当我们谈论"内存泄漏"时,我们可能找错了方向
想象一个监控面板:你的微服务在Kubernetes集群中运行,Prometheus显示容器内存使用率稳步上升,72小时后触发OOMKilled。你检查了所有new/malloc调用,使用了Valgrind,甚至重写了所有智能指针------但问题依然存在。
因为你找错了地方。
现代软件的资源泄漏早已不是"忘记delete"那么简单。它是一个多维度的复杂系统故障,涉及从用户态到内核态、从CPU缓存行到GPU显存、从语言运行时到操作系统的完整堆栈。当我们还在用20年前的思维寻找"丢失的堆块"时,真正的吞噬者正在系统的其他层次悄然生长。
第一部分:资源管理的九层架构
层级1:应用堆内存(最易察觉的显性泄漏)
特征 :进程私有工作集增长,malloc_trim无效
检测:AddressSanitizer, Valgrind, tcmalloc堆分析器
盲点:内存池内部碎片、大页未回收、jemalloc arena泄漏
cpp
// 典型但已过时的例子
void leak_memory() {
auto* data = new char[1024]; // 太明显了
// 现代泄漏更隐蔽:
static std::vector<std::unique_ptr<Resource>> cache;
cache.push_back(std::move(resource)); // "缓存"成为无限增长的坟墓
}层级2:系统调用边界(跨特权级的内存泄漏)
brk/sbrk已死,mmap当立 :现代分配器更多使用mmap直接获取内存,泄漏表现为:
-
MAP_ANONYMOUS映射未munmap -
文件映射
MAP_SHARED持久化 -
透明大页(THP)的碎片化保留
bash
# 查看进程的mmap泄漏
cat /proc/$(pidof yourapp)/maps | grep "deleted" # 已删除文件的内存映射
pmap -x $(pidof yourapp) | grep "anon" # 匿名映射区域层级3:被忽视的文件描述符问题
不仅是open/close:
c
// 容易被忽略的FD泄漏源
socket(AF_INET, SOCK_STREAM, 0); // 网络
eventfd(0, EFD_SEMAPHORE); // 事件通知
timerfd_create(CLOCK_MONOTONIC, 0); // 定时器
signalfd(-1, &mask, SFD_CLOEXEC); // 信号
inotify_init(); // 文件监控
epoll_create1(0); // epoll实例自身也是FDLinux特有的泄漏链 :fork() without exec()继承所有FD,子进程成为FD僵尸。
层级4:内核对象泄漏(以Windows系统为例)
GDI/USER只是冰山一角:
| 对象类型 | 创建API | 泄漏后果 |
|---|---|---|
| 作业对象 | CreateJobObject | 进程控制失效 |
| 令牌 | CreateRestrictedToken | 安全上下文累积 |
| 事务 | CreateTransaction | 文件系统锁定 |
| 命名管道 | CreateNamedPipe | 进程通信阻塞 |
| 完成端口 | CreateIoCompletionPort | I/O系统停滞 |
| 注册表键 | RegCreateKeyEx | 注册表空间耗尽 |
层级5:图形子系统中GPU显存的泄漏
DirectX 12/Vulkan的显式内存管理:
cpp
// 每一行都可能泄漏,且工具难以检测
D3D12_HEAP_PROPERTIES heapProps = {};
D3D12_RESOURCE_DESC resDesc = {};
ComPtr<ID3D12Resource> resource;
// 1. 资源泄漏
device->CreateCommittedResource(&heapProps, D3D12_HEAP_FLAG_NONE,
&resDesc, D3D12_RESOURCE_STATE_COMMON,
nullptr, IID_PPV_ARGS(&resource));
// 忘记释放resource
// 2. 描述符泄漏(更隐蔽)
D3D12_CPU_DESCRIPTOR_HANDLE handle =
descriptorHeap->GetCPUDescriptorHandleForHeapStart();
// 描述符堆中的槽位永久占用
// 3. 命令分配器泄漏
device->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT,
IID_PPV_ARGS(&allocator));
// GPU异步操作引用计数复杂层级6:虚拟机中的语言运行时泄漏
.NET的复杂对象图泄漏:
csharp
// 事件处理器:经典的根引用保持
public class EventSource {
public event EventHandler SomethingHappened;
}
public class Subscriber {
public void Subscribe(EventSource source) {
source.SomethingHappened += OnSomething; // 隐式强引用
}
// 即使Subscriber被"销毁",事件链仍保持引用
}
// WPF特有的泄漏模式
BindingOperations.SetBinding(element, prop, binding);
// 未清除的绑定保持整个Visual树存活
// AsyncLocal<T>:线程静态的分布式泄漏
private static AsyncLocal<Dictionary<string, object>> _context
= new AsyncLocal<Dictionary<string, object>>();
// 异步流中持续累积Java的Metaspace/堆外泄漏:
java
// 1. 堆外内存(sun.misc.Unsafe)
long address = unsafe.allocateMemory(1024 * 1024);
// 忘记unsafe.freeMemory(address);
// 2. 内存映射文件
MappedByteBuffer buffer = fileChannel.map(MapMode.READ_WRITE, 0, size);
// GC不管理MappedByteBuffer,需等待Cleaner
// 3. JNI全局引用
jobject globalRef = env->NewGlobalRef(localRef);
env->DeleteGlobalRef(globalRef); // 忘记调用
// 4. 线程局部累积
ThreadLocal<List<byte[]>> threadData = new ThreadLocal<>();
threadData.set(new ArrayList<>());
threadData.get().add(new byte[1024]); // 线程池复用导致累积层级7:容器化环境放大泄漏
Docker/Kubernetes的层叠效应:
yaml
# 容器内看到的"正常"可能只是假象
memory:
# 控制组(cgroup)的多层次限制
memory.limit_in_bytes: 1G
memory.kmem.limit_in_bytes: 1.5G # 内核内存独立配额
memory.kmem.tcp.limit_in_bytes: 500M # TCP缓冲区
# 泄漏场景:
# 1. 内核内存泄漏绕过容器限制
# 2. 多个容器共享主机内核资源
# 3. 容器重启不释放kmem层级8:分布式系统中跨服务的级联泄漏
微服务间的资源纠缠:
go
// Go例:HTTP客户端连接池泄漏
func makeRequest() {
client := &http.Client{
Timeout: 30 * time.Second,
Transport: &http.Transport{
MaxIdleConns: 100,
MaxConnsPerHost: 10,
IdleConnTimeout: 90 * time.Second,
},
}
// 每个请求创建新client,连接池永不释放
resp, _ := client.Get("http://service-b")
defer resp.Body.Close() // 但Transport本身泄漏
}
// gRPC流未正确关闭
stream, err := client.Chat(context.Background())
for {
msg, err := stream.Recv()
// 网络中断后,服务端仍保持流状态
}层级9:硬件抽象层的"隐性泄漏"
CPU缓存污染:
cpp
// 伪共享导致的"性能泄漏"
struct alignas(64) PaddedCounter { // 缓存行对齐
std::atomic<int64_t> value;
char padding[64 - sizeof(std::atomic<int64_t>)];
};
// 非对齐访问导致缓存行无效化,虽不占内存但耗带宽GPU内存的异步泄漏:
python
# PyTorch/TensorFlow的CUDA内存管理
import torch
x = torch.randn(1024, 1024).cuda()
del x # Python引用释放
# CUDA上下文可能仍持有内存,需显式清理
torch.cuda.empty_cache() # 开发者常忘记第二部分:诊断方法论------从现象到根源的排查路径
诊断决策树:快速定位泄漏类型
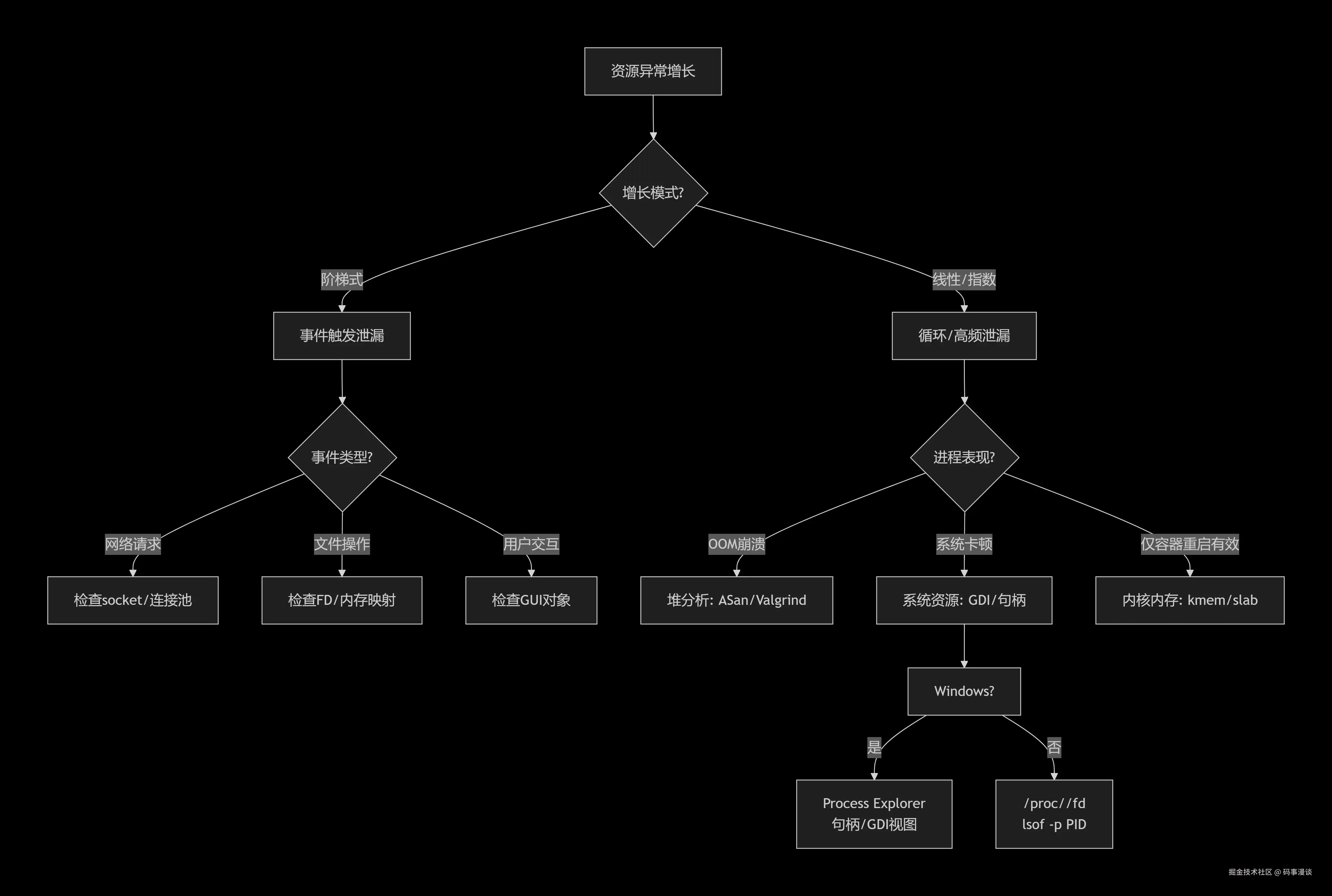
多工具联合诊断
bash
# 1. 基础三件套
top -p $(pidof app) # 实时RSS/VIRT
cat /proc/$(pidof app)/status # 详细统计
pmap -X $(pidof app) # 内存区域分布
# 2. 进阶组合拳
# 同时监控不同层级
(while true; do
date
# 用户空间
ps -o rss,vsz,pcpu -p $(pidof app)
# 内核空间
grep -E "(KernelStack|VmallocUsed|Slab)" /proc/meminfo
# 容器视角
docker stats --no-stream container_id
sleep 5
done) | tee -a monitor.log
# 3. 压力测试+实时分析
stress-ng --vm 2 --vm-bytes 1G & # 制造内存压力
perf record -e page-faults,kmem:kmalloc,kmem:kfree -p $(pidof app)Windows系统专项诊断:内核与用户态结合
powershell
# 1. 系统级监控
Get-Counter '\Process(*)\Handle Count' -Continuous |
Where-Object {$_.InstanceName -eq 'yourapp'}
# 2. GDI/USER对象分类统计
# 使用GDIView或自定义ETW监听
logman start GDITrace -p {8D98D946-795F-48F4-A2C3-1C7220935B00} -o gdi.etl
# 3. 内核池分析
poolmon.exe -p -b # 按标签排序池使用
# 查找异常增长的标签第三部分:从被动修复到主动防御的治理体系
架构层面的防御模式:从根源减少泄漏
cpp
// 模式1:资源所有权的类型系统强化
template<typename T>
class Owned {
T* ptr;
public:
explicit Owned(T* p) : ptr(p) {}
~Owned() { delete ptr; }
// 删除拷贝,强制移动语义
Owned(const Owned&) = delete;
Owned& operator=(const Owned&) = delete;
Owned(Owned&& other) noexcept : ptr(other.ptr) {
other.ptr = nullptr;
}
};
// 编译器保证资源释放
void process() {
Owned<Resource> res(new Resource()); // 栈展开保证析构
// 即使异常抛出也会释放
}
// 模式2:基于作用域的自动清理
class ScopeGuard {
std::function<void()> cleanup;
public:
template<typename F>
ScopeGuard(F&& f) : cleanup(std::forward<F>(f)) {}
~ScopeGuard() {
if (cleanup) cleanup();
}
void dismiss() { cleanup = nullptr; }
};
void risky_operation() {
HANDLE hFile = CreateFile(...);
ScopeGuard guard([hFile] { CloseHandle(hFile); });
// 复杂操作...
if (success) guard.dismiss(); // 手动转移所有权
}CI/CD集成:将泄漏检测嵌入研发流程
yaml
stages:
- static_analysis
- unit_testing
- integration_test
- stress_test
- production_canary
static_analysis:
stage: static_analysis
script:
- clang-tidy --checks='clang-analyzer-unix.Malloc,clang-analyzer-cplusplus.NewDelete'
# 自定义规则检测资源管理模式
- python scripts/detect_resource_patterns.py
resource_leak_detection:
stage: integration_test
script:
# 多维度监控框架
- python scripts/monitor_framework.py \
--metrics=rss,handles,gdi_objects,fd_count \
--thresholds="rss:100MB/24h,handles:5000" \
--application="./app --test-mode"
artifacts:
paths:
- resource_report.html
- leak_suspects.json
canary_deployment:
stage: production_canary
script:
# 金丝雀环境部署,实时监控资源
- kubectl apply -f canary-deployment.yaml
- python scripts/canary_monitor.py \
--namespace=canary \
--alert-slack="#alerts"运行时自愈:系统级的动态防护
go
// Go实现的资源守护进程
type ResourceGuard struct {
maxHandles int
maxMemoryMB int
checkInterval time.Duration
metricsChan chan ResourceMetrics
}
func (g *ResourceGuard) Monitor() {
ticker := time.NewTicker(g.checkInterval)
defer ticker.Stop()
for {
select {
case <-ticker.C:
metrics := g.collectMetrics()
g.metricsChan <- metrics
if metrics.Handles > g.maxHandles * 0.8 {
g.logAndAlert("Handle接近上限", metrics)
g.initiateCleanup()
}
if metrics.RSSMB > g.maxMemoryMB * 0.9 {
g.logAndAlert("内存压力预警", metrics)
g.releaseCaches() // 自动释放缓存
}
}
}
}
// 自动清理策略
func (g *ResourceGuard) initiateCleanup() {
// 1. 尝试优雅清理
g.forceGC()
g.clearInternalCaches()
// 2. 渐进式降级
if stillCritical() {
g.disableNonCriticalFeatures()
}
// 3. 最后手段:有状态重启
if emergency() {
g.snapshotState()
g.gracefulRestart()
}
}结论
资源泄漏的本质是软件系统中熵的增加------从有序的资源管理状态向无序的混沌状态演变。每一层抽象都在增加泄漏的可能性,每一个优化都可能隐藏新的泄漏模式。
核心洞察:
-
泄漏是分形的:在不同层级表现出相似但不同的模式
-
工具是层级绑定的:没有银弹工具,只有工具链
-
预防优于检测:架构设计时考虑资源生命周期
-
监控需要立体化:从应用指标到系统指标到硬件指标
未来的研究方向应关注:
-
形式化验证的资源安全证明
-
机器学习辅助的异常模式识别
-
硬件辅助的泄漏检测(如Intel MPX、ARM MTE)
-
跨层级的统一资源管理模型
在这个每增加一层抽象就可能引入一类新泄漏的时代,真正的专业不是知道如何修复泄漏,而是设计出让泄漏难以发生的系统。资源安全不是功能完成后才考虑的问题,而是架构设计的第一性原则。