论文:https://arxiv.org/pdf/2302.13971
1、为什么要做这个研究(理论走向和目前缺陷) ?
之前的效果的模型要么不开源,要么用了私有数据训练,完全开源的效果都不咋地。
2、他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
用完全开源的数据(1.4万亿tokens),并没有大的离谱模型(7B到65B), 做了一系列前面研究做的优化,如RMSNorm的Pre-normalization减少计算量,FFN的激活函数替换为SwiGLU增强表现能力更好,旋转位置编码RoPE提升模型长度外推性。这些优化基本都成了后续大模型设计的标配。
3、发现了什么(总结结果,补充和理论的关系)?
算是首个完全开源且效果和闭源模型相当的LLM模型,候选qwen也是基于这个模型改进得到的。
摘要
发布LLaMA系列模型,参数量从7B到65B量级,训练数据在1.5万亿tokens,且全是开源的数据,13B参数量的比175B的GPT-3性能还要好,65B的模型达到当前最好的大语言模型效果。
1 引言
在算力固定的情况下,小模型+大数据比大模型+小数据效果更好,而且小模型+大数据可能训练时间很长,但是推理时长比较短。
2 方案
2.1 预训练数据
全是开源数据,大部分都是其他LLM训练用的数据。
英文爬虫获取数据(67%) 。预处理之前别人通过爬虫获得的(2017-2020)文献,但做了以下处理,1)数据去重。2)用fastText线性分类器区分是否英文数据,把非英文的踢掉。3)ngram语言模型滤除内容质量底下的数据。4)训练了一个分类器区分是否来自维基百科数据,把非维基百科的数据丢弃掉。
C4数据(15%) 。预处理包括去重以及去非英文数据。
github数据(4.5%) 。去重,去低质量数据。
Wiki百科(4.5%) 。2022年1月-2022年月的数据。把超链接、评论、及废话去掉。
Gutenberg and Books3 4.5% 。来自书本的预料库,也做了去重。
ArXiv 2.5% . 移除文章第一节前的所有内容,包括作者信息也被移除。
Stack Exchange 2%. 有高质量问答数据的网站,类似stackoverflow。
分词器 : BPE.
最终获得共计1.4T(1.4万亿)个训练tokens,大多数训练数据只会被训练一次,除了维基百科和书本里的数据训练了两次。
2.2 架构
基于transformer了架构,并混合了后续模型提出的各种优化方法。包括:
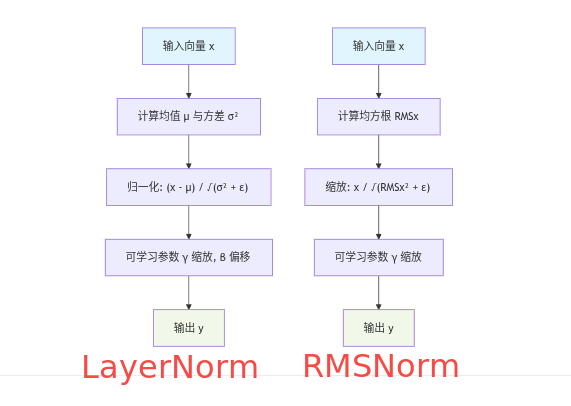
Pre-normalization GPT3. 使用RMSNorm在transofmer子层输入之前先做归一化,而不是像标准的transfomer一样在输出之后做LayerNorm归一化,可以提升训练的稳定性。注:LayerNorm和RMSNorm的主要区别在于是否有中心化,LayerNorm会减去特征均值,实现数据中心化,而RMSNorm没有这一步,故不会中心化。在大模型训练时,中心化不是必须的,而缩放是必要的,且RMSNorm计算量更小,
SwiGLU activation function PaLM 。SwiGLU替换FFN层中ReLU层。SwiGLU中的G即gate,引入了门控(0~1)之间权重逐元素和线性变换后的原始值相乘。虽然增加了计算量,但在大模型中表现能力更好,基本是现代大模型的标配。

Rotary Embeddings GPTNeo 。即RoPE相对位置编码。位置编码一般有绝对位置编码,即可学习的位置编码或标准的transfomer中使用的Sinusoidal位置编码。可学习的位置编码缺点是模型不具有长度外推性,因为位置编码矩阵的大小是预设的,若对其进行扩展,将会破坏模型在预训练阶段学习到的位置信息。Sinusoidal位置编码还具有远程衰减的性质,具体表现为对于两个相同的词向量,如果它们之间的距离越近,则他们的内积分数越高,反之则越低。Sinusoidal位置编码中的正弦余弦函数具备周期性,并且具备远程衰减的特性,所以理论上也具备一定长度外推的能力。而RoPE作者的出发点为:通过绝对位置编码的方式实现相对位置编码。Sinusoidal位置编码通过加法把相对位置信息融入到内容信息中,但需要模型隐式学习这种相对位置信息,而RoPE通过旋转(乘法)把相对位置信息融入到内容信息中,是一种显式的注入,不需要隐式学习,在长度外推性方面,RoPE比Sinusoidal更好。参考
https://hub.baai.ac.cn/view/32862 获取更详细的信息。

2.3 优化器
AdamW 优化器,cosine learning rate schedule等
2.4 高效实现
做了一些优化提升训练速度。首先是采用高效因果多头注意力(from xformers)减少内存占用和运行时间,即下三角矩阵只计算需要的部分,不用的部分不存不算,从而减少显存占用。其次,保存线性层的激活值,避免反向传播时还要重新计算。
最终训练65B的模型,1.4万亿的tokens数据,需要80G A100训练21天。
3 主要结果
在20个benchmarks做了实验。
- Zero-shot: 提供任务描述和一道测试题输入到模型中,让模型生成问题解答或选择正确答案。
- Few-shot: 提供一些任务解答案例和一道测试题,让模型生成问题解答或选择正确答案。
对比的模型:
- 闭源:GPT-3 2020, Gopher 2021, Chinchilla 2022, PaLM 2022
- 开源:OPT 2022, GPT-J 2021, GPT-Neo 2022, 以及指令微调的模型OPT-IML, Flan-PaLM.
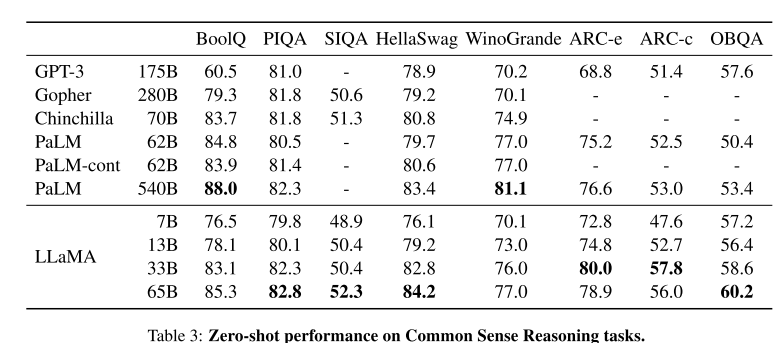
3.1 常识推理
8个benchmark: BoolQ, PIQA,SIQA , HellaSwag, WinoGrande, ARC easy/challenge, OpenBookQA.
3.2 书本知识问答
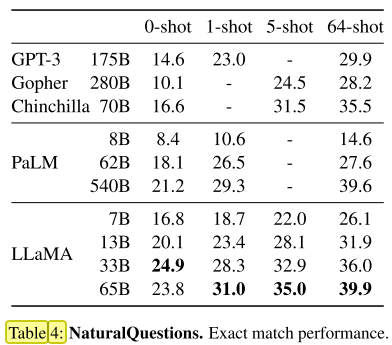
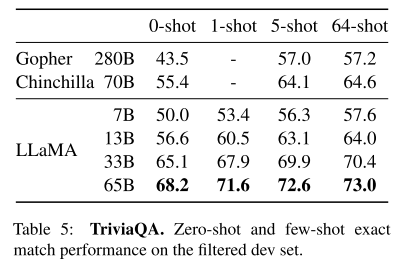
两个benchmark: Natural Questions和TriviaQA
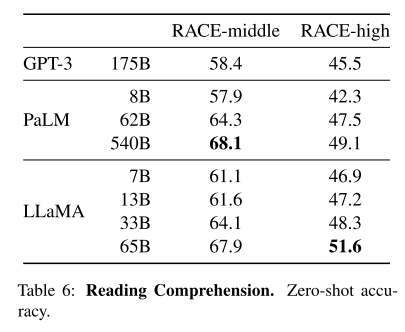
3.3 阅读理解
RACE benchmark,来源于中国初高中英语测试的阅读理解题。
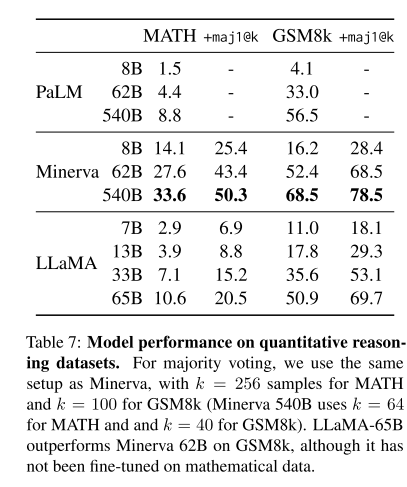
3.4 数学推理
2 benchmark : MATH, GSM8k,初高中数学题。
Minerva是PaLM在arxiv以及数学网站数据微调出来的模型,故效果很好。
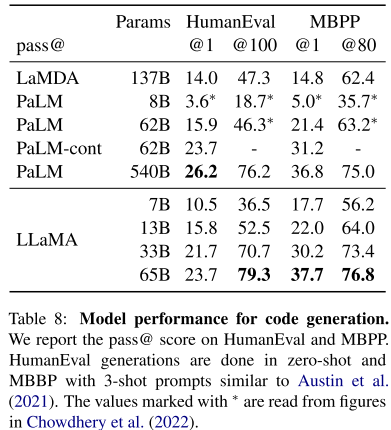
3.5 代码生成
2个benchmark: HumanEval, MBPP
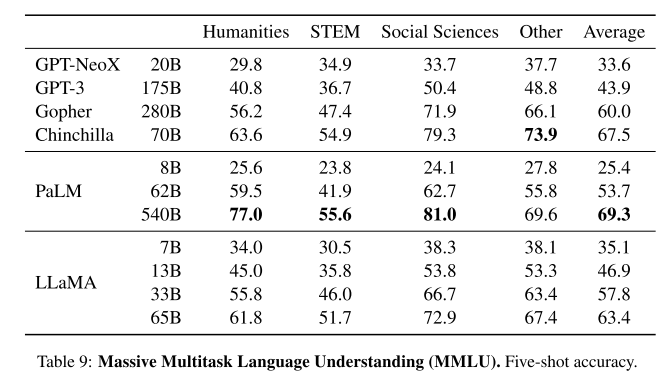
3.6 大规模多任务语言理解
MMLU benchmark
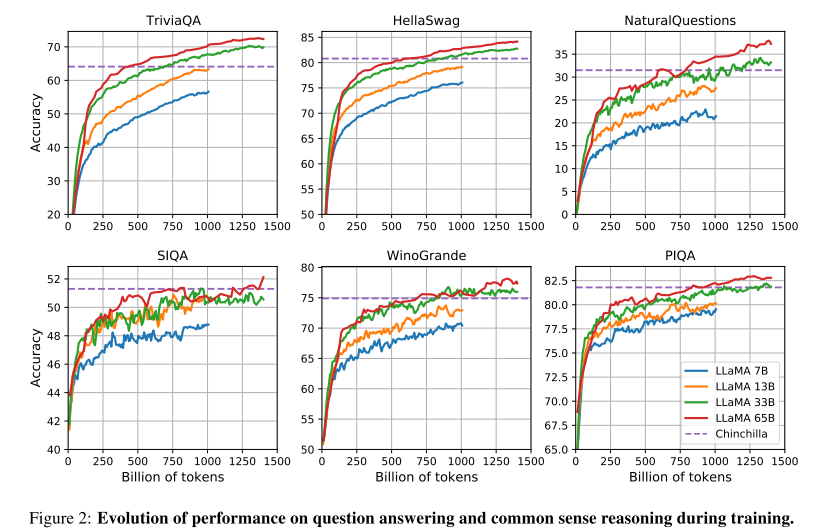
3.7 训练时的性能进化
训练时评估模型性能,一般情况下,训的tokens越多,性能越好。
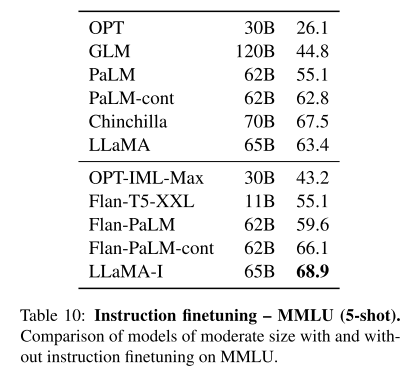
4 指令微调
加点指令微调后,模型效果大幅提升。
5 偏见、戾气以及错误
6 碳排放
7 相关研究
8 结论
开源了不同大小的LLaMA模型,通过相对较小模型+大量数据实现不错的效果,且所有数据都是开源的。