1 概述
Linux版本迭代过程出现过slab的三种算法分配器:slab/slob/slub,其中slab是较早期分配器,slob针对小型嵌入式系统简单的分配,slub分配器是针对大型服务器复杂系统分配器,目前Linux系统默认使用的是slub分配器。本文涉及的slab相关知识,都是基于slub分配器源码来分析,记录了对Linux下slub分配器原理的理解,走读了内核源码关于slub的代码流程,从源码层面分析和理解slub的框架与工作原理。
2 总览
本文要分析的slab,位于如下Linux内存框图位置,slab分配器的底层依托于buddy system,上层却对用户提供了更加灵活的内存分配服务。

相对于伙伴系统只安排page单位来分配内存,slab分配器能提供更小更合适的内存大小给使用者,但提供小内存块不是slab分配器的唯一任务,由于结构上的特点,它也用作一个缓存,主要针对经常分配并释放的对象,通过建立slab缓存,内核能够储备一些对象供后续使用。
3 slab的使用
slab框架提供了如下接口给用户linux-5.15.158\include\linux\slab.h
struct kmem_cache *kmem_cache_create(const char *name, unsigned int size,
unsigned int align, slab_flags_t flags,
void (*ctor)(void *));
struct kmem_cache *kmem_cache_create_usercopy(const char *name,
unsigned int size, unsigned int align,
slab_flags_t flags,
unsigned int useroffset, unsigned int usersize,
void (*ctor)(void *));
void kmem_cache_destroy(struct kmem_cache *);
void *kmem_cache_alloc(struct kmem_cache *cachep, int flags);
void kmem_cache_free(struct kmem_cache *cachep, void *objp);创建一个slab缓存池:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/slab.h>
#include <linux/init.h>
#include <linux/list.h>
#include <linux/string.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("A simple SLAB/SLUB allocator example");
/*
* 1. 定义我们要缓存的自定义数据结构
*/
struct example_struct {
int id;
char name[32];
struct list_head list; // 用于将分配的对象链接起来
};
/*
* 2. 声明一个全局的 kmem_cache 指针,用于指向我们创建的缓存
*/
static struct kmem_cache *my_example_cache;
/*
* 3. 声明一个全局链表头,用于跟踪所有分配的对象
*/
static LIST_HEAD(example_list_head);
/*
* 4. 辅助函数:分配一个新的 example_struct 对象
*/
struct example_struct* create_example_object(int id, const char* name) {
struct example_struct *obj;
// 从我们自定义的 slab 缓存中分配内存
// GFP_KERNEL 是标准的内存分配标志,表示可以在睡眠时等待内存可用
obj = kmem_cache_alloc(my_example_cache, GFP_KERNEL);
if (!obj) {
printk(KERN_ERR "Failed to allocate memory from my_example_cache\n");
return NULL;
}
// 初始化结构体成员
obj->id = id;
strncpy(obj->name, name, sizeof(obj->name) - 1);
obj->name[sizeof(obj->name) - 1] = '\0';
INIT_LIST_HEAD(&obj->list);
// 将新对象添加到全局链表中进行跟踪
list_add(&obj->list, &example_list_head);
printk(KERN_INFO "Allocated object ID %d (%s) from slab cache\n", obj->id, obj->name);
return obj;
}
/*
* 5. 辅助函数:释放一个 example_struct 对象
*/
void destroy_example_object(struct example_struct *obj) {
if (!obj) return;
printk(KERN_INFO "Freeing object ID %d\n", obj->id);
// 从链表中移除
list_del(&obj->list);
// 将内存归还给 slab 缓存
kmem_cache_free(my_example_cache, obj);
}
/*
* 6. 模块初始化函数
*/
static int __init slab_example_init(void) {
printk(KERN_INFO "Slab Example Module Init\n");
// 创建一个新的 SLAB 缓存
// 参数说明:
// "my_example_cache":缓存名称,可以在 /proc/slabinfo 中看到
// sizeof(struct example_struct):每个对象的大小
// 0:对齐方式(0表示默认对齐)
// 0:flags(标志,通常为 0,除非需要特殊行为,如 SLAB_HWCACHE_ALIGN)
// NULL:构造函数(可选,分配时自动调用,通常为 NULL)
my_example_cache = kmem_cache_create(
"my_example_cache",
sizeof(struct example_struct),
0,
0,
NULL
);
if (!my_example_cache) {
printk(KERN_ERR "Failed to create kmem_cache\n");
return -ENOMEM;
}
printk(KERN_INFO "kmem_cache 'my_example_cache' created successfully.\n");
// 分配几个对象进行测试
create_example_object(1, "First Item");
create_example_object(2, "Second Item");
create_example_object(3, "Third Item");
// 您现在可以运行 `cat /proc/slabinfo | grep my_example_cache` 查看统计信息
return 0;
}
/*
* 7. 模块退出函数
*/
static void __exit slab_example_exit(void) {
struct example_struct *obj, *temp;
printk(KERN_INFO "Slab Example Module Exit\n");
// 遍历链表,释放所有已分配的对象
list_for_each_entry_safe(obj, temp, &example_list_head, list) {
destroy_example_object(obj);
}
// 销毁整个 slab 缓存
// 必须确保所有对象都已经被释放,否则销毁会失败或导致问题
kmem_cache_destroy(my_example_cache);
printk(KERN_INFO "kmem_cache 'my_example_cache' destroyed.\n");
}
module_init(slab_example_init);
module_exit(slab_example_exit);4 slab分配器数据原理
在Linux内核中,Linux使用struct kmem_cache来描述一个slab cache对象:
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;//slab缓存对象
/* Used for retrieving partial slabs, etc. */
slab_flags_t flags;
unsigned long min_partial;
unsigned int size; /* The size of an object including metadata */
unsigned int object_size;/* The size of an object without metadata */
struct reciprocal_value reciprocal_size;
unsigned int offset; /* Free pointer offset */
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* Number of per cpu partial objects to keep around */
// 限定 slab cache 在每个 cpu 本地缓存 partial 链表中缓存的所有 slab 中空闲对象的总数
// cpu 本地缓存 partial 链表中空闲对象的数量超过该值,则会将 cpu 本地缓存 partial 链表中的所有 slab 转移到 numa node 缓存中。
unsigned int cpu_partial;
#endif
// 表示 cache 中的 slab 大小,包括 slab 所申请的页面个数,以及所包含的对象个数
// 其中低 16 位表示一个 slab 中所包含的对象总数,高 16 位表示一个 slab 所占有的内存页个数。
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
// 当按照 oo 的尺寸为 slab 申请内存时,如果内存紧张,会采用 min 的尺寸为 slab 申请内存,可以容纳一个对象即可。
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
unsigned int inuse; /* Offset to metadata */
unsigned int align; /* Alignment */
unsigned int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
#ifdef CONFIG_SYSFS
struct kobject kobj; /* For sysfs */
#endif
#ifdef CONFIG_SLAB_FREELIST_HARDENED
unsigned long random;
#endif
#ifdef CONFIG_NUMA
/*
* Defragmentation by allocating from a remote node.
*/
unsigned int remote_node_defrag_ratio;
#endif
#ifdef CONFIG_SLAB_FREELIST_RANDOM
unsigned int *random_seq;
#endif
#ifdef CONFIG_KASAN
struct kasan_cache kasan_info;
#endif
unsigned int useroffset; /* Usercopy region offset */
unsigned int usersize; /* Usercopy region size */
struct kmem_cache_node *node[MAX_NUMNODES];//CPU节点对应的slab cache
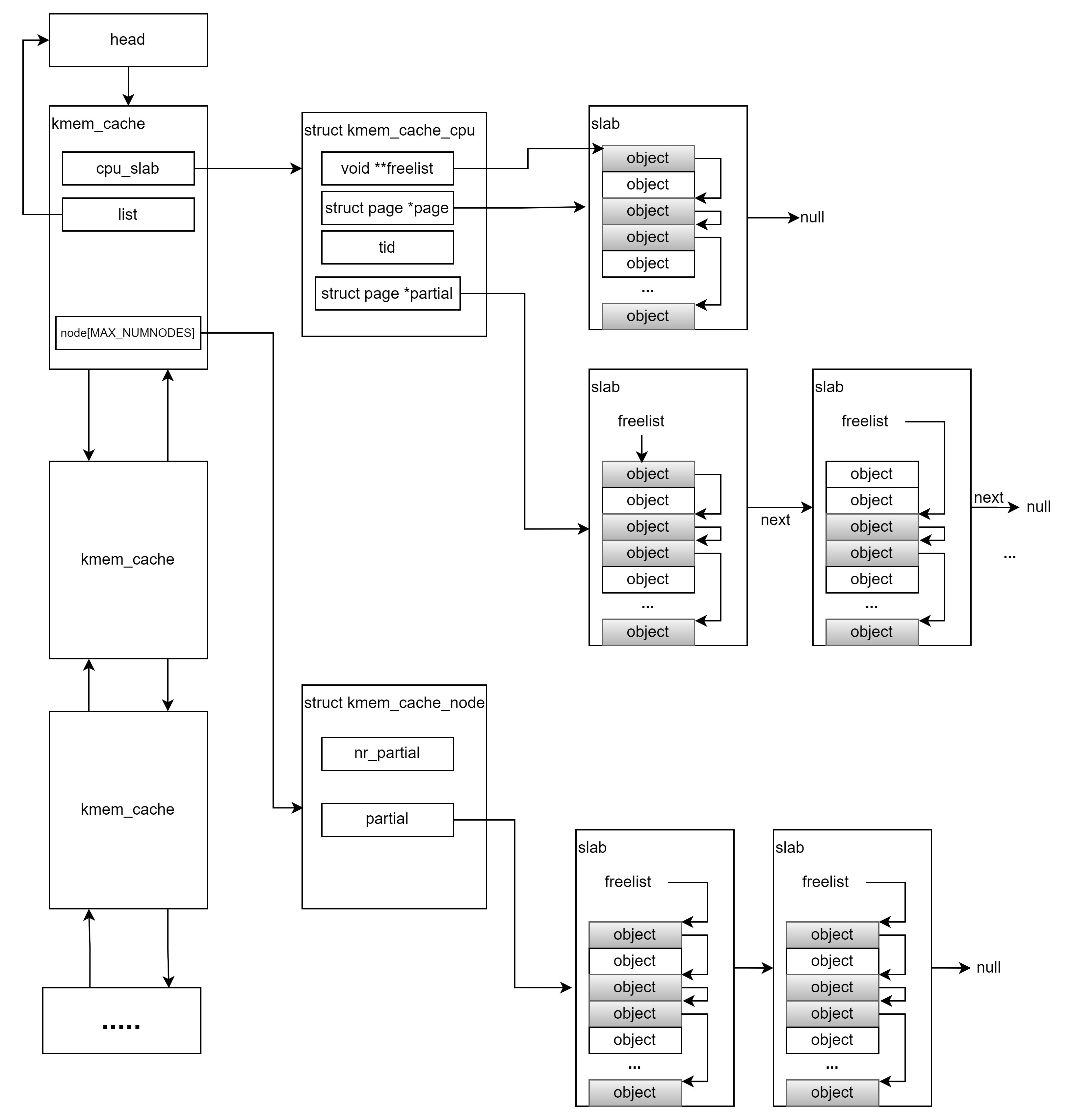
};每当用户创建一个slab cache时,该对象会被加入mm\slab_common.c内核一个全局的链表中:
LIST_HEAD(slab_caches);内核整体管理slab cache组织如下:

4.1 CPU的slab缓存
当用户申请内存时,首先从struct kmem_cache维护的struct kmem_cache_cpu __percpu *cpu_slab中申请内存,cpu_slab是为每个CPU绑定的缓存,充分考虑了多进程并发访问 slab cache 所带来的同步性能开销,当进程需要向 slab cache 申请对应的内存块(object)时,首先会直接来到 kmem_cache_cpu 中查看 cpu 本地缓存的 slab,如果本地缓存的 slab 中有空闲对象,那么就直接返回了,整个过程完全没有加锁。而且访问路径特别短,防止了对 CPU 硬件高速缓存 L1Cache 中的 Instruction Cache(指令高速缓存)污染。
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; /* Partially allocated frozen slabs */
#endif
local_lock_t lock; /* Protects the fields above */
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};freelist 指针指向的是该 slab 中第一个空闲的对象,每个对象里存放着用来指向下一个空闲对象的freepointer,这样将空闲的内存块链接起来,page指向当前可用的页内存首地址:
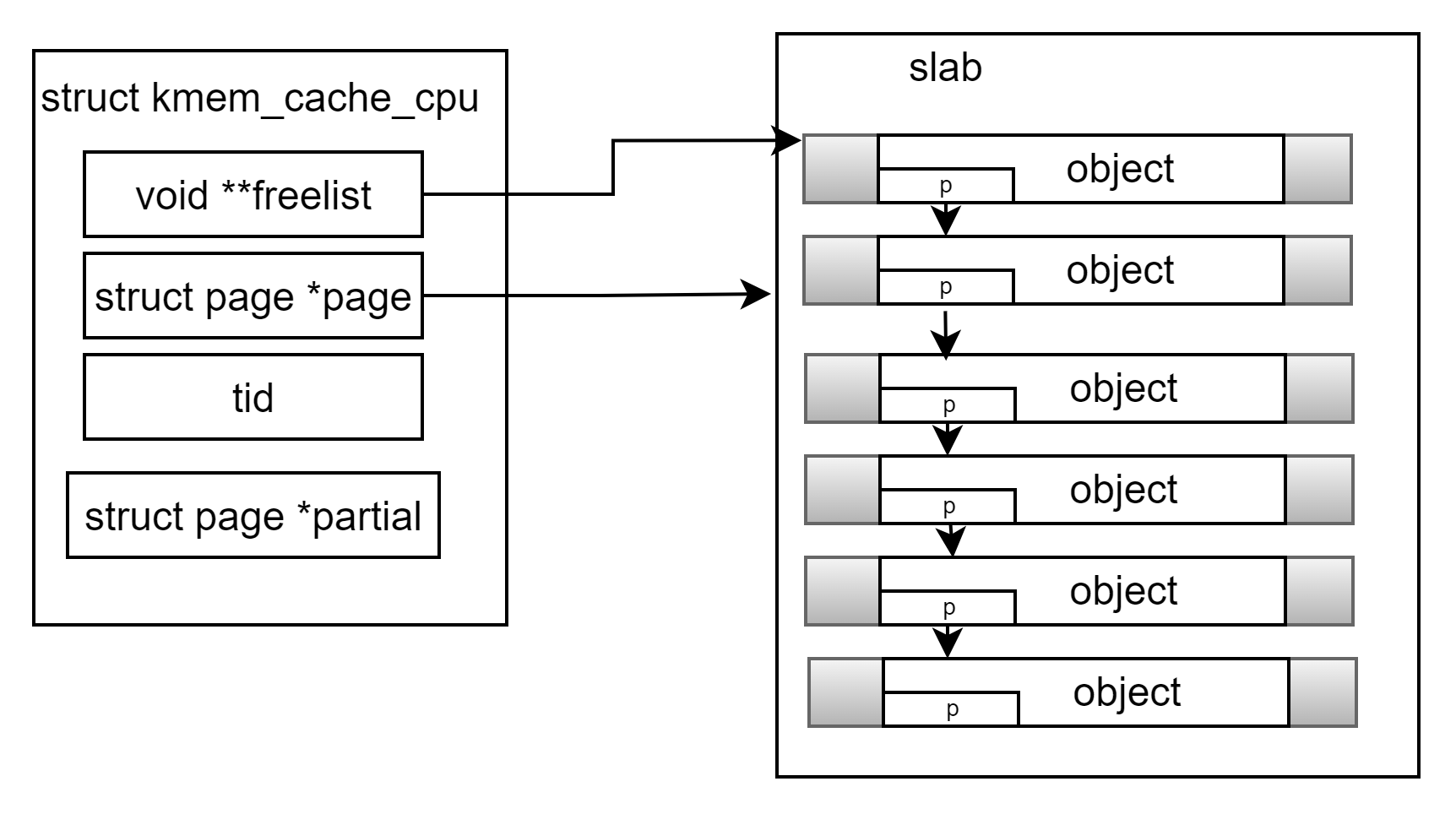
如果开启了 CONFIG_SLUB_CPU_PARTIAL 配置项,那么在 slab cache 的 cpu 本地缓存 kmem_cache_cpu 结构中就会多出一个 partial 列表即struct page *partial,在page被用完后,内核会先从该列表查找空闲的内存:
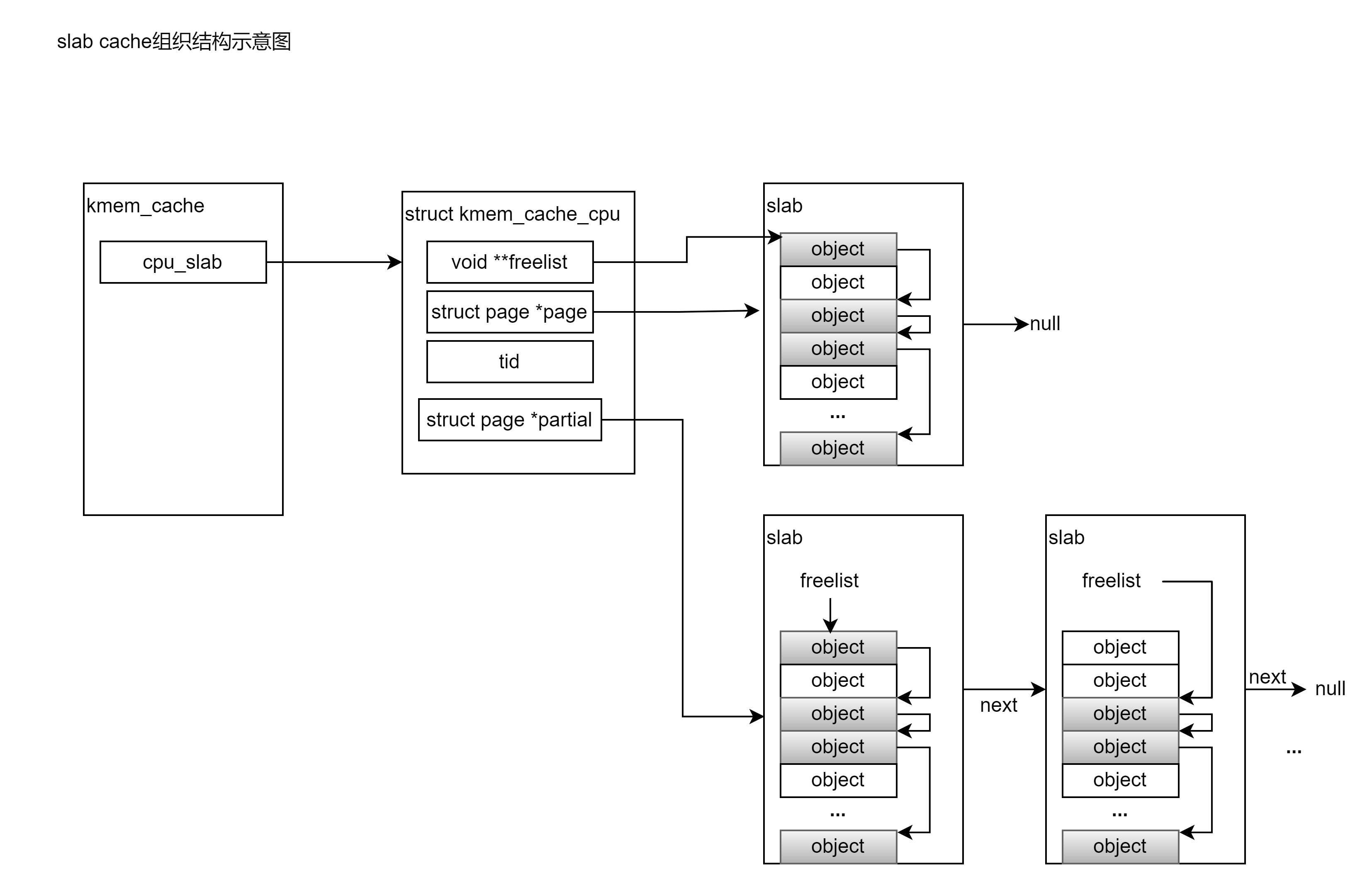
4.2 CPU节点内存
当进程申请内存时,内核在slab缓存中找不到可用的空闲内存块后(即此时缓存内存用完),此时内核会从 struct kmem_cache结构体中的struct kmem_cache_node *nodeMAX_NUMNODES成员查找可用内存,node是slab cache 中 NUMA node中的缓存,内核为了加速每个CPU的对内存访问,会为每个CPU缓存各自的内存,每个CPU在各自缓存取内存的时间是最快的。
/*
* The slab lists for all objects.
*/
struct kmem_cache_node {
spinlock_t list_lock;
....
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};其中nr_partial表示该 node 节点中缓存的 slab 个数, struct list_head partial链表用于组织串联node节点中缓存的slabs。
当上述node节点也没有可用的空闲内存时,内核才从伙伴系统中申请内存页到slab缓冲池中使用。
总结上述数据流程,进程申请内存时,先从缓存freelist指向的空闲对象查找,如果此时没有空闲内存,则从备用的缓存partial中查找,当partial用完再从每个CPU节点node中查找对应的内存,当在slab cache中找不到可用的内存时,才从伙伴系统中申请内存。
4.3 slab内存的释放
4.3.1 关于各个slab对象和内存数量的限制
在struct kmem_cache中,cpu_partial是有关于struct kmem_cache_cpu __percpu *cpu_slab里partial链表中slab的数量限制,它限定slab cache在每个cpu本地缓存partial链表中缓存的所有 slab 中空闲对象的总数,cpu本地缓存partial 链表中空闲对象的数量超过该值,则会将cpu本地缓存partial链表中的所有slab转移到NUMA node 缓存中。
内核向伙伴系统申请多少内存页是由 struct kmem_cache 结构中的 oo 来决定的,它的高 16 位表示一个 slab 所需要的内存页个数,低 16 位表示 slab 中所包含的对象总数。当系统中空闲内存不足时,无法获得 oo 指定的内存页个数,那么内核会降级采用 min 指定的内存页个数,重新到伙伴系统中去申请。
4.3.2 释放的几种情况
当释放的对象之前所属的slab是本地缓存时直接放回,当所属的slab是缓存中的kmem_cache_cpu->partial 链表,此时如果空闲对象数量没超过cpu_partial/2,则直接放回,否则将整个partial移动到kmem_cache_node->partial(这种情况下说明这些内存被频繁释放,避免因为释放而频繁转移)。
当释放对象所属的slab从partial slab(既有空闲也有被占用的)变成 empty slab(所有对象都是空闲的)时,内核将会把该 slab 插入到 slab cache 的备用仓库 NUMA 节点缓存中。但是 kmem_cache_node->partial 链表中的 slab 不可能是无限增长的,链表中缓存的 slab 个数受到 kmem_cache 结构中 min_partial 属性的限制, kmem_cache_node->partial 的缓存的 slab 个数 nr_partial 超过了 min_partial 的限制,则直接将 slab 释放回伙伴系统中。
5 slab内核源码分析
5.1 内核启动过程对slab cache的初始化
在内核启动如下调用栈过程中,内核会先建立一个全局的slab cache,提供后续创建流程,创建kmem_cache对象的内存使用。
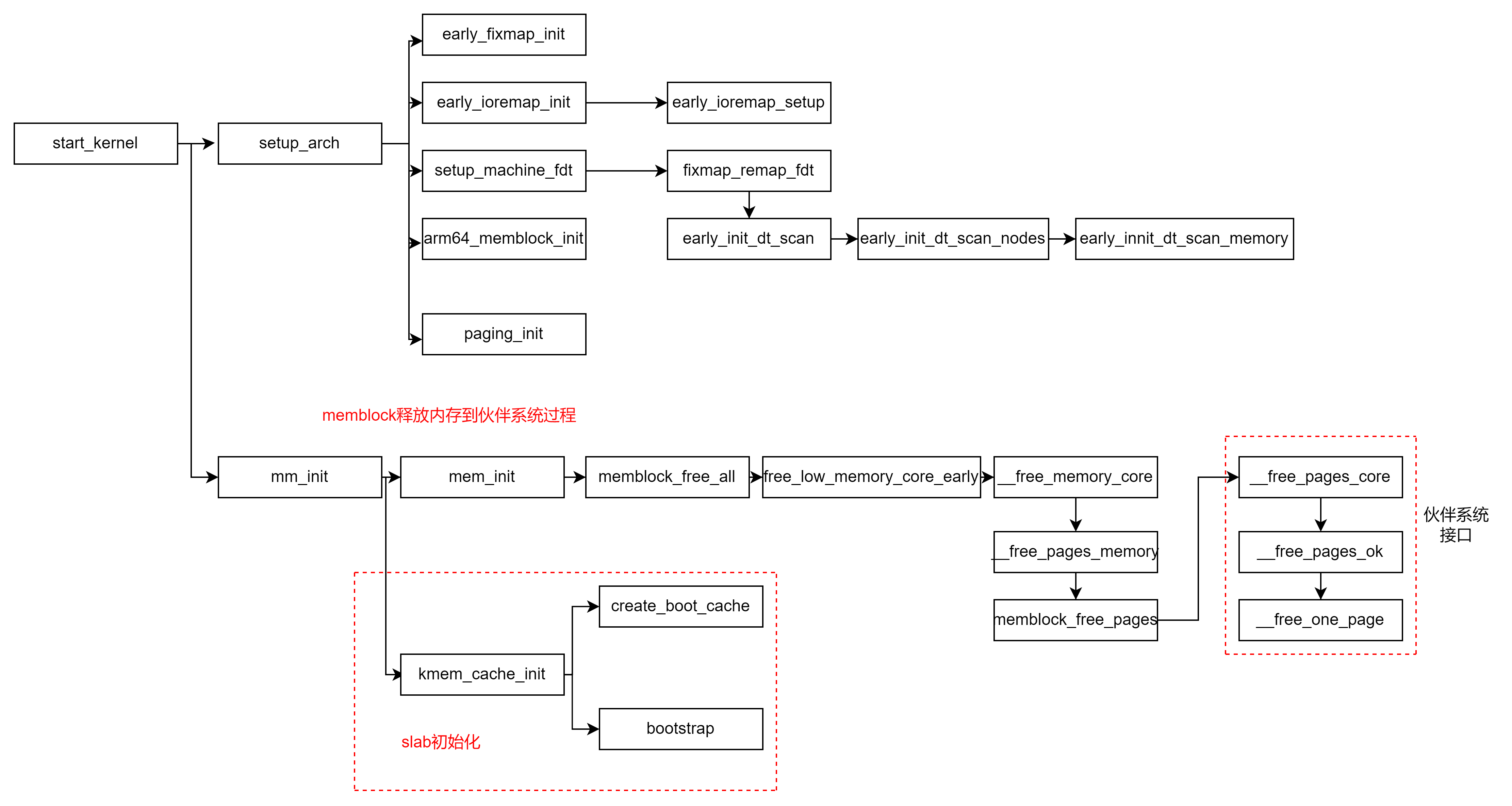
内核专门为每个kmem_cache和kmem_cache_node定义全局管理对象mm/slab_common.c
struct kmem_cache *kmem_cache;和mm/slub.c
static struct kmem_cache *kmem_cache_node;在启动过程调用kmem_cache_init对上述两个全局对象进行初始化
/*
// 全局变量,用于专门管理 kmem_cache 对象的 slab cache
// 定义在文件:/mm/slab_common.c
struct kmem_cache *kmem_cache;
// 全局变量,用于专门管理 kmem_cache_node 对象的 slab cache
// 定义在文件:/mm/slub.c
static struct kmem_cache *kmem_cache_node;
*/
void __init kmem_cache_init(void)
{
// slab allocator 体系结构中最核心的就是 kmem_cache 结构和 kmem_cache_node 结构,而这两个结构同时又被各自的 slab cache 所管理
// 而现在 slab allocator 体系还未创建,所以需要利用两个静态的结构来创建kmem_cache,kmem_cache_node 对象
// 这里就是定义两个 kmem_cache 类型的静态局部变量(静态结构):内核启动的时候被加载进 BSS 段中,随后会为其分配内存。
// boot_kmem_cache 用于临时创建 kmem_cache 结构。
// boot_kmem_cache_node 用于临时创建 kmem_cache_node 结构
// boot_kmem_cache 和 boot_kmem_cache_node 现在只是两个空的结构,需要静态的进行初始化。
static __initdata struct kmem_cache boot_kmem_cache,
boot_kmem_cache_node;
int node;
if (debug_guardpage_minorder())
slub_max_order = 0;
/* Print slub debugging pointers without hashing */
if (__slub_debug_enabled())
no_hash_pointers_enable(NULL);
// 暂时先将这两个静态结构赋值给对应的全局变量,后面会初始化这两个全局变量
kmem_cache_node = &boot_kmem_cache_node;
kmem_cache = &boot_kmem_cache;
/*
* Initialize the nodemask for which we will allocate per node
* structures. Here we don't need taking slab_mutex yet.
*/
for_each_node_state(node, N_NORMAL_MEMORY)
node_set(node, slab_nodes);
// 静态地初始化 boot_kmem_cache_node
// 从这里可以看出 slab体系,建立的第一个 slab cache 就是 kmem_cache_node(slab cache)
create_boot_cache(kmem_cache_node, "kmem_cache_node",
sizeof(struct kmem_cache_node), SLAB_HWCACHE_ALIGN, 0, 0);
register_hotmemory_notifier(&slab_memory_callback_nb);
// 当 kmem_cache_node (slab cache)被创建初始化之后,slab_state 变为 PARTIAL
// 这个状态表示目前 kmem_cache_node cache已经创建完毕,可以利用它动态分配 kmem_cache_node 对象了。
/* Able to allocate the per node structures */
slab_state = PARTIAL;
// 静态地初始化 boot_kmem_cache
// 从这里可以看出 slab 体系,建立的第二个 slab cache 就是 kmem_cache(slab cache)
create_boot_cache(kmem_cache, "kmem_cache",
offsetof(struct kmem_cache, node) +
nr_node_ids * sizeof(struct kmem_cache_node *),
SLAB_HWCACHE_ALIGN, 0, 0);
// 流程到这里,两个静态的 kmem_cache 结构:boot_kmem_cache,boot_kmem_cache_node 就已经初始化完毕了。
// 但是这两个静态结构只是临时的,目的是为了在 slab 体系初始化阶段静态的创建 kmem_cache 对象和 kmem_cache_node 对象。
// 在 bootstrap 中会将 boot_kmem_cache,boot_kmem_cache_node 中的内容深拷贝到最终的 kmem_cache(slab cache),kmem_cache_node(slab cache)中。
// 后面我们就可以利用这两个最终的核心结构来动态的进行 slab 创建。
kmem_cache = bootstrap(&boot_kmem_cache);
kmem_cache_node = bootstrap(&boot_kmem_cache_node);
/* Now we can use the kmem_cache to allocate kmalloc slabs */
setup_kmalloc_cache_index_table();
create_kmalloc_caches(0);
/* Setup random freelists for each cache */
init_freelist_randomization();
cpuhp_setup_state_nocalls(CPUHP_SLUB_DEAD, "slub:dead", NULL,
slub_cpu_dead);
pr_info("SLUB: HWalign=%d, Order=%u-%u, MinObjects=%u, CPUs=%u, Nodes=%u\n",
cache_line_size(),
slub_min_order, slub_max_order, slub_min_objects,
nr_cpu_ids, nr_node_ids);
}该函数先定义了两个静态struct kmem_cache结构体对象boot_kmem_cache,boot_kmem_cache_node,通过create_boot_cache函数,对两个对象进行slab内存结构初始化(后续章节详述该过程),再调用bootstrap从boot_kmem_cache,boot_kmem_cache_node分别申请出struct kmem_cache大小和struct kmem_cache_node大小内存,将boot_kmem_cache,boot_kmem_cache_node的全部内容拷贝到当前内存后,再重新赋值给全局kmem_cache_node和kmem_cache。
在后续章节分析可知道每次创建slab cache时,都会从kmem_cache和kmem_cache_node中申请出一个struct kmem_cache和struct kmem_cache_node,即这两个kmem_cache和kmem_cache_node是专门用于管理kmem_cache 对象的slab cache和kmem_cache_node对象的 slab cache。
其中bootstrap实现如上述,主要进行对两个静态的boot_kmem_cache,boot_kmem_cache_node变量进行深拷贝,将新申请的kmem_cache加入前面章节讲的用于维护slab cache的全局链表slab_caches。
static struct kmem_cache * __init bootstrap(struct kmem_cache *static_cache)
{
int node;
// kmem_cache 指向专门管理 kmem_cache 对象的 slab cache
// 该 slab cache 现在已经全部初始化完毕,可以利用它动态的分配最终的 kmem_cache 对象
struct kmem_cache *s = kmem_cache_zalloc(kmem_cache, GFP_NOWAIT);
struct kmem_cache_node *n;
// 将静态的 kmem_cache 对象,比如:boot_kmem_cache,boot_kmem_cache_node
// 深拷贝到最终的 kmem_cache 对象 s 中
memcpy(s, static_cache, kmem_cache->object_size);
/*
* This runs very early, and only the boot processor is supposed to be
* up. Even if it weren't true, IRQs are not up so we couldn't fire
* IPIs around.
*/
// 释放本地 cpu 缓存的 slab
__flush_cpu_slab(s, smp_processor_id());
// 遍历 node cache 数组,修正 kmem_cache_node 结构中 partial 链表中包含的 slab ( page 表示)对应 page 结构的 slab_cache 指针
// 使其指向最终的 kmem_cache 结构,之前在 create_boot_cache 中指向的静态 kmem_cache 结构,这里需要修正
for_each_kmem_cache_node(s, node, n) {
struct page *p;
list_for_each_entry(p, &n->partial, slab_list)
p->slab_cache = s;
#ifdef CONFIG_SLUB_DEBUG
list_for_each_entry(p, &n->full, slab_list)
p->slab_cache = s;
#endif
}
// 将最终的 kmem_cache 结构加入到全局 slab cache 链表中
list_add(&s->list, &slab_caches);
return s;
}5.2 slab cache的创建流程
slab cache的创建,涉及以下创建的函数,本节将按照如下函数调用栈过程,逐一分析每个函数调用过程的作用。
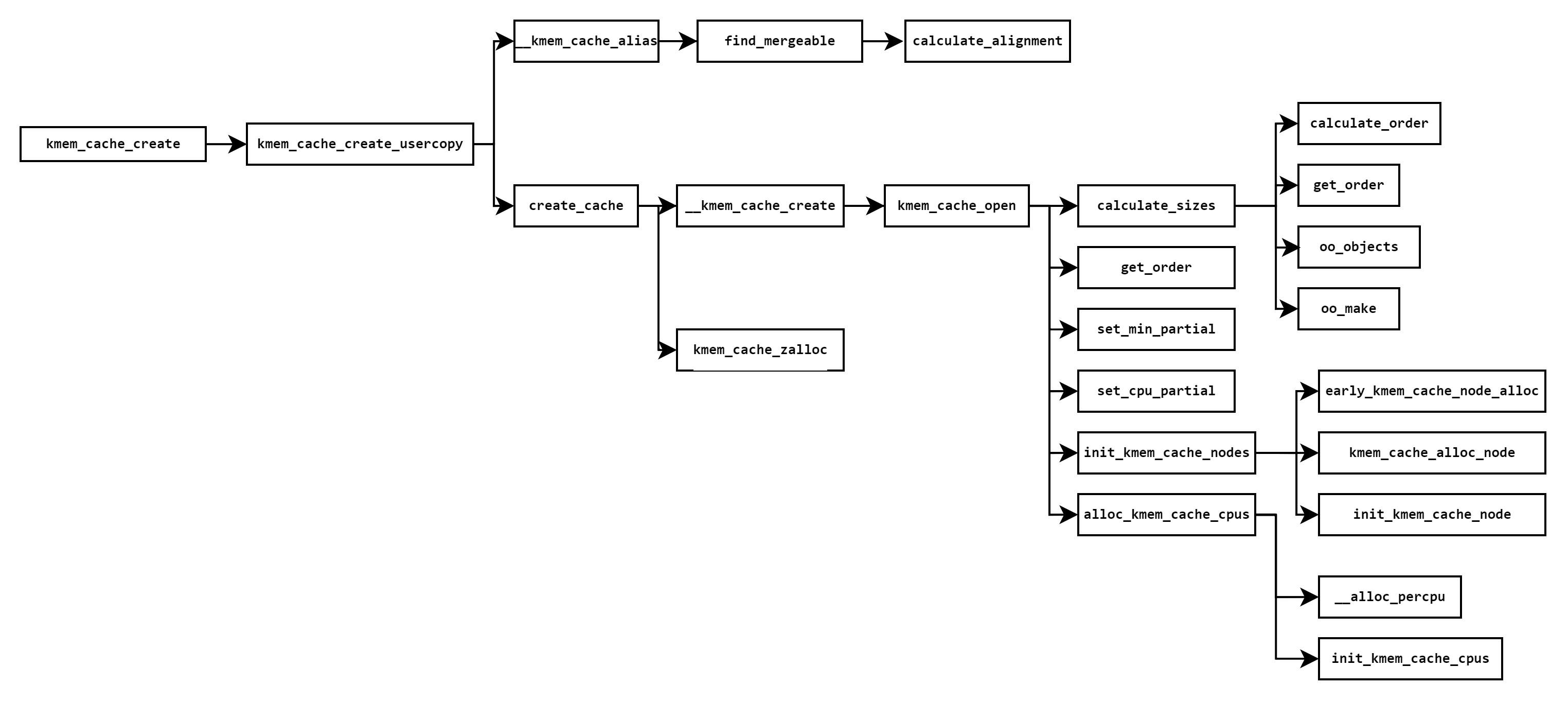
函数调用过程,主要是对struct kmem_cache结构体进行初始化,关系到后续内存申请的内存布局,struct kmem_cache结构各成员含义需要先了解下:
/*
* Slab cache management.
*/
struct kmem_cache {
// 每个 cpu 拥有一个本地缓存,用于无锁化快速分配释放对象
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retrieving partial slabs, etc. */
// slab cache 的管理标志位,用于设置 slab 的一些特性
slab_flags_t flags;
// slab cache 在 numa node 中缓存的 slab 个数上限,slab 个数超过该值,空闲的 empty slab 则会被回收至伙伴系统
unsigned long min_partial;
// slab 中管理的对象大小,注意:这里包含对象为了对齐所填充的字节数
unsigned int size; /* The size of an object including metadata */
// 对应参数 size,指 slab 中对象的实际大小,不包含填充的字节数
unsigned int object_size;/* The size of an object without metadata */
struct reciprocal_value reciprocal_size;
// slab 对象池中的对象在没有被分配之前,我们是不关心对象里边存储的内容的。
// 内核巧妙的利用对象占用的内存空间存储下一个空闲对象的地址。
// offset 表示用于存储下一个空闲对象指针的位置距离对象首地址的偏移
unsigned int offset; /* Free pointer offset */
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* Number of per cpu partial objects to keep around */
unsigned int cpu_partial;
#endif
// 表示 cache 中的 slab 大小,包括 slab 所申请的页面个数,以及所包含的对象个数
// 其中低 16 位表示一个 slab 中所包含的对象总数,高 16 位表示一个 slab 所占有的内存页个数。
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
// slab 中所能包含对象以及内存页个数的最大值
struct kmem_cache_order_objects max;
// 当按照 oo 的尺寸为 slab 申请内存时,如果内存紧张,会采用 min 的尺寸为 slab 申请内存,可以容纳一个对象即可。
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
// slab cache 的引用计数,为 0 时就可以销毁并释放内存回伙伴系统重
int refcount; /* Refcount for slab cache destroy */
// 池化对象的构造函数,用于创建 slab 对象池中的对象
void (*ctor)(void *);
// 对象的 object_size 按照 word 字长对齐之后的大小
unsigned int inuse; /* Offset to metadata */
// 对象按照指定的 align 进行对齐
unsigned int align; /* Alignment */
unsigned int red_left_pad; /* Left redzone padding size */
// slab cache 的名称, 也就是在 slabinfo 命令中 name 那一列
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
#ifdef CONFIG_SYSFS
struct kobject kobj; /* For sysfs */
#endif
#ifdef CONFIG_SLAB_FREELIST_HARDENED
unsigned long random;
#endif
#ifdef CONFIG_NUMA
/*
* Defragmentation by allocating from a remote node.
*/
unsigned int remote_node_defrag_ratio;
#endif
#ifdef CONFIG_SLAB_FREELIST_RANDOM
unsigned int *random_seq;
#endif
#ifdef CONFIG_KASAN
struct kasan_cache kasan_info;
#endif
unsigned int useroffset; /* Usercopy region offset */
unsigned int usersize; /* Usercopy region size */
// slab cache 中 numa node 中的缓存,每个 node 一个
struct kmem_cache_node *node[MAX_NUMNODES];
};5.1.1 创建slab cache的准备
kmem_cache_create 函数直接调用kmem_cache_create_usercopy,其中kmem_cache_create_usercopy的useroffset和usersize参数表示指定内核对象内存布局区域中 useroffset 到 usersize 的这段内存区域可以被复制到用户空间中,其他区域则不可以。这里kmem_cache_create除了透传参数给kmem_cache_create_usercopy,还将可复制给调用者内存区域置为0(目的其实是为了防止 slab cache 中管理的内核核心对象被泄露)。
struct kmem_cache *
kmem_cache_create(const char *name, unsigned int size, unsigned int align,
slab_flags_t flags, void (*ctor)(void *))
{
return kmem_cache_create_usercopy(name, size, align, flags, 0, 0,
ctor);
}
EXPORT_SYMBOL(kmem_cache_create);
struct kmem_cache *
kmem_cache_create_usercopy(const char *name,
unsigned int size, unsigned int align,
slab_flags_t flags,
unsigned int useroffset, unsigned int usersize,
void (*ctor)(void *))
{
struct kmem_cache *s = NULL;
const char *cache_name;
int err;
#ifdef CONFIG_SLUB_DEBUG
/*
* If no slub_debug was enabled globally, the static key is not yet
* enabled by setup_slub_debug(). Enable it if the cache is being
* created with any of the debugging flags passed explicitly.
*/
if (flags & SLAB_DEBUG_FLAGS)
static_branch_enable(&slub_debug_enabled);
#endif
// 获取 slab cache 链表的全局互斥锁
mutex_lock(&slab_mutex);
// 入参检查,校验 name 和 size 的有效性,防止创建过程在中断上下文中进行
err = kmem_cache_sanity_check(name, size);
if (err) {
goto out_unlock;
}
/* Refuse requests with allocator specific flags */
// 检查有效的 slab flags 标记位,如果传入的 flag 是无效的,则拒绝本次创建请求
if (flags & ~SLAB_FLAGS_PERMITTED) {
err = -EINVAL;
goto out_unlock;
}
/*
* Some allocators will constraint the set of valid flags to a subset
* of all flags. We expect them to define CACHE_CREATE_MASK in this
* case, and we'll just provide them with a sanitized version of the
* passed flags.
*/
flags &= CACHE_CREATE_MASK;// 设置创建 slab cache 时用到的一些标志位
/* Fail closed on bad usersize of useroffset values. */
// 校验 useroffset 和 usersize 的有效性
if (WARN_ON(!usersize && useroffset) ||
WARN_ON(size < usersize || size - usersize < useroffset))
usersize = useroffset = 0;
if (!usersize)
// 在全局 slab cache 链表中查找与当前创建参数相匹配的 kmem_cache
// 如果有,就不需要创建新的了,直接和已有的 slab cache 合并
// 并且在 sys 文件系统中使用指定的 name 作为已有 slab cache 的别名
s = __kmem_cache_alias(name, size, align, flags, ctor);
if (s)
goto out_unlock;//找到合适的slab cache可复用,直接返回可用slab cache
// 在内核中为指定的 name 生成字符串常量并分配内存
// 这里的 cache_name 就是将要创建的 slab cache 名称,用于在 /proc/slabinfo 中显示
cache_name = kstrdup_const(name, GFP_KERNEL);
if (!cache_name) {
err = -ENOMEM;
goto out_unlock;
}
// 按照我们指定的参数,创建新的 slab cache
s = create_cache(cache_name, size,
calculate_alignment(flags, align, size),
flags, useroffset, usersize, ctor, NULL);
if (IS_ERR(s)) {
err = PTR_ERR(s);
kfree_const(cache_name);
}
out_unlock:
mutex_unlock(&slab_mutex);
if (err) {
if (flags & SLAB_PANIC)
panic("%s: Failed to create slab '%s'. Error %d\n",
__func__, name, err);
else {
pr_warn("%s(%s) failed with error %d\n",
__func__, name, err);
dump_stack();
}
return NULL;
}
return s;
}
EXPORT_SYMBOL(kmem_cache_create_usercopy);kmem_cache_create_usercopy主要做了三件事:
(1)参数检查:kmem_cache_sanity_check检查创建的size是否超过KMALLOC_MAX_SIZE 4M,是否处于中断上下文
static int kmem_cache_sanity_check(const char *name, unsigned int size)
{
// 1: 传入 slab cache 的名称不能为空
// 2: 创建 slab cache 的过程不能处在中断上下文中
// 3: 传入的对象大小 size 需要在 8 字节到 KMALLOC_MAX_SIZE = 4M 之间
if (!name || in_interrupt() || size > KMALLOC_MAX_SIZE) {
pr_err("kmem_cache_create(%s) integrity check failed\n", name);
return -EINVAL;
}
WARN_ON(strchr(name, ' ')); /* It confuses parsers */
return 0;
}另外还进行了flags、useroffset等参数合法性检查。
(2)调用__kmem_cache_alias进行复用合并检查,即如果当前存在一个满足用户需要创建的slab cache,则直接复用已存在的slab cache,不重新创建直接返回已有的slab cache给用户。
struct kmem_cache *
__kmem_cache_alias(const char *name, unsigned int size, unsigned int align,
slab_flags_t flags, void (*ctor)(void *))
{
struct kmem_cache *s;
// 在全局 slab cache 链表中查找与当前创建参数相匹配的 slab cache
// 如果在全局查找到一个 slab cache,它的核心参数和我们指定的创建参数很贴近
// 那么就没必要再创建新的 slab cache了,复用已有的 slab cache
s = find_mergeable(size, align, flags, name, ctor);
if (s) {
// 如果存在可复用的 kmem_cache,则将它的引用计数 + 1
s->refcount++;
/*
* Adjust the object sizes so that we clear
* the complete object on kzalloc.
*/
// 采用较大的值,更新已有的 kmem_cache 相关的元数据
s->object_size = max(s->object_size, size);
s->inuse = max(s->inuse, ALIGN(size, sizeof(void *)));
// 由于这里我们会复用已有的 kmem_cache 并不会创建新的,而且我们指定的 kmem_cache 名称是 name。
// 为了看起来像是创建了一个名称为 name 的新 kmem_cache,所以要给被复用的 kmem_cache 起一个别名,这个别名就是我们指定的 name
// 在 sys 文件系统中使用我们指定的 name 为被复用 kmem_cache 创建别名
// 这样一来就会在 sys 文件系统中出现一个这样的目录 /sys/kernel/slab/'name' ,该目录下的文件包含了对应 slab cache 运行时的详细信息
if (sysfs_slab_alias(s, name)) {
s->refcount--;
s = NULL;
}
}
return s;
}__kmem_cache_alias调用find_mergeable找到合适的slab cache后,调整了一个slab对象的大小,增加引用,同事在/sys/kernel/slab/"slab_cache_name"文件系统创建链接指向匹对到的slab cache文件。
find_mergeable进行参数匹对时,匹配主要包括:
指定对象 size 不能超过已有 slab cache 中的对象 size
指定的 flag 是否与已有 slab cache 中的 flag 一致
两者的 size 相差在一个 word size 之内
已有 slab cache 中对象的对齐 align 要大于等于指定的 align并且可以整除 align。
struct kmem_cache *find_mergeable(unsigned int size, unsigned int align,
slab_flags_t flags, const char *name, void (*ctor)(void *))
{
struct kmem_cache *s;
if (slab_nomerge)
return NULL;
if (ctor)
return NULL;
// 与 word size 进行对齐
size = ALIGN(size, sizeof(void *));
// 根据我们指定的对齐参数 align 并结合 CPU cache line 大小,计算出一个合适的对齐参数
align = calculate_alignment(flags, align, size);
// 对象 size 重新按照 align 进行对齐
size = ALIGN(size, align);
flags = kmem_cache_flags(size, flags, name);
// 如果 flag 设置的是不允许合并,则停止
if (flags & SLAB_NEVER_MERGE)
return NULL;
// 开始遍历内核中已有的 slab cache,寻找可以合并的 slab cache
list_for_each_entry_reverse(s, &slab_caches, list) {
if (slab_unmergeable(s))
continue;
// 指定对象 size 不能超过已有 slab cache 中的对象 size
if (size > s->size)
continue;
// 校验指定的 flag 是否与已有 slab cache 中的 flag 一致
if ((flags & SLAB_MERGE_SAME) != (s->flags & SLAB_MERGE_SAME))
continue;
/*
* Check if alignment is compatible.
* Courtesy of Adrian Drzewiecki
*/
if ((s->size & ~(align - 1)) != s->size)
continue;
// 两者的 size 相差在一个 word size 之内
if (s->size - size >= sizeof(void *))
continue;
// 已有 slab cache 中对象的对齐 align 要大于等于指定的 align并且可以整除 align。
if (IS_ENABLED(CONFIG_SLAB) && align &&
(align > s->align || s->align % align))
continue;
// 查找到可以合并的已有 slab cache,不需要再创建新的 slab cache 了
return s;
}
return NULL;
}find_mergeable遍历了管理slab cache的全局链表slab_caches,以此比对了上述参数,如果全局符合,则直接使用匹对到的slab cache返回给用户。
(3)调用create_cache开始创建新的slab cache缓存池对象。
5.1.2 create_cache开始创建一个slab cache
上节提到create_cache用于真正开始创建一个slab cache:
static struct kmem_cache *create_cache(const char *name,
unsigned int object_size, unsigned int align,
slab_flags_t flags, unsigned int useroffset,
unsigned int usersize, void (*ctor)(void *),
struct kmem_cache *root_cache)
{
struct kmem_cache *s;
int err;
if (WARN_ON(useroffset + usersize > object_size))
useroffset = usersize = 0;
err = -ENOMEM;
// 为将要创建的 slab cache 分配 kmem_cache 结构
// kmem_cache 也是内核的一个核心数据结构,同样也会被它对应的 slab cache 所管理
// 这里就是从 kmem_cache 所属的 slab cache 中拿出一个 kmem_cache 对象出来
s = kmem_cache_zalloc(kmem_cache, GFP_KERNEL);
if (!s)
goto out;
// 利用我们指定的创建参数初始化 kmem_cache 结构
s->name = name;
s->size = s->object_size = object_size;
s->align = align;
s->ctor = ctor;
s->useroffset = useroffset;
s->usersize = usersize;
// 创建 slab cache 的核心函数,这里会初始化 kmem_cache 结构中的其他重要属性
// 包括创建初始化 kmem_cache_cpu 和 kmem_cache_node 结构
err = __kmem_cache_create(s, flags);
if (err)
goto out_free_cache;
// slab cache 初始状态下,引用计数为 1
s->refcount = 1;
// 将刚刚创建出来的 slab cache 加入到 slab cache 在内核中的全局链表管理
list_add(&s->list, &slab_caches);
out:
if (err)
return ERR_PTR(err);
return s;
out_free_cache:
kmem_cache_free(kmem_cache, s);
goto out;
}create_cache并未对slab cache的内存布局参数进行初始化,先调用kmem_cache_zalloc生成一个struct kmem_cache(kmem_cache_zalloc申请的内存来自之前分析的kmem_cache,kmem_cache_zalloc的实现在后续内存申请章节分析),初始化了结构体非内存组织相关参数,再调用__kmem_cache_create初始化 kmem_cache 结构中的其他重要属性,包括创建初始化 kmem_cache_cpu 和 kmem_cache_node 结构。最后将该对象加入slab_caches全局链表(本文开头提到过slab cache都被加入一个全局链表slab_caches)。
__kmem_cache_create调用kmem_cache_open,是创建 slab cache 的核心函数,真正的对缓存和NUMA cpu节点缓存进行初始化的流程:
int __kmem_cache_create(struct kmem_cache *s, slab_flags_t flags)
{
int err;
// 核心函数,在这里会初始化 kmem_cache 的其他重要属性
err = kmem_cache_open(s, flags);
if (err)
return err;
// 检查内核中 slab 分配器的整体体系是否已经初始化完毕,只有状态是 FULL 的时候才是初始化完毕,其他的状态表示未初始化完毕。
// 在 slab allocator 体系初始化的时候在 slab_sysfs_init 函数中将 slab_state 设置为 FULL
/* Mutex is not taken during early boot */
if (slab_state <= UP)
return 0;
// 在 sys 文件系统中创建 /sys/kernel/slab/"name" 节点,该目录下的文件包含了对应 slab cache 运行时的详细信息
err = sysfs_slab_add(s);
if (err) {
__kmem_cache_release(s);// 出现错误则释放 kmem_cache 结构
return err;
}
if (s->flags & SLAB_STORE_USER)
debugfs_slab_add(s);
return 0;
}此外还对slab状态进行检查,在文件系统/sys/kernel/slab/"name"创建name节点
kmem_cache_open实现在mm\slub.c
static int kmem_cache_open(struct kmem_cache *s, slab_flags_t flags)
{
s->flags = kmem_cache_flags(s->size, flags, s->name);
#ifdef CONFIG_SLAB_FREELIST_HARDENED
s->random = get_random_long();
#endif
// 计算 slab 中对象的整体内存布局所需要的 size
// slab 所需最合适的内存页面大小 order,slab 中所能容纳的对象个数
// 初始化 slab cache 中的核心参数 oo ,min,max的值
if (!calculate_sizes(s, -1))
goto error;
if (disable_higher_order_debug) {
/*
* Disable debugging flags that store metadata if the min slab
* order increased.
*/
if (get_order(s->size) > get_order(s->object_size)) {
s->flags &= ~DEBUG_METADATA_FLAGS;
s->offset = 0;
if (!calculate_sizes(s, -1))
goto error;
}
}
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
if (system_has_cmpxchg_double() && (s->flags & SLAB_NO_CMPXCHG) == 0)
/* Enable fast mode */
s->flags |= __CMPXCHG_DOUBLE;
#endif
/*
* The larger the object size is, the more pages we want on the partial
* list to avoid pounding the page allocator excessively.
*/
// 设置 slab cache 在 node 缓存 kmem_cache_node 中的 partial 列表中 slab 的最小个数 min_partial
set_min_partial(s, ilog2(s->size) / 2);
// 设置 slab cache 在 cpu 本地缓存的 partial 列表中所能容纳的最大空闲对象个数
set_cpu_partial(s);
#ifdef CONFIG_NUMA
s->remote_node_defrag_ratio = 1000;
#endif
/* Initialize the pre-computed randomized freelist if slab is up */
if (slab_state >= UP) {
if (init_cache_random_seq(s))
goto error;
}
// 为 slab cache 创建并初始化 node cache 数组
if (!init_kmem_cache_nodes(s))
goto error;
// 为 slab cache 创建并初始化 cpu 本地缓存列表
if (alloc_kmem_cache_cpus(s))
return 0;
error:
__kmem_cache_release(s);
return -EINVAL;
}kmem_cache_open主要调用calculate_sizes对slab内存参数进行初始化;设置了slab cache的partial内存个数限制,CPU node的内存个数限制;调用init_kmem_cache_nodes申请初始化CPU node内存参数,最后调用alloc_kmem_cache_cpus对slab cache 本地缓存列表cpu_slab进行初始化。
(1)调用calculate_sizes
计算 slab 中对象的整体内存布局所需要的size,slab所需最合适的内存页面大小 order,slab 中所能容纳的对象个数初始化 slab cache 中的核心参数 oo,min,max的值。
static int calculate_sizes(struct kmem_cache *s, int forced_order)
{
slab_flags_t flags = s->flags;
unsigned int size = s->object_size;
unsigned int order;
/*
* Round up object size to the next word boundary. We can only
* place the free pointer at word boundaries and this determines
* the possible location of the free pointer.
*/
// 为了提高 cpu 访问对象的速度,slab 对象的 object size 首先需要与 word size 进行对齐
size = ALIGN(size, sizeof(void *));
#ifdef CONFIG_SLUB_DEBUG
/*
* Determine if we can poison the object itself. If the user of
* the slab may touch the object after free or before allocation
* then we should never poison the object itself.
*/
if ((flags & SLAB_POISON) && !(flags & SLAB_TYPESAFE_BY_RCU) &&
!s->ctor)
s->flags |= __OBJECT_POISON;
else
s->flags &= ~__OBJECT_POISON;
/*
* If we are Redzoning then check if there is some space between the
* end of the object and the free pointer. If not then add an
* additional word to have some bytes to store Redzone information.
*/
if ((flags & SLAB_RED_ZONE) && size == s->object_size)
size += sizeof(void *);
#endif
/*
* With that we have determined the number of bytes in actual use
* by the object and redzoning.
*/
// inuse 表示 slab 中的对象实际使用的内存区域大小
// 该值是经过与 word size 对齐之后的大小,如果设置了 SLAB_RED_ZONE,则也包括红**域大小
s->inuse = size;
if ((flags & (SLAB_TYPESAFE_BY_RCU | SLAB_POISON)) ||
((flags & SLAB_RED_ZONE) && s->object_size < sizeof(void *)) ||
s->ctor) {
/*
* Relocate free pointer after the object if it is not
* permitted to overwrite the first word of the object on
* kmem_cache_free.
*
* This is the case if we do RCU, have a constructor or
* destructor, are poisoning the objects, or are
* redzoning an object smaller than sizeof(void *).
*
* The assumption that s->offset >= s->inuse means free
* pointer is outside of the object is used in the
* freeptr_outside_object() function. If that is no
* longer true, the function needs to be modified.
*/
// 如果我们开启了 RCU 保护或者设置了对象 poison或者设置了对象的构造函数
// 这些都会占用对象中的内存空间。这种情况下,我们需要额外增加一个 word size 大小的空间来存放 free pointer,否则 free pointer 存储在对象的起始位置
// offset 为 free pointer 与对象起始地址的偏移
s->offset = size;
size += sizeof(void *);
} else {
/*
* Store freelist pointer near middle of object to keep
* it away from the edges of the object to avoid small
* sized over/underflows from neighboring allocations.
*/
s->offset = ALIGN_DOWN(s->object_size / 2, sizeof(void *));
}
#ifdef CONFIG_SLUB_DEBUG
if (flags & SLAB_STORE_USER)
/*
* Need to store information about allocs and frees after
* the object.
*/
size += 2 * sizeof(struct track);
#endif
kasan_cache_create(s, &size, &s->flags);
#ifdef CONFIG_SLUB_DEBUG
if (flags & SLAB_RED_ZONE) {
/*
* Add some empty padding so that we can catch
* overwrites from earlier objects rather than let
* tracking information or the free pointer be
* corrupted if a user writes before the start
* of the object.
*/
size += sizeof(void *);
s->red_left_pad = sizeof(void *);
s->red_left_pad = ALIGN(s->red_left_pad, s->align);
size += s->red_left_pad;
}
#endif
/*
* SLUB stores one object immediately after another beginning from
* offset 0. In order to align the objects we have to simply size
* each object to conform to the alignment.
*/
// slab 从它所申请的内存页 offset 0 开始,一个接一个的存储对象
// 调整对象的 size 保证对象之间按照指定的对齐方式 align 进行对齐
size = ALIGN(size, s->align);
s->size = size;
s->reciprocal_size = reciprocal_value(size);
if (forced_order >= 0)//-1
order = forced_order;
else
order = calculate_order(size);// 计算 slab 所需要申请的内存页数(2 ^ order 个内存页)
if ((int)order < 0)
return 0;
// 根据 slab 的 flag 设置,设置向伙伴系统申请内存时使用的 allocflags
s->allocflags = 0;
if (order)
s->allocflags |= __GFP_COMP;
if (s->flags & SLAB_CACHE_DMA)
s->allocflags |= GFP_DMA;
if (s->flags & SLAB_CACHE_DMA32)
s->allocflags |= GFP_DMA32;
if (s->flags & SLAB_RECLAIM_ACCOUNT)
s->allocflags |= __GFP_RECLAIMABLE;
/*
* Determine the number of objects per slab
*/
// 计算 slab cache 中的 oo,min,max 值
// 一个 slab 到底需要多少个内存页,能够存储多少个对象
// 低 16 为存储 slab 所能包含的对象总数,高 16 为存储 slab 所需的内存页个数
s->oo = oo_make(order, size);
// get_order 函数计算出的 order 为容纳一个 size 大小的对象至少需要的内存页个数
s->min = oo_make(get_order(size), size);
if (oo_objects(s->oo) > oo_objects(s->max))
s->max = s->oo;// 初始时 max 和 oo 相等
return !!oo_objects(s->oo);// 返回 slab 中所能容纳的对象个数
}在内核打开CONFIG_SLUB_DEBUG下,函数会检查用户是否打SLAB_POISON (毒化,是 slab 中的一个术语,用于将对象所占内存填充某些特定的值,表示这块对象不同的使用状态,防止非法越界访问)、SLAB_RED_ZONE(表示需要再对象 object size 内存区域前后各插入一段 red zone 区域,目的是为了防止内存的读写越界)和SLAB_STORE_USER(表示我们期望跟踪 slab 对象的分配与释放相关的信息,而这些跟踪信息内核使用一个 struct track 结构来存储),这些将在slab对象大小中占一定空间,在不开启SLAB_POISON只有SLAB_RED_ZONE和SLAB_STORE_USER时,对象大小布局如下,其中offset是freepointer的偏移,用于指向下一个空闲size slab区域,size则是当前对象大小。

在开启SLAB_POISON时,对象空闲指针会被单独往后放,此时object对象里会先被填充成0x6d,最后一个字节填充成0xa5。
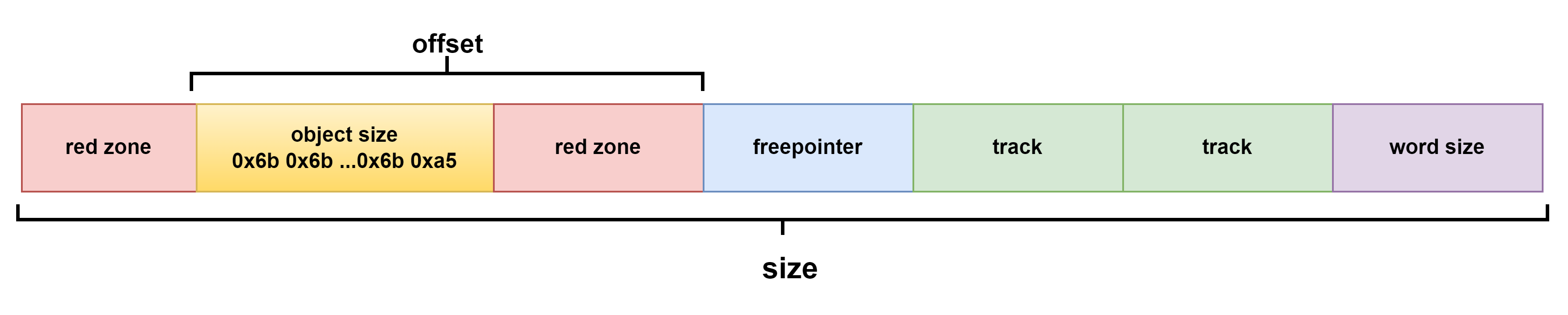
对上述对象size进行补充大小后,最后则构成了一个page里各个slab:

除了设置slab对象大小size外,函数还调用calculate_order设置了当前slab cache所需的page数量order(2 ^ order 个内存页):
static unsigned int slub_min_order;
static unsigned int slub_max_order = PAGE_ALLOC_COSTLY_ORDER;
static unsigned int slub_min_objects;
static inline int calculate_order(unsigned int size)
{
unsigned int order;
unsigned int min_objects;
unsigned int max_objects;
unsigned int nr_cpus;
/*
* Attempt to find best configuration for a slab. This
* works by first attempting to generate a layout with
* the best configuration and backing off gradually.
*
* First we increase the acceptable waste in a slab. Then
* we reduce the minimum objects required in a slab.
*/
// 计算 slab 中可以容纳的最小对象个数
min_objects = slub_min_objects;
if (!min_objects) {
/*
* Some architectures will only update present cpus when
* onlining them, so don't trust the number if it's just 1. But
* we also don't want to use nr_cpu_ids always, as on some other
* architectures, there can be many possible cpus, but never
* onlined. Here we compromise between trying to avoid too high
* order on systems that appear larger than they are, and too
* low order on systems that appear smaller than they are.
*/
nr_cpus = num_present_cpus();
if (nr_cpus <= 1)
nr_cpus = nr_cpu_ids;
// nr_cpu_ids 表示当前系统中的 cpu 个数
// fls 可以获取参数的最高有效 bit 的位数,比如 fls(0)=0,fls(1)=1,fls(4) = 3
// 如果当前系统中有4个cpu,那么 min_object 的初始值为 4*(3+1) = 16
min_objects = 4 * (fls(nr_cpus) + 1);
}
// slab 最大内存页 order 初始为 3,计算 slab 最大可容纳的对象个数
max_objects = order_objects(slub_max_order, size);
min_objects = min(min_objects, max_objects);
while (min_objects > 1) {
// slab 中的碎片控制系数,碎片大小不能超过 (slab所占内存大小 / fraction)
// fraction 值越大,slab 中所能容忍的碎片就越小
unsigned int fraction;
fraction = 16;
while (fraction >= 4) {
// 根据当前 fraction 计算 order,需要查找出能够使 slab 产生碎片最小化的 order 值出来
order = slab_order(size, min_objects,
slub_max_order, fraction);
// order 不能超过 max_order,否则需要降低 fraction,放宽对碎片的要求限制,重新循环计算
if (order <= slub_max_order)
return order;
fraction /= 2;
}
min_objects--;// 进一步放宽对 min_object 的要求,slab 会尝试少放一些对象
}
/*
* We were unable to place multiple objects in a slab. Now
* lets see if we can place a single object there.
*/
// 经过前边 while 循环的计算,我们无法在这一个 slab 中放置多个 size 大小的对象,因为 min_object = 1 的时候就退出循环了。
// 那么下面就会尝试看能不能只放入一个对象
order = slab_order(size, 1, slub_max_order, 1);
if (order <= slub_max_order)
return order;
/*
* Doh this slab cannot be placed using slub_max_order.
*/
// 流程到这里表示,我们要池化的对象 size 太大了,slub_max_order 都放不下
// 现在只能放宽对 max_order 的限制到 MAX_ORDER = 11
order = slab_order(size, 1, MAX_ORDER, 1);
if (order < MAX_ORDER)
return order;
return -ENOSYS;
}其中slub_min_objects表示slab中可以容纳的最小对象个数,该参数由内核启动参数"slub_min_objects="确定,当启动参数没有该参数配置时,默认为0。为0时min_objects的确定跟cpu个数有关,min_objects= 4 * (fls(nr_cpus) + 1)。最大可容纳对象个数max_objects通过slub_max_order确定。确定了最小最大可容纳对象个数后,通过while循环计算找出碎片化最小最合适的order,如果此时没有合适的order,就会尝试看能不能只放入一个对象,如果size太大,则诚实把max放宽到伙伴系统最大order尝试分配出一个合适的order:
static inline unsigned int slab_order(unsigned int size,
unsigned int min_objects, unsigned int max_order,
unsigned int fract_leftover)
{
unsigned int min_order = slub_min_order;
unsigned int order;
// 如果 2^min_order个内存页可以存放的对象个数超过 32767 限制
// 那么返回 size * MAX_OBJS_PER_PAGE 所需要的 order 减 1
if (order_objects(min_order, size) > MAX_OBJS_PER_PAGE)
return get_order(size * MAX_OBJS_PER_PAGE) - 1;
// 从 slab 所需要的最小 order 到最大 order 之间开始遍历,查找能够使 slab 碎片最小的 order 值
for (order = max(min_order, (unsigned int)get_order(min_objects * size));
order <= max_order; order++) {
// slab 在当前 order 下,所占用的内存大小
unsigned int slab_size = (unsigned int)PAGE_SIZE << order;
unsigned int rem;
rem = slab_size % size;// slab 的碎片大小:分配完 object 之后,所产生的碎片大小
// 碎片大小 rem 不能超过 slab_size / fract_leftover 即符合要求
if (rem <= slab_size / fract_leftover)
break;
}
return order;
}当找出合适order后,最后是配置oo,min,max 三个值。
oo表示一个 slab 到底需要多少个内存页,能够存储多少个对象,低16 bit为存储slab所能包含的对象总数,高16bit为存储slab所需的内存页个数。
s->oo = oo_make(order, size);
static inline struct kmem_cache_order_objects oo_make(unsigned int order,
unsigned int size)
{
struct kmem_cache_order_objects x = {
(order << OO_SHIFT) + order_objects(order, size)
};
return x;
}min表示当按照 oo 的尺寸为 slab 申请内存时,如果内存紧张会采用 min 的尺寸为 slab 申请内存,可以容纳一个对象即可。
s->min = oo_make(get_order(size), size);
if (oo_objects(s->oo) > oo_objects(s->max))
s->max = s->oo;// 初始时 max 和 oo 相等函数最后返回 slab 中所能容纳的对象个数。
(2)设置 CPU本地缓存数量限制
kmem_cache_open调用calculate_sizes后完成了最重要的slab对象大小和页数量设置后,调用set_min_partial和set_cpu_partial分别配置了slab cache在node缓存 kmem_cache_node中的 partial 列表中 slab 的最小个数 min_partial,和slab cache在cpu本地缓存的partial列表中所能容纳的最大空闲对象个数:
static void set_min_partial(struct kmem_cache *s, unsigned long min)
{
if (min < MIN_PARTIAL)
min = MIN_PARTIAL;
else if (min > MAX_PARTIAL)
min = MAX_PARTIAL;
s->min_partial = min;
}
static void set_cpu_partial(struct kmem_cache *s)
{
#ifdef CONFIG_SLUB_CPU_PARTIAL
/*
* cpu_partial determined the maximum number of objects kept in the
* per cpu partial lists of a processor.
*
* Per cpu partial lists mainly contain slabs that just have one
* object freed. If they are used for allocation then they can be
* filled up again with minimal effort. The slab will never hit the
* per node partial lists and therefore no locking will be required.
*
* This setting also determines
*
* A) The number of objects from per cpu partial slabs dumped to the
* per node list when we reach the limit.
* B) The number of objects in cpu partial slabs to extract from the
* per node list when we run out of per cpu objects. We only fetch
* 50% to keep some capacity around for frees.
*/
if (!kmem_cache_has_cpu_partial(s))
slub_set_cpu_partial(s, 0);
else if (s->size >= PAGE_SIZE)
slub_set_cpu_partial(s, 2);
else if (s->size >= 1024)
slub_set_cpu_partial(s, 6);
else if (s->size >= 256)
slub_set_cpu_partial(s, 13);
else
slub_set_cpu_partial(s, 30);
#endif
}(3)创建slab cache的node数组
kmem_cache_open调用了init_kmem_cache_nodes为struct kmem_cache的struct kmem_cache_node *nodeMAX_NUMNODES成员分配对象,并调用init_kmem_cache_node进行初始化。
static int init_kmem_cache_nodes(struct kmem_cache *s)
{
int node;
// 遍历所有的 numa 节点,为 slab cache 创建 node cache
for_each_node_mask(node, slab_nodes) {
struct kmem_cache_node *n;
if (slab_state == DOWN) {
// 如果此时 slab allocator 体系还未建立,则调用该方法分配 kmem_cache_node 结构,并初始化。
// slab cache 的正常创建流程不会走到这个分支,该分支用于在内核初始化的时候创建 kmem_cache_node 对象池使用
early_kmem_cache_node_alloc(node); // 创建 boot_kmem_cache_node 时会走到这个分支
continue;
}
// 为 node cache 分配对应的 kmem_cache_node 对象
// kmem_cache_node 对象也由它对应的 slab cache 管理
n = kmem_cache_alloc_node(kmem_cache_node,
GFP_KERNEL, node);
if (!n) {
free_kmem_cache_nodes(s);
return 0;
}
// 初始化 node cache
init_kmem_cache_node(n);
s->node[node] = n;// 初始化 slab cache 结构 kmem_cache 中的 node 数组
}
return 1;
}其中kmem_cache_alloc_node申请的内存来自前面讲到的kmem_cache_node slab cache缓存池中。
alloc_kmem_cache_cpus则是为成员struct kmem_cache_cpu __percpu *cpu_slab,slab缓存对象申请对应CPU的内存。
static inline int alloc_kmem_cache_cpus(struct kmem_cache *s)
{
BUILD_BUG_ON(PERCPU_DYNAMIC_EARLY_SIZE <
KMALLOC_SHIFT_HIGH * sizeof(struct kmem_cache_cpu));
/*
* Must align to double word boundary for the double cmpxchg
* instructions to work; see __pcpu_double_call_return_bool().
*/
// 为 slab cache 分配 cpu 本地缓存结构 kmem_cache_cpu
// __alloc_percpu 函数在内核中专门用于分配 percpu 类型的结构体(the percpu allocator)
// kmem_cache_cpu 结构也是 percpu 类型的,这里通过 __alloc_percpu 直接分配
s->cpu_slab = __alloc_percpu(sizeof(struct kmem_cache_cpu),
2 * sizeof(void *));
if (!s->cpu_slab)
return 0;
// 初始化 cpu 本地缓存结构 kmem_cache_cpu
init_kmem_cache_cpus(s);
return 1;
}5.3 申请slab内存
总的来说,当用户调用kmem_cache_alloc申请内存时,slab的处理会经历两个大过程,一个是快速分配路径,另外一个是慢速分配路径。当当前缓存struct kemem_cache->freelist和page存在缓存内存时,此时会进入快速路径分配,直接从该缓存中申请内存后返回。如果缓存中没有内存,则会进入慢速路径,先检查struct kmem_cache->partial缓存列表是否有内存,有就直接申请返回,没有则检查struct kmem_cache->node CPU节点缓存,有则摘下当前空闲页放到前面的freelist缓存中,再从该缓存中申请内存返回,没有则从伙伴系统申请,从伙伴系统系统摘下空闲页后放到freelist中进行重新申请流程。
kmem_cache_alloc定义于mm\slub.c,最终透传参数调用了slab_alloc_node:
static __always_inline void *slab_alloc(struct kmem_cache *s,
gfp_t gfpflags, unsigned long addr, size_t orig_size)
{
return slab_alloc_node(s, gfpflags, NUMA_NO_NODE, addr, orig_size);
}
void *kmem_cache_alloc(struct kmem_cache *s, gfp_t gfpflags)
{
void *ret = slab_alloc(s, gfpflags, _RET_IP_, s->object_size);
trace_kmem_cache_alloc(_RET_IP_, ret, s->object_size,
s->size, gfpflags);
return ret;
}
EXPORT_SYMBOL(kmem_cache_alloc);slab_alloc_node是内存分配的真正入口:
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr, size_t orig_size)
{
// 用于指向分配成功的对象
void *object;
// slab cache 在当前 cpu 下的本地 cpu 缓存
struct kmem_cache_cpu *c;
struct page *page;// object 所在的内存页
unsigned long tid;// 当前 cpu 编号
struct obj_cgroup *objcg = NULL;
bool init = false;
/*
进行一些预处理,例如处理 cgroup 内存记账
*/
s = slab_pre_alloc_hook(s, &objcg, 1, gfpflags);
if (!s)
return NULL;
/*
kfence_alloc 是内核调试选项 KFENCE 的实现。如果对象被 KFENCE 拦截并分配(用于检测缓冲区溢出),则直接返回该调试对象,跳过常规 SLUB 分配流程。
*/
object = kfence_alloc(s, orig_size, gfpflags);
if (unlikely(object))
goto out;
redo:
/*
* Must read kmem_cache cpu data via this cpu ptr. Preemption is
* enabled. We may switch back and forth between cpus while
* reading from one cpu area. That does not matter as long
* as we end up on the original cpu again when doing the cmpxchg.
*
* We must guarantee that tid and kmem_cache_cpu are retrieved on the
* same cpu. We read first the kmem_cache_cpu pointer and use it to read
* the tid. If we are preempted and switched to another cpu between the
* two reads, it's OK as the two are still associated with the same cpu
* and cmpxchg later will validate the cpu.
*/
c = raw_cpu_ptr(s->cpu_slab);//当前CPU slab缓存
tid = READ_ONCE(c->tid);//读出当前CPU编号
/*
* Irqless object alloc/free algorithm used here depends on sequence
* of fetching cpu_slab's data. tid should be fetched before anything
* on c to guarantee that object and page associated with previous tid
* won't be used with current tid. If we fetch tid first, object and
* page could be one associated with next tid and our alloc/free
* request will be failed. In this case, we will retry. So, no problem.
*/
/*
barrier() 在这里的作用是强制执行特定的读取顺序:先读取事务 ID (tid),再读取 freelist 指针和 page 指针
即确保当前cpu编号与当前数据不因为事务调度而不一致。
*/
barrier();
/*
* The transaction ids are globally unique per cpu and per operation on
* a per cpu queue. Thus they can be guarantee that the cmpxchg_double
* occurs on the right processor and that there was no operation on the
* linked list in between.
*/
// 从 slab cache 的 cpu 本地缓存 kmem_cache_cpu 中获取缓存的 slub 空闲对象列表
// 这里的 freelist 指向本地 cpu 缓存的 slub 中第一个空闲对象
object = c->freelist;
// 获取本地 cpu 缓存的 slub,这里用 page 表示,如果是复合页,这里指向复合页的首页 head page
page = c->page;
/*
* We cannot use the lockless fastpath on PREEMPT_RT because if a
* slowpath has taken the local_lock_irqsave(), it is not protected
* against a fast path operation in an irq handler. So we need to take
* the slow path which uses local_lock. It is still relatively fast if
* there is a suitable cpu freelist.
*/
if (IS_ENABLED(CONFIG_PREEMPT_RT) ||
unlikely(!object || !page || !node_match(page, node))) {
// 如果 slab cache 的 cpu 本地缓存freelist/page都中已经没有空闲对象了
// 或者 cpu 本地缓存中的 slub 并不属于我们指定的 NUMA 节点
//或者当前内核打开了CONFIG_PREEMPT_RT(完全可抢占内核/实时内核)
// 那么我们就需要进入慢速路径中分配对象:
// 1. 重新检查缓存是否有数据,有时因为调度问题或者其他线程释放内存,缓存重新有了数据
// 2. 检查 kmem_cache_cpu 的 partial 列表中是否有空闲的 slub
// 3. 检查 kmem_cache_node 的 partial 列表中是否有空闲的 slub
// 4. 如果都没有,则只能重新到伙伴系统中去申请内存页
object = __slab_alloc(s, gfpflags, node, addr, c);
} else {
// 走到该分支表示,slab cache 的 cpu 本地缓存中还有空闲对象,直接分配
// 快速路径 fast path 下分配成功,从当前空闲对象中获取下一个空闲对象指针 next_object
void *next_object = get_freepointer_safe(s, object);
/*
* The cmpxchg will only match if there was no additional
* operation and if we are on the right processor.
*
* The cmpxchg does the following atomically (without lock
* semantics!)
* 1. Relocate first pointer to the current per cpu area.
* 2. Verify that tid and freelist have not been changed
* 3. If they were not changed replace tid and freelist
*
* Since this is without lock semantics the protection is only
* against code executing on this cpu *not* from access by
* other cpus.
*/
// 更新 kmem_cache_cpu 结构中的 freelist 指向 next_object
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))) {
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
// cpu 预取 next_object 的 freepointer 到 cpu 高速缓存,加快下一次分配对象的速度
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH);// 统计 slab cache 的状态信息
}
maybe_wipe_obj_freeptr(s, object);
// 如果 gfpflags 掩码中设置了 __GFP_ZERO,则需要将对象所占的内存初始化为零值
init = slab_want_init_on_alloc(gfpflags, s);
out:
slab_post_alloc_hook(s, objcg, gfpflags, 1, &object, init);
return object;// 返回分配好的对象
}先是预处理读取出当前CPU id和对应的缓存信息,再根据当前缓存是否有内存,走直接从缓存分配还是进入__slab_alloc再次详细检查分配,这里检查到缓存有内存时,先检查了当前的CPU id和缓存对应的tid是否一致,不一致则说明此时任务被调度到其他CPU上或者产生中断回来,需要重新读取到一致的tid才能保证缓存属于当前CPU的缓存内存。
__slab_alloc进入慢速分配路径:
static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *p;
#ifdef CONFIG_PREEMPT_COUNT
/*
* We may have been preempted and rescheduled on a different
* cpu before disabling preemption. Need to reload cpu area
* pointer.
*/
// 当开启了 CONFIG_PREEMPT,表示允许其他进程抢占当前 cpu
// 运行进程的当前 cpu 可能会被其他优先级更高的进程抢占,当前进程可能会被调度到其他 cpu 上
// 所以这里需要重新获取 slab cache 的 cpu 本地缓存
c = slub_get_cpu_ptr(s->cpu_slab);
#endif
// 进入 slab cache 的慢速分配路径
p = ___slab_alloc(s, gfpflags, node, addr, c);
#ifdef CONFIG_PREEMPT_COUNT
slub_put_cpu_ptr(s->cpu_slab);
#endif
return p;
}__slab_alloc检查CONFIG_PREEMPT_COUNT进程抢占后,直接调用___slab_alloc:
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *freelist; // 指向 slub 中可供分配的第一个空闲对象
struct page *page;// 空闲对象所在的 slub (用 page 表示)
unsigned long flags;
stat(s, ALLOC_SLOWPATH);// 统计 slab cache 的状态信息,记录本次分配走的是慢速路径 slow path
reread_page:
page = READ_ONCE(c->page);// 从 slab cache 的本地 cpu 缓存中获取缓存的 slub
if (!page) {
/*
* if the node is not online or has no normal memory, just
* ignore the node constraint
*/
if (unlikely(node != NUMA_NO_NODE &&
!node_isset(node, slab_nodes)))
node = NUMA_NO_NODE;
// 如果缓存的 slub 中的对象已经被全部分配出去,没有空闲对象了
// 那么就会跳转到 new_slab 分支进行降级处理走慢速分配路径
goto new_slab;
}
redo:
//检查节点有效性
if (unlikely(!node_match(page, node))) {
/*
* same as above but node_match() being false already
* implies node != NUMA_NO_NODE
*/
if (!node_isset(node, slab_nodes)) {
node = NUMA_NO_NODE;
goto redo;
} else {
stat(s, ALLOC_NODE_MISMATCH);
goto deactivate_slab;
}
}
/*
* By rights, we should be searching for a slab page that was
* PFMEMALLOC but right now, we are losing the pfmemalloc
* information when the page leaves the per-cpu allocator
pfmemalloc_match_unsafe 检查(与内存压力相关的标志).
*/
if (unlikely(!pfmemalloc_match_unsafe(page, gfpflags)))
goto deactivate_slab;// 标志不匹配,停用当前 slab
/* must check again c->page in case we got preempted and it changed */
local_lock_irqsave(&s->cpu_slab->lock, flags);
//这里因为CPU调度问题,可能在当前CPU缓存读出来的page和之前读出来的不一样,需要重新读取确保读到的是当前CPU缓存
if (unlikely(page != c->page)) {
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
goto reread_page;
}
freelist = c->freelist;//如果当前缓存有数据,直接到load_freelist标签申请内存分配后返回
if (freelist)
goto load_freelist;
//从这里拿到的是page->freelist,该内存是本来属于该CPU下的缓存slab,因为调度被其他CPU使用,其他CPU释放时释放到page->freelist中
//和c->freelist不一样的是,c->freelist当前slab缓存,page->freelist的内存需要被摘下放到c->freelist中,frozen=1才能用。
freelist = get_freelist(s, page);
//确认了当前缓存没有内存,则跳转到慢速路径分配内存
//慢速路径包括cpu缓存中的partial和CPU节点的缓存查找,如果都没有,则到伙伴系统申请。
if (!freelist) {
c->page = NULL;
c->tid = next_tid(c->tid);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
stat(s, ALLOC_REFILL);
load_freelist:
//走到这里说明缓存有数据,进行内存申请分配
lockdep_assert_held(this_cpu_ptr(&s->cpu_slab->lock));
/*
* freelist is pointing to the list of objects to be used.
* page is pointing to the page from which the objects are obtained.
* That page must be frozen for per cpu allocations to work.
*/
VM_BUG_ON(!c->page->frozen);
//调用get_freepointer返回下一个空闲内存给c->freelist,同时返回当前空闲内存地址freelist
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);//更新tid
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
return freelist;
deactivate_slab:
//当本地 slab 不匹配请求(NUMA 或 PFMEMALLOC 标志)时,会来到这里
// ... 加锁并再次检查 ...
// 清空本地 c->page 和 c->freelist
// 调用 deactivate_slab(s, page, freelist); 将该 slab 页返回到节点的 partial 列表
// 然后跳到 new_slab 流程寻找新的 slab
local_lock_irqsave(&s->cpu_slab->lock, flags);
if (page != c->page) {
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
goto reread_page;
}
freelist = c->freelist;
c->page = NULL;
c->freelist = NULL;
c->tid = next_tid(c->tid);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
deactivate_slab(s, page, freelist);
new_slab:
//走到这里,进入慢速路径内存分配过程
//检查缓存中的partial链表是否有内存
if (slub_percpu_partial(c)) {
local_lock_irqsave(&s->cpu_slab->lock, flags);
if (unlikely(c->page)) {//再次检查缓存,有数据则重新读取页后检查申请
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
goto reread_page;
}
if (unlikely(!slub_percpu_partial(c))) {//partical没有内存,去CPU的node缓存中申请
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
/* we were preempted and partial list got empty */
goto new_objects;
}
//从partial链表摘下一个page,放到缓存中
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);//partial指针指向下一个可用的空闲page
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;//缓存有内存可用了,重新来一遍
}
new_objects:
//走到这里,说明CPU缓存和缓存的partial链表都没有内存了,则到CPU节点对应的node内存中申请
// 尝试从指定的 node 节点缓存 kmem_cache_node 中的 partial 列表获取可以分配空闲对象的 slub
// 如果指定 numa 节点的内存不足,则会根据 cpu 访问距离的远近,进行跨 numa 节点分配
freelist = get_partial(s, gfpflags, node, &page);//取下一个可以用的内存区域
if (freelist)
goto check_new_page;//跳转处理从node摘下的内存区域
//走到这里说明连CPU的node节点内存也没有了,则从伙伴系统中申请
slub_put_cpu_ptr(s->cpu_slab);
page = new_slab(s, gfpflags, node);//伙伴系统申请内存
c = slub_get_cpu_ptr(s->cpu_slab);
//伙伴系统都没有,没有内存了直接返回失败
if (unlikely(!page)) {
slab_out_of_memory(s, gfpflags, node);
return NULL;
}
/*
* No other reference to the page yet so we can
* muck around with it freely without cmpxchg
*/
//从伙伴系统中摘下page内存后,赋值给缓存,同时page->freelist 置空。
freelist = page->freelist;
page->freelist = NULL;
stat(s, ALLOC_SLAB);
check_new_page:
if (kmem_cache_debug(s)) {
if (!alloc_debug_processing(s, page, freelist, addr)) {
/* Slab failed checks. Next slab needed */
goto new_slab;
} else {
/*
* For debug case, we don't load freelist so that all
* allocations go through alloc_debug_processing()
*/
// 如果开启调试选项,可能只返回一个对象,剩下的走调试路径
goto return_single;
}
}
if (unlikely(!pfmemalloc_match(page, gfpflags)))
/*
* For !pfmemalloc_match() case we don't load freelist so that
* we don't make further mismatched allocations easier.
*/
goto return_single;
retry_load_page:
//如果一切正常,且没有进入调试或 return_single 分支,那么新找到的(或新建的)整页 slab 将被加载到当前 CPU 的本地缓存 c->page 中。
local_lock_irqsave(&s->cpu_slab->lock, flags);
if (unlikely(c->page)) {
void *flush_freelist = c->freelist;
struct page *flush_page = c->page;
c->page = NULL;
c->freelist = NULL;
c->tid = next_tid(c->tid);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
deactivate_slab(s, flush_page, flush_freelist);
stat(s, CPUSLAB_FLUSH);
goto retry_load_page;
}
c->page = page;
goto load_freelist;
return_single:
// 返回一个对象,并将该 slab 的其余部分停用/返回给全局列表
deactivate_slab(s, page, get_freepointer(s, freelist));
return freelist;
}___slab_alloc大致处理了四个方面,一是再次检查缓存freelist/page是否有内存,有的话走快速路径分配内存后直接返回;二是在确认了缓存无内存后,进入满足路径检查缓存中的partial链表是否有内存;三是在缓存partial没有内存情况下进入CPU节点缓存node的检查,四是在所有缓存都没有数据情况下,进入伙伴系统申请页内存。
(1)检查缓存freelist/page
进入___slab_alloc最开始,函数会再次检查page是否为空,为空则跳转到new_slab进入慢速路径检查
reread_page:
page = READ_ONCE(c->page);// 从 slab cache 的本地 cpu 缓存中获取缓存的 slub
if (!page) {
/*
* if the node is not online or has no normal memory, just
* ignore the node constraint
*/
if (unlikely(node != NUMA_NO_NODE &&
!node_isset(node, slab_nodes)))
node = NUMA_NO_NODE;
// 如果缓存的 slub 中的对象已经被全部分配出去,没有空闲对象了
// 那么就会跳转到 new_slab 分支进行降级处理走慢速分配路径
goto new_slab;
}不为空时,先检查CPU调度问题导致读出的缓存不一致,需要重新到reread_page标签读取
/* must check again c->page in case we got preempted and it changed */
local_lock_irqsave(&s->cpu_slab->lock, flags);
//这里因为CPU调度问题,可能在当前CPU缓存读出来的page和之前读出来的不一样,需要重新读取确保读到的是当前CPU缓存
if (unlikely(page != c->page)) {
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
goto reread_page;
}否则直接检查freelist,这里有两种情况,freelist不为空最简单直接进入load_freelist标签申请内存返回即可,为空的情况下,因为此时page不为空,需要检查page->freelist是否为空,page->freelist是当前CPU缓存slab因为调度问题被其他CPU调度使用后释放的位置,即其他CPU释放当前CPU的slab缓存对象时,会释放到page->freelist中。在进程对当前CPU缓存slab对象申请时,会先将page->freelist链表摘下放到c->freelist中再申请,调用函数get_freelist即是在处理该过程,此时当page->freelist被摘下为空后,page->frozen置为0表示该内存被脱离解冻:
static inline void *get_freelist(struct kmem_cache *s, struct page *page)
{
struct page new;// 用于存放要更新的 page 属性值
unsigned long counters;
void *freelist;
lockdep_assert_held(this_cpu_ptr(&s->cpu_slab->lock));
do {
// 获取 page 结构的 freelist,当其他 cpu 向 page 释放对象时 freelist 指向被释放的空闲对象
// 当 page 被 slab cache 的 cpu 本地缓存时,freelist 置为 null
freelist = page->freelist;
counters = page->counters;
new.counters = counters;
VM_BUG_ON(!new.frozen);
// 更新 inuse 字段,表示 page 中的对象 objects 全部被分配出去了
new.inuse = page->objects;
// 如果 freelist != null,表示其他 cpu 又释放了一些对象到 page 中 (slub)。
// 则 page->frozen = 1 , slub 依然冻结在 cpu 本地缓存中
// 如果 freelist == null,则 page->frozen = 0, slub 从 cpu 本地缓存中脱离解冻
new.frozen = freelist != NULL;
// 最后 cas 原子更新 page 结构中的相应属性
// 这里需要注意的是,当 page 被 slab cache 本地 cpu 缓存时,page -> freelist 需要置空。
// 因为在本地 cpu 缓存场景下 page -> freelist 指向其他 cpu 释放的空闲对象列表
// kmem_cache_cpu->freelist 指向的是被本地 cpu 缓存的空闲对象列表
// 这两个列表中的空闲对象共同组成了 slub 中的空闲对象
} while (!__cmpxchg_double_slab(s, page,
freelist, counters,
NULL, new.counters,
"get_freelist"));
return freelist;
}所以这里再次检查了page->freelist,当确认page->freelist也没有内存时,才进入慢速路径分配。
freelist = c->freelist;//如果当前缓存有数据,直接到load_freelist标签申请内存分配后返回
if (freelist)
goto load_freelist;
//从这里拿到的是page->freelist,该内存是本来属于该CPU下的缓存slab,因为调度被其他CPU使用,其他CPU释放时释放到page->freelist中
//和c->freelist不一样的是,c->freelist当前slab缓存,page->freelist的内存需要被摘下放到c->freelist中,frozen=1才能用。
freelist = get_freelist(s, page);
//确认了当前缓存没有内存,则跳转到慢速路径分配内存
//慢速路径包括cpu缓存中的partial和CPU节点的缓存查找,如果都没有,则到伙伴系统申请。
if (!freelist) {
c->page = NULL;
c->tid = next_tid(c->tid);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
stat(s, ALLOC_REFILL);当确认page->freelist有数据时,进入load_freelist申请内存:
load_freelist:
//走到这里说明缓存有数据,进行内存申请分配
lockdep_assert_held(this_cpu_ptr(&s->cpu_slab->lock));
/*
* freelist is pointing to the list of objects to be used.
* page is pointing to the page from which the objects are obtained.
* That page must be frozen for per cpu allocations to work.
*/
VM_BUG_ON(!c->page->frozen);
//调用get_freepointer返回下一个空闲内存给c->freelist,同时返回当前空闲内存地址freelist
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);//更新tid
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
return freelist;load_freelist标签内容主要将当前缓存摘下,将当前空闲指针freelist指向下一个空闲的内存区域首地址,c->freelist = get_freepointer(s, freelist);用来处理得到下一个空闲内存区域。
(2)慢速路径的缓存partial链表检查
当缓存没有数据时,进入慢速路径最先检查的是partial链表
//检查缓存中的partial链表是否有内存
if (slub_percpu_partial(c)) {
local_lock_irqsave(&s->cpu_slab->lock, flags);
if (unlikely(c->page)) {//再次检查缓存,有数据则重新读取页后检查申请
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
goto reread_page;
}
if (unlikely(!slub_percpu_partial(c))) {//partical没有内存,去CPU的node缓存中申请
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
/* we were preempted and partial list got empty */
goto new_objects;
}
//从partial链表摘下一个page,放到缓存中
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);//partial指针指向下一个可用的空闲page
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;//缓存有内存可用了,重新来一遍
}除了重新检查一遍缓存(防止已经有其他线程释放了内存到缓存中,再次检查有的话直接用缓存内存返回),还重新检查了partial链表,在确认没有内存情况下跳转到new_objects标签,进行CPU node缓存内存检查申请。当partial链表有内存时,从partial链表摘下一个页内存,同时将partial指向下一个空闲的内存区域后,返回redo重新检查申请内存,由于此时page有内存了,此时会走快速路径,直接申请一个freelist内存后返回。
(3)从CPU缓存节点申请内存
进入new_objects标签,说明slab cache缓存池没有任何内存,此时要进入CPU对应的节点缓存中检查申请。
// 尝试从指定的 node 节点缓存 kmem_cache_node 中的 partial 列表获取可以分配空闲对象的 slub
// 如果指定 numa 节点的内存不足,则会根据 cpu 访问距离的远近,进行跨 numa 节点分配
freelist = get_partial(s, gfpflags, node, &page);//取下一个可以用的内存区域
if (freelist)
goto check_new_page;//跳转处理从node摘下的内存区域调用get_partial不仅会检查当前CPU节点的缓存,如果当前CPU节点缓存为空,还是依次就近查找附近CPU节点内存,找到就返回。
static void *get_partial(struct kmem_cache *s, gfp_t flags, int node,
struct page **ret_page)
{
// 从指定 node 的 kmem_cache_node 缓存中的 partial 列表中获取到的对象
void *object;
// 即将要所搜索的 kmem_cache_node 缓存对应 numa node
int searchnode = node;
// 如果我们指定的 numa node 已经没有空闲内存了,则选取访问距离最近的 numa node 进行跨节点内存分配
if (node == NUMA_NO_NODE)
searchnode = numa_mem_id();
// 从 searchnode 的 kmem_cache_node 缓存中的 partial 列表中获取对象
object = get_partial_node(s, get_node(s, searchnode), ret_page, flags);
if (object || node != NUMA_NO_NODE)
return object;
// 如果 searchnode 对象的 kmem_cache_node 缓存中的 partial 列表是空的,没有任何可供分配的 slub
// 那么继续按照访问距离,遍历 searchnode 之后的 numa node,进行跨节点内存分配
return get_any_partial(s, flags, ret_page);
}get_partial_node函数取了距离最近的serachnode CPU缓存:
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
struct page **ret_page, gfp_t gfpflags)
{
// 接下来就会挨个遍历 kmem_cache_node 的 partial 列表中的 slub
// 这两个变量用于临时存储遍历的 slub
struct page *page, *page2;
void *object = NULL; // 用于指向从 partial 列表 slub 中申请到的对象
// 用于记录 slab cache 本地 cpu 缓存 kmem_cache_cpu 中所缓存的空闲对象总数(包括 partial 列表)
// 后续会向 kmem_cache_cpu 中填充 slub
unsigned int available = 0;
unsigned long flags;
// 临时记录遍历到的 slub 中包含的剩余空闲对象个数
int objects;
/*
* Racy check. If we mistakenly see no partial slabs then we
* just allocate an empty slab. If we mistakenly try to get a
* partial slab and there is none available then get_partial()
* will return NULL.
*/
if (!n || !n->nr_partial)
return NULL;
spin_lock_irqsave(&n->list_lock, flags);
// 开始挨个遍历 kmem_cache_node 的 partial 列表,获取 slub 用于分配对象以及填充 kmem_cache_cpu
list_for_each_entry_safe(page, page2, &n->partial, slab_list) {
void *t;
if (!pfmemalloc_match(page, gfpflags))
continue;
// page 表示当前遍历到的 slub,这里会从该 slub 中获取空闲对象赋值给 t
// 并将 slub 从 kmem_cache_node 的 partial 列表上摘下
t = acquire_slab(s, n, page, object == NULL, &objects);
// 如果 t 是空的,说明 partial 列表上已经没有可供分配对象的 slub 了
// slub 都满了,退出循环,进入伙伴系统重新申请 slub
if (!t)
break;
// objects 表示当前 slub 中包含的剩余空闲对象个数
// available 用于统计目前遍历的 slub 中所有空闲对象个数
// 后面会根据 available 的值来判断是否继续填充 kmem_cache_cpu
available += objects;
if (!object) {
// 第一次循环会走到这里,第一次循环主要是满足当前对象分配的需求
// 将 partila 列表中第一个 slub 缓存进 kmem_cache_cpu 中
*ret_page = page;
stat(s, ALLOC_FROM_PARTIAL);
object = t;
} else {
// 第二次以及后面的循环就会走到这里,目的是从 kmem_cache_node 的 partial 列表中
// 摘下 slub,然后填充进 kmem_cache_cpu 的 partial 列表里
put_cpu_partial(s, page, 0);
stat(s, CPU_PARTIAL_NODE);
}
// 这里是用于判断是否继续填充 kmem_cache_cpu 中的 partial 列表
// kmem_cache_has_cpu_partial 用于判断 slab cache 是否配置了 cpu 缓存的 partial 列表
// 配置了 CONFIG_SLUB_CPU_PARTIAL 选项意味着开启 kmem_cache_cpu 中的 partial 列表,没有配置的话, cpu 缓存中就不会有 partial 列表
// kmem_cache_cpu 中缓存被填充之后的空闲对象个数(包括 partial 列表)不能超过 ( kmem_cache 结构中 cpu_partial 指定的个数 / 2 )
if (!kmem_cache_has_cpu_partial(s)
|| available > slub_cpu_partial(s) / 2)
break; // kmem_cache_cpu 已经填充满了,就退出循环,停止填充
}
spin_unlock_irqrestore(&n->list_lock, flags);
return object;
}当最近的CPU节点缓存也为空时,调用get_any_partial继续按照距离访问其他node节点缓存。
(4)从伙伴系统申请
上述内存都为空时,内核就会进入伙伴系统申请内存页,放到slab cache缓存池中:
//走到这里说明连CPU的node节点内存也没有了,则从伙伴系统中申请
slub_put_cpu_ptr(s->cpu_slab);
page = new_slab(s, gfpflags, node);//伙伴系统申请内存
c = slub_get_cpu_ptr(s->cpu_slab);
//伙伴系统都没有,没有内存了直接返回失败
if (unlikely(!page)) {
slab_out_of_memory(s, gfpflags, node);
return NULL;
}
/*
* No other reference to the page yet so we can
* muck around with it freely without cmpxchg
*/
//从伙伴系统中摘下page内存后,赋值给缓存,同时page->freelist 置空。
freelist = page->freelist;
page->freelist = NULL;伙伴系统里都没有内存的话就直接返回失败,获取成功后在没有任何调试情况检查情况下,最后进入load_freelist进行快速路径内存分配。
从伙伴系统申请内存大小,主要依赖前面创建过程中初始化的oo和min,首先用oo记录的内存大小申请页数量,在内存较为紧张时可能会申请失败,此时内核重新用min降级申请伙伴系统内存。
static struct page *new_slab(struct kmem_cache *s, gfp_t flags, int node)
{
if (unlikely(flags & GFP_SLAB_BUG_MASK))
flags = kmalloc_fix_flags(flags);
WARN_ON_ONCE(s->ctor && (flags & __GFP_ZERO));
return allocate_slab(s,
flags & (GFP_RECLAIM_MASK | GFP_CONSTRAINT_MASK), node);
}
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
struct page *page;// 用于指向从伙伴系统中申请到的内存页
// kmem_cache 结构的中的 kmem_cache_order_objects oo,表示该 slub 需要多少个内存页,以及能够容纳多少个对象
// kmem_cache_order_objects 的高 16 位表示需要的内存页个数,低 16 位表示能够容纳的对象个数
struct kmem_cache_order_objects oo = s->oo;
gfp_t alloc_gfp;// 控制向伙伴系统申请内存的行为规范掩码
void *start, *p, *next;
int idx;
bool shuffle;
flags &= gfp_allowed_mask;
flags |= s->allocflags;
/*
* Let the initial higher-order allocation fail under memory pressure
* so we fall-back to the minimum order allocation.
*/
alloc_gfp = (flags | __GFP_NOWARN | __GFP_NORETRY) & ~__GFP_NOFAIL;
if ((alloc_gfp & __GFP_DIRECT_RECLAIM) && oo_order(oo) > oo_order(s->min))
alloc_gfp = (alloc_gfp | __GFP_NOMEMALLOC) & ~(__GFP_RECLAIM|__GFP_NOFAIL);
// 向伙伴系统申请 oo 中规定的内存页
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page)) {
// 如果伙伴系统无法满足正常情况下 oo 指定的内存页个数
// 那么这里再次尝试用 min 中指定的内存页个数向伙伴系统申请内存页
// min 表示当内存不足或者内存碎片的原因无法满足内存分配时,至少要保证容纳一个对象所使用内存页个数
oo = s->min;
alloc_gfp = flags;
/*
* Allocation may have failed due to fragmentation.
* Try a lower order alloc if possible
*/
// 再次向伙伴系统申请容纳一个对象所需要的内存页(降级)
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page))
goto out; // 如果内存还是不足,则走到 out 分支直接返回 null
stat(s, ORDER_FALLBACK);
}
// 初始化 slub 对应的 struct page 结构中的属性
// 获取 slub 可以容纳的对象个数
page->objects = oo_objects(oo);
account_slab_page(page, oo_order(oo), s, flags);
page->slab_cache = s;// 将 slub cache 与 page 结构关联
// 将 PG_slab 标识设置到 struct page 的 flag 属性中
// 表示该内存页 page 被 slub 所管理
__SetPageSlab(page);
if (page_is_pfmemalloc(page))
SetPageSlabPfmemalloc(page);
// 用 0xFC 填充 slub 中的内存,用于内核对内存访问越界检查
kasan_poison_slab(page);
// 获取内存页对应的虚拟内存地址
start = page_address(page);
setup_page_debug(s, page, start);
// 在配置了 CONFIG_SLAB_FREELIST_RANDOM 选项的情况下
// 会在 slub 的空闲对象中以随机的顺序初始化 freelist 列表
// 返回值 shuffle = true 表示随机初始化 freelist,shuffle = false 表示按照正常的顺序初始化 freelist
shuffle = shuffle_freelist(s, page);
if (!shuffle) {// shuffle = false 则按照正常的顺序来初始化 freelist
// 获取 slub 第一个空闲对象的真正起始地址
// slub 可能配置了 SLAB_RED_ZONE,这样会在 slub 对象内存空间两侧填充 red zone,防止内存访问越界
// 这里需要跳过 red zone 获取真正存放对象的内存地址
start = fixup_red_left(s, start);
// 填充对象的内存区域以及初始化空闲对象
start = setup_object(s, page, start);
// 用 slub 中的第一个空闲对象作为 freelist 的头结点,而不是随机的一个空闲对象
page->freelist = start;
// 从 slub 中的第一个空闲对象开始,按照正常的顺序通过对象的 freepointer 串联起 freelist
for (idx = 0, p = start; idx < page->objects - 1; idx++) {
next = p + s->size;// 获取下一个对象的内存地址
next = setup_object(s, page, next);// 填充下一个对象的内存区域以及初始化
set_freepointer(s, p, next);// 通过 p 的 freepointer 指针指向 next,设置 p 的下一个空闲对象为 next
p = next;// 通过循环遍历,就把 slub 中的空闲对象按照正常顺序串联在 freelist 中了
}
set_freepointer(s, p, NULL); // freelist 中的尾结点的 freepointer 设置为 null
}
page->inuse = page->objects;// slub 的初始状态 inuse 的值为所有空闲对象个数
page->frozen = 1;// slub 被创建出来之后,需要放入 cpu 本地缓存 kmem_cache_cpu 中
out:
if (!page)
return NULL;
// 更新 page 所在 numa 节点在 slab cache 中的缓存 kmem_cache_node 结构中的相关计数
// kmem_cache_node 中包含的 slub 个数加 1,包含的总对象个数加 page->objects
inc_slabs_node(s, page_to_nid(page), page->objects);
inc_slabs_node(s, page_to_nid(page), page->objects);
return page;
}这里从伙伴系统获取页内存后,会用freelist将每个内存链接起来成链表,期间还处理了创建slab cache时一个对象red区域,找到对象的起始地址,如果设置了内存初始化还需对内存进行初始化填充等。
// 在配置了 CONFIG_SLAB_FREELIST_RANDOM 选项的情况下
// 会在 slub 的空闲对象中以随机的顺序初始化 freelist 列表
// 返回值 shuffle = true 表示随机初始化 freelist,shuffle = false 表示按照正常的顺序初始化 freelist
shuffle = shuffle_freelist(s, page);
if (!shuffle) {// shuffle = false 则按照正常的顺序来初始化 freelist
// 获取 slub 第一个空闲对象的真正起始地址
// slub 可能配置了 SLAB_RED_ZONE,这样会在 slub 对象内存空间两侧填充 red zone,防止内存访问越界
// 这里需要跳过 red zone 获取真正存放对象的内存地址
start = fixup_red_left(s, start);
// 填充对象的内存区域以及初始化空闲对象
start = setup_object(s, page, start);
// 用 slub 中的第一个空闲对象作为 freelist 的头结点,而不是随机的一个空闲对象
page->freelist = start;
// 从 slub 中的第一个空闲对象开始,按照正常的顺序通过对象的 freepointer 串联起 freelist
for (idx = 0, p = start; idx < page->objects - 1; idx++) {
next = p + s->size;// 获取下一个对象的内存地址
next = setup_object(s, page, next);// 填充下一个对象的内存区域以及初始化
set_freepointer(s, p, next);// 通过 p 的 freepointer 指针指向 next,设置 p 的下一个空闲对象为 next
p = next;// 通过循环遍历,就把 slub 中的空闲对象按照正常顺序串联在 freelist 中了
}
set_freepointer(s, p, NULL); // freelist 中的尾结点的 freepointer 设置为 null
}alloc_slab_page接口调用了伙伴系统申请接口,在计算了所需的order阶数之后调用:
static inline struct page *alloc_slab_page(struct kmem_cache *s,
gfp_t flags, int node, struct kmem_cache_order_objects oo)
{
struct page *page;
unsigned int order = oo_order(oo);
if (node == NUMA_NO_NODE)
page = alloc_pages(flags, order);
else
page = __alloc_pages_node(node, flags, order);
return page;
}5.4 内存的释放与slab的销毁
5.4.1 内存的释放
调用kmem_cache_free进行内存释放时,会先进行校验,检查当前释放的内存,是否属于当前slab cache缓冲池,如果不是则不进行释放。
void kmem_cache_free(struct kmem_cache *s, void *x)
{
s = cache_from_obj(s, x);
if (!s)
return;
slab_free(s, virt_to_head_page(x), x, NULL, 1, _RET_IP_);
trace_kmem_cache_free(_RET_IP_, x, s->name);
}
EXPORT_SYMBOL(kmem_cache_free);
static inline struct kmem_cache *cache_from_obj(struct kmem_cache *s, void *x)
{
struct kmem_cache *cachep;
if (!IS_ENABLED(CONFIG_SLAB_FREELIST_HARDENED) &&
!kmem_cache_debug_flags(s, SLAB_CONSISTENCY_CHECKS))
return s;
// 通过对象的虚拟内存地址 x 找到对象所属的 slab cache
cachep = virt_to_cache(x);
// 校验指定的 slab cache : s 是否是对象真正所属的 slab cache : cachep
if (WARN(cachep && cachep != s,
"%s: Wrong slab cache. %s but object is from %s\n",
__func__, s->name, cachep->name))
print_tracking(cachep, x);
return cachep;
}其中virt_to_cache根据内存地址x,找到x所在的page,page维护的slab_cache成员是当前page所属的slab cache对象。
static inline struct kmem_cache *virt_to_cache(const void *obj)
{
struct page *page;
page = virt_to_head_page(obj);
if (WARN_ONCE(!PageSlab(page), "%s: Object is not a Slab page!\n",
__func__))
return NULL;
return page->slab_cache;
}校验通过后才会进入内存释放流程
static __always_inline void slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
/*
* With KASAN enabled slab_free_freelist_hook modifies the freelist
* to remove objects, whose reuse must be delayed.
*/
if (slab_free_freelist_hook(s, &head, &tail, &cnt))
do_slab_free(s, page, head, tail, cnt, addr);
}do_slab_free是内存释放核心入口:
static __always_inline void do_slab_free(struct kmem_cache *s,
struct page *page, void *head, void *tail,
int cnt, unsigned long addr)
{
void *tail_obj = tail ? : head;
struct kmem_cache_cpu *c;
// slub 中对象分配与释放流程的全局事务 id
// 既可以用来标识同一个分配或者释放的事务流程,也可以用来标识区分所属 cpu 本地缓存
unsigned long tid;
/* memcg_slab_free_hook() is already called for bulk free. */
if (!tail)
memcg_slab_free_hook(s, &head, 1);
redo:
/*
* Determine the currently cpus per cpu slab.
* The cpu may change afterward. However that does not matter since
* data is retrieved via this pointer. If we are on the same cpu
* during the cmpxchg then the free will succeed.
*/
// 接下来我们需要获取 slab cache 的 cpu 本地缓存
c = raw_cpu_ptr(s->cpu_slab);
tid = READ_ONCE(c->tid);
/* Same with comment on barrier() in slab_alloc_node() */
//保证获取到的 cpu 本地缓存 c 是属于执行进程的当前 cpu
// 因为进程可能由于抢占或者中断的原因被调度到其他 cpu 上执行,所需需要确保两者的 tid 是否一致
barrier();
// 如果释放对象所属的 slub (page 表示)正好是 cpu 本地缓存的 slub
// 那么直接将对象释放到 cpu 缓存的 slub 中即可,这里就是快速释放路径 fastpath
if (likely(page == c->page)) {
#ifndef CONFIG_PREEMPT_RT
void **freelist = READ_ONCE(c->freelist);
// 将对象释放至 cpu 本地缓存 freelist 中的头结点处
// 释放对象中的 freepointer 指向原来的 c->freelist
set_freepointer(s, tail_obj, freelist);
// cas 更新 cpu 本地缓存 s->cpu_slab 中的 freelist,以及 tid
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
freelist, tid,
head, next_tid(tid)))) {
note_cmpxchg_failure("slab_free", s, tid);
goto redo;
}
#else /* CONFIG_PREEMPT_RT */
/*
* We cannot use the lockless fastpath on PREEMPT_RT because if
* a slowpath has taken the local_lock_irqsave(), it is not
* protected against a fast path operation in an irq handler. So
* we need to take the local_lock. We shouldn't simply defer to
* __slab_free() as that wouldn't use the cpu freelist at all.
*/
void **freelist;
local_lock(&s->cpu_slab->lock);
c = this_cpu_ptr(s->cpu_slab);
if (unlikely(page != c->page)) {
local_unlock(&s->cpu_slab->lock);
goto redo;
}
tid = c->tid;
freelist = c->freelist;
set_freepointer(s, tail_obj, freelist);
c->freelist = head;
c->tid = next_tid(tid);
local_unlock(&s->cpu_slab->lock);
#endif
stat(s, FREE_FASTPATH);
} else
// 如果当前释放对象并不在 cpu 本地缓存中,那么就进入慢速释放路径 slowpath
__slab_free(s, page, head, tail_obj, cnt, addr);
}先检查了当前内存所属page,是否和当前缓存一致,如果是直接释放到缓存中返回即可(即所谓的快速路径)。如果释放的内存不在当前缓存中,则调用__slab_free进入慢速路径释放过程,__slab_free释放主要处理四种情况:
1)如果 slab 本来就在 slab cache 本地 cpu 缓存 kmem_cache_cpu->partial 链表中,那么对象在释放之后,slab 的位置不做任何改变。
2)如果 slab 不在 kmem_cache_cpu->partial 链表中,并且该 slab 由于对象的释放刚好由一个 full slab 变为了一个 partial slab,为了利用局部性的优势,内核需要将该 slab 插入到 kmem_cache_cpu->partial 链表中。
3)如果 slab 不在 kmem_cache_cpu->partial 链表中,并且该 slab 由于对象的释放刚好由一个 partial slab 变为了一个 empty slab,说明该 slab 并不是很活跃,内核会将该 slab 放入对应 NUMA 节点缓存 kmem_cache_node->partial 链表中。
4)如果不符合第 2, 3 种场景,但是 slab 本来就在对应的 NUMA 节点缓存 kmem_cache_node->partial 链表中,那么对象在释放之后,slab 的位置不做任何改变。
static void __slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
// 用于指向对象释放回 slub 之前,slub 的 freelist
void *prior;
// 对象所属的 slub 之前是否在本地 cpu 缓存 partial 链表中
int was_frozen;
// 后续会对 slub 对应的 page 结构相关属性进行修改
// 修改后的属性会临时保存在 new 中,后面通过 cas 替换
struct page new;
unsigned long counters;
struct kmem_cache_node *n = NULL;
unsigned long flags;
stat(s, FREE_SLOWPATH);
if (kfence_free(head))
return;
// free_debug_processing 中会调用 init_object,清理对象内存无用信息,重新恢复对象内存布局到初始状态
if (kmem_cache_debug(s) &&
!free_debug_processing(s, page, head, tail, cnt, addr))
return;
do {
if (unlikely(n)) {
spin_unlock_irqrestore(&n->list_lock, flags);
n = NULL;
}
// 获取 slub 中的空闲对象列表,prior = null 表示此时 slub 是一个 full slub,意思就是该 slub 中的对象已经全部被分配出去了
prior = page->freelist;
counters = page->counters;
// 将释放的对象插入到 freelist 的头部,将对象释放回 slub
// 将 tail 对象的 freepointer 设置为 prior+
set_freepointer(s, tail, prior);
// 将原有 slab 的相应属性赋值给 new page
new.counters = counters;
// 获取原来 slub 中的 frozen 状态,是否在 cpu 缓存 partial 链表中
was_frozen = new.frozen;
// inuse 表示 slub 已经分配出去的对象个数,这里是释放 cnt 个对象,所以 inuse 要减去 cnt
new.inuse -= cnt;
// !new.inuse 表示此时 slub 变为了一个 empty slub,意思就是该 slub 中的对象还没有分配出去,全部在 slub 中
// !prior 表示由于本次对象的释放,slub 刚刚从一个 full slub 变成了一个 partial slub (意思就是该 slub 中的对象部分分配出去了,部分没有分配出去)
// !was_frozen 表示该 slub 不在 cpu 本地缓存中
if ((!new.inuse || !prior) && !was_frozen) {
// 注意进入该分支的 slub 之前都不在 cpu 本地缓存中
// 如果配置了 CONFIG_SLUB_CPU_PARTIAL 选项,那么表示 cpu 本地缓存 kmem_cache_cpu 结构中包含 partial 列表,用于 cpu 缓存部分分配的 slub
if (kmem_cache_has_cpu_partial(s) && !prior) {
/*
* Slab was on no list before and will be
* partially empty
* We can defer the list move and instead
* freeze it.
*/
// 如果 kmem_cache_cpu 包含 partial 列表并且该 slub 刚刚由 full slub 变为 partial slub
// 冻结该 slub,后续会将该 slub 插入到 kmem_cache_cpu 的 partial 列表中
new.frozen = 1;
} else { /* Needs to be taken off a list */
// 如果 kmem_cache_cpu 中没有配置 partial 列表,那么直接释放至 kmem_cache_node 中
// 或者该 slub 由一个 partial slub 变为了 empty slub,调整 slub 的位置到 kmem_cache_node->partial 链表中
n = get_node(s, page_to_nid(page));
/*
* Speculatively acquire the list_lock.
* If the cmpxchg does not succeed then we may
* drop the list_lock without any processing.
*
* Otherwise the list_lock will synchronize with
* other processors updating the list of slabs.
*/
// 后续会操作 kmem_cache_node 中的 partial 列表,所以这里需要获取 list_lock
spin_lock_irqsave(&n->list_lock, flags);
}
}
// cas 更新 slub 中的 freelist 以及 counters
} while (!cmpxchg_double_slab(s, page,
prior, counters,
head, new.counters,
"__slab_free"));
// 该分支要处理的场景是:
// 1: 该 slub 原来不在 cpu 本地缓存的 partial 列表中(!was_frozen),但是该 slub 刚刚从 full slub 变为了 partial slub,需要放入 cpu-> partial 列表中
// 2: 该 slub 原来就在 cpu 本地缓存的 partial 列表中,直接将对象释放回 slub 即可
if (likely(!n)) {
// 处理场景2,因为之前已经通过 set_freepointer 将对象释放回 slub 了,这里只需要记录 slub 状态即可
if (likely(was_frozen)) {
/*
* The list lock was not taken therefore no list
* activity can be necessary.
*/
stat(s, FREE_FROZEN);
} else if (new.frozen) {
// 处理场景 1
/*
* If we just froze the page then put it onto the
* per cpu partial list.
*/
// 将 slub 插入到 kmem_cache_cpu 中的 partial 列表中
put_cpu_partial(s, page, 1);
stat(s, CPU_PARTIAL_FREE);
}
return;
}
// 后续的逻辑就是处理需要将 slub 放入 kmem_cache_node 中的 partial 列表的情形
// 在将 slub 放入 node 缓存之前,需要判断 node 缓存的 nr_partial 是否超过了指定阈值 min_partial(位于 kmem_cache 结构)
// nr_partial 表示 kmem_cache_node 中 partial 列表中缓存的 slub 个数
// min_partial 表示 slab cache 规定 kmem_cache_node 中 partial 列表可以容纳的 slub 最大个数
// 如果 nr_partial 超过了最大阈值 min_partial,则不能放入 kmem_cache_node 里
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
// 如果 slub 变为了一个 empty slub 并且 nr_partial 超过了最大阈值 min_partial
// 跳转到 slab_empty 分支,将 slub 释放回伙伴系统中
goto slab_empty;
/*
* Objects left in the slab. If it was not on the partial list before
* then add it.
*/
// 如果 cpu 本地缓存中没有配置 partial 列表并且 slub 刚刚从 full slub 变为 partial slub
// 则将 slub 插入到 kmem_cache_node 中
if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) {
remove_full(s, n, page);
add_partial(n, page, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
spin_unlock_irqrestore(&n->list_lock, flags);
// 剩下的情况均属于 slub 原来就在 kmem_cache_node 中的 partial 列表中
// 直接将对象释放回 slub 即可,无需改变 slub 的位置,直接返回
return;
slab_empty:
// 该分支处理的场景是: slub 太多了,将 empty slub 释放会伙伴系统
// 首先将 slub 从对应的管理链表上删除
if (prior) {
/*
* Slab on the partial list.
*/
remove_partial(n, page);
stat(s, FREE_REMOVE_PARTIAL);
} else {
/* Slab must be on the full list */
remove_full(s, n, page);
}
spin_unlock_irqrestore(&n->list_lock, flags);
stat(s, FREE_SLAB);
// 释放 slub 回伙伴系统,底层调用 __free_pages 将 slub 所管理的所有 page 释放回伙伴系统
discard_slab(s, page);
}(1)释放对象回对应的slab中(page)
释放过程第一步就是把内存先放到page中,在修改各种属性,包括把当前释放的对象freepointer指向freelist,freelist指向当前释放的对象,减少已分配计数inuse等。
do {
if (unlikely(n)) {
spin_unlock_irqrestore(&n->list_lock, flags);
n = NULL;
}
// 获取 slub 中的空闲对象列表,prior = null 表示此时 slub 是一个 full slub,意思就是该 slub 中的对象已经全部被分配出去了
prior = page->freelist;
counters = page->counters;
// 将释放的对象插入到 freelist 的头部,将对象释放回 slub
// 将 tail 对象的 freepointer 设置为 prior+
set_freepointer(s, tail, prior);
// 将原有 slab 的相应属性赋值给 new page
new.counters = counters;
// 获取原来 slub 中的 frozen 状态,是否在 cpu 缓存 partial 链表中
was_frozen = new.frozen;
// inuse 表示 slub 已经分配出去的对象个数,这里是释放 cnt 个对象,所以 inuse 要减去 cnt
new.inuse -= cnt;
...
...
...
// cas 更新 slub 中的 freelist 以及 counters
} while (!cmpxchg_double_slab(s, page,
prior, counters,
head, new.counters,
"__slab_free"));(2) 释放对象本身就在kmem_cache_cpu->partial
was_frozen如果为1表示释放对象所属的slab(page)之前就在kmem_cache_cpu->partial中,内核需要直接释放回slab中不做位置相关的改变。
// !new.inuse 表示此时 slub 变为了一个 empty slub,意思就是该 slub 中的对象还没有分配出去,全部在 slub 中
// !prior 表示由于本次对象的释放,slub 刚刚从一个 full slub 变成了一个 partial slub (意思就是该 slub 中的对象部分分配出去了,部分没有分配出去)
// !was_frozen 表示该 slub 不在 cpu 本地缓存中
if ((!new.inuse || !prior) && !was_frozen) {
// 注意进入该分支的 slub 之前都不在 cpu 本地缓存中
// 如果配置了 CONFIG_SLUB_CPU_PARTIAL 选项,那么表示 cpu 本地缓存 kmem_cache_cpu 结构中包含 partial 列表,用于 cpu 缓存部分分配的 slub
if (kmem_cache_has_cpu_partial(s) && !prior) {
/*
* Slab was on no list before and will be
* partially empty
* We can defer the list move and instead
* freeze it.
*/
// 如果 kmem_cache_cpu 包含 partial 列表并且该 slub 刚刚由 full slub 变为 partial slub
// 冻结该 slub,后续会将该 slub 插入到 kmem_cache_cpu 的 partial 列表中
new.frozen = 1;
} else { /* Needs to be taken off a list */
// 如果 kmem_cache_cpu 中没有配置 partial 列表,那么直接释放至 kmem_cache_node 中
// 或者该 slub 由一个 partial slub 变为了 empty slub,调整 slub 的位置到 kmem_cache_node->partial 链表中
n = get_node(s, page_to_nid(page));
/*
* Speculatively acquire the list_lock.
* If the cmpxchg does not succeed then we may
* drop the list_lock without any processing.
*
* Otherwise the list_lock will synchronize with
* other processors updating the list of slabs.
*/
// 后续会操作 kmem_cache_node 中的 partial 列表,所以这里需要获取 list_lock
spin_lock_irqsave(&n->list_lock, flags);
}(3)释放对象后,所属slab(page)由full(全部被用)变成了partial(部分空闲)
这种情况下内核将其插入到CPU缓存kmem_cache_cpu->partial中(该slab经常full说明slab 十分活跃)
// 该分支要处理的场景是:
// 1: 该 slub 原来不在 cpu 本地缓存的 partial 列表中(!was_frozen),但是该 slub 刚刚从 full slub 变为了 partial slub,需要放入 cpu-> partial 列表中
// 2: 该 slub 原来就在 cpu 本地缓存的 partial 列表中,直接将对象释放回 slub 即可
if (likely(!n)) {
// 处理场景2,因为之前已经通过 set_freepointer 将对象释放回 slub 了,这里只需要记录 slub 状态即可
if (likely(was_frozen)) {
/*
* The list lock was not taken therefore no list
* activity can be necessary.
*/
stat(s, FREE_FROZEN);
} else if (new.frozen) {
// 处理场景 1
/*
* If we just froze the page then put it onto the
* per cpu partial list.
*/
// 将 slub 插入到 kmem_cache_cpu 中的 partial 列表中
put_cpu_partial(s, page, 1);
stat(s, CPU_PARTIAL_FREE);
}
return;
}put_cpu_partial用于将内存插入到kmem_cache_cpu->partial,该函数还检查了当前 kmem_cache_cpu->partial 链表中包含的空闲对象总数 pobjects 是否超过了 kmem_cache->cpu_partial 的限制,如果超过了,则需要先将当前 kmem_cache_cpu->partial 链表中所有的 slab 转移到其对应的 NUMA 节点缓存 kmem_cache_node->partial 链表中。转移完成之后,在将释放对象所属的 slab 插入到 kmem_cache_cpu->partial 链表中,没超过则直接插入不需要转移。
static void put_cpu_partial(struct kmem_cache *s, struct page *page, int drain)
{
struct page *oldpage; // 指向原有 kmem_cache_cpu 中的 partial 列表
struct page *page_to_unfreeze = NULL;
unsigned long flags;
int pages = 0;// slub 所在管理列表中的 slub 个数,这里的列表是指 partial 列表
// slub 所在管理列表中的包含的空闲对象总数,这里的列表是指 partial 列表
// 内核会将列表总体的信息存放在列表首页 page 的相关字段中
int pobjects = 0;
// 禁止抢占
local_lock_irqsave(&s->cpu_slab->lock, flags);
// 获取 slab cache 中原有的 cpu 本地缓存 partial 列表首页
oldpage = this_cpu_read(s->cpu_slab->partial);
// 如果 partial 列表不为空,则需要判断 partial 列表中所有 slub 包含的空闲对象总数是否超过了 s->cpu_partial 规定的阈值
// 超过 s->cpu_partial 则需要将 kmem_cache_cpu->partial 列表中原有的所有 slub 转移到 kmem_cache_node-> partial 列表中
// 转移之后,再把当前 slub 插入到 kmem_cache_cpu->partial 列表中
// 如果没有超过 s->cpu_partial ,则无需转移直接插入
if (oldpage) {
if (drain && oldpage->pobjects > slub_cpu_partial(s)) {
/*
* Partial array is full. Move the existing set to the
* per node partial list. Postpone the actual unfreezing
* outside of the critical section.
*/
page_to_unfreeze = oldpage;//需要释放到node的页
oldpage = NULL;//将当前partial清空,// 重置 partial 列表
} else {
pobjects = oldpage->pobjects;// 从 partial 列表首页中获取列表中包含的空闲对象总数
pages = oldpage->pages;// 从 partial 列表首页中获取列表中包含的 slub 总数
}
}
// 无论 kmem_cache_cpu-> partial 列表中的 slub 是否需要转移
// 释放对象所在的 slub 都需要填加到 kmem_cache_cpu-> partial 列表中
pages++;
pobjects += page->objects - page->inuse;
page->pages = pages;
page->pobjects = pobjects;
page->next = oldpage;
//将 slub 插入到 partial 列表的头部
this_cpu_write(s->cpu_slab->partial, page);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
if (page_to_unfreeze) {
// partial 列表中所包含的空闲对象总数 pobjects 超过了 s->cpu_partial 规定的阈值
// 则需要将现有 partial 列表中的所有 slub 转移到相应的 kmem_cache_node->partial 列表中
__unfreeze_partials(s, page_to_unfreeze);
stat(s, CPU_PARTIAL_DRAIN);
}
}函数调用了__unfreeze_partials进行多余内存(kmem_cache_cpu->partial 链表中包含的空闲对象总数 pobjects 是否超过了 kmem_cache->cpu_partial 的限制)转移到kmem_cache_node->partial 中:
static void __unfreeze_partials(struct kmem_cache *s, struct page *partial_page)
{
struct kmem_cache_node *n = NULL, *n2 = NULL;
struct page *page, *discard_page = NULL;
unsigned long flags = 0;
// 挨个遍历 kmem_cache_cpu->partial 列表,将列表中的 slub 转移到对应 kmem_cache_node->partial 列表中
while (partial_page) {
struct page new;
struct page old;
// 将当前遍历到的 slub 从 kmem_cache_cpu->partial 列表摘下
page = partial_page;
partial_page = page->next;
// 获取当前 slub 所在的 numa 节点对应的 kmem_cache_node 缓存
n2 = get_node(s, page_to_nid(page));
// 如果和上一个转移的 slub 所在的 numa 节点不一样
// 则需要释放上一个 numa 节点的 list_lock,并对当前 numa 节点的 list_lock 加锁
if (n != n2) {
if (n)
spin_unlock_irqrestore(&n->list_lock, flags);
n = n2;
spin_lock_irqsave(&n->list_lock, flags);
}
do {
old.freelist = page->freelist;
old.counters = page->counters;
VM_BUG_ON(!old.frozen);
new.counters = old.counters;
new.freelist = old.freelist;
// unfrozen 当前 slub,因为即将被转移到对应的 kmem_cache_node->partial 列表
new.frozen = 0;
// cas 更新当前 slub 的 freelist,frozen 属性
} while (!__cmpxchg_double_slab(s, page,
old.freelist, old.counters,
new.freelist, new.counters,
"unfreezing slab"));
// 因为 kmem_cache_node->partial 列表中所包含的 slub 个数是受 s->min_partial 阈值限制的
// 所以这里还需要检查 nr_partial 是否超过了 min_partial
// 如果当前被转移的 slub 是一个 empty slub 并且 nr_partial 超过了 min_partial 的限制,则需要将 slub 释放回伙伴系统中
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) {
page->next = discard_page;
discard_page = page;
} else {
// 其他情况,只要 slub 不为 empty ,不管 nr_partial 是否超过了 min_partial
// 都需要将 slub 转移到对应 kmem_cache_node->partial 列表的末尾
add_partial(n, page, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
}
if (n)
spin_unlock_irqrestore(&n->list_lock, flags);
// 将 discard_page 链表中的 slub 统一释放回伙伴系统
while (discard_page) {
page = discard_page;
discard_page = discard_page->next;
stat(s, DEACTIVATE_EMPTY);
discard_slab(s, page);// 底层调用 __free_pages 将 slub 所管理的所有 page 释放回伙伴系统
stat(s, FREE_SLAB);
}
}函数除了处理自身插入内存,还检查了当前kmem_cache_node的nr_partial是否超过min_partial,超过时内核就会直接将这个 empty slab 释放回伙伴系统中。
(4)释放对象slab(当前对象内存页)从partial(部分空闲)变成empty(全部空闲)
这种情况将被释放回 kmem_cache_node->partial 链表中作为本地 cpu 缓存的后备选项(该 slab 并不是一个活跃的 slab,它的局部性不好,内核已经好久没有从该 slab 中分配对象了)。同样的对当前kmem_cache_node的nr_partial进行了检查,如果超过min_partial直接将这个 empty slab 释放回伙伴系统中。
// 后续的逻辑就是处理需要将 slub 放入 kmem_cache_node 中的 partial 列表的情形
// 在将 slub 放入 node 缓存之前,需要判断 node 缓存的 nr_partial 是否超过了指定阈值 min_partial(位于 kmem_cache 结构)
// nr_partial 表示 kmem_cache_node 中 partial 列表中缓存的 slub 个数
// min_partial 表示 slab cache 规定 kmem_cache_node 中 partial 列表可以容纳的 slub 最大个数
// 如果 nr_partial 超过了最大阈值 min_partial,则不能放入 kmem_cache_node 里
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
// 如果 slub 变为了一个 empty slub 并且 nr_partial 超过了最大阈值 min_partial
// 跳转到 slab_empty 分支,将 slub 释放回伙伴系统中
goto slab_empty;5.4.2 销毁slab cache
用户调用kmem_cache_destroy进行slab cache的销毁,主要进行cpu 中的缓存 kmem_cache_cpu内存释放(kmem_cache_cpu->page和kmem_cache_cpu->partial 链表中缓存的所有 slab)、释放kmem_cache_node->partial NUMA节点缓存、移除文件系统/sys/kernel/slab/下信息(在只有单个引用时)、把该slab cache从slab_caches全局链表删除、释放slab cache相关管理结构内存,例如kmem_cache_node。
kmem_cache_destroy首先判断当前是否还有其他模块在使用该slab cache,如果引用不为0则直接返回不能销毁。
void kmem_cache_destroy(struct kmem_cache *s)
{
int err;
if (unlikely(!s))
return;
cpus_read_lock();
mutex_lock(&slab_mutex);
// 将 slab cache 的引用技术减 1
s->refcount--;
if (s->refcount)// 判断 slab cache 是否还存在其他地方的引用
goto out_unlock;// 如果该 slab cache 还存在引用,则不能销毁,跳转到 out_unlock 分支
// slab cache 销毁的核心函数,销毁逻辑就封装在这里
err = shutdown_cache(s);
if (err) {
pr_err("%s %s: Slab cache still has objects\n",
__func__, s->name);
dump_stack();
}
out_unlock:
// 释放相关的自旋锁和信号量
mutex_unlock(&slab_mutex);
cpus_read_unlock();
}
EXPORT_SYMBOL(kmem_cache_destroy);否则调用shutdown_cache进行slab cache销毁流程:
static int shutdown_cache(struct kmem_cache *s)
{
/* free asan quarantined objects */
kasan_cache_shutdown(s);
// 这里会释放 slab cache 占用的所有资源
if (__kmem_cache_shutdown(s) != 0)
return -EBUSY;
// 从 slab cache 的全局列表中删除该 slab cache
list_del(&s->list);
// 释放 sys 文件系统中移除 /sys/kernel/slab/name 节点的相关资源
if (s->flags & SLAB_TYPESAFE_BY_RCU) {
#ifdef SLAB_SUPPORTS_SYSFS
sysfs_slab_unlink(s);
#endif
list_add_tail(&s->list, &slab_caches_to_rcu_destroy);
schedule_work(&slab_caches_to_rcu_destroy_work);
} else {
kfence_shutdown_cache(s);
debugfs_slab_release(s);
#ifdef SLAB_SUPPORTS_SYSFS
sysfs_slab_unlink(s);
sysfs_slab_release(s);
#else
// 释放 kmem_cache_cpu 结构
// 释放 kmem_cache_node 结构
// 释放 kmem_cache 结构
slab_kmem_cache_release(s);
#endif
}
return 0;
}__kmem_cache_shutdown用于释放缓存和节点内存
int __kmem_cache_shutdown(struct kmem_cache *s)
{
int node;
struct kmem_cache_node *n;
// 释放 slab cache 本地 cpu 缓存 kmem_cache_cpu 中缓存的 slub 以及 partial 列表中的 slub,统统归还给伙伴系统
flush_all_cpus_locked(s);
/* Attempt to free all objects */
// 释放 slab cache 中 numa 节点缓存 kmem_cache_node 中 partial 列表上的所有 slub
for_each_kmem_cache_node(s, node, n) {
free_partial(s, n);
if (n->nr_partial || slabs_node(s, node))
return 1;
}
return 0;
}slab_kmem_cache_release用于释放所有管理结构
void slab_kmem_cache_release(struct kmem_cache *s)
{
// 释放 slab cache 中的 kmem_cache_cpu 结构以及 kmem_cache_node 结构
__kmem_cache_release(s);
kfree_const(s->name);
// 最后释放 slab cache 的核心数据结构 kmem_cache
kmem_cache_free(kmem_cache, s);
}6 参考
https://heapdump.cn/article/5992154
https://heapdump.cn/article/5902112