前言
本文学习自Flink官方社区
一.什么是Delta Join,它是干啥的?
1.实时的痛点
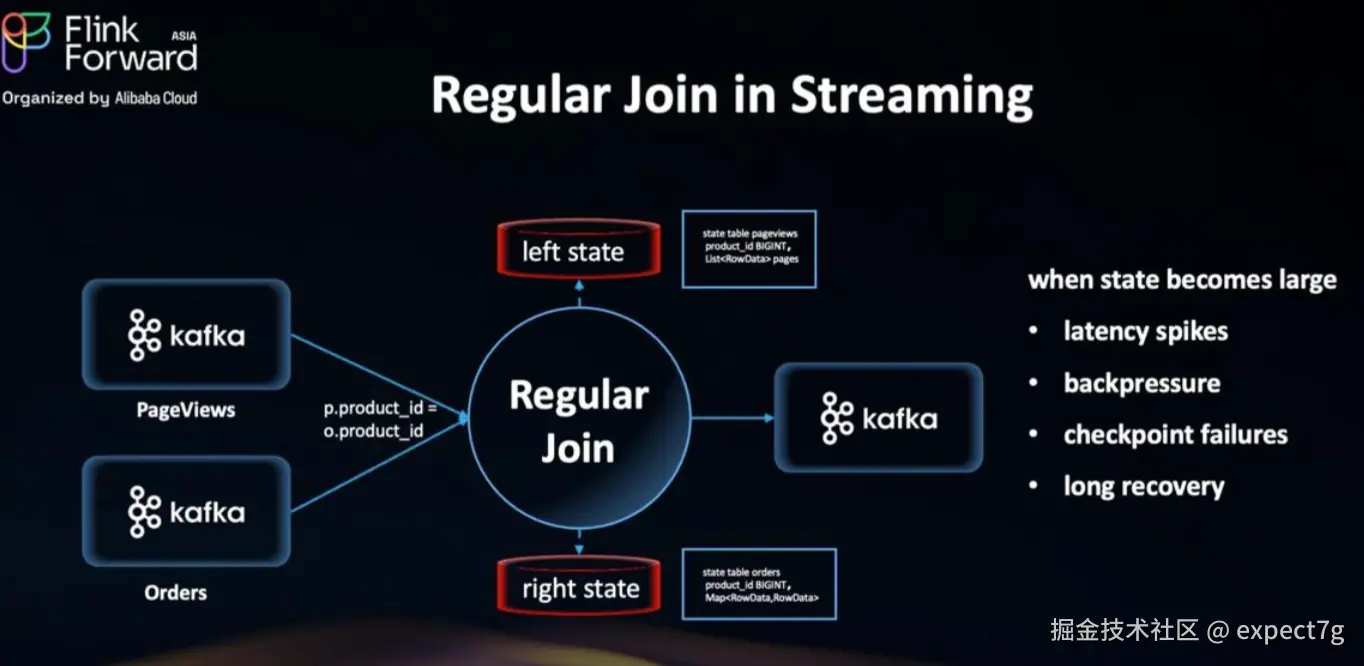
实时最大痛点:传统流式 Join 在面对海量数据和高基数 Key 时却遇到了瓶颈。问题在于2点
- 为了保证正确性:你必须将所有历史数据永久保存在 Flink 状态中,且处理乱序到达的情况------这是个无底洞,状态极大,cp极慢
- 为了保证实时性:必须将需要关联的数据放在内存中,去实现快速查询------这显然很浪费资源,内存动不动就得几T甚至几百T
Delta Join 出现将彻底改变了这一局面 。它不再将所有数据缓存在Flink内部,而是将 Join 转变为一种无状态的查询机制,直接从 Apache Fluss 或 Apache Paimon 等外部表中实时获取所需数据。
当然不是像HBase那样,去直接访问外部系统HBase,这显然很慢;
传统实时数仓为了节省成本,也能提高效率,选择的是redis做缓存,HBase做存储,这种思路很好,因此,被用到了Delta Join的开发中。
2.Delta Join 设计
Delta Join:让算子不再将全部历史数据存于 Flink 状态,而是在需要时才去外部存储查询。从此告别状
(1) 核心理念:计算 vs 历史
Delta Join(FLIP-486)的核心是关注点分离。其原则非常清晰:
"按需查询,最小作业状态,最终一致性"
当事件到达 Join 的任意一侧时,算子不会翻查内部历史,而是实时查询外部索引。不再囤积数据,用时再取。
(2) StreamingDeltaJoinOperator 如何工作?
StreamingDeltaJoinOperator 是实现这一切的引擎,关键组件包括:
- 双侧 LRU 缓存:查询前先查缓存,热数据驻留内存,冷数据自动淘汰 -- 类似redis
- 异步探查(Async Probing) :缓存未命中时立即发起查询,不阻塞处理流水线 -- 类似HBase
- AsyncDeltaJoinRunner:每侧一个实例,负责管理缓存与外部 I/O -- 解耦
注意:Delta Join 并非完全无状态,而是一种混合模型。算子仍保留 LRU 缓存和协调状态以保证一致性。性能表现取决于缓存命中率和外部查询延迟。
(3) 正确性保障:异步顺序控制
异步查询的一大挑战是:同一个 Key 的更新可能乱序到达,破坏结果正确性。
Delta Join 通过 FLIP-519 引入的KeyedAsyncWaitOperator 解决此问题:
- 同一 Key 的操作严格串行执行
- 不同 Key 仍可并行处理
既保留了高吞吐优势,又确保了结果正确性。
3. 配置、使用、适用场景
(1) 在 SQL 中使用 Delta Join
Delta Join 完全兼容标准 SQL,无需特殊语法。只需像平常一样写 JOIN ,案例如下:
sql
SELECT * FROM orders
INNER JOIN Product
ON orders.productId = Product.id只要满足条件,Flink 优化器会自动将其转换为 Delta Join:
- SQL 模式支持 Regular Join → Delta Join 转换
- 已配置合适的外部存储
在较新 Flink 版本中,这一转换通常自动发生。
(2) 关键配置参数
sql
# 自动决策是否启用 Delta Join(默认)
set 'table.optimizer.delta-join.strategy'='AUTO'
# 启用缓存(默认开启)
set 'table.exec.delta-join.cache-enabled'='true'
# 左表缓存大小
set 'table.exec.delta-join.left.cache-size'=10000
# 右表缓存大小
set 'table.exec.delta-join.right.cache-size'=10000
# 异步查询并发上限
set 'table.exec.async-lookup.buffer-capacity'=100 (3) Delta Join适用场景
Delta Join 在以下场景大放异彩:
- 高基数流式 enrichment:将海量事件流(点击、交易)与大型、高频更新的维表(用户画像、商品目录)关联,避免状态爆炸 -- 实现日志表和日志表Join
- 实时可追溯性:所有 Join 历史存于外部存储,可精准审计任意计算所用数据 -- 解耦存储、查询计算
- 复杂变更追踪:在维表频繁增删改的同时,保持 Flink 内部状态极小化 -- 解决大状态问题
二.未来展望
目前,Apache Fluss(孵化中)和Delta Join 高度匹配 ,其正是为这类场景而生------它是一个专为 Apache Flink 设计的解耦式表存储引擎。
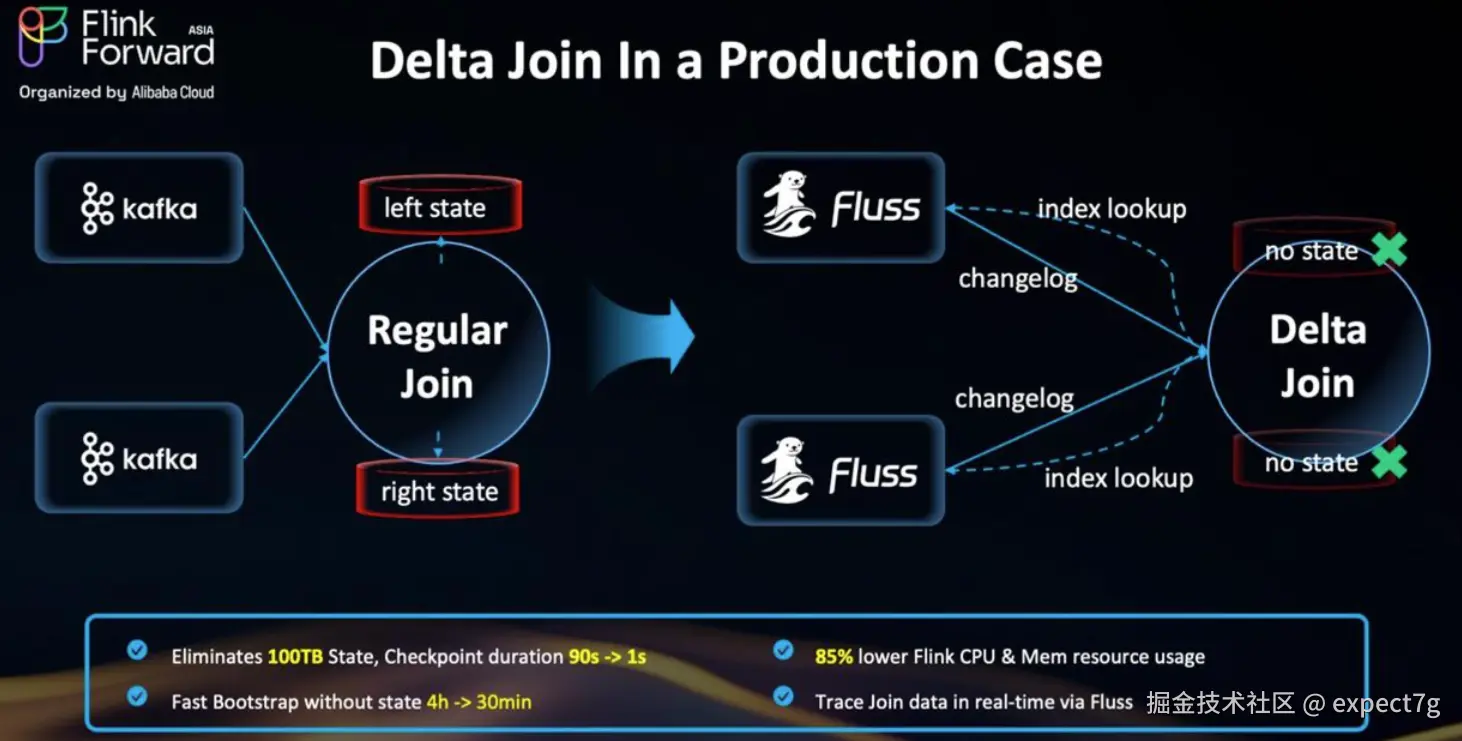
关键特性:
- 分布式架构:Coordinator + 基于 RocksDB 的 Tablet Server
- 双结构设计:KV 存储 + 日志 Tablet = 支持任意时间点查询 + CDC 流输出
- 前缀查询(Prefix Lookups) :支持使用复合主键的部分字段查询(例如仅用
customer_id,而非完整的(customer_id, order_id, item_id))。多数系统要求精确匹配,Fluss 则灵活得多 -- 关键
虽然 Fluss 是 Delta Join 的初始载体,但 Flink 社区正积极推动其与开源湖仓格式的融合。Flink SQL 路线图已明确计划支持 Apache Paimon,以实现更广泛的近实时 Delta Join 能力。
Paimon 的优势:
- 支持主键表与实时流式更新
- 分钟级可查
- 灵活的 Merge 引擎(去重、部分更新、聚合)
- 与 Spark、Hive、Trino 无缝集成
目标很明确:让 Delta Join 成为整个湖仓生态的通用能力,而不仅限于 Fluss。
目前,Delta Join 在 Fluss(尤其是其强大的前缀查询能力)上表现卓越。未来,随着对 Apache Paimon 等湖仓格式的支持落地,Delta Join 将成为整个流处理生态的标准能力。