【论文阅读】VLA-pilot:Towards Deploying VLA without Fine-Tuning
- [1 问题背景](#1 问题背景)
- [2 关键洞察 key insights](#2 关键洞察 key insights)
-
- [2.1 预训练模型具备生成正确轨迹的能力](#2.1 预训练模型具备生成正确轨迹的能力)
- [2.2 使用推理时策略引导](#2.2 使用推理时策略引导)
- [3 具体实现](#3 具体实现)
-
- [3.1 外部验证器作为大脑](#3.1 外部验证器作为大脑)
- [3.2 进化扩散(evolutionary diffusion)作为双手](#3.2 进化扩散(evolutionary diffusion)作为双手)
- [4 实验结果](#4 实验结果)
-
- [4.1 实验配置](#4.1 实验配置)
- [4.2 实验结果](#4.2 实验结果)
1 问题背景
当前的预训练模型几乎无法完成特定任务,需要微调。但是微调带来了2个问题:
- 微调需要收集数据,这个过程的成本高,耗时长。
- 微调会导致泛化性出现下滑。尤其是泛化性下滑,违背了使用VLA的初衷。
另外,在部署时,使用了推理时策略引导(inference-time policy steering)。策略引导是指的将模型输出的多种轨迹进行评估,从而选择最佳的轨迹。
策略引导一般采用外部验证器(external verifier)。外部验证器一般是多模态大模型,但是还需要额外训练。
First, the verifiers used in these approaches typically require additional training and often exhibit limited generalization due to the narrow distribution of their training data.
2 关键洞察 key insights
其实预训练的模型是具备任务能力的,只是选不出来。
In fact, such deployment failures do not necessarily indicate that the pre-trained VLA policy is incapable of generating the correct behavior. The desired behavior mode may already exist within the policy's generative distribution, but due to suboptimal mode selection at runtime, it fails to be executed reliably.
2.1 预训练模型具备生成正确轨迹的能力
VLA模型本质上是一个条件概率模型------根据观测,输出各个动作的概率。但是由于预训练数据和特定任务的分布不一致(比如预训练中是抓蓝色杯子,但是任务是抓红色杯子),导致抓取动作的概率很低。
2.2 使用推理时策略引导
该论文提出了一种【推理时引导】的方法,应用于VLA输出动作之后,执行器对动作执行之前。好处是:不需再SFT,实现零样本部署。该论文形容为"Plug and play"(即插即用)。
该论文的方法和之前的方法对比如下:

3 具体实现
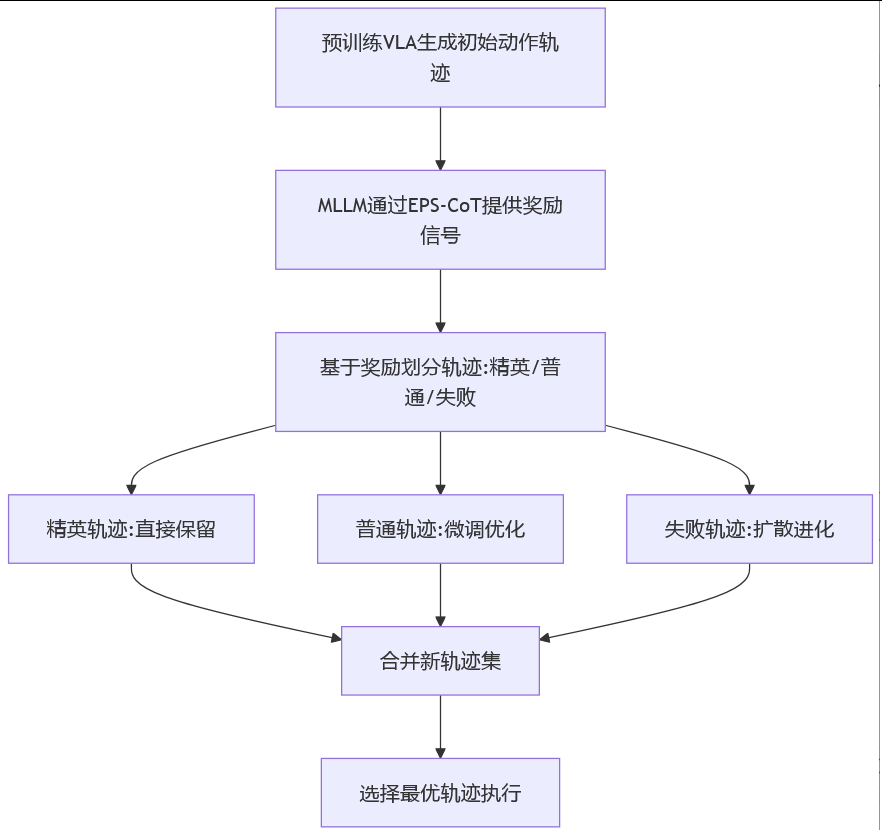
3.1 外部验证器作为大脑
VLA提供动作分布和置信度,外部验证器利用多模态大模型(比如GPT-4V)对开放世界的理解能力,通过自然语言推理对任务和动作进行重新评估,使得正确动作的概率更高。
具体实现:通过Embodied Policy Steering Chain-of-Thought (EPS-CoT)模块
工作方式:接收任务描述+场景图像→生成自然语言推理链→输出任务对齐的奖励信号
using the open-world reasoning capabilities of MLLMs. This removes the need for training task-specific verifiers
注意:该外部验证器是使用了EPS-CoT的提示模板,并没有对其进行训练。可以将EPS-CoT理解为CoT在具身智能领域的应用。
3.2 进化扩散(evolutionary diffusion)作为双手
通过初始的采样轨迹,剔除差的,保留好的,然后基于好的再进行扩散,如此迭代,最终选择打分最高的轨迹。
区别:
传统方法:只能从VLA生成的动作中选择
VLA-Pilot:能主动优化/进化动作,即使初始动作全部不可行
Unlike previous selection-based steering method, Evolutionary Diffusion not only selects, but also evolves action candidates toward a task-aligned distribution, enabling effective policy steering even when initial proposals are suboptimal or infeasible.
4 实验结果
4.1 实验配置
6个操作任务,2个本体
4.2 实验结果
直接部署预训练模型,如OpenVLA和RT-2,成功率有显著提高。
Experimental results demonstrate that VLA-Pilot substantially boosts the success rates of off-the-shelf pre-trained VLA policies, enabling robust zero-shot generalization to diverse tasks and embodiments.