指明要生成的.lstmf文件的名称
-l eng 表示用到的语言,我这里训练的是英语,故省略
--psm 6 表示采用的分割模式
运行后工作目录会多出一个smecs.font.exp5.lstmf文件
页面分割方法
默认情况下,Tesseract 在分割图像时需要一页文本。如果您只是想对一个小区域进行 OCR,请使用--psm参数尝试不同的分割模式。请注意,为剪裁过紧的文本添加白色边框也可能会有所帮。
要查看支持的页面分段模式的完整列表,请使用tesseract -h:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
步骤六、从已有的.traineddata中提取.lstm文件
将下载好的.traineddata文件拷贝到工作目录(为什么用下载的,而不用Tesseract-OCR自带的,原因参考前面),我这里是eng.traineddata,命令行工具执行:combine_tessdata -e eng.traineddata eng.lstm
注意:如果需要其他语言包,请自行下载。
步骤七、创建smecs5.training_files.txt文件,里边的内容为.lstmf文件的路径地址
我这里是:C:\Users\60939\Desktop\testlang\smecs.font.exp5.lstmf
步骤八、进行训练
在工作目录创建output子目录
命令行工具执行:lstmtraining --model_output="C:\Users\60939\Desktop\testlang\output\output" --continue_from="C:\Users\60939\Desktop\testlang\eng.lstm" --train_listfile="C:\Users\60939\Desktop\testlang\smecs5.training_files.txt" --traineddata="C:\Users\60939\Desktop\testlang\eng.traineddata" --debug_interval -1 --max_iterations 800
参数含义:
--model_output 模型训练输出的路径
--continue_from 训练从哪里继续,这里指定从上面提取的 eng.lstm文件,
--train_listfile 指定上一步创建的文件的路径
--traineddata 指定.traineddata文件的路径
--debug_interval 当值为-1时,训练结束,会显示训练的一些结果参数
--max_iterations 指明训练遍历次数
此时命令窗口中会有滚动的训练历程,这一步操作比较耗费时间。训练结束后,在output文件夹中会生成i一个output_checkpoint文件和多个类似output0.012_3.checkpoint的.checkpoint文件。
步骤九、将checkpoint文件和.traineddata文件合并成新的.traineddata文件
在工作目录,命令行工具执行:
lstmtraining --stop_training --continue_from="C:\Users\60939\Desktop\testlang\output\output_checkpoint" --traineddata="C:\Users\60939\Desktop\testlang\eng.traineddata" --model_output="C:\Users\60939\Desktop\testlang\output\smecs.traineddata"
参数含义:
--stop_training 默认要有的
--continue_from 上一步生成的output_checkpoint文件路径
--traineddata 第4步中下载的.traineddata文件的路径
--model_output zth.traineddata 输出的路径
然后,将新生成的smecs.traineddata文件拷贝到tesseract-OCR\tessdata文件夹下,通过代码进行识别。
进一步测试
在工作目录,命令行工具执行:
tesseract 1.png lstmresult1 -l smecs
注意:语言包,必须选择刚刚创建的smecs。打开工作目录下的lstmresult1 .txt,使用训练后的辛苦得到识别结果。