目录
[一、 数据分析流程](#一、 数据分析流程)
[1. 数据的导入(pd.read_csv(【文件名】)) 和 导出(pd.to_csv(【文件名】))](#1. 数据的导入(pd.read_csv(【文件名】)) 和 导出(pd.to_csv(【文件名】)))
[2. json 数据的读取](#2. json 数据的读取)
[3. 缺失值的处理](#3. 缺失值的处理)
[4. 剔除缺失值](#4. 剔除缺失值)
[5. 填充缺失值](#5. 填充缺失值)
[6. 数据类型转换](#6. 数据类型转换)
[7. 数据变形](#7. 数据变形)
[8. 数据分列](#8. 数据分列)
[9. 数据分箱](#9. 数据分箱)
[10. 时间数据的处理](#10. 时间数据的处理)
[11. 分组聚合](#11. 分组聚合)
[总结不易~ 本章节对我有很大的收获, 希望对你也是!!!](#总结不易~ 本章节对我有很大的收获, 希望对你也是!!!)
一、 数据分析流程
1. 数据的导入(pd.read_csv(【文件名】)) 和 导出(pd.to_csv(【文件名】))
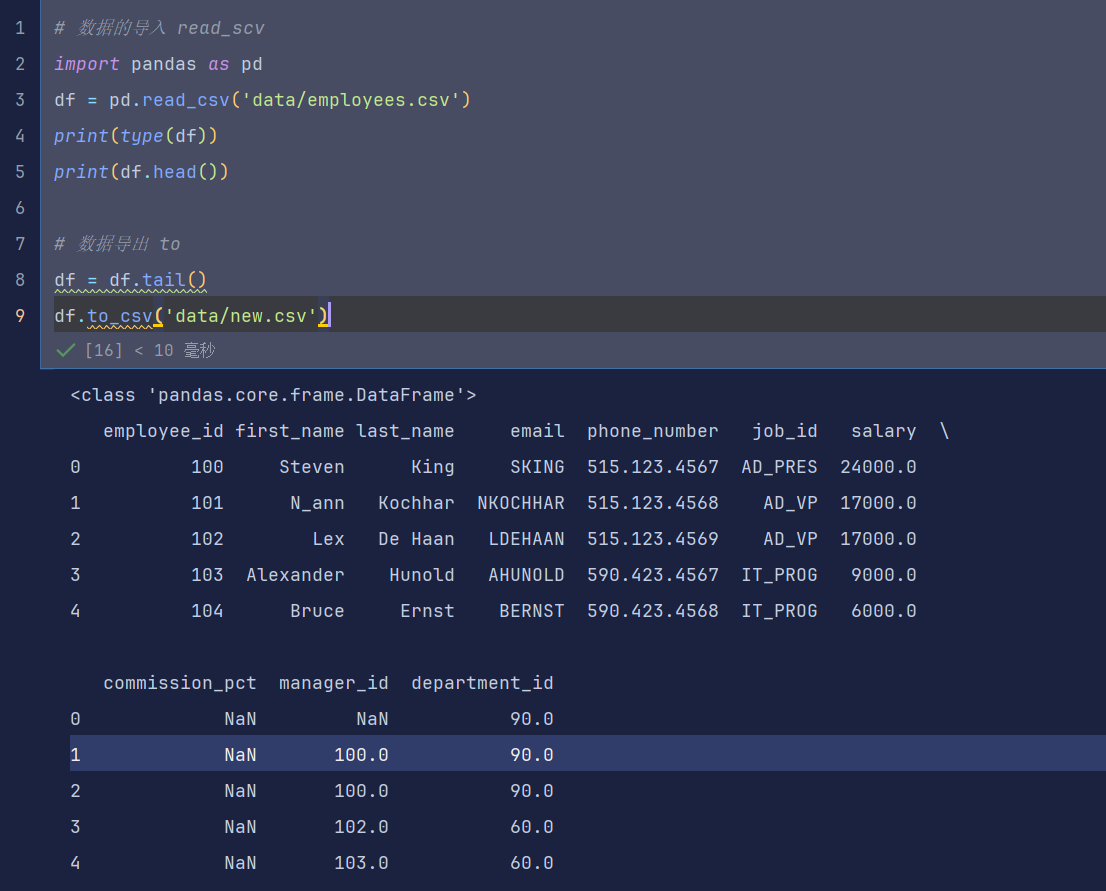
2. json 数据的读取
python
# json数据
df = pd.read_csv('data/data1.json')
print(df, type(df))
df
如果json数据 读取有问题 那么就先将json文件数据读入字典里 再重新用pd.DataFrame 来进行读出
import json
with open('data/test.json') as f:
data = json.load(f) # json.load 将json文件数据 先读到字典里
print(data)
print(type(data))
df = pd.DataFrame(data['users'])
df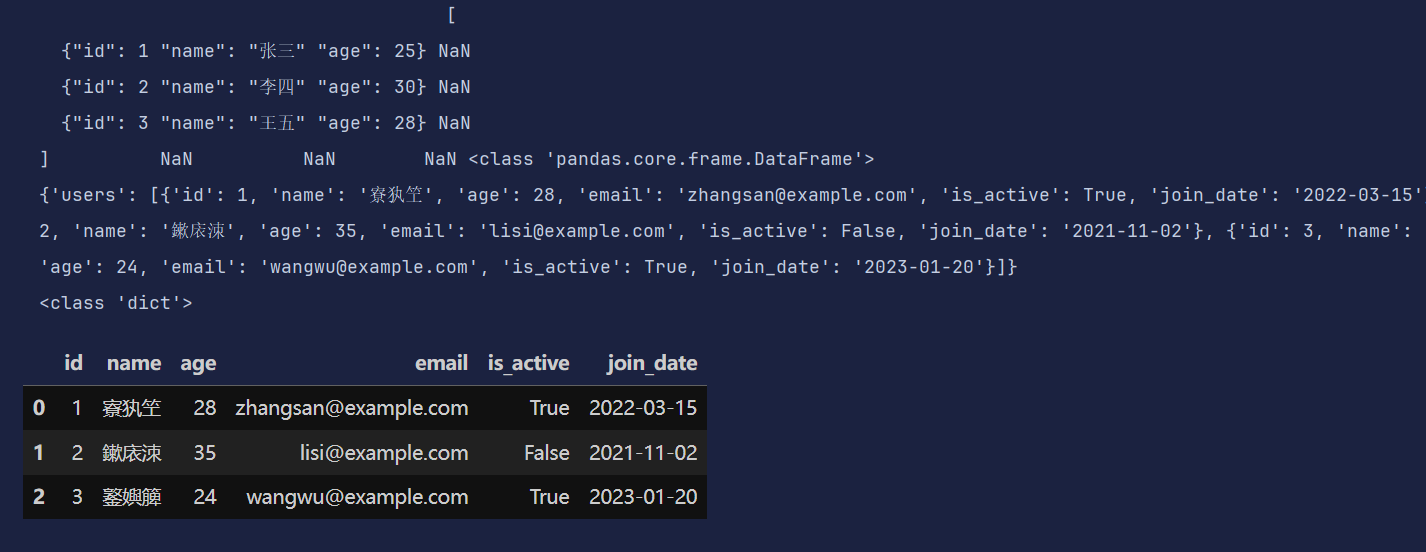
3. 缺失值的处理
python
# 缺失值的处理
import numpy as np
import pandas as pd
import json
s = pd.Series([1, 2, np.nan, None, pd.NA])
# print(s)
# 监测 是否是缺失值
# print(s.isna())
# print(s.isnull())
df = pd.DataFrame([[1, pd.NA, 2], [2, 3, 5], [None, 4, 6]])
df
# print(df.isna()) # 查看是否是缺失值
print(df.isna().sum(axis=1)) # 查看缺失值的个数 默认表示的是列索引 在sum内axis=1 表示计算行缺失值的个数
print(s.isna().sum())
4. 剔除缺失值
python
# 剔除缺失值
print(s.dropna())
print(df)
print('-'*30)
print(df.dropna()) # 只要该行有缺失值 就直接删除一行
print('-'*30)
print(df.dropna(how='all')) # 如果所有的值都是缺失值 删除这一行
print('-'*30)
print(df.dropna(thresh=2)) # 如果至少有n个值不是缺失值 就保留
print('-'*30)
print('@',df.dropna(subset=[1])) # 如果某列有缺失值 则删除这一行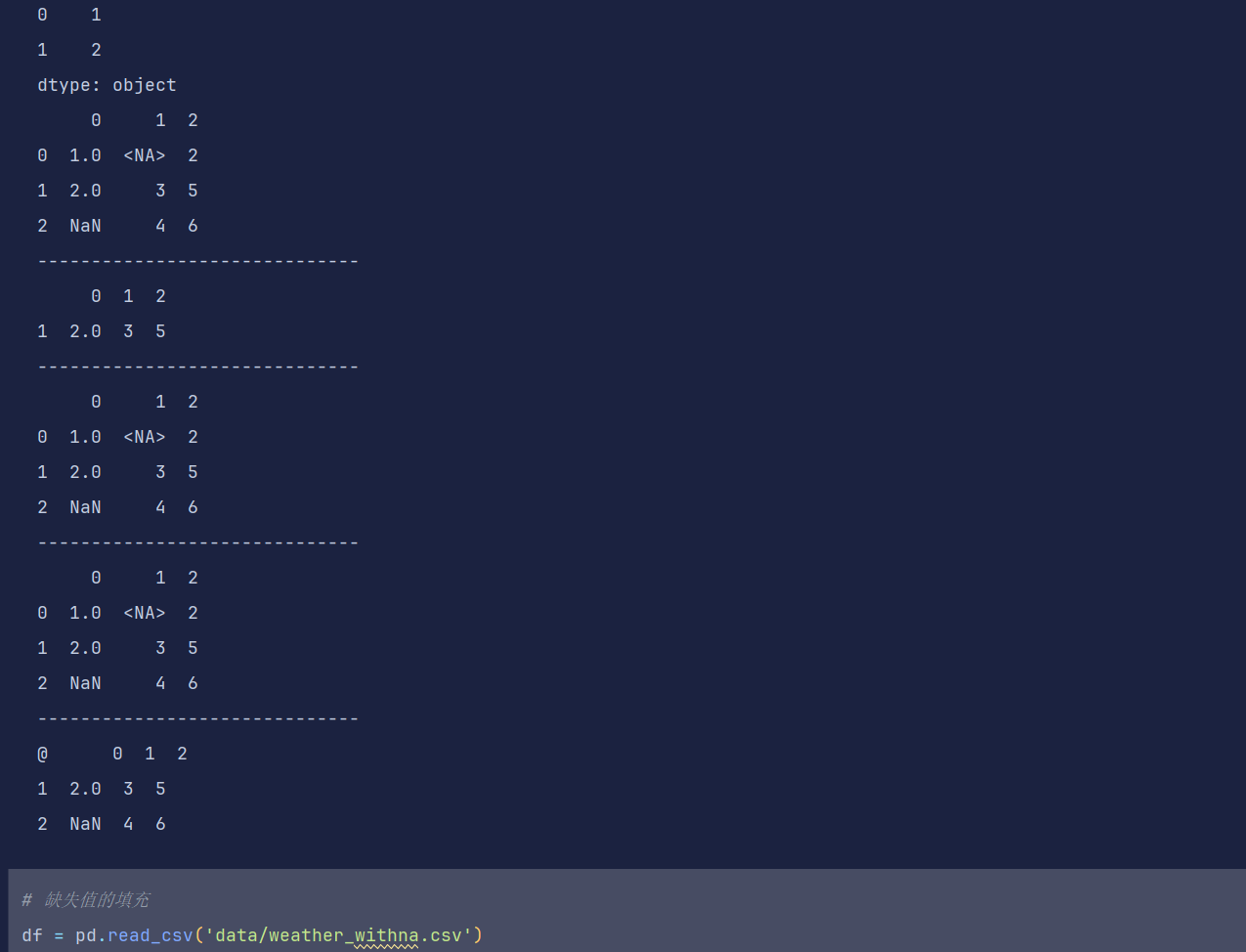
5. 填充缺失值
python
# 缺失值的填充
df = pd.read_csv('data/weather_withna.csv')
df.tail()
df.isna().sum()
df.head()
# 使用字典来填充
print(df.fillna({'temp_max':20, 'wind': 2.5}))
print(df.fillna(df[['wind']].mean()).tail()) # 使用统计值来填充
print(df.ffill().tail()) # 使用前面的值来进行填充
print(df.bfill().tail()) # 使用后面的值来进行填充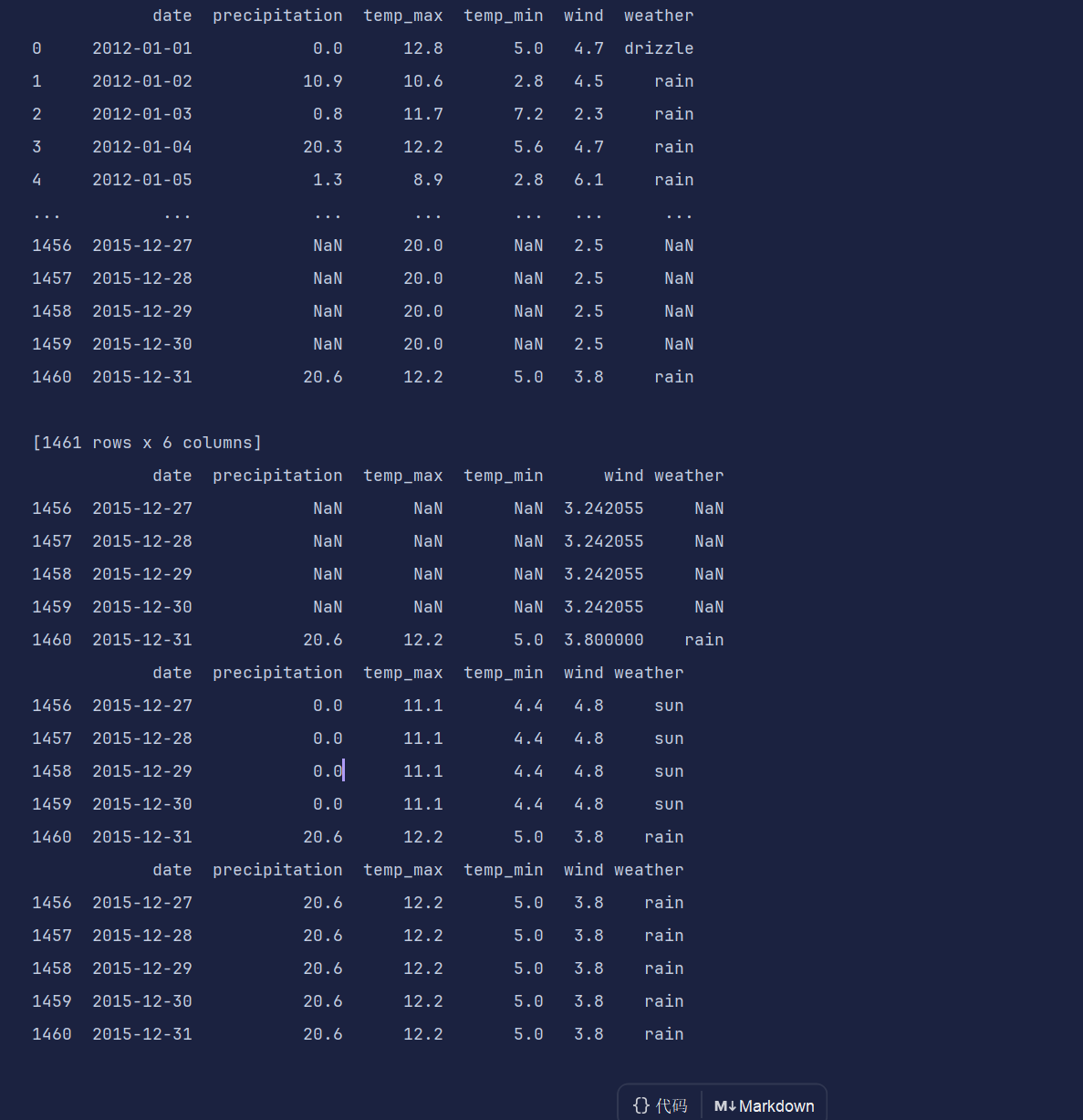
6. 数据类型转换
python
import pandas as pd
data = {
"name":["alice",'alice','bob','alice','jack','bob'],
"age":[26,25,30,25,35,30],
"city":['NY','NY','LA','NY','SF','LA']
}
df = pd.DataFrame(data)
df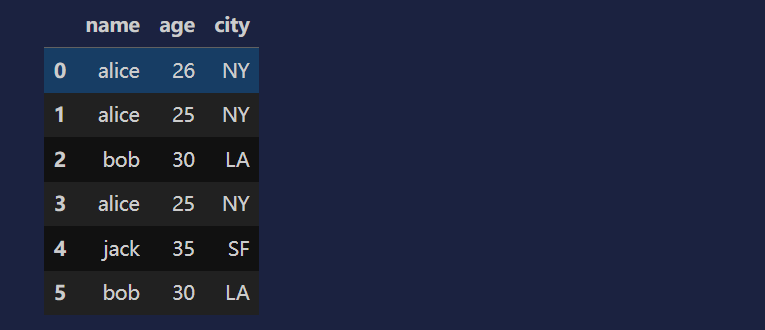
python
df.duplicated() # 一整条记录都是一样的 才会标记成重复 true
df.drop_duplicates(subset=['name']) # 去重
df.drop_duplicates(subset=['name'], keep='last') # keep 保留最后一次出现的行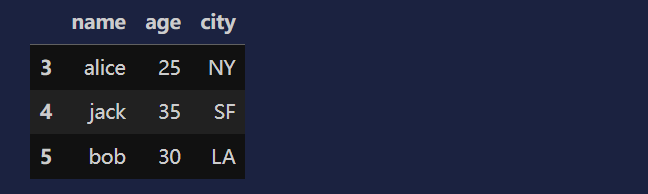
python
# 数据类型的转换
df = pd.read_csv('data/sleep.csv')
df.dtypes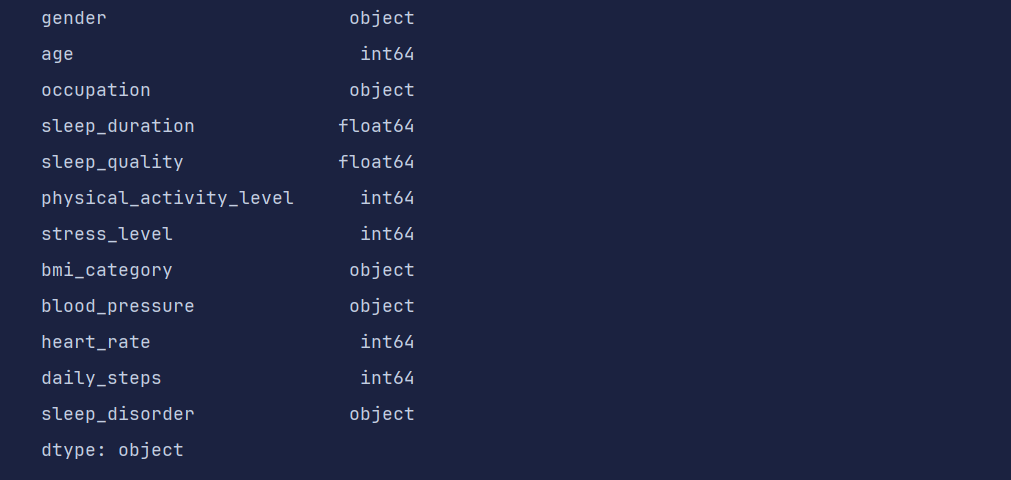
python
df['age'] = df['age'].astype('int16')
df.dtypes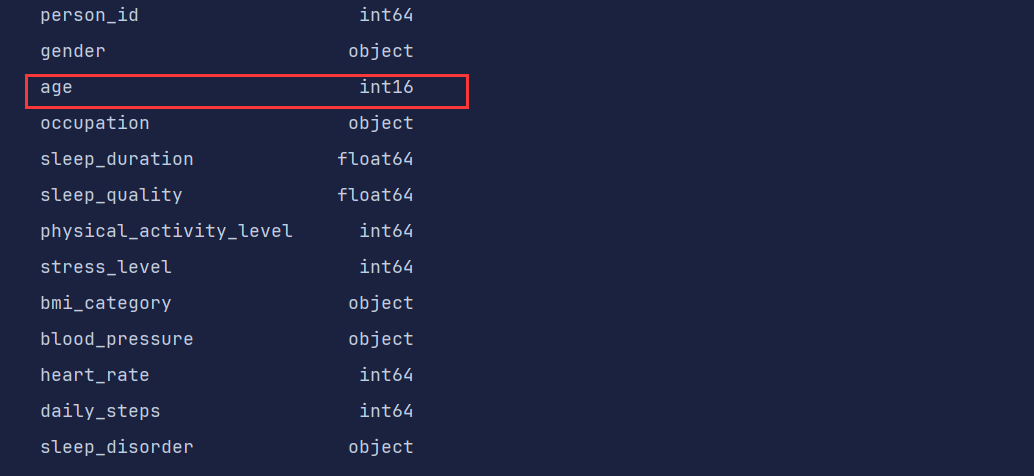
python
df['gender'] = df['gender'].astype('category') # 分类 类型 category
df.dtypes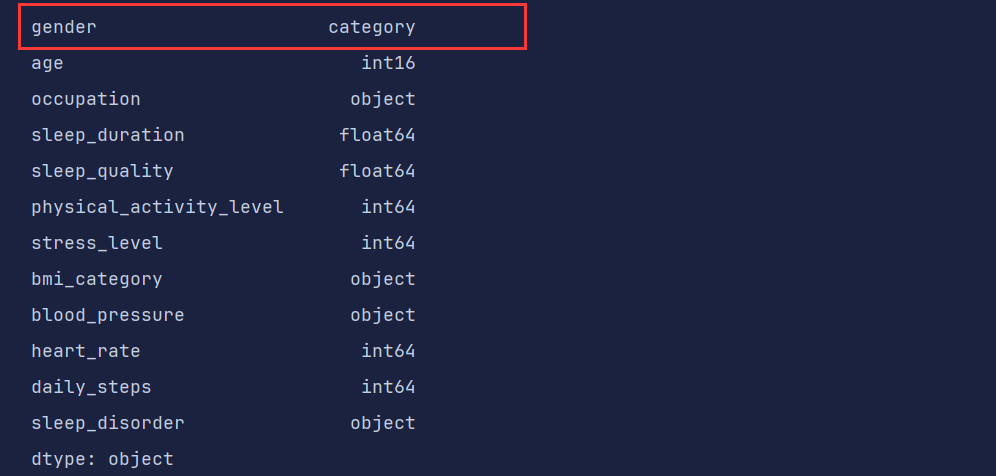
python
df['is_male'] = df['gender'].map({'Female':True, 'Male':False})
df.is_male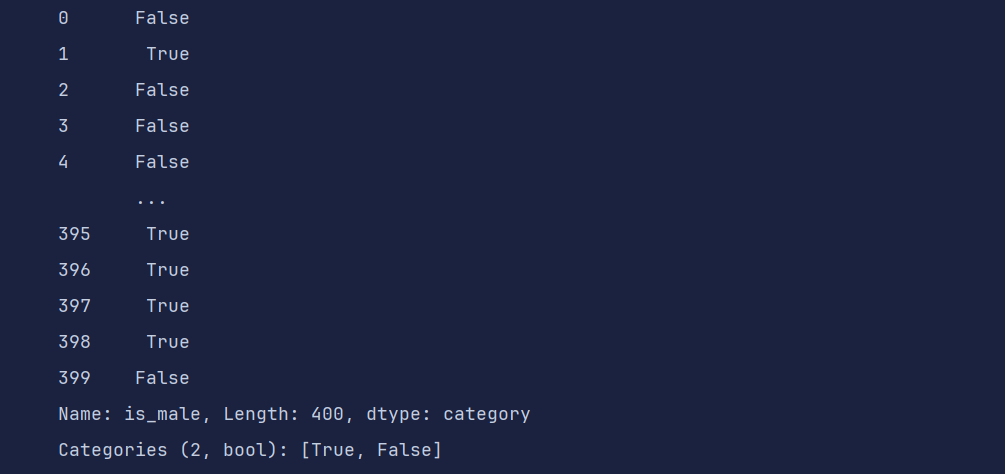
7. 数据变形
| 参数名 | 作用(通俗解释) | 对应原数据的部分 | 举例(你的代码) |
|---|---|---|---|
var_name |
给「原列名」整合后的列起名字 | 原宽表的列名(如 Math) | var_name='科目' → 生成「科目」列,存 Math/English 等 |
value_name |
给「原列值」整合后的列起名字 | 原宽表的单元格值(如 90) | value_name='分数' → 生成「分数」列,存 90/85 等 |
python
#数据变形
import pandas as pd
data = {
'ID': [1, 2],
'name':['alice','bob'],
'Math': [90, 85],
'English': [88, 92],
'Science': [95, 89]
}
df = pd.DataFrame(data)
df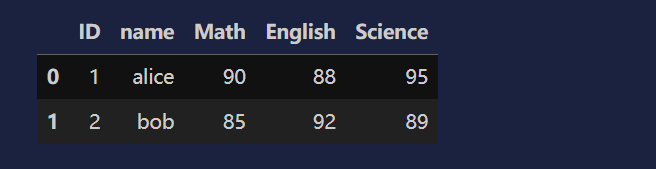
宽表转长表
python
df.T # 行列转置
df
# 1 alich math 90
# 1 alich english 88
# 1 alich science 95
# 宽表转换成 长表
df2 = pd.melt(df, id_vars=['ID', 'name'], var_name='科目', value_name='分数')
df2.sort_values('name')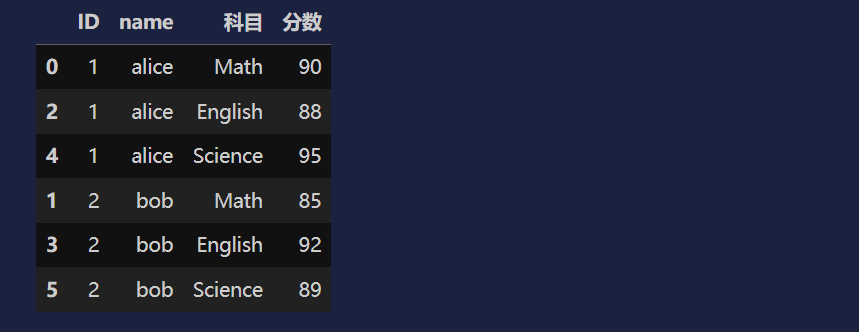
长表转宽表
python
# 长表转宽表
pd.pivot(df2, index=['ID', 'name'], columns='科目', values='分数')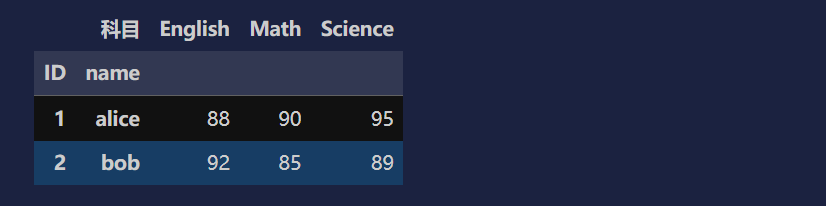
8. 数据分列
python
data = {
'ID': [1, 2],
'name':['alice smith','bob smith'],
'Math': [90, 85],
'English': [88, 92],
'Science': [95, 89]
}
df = pd.DataFrame(data)
# 分列
df[['first', 'last']] = df['name'].str.split(" ",expand=True) # expand=True 就是多列的意思
df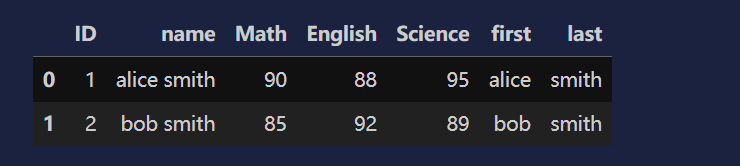
python
df = pd.read_csv('data/sleep.csv')
df = df[['person_id', 'blood_pressure']]
df[['high', 'low']] = df['blood_pressure'].str.split('/', expand=True) # 当前还是字符形式
df['high'] = df['high'].astype('int64')
df['low'] = df['low'].astype('int64')
df.info()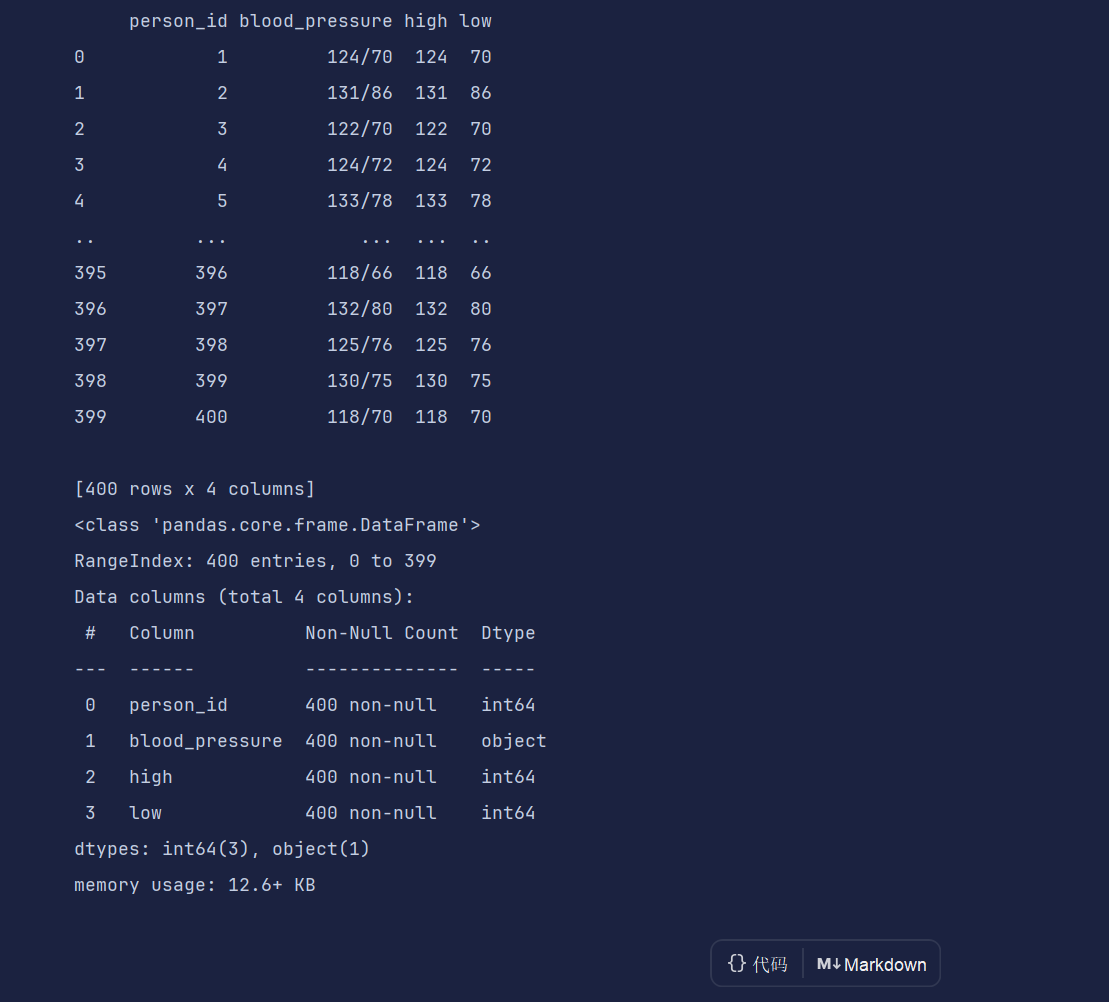
9. 数据分箱
python
# 数据分箱 pd.cut(x, bins, labels)
import pandas as pd
df = pd.read_csv('data/employees.csv')
df.head(10)
python
df1 = df.head(10)[['employee_id', 'salary']]
df1
python
# bins 分段 bins=2 分成两端 起始值和结束值的中位数
pd.cut(df1['salary'], bins=2)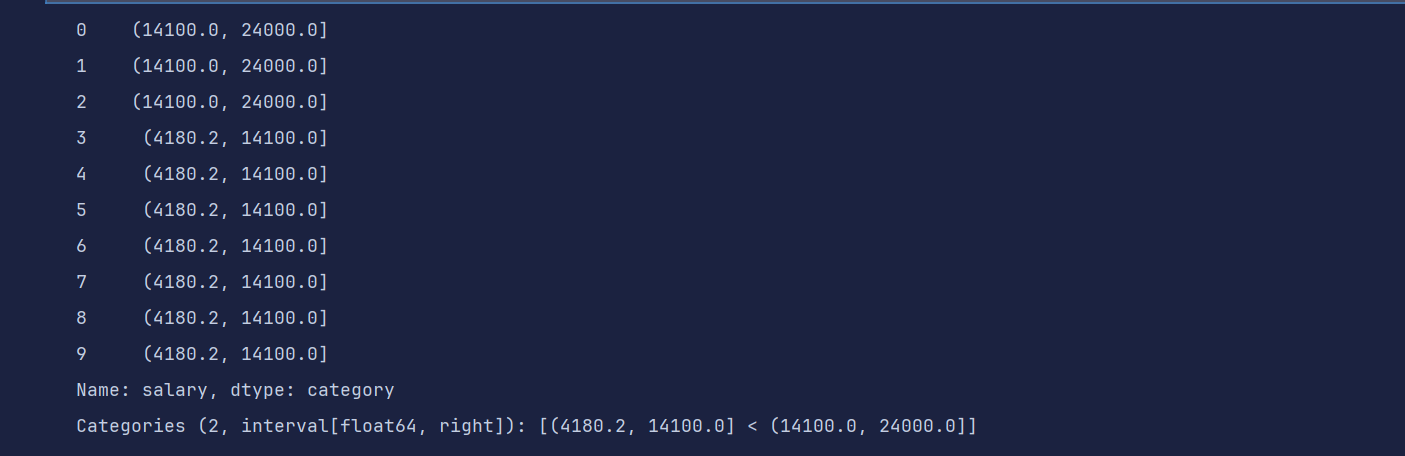
python
pd.cut(df1['salary'], bins=2).value_counts() # 计算每段的人数总数
python
pd.cut(df1['salary'], bins=[0, 10000, 20000, 30000]).value_counts() # bins 也可以自定义分段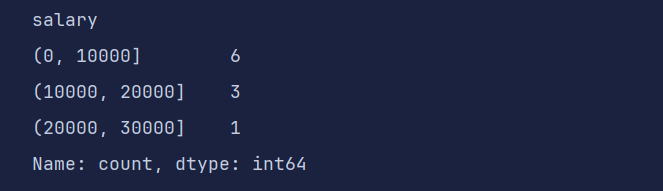
python
# labels 对范围进行标记
df1['收入范围'] = pd.cut(df1['salary'], bins=[0, 10000, 20000, 30000], labels=['低', '中', '高'])
df1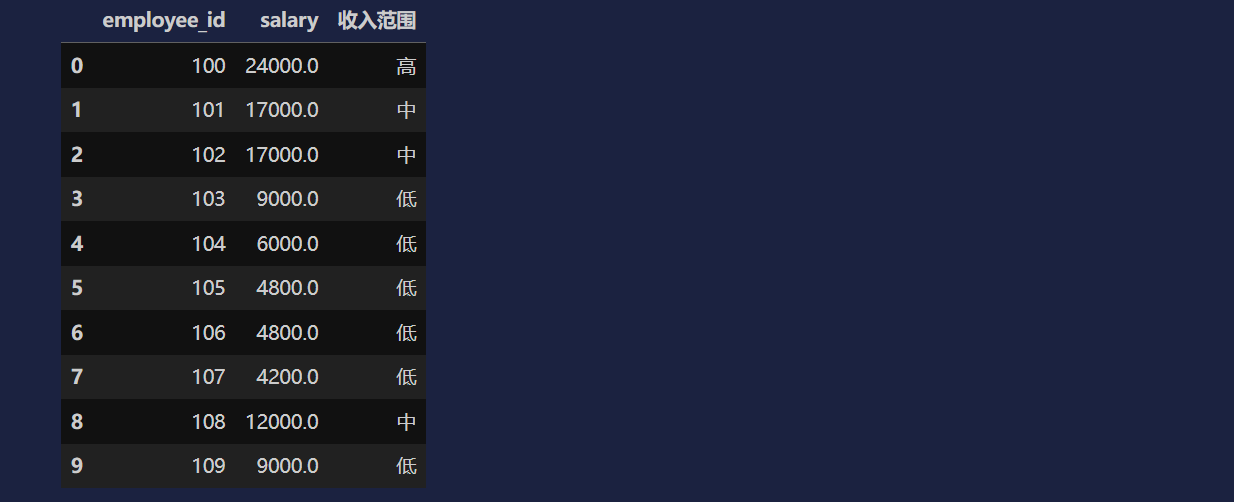
python
# qcut 进行等频率划分
pd.qcut(df1['salary'], 3).value_counts()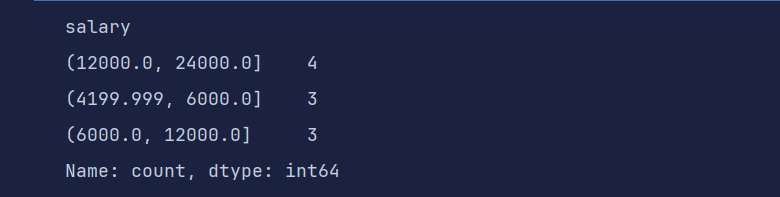
python
# 睡眠数据
df = pd.read_csv('data/sleep.csv')
df1 = df.head(10)[['person_id', 'sleep_quality']]
df1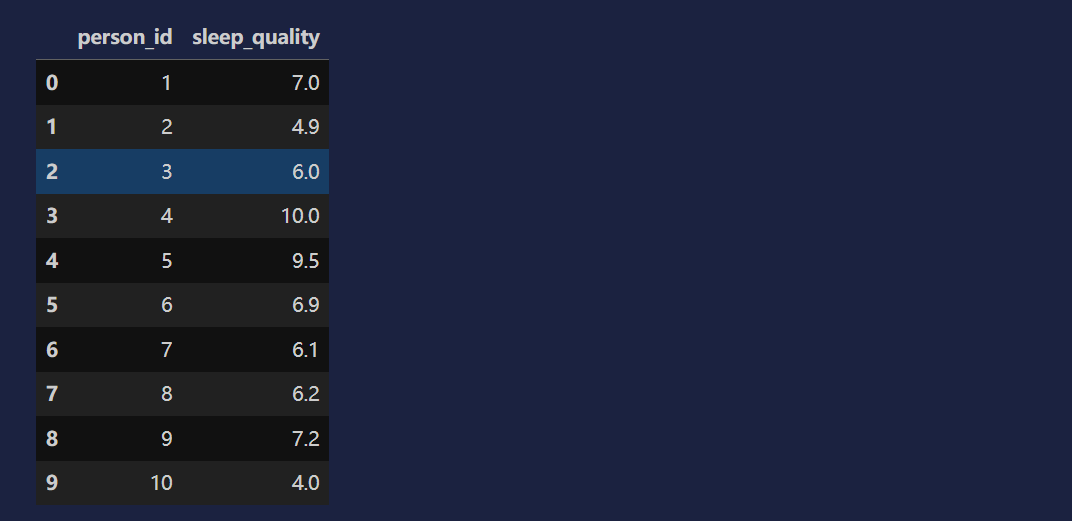
python
df['睡眠质量'] = pd.cut(df['sleep_quality'], bins=3, labels=['差', '中', '优'])
print(df1)
print(df['睡眠质量'].value_counts())
df['gender'] = df['gender'].astype('category')
print(df['gender'].value_counts())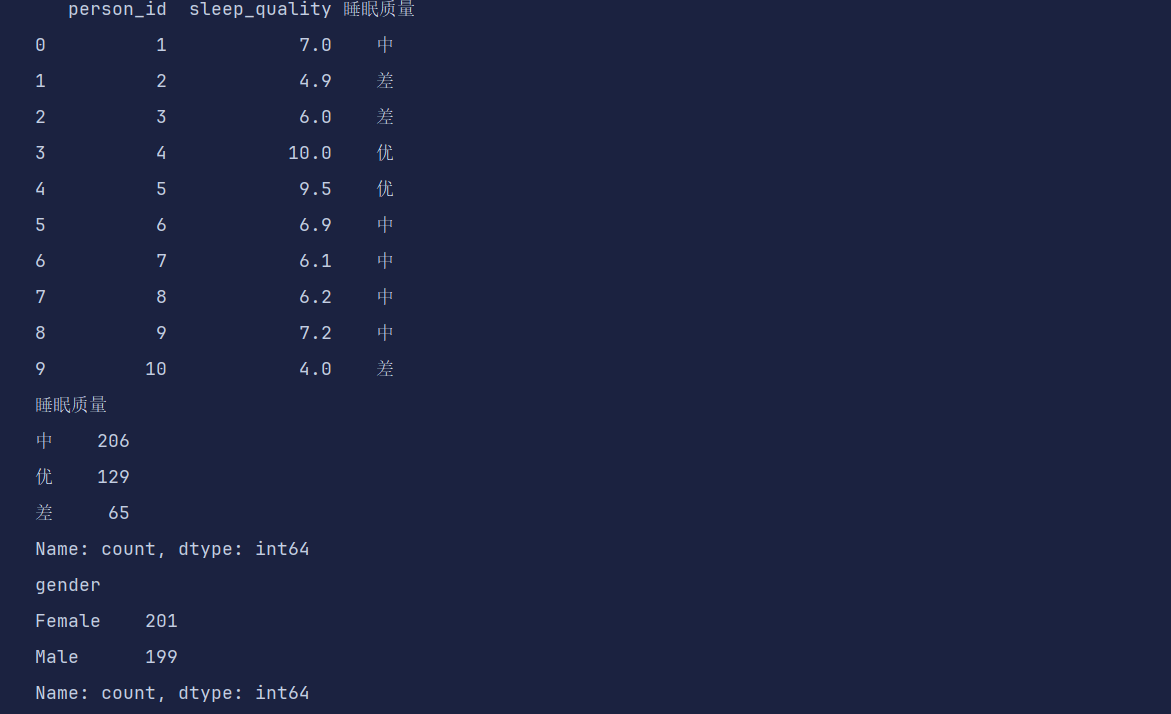
数据分箱的目的
python
# 分箱的目的 就是为了要把数值 给转换成类别 然后进行统计
# 字符串 -> 类别 -> 统计
# 数值 -> 分箱 -> 统计
print(df['gender'].dtype)
print(df['睡眠质量'].dtype)
python
# df.rename() df.set_index() df.reset_index()
df = pd.DataFrame({
'name':['jack', 'alice', 'tom', 'bob'],
'age':[20, 30, 40, 50],
'gender':['female', 'male', 'female', 'male'],
})
# 直接设置索引 设置索引为name这一列 inplace=True 进行固定
df.set_index('name', inplace=True)
df
python
# 设置索引为原来的状态
df.reset_index(inplace=True)
df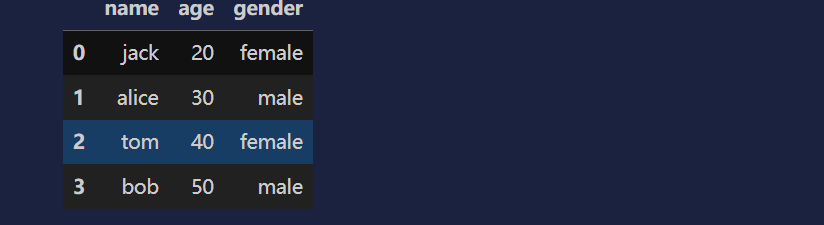
python
# 修改列名(columns) 修改索引名(index)
df.rename(columns={'age':'年龄'}, index={0:4})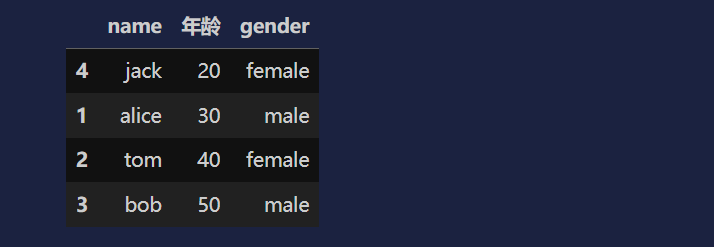
python
df.index=[1, 2, 3, 4]
df.columns = ['姓名', '年龄', '性别']
df
10. 时间数据的处理
python
# 时间数据的分析
import pandas as pd
d = pd.Timestamp('2015-05-02 10:22')
print(d)
print(type(d))
print('年:', d.year)
print('月:', d.month)
print('日:', d.day)
print(d.hour, d.minute, d.second)
print('季度', d.quarter)
print('是否是月底:', d.is_month_end)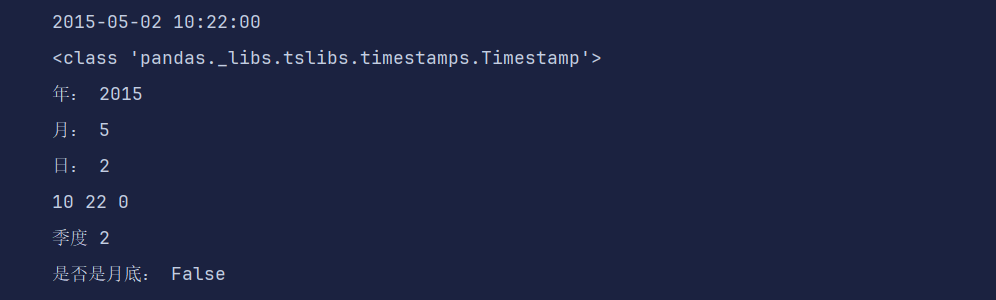
python
# 方法
print('星期几:', d.day_name)
print('转换为天:', d.to_period('D'))
print('转换为季度:', d.to_period('Q'))
print('转换为年度:', d.to_period('Y'))
print('转换为月度:', d.to_period('M'))
python
# 字符串转换为日期类型
a = pd.to_datetime('2015-02-28 10:22')
print(a)
print(type(a))
print(a.day_name())
# dataframe 日期转换
df = pd.DataFrame({
'sales': [100, 200, 300],
'date': ['20250601', '20250602', '20250603']
})
# df['datetime'] 是「日期时间型 Series」,.dt 是 Pandas 专门为这类 Series 设计的「日期时间属性访问器」------ 只有通过 .dt,才能调用日期时间专属的方法 / 属性(比如年、月、星期名)。
df['datetime'] = pd.to_datetime(df['date'])
df['week'] = df['datetime'].dt.day_name()
df['datetime'].dt.year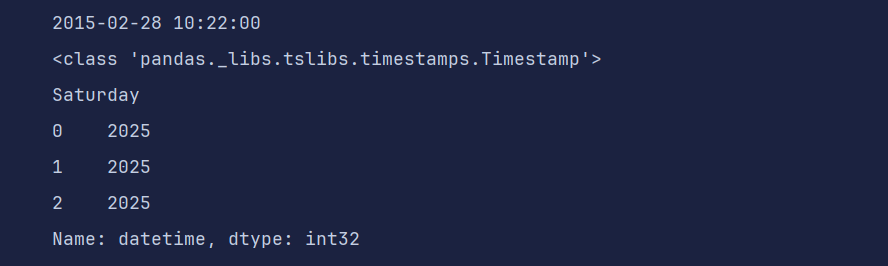
python
# csv 日期转换
df = pd.read_csv('data/weather.csv')
df['datetime'] = pd.to_datetime(df['date'])
df.info()
df['datetime'].dt.day_name()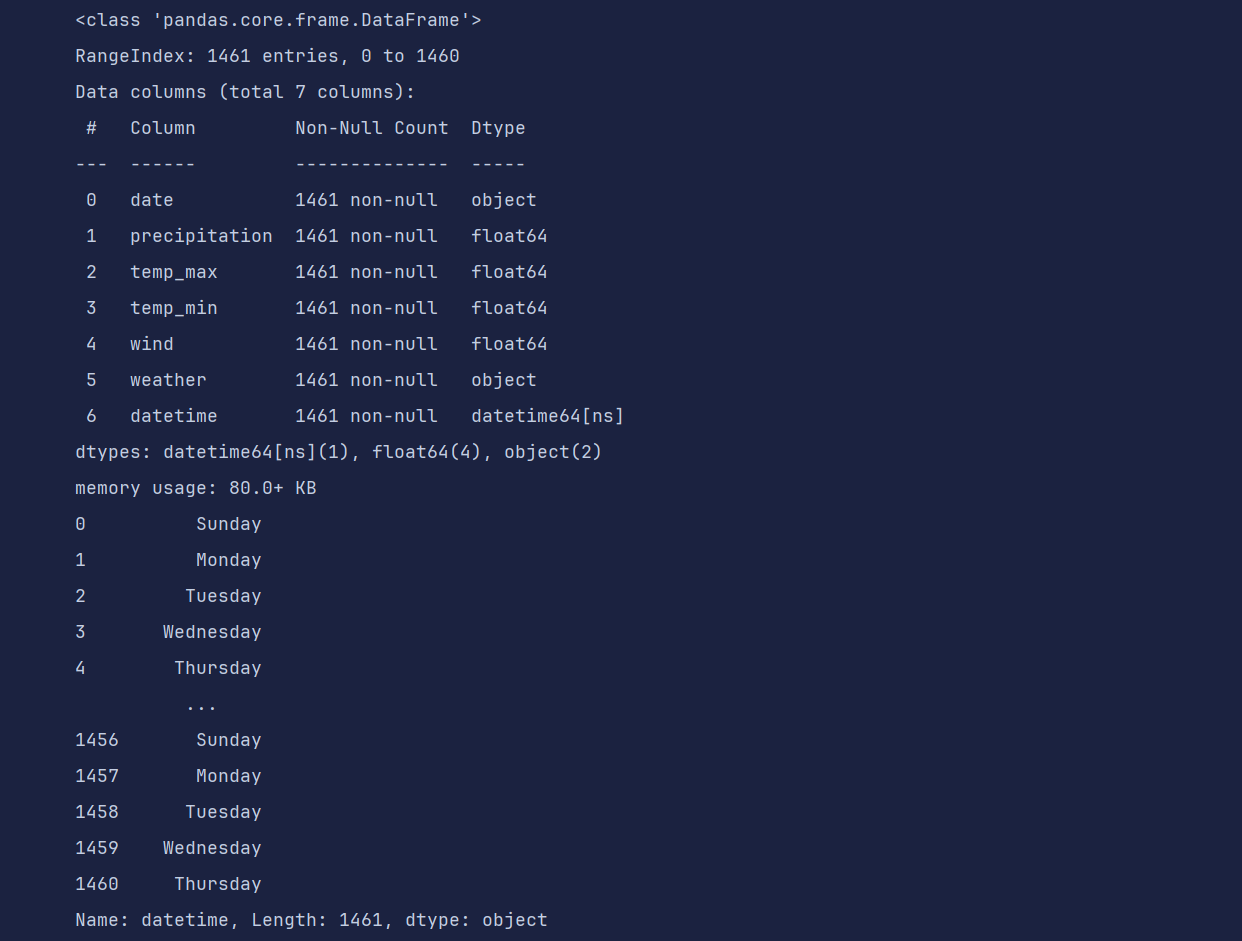
python
# csv 日期转换 parse_dates=[] 跟上面一行一样
df = pd.read_csv('data/weather.csv', parse_dates=['date'])
df.info()
df['date'].dt.day_name()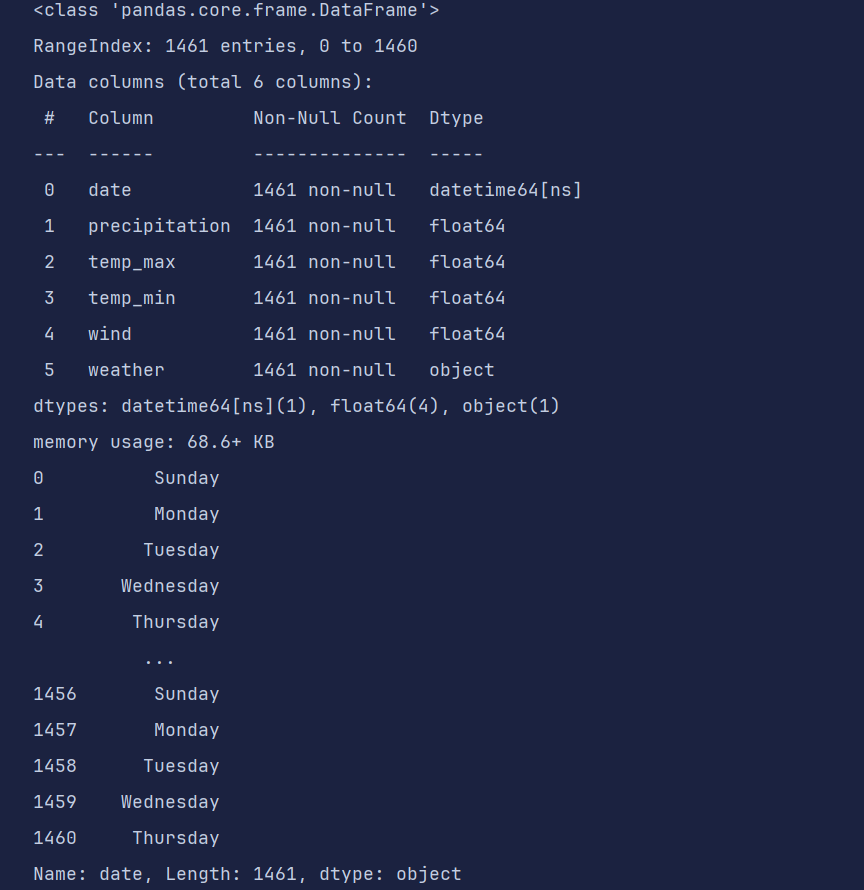
python
# 日期数据作为索引
# 设置一次就生效了 不需要多次设置
# df.set_index('date', inplace=True) # 将原来的df设置为索引
print(df)
print(df.loc['2013-01':'2013-02'])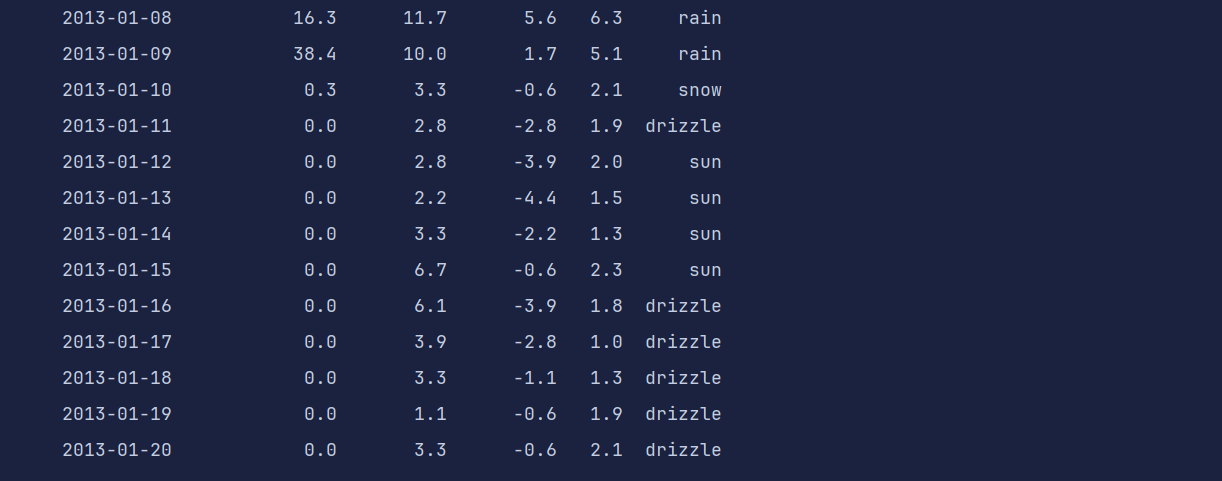
python
# 时间间隔
d1 = pd.Timestamp('2013-01-15')
d2 = pd.Timestamp('2023-02-23')
d3 = d2 -d1
print(d3)
python
df = pd.read_csv('data/weather.csv', parse_dates=['date'])
df.info()
df['delta'] = df['date'] - df['date'][0]
df.set_index('delta', inplace=True)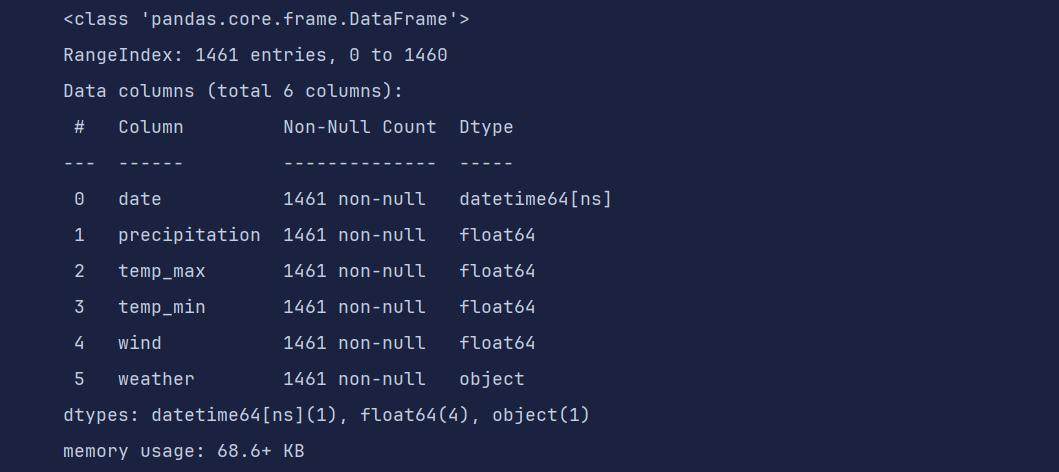
python
df
print(df.loc['10 days' : '20 days'])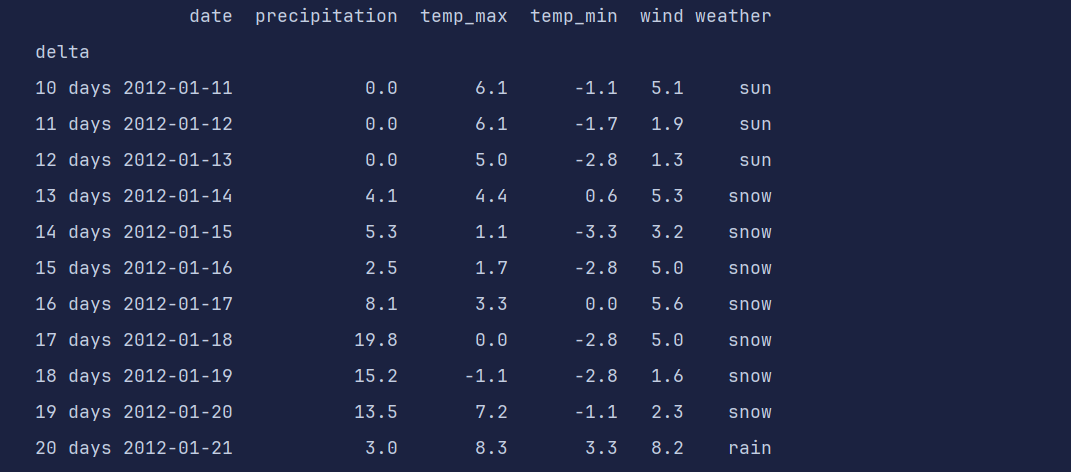
python
days = pd.date_range('2025-07-03', '2026-02-09', freq='W') # W 隔一周
days = pd.date_range('2025-07-03', periods=10, freq='W') # W 隔一周
print(days)
python
df = pd.read_csv('data/weather.csv', parse_dates=['date'])
# 重新采样
df.set_index('date', inplace=True)
df[['temp_max', 'temp_min']].resample('YE').mean()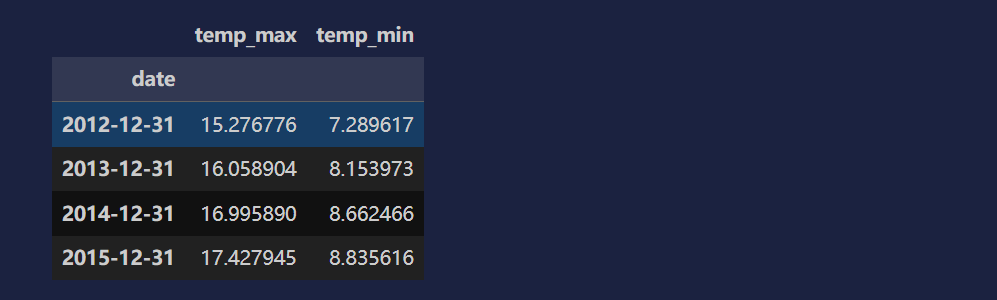
python
df[['temp_max', 'temp_min']].resample('YS').mean()
11. 分组聚合
分组聚合是 Pandas 最核心的数据分析功能之一,核心逻辑是「先分组、后聚合」------ 把数据按某个 / 某些字段分成若干组,再对每组数据计算统计值(比如平均值、求和、计数)。
- 分组:把所有员工按「部门 ID」分开(比如部门 20 的放一堆、部门 30 的放另一堆);
- 聚合:对每一堆(每个部门)计算「平均薪资」(比如部门 20 的平均薪资、部门 30 的平均薪资)。
python
# 分组聚合
import pandas as pd
df = pd.read_csv('data/employees.csv') # 读取员工数据
print(df['department_id'].isna().sum()) # 统计部门ID的缺失值数量(比如输出5,说明有5行没填部门ID)
df = df.dropna(subset=['department_id']) # 删除部门ID为空的行(没部门的员工,没法按部门分组)
df['department_id'] = df['department_id'].astype('int64') # 把部门ID转成整数(比如从字符串"20"变成数字20,方便分组)
# 查看所有分组:返回一个字典,键=分组值(部门ID),值=该组对应的行索引
df.groupby('department_id').groups
# 示例输出:{10: [0,5], 20: [1,3,7], 30: [2,4,6]} → 部门10包含索引0、5的行,部门20包含1、3、7的行...
# 查看具体分组:提取部门ID=20的所有数据(相当于"只看部门20的员工表")
df.groupby('department_id').get_group(20)
# 第一步:按部门分组,对salary列计算平均值
df2 = df.groupby('department_id')[['salary']].mean()
# 拆解这行的每一部分:
# - df.groupby('department_id') → 按部门ID分堆
# - [['salary']] → 只关注每堆的salary列(不关心其他列)
# - .mean() → 对每堆的salary列计算平均值
# 结果df2的结构:
# salary
# department_id
# 10 5000.0
# 20 8000.0
# 30 6500.0
# 注意:此时department_id是"索引"(行名),不是普通列
# 第二步:把平均薪资保留2位小数(比如8000.123→8000.12)
df2['salary'] = df2['salary'].round(2)
# 第三步:重置索引(把部门ID从"索引"变回普通列,方便后续排序/查看)
df2.reset_index()
# 重置后结构:
# department_id salary
# 0 10 5000.00
# 1 20 8000.00
# 2 30 6500.00
# 第四步:按薪资从高到低排序(看哪个部门平均薪资最高)
df2.sort_values('salary', ascending=False)
# 排序后结果:
# department_id salary
# 1 20 8000.00
# 2 30 6500.00
# 0 10 5000.00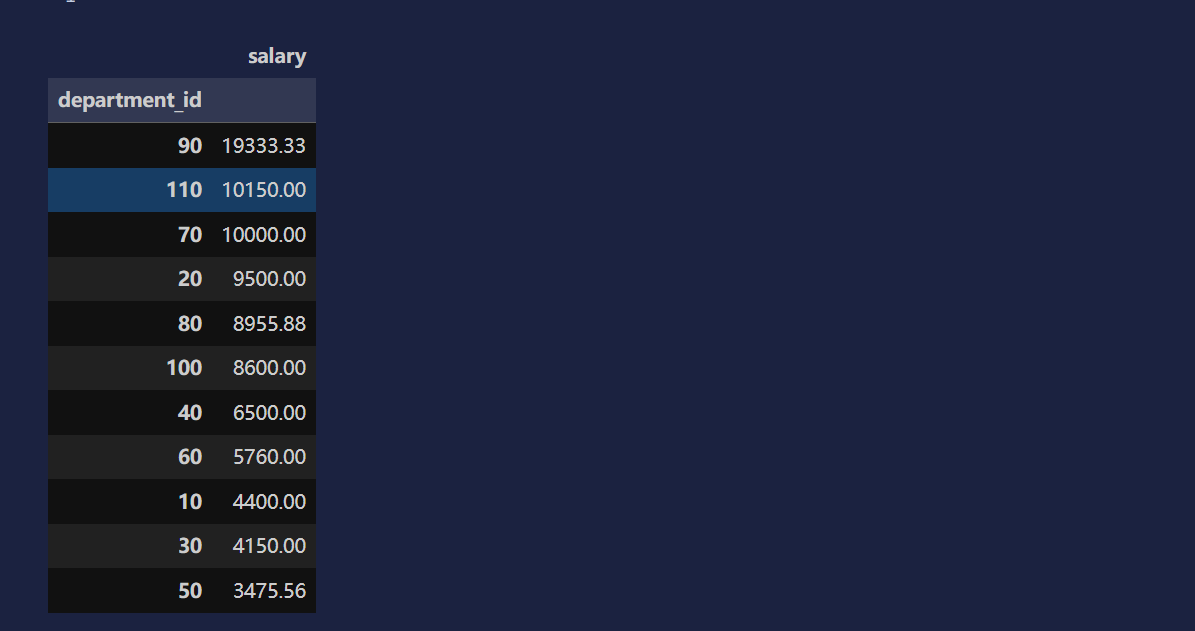
python
# 计算不同岗位的人的平均薪资
df.groupby(['department_id', 'job_id'])[['salary']].mean()
df2 = df2.reset_index()
df2['salary'] = df2['salary'].round(1)
df2.sort_values('salary',ascending=False)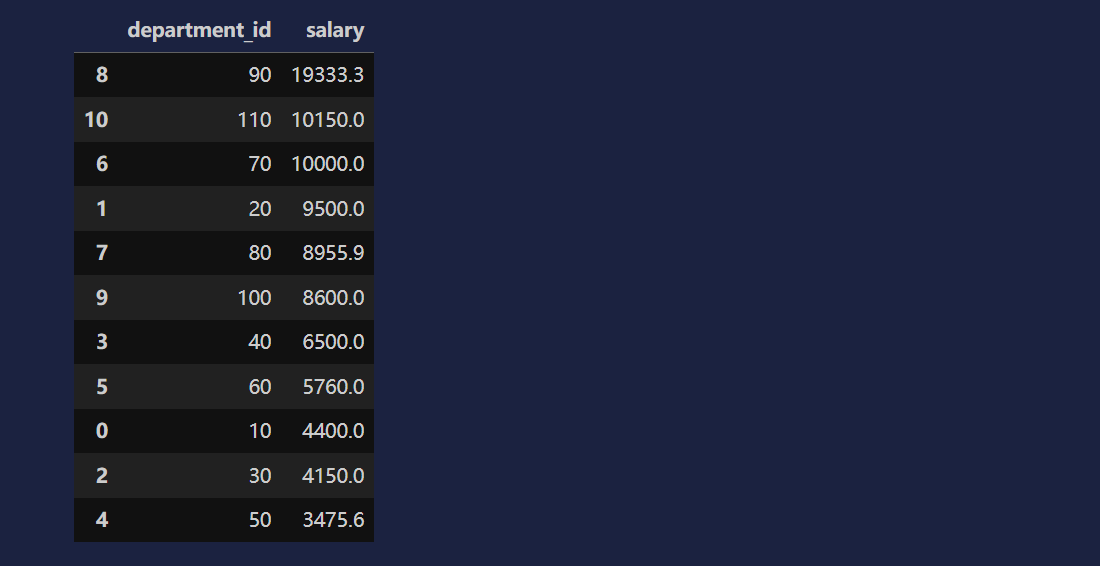
python
import pandas as pd
# 模拟员工数据
data = {
'department_id': [10,20,20,30,30,20,10],
'job_id': [1001,1001,1002,1001,1002,1001,1002],
'salary': [4500, 8000, 7000, 6500, 6000, 8500, 5500]
}
df = pd.DataFrame(data)
# 1. 按部门计算平均薪资
df2 = df.groupby('department_id')[['salary']].mean()
df2['salary'] = df2['salary'].round(2)
df2 = df2.reset_index() # 注意:要赋值给df2,否则重置不生效!
df2 = df2.sort_values('salary', ascending=False)
print("各部门平均薪资(从高到低):")
print(df2)
# 2. 按部门+岗位计算平均薪资
df3 = df.groupby(['department_id', 'job_id'])[['salary']].mean().round(1)
df3 = df3.reset_index()
print("\n各部门-岗位平均薪资:")
print(df3)
各部门平均薪资(从高到低):
department_id salary
1 20 7833.33
2 30 6250.00
0 10 5000.00
各部门-岗位平均薪资:
department_id job_id salary
0 10 1001 4500.0
1 10 1002 5500.0
2 20 1001 8250.0
3 20 1002 7000.0
4 30 1001 6500.0
5 30 1002 6000.0最后总结分组聚合的核心步骤
- 数据清洗:保证分组字段无缺失、格式正确;
- 分组 :
df.groupby(分组字段)→ 把数据分堆; - 选字段 :
[聚合字段]→ 确定要计算的列; - 聚合 :
.聚合函数()→ 对每堆计算统计值; - 格式化:round ()(保留小数)、reset_index ()(重置索引)、sort_values ()(排序)→ 让结果更易读。
案例分析
企鹅数据分析
python
# 企鹅数据分析
# 1. 导入必要的库
import pandas as pd
# 2. 导入数据
df = pd.read_csv('data/penguins.csv')
df.head(5)
df.info()
# 3. 数据清洗
# 4. 数据特征的构造
# 5. 数据分析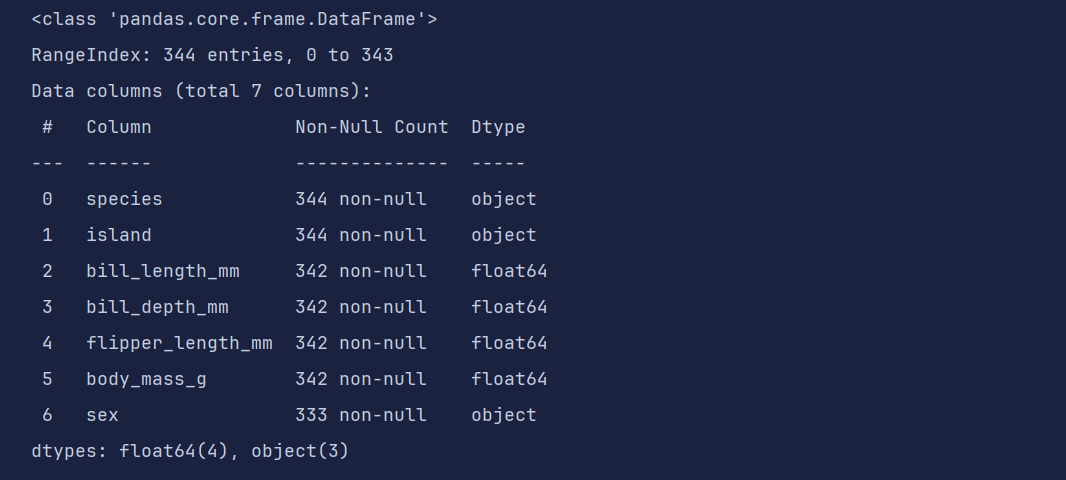
python
# 3. 数据清洗
# 缺失值检查
print(df.isna().sum())
df.dropna(inplace=True) # 当场去掉缺失值df就直接发送变化
# 4. 数据特征的构造
# 5. 数据分析
python
df.isna().sum()
len(df)
# 4. 数据特征的构造
# 5. 数据分析
python
# 4. 数据特征的构造
df['sex'] = df['sex'].astype('category')
df['bill_ratio'] = df['bill_length_mm'] / df['bill_depth_mm']
# 5. 数据分析
# 数据分箱 - 把体重分为三个等级
labels = ['低', '中', '高']
df['mass_level'] = pd.cut(df['body_mass_g'], bins=3, labels=labels)
print(df['mass_level'].value_counts())
# 按岛屿、 性别分组分析
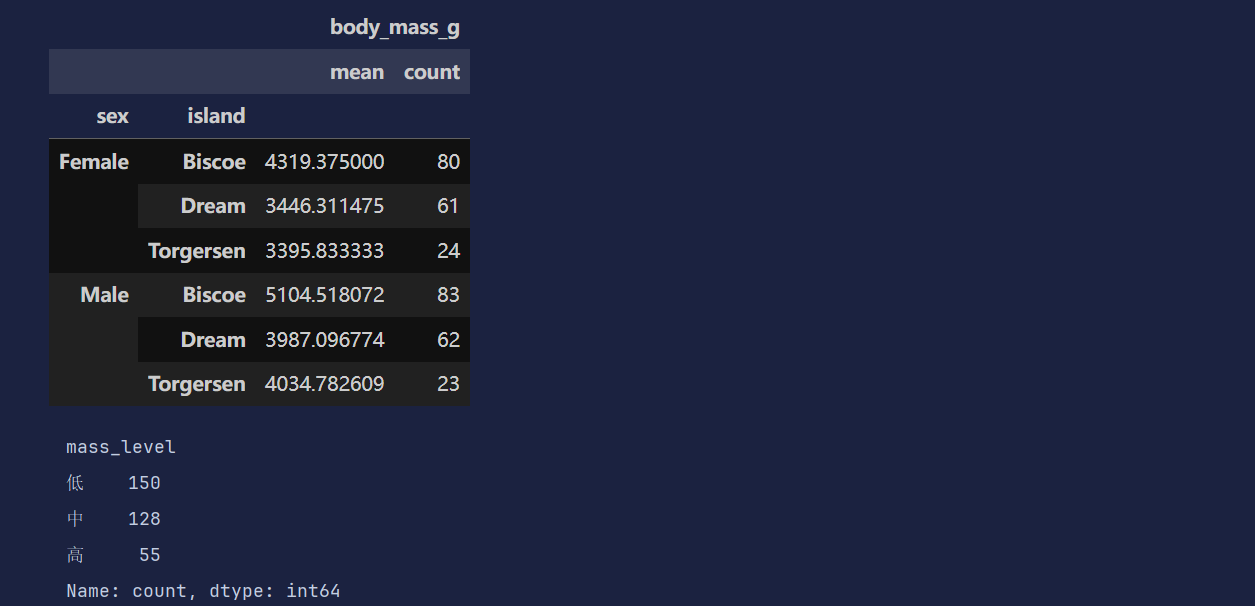
df.groupby(['sex', 'island']).agg({
'body_mass_g': ['mean', 'count'],
})
睡眠质量分析
python
# 1. 导入库
import pandas as pd
import numpy as np
# 2. 导入数据
df = pd.read_csv('data/sleep.csv')
df.head()
df.info()
df.describe()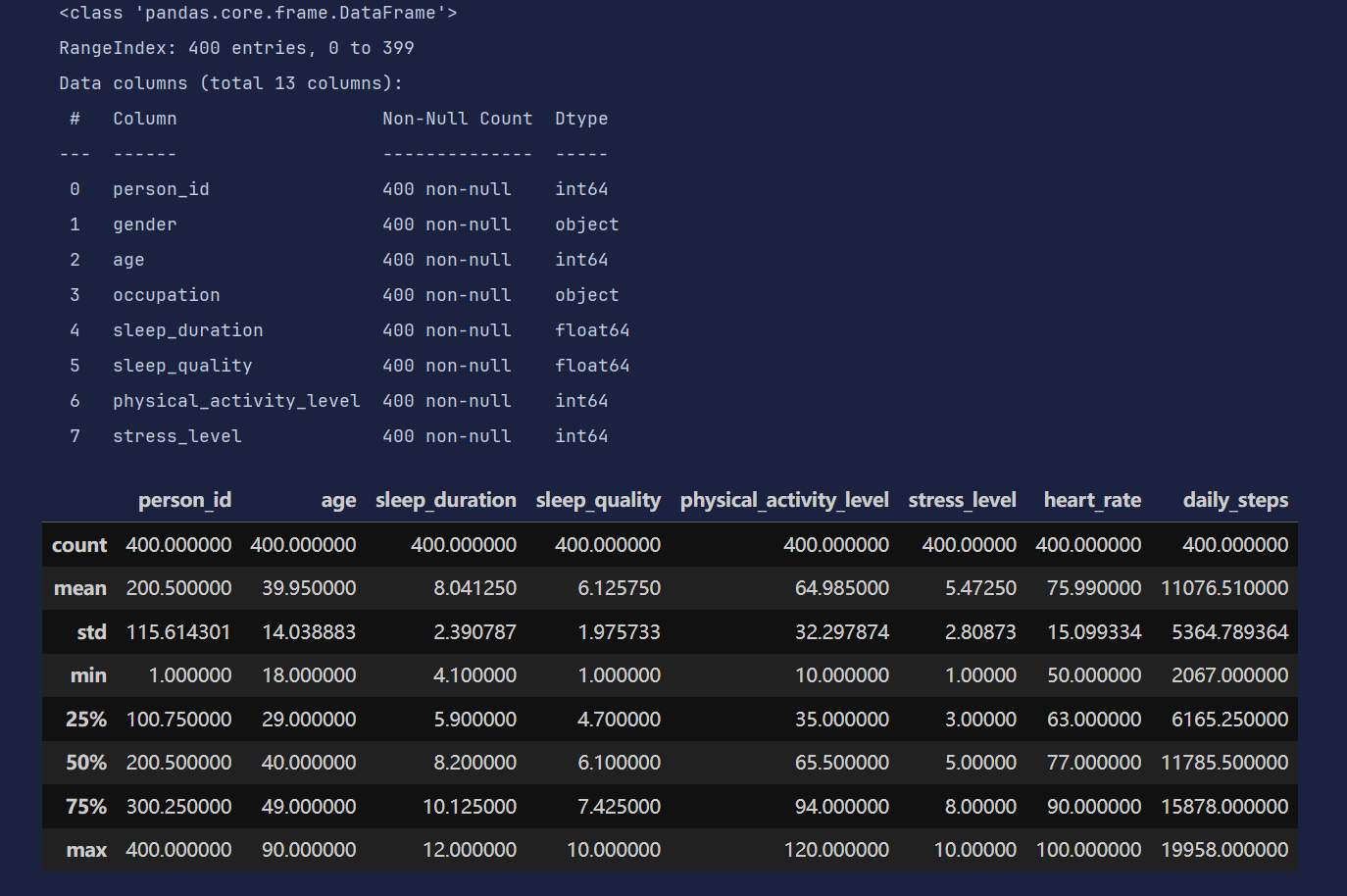
python
# 3. 数据清洗 查看是否有缺失值
df.isna().sum()
df.drop(columns='sleep_disorder', inplace=True)
# 4. 数据特征的构造
df['gender'] = df['gender'].astype('category')
df['occupation'] = df['occupation'].astype('category')
df['bmi_category'] = df['bmi_category'].astype('category')
df[['high', 'low']] = df['blood_pressure'].str.split('/', expand=True)
df.head()
# 睡眠质量的分箱
labels = ['差', '中', '优']
df['quality_level'] = pd.cut(df['sleep_quality'], bins=3, labels=labels)
age_labels=['青少年', '中年', '老年']
df['age_level'] = pd.cut(df['age'], bins=3, labels=age_labels)
df.head()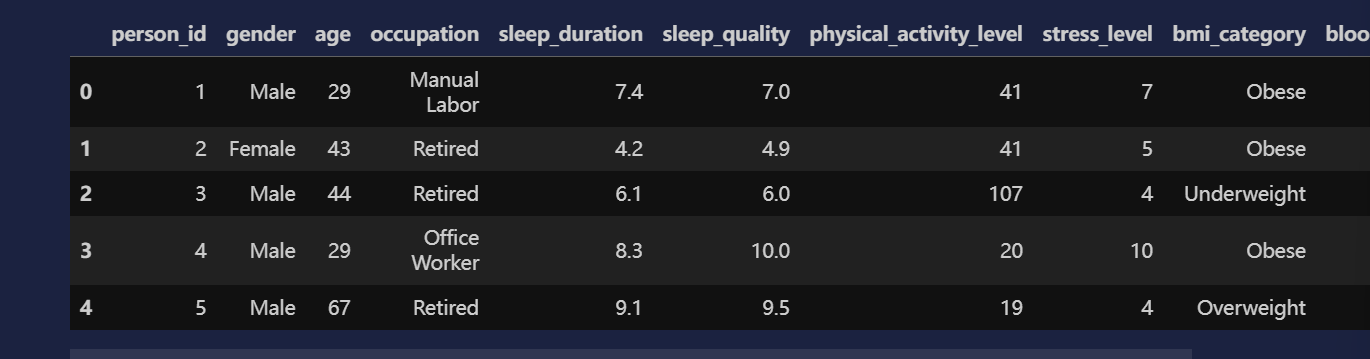
python
# 5. 数据的统计与分析
print(df['bmi_category'].value_counts())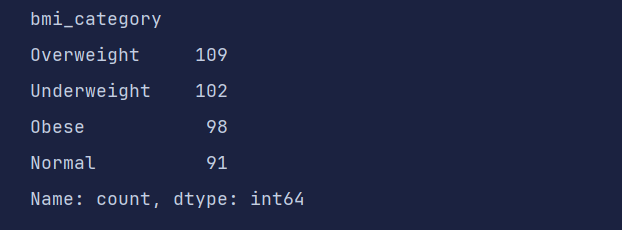
python
# 根据不同的bmi 分组 睡眠质量
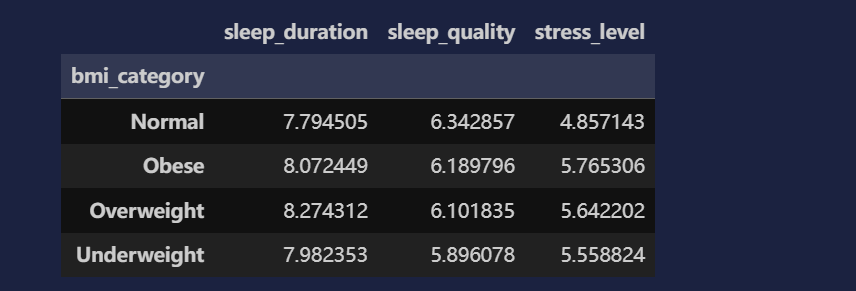
df.groupby('bmi_category').agg({
'sleep_duration': 'mean',
'sleep_quality': 'mean',
'stress_level': 'mean',
})