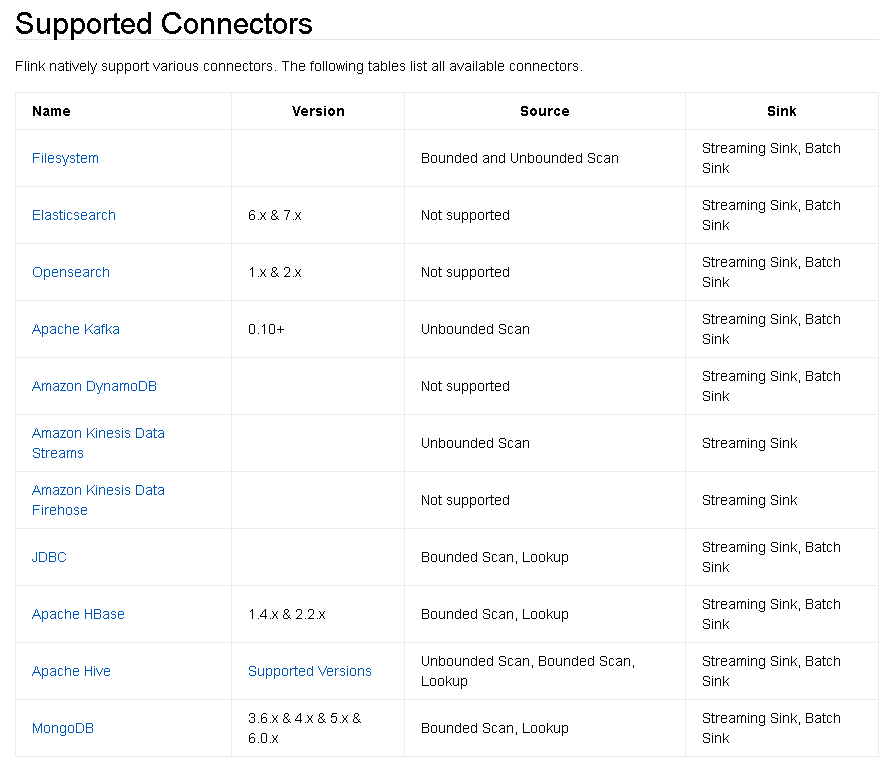
一、Flink SQL
FlinkSQL开发步骤
Concepts & Common API | Apache Flink
添加依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
</dependency>这里的依赖是一个Java的"桥接器"(bridge),主要就是负责Table API和下层DataStream API的连接支持,按照不同的语言分为Java版和Scala版。
如果我们希望在本地的集成开发环境(IDE)里运行Table API和SQL,还需要引入以下依赖:
XML
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>第一步:创建表环境
对于Flink这样的流处理框架来说,数据流和表在结构上还是有所区别的。所以使用Table API和SQL需要一个特别的运行时环境,这就是所谓的"表环境"(TableEnvironment)。
对于流处理场景,其实默认配置就完全够用了。所以我们也可以用另一种更加简单的方式来创建表环境:
java
package com.bigdata;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class _001Demo {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv2 = StreamTableEnvironment.create(env);
System.out.println(tableEnv2);
}
}第二步:创建表
表(Table)是我们非常熟悉的一个概念,它是关系型数据库中数据存储的基本形式,也是SQL执行的基本对象。
java
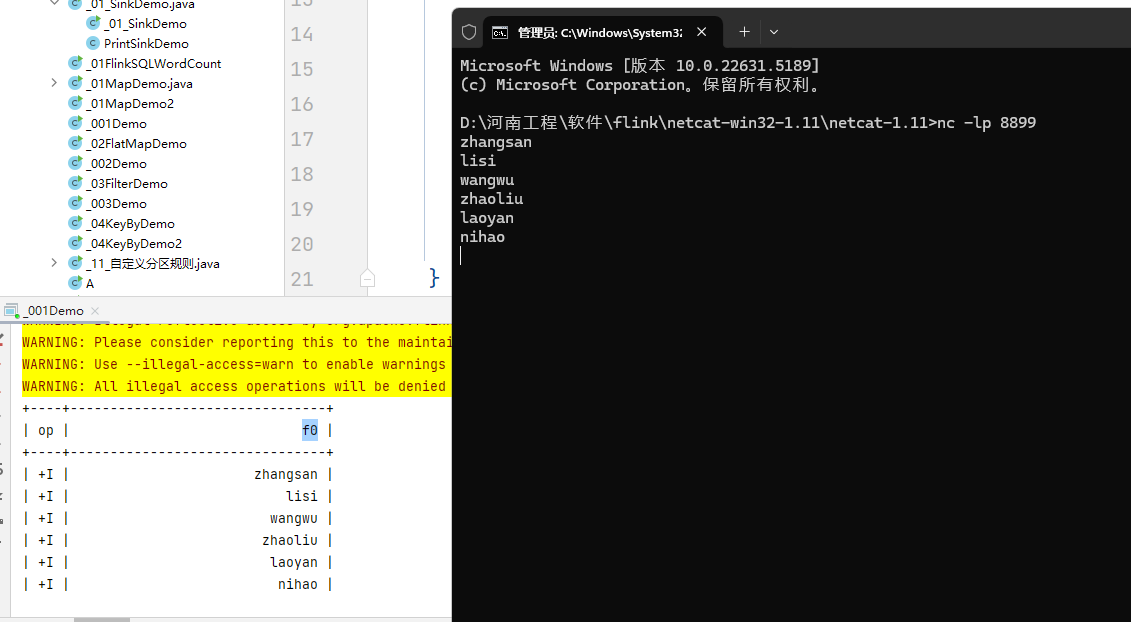
DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 8899);
// 将这个流对象变为一个表
tableEnv.createTemporaryView("table1", dataStreamSource);第三步:表的查询
创建好了表,接下来自然就是对表进行查询转换了。对一个表的查询(Query)操作,就对应着流数据的转换(Transform)处理。
//TableResult tableResult = tableEnv.executeSql("select * from table1");
//tableResult.print();
Table table = tableEnv.sqlQuery("select * from table1");第一个flinksql案例
java
package com.bigdata.day06;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* @基本功能:
* @program:FlinkDemo
* @author: 闫哥
* @create:2025-12-02 10:11:04
**/
public class Demo01 {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 8888);
tableEnv.createTemporaryView("table1",dataStreamSource);
/*TableResult tableResult = tableEnv.executeSql("select * from table1");
tableResult.print();*/
Table table = tableEnv.sqlQuery("select * from table1");
table.printSchema();// 打印表结构
// table 中的数据是无法直接打印的,要想得到里面的数据,需要将table对象变为流对象
// toAppendStream 已经淘汰啦
//DataStream<Row> appendStream = tableEnv.toAppendStream(table, Row.class);
// 新的api 和toAppendStream 作用一样
DataStream<Row> dataStream = tableEnv.toDataStream(table, Row.class);
dataStream.print();
env.execute();
}
}
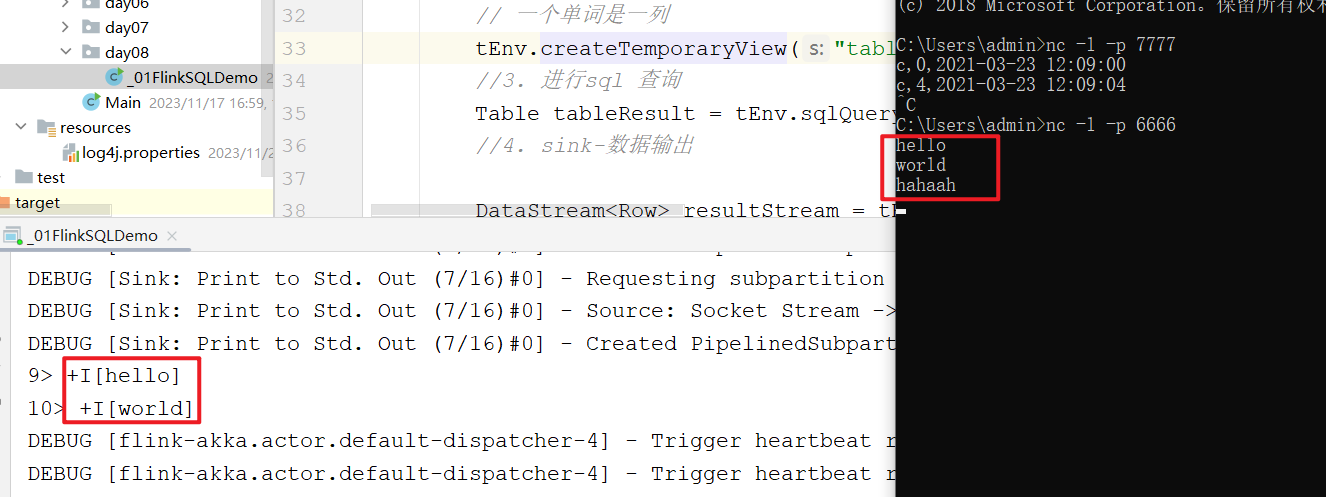
因为DataStream中是Row 类型,所以打印的格式是Row 这个类中的toString方法决定的。这个地方的 +I 的意思是新增的数据。
第四步:输出表
表的创建和查询,就对应着流处理中的读取数据源(Source)和转换(Transform);而最后一个步骤Sink,也就是将结果数据输出到外部系统,就对应着表的输出操作。
在代码上,输出一张表最直接的方法,就是调用Table的方法executeInsert()方法将一个 Table写入到注册过的表中,方法传入的参数就是注册的表名。
// 注册表,用于输出数据到外部系统
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// 经过查询转换,得到结果表
Table result = ...
// 将结果表写入已注册的输出表中
result.executeInsert("OutputTable");在底层,表的输出是通过将数据写入到TableSink来实现的。TableSink是Table API中提供的一个向外部系统写入数据的通用接口,可以支持不同的文件格式(比如CSV、Parquet)、存储数据库(比如JDBC、Elasticsearch)和消息队列(比如Kafka)。
第五步: 表和流的转换
1 )将流( DataStream )转换成表( Table )
(1)调用fromDataStream()方法
想要将一个DataStream转换成表很简单,可以通过调用表环境的fromDataStream()方法来实现,返回的就是一个Table对象。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取数据源
SingleOutputStreamOperator<WaterSensor> sensorDS = env.fromSource(...)
// 将数据流转换成表
Table sensorTable = tableEnv.fromDataStream(sensorDS);由于流中的数据本身就是定义好的POJO类型WaterSensor,所以我们将流转换成表之后,每一行数据就对应着一个WaterSensor,而表中的列名就对应着WaterSensor中的属性。
另外,我们还可以在fromDataStream()方法中增加参数,用来指定提取哪些属性作为表中的字段名,并可以任意指定位置:
// 提取Event中的timestamp和url作为表中的列
Table sensorTable = tableEnv.fromDataStream(sensorDS, $("id"), $("vc"));也可以通过表达式的as()方法对字段进行重命名:
// 将timestamp字段重命名为ts
Table sensorTable = tableEnv.fromDataStream(sensorDS, $("id").as("sid"), $("vc"));(2)调用createTemporaryView()方法
调用fromDataStream()方法简单直观,可以直接实现DataStream到Table的转换;不过如果我们希望直接在SQL中引用这张表,就还需要调用表环境的createTemporaryView()方法来创建虚拟视图了。
对于这种场景,也有一种更简洁的调用方式。我们可以直接调用createTemporaryView()方法创建虚拟表,传入的两个参数,第一个依然是注册的表名,而第二个可以直接就是DataStream。之后仍旧可以传入多个参数,用来指定表中的字段
tableEnv.createTemporaryView("sensorTable",sensorDS, $("id"),$("ts"),$("vc"));这样,我们接下来就可以直接在SQL中引用表sensorTable了。
2 )将表( Table )转换成流( DataStream )
(1)调用toDataStream()方法
将一个Table对象转换成DataStream非常简单,只要直接调用表环境的方法toDataStream()就可以了。例如,我们可以将2.4小节经查询转换得到的表aliceClickTable转换成流打印输出:
tableEnv.toDataStream(table).print();(2)调用toChangelogStream()方法
表中进行了分组聚合统计,所以表中的每一行是会"更新"的。对于这样有更新操作的表,我们不应该直接把它转换成DataStream打印输出,而是记录一下它的"更新日志"(change log)。这样一来,对于表的所有更新操作,就变成了一条更新日志的流,我们就可以转换成流打印输出了。
代码中需要调用的是表环境的toChangelogStream()方法:
Table table = tableEnv.sqlQuery(
"SELECT id, sum(vc) " +
"FROM source " +
"GROUP BY id "
);
// 将表转换成更新日志流
tableEnv.toChangelogStream(table).print();假如你的 sql 语句中带有分组,table 对象,要使用toChangelogStream 将其变为流,而不能使用toDataStream
3 )支持的数据类型
整体来看,DataStream中支持的数据类型,Table中也是都支持的,只不过在进行转换时需要注意一些细节。
(1)原子类型
在Flink中,基础数据类型(Integer、Double、String)和通用数据类型(也就是不可再拆分的数据类型)统一称作"原子类型"。原子类型的DataStream,转换之后就成了只有一列的Table,列字段(field)的数据类型可以由原子类型推断出。另外,还可以在fromDataStream()方法里增加参数,用来重新命名列字段。
StreamTableEnvironment tableEnv = ...;
DataStream<Long> stream = ...;
// 将数据流转换成动态表,动态表只有一个字段,重命名为myLong
Table table = tableEnv.fromDataStream(stream, $("myLong"));(2)Tuple 类型
当原子类型不做重命名时,默认的字段名就是"f0",容易想到,这其实就是将原子类型看作了一元组Tuple1的处理结果。
Table支持Flink中定义的元组类型Tuple,对应在表中字段名默认就是元组中元素的属性名f0、f1、f2...。所有字段都可以被重新排序,也可以提取其中的一部分字段。字段还可以通过调用表达式的as()方法来进行重命名。
StreamTableEnvironment tableEnv = ...;
DataStream<Tuple2<Long, Integer>> stream = ...;
// 将数据流转换成只包含f1字段的表
Table table = tableEnv.fromDataStream(stream, $("f1"));
// 将数据流转换成包含f0和f1字段的表,在表中f0和f1位置交换
Table table = tableEnv.fromDataStream(stream, $("f1"), $("f0"));
// 将f1字段命名为myInt,f0命名为myLong
Table table = tableEnv.fromDataStream(stream, $("f1").as("myInt"), $("f0").as("myLong"));(3)POJO 类型
Flink也支持多种数据类型组合成的"复合类型",最典型的就是简单Java对象(POJO 类型)。由于POJO中已经定义好了可读性强的字段名,这种类型的数据流转换成Table就显得无比顺畅了。
将POJO类型的DataStream转换成Table,如果不指定字段名称,就会直接使用原始 POJO 类型中的字段名称。POJO中的字段同样可以被重新排序、提却和重命名。
StreamTableEnvironment tableEnv = ...;
DataStream<Event> stream = ...;
Table table = tableEnv.fromDataStream(stream);
Table table = tableEnv.fromDataStream(stream, $("user"));
Table table = tableEnv.fromDataStream(stream, $("user").as("myUser"), $("url").as("myUrl"));(4)Row类型
Flink中还定义了一个在关系型表中更加通用的数据类型------行(Row),它是Table中数据的基本组织形式。
DataStream -> 表
第一种方案:

第二种方案:

表->DataStream
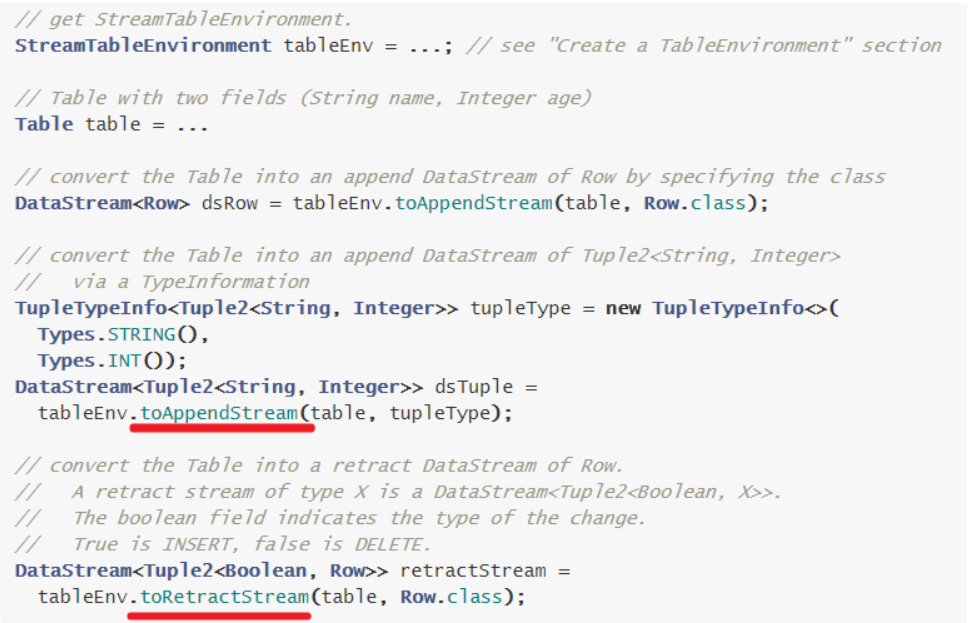
以上的 toAppendStream 已经变为了 toDataStream
toRetractStream 已经为变为了 toChangelogStream
综合应用示例
现在,我们可以将介绍过的所有API整合起来,写出一段完整的代码。同样还是用户的一组点击事件,我们可以查询出某个用户(例如Alice)点击的url列表,也可以统计出每个用户累计的点击次数,这可以用两句SQL来分别实现。具体代码如下:
java
package com.bigdata;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class WaterSensor {
private String id;
private Long ts;
private int vc;
}
java
package com.bigdata.flinksql;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class _002Demo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取tableEnv
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStreamSource<WaterSensor> sensorDS = env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 2L, 2),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3),
new WaterSensor("s3", 4L, 4)
);
// 第一个需求,ts > 2 的用户数据
tableEnv.createTemporaryView("sensor", sensorDS);
Table table = tableEnv.sqlQuery("select id,ts,vc from sensor where ts>2");
DataStream<WaterSensor> dataStream = tableEnv.toDataStream(table, WaterSensor.class);
dataStream.print();
// 统计每一个用户的 总的浏览量
// 也可以使用别的方法,将一个流变为一个表
Table sensorTable = tableEnv.fromDataStream(sensorDS);
tableEnv.createTemporaryView("sensor2", sensorTable);
Table table2 = tableEnv.sqlQuery("select id,sum(vc) from sensor2 group by id");
DataStream<Row> changelogStream = tableEnv.toChangelogStream(table2);
changelogStream.print();
env.execute();
}
}因为我们经常编写flinksql,所以创建一个模板:
java
#if (${PACKAGE_NAME} && ${PACKAGE_NAME} != "")package ${PACKAGE_NAME};#end
#parse("File Header.java")
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
@基本功能:
@program:${PROJECT_NAME}
@author: 闫哥
@create:${YEAR}-${MONTH}-${DAY} ${HOUR}:${MINUTE}:${SECOND}
**/
public class ${NAME} {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 获取tableEnv对象
// 通过env 获取一个table 环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2. 创建表对象
//3. 编写sql语句
//4. 将Table变为stream流
//5. execute-执行
env.execute();
}
}单词统计案例
根据这个可以做一个单词统计的案例:
java
package com.bigdata.flinksql;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.Collector;
import static org.apache.flink.table.api.Expressions.$;
/**
* @基本功能:
* @program:FlinkDemo2
* @author: 闫哥
* @create:2025-04-19 17:06:52
**/
public class _003FlinkSQLWordCount {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取tableEnv对象
// 通过env 获取一个table 环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
//2. 创建表对象
DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 8899);
// hello hello word abc hello
SingleOutputStreamOperator<Tuple2<String, Integer>> flatMapStream = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] arr = line.split("\\s+");
for (String word : arr) {
collector.collect(Tuple2.of(word, 1));
}
}
});
tEnv.createTemporaryView("wordcount", flatMapStream,$("word"),$("num"));
Table table = tEnv.sqlQuery("select word,sum(num) as cnt from wordcount group by word");
//3. 编写sql语句
//4. 将Table变为stream流
DataStream<Row> changelogStream = tEnv.toChangelogStream(table);
changelogStream.print();
//tEnv.toDataStream(table).print();
//5. execute-执行
env.execute();
}
}测试输入:hello world spark hello world spark laoyan
Exception in thread "main" org.apache.flink.table.api.TableException: Table sink '*anonymous_datastream_sink$2*' doesn't support consuming update changes which is produced by node GroupAggregate(groupBy=[word], select=[word, SUM(num) AS cnt])
at org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.createNewNode(FlinkChangelogModeInferenceProgram.scala:405)
at org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.visit(FlinkChangelogModeInferenceProgram.scala:185)
at org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.visitChild(FlinkChangelogModeInferenceProgram.scala:366)
at org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.$anonfun$visitChildren$1(FlinkChangelogModeInferenceProgram.scala:355)
at org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.$anonfun$visitChildren$1$adapted(FlinkChangelogModeInferenceProgram.scala:354)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:233)解决方案:
//DataStream<Row> resultStream = tEnv.toDataStream(table);
修改为:
tEnv.toChangelogStream(table);
- I 表示新增
-U 更新前
+U 更新后

FlinkSQL-API:
**需求:**使用SQL对DataStream中的单词进行统计
java
package com.bigdata.sql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class WC{
private String word;
private int num;
}
java
package com.bigdata.day06;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.Collector;
import static org.apache.flink.table.api.Expressions.$;
/**
* @基本功能:
* @program:FlinkDemo
* @author: 闫哥
* @create:2025-12-02 11:02:46
**/
public class Demo04 {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取tableEnv对象
// 通过env 获取一个table 环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 8888);
// hello abc hello spark
SingleOutputStreamOperator<Tuple2<String, Integer>> flatMap = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] arr = line.split("\\s+");
for (String word : arr) {
out.collect(Tuple2.of(word, 1));
}
}
});
Table table = tableEnv.fromDataStream(flatMap,$("word"),$("num"));
// DSL的语法
Table resultTable = table.groupBy($("word")).select($("word"), $("num").sum().as("sumNum"));
// resultTable.printSchema();
// 创建一个schema ,发现返回值依然是 Row对象,所以没什么特别大的效果,以后不写了
/*Schema schema = Schema.newBuilder()
.column("word", DataTypes.STRING())
.column("sumNum", DataTypes.INT())
.build();*/
//DataStream<Row> changelogStream = tableEnv.toChangelogStream(resultTable,schema);
DataStream<Row> changelogStream = tableEnv.toChangelogStream(resultTable);
//changelogStream.print();
changelogStream.map(new MapFunction<Row, WC>() {
@Override
public WC map(Row row) throws Exception {
String word = (String) row.getField("word");
int sumNum = (int) row.getField("sumNum");
return new WC(word,sumNum);
}
}).print();
env.execute();
}
}Exception in thread "main" org.apache.flink.table.api.ValidationException: Too many fields referenced from an atomic type.
at org.apache.flink.table.typeutils.FieldInfoUtils.extractFieldInfoFromAtomicType(FieldInfoUtils.java:473)
假如遇到以上错误,请检查wc实体类中,是否有 无参构造方法。全新的方式(必须掌握)-- connector 连接方式
DataStream需要变为Table,计算结果还要变为DataStream,过于麻烦了。
以下内容是FlinkSQL的全新的方式,更加简单高效。
datagen + print
java
package com.bigdata.flinksql.day02;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @基本功能:
* @program:FlinkDemo2
* @author: 闫哥
* @create:2025-04-20 09:29:01
*
* 该案例主要用于测试flink中的connector 的用法,无特殊的实战意义
*
**/
public class _001Demo {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
// 获取tableEnv对象
// 通过env 获取一个table 环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
//2. 创建表对象
tEnv.executeSql("CREATE TABLE source ( \n" +
" id INT, \n" +
" ts BIGINT, \n" +
" vc INT\n" +
") WITH ( \n" +
" 'connector' = 'datagen', \n" +
" 'rows-per-second'='1', \n" +
" 'fields.id.kind'='random', \n" +
" 'fields.id.min'='1', \n" +
" 'fields.id.max'='10', \n" +
" 'fields.ts.kind'='sequence', \n" +
" 'fields.ts.start'='1', \n" +
" 'fields.ts.end'='1000000', \n" +
" 'fields.vc.kind'='random', \n" +
" 'fields.vc.min'='1', \n" +
" 'fields.vc.max'='100'\n" +
");\n");
//3. 在创建一个表
tEnv.executeSql("CREATE TABLE sink (\n" +
" id INT, \n" +
" sumVC INT \n" +
") WITH (\n" +
"'connector' = 'print'\n" +
");\n");
//4. 将Table变为stream流
tEnv.executeSql("insert into sink select id,sum(vc) sumVC from source group by id");
// 本身想着将数据写入到了sink 中,需要查询查看结果,但是此处的sink 是print,所以会直接打印到控制台,所以如果你书写如下代码,会报错
// Connector 'print' can only be used as a sink. It cannot be used as a source.
/*TableResult tableResult = tEnv.executeSql("select * from sink");
tableResult.print();*/
//5. execute-执行
// No operators defined in streaming topology. Cannot execute.
// env.execute();
}
}FlinkSQL-kafka
**需求:**从Kafka的topic1中消费数据并过滤出状态为success的数据再写入到Kafka的topic2
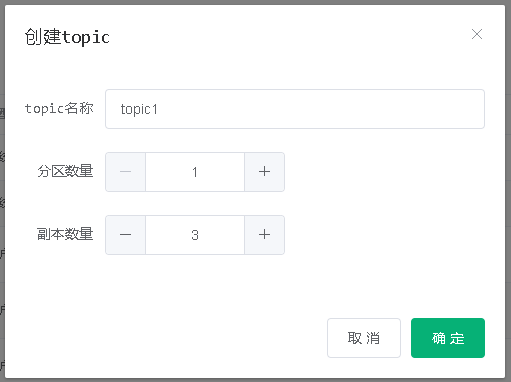
先创建两个 topic
{"user_id": "1", "page_id":"1", "status": "success"}
{"user_id": "1", "page_id":"1", "status": "success"}
{"user_id": "1", "page_id":"1", "status": "success"}
{"user_id": "1", "page_id":"1", "status": "success"}
{"user_id": "1", "page_id":"1", "status": "fail"}代码实现
https://nightlies.apache.org/flink/flink-docs-release-2.0/docs/connectors/table/kafka/
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
{"user_id": "1", "page_id":"1", "status": "success"}
CREATE TABLE table1 (
`user_id` int,
`page_id` int,
`status` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'topic1',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'g1',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
)
CREATE TABLE table2 (
`user_id` int,
`page_id` int,
`status` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'topic2',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'g1',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
)
编写sql即可。
insert into table2 select * from table1 where status='success'
java
package com.bigdata.flinksql.day02;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @基本功能:
* @program:FlinkDemo2
* @author: 闫哥
* @create:2025-04-20 09:49:50
**/
public class _002Demo {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取tableEnv对象
// 通过env 获取一个table 环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
tEnv.executeSql("CREATE TABLE table1 (\n" +
" `user_id` int,\n" +
" `page_id` int,\n" +
" `status` STRING\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'topic1',\n" +
" 'properties.bootstrap.servers' = 'node01:9092',\n" +
" 'properties.group.id' = 'g1',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json'\n" +
")");
tEnv.executeSql("CREATE TABLE table2 (\n" +
" `user_id` int,\n" +
" `page_id` int,\n" +
" `status` STRING\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'topic2',\n" +
" 'properties.bootstrap.servers' = 'node01:9092',\n" +
" 'properties.group.id' = 'g1',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json'\n" +
")");
tEnv.executeSql(" insert into table2 select * from table1 where status='success'");
}
}注意:如果最后一句写了:
env.execute();
而且以上写法可以将最后两步简化为:
tenv.executeSql("insert into table2 select * from table1 where status = 'success' ")其实会进行报错,这句话其实已经没有用处了,但是这个错误不影响最终的结果。

将最后一句env.execute(); 删除即可。
假如报以下错误:说明没有导入json的包:
Caused by: org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'json' that implements 'org.apache.flink.table.factories.DeserializationFormatFactory' in the classpath.
Available factory identifiers are:
raw
at org.apache.flink.table.factories.FactoryUtil.discoverFactory(FactoryUtil.java:319)
at org.apache.flink.table.factories.FactoryUtil$TableFactoryHelper.discoverOptionalFormatFactory(FactoryUtil.java:751)需要导入这个包:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.17.2</version>
</dependency>这个jar包可以在此处找到:
测试一下:
先启动生产者,
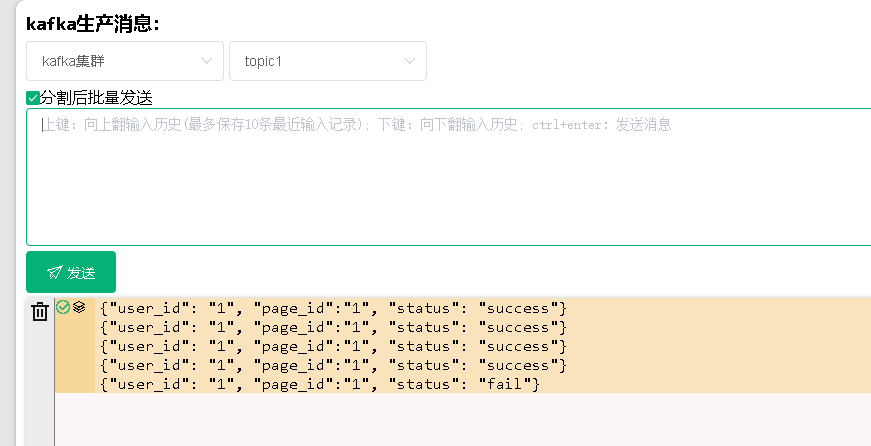
再启动消费者:
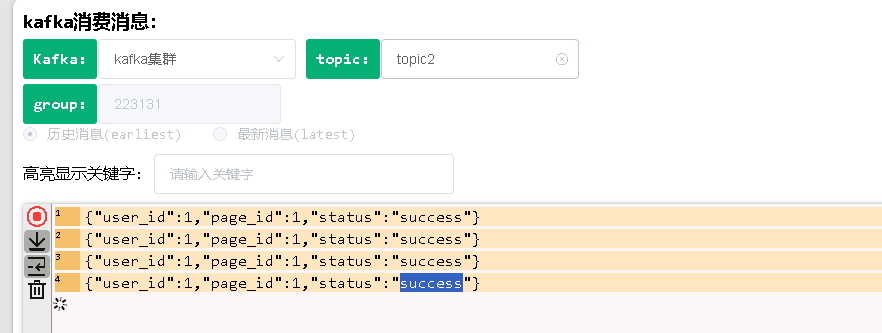
从上面可以看到,生产者向topic1中发送数据,topic2中只有success数据。
FlinkSQL-kafka To mysql
**需求:**从Kafka的topic1中消费数据并过滤出状态为success的数据再写入到MySQL
{"user_id": "1", "page_id":"1", "status": "success"}
{"user_id": "1", "page_id":"1", "status": "success"}
{"user_id": "1", "page_id":"1", "status": "success"}
{"user_id": "1", "page_id":"1", "status": "success"}
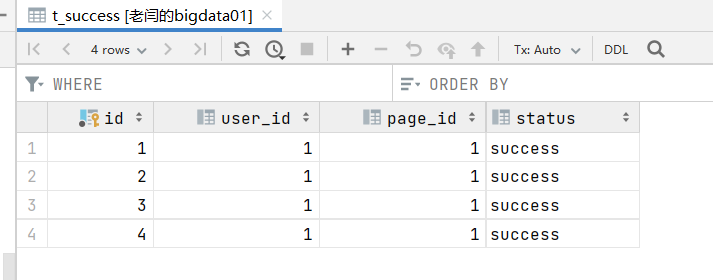
{"user_id": "1", "page_id":"1", "status": "fail"}在mysql中需要有一个数据库 demo ,需要由一个表 t_success
create table t_success
(
id int auto_increment,
user_id int null,
page_id int null,
status varchar(20) null,
constraint t_success_pk
primary key (id)
);官方示例代码如下:
CREATE TABLE MyUserTable (
id BIGINT,
name STRING,
age INT,
status BOOLEAN,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/spark_demo',
'table-name' = 't_success',
'username' = 'root',
'password' = '123456'
);代码实现
java
package com.bigdata.flinksql.day02;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @基本功能:
* @program:FlinkDemo2
* @author: 闫哥
* @create:2025-04-20 09:49:50
**/
public class _003Demo {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取tableEnv对象
// 通过env 获取一个table 环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
tEnv.executeSql("CREATE TABLE table1 (\n" +
" `user_id` int,\n" +
" `page_id` int,\n" +
" `status` STRING\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'topic1',\n" +
" 'properties.bootstrap.servers' = 'node01:9092',\n" +
" 'properties.group.id' = 'g1',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json'\n" +
")");
tEnv.executeSql("CREATE TABLE table2 (\n" +
" `user_id` int,\n" +
" `page_id` int,\n" +
" `status` STRING\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://node01:3306/gongcheng?useUnicode=true&characterEncoding=utf8',\n" +
" 'table-name' = 't_success', \n" +
" 'username' = 'root',\n" +
" 'password' = '123456'\n" +
")");
tEnv.executeSql(" insert into table2 select * from table1 where status='success'");
}
}
FlinkSQL 读取 mysql 数据的案例代码:
java
package com.bigdata.flinksql.day02;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @基本功能:
* @program:FlinkDemo2
* @author: 闫哥
* @create:2025-04-20 09:49:50
*
* flinksql 读取mysql的数据
**/
public class _004Demo {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取tableEnv对象
// 通过env 获取一个table 环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
tEnv.executeSql("CREATE TABLE table1 (\n" +
" `user_id` int,\n" +
" `page_id` int,\n" +
" `status` STRING\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://node01:3306/gongcheng?useUnicode=true&characterEncoding=utf8',\n" +
" 'table-name' = 't_success', \n" +
" 'username' = 'root',\n" +
" 'password' = '123456'\n" +
")");
// 第一种打印的方式
//TableResult tableResult = tEnv.executeSql("select * from table1 where status='success'");
//tableResult.print();
// 第二种打印的方式
tEnv.executeSql("CREATE TABLE table2 (\n" +
" user_id INT, \n" +
" `status` STRING\n" +
") WITH (\n" +
"'connector' = 'print'\n" +
");\n");
tEnv.executeSql("insert into table2 select user_id,status from table1 where status='success'");
}
}二、flinksql的窗口
关于窗口
窗口的两个属性:窗口长度、窗口间隔
1. 从窗口长度和窗口间隔的角度可以将窗口分为:滑动窗口和滚动窗口
窗口长度= 窗口间隔 (滚动窗口)
窗口长度> 窗口间隔 (滑动窗口)
2. flink的时间语义:EventTime和ProcessingTime
EventTime: 事件发生的时间
ProcessingTime: flink程序处理的时间
结合语义窗口可以划分为:基于eventTime的滚动和滑动窗口、基于ProcessingTime的滚动和滑动窗口。
基于ProcessingTime的窗口,它的窗口触发条件是 :系统时间大于等于窗口的结束时间,且窗口内有数据,则触发窗口中的数据计算。
基于EventTime的窗口,它的窗口触发条件是:watermark(水印)大于等于窗口的结束时间,且窗口内有数据,则触发窗口中的数据计算。
watermark是什么? watermark其实就是给数据额外添加的一列时间戳,watermark = maxEventTime - 设置允许延迟时间。1.1 滚动窗口 Tumble
1.2 滑动窗口 HOP
1.3 累积窗口 Cumulate
在实际应用中还会遇到这样一类需求:我们的统计周期可能较长,因此希望中间每隔一段时间就输出一次当前的统计值;
与滑动窗口不同的是,在一个统计周期内,我们会多次输出统计值,它们应该是不断叠加累积的。这种特殊的窗口就叫作"累积窗口"(Cumulate Window),它会在一定的统计周期内进行累积计算。
累积窗口中有两个核心的参数:最大窗口长度(max window size)和累积步长(step)。
所谓的最大窗口长度其实就是我们所说的"统计周期",最终目的就是统计这段时间内的数据。开始时,创建的第一个窗口大小就是步长 step;之后的每个窗口都会在之前的基础上再扩展 step 的长度,直到达到最大窗口长度。在 SQL 中可以用 CUMULATE()函数来定义。
eventTime
测试数据如下:
{"username":"zs","price":20,"event_time":"2025-07-17 10:10:10"}
{"username":"zs","price":15,"event_time":"2025-07-17 10:10:30"}
{"username":"zs","price":20,"event_time":"2025-07-17 10:10:40"}
{"username":"zs","price":20,"event_time":"2025-07-17 10:11:03"}
{"username":"zs","price":20,"event_time":"2025-07-17 10:11:04"}
{"username":"zs","price":20,"event_time":"2025-07-17 10:12:04"}
{"username":"zs","price":20,"event_time":"2025-07-17 11:12:04"}
{"username":"zs","price":20,"event_time":"2025-07-17 11:12:04"}
{"username":"zs","price":20,"event_time":"2025-07-17 12:12:04"}
{"username":"zs","price":20,"event_time":"2025-07-18 12:12:04"}需求:每隔1分钟统计这1分钟的每个用户的总消费金额和消费次数
需要用到滚动窗口
编写好sql:
CREATE TABLE table1 (
`username` string,
`price` int,
`event_time` TIMESTAMP(3),
watermark for event_time as event_time - interval '3' second
) WITH (
'connector' = 'kafka',
'topic' = 'topic1',
'properties.bootstrap.servers' = 'bigdata01:9092',
'properties.group.id' = 'g1',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
编写sql:
select
window_start,
window_end,
username,
count(1) zongNum,
sum(price) totalMoney
from table(TUMBLE(TABLE table1, DESCRIPTOR(event_time), INTERVAL '60' second))
group by window_start,window_end,username;分享一个错误:
Exception in thread "main" org.apache.flink.table.api.ValidationException: SQL validation failed. The window function TUMBLE(TABLE table_name, DESCRIPTOR(timecol), datetime interval) requires the timecol is a time attribute type, but is VARCHAR(2147483647).
说明创建窗口的时候,使用的字段不是时间字段,需要写成时间字段TIMESTAMP(3),使用了eventtime需要添加水印,否则报错。
需求:按照滚动窗口和EventTime进行统计,每隔1分钟统计每个人的消费总额是多少
java
package com.bigdata.flinksql.day02;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @基本功能:
* @program:FlinkDemo2
* @author: 闫哥
* @create:2025-04-20 10:59:41
**/
public class _005Demo {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
tEnv.executeSql("CREATE TABLE table1 (\n" +
" `username` string,\n" +
" `price` int,\n" +
" `event_time` TIMESTAMP(3),\n" +
" watermark for event_time as event_time - interval '3' second\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'topic1',\n" +
" 'properties.bootstrap.servers' = 'node01:9092',\n" +
" 'properties.group.id' = 'g1',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json'\n" +
")");
// 编写sql语句
tEnv.executeSql("select \n" +
" window_start,\n" +
" window_end,\n" +
" username,\n" +
" count(1) zongNum,\n" +
" sum(price) totalMoney \n" +
" from table(TUMBLE(TABLE table1, DESCRIPTOR(event_time), INTERVAL '60' second))\n" +
"group by window_start,window_end,username").print();
}
}注意:在本地运行时,默认的并行度是和你的cpu核数挂钩的,所以,为了快速看到结果,需要将并行度设置为1
测试数据时,因为我们这个是eventTime,所以测试数据时,假如第一条数据是:
{"username":"zs","price":20,"event_time":"2025-07-17 10:10:10"}
说明第一个窗口是 2025-07-17 10:10:00 ~ 2025-07-17 10:11:00
因为有水印,水印时间是3秒,所以,要想触发第一个窗口有结果,必须出现条件是:
{"username":"zs","price":20,"event_time":"2025-07-17 10:11:03"}
所以第一批测试数据如下:
{"username":"zs","price":20,"event_time":"2025-07-17 10:10:10"}
{"username":"zs","price":15,"event_time":"2025-07-17 10:10:30"}
{"username":"zs","price":20,"event_time":"2025-07-17 10:10:40"}
{"username":"zs","price":20,"event_time":"2025-07-17 10:11:03"}结果如下:

假如你测试数据如下:
{"username":"zs","price":20,"event_time":"2025-07-17 10:10:10"}
{"username":"zs","price":15,"event_time":"2025-07-17 10:10:30"}
{"username":"zs","price":20,"event_time":"2025-07-17 10:10:40"}
{"username":"zs","price":20,"event_time":"2025-07-17 10:11:03"}
{"username":"zs","price":20,"event_time":"2025-07-17 10:11:04"}
{"username":"zs","price":20,"event_time":"2025-07-17 10:12:04"}
{"username":"zs","price":20,"event_time":"2025-07-17 11:12:04"}
{"username":"zs","price":20,"event_time":"2025-07-17 11:12:04"}
{"username":"zs","price":20,"event_time":"2025-07-17 12:12:04"}
{"username":"zs","price":20,"event_time":"2025-07-18 12:12:04"}统计结果如下:

测试一下滑动窗口,每隔10秒钟,计算前1分钟的数据:
java
package com.bigdata.flinksql.day02;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @基本功能:
* @program:FlinkDemo2
* @author: 闫哥
* @create:2025-04-20 10:59:41
**/
public class _006Demo {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
tEnv.executeSql("CREATE TABLE table1 (\n" +
" `username` string,\n" +
" `price` int,\n" +
" `event_time` TIMESTAMP(3),\n" +
" watermark for event_time as event_time - interval '3' second\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'topic1',\n" +
" 'properties.bootstrap.servers' = 'node01:9092',\n" +
" 'properties.group.id' = 'g1',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json'\n" +
")");
// 编写sql语句
tEnv.executeSql("select \n" +
" window_start,\n" +
" window_end,\n" +
" username,\n" +
" count(1) zongNum,\n" +
" sum(price) totalMoney \n" +
" from table(HOP(TABLE table1, DESCRIPTOR(event_time), INTERVAL '10' second,INTERVAL '60' second))\n" +
"group by window_start,window_end,username").print();
}
}结果如图所示:
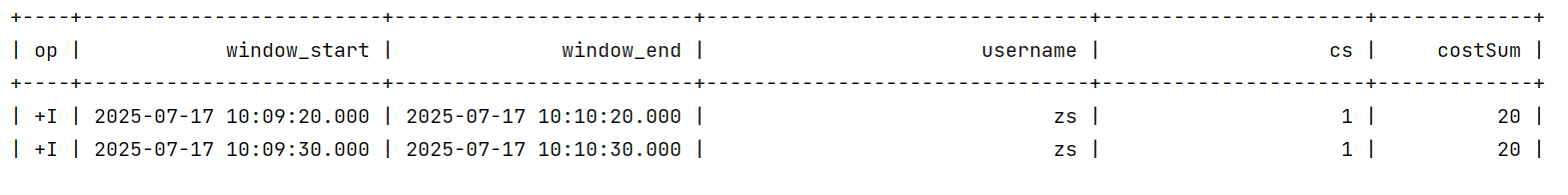
当我输入第一条数据的时候:
{"username":"zs","price":20,"event_time":"2025-07-17 10:10:10"}
它的窗口结束时间是10:10:20秒,往前推1分钟,10:09:20,所以第一个窗口就是
10:09:20~10:10:20 这个窗口的触发时间是10:10:23
第二条数据是:
{"username":"zs","price":15,"event_time":"2025-07-17 10:10:30"}
它的时间是10:10:30 >=10:10:23 所以第一条被触发啦processTime
测试数据:
{"username":"zs","price":20}
{"username":"lisi","price":15}
{"username":"lisi","price":20}
{"username":"zs","price":20}
{"username":"zs","price":20}
{"username":"zs","price":20}
{"username":"zs","price":20}
package com.bigdata.flinksql.day02;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @基本功能:
* @program:FlinkDemo2
* @author: 闫哥
* @create:2025-04-20 10:59:41
**/
public class _007Demo {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
tEnv.executeSql("CREATE TABLE table1 (\n" +
" `username` string,\n" +
" `price` int,\n" +
" `event_time` as proctime()\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'topic1',\n" +
" 'properties.bootstrap.servers' = 'node01:9092',\n" +
" 'properties.group.id' = 'g1',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json'\n" +
")");
// 编写sql语句
tEnv.executeSql("select \n" +
" window_start,\n" +
" window_end,\n" +
" username,\n" +
" count(1) zongNum,\n" +
" sum(price) totalMoney \n" +
" from table(TUMBLE(TABLE table1, DESCRIPTOR(event_time), INTERVAL '60' second))\n" +
" group by window_start,window_end,username").print();
}
}计算结果: 等到正分钟 00 秒的时候会出结果。

结果需要等1分钟,才能显示出来,不要着急!
窗口分为滚动和滑动,时间分为事件时间和处理时间,两两组合,4个案例。
以下是滑动窗口+处理时间:
package com.bigdata.flinksql.day02;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @基本功能:
* @program:FlinkDemo2
* @author: 闫哥
* @create:2025-04-20 10:59:41
**/
public class _008Demo {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
tEnv.executeSql("CREATE TABLE table1 (\n" +
" `username` string,\n" +
" `price` int,\n" +
" `event_time` as proctime() \n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'topic1',\n" +
" 'properties.bootstrap.servers' = 'node01:9092',\n" +
" 'properties.group.id' = 'g1',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json'\n" +
")");
// 编写sql语句
tEnv.executeSql("select \n" +
" window_start,\n" +
" window_end,\n" +
" username,\n" +
" count(1) zongNum,\n" +
" sum(price) totalMoney \n" +
" from table(HOP(TABLE table1, DESCRIPTOR(event_time), INTERVAL '10' second,INTERVAL '60' second))\n" +
"group by window_start,window_end,username").print();
}
}测试时假如你的控制台不出数据,触发不了,请进入如下操作:
1、重新创建一个新的 topic,分区数为 1
2、kafka 对接的 server,写全 bigdata01:9092,bigdata02:9092,bigdata03:9092
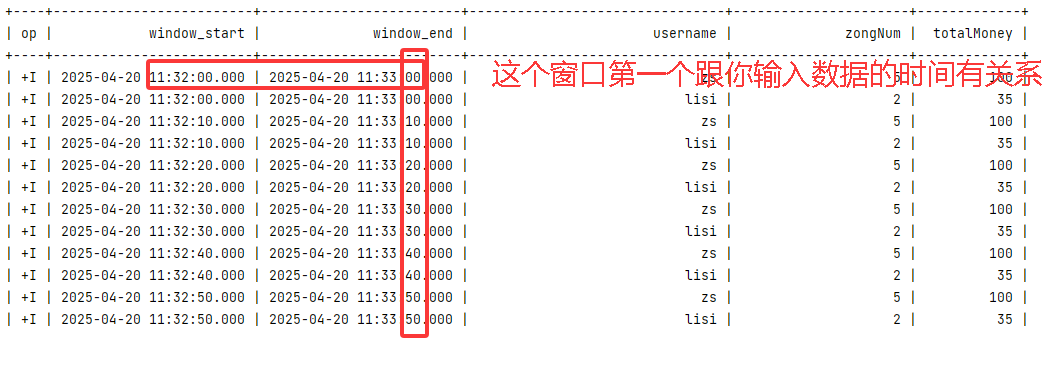
假如我是 11:41:42 秒发送的数据,等到 11:41:50 出结果
第一个结果是:
| +I | 2025-04-20 11:40:50.000 | 2025-04-20 11:41:50.000 | zs | 5 | 100 |
| +I | 2025-04-20 11:40:50.000 | 2025-04-20 11:41:50.000 | lisi | 2 | 35 |
最后一个结果应该结束时间是 11:42:40 才对:
| +I | 2025-04-20 11:40:50.000 | 2025-04-20 11:41:50.000 | zs | 5 | 100 |
| +I | 2025-04-20 11:40:50.000 | 2025-04-20 11:41:50.000 | lisi | 2 | 35 |
| +I | 2025-04-20 11:41:00.000 | 2025-04-20 11:42:00.000 | zs | 5 | 100 |
| +I | 2025-04-20 11:41:00.000 | 2025-04-20 11:42:00.000 | lisi | 2 | 35 |
| +I | 2025-04-20 11:41:10.000 | 2025-04-20 11:42:10.000 | zs | 5 | 100 |
| +I | 2025-04-20 11:41:10.000 | 2025-04-20 11:42:10.000 | lisi | 2 | 35 |
| +I | 2025-04-20 11:41:20.000 | 2025-04-20 11:42:20.000 | zs | 5 | 100 |
| +I | 2025-04-20 11:41:20.000 | 2025-04-20 11:42:20.000 | lisi | 2 | 35 |
| +I | 2025-04-20 11:41:30.000 | 2025-04-20 11:42:30.000 | zs | 5 | 100 |
| +I | 2025-04-20 11:41:30.000 | 2025-04-20 11:42:30.000 | lisi | 2 | 35 |
| +I | 2025-04-20 11:41:40.000 | 2025-04-20 11:42:40.000 | zs | 5 | 100 |
| +I | 2025-04-20 11:41:40.000 | 2025-04-20 11:42:40.000 | lisi | 2 | 35 |