在自然语言处理(NLP)中,词向量(Word Embedding)是表示单词或短语的一种稠密向量表示。与传统的one-hot 表示方法相比,词向量可以将语义相似的单词映射到相近的向量空间。Word2Vec 是最著名的词向量生成算法之一,它通过学习词汇的上下文信息来生成稠密的词向量。本文将深入探讨 Word2Vec 的工作原理、应用以及它的局限性。
一、什么是 Word2Vec?
Word2Vec 是由 Google 提出的一个模型,旨在将单词的稀疏向量映射到一个稠密的向量空间中,它就是一个查找表 。它使用神经网络模型来通过上下文学习每个词的语义,并将语义相似的词映射到相近的向量空间。
对稀疏和稠密向量区别有兴趣的可以看这篇文章:
Word2Vec 的核心目标是:学习一个映射,将单词映射到一个低维向量空间,保证在该空间中,语义相似的词靠得更近。
如图片所示:
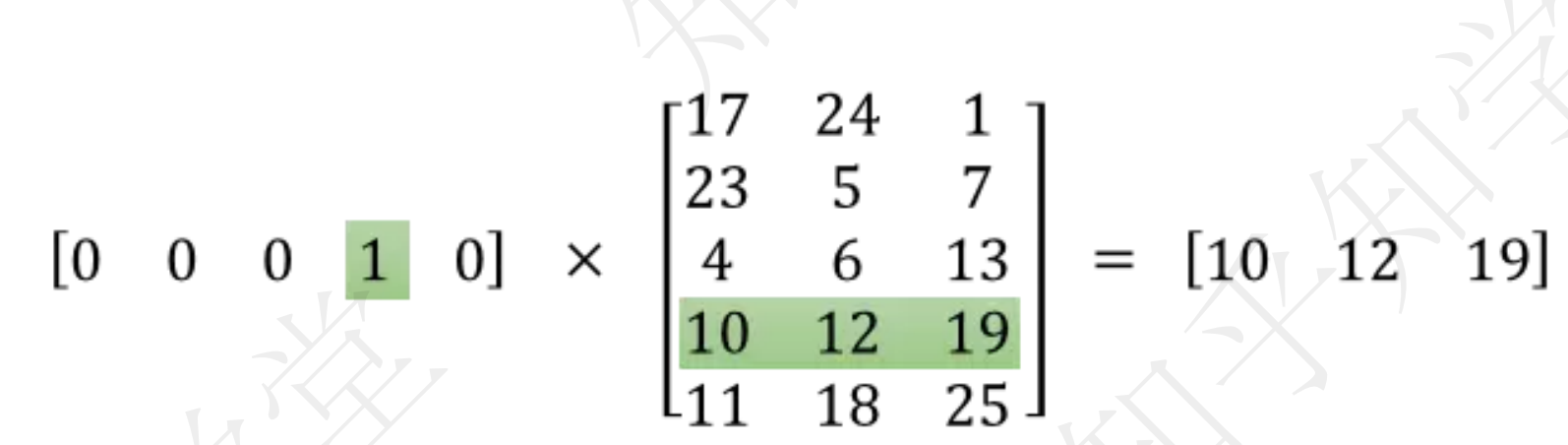
one-hot : 有多个为0的地方,没有任何意义
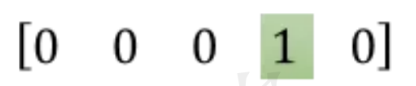
Word2Vec: 其实就是一个词典
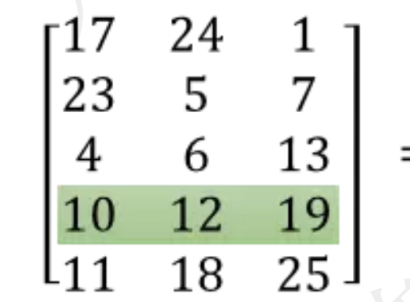
计算结果为: 把高维稀疏转成低维稠密,更加能体现出该词的特征。
二、Word2Vec 的工作原理
Word2Vec 使用一种基于神经网络的算法来训练词向量,主要有两种训练模型:Skip-gram 和 CBOW(Continuous Bag of Words) ,这两种模型都是为了让 Word2Vec 这本词典更加准确。
1. 传统的 One-hot 表示法
在传统的 one-hot 表示方法中,每个词都会被表示为一个维度为词汇表大小的稀疏向量。假设我们的词汇表大小为 5,包含单词 "cat", "dog", "fish", "bird", "horse",那么 "cat" 的 one-hot 向量就是:1, 0, 0, 0, 0
同样,"dog" 的 one-hot 向量是:0, 1, 0, 0, 0
每个词都是一个高维的稀疏向量,只有一个元素是 1,其他元素都是 0。
这种表示方法虽然简单,但在计算上非常低效且无法捕捉词与词之间的关系。不同的词,即使有相似的意义,它们的 one-hot 向量也完全不同,无法体现出它们之间的语义关系。
2. Skip-gram 和 CBOW 模型的作用
Word2Vec 的核心思想是通过上下文来学习词的表示。为了更好地学习这些表示,Word2Vec 使用了两种不同的模型:Skip-gram 和 CBOW,它们在训练词向量时的作用如下:
Skip-gram 模型
Skip-gram 模型的目标是给定一个输入词,预测它周围的上下文词。换句话说,它通过一个词来预测它的上下文词汇。
举个例子,假设我们有句子:
Bereft of life he rests in peace!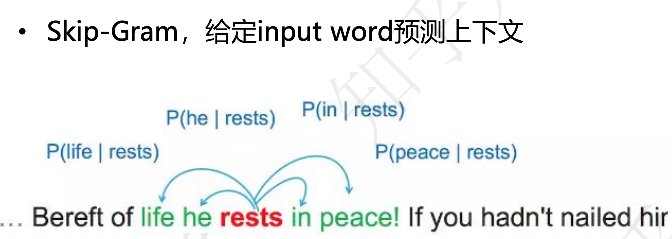
如果我们选择"rests"作为输入词(即中心词),Skip-gram 的任务是预测"rests"周围的词,比如"he","in","peace"。Skip-gram 模型会从句子中抽取出这些上下文词,并通过它们来训练模型,从而得到词的向量表示。
CBOW 模型
CBOW(Continuous Bag of Words)模型与 Skip-gram 相反。CBOW 给定上下文,预测中心词。也就是说,它使用上下文词来预测目标词。
举个例子,还是用同一句话:
Bereft of life he rests in peace!
如果我们选择"rests"作为目标词,CBOW 的任务是给定上下文词(例如 "life", "he", "in", "peace"),预测中心词"rests"。通过上下文预测目标词的模型,将根据这些上下文词的向量来推测目标词的向量。
3. Word2Vec 如何整理词向量矩阵
通过 Skip-gram 和 CBOW 这两种模型,Word2Vec 逐步调整其内部的词向量矩阵,目的是让在语义上相似的词在向量空间中距离更近。
例如,在学习过程中,"cat"和"dog"这样的词,因为有相似的语义和上下文,模型会通过 Skip-gram 或 CBOW 的训练机制使得它们的词向量在高维空间中靠得更近。这个训练过程就是 Word2Vec 学习到一个 词向量查找表,而不是直接的推理过程。
训练过程中的表格
Word2Vec 训练时并不是立即得到词的准确向量,而是通过反复训练来更新词向量矩阵中的每一行。每当我们输入一个词并利用上下文进行预测时,模型会根据预测的误差来调整词向量,逐步优化矩阵。
在经过多次训练之后,得到的词向量矩阵将能够较好地反映出词与词之间的语义关系。例如:
- "king" 和 "queen" 在向量空间中会较为接近;
- "man" 和 "woman" 之间的关系也会体现在向量空间中。
三、Word2Vec 的应用
1. 词语相似度计算
通过 Word2Vec 训练出的词向量,我们可以直接计算词与词之间的相似度。例如,给定词向量 ( \vec{king} ) 和 ( \vec{queen} ),我们可以计算它们的余弦相似度,得出它们的相似度值。
2. 语义推理
Word2Vec 不仅能够捕捉词与词之间的相似度,还可以完成一些有趣的语义推理任务。例如,"king - man + woman = queen" 这样的类比任务可以通过词向量空间中的向量运算来完成。Word2Vec 可以通过向量加减运算推理出"国王"和"女人"之间的关系,从而推断出"王后"。
3. 文本分类与情感分析
在文本分类、情感分析等 NLP 任务中,我们可以将每个单词映射到 Word2Vec 词向量空间,然后通过对文本中所有词向量的平均或者加权平均,得到一个文本的向量表示。这个文本向量可以作为分类模型的输入,用于后续的任务处理。
四、总结
Word2Vec 通过学习上下文来训练词向量,能够有效地捕捉语义信息,并在许多自然语言处理任务中取得了优异的表现。它不仅为后来的许多 NLP 任务提供了基础,而且影响了后来的更多模型,如 GloVe 和 FastText。尽管如此,它仍然存在一些局限性,特别是在处理复杂语法和上下文时。对于更复杂的任务,现代的模型如 BERT 已经逐步取代了 Word2Vec 的地位。
通过本文的学习,希望你能够理解 Word2Vec 的基本原理、应用场景以及它的局限性,为你在 NLP 任务中的应用提供一些思路。