简介
混合专家(MOE)是大模型一种主流的模型架构,相比稠密模型,MOE的训练速度更快,在同样的参数量下,有更快的推理速度,同时,MOE以多专家的形式扩展了模型容量,能达到较好的效果。
MOE发展历史
OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER
2017一篇论文,较早的提出了MOE在多层LSTM上的实验,实验做的也比较充分,效果还不错。
模型结构如下图,在两层的LSTM之家,加入MOE layer, 有一个门控路由网络和多个专家组合而成,门控网络每次选择两个专家进行输出
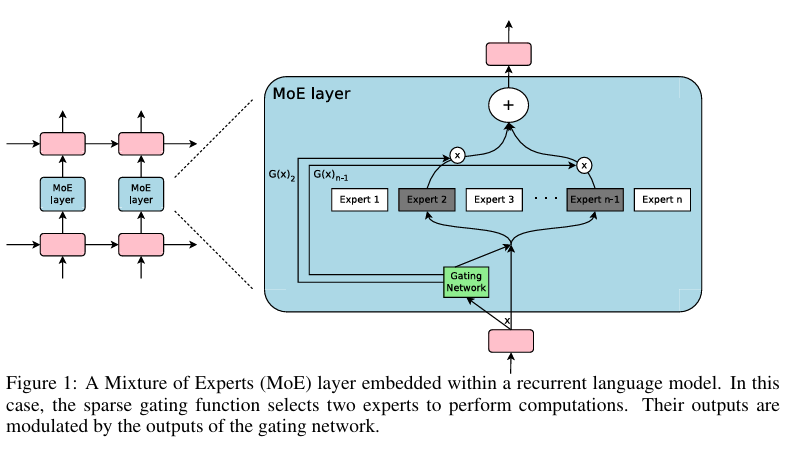
MOE Layer的实现有多个专家组成,每个都是一个前向神经网络,和一个可训练的门控网络,用于选择一组合适的专家,
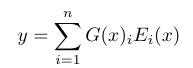
门控网络
输入x乘以一个参数Wg, 再经过一个Softmax函数
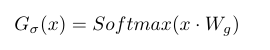
使用带有噪声的TopK, 目的是为了负载均衡,避免softmax每次输出相同的topk个专家

实验部分设计了不同的MOE层的变体, 结果表明还是使用MOE的网络效果最好
- 更宽的网络:使用一个专家,但使用更宽的隐藏状态(hidden size=4096)
- 更深的网络:使用一个专家,4层FFN,每层的hidden size=1024
- 替换MOE: 将MOE层替换成两层额外的hidden size=512 的LSTM网络
- 更大的LSTM: hidden size=2048(没有MOE层),输出层大小512
文章在附录中说,不同的Expert关注的词不同,第381个专家关注每个句子中的名词,第752个专家关注句子中的介词,第2004个专家关注句子中的形容词和副词

GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
2020年谷歌发表的一篇关于MOE的论文,将Transformer模型和MOE架构结合,在多语言的翻译任务上,使用稀疏门控混合专家模型,训练了一个600b的模型
核心:数据越多,模型越大,专家越多,表现也就越好
模型结构
同样使用了一个gate网络,为每个token选择最多两个专家,最后将路由概率和专家输出FFN(x)进行加权求和

相较于Transformer的Encoder, GShard改进了FFN层,使用MOE层进行替代,同时为了提升计算速度,在不同设备之间进行了共享
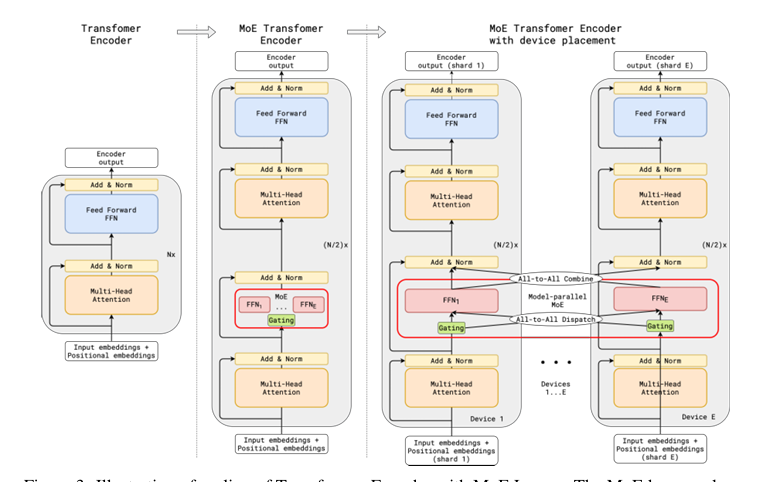
路由的gate网络需要满足
- 负载均衡
使用softmax选择topk个专家,防止一些专家频繁被选择而另一部分未训练 - 高效
O(NE), N是百万级E是专家数量 - 专家容量
对于一个Batch内的token数N, 每个token被派到两个专家,每个专家的token容量为O(N/E), 如果被一个token选择的专家,已经超过其容量,则该token溢出,直接使用一个残差进行连接 - 辅助损失
防止门控网络总是选择相同的少量专家,需要一个辅助损失Laux进行限制
-随机路由
高度并行
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
2022年1月发表。通过简化MOE算法,使用bf16半精度训练,获得7倍的预训练速度提升,在多语言任务上性能超过T5-Base
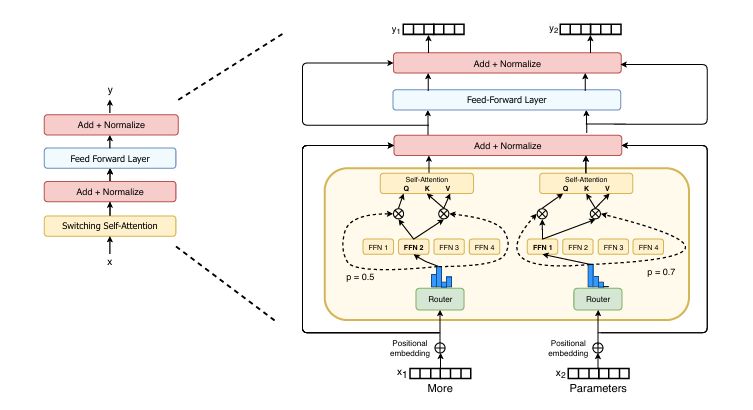
模型结构
-
简化稀疏路由
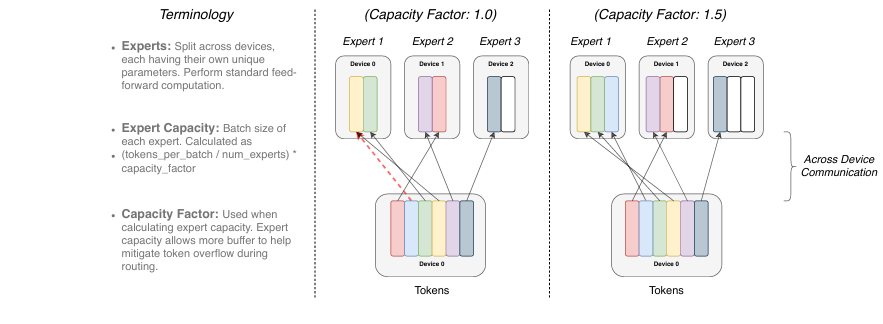
将top k个专家简化成直接使用一个专家(k=1),如下图,每个专家token只选择一个专家
-
专家容量因子
即每个专家通过多少token数,计算方式为(total tokens/ num experts) * capcity_factor, 容量因子* capcity_factor越大,通过专家的token数越多,专家训练的越充分。越大的容量因子能防止token溢出,同时带来了计算和通信开销
-
可微分的负载均衡损失
load balance loss被设计用于平衡专家之间的选择,其加到模型训练的loss一同训练,在Switch-transformer中,负载均衡损失被设计成两个向量点积的累加和。N是专家个数,i是第i个专家,alpha是超参数
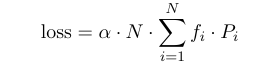
向量fi表示被分配到专家i的部分token,T表示token总数
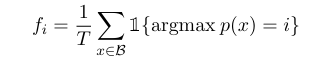
Pi是路由网络分配给专家i的路由概率
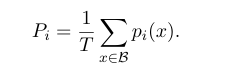
一个是token限制,一个是路由概率限制,两项相乘,得到负载均衡项,越小越好,即所有expert之间这两项乘积之和的差异越小越好
-
使用bf16精度训练
在路由保留float32精度,保持了训练的稳定性, 而其他地方使用bf16
浮点数由指数位和尾数位组成, float32精度包含8个指数位,23个尾数位;bf16包含8个指数位和7个尾数位。可以看到float32和bf16的区别在于尾数位,bf16保留的尾数位更少,精度更低
BF16与FP32的区别
bf16与fp32能覆盖同样的数值范围, bf16的优点在于计算效率快,使用更大batchsize,可以训练更大规模参数的模型, 减少显存占用, bf16 的权重、梯度、激活值等张量占用内存仅为 fp32 的一半; 数据传输(如 GPU 间通信)带宽减半,加速分布式训练。bf16 计算吞吐量通常为fp32 的 2-8 倍;
使用混合精度训练(如 torch.cuda.amp),兼顾 bf16 的效率与 fp32 的稳定性。

- 正则化
在非MOE层使用较小的dropout, 而在MOE层使用较大的dropout, 达到最优的性能
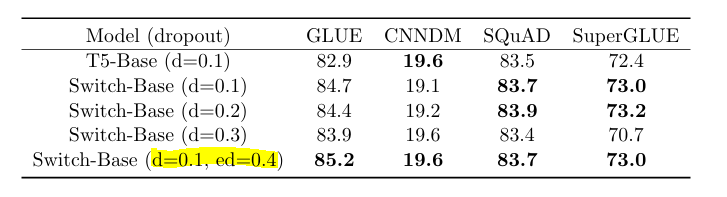
超参数
专家数越多,损失越小,负对数困惑度越大
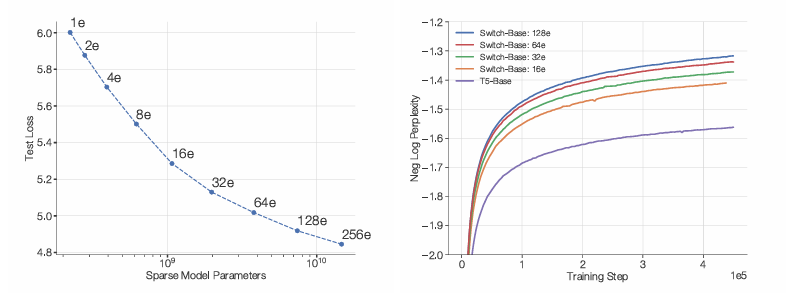
文章指出了当时MOE模型没有被广泛使用的原因
- 模型复杂度
引入MOE网络,增加了路由网络、多个专家,相比单一的FFN更加复杂,总的参数量并没有减少 - 训练困难
MOE网络训练loss不稳定,作者采样了路由网络全精度和其他部分bf16半精度的形式,此外在MOE层使用了更大的dropout, 专家容量因子设计和溢出token的残差连接设计,以及从token分配和路由概率分配两个角度设计了负载均衡损失,加强了训练的稳定性 - 通信开销
主要是在多专家情况下,如何进行模型和数据的并行计算,以及通信开销
文章在未来工作提到在Attention 层前使用MOE层,但是半精度的训练导致了不稳定
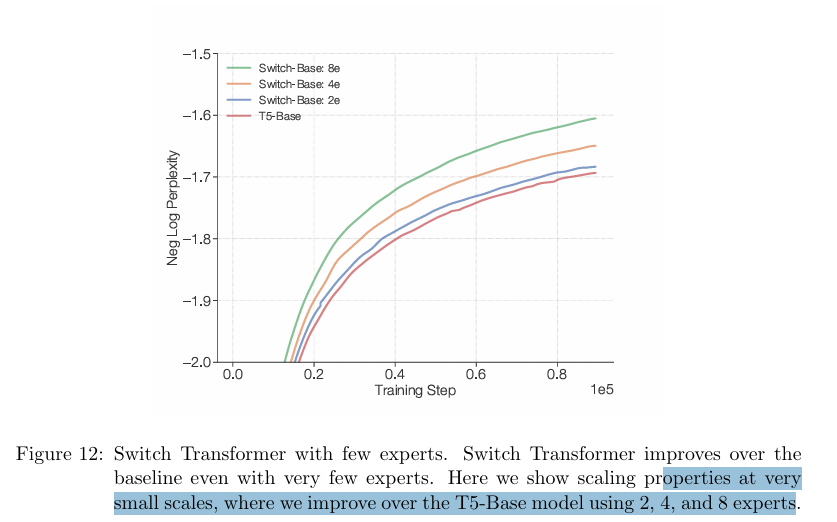
附录部分显示,少量的专家实验中,专家越多效果越好
ST-MOE: DESIGNING STABLE AND TRANSFERABLE SPARSE EXPERT MODELS
2022年4月发表。文章支出稀疏模型训练不稳定,如下图左图,右图是稳定训练,因此针对训练稳定性做出改进。这是一篇实验性质的论文,从稳定训练,到微调sparse model与dense model对比,设计sparse model, 专家个数设计,专家容量,以及路由算法,最后对专家选择的token进行了解释说明。
第一部分 稳定训练
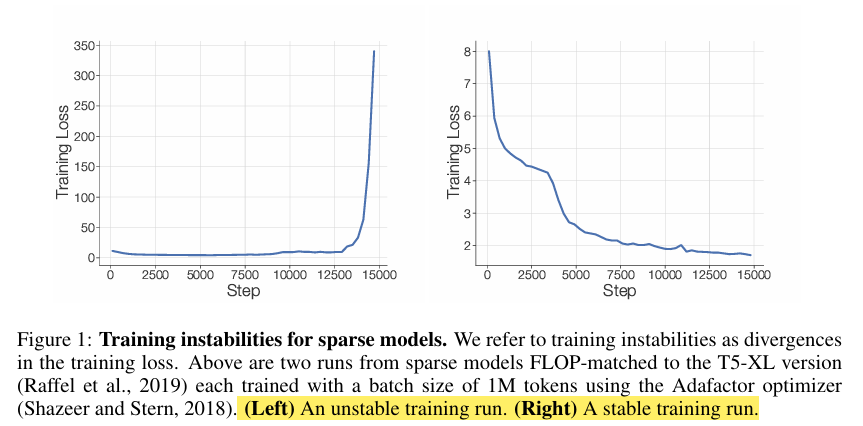
核心:提升MOE训练的稳定性和可迁移性,提出了以下几点改进
A.使用GLUE计划函数
对于Transformer中的激活函数,改进成GELU函数,进行非线性选择

实验表明在训练时移除GEGLUE、RMS Norm会增加稳定性,但也会使得性能下降
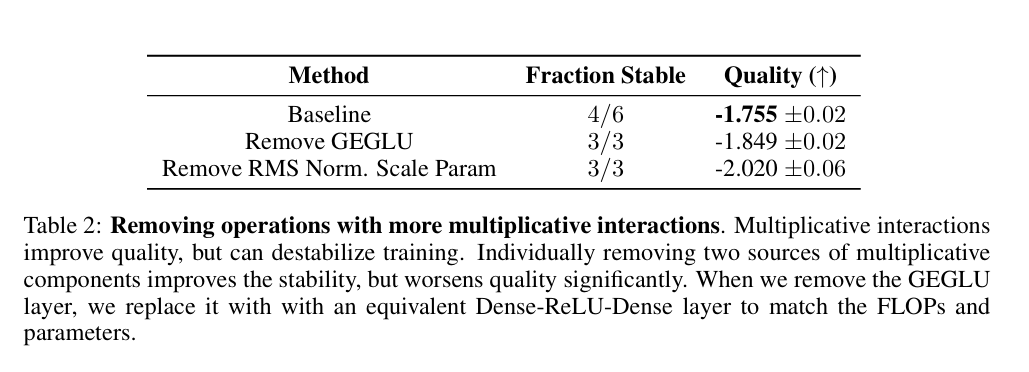
B. 使用root-mean square缩放参数
提到几个稳定训练的trick, 1) RMS Norm 2) layer call(eg SelfAttention) 3) dropout, 4) residual connection
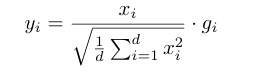
C.提出router-z loss损失函数
Route-z loss惩罚大的logits, B是所有token数,N是expert数,i是第i个token
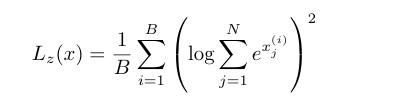
将route-z loss加入到最终的训练loss中
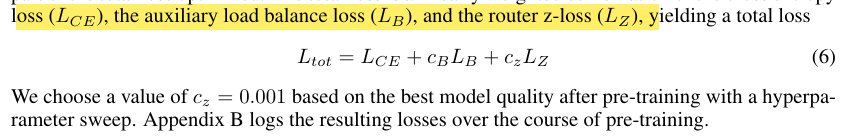
作者观察到在实验时使用route-z loss,可以使得训练更稳定,同时带来轻微的性能提升
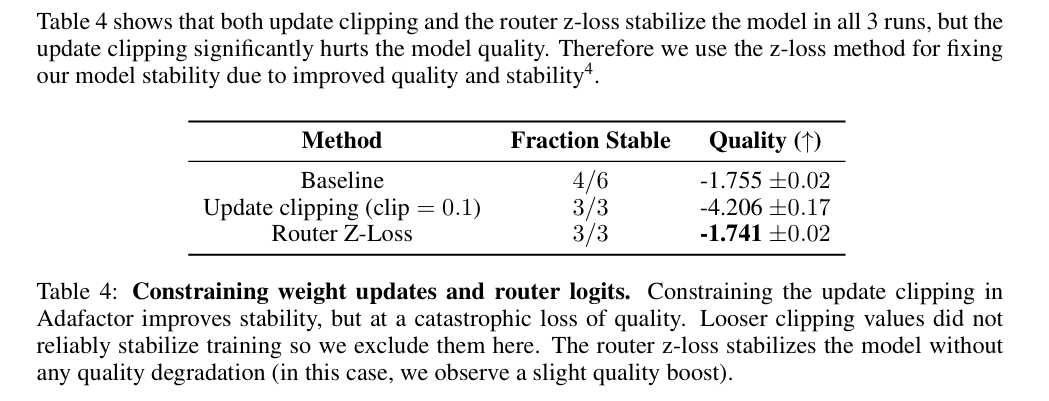
c.使用噪声注入加dropout机制
输入抖动和 Dropout 方法能提高稳定性,但导致模型质量下降。实验结果显示,这些方法在提高稳定性的同时,显著降低了模型的性能
d.使用bf16代替bf32进行训练
文章对比了float32和bf16两种精度,数值精度格式和舍入误差。数字越大,四舍五入越大错误。Bfloat16的舍入误差比float32高65,536倍。Route-z loss鼓励数字的绝对值较小,这不会妨碍模型的性能, 并减少舍入误差。Route-z loss在误差较大的函数中最有效,可以极大地改变相对输出(例如指数函数和正弦函数)。

第二部分 微调稀疏模型
假设1. 稀疏模型容易过拟合
通过 SuperGLUE 任务验证这一假设。实验结果表明,稀疏模型在小数据集上的泛化性能较弱,但在大数据集上则优于密集模型。
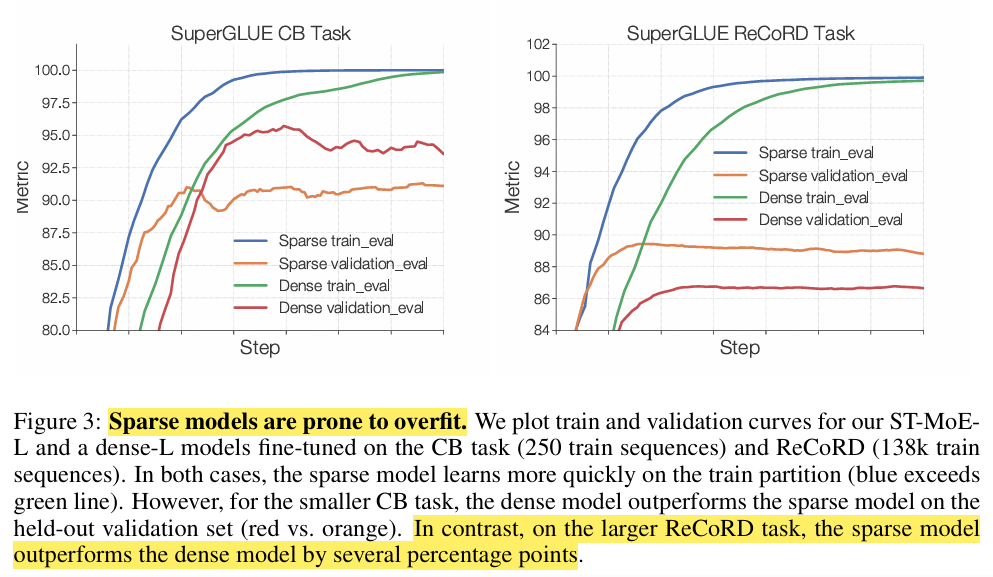
稀疏模型的微调性能实践2:微调策略的影响
探究不同 Batch Size 和学习率对稀疏和密集模型微调性能的影响。结果表明,稀疏模型受益于较小的 Batch Size 和较大的学习率,可能通过提高泛化能力来缓解过拟合。而稠密模型在较大的Batch Size和较小的学习率上表现更好
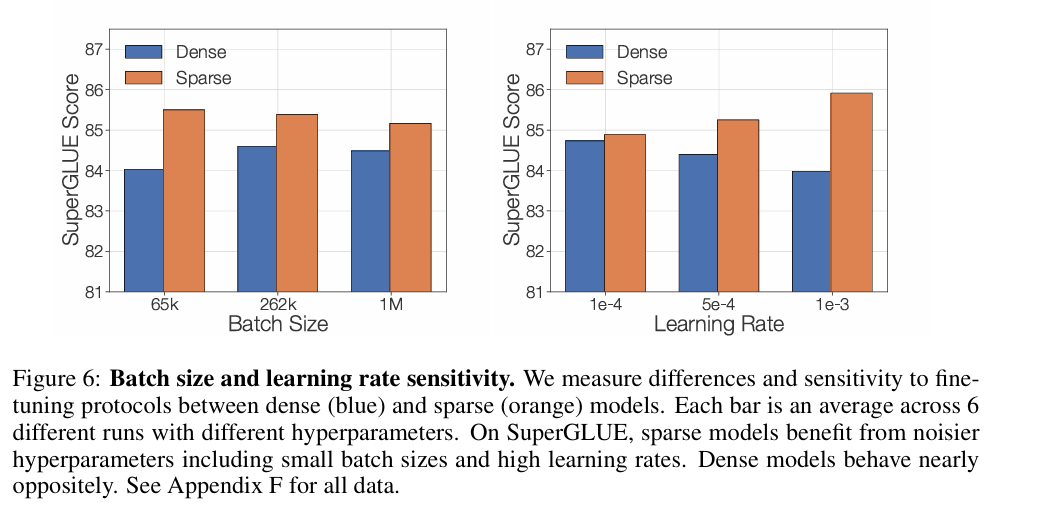
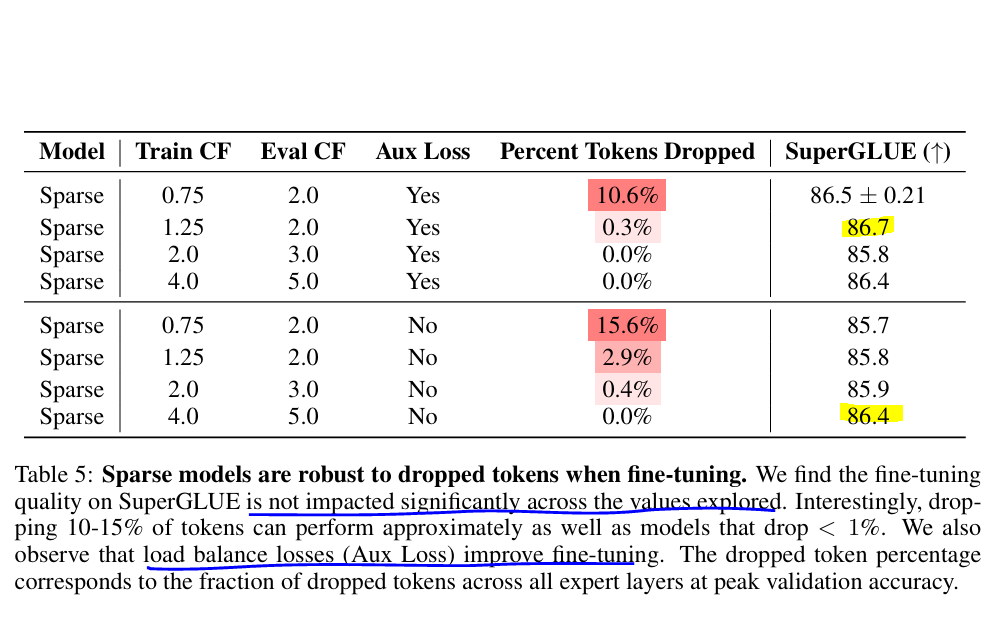
专家容量因子参数消融实验
容量因子可以决定每个专家通过多少token, 容量因子越小,溢出的token越多,越大通过的token越多,文章对比了不同的容量因子和训练的结果
-
效果受容量因子影响不大
-
负载均衡损失(辅助损失)有助于于提高微调的效果
第三部分 设计稀疏模型
作者提出了以下几个问题
1)使用多少专家
作者推荐使用top2专家,使用1.25的容量因子作为初始设置
2)使用什么路由算法
3)容量因子设置为多少
根据显存的大小和计算速度改变容量因子
4)硬件如何改变这些决策
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
- Fine-Grained Expert Segmentation-细粒度的专家分割, 通过细化FFN中间隐藏维度,维持参数数量不变的同时激活更多细粒度的专家,使得激活的专家更加灵活和适应性更强;
- Shared Expert Isolation-共享专家隔离,将某些专家隔离为共享专家,始终激活,旨在捕捉和巩固不同上下文中的共同知识。
模型结构:
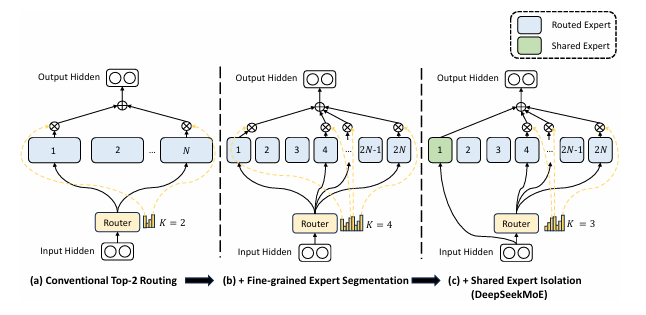
实验结果:
零样本和少样本任务上,证明DeepSeekMoE 超越了相似的模型,通过消融实验证明了细粒度专家和共享专家隔离的有效性
参考
1 Mixtral of Experts
2 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
3 Let's train a Mixture of Experts (MoE) model using Hugging Face 🤗