文章目录
- QA
- [Deep think with confidence](#Deep think with confidence)
-
- 一、核心问题与背景
- 二、DeepConf的核心思想
- 三、DeepConf的具体实现
-
- [1. 置信度衡量指标](#1. 置信度衡量指标)
- [2. 离线思考模式 (Offline Thinking)](#2. 离线思考模式 (Offline Thinking))
- [3. 在线思考模式 (Online Thinking)](#3. 在线思考模式 (Online Thinking))
- 四、实验结果与结论
- 五、总结
- [From Selection to Generation: A Survey of LLM-based Active Learning](#From Selection to Generation: A Survey of LLM-based Active Learning)
-
- 主动学习 (Active Learning, AL)
- 传统AL的无标注数据挑选策略
- LLM的无标注数据挑选策略
- [AL 作用于LLM几类后训练(ICL, SFT, 偏好对齐,知识蒸馏)](#AL 作用于LLM几类后训练(ICL, SFT, 偏好对齐,知识蒸馏))
-
- [Active In-Context Learning](#Active In-Context Learning)
- [Active SFT](#Active SFT)
- [Active preference alignment](#Active preference alignment)
- [Active knowledge Distillation](#Active knowledge Distillation)
QA
- Deep think with confidence:本文章着力于在推理阶段,节省并行思考的计算量,同时保持甚至提升输出结果的准确度。这种置信度衡量的方式,能否也用于训练阶段?
- 置信度可以作为一种信号,来动态地调整训练过程。
- 课程学习 (Curriculum Learning):
训练初期,先给模型看那些它高置信度就能解决的"简单"问题。
随着模型能力增强,逐步引入那些让它感到低置信度的"困难"问题。
这样由易到难的学习路径,比随机混合所有数据进行训练,可能更符合学习规律,效果更好。 - 数据加权 (Data Weighting): (类似于强化学习公式,对于超出最大、最小范围数值的裁剪)
在训练时,对于那些模型低置信度但最终做对了的样本,可以给予更高的权重(loss weight),因为这些是模型"学到了新东西"的宝贵案例。
对于那些模型高置信度且做对了的样本("过于简单"),可以降低它们的权重。
对于那些模型高置信度但做错了的样本("迷之自信"),需要给予极高的权重,因为这暴露了模型的知识盲区或偏见,需要重点纠正。
- 课程学习 (Curriculum Learning):
Deep think with confidence
- meta
- 2025.8
- project: https://jiaweizzhao.github.io/deepconf/
一、核心问题与背景
-
现有方法的困境:
- 为了让LLM在数学、编程等复杂推理任务上表现更好,一个常用且有效的方法叫做"自洽性 (Self-Consistency) "或"平行思考 (Parallel Thinking)"。
- 这个方法很简单:让模型针对同一个问题,独立地生成很多个(比如512个)不同的解题思路(称为"推理迹线",reasoning traces)。最后,通过"少数服从多数 (Majority Voting)"的原则,选择出现次数最多的答案作为最终答案。
- 问题1:成本高昂。生成512个解题过程,计算量就是原来的512倍,这在实际应用中是无法接受的。
- 问题2:收益递减。当生成的解题思路数量增加到一定程度后,准确率的提升会变得非常缓慢,甚至可能因为低质量的思路过多而下降。
-
现有方法的缺陷:
- 传统的"少数服从多数"投票法有一个致命缺陷:它平等地对待每一个解题思路。无论一个思路是清晰、流畅、充满自信,还是磕磕巴巴、自我怀疑,它都只算一票。这显然不合理。
二、DeepConf的核心思想
这篇文章提出的 DeepConf (Deep Think with Confidence) 方法,其核心思想非常直观且巧妙:利用模型自身的"自信程度"来判断解题思路的质量,从而对它们进行筛选或加权。
- 什么是"自信程度"?
- LLM在生成每一个词(token)时,都不是随口一说的,它内部会有一个关于下一个词应该是什么的概率分布。
- 如果模型对下一个词非常确定,那么这个概率分布会非常"尖锐"(比如99%的概率是A,其他词概率极低),这代表高置信度。
- 如果模型很纠结,不确定下一个词是什么,那么概率分布会很"平坦"(比如A、B、C的概率差不多),这代表低置信度。
- DeepConf如何利用"自信程度"?
- 通过计算每个解题思路中所有(或部分)token的置信度,可以给整个思路打一个"质量分"。
- 一个高质量的解题思路,通常全程都比较"自信";而一个低质量的思路,很可能在某个关键步骤上表现出"犹豫"和"不确定"(例如,模型会生成"等等,我再想想"、"让我重新检查一下"等词语,此时置信度会显著下降)。
- DeepConf就是通过这个"质量分"来过滤掉低质量的思路 ,或者在投票时给高质量的思路更大的权重。
三、DeepConf的具体实现
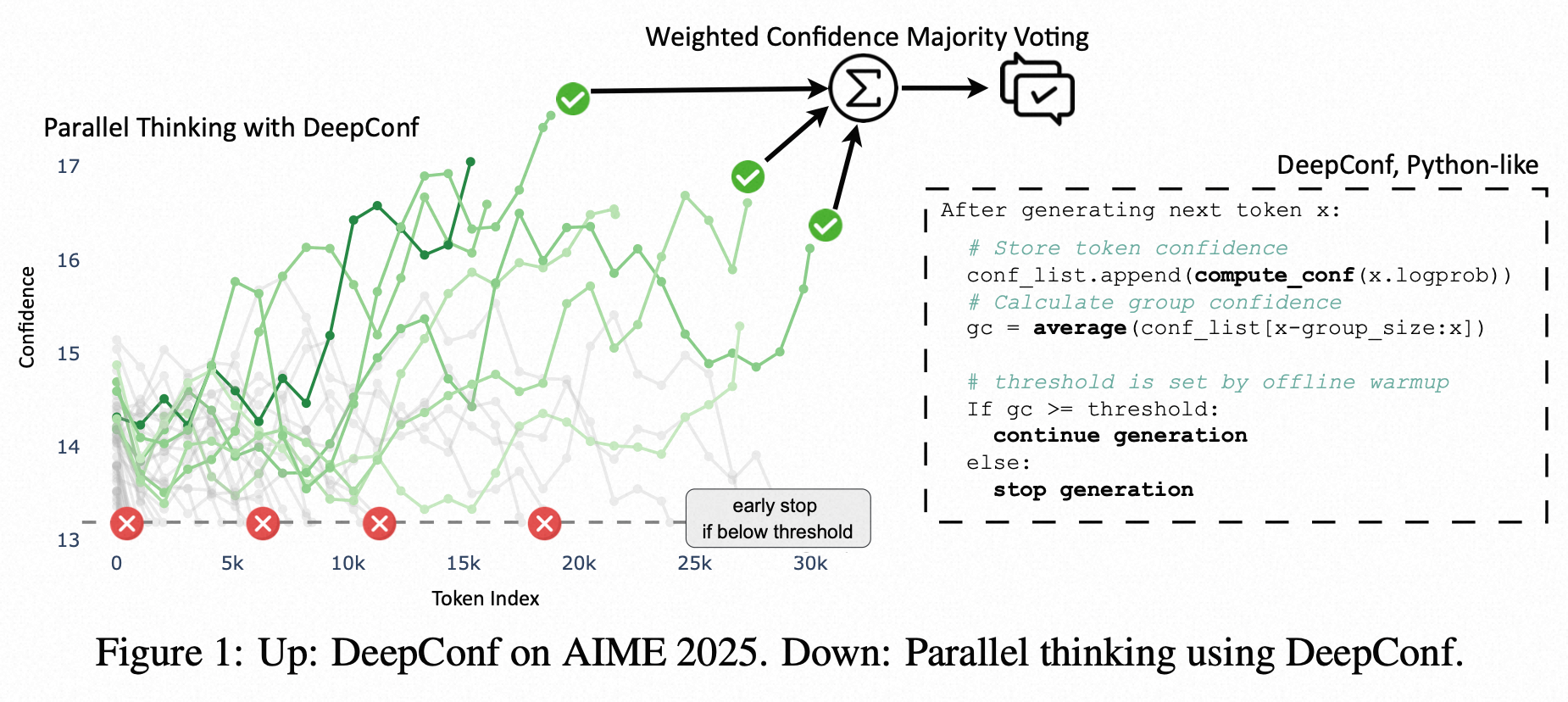
DeepConf提出了几种衡量"置信度"的指标,并设计了两种工作模式:离线思考 (Offline Thinking) 和 在线思考 (Online Thinking)。
1. 置信度衡量指标
论文不只使用简单的平均置信度,而是提出了几种更精细的指标,因为一个思路的质量往往取决于其最薄弱的环节:
- 组置信度 (Group Confidence): 不看单个token,而是看一个滑动窗口内(比如最近的1024个token)的平均置信度。这可以平滑噪声,得到更稳定的局部置信度信号。
- 最低组置信度 (Lowest Group Confidence): 整个解题思路中,置信度最低的那个"组"的置信度。这就像木桶效应,一个思路的质量取决于其最不确定的那一步。
- 底部10%组置信度 (Bottom 10% Group Confidence): 将所有组置信度排序,取最低的10%求平均。这是对"最低组置信度"的一个更鲁棒的估计。
- 尾部置信度 (Tail Confidence): 只看解题思路最后一部分(比如最后2048个token)的置信度。因为很多错误发生在最后得出结论的步骤。
实验证明,最低组置信度、底部10%组置信度 和尾部置信度这些局部指标,比全局平均置信度更能有效地区分正确和错误的解题思路。
- 根据推理路径的每个token 概率值,计算对应的置信度结果(概率越高,对应的置信度越高),按照需求统计
2. 离线思考模式 (Offline Thinking)
在这种模式下,模型已经生成了全部N个解题思路。DeepConf要做的是如何更好地利用它们。
- 置信度过滤 (Confidence Filtering) : 根据上面计算出的置信度分数,只保留质量最高的 前η% 的思路(比如前10%或前90%)。
- 置信度加权投票 (Confidence-Weighted Majority Voting): 在投票时,每个答案不再是简单的+1票,而是加上它对应思路的置信度分数。这样,由高置信度思路得出的答案会有更大的影响力。
离线模式的核心目标:提升准确率。 实验表明,即使只保留前10%最高质量的思路进行投票,准确率也远超传统的512路多数投票。例如,在AIME 2025测试中,GPT-OSS-120B模型使用DeepConf后准确率达到99.9%,几乎完美,而传统方法只有97.0%。
3. 在线思考模式 (Online Thinking)
这是DeepConf更具创新性和实用价值的部分。它在模型生成解题思路的过程中实时监控置信度。
- 工作流程 :
- 热身 (Offline Warmup): 先生成少量(比如16个)完整的解题思路。
- 设定阈值 (Set Threshold): 根据这16个思路的置信度,计算出一个"及格线"(置信度阈值s)。例如,取这16个思路中,置信度排名前90%的思路里分数最低的那个作为阈值。
- 动态提前终止 (Dynamic Early Stopping) : 之后,在生成新的解题思路时,实时计算"组置信度"。一旦当前的组置信度低于 这个"及格线"s,就立即停止生成这个思路,因为它很可能是一个低质量的思路,没必要再浪费计算资源了。
- 自适应采样 (Adaptive Sampling): 在生成一定数量的思路后,如果大多数思路得出的答案已经高度一致,就提前停止整个过程,不再生成更多的思路。
在线模式的核心目标:在保持(甚至提升)准确率的同时,大幅节省计算成本(减少生成的token数量)。 实验结果惊人,在AIME 2025上,与生成完整的512个思路相比,DeepConf最多可以**减少84.7%**的token生成量,同时准确率不降反升。
四、实验结果与结论
- 效果显著: 无论是在离线还是在线模式下,DeepConf都表现出色。它不仅能将准确率推向新的高度(在某些任务上达到近100%),还能极大地降低计算开销。
- 普适性强: 该方法在多种模型(从8B到120B参数)、多种高难度推理任务(数学竞赛题AIME, HMMT等)上都取得了稳定的效果。
- 实现简单: DeepConf不需要重新训练模型,也不需要复杂的超参数调整,可以无缝集成到现有的服务框架中(论文附录甚至给出了在vLLM框架中修改几行代码就能实现的教程)。
五、总结
《Deep Think with Confidence》提出了一种简单、优雅且高效的方法,来优化大模型的推理过程。它抓住了"模型置信度"这一内在信号,巧妙地解决了"平行思考"策略中成本与性能的矛盾。
可以把它理解为给LLM的"思考"过程装上了一个质量监控器:
- 在离线 模式下,它像一个评审员,对已经完成的所有"答卷"进行打分和筛选,选出最好的答案。
- 在在线 模式下,它像一个监工,实时监控每一份"答卷"的写作过程,一旦发现写得"磕磕巴巴"、"信心不足",就立刻让它停笔,避免浪费时间。
这项工作为如何更经济、更有效地利用LLM的推理能力提供了一个极具实践价值的范例,展示了"测试时压缩(test-time compression)"作为一种实用且可扩展的解决方案的巨大潜力。
From Selection to Generation: A Survey of LLM-based Active Learning
主动学习 (Active Learning, AL)
- 在监督学习任务上,通常需要大量的高质量标注才能让模型达到比较好的性能。Active Learning是希望通过最小数量的标注,解决模型的性能瓶颈:比如长尾数据拟合不好的问题,部分数据预测精度较差的问题。
- 对于模型而言有两类数据价值比较高:
- 不确定性(Uncertainty)------模型最没把握的
- 多样性(Diversity)------覆盖数据空间的不同区域
传统AL的无标注数据挑选策略
-
传统AL的挑选:它是一个量化、计算驱动的过程。模型扮演的是一个"计算器"的角色,通过数学公式计算出每个样本的"不确定性分数"或"多样性分数",然后按分数高低进行排序和挑选。
-
基于不确定性的挑选策略 (Uncertainty-based):这是最主流的一类方法,核心思想是"挑模型最没把握的"。因为模型最没把握的样本,往往位于决策边界附近,学习它们能最快地帮助模型明确边界。
- 最小置信度 (Least Confidence):实现: 对于一个样本,模型会预测它属于各个类别的概率。比如对于一个三分类问题,预测结果可能是 0.4, 0.3, 0.3。我们取其中最高的那个概率值(这里是0.4),这个值就是模型的"置信度"。置信度越低,说明模型越不确定。挑选: 挑选出所有未标注样本中,置信度最低的那个(或一批)。
- 边际采样 (Margin Sampling):实现: 还是上面的例子 0.4, 0.3, 0.3。我们看概率最高和次高的两个值,计算它们的差值(0.4 - 0.3 = 0.1)。这个差值就是"边际(margin)"。边际越小,说明模型在两个最可能的选项之间越纠结。挑选: 挑选出边际最小的那个样本。
- 最大熵 (Max-Entropy): 实现: 熵(Entropy)是信息论中衡量不确定性的指标。一个概率分布越"平坦",熵就越大,代表不确定性越高。对于 0.4, 0.3, 0.3,其熵就比 0.9, 0.05, 0.05 要高得多。挑选: 计算每个样本预测概率分布的熵,挑选出熵最大的那个。
- 委员会查询 (Query-By-Committee, QBC):实现: 训练多个(一个"委员会")结构或初始化不同的模型。让这个委员会的所有模型对同一个样本进行预测。如果它们的预测结果分歧很大,说明这个样本很有争议,很有价值。挑选: 挑选出委员会成员分歧最大的样本。
-
基于多样性的挑选策略 (Diversity-based):这类方法旨在确保挑选出的样本能够覆盖数据空间的不同区域,避免挑出来的样本都挤在一个小角落里,从而提高模型的泛化能力。
- 核心集方法 (Core-Set):实现: 目标是挑选出一小批样本,使得这一小批样本能够"代表"整个未标注数据池。这可以被看作一个设施选址问题:选择k个点,使得所有其他点到这k个点的距离之和最小。挑选: 通常将样本表示为特征向量,然后使用聚类或几何算法(如贪婪的"最远优先"遍历)来挑选出能够最好地覆盖整个特征空间的样本。
LLM的无标注数据挑选策略
- LLM的挑选方式主要依赖于其强大的上下文理解和推理能力,通常通过精心设计的**提示(Prompting)**来实现。
- 挑选&生成&标注能力兼备:不仅可以挑选出符合要求的无标注数据,还可以根据元数据样例生成标注数据,以及给无标注数据打标。(为了避免LLM的bias或者幻觉,也可以LLM初标,人工校验,加快速度)
AL 作用于LLM几类后训练(ICL, SFT, 偏好对齐,知识蒸馏)
Active In-Context Learning
- ICL format:指令 + 范例1:输入-\>输出 + 范例2:输入-\>输出 + ... + 新问题:输入-\>?。
- 核心问题: 提示长度是有限的(比如只能放8个范例),应该挑选哪8个范例放入提示中,才能让LLM在回答新问题时表现得最好?
- 挑选方法:
- 相似度采样:最大化范例与新问题的相关性,
- 如何实现:将新问题和候选池里所有的样本用编码器转换成向量,得到cosine距离最近的top-k个样本作为范例。
- 直观理解:给LLM看和当前问题最像的例子,能最直接地激活它处理这类问题的能力。这是目前被证明在ICL中最简单且有效的方法之一。
- 核心集选择 (Core-Set Selection) / 语义覆盖 (Semantic Coverage):最大化示例的多样性与覆盖度 (Maximizing Diversity & Coverage)
- 如何实现:使用聚类算法先将所有样本聚成k类,然后从每个类的中心挑选一个样本。避免选出的范例都太相似。
- 直观理解:比如都是关于"头痛"的,通过展示不同类型的"药物不良反应"(如头痛、皮疹、恶心),让LLM了解这个任务的全貌,从而提高泛化能力。CoverICL (Mavromatis et al., 2024) 就是这个思路的代表。
- 不确定性/模糊性采样:选择模型最"需要"学习的示例
- 如何实现:对于一个新问题,先尝试用不同的范例组合来让LLM回答。观察LLM的输出。如果用不同的范例组合,LLM给出的答案摇摆不定、分歧很大,这说明当前问题对于LLM来说是"模糊的"。此时,主动学习的目标就变成了去候选池里寻找那些能最大程度减少这种模糊性的范例。
- 直观理解: "诊断"出LLM在面对当前问题时的"知识盲区",然后有针对性地提供能"答疑解惑"的范例。
- 相似度采样:最大化范例与新问题的相关性,
Active SFT
- 目的是最小化昂贵的人工标注成本
- 方法:用大模型/能力更强的模型去标注最不确定的数据---用于人类标注,最确定的数据用于巩固加强(高置信度伪标签),训练模型。
- Q:高置信度伪标签在训练时的用法?
- A:
- 将伪标签视为真实标签,和真实标签用法一样;
- 承认伪标签的不可靠性,通过策略来控制其影响、最大化其价值。
- 损失加权: 降低伪标签数据的损失权重。 T o t a l _ L o s s = L o s s _ h u m a n + α ∗ L o s s _ p s e u d o Total\_Loss = Loss\_human + α * Loss\_pseudo Total_Loss=Loss_human+α∗Loss_pseudo,其中α (0 < α < 1),直观理解:老师(人工标签)说的话要全信,同学(伪标签)说的参考一下。
- 一致性正则化: 利用数据增强来强迫模型学习不变性。
- 课程学习: 逐步、有选择地引入伪标签。
- 标签修正: 动态更新和提纯伪标签。
Active preference alignment
- 确保LLM的回答"有用、诚实、无害",需要大量的偏好数据,即对于一个问题,给出两个或多个回答,然后由人类标注哪个更好。但是这一类偏好数据问题的收集成本高昂。
- 主动学习如何解决?让模型主动提问,只询问那些最有争议或最不确定的回答对"偏好对",以最高效地对齐模型。比如,对于问题A,模型生成了两个回答 y1 和 y2,模型自己觉得 y1 比 y2 好的概率是51%,非常接近50%。这就意味着模型极度不确定。那么对于这一类数据辅助人工偏好,能给模型带来最大的信息增益,
- 总结:从被动接受标注好的偏好数据,到主动根据不确定性选择数据,优化了标注效率。
Active knowledge Distillation
- 主动选择对学生模型最有帮助的知识进行蒸馏。
- 具体做法 (论文引用的工作):
- Zhang et al. (2024c): 提出ELAD,它在蒸馏过程中会关注学生模型的"不确定性"。对于学生模型不确定的样本,会请求教师模型给出更详细的"解释(explanation)",然后用这些解释来指导学生学习,而不仅仅是最终答案。
- Liu et al. (2024): 提出EvoKD,这是一个迭代策略。它首先识别出学生模型的"弱点"(在哪些数据上表现不好),然后让教师模型(LLM)动态地生成针对这些弱点的新数据和标签,从而持续地"补强"学生模型。
- Palo et al. (2024): 提出PGKD,这是一个主动反馈循环,利用"难例挖掘(hard-negative mining)"等性能信号来指导教师模型生成新的数据,从而提升蒸馏效率。