Xiaoxiao Long∗, Qingrui Zhao∗, Kaiwen Zhang∗, Zihao Zhang∗, Dingrui Wang∗, Yumeng Liu∗, Zhengjie Shu∗
Yi Lu∗, Shouzheng Wang∗, Xinzhe Wei∗, Wei Li, Wei Yin, Yao Yao, Jia Pan, Qiu Shen, Ruigang Yang,
Xun Cao†, Qionghai Dai
摘要:
AGI的探索将具身智能推至机器人研究的前沿。具身智能聚焦于能够在物理世界中感知、推理和行动的智能体。实现稳健的具身智能不仅需要先进的感知与控制,还需将抽象认知扎根于现实世界的交互。物理模拟器与世界模型作为两项基础技术,已成为该探索中的关键使能技术。物理模拟器提供受控、高保真环境,用于训练和评估机器人智能体,支持复杂行为的安全高效开发。相比之下,世界模型赋予机器人对周围环境的内部表征,使其能够进行超出直接感官输入的预测性规划与自适应决策。
本综述系统回顾了通过整合物理模拟器与世界模型学习具身人工智能的最新进展。我们分析了它们在增强智能机器人自主性、适应性与泛化能力方面的互补作用,并探讨了外部模拟与内部建模在弥合仿真训练与实际部署差距中的相互作用。通过整合当前进展并识别开放性挑战,本综述旨在为更强大、更泛化的具身AI系统的发展路径提供全面视角。此外,我们维护了一个活跃的代码仓库,包含最新文献和开源项目,地址为
https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey。
**关键词:**具身智能、世界模型、物理模拟器、自动驾驶、机器人学习
1 引言
1.1 概述
随着人工智能1, 2和机器人技术3, 4的快速发展,智能体与物理世界的交互日益成为研究的核心焦点。AGI------即能够跨越不同领域匹配或超越人类认知能力的系统------的追求面临一个关键问题:如何将抽象推理扎根于现实世界的理解和行动中?
智能机器人已成为关键的具身智能体,通过提供连接计算智能与现实世界交互的物理媒介,为通向AGI铺平道路。与仅基于符号或数字数据运行的非具身智能系统不同,具身智能强调通过与环境的物理交互来实现感知、行动和认知的重要性。这一范式使机器人能够在执行任务时基于物理世界的反馈持续调整其行为和认知,使机器人技术不仅仅是AI的应用,更是通向AGI的关键组成部分。
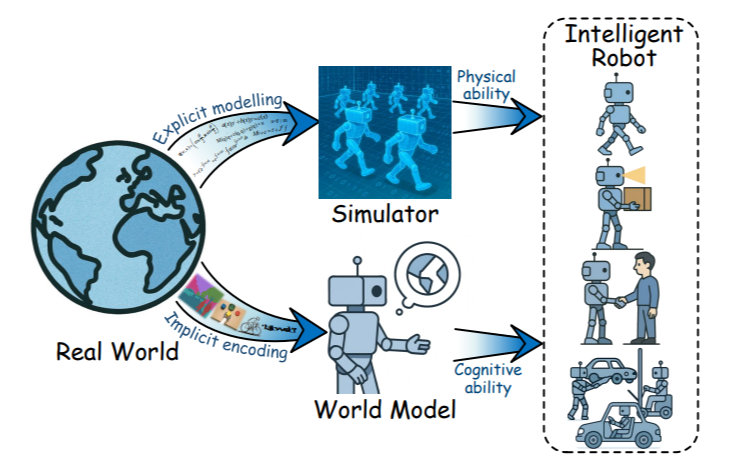
图1:物理模拟器和世界模型在具身智能中发挥关键作用。物理模拟器提供了对现实世界的显式建模,为机器人提供了一个受控环境,使其能够训练、测试和优化行为。世界模型提供了环境的内部表征,机器人能够在认知框架内自主模拟、预测和规划行动。
具身智能的意义不仅限于物理任务的执行。依托物理身体进行行动与感知 5,机器人能够鲁棒地从经验中学习、测试假设并通过持续交互优化策略。这种感官输入、运动控制与认知处理的闭环集成构成了真正自主性与适应性的基础,使机器人能够以更拟人化的方式推理和应对世界 6。
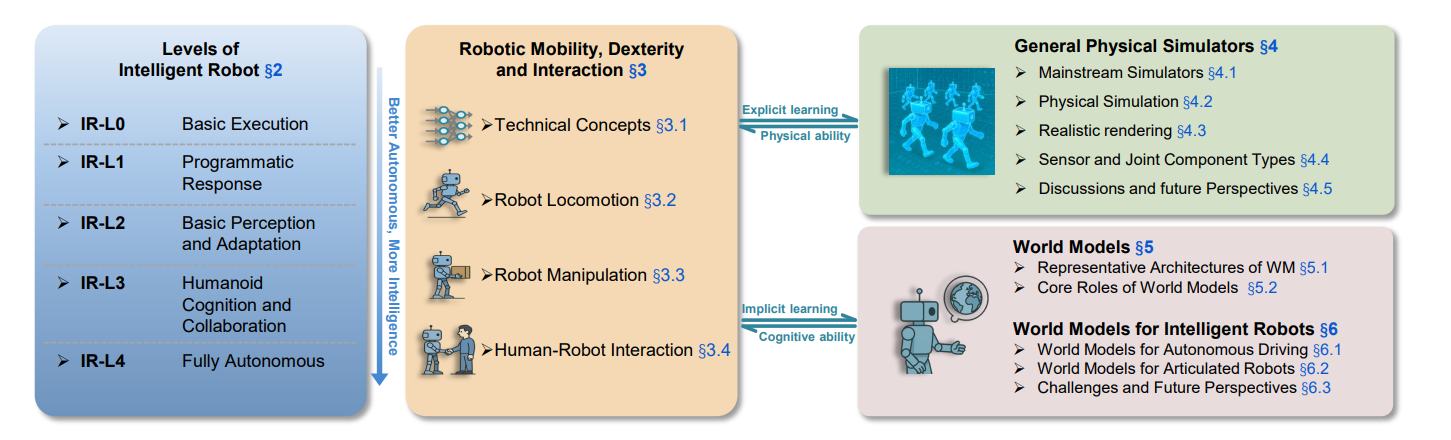
图2:综述大纲:我们将智能机器人发展分为五个级别(IR-L0至IR-L4),并综述了机器人移动、操作和交互方面的进展与关键技术(§3)、物理仿真器在学习和控制算法验证中的应用(§4),以及世界模型作为内部表征在学习、规划和决策中的设计与应用(§5--§6),强调显性和隐性学习路径,以更拟人化的方式6。
随着智能机器人在现实场景中的应用日益广泛,例如养老护理 7、医疗辅助 8、灾难救援 9 和教育 10,其在动态、不确定环境中的自主安全运行能力变得至关重要。然而,应用的多样性和技术进步的快速步伐催生了对系统性框架的迫切需求,以评估和比较机器人能力。建立科学的机器人智能分级体系不仅能够明确技术发展路线图,还能为监管、安全评估和伦理部署提供重要指导。
为应对这一需求,近期研究探索了多种量化机器人能力的框架,例如 DARPA 机器人挑战赛评估方案 11、ISO 13482 服务机器人安全标准 12 以及自主性水平的相关综述 13、14。然而,一个整合了智能认知、自主行为和社会互动维度的综合性分级体系仍然缺失。
本文提出一种智能机器人的能力分级模型,系统性地阐述了从基础机械执行到高级完全自主社会智能的五个渐进级别(IR-L0至IR-L4)。该分类涵盖了自主性、任务处理能力、环境适应性和社会认知等关键维度,为评估和指导智能机器人在整个技术演进谱系中的发展提供了统一框架。
实现机器人智能行为的两大关键技术是物理模拟器和世界模型。两者在提升机器人控制能力及拓展其潜力方面发挥关键作用。模拟器(如Gazebo 15或MuJoCo 16)对物理世界进行显式建模,为机器人提供受控环境,使其能在部署到现实场景前训练、测试和微调行为。模拟器作为训练场,可在无需现实世界实验高成本和高风险的情况下预测、测试和微调机器人的动作。
与模拟器不同,世界模型提供环境的内部表征,使机器人能够在认知框架内自主模拟、预测和规划动作。根据NVIDIA的定义,世界模型是"理解现实世界动态特性(包括物理和空间属性)的生成式AI模型"17。这一概念在Ha和Schmidhuber的开创性工作18中获得广泛关注,该研究展示了智能体如何学习紧凑的环境表征以进行内部规划。
模拟器与世界模型的协同作用提升了机器人在多样化场景中的自主性、适应性和任务性能。本文将探讨机器人控制算法、模拟器与世界模型之间的相互作用。通过分析模拟器如何提供结构化的外部训练环境,以及世界模型如何创建内部表征以支持更具适应性的决策,我们旨在全面理解这些组件如何协同工作以提升智能机器人的能力。
1.2 范围与贡献
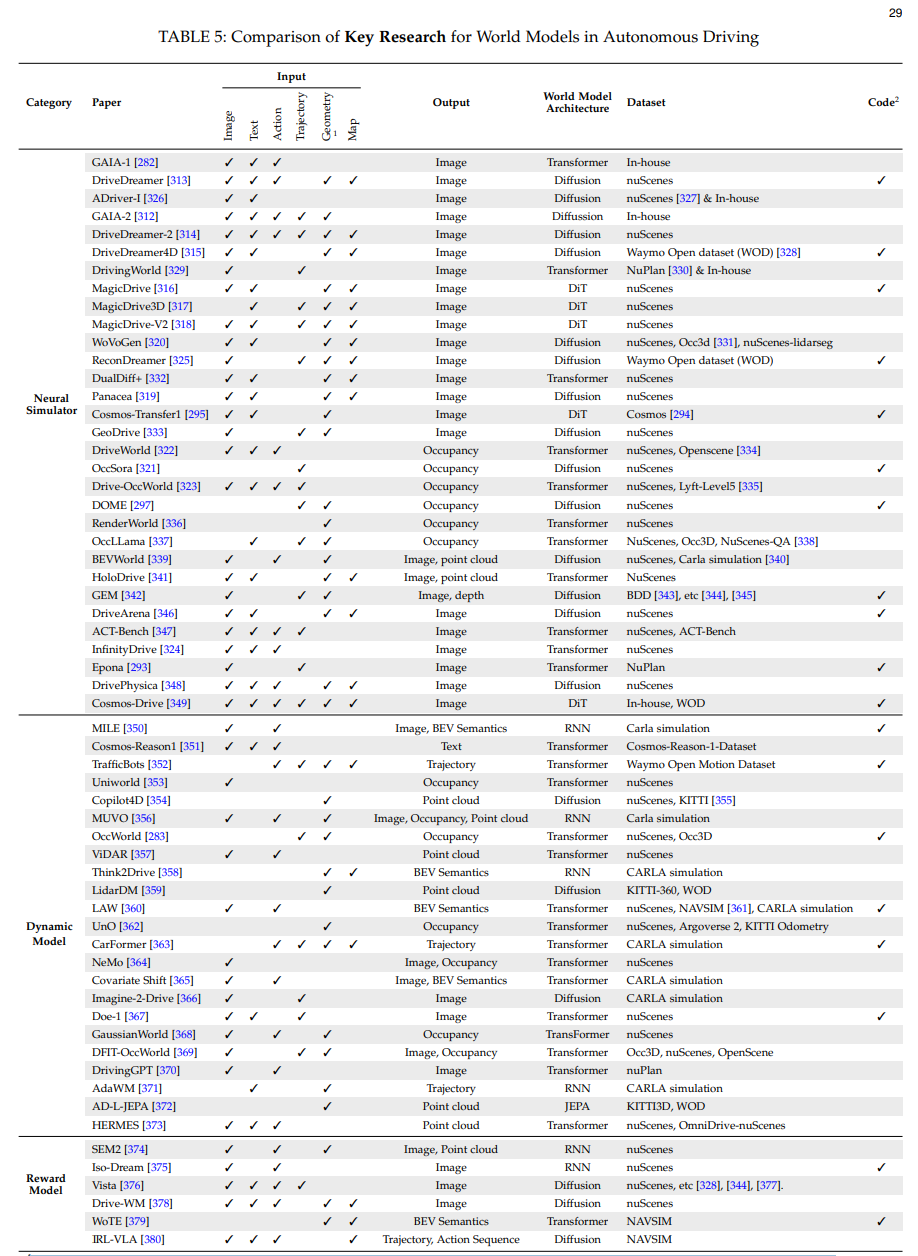
范围:本综述全面分析了机器人控制算法、仿真器和世界模型之间的相互作用,主要聚焦于2018年至2025年的进展。我们的覆盖范围包括传统基于物理的仿真器和新兴世界模型,强调它们在自动驾驶和机器人领域的影响。
与现有文献不同,本综述全面探讨了物理模拟器与世界模型在推动具身智能中的协同关系。以往的综述通常仅关注单一组件(如机器人模拟器19--21和世界模型22--24),而本文则弥合了这两个领域,揭示了它们在智能机器人开发中的互补作用。
贡献.主要贡献如下:
**• 智能机器人等级划分:**提出人形机器人自主性评估的五级分级标准(IR-L0至IR-L4),涵盖自主性、任务处理能力、环境适应性和社会认知能力四个关键维度。
**• 机器人学习技术分析:**系统回顾智能机器人在腿式运动(双足行走、跌倒恢复)、操作(灵巧控制、双手机能协调)及人机交互(认知协作、社会嵌入性)领域的最新进展。
**• 物理仿真器分析:**对主流仿真器(Webots、Gazebo、MuJoCo、Isaac Gym/Sim/Lab等)进行综合对比分析,涵盖物理仿真能力、渲染质量及传感器支持。
**• 世界模型的最新进展:**首先回顾世界模型的主要架构及其潜在作用,例如作为具身智能的可控仿真器、动力学模型和奖励模型;此外,全面讨论了专为自动驾驶和关节机器人等特定应用设计的最新世界模型。
1.3 结构
论文结构摘要如图2所示,具体如下:
• 第1节介绍具身AI的重要性,并阐述物理仿真器和世界模型如何推动具身AI的发展。
• 第2节提供了一个五级智能机器人综合分级系统。
-- 2.1 等级标准
-- 2.2 等级因素
-- 2.3 分级级别
• 第3节回顾智能机器人任务在移动性、灵巧性和人机交互方面的当前进展。
-- 3.1 相关机器人技术
-- 3.2 机器人运动
-- 3.3 机器人操作
-- 3.4 人机交互
• 第4节讨论当代机器人研究中主流仿真器的优缺点。
-- 4.1 主流仿真器
-- 4.2 仿真器的物理特性
-- 4.3 渲染能力
-- 4.4 传感器与关节组件类型
-- 4.5 讨论与未来展望
• 第5节介绍世界模型的代表性架构和核心作用。
-- 5.1 世界模型的代表性架构
-- 5.2 世界模型的核心作用
• 第6节进一步回顾世界模型在智能体(包括自动驾驶和关节机器人)中的应用与挑战。
-- 6.1 自动驾驶中的世界模型
-- 6.2 关节机器人中的世界模型
-- 6.3 挑战与未来展望
2 智能机器人级别
随着人工智能、机械工程、传感器融合和人机交互等领域的快速发展,智能机器人正逐步从实验室走向实际应用场景,包括老年护理7、医疗辅助8、灾害救援9和教育10。与传统工业机器人不同,智能机器人强调基于类人结构完成复杂的认知、感知和执行任务。真实环境中的动态性和不确定性使得能力评估成为关键问题。因此,建立科学的能力分级体系不仅有助于明确技术发展路线,还能为机器人监管和安全评估提供指导。
目前,已有若干研究尝试量化机器人能力,例如DARPA机器人挑战赛框架用于评估执行复杂任务的能力 11、ISO 13482服务机器人安全分级标准 12,以及关于机器人自主性等级的综述 13, 14。然而,目前仍缺乏将"智能认知"与"自主行为"两个维度相结合的综合分级体系。为此,本文提出并系统阐述了从IR-L0到IR-L4的智能机器人能力分级模型,涵盖从机械操作级别到高级社会交互级别的完整技术演进路径。
2.1 级别标准
该标准依据机器人在不同环境中的任务执行能力、自主决策深度、交互复杂性及伦理认知对其进行分类。涵盖的核心维度如下:
• 机器人独立完成任务的能力,从完全依赖人工控制到完全自主。
• 机器人可处理任务的难度,从简单重复性劳动到创新性问题解决。
• 机器人在动态或极端环境中的工作能力。
• 机器人理解、互动及应对人类社会中社交情境的能力。
2.2 等级因素
机器人的智能等级根据以下五个因素进行分级。
**• 自主性:**机器人在各种任务中自主决策的能力
**• 任务处理能力:**机器人可处理任务的复杂度
**• 环境适应性:**机器人在不同环境中的适应能力
**• 社会认知能力:**机器人在社交场景中的智能水平

图3:智能机器人等级:从基础执行到完全自主
分级与层级因素的关系列于表1中。
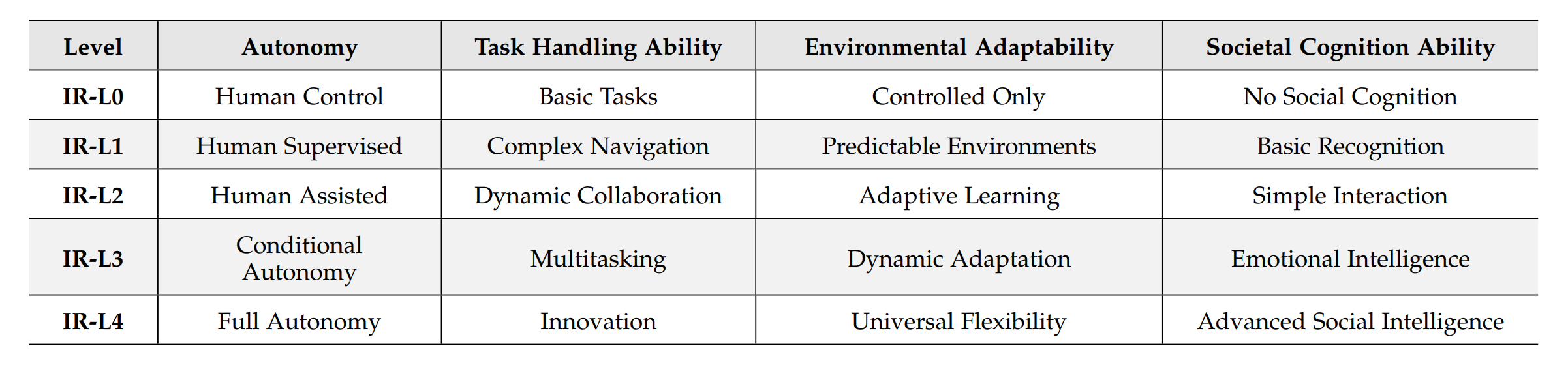
表1:分级与层级因素的关系
分级与层级因素的关系列于表1中。
2.3 分类级别
2.3.1 IR-L0:基础执行级别
IR-L0 代表该系统中的基础执行级别,其特征是完全非智能、程序驱动型的属性。该级别机器人专注于执行高度重复、机械化、确定性任务,例如工业焊接和固定路径物料搬运。这种"低感知-高执行"的操作模式使机器人完全依赖预定义的程序指令或实时遥操作。它缺乏环境感知、状态反馈或自主决策能力,形成单向闭环系统,即"命令输入-机械执行" 25。潜在的技术要求总结如下:
**• 硬件:**高精度伺服电机和刚性机械结构,运动控制器基于PLC或MCU。
**• 感知:**极其有限,通常仅涉及限位开关、编码器等。
**• 控制算法:**主要基于预定义脚本、动作序列或遥操作,无实时反馈回路。
**• 人机交互:**无,或仅限于简单按钮/遥操作。
2.3.2 IR-L1:程序化响应级别
IR-L1机器人具有有限的基于规则的反应能力,能够执行预定义的任务序列,例如清洁机器人和接待机器人所执行的任务。这些系统利用基本传感器(包括红外、超声波和压力传感器)来触发特定的行为模式。它们无法处理复杂或意外事件,只能在具有明确规则的封闭任务环境中保持操作稳定性。它们体现了"有限感知-有限执行"的范式,代表了基础机器人智能的开端26。潜在的技术要求总结如下:
**• 硬件:**集成基本传感器(红外、超声波、压力)与适度增强的处理器能力。
**• 感知:**障碍物、边界及简单人体运动的检测。
**• 控制算法:**规则引擎和有限状态机(FSM),辅以基本SLAM或随机游走算法。
**• 人机交互:**支持简单命令-响应协议的基本语音和触摸界面。
**• 软件架构:**嵌入式实时操作系统,具备基本的任务调度能力。
2.3.3 IR-L2:基本感知与适应层级
IR-L2机器人引入了初步的环境感知能力和自主能力,代表了机器人智能的重大进步。其特点包括对环境变化的基本响应能力以及在多种任务模式间切换的能力。例如,该级别的服务机器人能够根据语音命令执行"送水"或"导航指引"等不同任务,同时在路径执行过程中避障。这些系统需要集成感知模块(摄像头、麦克风阵列、LiDAR)和基础行为决策框架,如有限状态机(FSM)或行为树27。
尽管人工监督仍然必不可少,但IR-L2机器人相较于IR-L1系统展现出显著更高的执行灵活性,标志着其向真正的"上下文理解"迈进。潜在的技术要求总结如下:
**• 硬件:**多模态传感器阵列(摄像头、LiDAR、麦克风阵列)搭配增强的计算资源。
**• 感知:**视觉处理、听觉识别和空间定位能力,支持基本物体识别和环境建图。
**• 控制算法:**有限状态机、行为树、SLAM实现、路径规划和避障系统。
**• 人机交互:**语音识别与合成能力,支持基本指令的理解与执行。
**• 软件架构:**模块化设计框架,支持并行任务执行及初步优先级管理系统。
2.3.4 IR-L3:人形认知与协作级别
IR-L3机器人在复杂动态环境中具备自主决策能力,同时支持复杂的多模态人机交互。这些系统能够推断用户意图,相应调整行为,并在既定的伦理约束下运行。例如,在养老护理应用中,IR-L3机器人通过分析语音模式和面部表情检测老年患者的情绪状态变化,并采取相应的安慰措施或发出紧急警报。潜在的技术要求总结如下:
**• 硬件:**集成全面多模态传感器套件(深度摄像头、肌电传感器、力传感阵列)的高性能计算平台。
**• 感知:**视觉、语音和触觉输入的多模态融合;情感计算用于情绪识别和动态用户建模。
**• 控制算法:**用于感知和语言理解的深度学习架构(CNNs、Transformers);用于自适应策略优化的强化学习;用于复杂任务工作流管理的规划与推理模块。
**• 人机交互:**多轮自然语言对话支持;面部表情识别与反馈;基础共情与情绪调节能力。
**• 软件架构:**支持任务分解与协同执行的面向服务分布式框架;集成学习与自适应机制。
**• 安全与伦理:**嵌入式伦理治理体系,防止不安全或不合规行为。
2.3.5 IR-L4:完全自主级别
IR-L4代表了智能机器人的巅峰:系统在感知、决策和执行方面具备完全自主能力,能够在任何环境中独立运行而无需人工干预。这类机器人具备自我进化的伦理推理能力、高级认知能力、同理心以及长期适应性学习能力。除了处理开放式任务外,它们还参与复杂的社交互动,包括多轮自然语言对话、情感理解、文化适应和多智能体协作。潜在的技术要求总结如下:
**• 硬件:**高度仿生结构,具备全身多自由度关节;分布式高性能计算平台。
**• 感知:**全向、多尺度、多模态传感系统;实时环境建模与意图推断。
**• 控制算法:**集成元学习、生成式AI和具身智能的AGI框架;自主任务生成与高级推理能力。
**• 人机交互:**自然语言理解与生成;复杂社交情境适应;同理心与伦理考量。
**• 软件架构:**云-边-端协同系统;支持自进化与知识迁移的分布式智能体架构。
**• 安全与伦理:**嵌入式动态伦理决策系统,约束行为并确保在伦理困境中做出道德上正确的选择。
3 机器人移动性、灵巧性与交互
在各种智能机器人的形态中,人形机器人以其类人外观为特征,能够无缝融入以人类为中心的环境并提供有意义的帮助,因此它们是具身智能的关键物理体现。
近年来,机器学习技术的快速发展在机器人全身控制和通用操作方面取得了重大突破。本章首先概述智能机器人领域的基础技术方法,然后回顾机器人运动与操作的最新进展,最后探讨旨在实现自然直观的人机交互的持续研究。
3.1相关机器人技术
3.1.1 模型预测控制(MPC)
模型预测控制(MPC)28 是一种强大的控制策略,在过去二十年中在人形机器人领域获得了广泛应用。其核心是基于优化的方法,通过动态模型预测系统未来行为,并在每个时间步求解优化问题以计算控制动作。这使得控制器能够显式处理输入和状态的约束,特别适用于人形机器人等复杂高维系统29。
Tom Erez 等人提出了一套全面的实时MPC系统,将MPC应用于人形机器人的完整动力学,使其能够完成站立、行走和从扰动中恢复等复杂任务30。在此基础上,2015年,Jonas Koenemann、Andrea Del Prete、Yuval Tassa、Emanuel Todorov等人实现了完整的MPC,并在物理HRP-2机器人上实时应用,首次在复杂动力学机器人上实现了全身模型预测控制器的实时应用31。
3.1.2 全身控制(WBC)
人形机器人中的全身控制(WBC)是一个综合框架,使机器人能够同时协调所有关节和肢体以实现不同的运动。全身控制的基本方法通常涉及将机器人的运动和力目标表示为一组具有优先级的任务,例如保持平衡、跟踪期望轨迹或用手施加特定力。这些任务随后被转化为数学约束和目标,并通过优化技术或分层控制框架32求解。
在实现过程中,WBC通常采用动态建模、逆运动学求解和优化算法等技术,以确保机器人在满足物理约束的同时实现期望的运动行为。2000年代初,Oussama Khatib及其合作者提出了用于控制冗余机械臂的操作空间公式,并将其扩展至人形机器人33。基于优化的WBC具有高度灵活性,支持模块化添加或移除约束,并通过设置不同的任务层次或软任务权重来解决冲突约束34--36。近年来,随着人工智能(如强化学习)的发展,研究者提出了ExBody237和HugWBC38等框架,这些框架在模拟环境中训练控制策略并将其迁移至实际机器人,实现了更自然、更具表现力的全身运动控制。
3.1.3 强化学习
强化学习(RL)39 是机器学习的一个分支,在人形机器人领域影响力日益增强。RL 的核心思想是,智能体(例如人形机器人)可以通过与环境交互并接收奖励或惩罚形式的反馈来学习执行复杂任务。与需要显式编程或行为建模的传统控制方法 40, 41 不同,RL 使机器人能够通过试错自主发现最优动作,特别适用于人形机器人常面临的高维、动态及不确定环境 42。
强化学习在人形机器人中的应用可追溯至20世纪90年代末和21世纪初。1998年,森本正弘(Masahiro Morimoto)和东野健二(Kenji Doya)提出了一种强化学习方法,使模拟的双关节三连杆机器人能够自主学习从躺卧状态到站立的动态动作 43。此后,RL 被用于实现人形机器人的复杂行为;DeepLoco 44 及其他研究 45, 46 对深度强化学习在双足任务中的能力进行了广泛探索,但尚未证明适用于物理机器人。2019年,谢等人采用迭代强化学习和确定性动作随机状态(DASS)元组,逐步优化奖励函数和策略架构,使物理 Cassie 双足机器人能够实现稳健的动态行走 47。
3.1.4 模仿学习
模仿学习(IL)是机器人学中的一种范式,机器人通过观察和模仿人类或其他智能体提供的演示来学习执行任务。模仿学习的核心理念在于无需显式编程或手工设计的奖励函数,使仿人机器人能够更高效、直观地习得复杂行为。通过利用演示数据,机器人可以学习行走、操作或社交互动等技能,而这些技能若通过传统控制或强化学习方法则难以明确指定3、48--50。
在仿人机器人运动控制中,模仿学习通常利用Retargeting后的人体动作捕捉数据,或基于模型轨迹规划生成的参考步态(如自然行走、跑步等),并促使机器人在仿真中遵循这些参考轨迹,以实现更自然、稳定的运动步态51--53。
虽然IL有效利用现有知识进行学习,但其面临诸多挑战,如获取专家演示数据的成本高昂、数据多样性不足、质量担忧以及流程耗时等问题。此外,基于有限演示数据训练的策略往往泛化能力较差,难以适应新环境或任务,所学操作技能也可能较为单一。为应对这些挑战,研究人员和公司正致力于开发更高效的数据收集硬件平台或遥操作技术以扩充数据49、54、55,同时探索新型训练数据,例如从视频数据中提取人类动作56。
3.1.5 VLA模型
VLA模型是一种跨模态人工智能框架,整合了视觉感知、语言理解和动作生成。其核心概念是利用LLMs的推理能力,将自然语言指令直接映射到物理机器人的动作。

图4:人形机器人非结构化环境适应进展时间线
2023年,Google DeepMind推出了RT-2,首次将这一范式应用于机器人控制,通过将机器人控制指令离散化为类语言token,实现了端到端的视觉-语言-动作映射65。通过利用互联网规模的视觉-语言数据进行预训练,机器人能够理解先前未见过的语义概念,并通过思维链推理生成合理的动作序列。随后,众多端到端VLA模型涌现 4 66 67 68 69 70 71,进一步推动了VLA模型在机器人领域的应用与发展。
尽管当前VLA模型已取得显著进展,但仍存在若干关键挑战。这些模型往往难以可靠地处理此前未遇到的任务或环境。此外,实时推理约束限制了它们在动态场景中的响应能力。此外,训练数据集中的偏差、跨模态语义 grounding 的困难以及系统集成的高计算复杂度继续阻碍进一步发展 72。
3.2 机器人运动
机器人运动的目标是实现自然的运动模式,包括行走、奔跑和跳跃。通过整合感知、规划和控制等多个领域,具备运动能力的机器人可归类于IR-L2级别。这种整合使机器人能够动态适应多变地形、外部干扰和突发情况,从而实现稳健且流畅的双足运动。此外,自主从意外事件中恢复的能力减少了对人工干预的依赖,为更高智能与自主性铺平了道路。本节将探讨腿式运动的最新进展,并讨论跌倒预防与恢复策略。
3.2.1 腿式运动
双足机器人在复杂地形导航、模拟人类行为以及无缝融入以人为中心的环境中具有独特优势。双足步态控制领域的研究可分为两个任务:Unstructured Environment Adaption ,强调在复杂、未知或动态环境中保持稳定行走的能力;以及High Dynamic Movements,聚焦于在跑步、跳跃等高速动态运动中实现稳定性和敏捷性的平衡
非结构化环境适应。"非结构化环境"通常指复杂的自然或人工地形,如崎岖的山路、布满碎石的地面、湿滑的草地、楼梯以及其他不可预测的障碍物。早期双足行走稳定化研究主要采用位置控制的人形机器人。2008年,桑霍·海恩57提出了一种基于被动性的接触力控制框架,使SARCOS人形机器人73能够在高度变化和倾斜角度随时间变化的室内地形上主动保持平衡。后续研究探索了多种提升运动稳定性的策略,包括用于地形适应的在线学习74、结合地形估计的柔顺控制58,以及线性倒立摆模型(LIPM)与足部力控制的结合75,这些在2010年由角田等人在HRP-4C人形机器人上得到验证。
上述方法仅使人形机器人具备有限的地形适应能力,例如在细梁、路面或平坦但倾斜的坡道上行走。这是由于位置控制关节的高减速比。这些关节具有高阻抗,在输出轴或末端执行器(hand and foot)受到较大冲击时容易损坏 76。为了在未知环境中实现更好的适应性,现代人形和四足机器人采用低减速比的力控关节,能够在较大冲击下提供更好的顺应性和平稳的响应 77, 78。
随着力控人形机器人的发展和计算能力的提升,研究人员能够开发和实施更复杂的控制算法85,这进一步提升了机器人在多样化环境中的适应性。Jacob Reher等人提出了一种全面的全身动力学控制器,明确考虑了Cassie双足机器人中的被动弹簧机构59,成功实现了包括户外草地在内的多种地形上能稳定双足行走。George Mesesan等人将运动发散分量(DCM)用于质心轨迹规划,并结合基于被动性的全身控制器(WBC)计算关节力矩60,在TORO机器人上实现了软垫上的动态行走。

图5:人形机器人高动态运动发展时间线
除了本体感觉盲行外,研究人员还探索了整合外部感知与路径规划模块以应对更复杂的环境。Jiunn-Kai Huang等人将低频路径规划器与高频反应式控制器相结合,生成平滑的反馈驱动运动指令62。这使Cassie Blue机器人能够自主穿越更复杂的地形,例如密歇根大学Wave Field。
基于学习的方法在户外复杂环境中也展现出良好的稳定性。2020年,Joonho Lee等人86首次在真实世界中成功应用强化学习于腿式运动,其在户外环境中的表现优于传统方法87。Jonah Siekmann等人使用Cassie机器人实现了无视觉楼梯穿越61。他们采用域随机化方法调整楼梯尺寸和机器人动力学参数,使学习到的策略成功迁移至现实场景。研究人员还利用深度相机和LiDAR构建高程地图63、感知内部模型(PIM)88或端到端策略64,显著提升了机器人在不同地形中的移动能力。如今,机器人能够穿越楼梯、跨越障碍物,甚至跳跃跨越宽度达0.8米的间隙。
**高动态运动。**跑步和跳跃等高动态运动对双足机器人的控制系统提出了更高要求。在快速运动过程中,机器人必须在极短时间内处理快速支撑转换、姿态调整和精确力控制。
早期研究采用简化的动力学模型,例如弹簧负载倒立摆(SLIP)89、线性倒立摆模型(LIPM)90和单刚体模型(SRBM)91,以降低计算复杂度并实现实时控制。熊晓斌和Aaron D. Ames开发了一种通过基于控制李雅普诺夫函数的二次规划(CLF-QP)79控制的简化弹簧质量模型,成功使卡西机器人实现18 cm垂直跳跃。Qi等80提出了一种基于压力中心(CoP)引导的角动量控制器,通过在飞行中稳定角动量,实现了高达0.5米的垂直跳跃。近期,He等83引入了结合模型预测控制(MPC)框架的质心动力学模型(CDM),称为CDM-MPC,以在KUAVO人形机器人上实现连续跳跃动作。
RL方法也被应用于动态任务。学习到的隐式机器人动力学在跑步81、跳跃82和离散地形跑酷92等活动中取得了有前景的结果,显著提升了双足运动能力。
从零开始训练高度动态的动作通常需要繁琐的奖励函数设计和参数调优。模仿学习利用大量人类运动数据集93,实现了表现力强且动态的机器人行为。对抗性运动先验(AMP)94从动作捕捉数据中提取基于风格的奖励,增强了机器人动作的自然性。Exbody 37,95、OmniH2O 96和ASAP 84等框架实现了自然且敏捷的全身运动。ASAP专门解决仿真到现实的差距,实现了诸如后仰跳投等复杂动作。
3.2.2 跌倒防护与恢复
人形机器人易因不稳定而跌倒,可能导致硬件损坏或操作中断。因此,人形机器人的跌倒防护及跌倒后高效恢复站立姿势已成为人形机器人研究中的重要课题。
**基于模型的方法。**早期基于模型的跌倒防护与恢复控制主要借鉴生物力学原理,模仿人类跌倒过程的生物力学特征,并结合优化控制方法生成运动轨迹,以减少跌倒时的损伤并实现稳定站立恢复。
UKEMI 97 控制机器人在跌倒时的姿态,以分散冲击力并减少对关键部件的损伤。他们还设计了特定的关节运动模式和控制策略,以实现机器人跌倒恢复 98。孟立波等人通过人体跌倒的生物力学分析提出了一种跌倒运动控制方法,实现了适应不同跌倒方向的冲击保护控制 99。董等人提出了一种柔顺控制框架,使机器人能够根据外部扰动调整刚度和阻尼特性,类似于人类调节肌肉刚度以维持平衡的方式 100。
**基于学习的方法。**这类方法不依赖高精度模型且具备强大的泛化能力,能够更好地应对该任务。HiFAR 102 通过多阶段课程学习方法逐步提升场景难度,训练人形机器人在多种真实场景中实现高成功率的摔倒恢复。HoST 101 利用平滑正则化和隐式动作速度限制,在Unitree G1机器人上实现了多种环境中的稳健自然站立动作。Embrace Collisions 103 通过全身接触扩展了机器人与环境的交互能力,突破了仅限于手和脚的限制;通过模仿翻滚起立、侧躺及其他多接触行为,该方法提升了人形机器人在现实场景中的运动范围和适应性。

图6:Tao Huang等101提出的HOST,使Unitree G1机器人能在复杂环境中从多种姿势起身。
3.3 机器人操作
机器人操作任务涵盖从拾取物体等简单动作到涉及装配或烹饪的复杂序列的广泛活动。本节将回顾机器人操作领域的研究进展,重点关注不同任务所需协调复杂度的逐步提升。从使用单个末端执行器(如手或夹爪)的操作开始,逐步过渡到双臂协调,最后探讨需要对整个机器人进行集成控制的全身操作任务。
3.3.1 单手操作任务
单手操作指的是使用单个末端执行器与物体交互并进行操作,例如平行夹爪或灵巧机械手。此类任务从基础的拾取和放置操作到更复杂的动作,如推动、插入、工具使用以及操作可变形或关节式物体不等。这些任务的复杂程度取决于末端执行器的性能及其交互环境。
**夹爪操作。**平行双指夹爪104是用于抓取、放置和工具使用等操作的最常见末端执行器,依靠简单的开合动作。早期研究侧重于精确的物理模型和预编程105,在工业自动化等结构化环境中(如具有预定轨迹)或采用视觉伺服106进行反馈时效果良好。这些方法在非结构化环境、物体多样性以及复杂交互(如摩擦、变形)中适应性不足。

图 7:DexCap 54 是一种便携式动作捕捉系统,能够采集人手动作,使机器人能够完成从简单抓取到复杂操作(如Tea preparing)等任务。
基于学习的方法克服了这些限制。在感知方面,PoseCNN 107 实现了实例级6D位姿估计,而NOCS 108 推进了类别级估计以实现泛化。功能affordance学习方面,AffordanceNet 109 通过监督学习识别可操作区域,Where2Act 110 利用自监督模拟交互。模仿学习方面,神经描述场(NDFs)111 增强了策略泛化能力,Diffusion Policy 3 利用扩散模型处理多模态动作,RT-2 112 整合基础模型以解析复杂指令。
任务导向的操纵随着这些进展而扩展。除了基本抓取 3 外,机器人通过避碰(例如CollisionNet 113、PerAct 114)处理杂乱环境,操作可变形和关节式物体 115--118,并执行双臂协调 49、灵巧手操作 54 和全身控制 119。这一演进凸显了基于夹爪的操纵在多样复杂任务中能力的提升。
**灵巧手操作。**灵巧操纵旨在使机器人能够以复杂、精确的方式与物理世界交互,类似于人手,这是机器人学数十年来的核心挑战 120。该领域致力于实现类人般的多功能性和精确性,处理需要精细控制和适应性的任务。
早期灵巧操作研究集中在硬件设计和理论基础。开创性设计如Utah/MIT Hand 121和Shadow Hand 122探索了高自由度和仿生结构(例如肌腱驱动机制),而BarrettHand 123展示了用于自适应抓取的欠驱动设计。同时,Napier对人类抓握模式的分类124以及Salisbury和Craig对多指力控制与运动学的分析125为后续研究奠定了基础。传统基于模型的控制方法在高维状态空间和复杂接触动力学方面存在困难,限制了其在现实世界中的有效性。基于学习的方法,包括两阶段和端到端方法,此后已成为主流,利用机器学习应对这些挑战。
两阶段方法首先生成抓取位姿,随后控制灵巧手实现这些位姿。关键挑战在于从视觉观测中生成高质量位姿,这通过基于优化126-128、基于回归129130或基于生成131-140的策略解决,常与运动规划结合。例如,UGG 136 使用扩散模型统一位姿与物体几何生成,而SpringGrasp 141 则通过建模部分观测中的不确定性来提升位姿质量。尽管这些方法得益于解耦的感知与控制以及仿真数据,但由于缺乏闭环反馈,仍对干扰和标定误差敏感。
端到端方法直接通过强化学习或模仿学习建模抓取轨迹。强化学习在仿真中训练策略以实现现实世界迁移142--144,例如DexVIP145和GRAFF146将视觉affordance线索与强化学习相结合。DextrAH-G147和DextrAH-RGB148通过大规模仿真实现现实世界泛化,但sim-to-real差距和样本效率问题仍具挑战性。由人类演示驱动的模仿学习54146149在复杂任务中表现优异,但泛化能力不足。创新方法如SparseDFF150和Neural Attention Field151通过三维特征场提升泛化能力,而DexGraspVLA152采用视觉-语言-动作框架:结合预训练的视觉-语言模型与基于扩散的动作控制器。在零样本设置下,其在1,287种未见过的对象、光照和背景组合中达到90.8%的成功率。
3.3.2 双臂操作任务
双臂操作是指机器人需要协调使用双臂完成的任务,使机器人能够执行诸如协同运输、精密装配以及处理柔性或可变形物体等复杂操作155。与单臂操作相比,这些双臂任务面临更大的挑战,包括高维状态-动作空间、臂间及环境碰撞的潜在风险,以及有效双臂协调和动态角色分配的必要性。
早期研究通过引入归纳偏差或结构分解来简化学习与控制,从而应对这些挑战。例如,BUDS 156 将双臂操作任务分解为稳定器和执行器两种功能角色,这不仅降低了双臂动作空间的复杂性,还促进了双臂间的有效协作。该框架在切菜、拉拉链和盖标记笔帽等任务中表现出稳健的性能。同时,SIMPLe 157 利用图高斯过程(GGP)表征双臂操作中的运动基元,确保轨迹稳定性,并借助运动学反馈从单臂演示中学习双臂协调。

图8:(1)ALOHA系列49,153是一款低成本开源硬件系统,支持细粒度、复杂及长时程移动双臂操作任务的学习,例如slot battery和cooking shrimp,为后续研究奠定机器人平台基础。(2)RoboTwin 2.0154通过模拟器生成模拟数据增强双臂操作能力,提供50个双臂任务、731种不同物体和5种实体,全面支持研究与开发。
随着大规模数据收集和模仿学习的进步,端到端方法在双臂操作研究中日益突出。ALOHA系列49153158通过利用现成硬件和定制3D打印组件,高效收集用于高精度双臂操作的多样化、大规模演示数据,体现了这一趋势。这些数据集促进了具有强大泛化能力的端到端神经网络的训练。特别是,ACT 49将动作分块与条件变分自编码器(CVAE)框架结合,使机器人能够从仅10分钟的演示数据中学习有效策略,并在电池插入和杯盖开启等具有挑战性的任务中实现高成功率。在此基础上,Mobile ALOHA 153引入移动底盘并进一步简化ACT流程,实现移动双臂任务的高效完成。此外,RDT-1B 50提出基于扩散DiT架构的双臂操作基础模型,统一异构多机器人系统的动作表征。该方法通过零样本泛化到新任务和平台,解决了数据稀缺问题。
尽管这些研究显著推动了双臂操作领域的发展,但其重点主要集中在配备平行夹爪的系统上。相比之下,灵巧手的双臂操作带来了额外的挑战,特别是在精细协调和高维控制方面。最近,几项研究 140, 159, 160 探索了基于RL的方法,将人类双臂操作技能迁移到灵巧手上,从而实现更复杂的操作能力。

图9:江云帆等119提出的BRS使人形机器人能够执行需要Whole-Body Manipulation Control的多种复杂家务,例如清洁马桶、倒垃圾和整理架子。
总结来说,双臂操作研究已从依赖任务特定的强先验和结构简化的方法,发展为利用大规模演示的数据驱动端到端框架。这些进展显著提升了双臂机器人系统的鲁棒性、通用性和多功能性,使其能够处理日益多样化的复杂操作任务。此外,旨在将这些方法适配到灵巧手的持续研究正在扩展双臂操作的能力,使机器人能够执行越来越复杂且类人的任务。
3.3.3 全身操作控制
全身操作是指人形机器人利用全身(包括双臂155、躯干161、轮式或腿式底盘162及其他部件163)与物体交互并操作的能力。
近年来,人形机器人基于学习的全身操控技术取得了显著进展,聚焦于提升机器人在复杂环境中的自主性、适应性和交互能力。趋势之一是利用大型预训练模型(如LLMs、VLMs和生成模型)来增强语义理解和泛化能力。例如,TidyBot 164 利用LLMs的归纳能力,从少量示例中学习个性化的家庭整理偏好。MOO 165 通过VLMs将语言指令中的物体描述映射到视觉观测,实现对未见过的物体类别的零样本操作泛化。HAR-MON 166 结合人类运动生成先验与VLM编辑技术,基于自然语言生成多样且富有表现力的人形机器人动作。
视觉演示同样指导操作技能的学习。OKAMI 167 提出了一种物体感知重定向方法,使人形机器人能够从单一的人体RGB-D视频中模仿技能,并适应不同的物体布局。iDP3 168 通过改进的3D扩散策略,实现了从单场景遥操作数据训练的多场景任务执行策略。为实现稳健灵活的全身控制,OmniH2O 96 采用强化学习Sim-to-Real方法,训练协调运动与操作的全身控制策略,并设计了一个与VR遥操作和自主智能体兼容的通用运动学接口。
HumanPlus 6 系统将基于Transformer的底层控制策略与视觉模仿策略相结合,使仅需单目RGB相机的人形机器人能够进行全身动作示范并自主学习复杂技能。该系统能够在现实世界中学习全身操作和运动技能,例如穿鞋、站立和行走。WB-VIMA 119 通过自回归动作去噪建模全身动作的层次结构及特定人形机器人形态中组件间的相互依赖关系,预测协调的全身动作,有效学习全身操作以完成具有挑战性的现实世界家庭任务。
3.3.4 人形机器人操作中的基础模型
基础模型(FMs)是指在海量互联网数据上预训练的大规模模型,包括大型语言模型(LLMs)、视觉模型(VMs)和视觉-语言模型(VLMs)。凭借其在语义理解、世界知识整合、逻辑推理、任务规划和跨模态表征方面的强大能力,这些模型可直接部署或微调以应用于广泛的下游任务。
Foundation Models使人形机器人能够在复杂、动态和非结构化环境中执行操作任务,通常涉及复杂的环境感知与建模、抽象任务理解以及长序列和多步骤任务的自主规划。图10展示了利用foundation models驱动人形机器人操作的两种主要技术范式。
层次化方法利用预训练的语言或视觉-语言基础模型作为高级任务规划与推理引擎,以理解用户指令、解析场景信息并将复杂任务分解为子目标序列。这些高级输出(通常是可操作的知识或image-language tokens)随后传递给底层动作策略(通常为通过模仿学习或强化学习训练的专家策略),以执行物理交互动作。Transformer已成为此类底层策略的常见选择,因其可扩展性。
该分层架构利用基础模型强大的语义和逻辑推理能力,同时结合底层策略在特定动作执行中的高效性,使机器人在多任务处理和跨场景泛化方面表现出色169--173。该方法的优势在于模块化和可解释性,但也面临高层与底层之间的信息瓶颈和语义鸿沟等挑战。例如,Figure AI展示了用于灵巧操作和双人形机器人协作的分层VLA模型Helix174,而NVIDIA开发了通用人形机器人基础模型GR00T N1175。π0模型176将预训练的视觉-语言模型与流匹配架构相结合,实现对多种机器人平台的通用控制,高效执行洗衣折叠和物体分类等复杂灵巧任务。
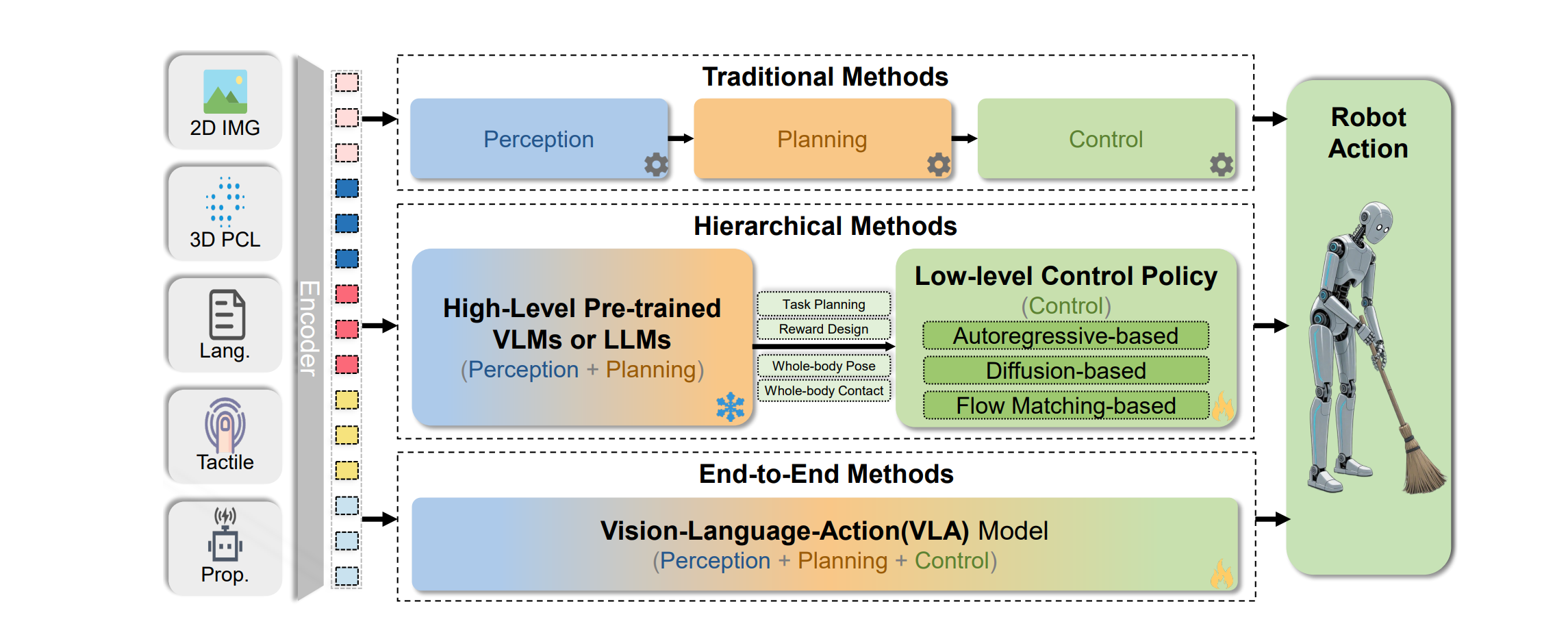
图10:三种常见人形机器人操作框架(传统、分层和端到端)的示意图,展示了输入→动作的数据流及结构差异。
端到端方法直接将机器人操作数据整合到基础模型的训练或微调过程中,构建端到端的视觉-语言-动作(VLA)模型4、68、177、178。这些模型直接学习从多模态输入(如图像和语言指令)到机器人动作输出的映射。通过在大量机器人交互数据上进行预训练或微调,VLA模型可以隐式地学习任务规划、场景理解和动作生成,无需显式分层。这种端到端方法允许模型针对下游部署任务进行整体优化,可能实现更优的性能和更快的响应速度,但通常需要大量机器人专用数据,且模型可解释性相对较弱。例如,Google DeepMind的RT(机器人Transformer)系列112、177是典型的操作VLA模型。
3.4 人机交互(HRI)
人机交互(HRI)专注于使机器人能够理解并响应人类的需求和情感,促进高效协作、陪伴及个性化服务,广泛应用于家庭、医疗保健、教育和娱乐等领域179。为了准确理解和适应多样化的人类行为,机器人需要具备类人能力,如多模态感知、自然语言处理和协同控制。
人机交互研究可分为三个主要维度:Cognitive Collaboration、Physical Reliability 和 Social Embeddedness。这些维度分别关注机器人如何感知和理解人类认知模式、协调物理动作以及有效融入人类社会环境。
以机器人在拥挤环境中导航为例,Cognitive Collaboration指机器人识别行人的潜在紧迫性;Physical Reliability通过调整速度和轨迹避免碰撞来体现;Social Embeddedness则通过机器人主动使用语言提示或肢体语言协商通行权、建立临时社交规范来体现。此类综合能力使机器人能够无缝融入日常人类活动,提升交互的自然性与效率。后续章节将详细阐述各维度的理论基础、当前研究进展、主要研究方向及代表性文献。
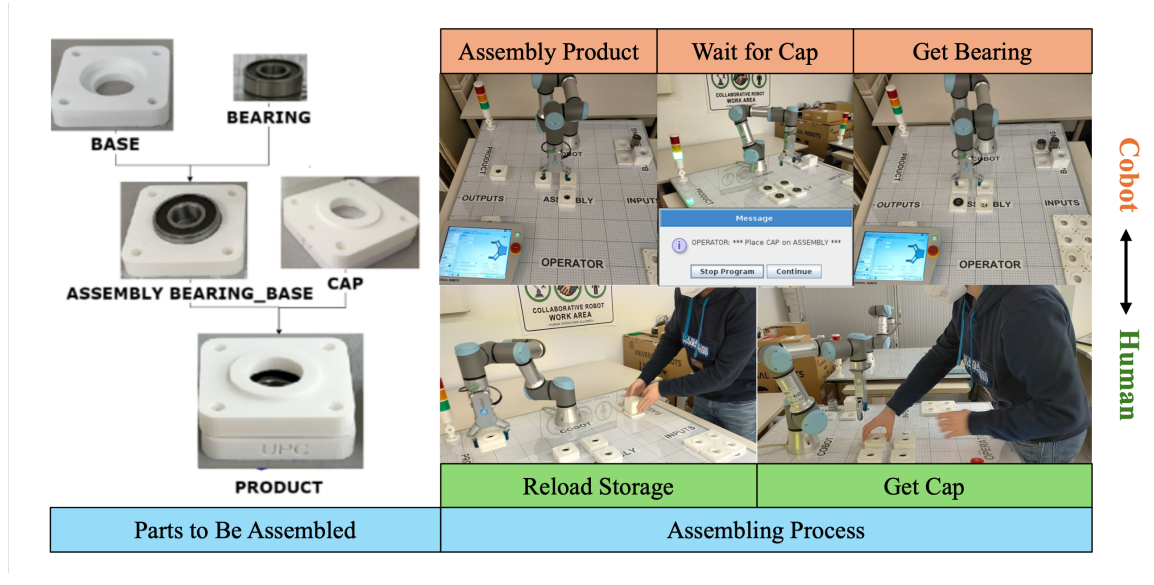
图11:认知交互分析实现装配任务中的人机有效协作180
3.4.1 认知协作:理解与对齐人类认知
在人机交互中,认知协作指机器人与人类之间的双向认知对齐,实现自然直观的交流与合作。这种协作不仅强调机器人对人类行为的被动响应,还强调深度认知理解和动态适应,形成类似人类高效协作的模式。其核心目标是使机器人不仅能理解人类的明确指令(如语音指令和手语指令181),还能理解隐含意图(如情绪和上下文),动态调整行为以匹配人类的认知模式和期望13。该能力的实现对提升机器人在复杂场景中的适应性及自然交互体验至关重要。
研究表明,实现认知协作依赖于复杂的认知架构和多模态信息处理能力。例如,Lemaignan等人182探讨了社会人机交互中机器人认知所需的关键技能,包括几何推理、情境评估和多模态对话。机器人需要通过这些技能理解人类意图并与人类协作完成共同任务180。
此外,多模态意图学习已被确定为实现认知协作的关键因素183。例如,整合面部表情和肢体动作以解读口头指令的情感基调和潜在意图,可显著减少误解并提升人机交互的自然性184。
进一步地,认知协作要求机器人具备对环境和交互情境的深入语义理解。Laplaza等人185的研究展示了如何通过人类动作的上下文语义分析来推断交互意图。他们提出了一种基于动态语义分析的模型,可实时解析人类动作的潜在目标并结合环境信息进行预测,从而让机器人更准确地协作完成任务。
在无需直接人类参与的交互任务中,认知协作同样扮演着重要角色。例如,在家用服务机器人场景中,机器人可通过环境语义理解完成目标导向的导航任务。该任务要求机器人在未知环境中定位特定目标物体(如杯子、沙发或电视)或指定区域(如卧室和浴室)。L3mvn 186、Sg-Nav 187、Trihelper 188、CogNav 189 和 UniGoal 190 等工作通过利用LLMs模拟多种人类认知状态(如广泛搜索和上下文搜索),提升了机器人在目标导向导航任务中的性能。
总之,人机交互中认知协作的进步需要跨学科合作,包括认知科学、语义理解,以及涉及语言、视觉和音频感知的多模态大模型的开发。随着认知协作能力的不断提升,机器人将更加熟练地支持实际应用场景中的各类任务。
3.4.2 物理可靠性:物理动作的协调与安全
人机交互中的物理可靠性是指人类与机器人之间在力量、时序和距离上的有效协调,以确保安全、高效且人机兼容的任务执行。其核心目标是使机器人能够动态响应人类动作的实时变化,包括调整运动策略、避免物理冲突,并在交互中保障人身安全。为此,研究主要聚焦于两个方向:物理交互中的实时控制和基于仿真平台的大规模生成数据集构建。
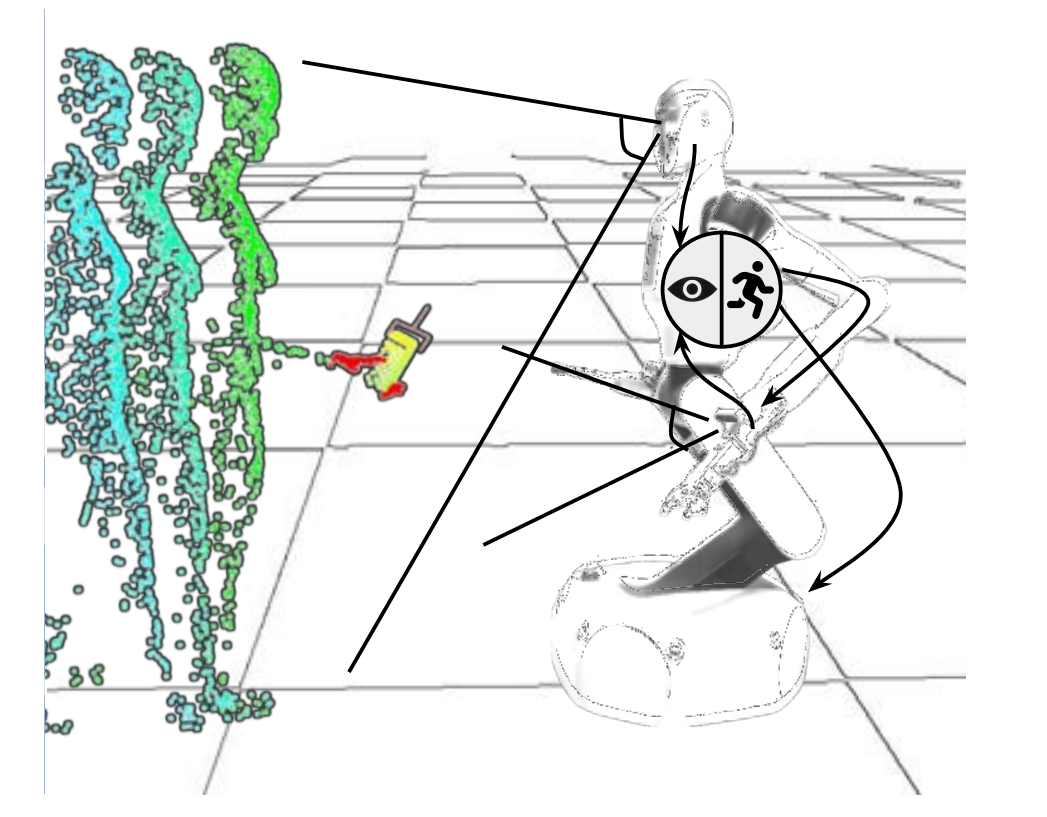
图12:物理可靠性通过感知和规划得到确保 191
人机交互中的物理可靠性保障依赖于先进的运动规划与控制策略,这些策略需同时处理人与机器人之间的协调与安全问题192。基于采样的规划器,如概率路线图(PRM)193、快速探索随机树(RRT)194及其扩展方法,已被广泛应用于共享工作空间中生成无碰撞且考虑人类因素的轨迹195-199。基于优化的规划器,包括CHOMP 200、STOMP 201、IT-OMP 202、TrajOpt 203, 204和GPMP 205,通过最小化动态场景中可行性和平滑性相关的成本,进一步提升了轨迹质量。这些方法非常适合应用于人机协作环境以确保物理可靠性206, 207。
在控制方面,阻抗控制和导纳控制能够对物理接触作出柔顺且安全的响应,而自适应控制器和混合控制器则进一步增强了对干扰和不确定性的鲁棒性 208--211。这些方法确保机器人可靠且可预测地运行,从而降低人类合作者受伤和不适的风险。
然而,随着机器人在多样且非结构化环境中的部署日益增多,实现安全稳健的物理协作仅靠传统控制策略已不足。感知、意图预测与实时适应的融合已成为机器人应对动态变化和复杂人类行为的关键 212, 213。基于这些进展,近期研究探索了模仿学习和强化学习方法,使机器人能够直接从数据和经验中习得自适应运动策略 214--216。然而,这些学习方法的有效性高度依赖于高质量交互数据的可用性。
因此,通过物理仿真生成的大规模生成式数据集已成为提升机器人动作可靠性和安全性的重要资源。例如,Handover-14 Sim 217 提供了一个用于人机物体传递的仿真与基准测试平台,利用物理引擎和轨迹优化来确保无碰撞及标准化的安全评估。在此基础上,GenH2R 218 引入了包含大量3D模型和灵巧抓取生成的仿真环境,通过模仿学习训练通用的传递策略。此外,MobileH2R 191 整合了由CHOMP 200 生成的专家演示,以应对动态场景中移动机器人安全高效物体传递的挑战。
尽管当前研究已取得显著进展,但确保HRI中的物理可靠性仍面临高计算成本和复杂场景下鲁棒性有限等挑战。未来需要进一步探索以开发更高效的算法并提升适应性,从而在多样且动态的环境中实现可靠的HRI。
3.4.3 社会嵌入性:与社会规则和文化规范的整合
人机交互中的社会嵌入性指机器人能够识别并适应社会规范、文化期望和群体动态,从而无缝融入人类环境的能力。这不仅限于任务完成,还包括协商、礼仪和情感表达等行为。如图13所示,机器人正与人类伙伴进行协商。为促进机器人无缝融入社交场景,近期研究探索了多种策略,这些策略同时关注社会空间理解和行为理解。这两个互补方面是实现人机交互中有效社会嵌入性的关键。
一方面,社交空间理解使机器人能够理解和适应人类群体的空间动态。通过在社交场景中应用空间理解,机器人能够借助近体空间219、220等概念更好地解读协作或防御行为。典型应用是使机器人在社交环境中更有效地导航和互动,从而为视障人士提供更合适、自然的协助221--223。
另一方面,行为理解侧重于从语言和非语言角度解码人类交流的复杂性。语言学研究探讨对话建模、会话结构和话语分析等方面224--228,而非语言研究则侧重于手势、眼神和情感表达的解读229、230。为捕捉这些多样的社交信号,已提出多种方法用于建模和识别非语言行为,涵盖从个体手势分析到多方现实世界互动的范围231--236。
尽管取得了这些进展,稳健的社会嵌入性仍面临挑战。机器人必须在任务效率与社会适宜性之间准确平衡,这需要提升多模态感知、长期适应能力以及将社会知识融入决策的能力。未来研究还应关注终身学习、跨文化适应以及社会嵌入式机器人的伦理问题,为IR-L4自主性铺平道路。
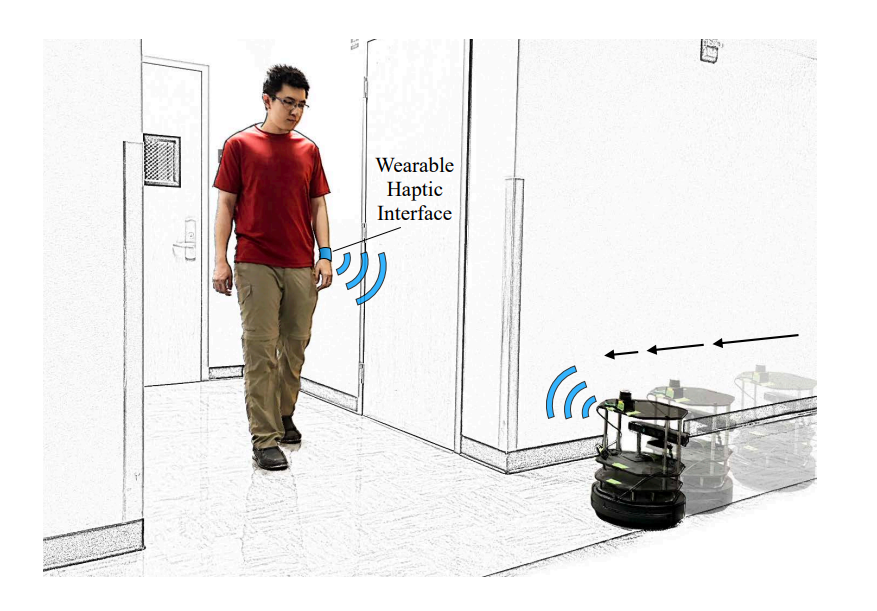
图13:机器人通过可穿戴触觉界面向人类传达其意图的社交导航场景237
4 通用物理模拟器
随着传统机器人向具身智能演进,其应用需求正逐渐从结构化工业环境转向开放动态的人类生活环境。然而,智能机器人算法研究仍面临显著的数据瓶颈,严重限制了相关算法的泛化能力和适用性。
具体来说,当前智能机器人的数据收集仍面临以下挑战:1)成本与安全问题:基于遥操作55153或通用操作接口(UMI)238的数据收集策略对硬件要求较高,且需要操作员具备一定熟练度,导致成本上升。此外,物理实验还存在危险场景或机器人动作带来的安全隐患。2)控制与可重复性问题:数据收集过程受光照、背景和传感器噪声等因素影响,导致数据质量不稳定。为控制这些因素,必须精心设计收集场景。然而,由于场景无法完全受控,难以在相同条件下重复实验以评估相关算法的适用性。
为解决上述瓶颈,Sim2Real迁移技术已成为克服数据限制的关键方法。该范式构建高保真虚拟环境以生成多模态合成数据,具有以下主要优势:
**1)数据生成效率显著提升:**利用GPU加速的物理引擎和分布式渲染,模拟器能够快速生成大量仿真数据,使数据采集过程既经济又安全;
**2)自动化标注与可控语义标注:**模拟器可直接输出像素级真实数据,包括语义分割图、深度图和6D物体位姿,从而实现对模拟环境的精准控制。
此外,模拟器还为调试、验证和优化机器人感知、控制及规划算法提供了高效、安全且可复现的测试环境,显著提升了这些算法在实际部署中的鲁棒性与可靠性。
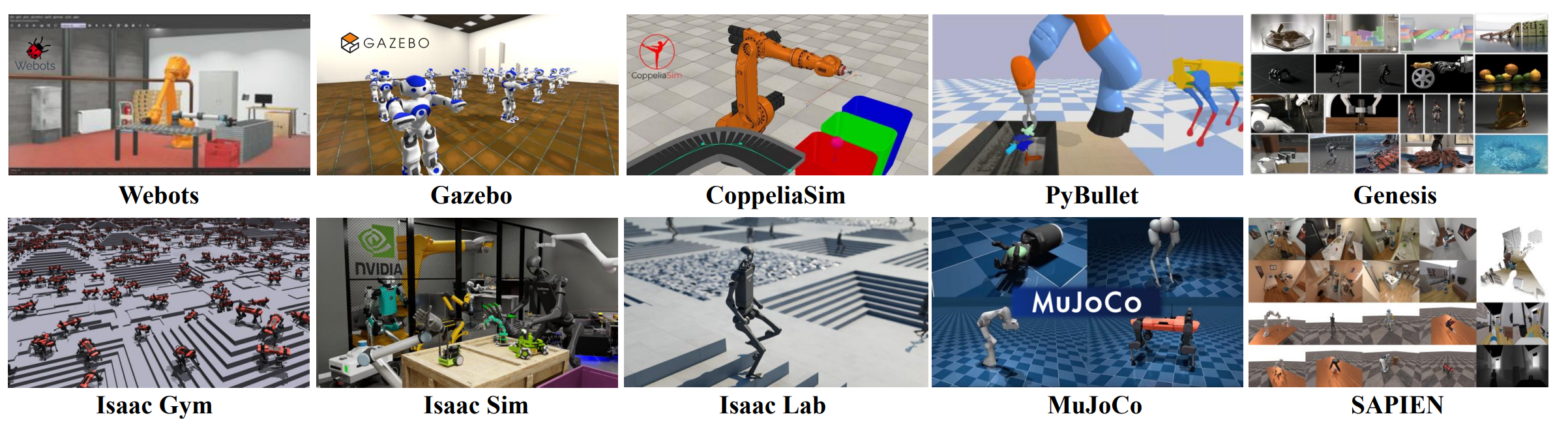
图14:机器人研究主流仿真器
本章聚焦于当代机器人研究中的主流仿真器。首先介绍广泛采用的仿真平台,随后阐述其多样化的功能,涵盖物理仿真特性、渲染能力以及对传感器和关节组件的支持能力。最后总结机器人仿真器的当前发展,并探讨未来研究方向。
4.1 主流仿真器
Webots 239由Cyberbotics Ltd.于1998年推出,提供了一个集成的机器人建模、编程和仿真框架,在教育、工业和学术界被广泛采用。2018年开源后,显著提升了其在全球研究和教育中的可访问性。Webots提供丰富的预构建机器人模型,支持多种传感器模态,跨平台,并提供多语言API,是一款多功能且用户友好的工具。然而,它不支持可变形体和流体动力学,在高级物理和大规模学习任务方面存在局限性。
Gazebo 15 由安德鲁·霍华德和内特·科尼格于2002年在南加州大学开发,是一款广泛采用的开源仿真器,以其可扩展性和与机器人中间件的集成而著称。除了支持多种传感器和机器人模型外,Gazebo还具备模块化插件系统,允许用户自定义仿真组件,包括模型、控制器和传感器。Gazebo还支持接入多种物理引擎和渲染引擎。然而,在高级物理交互方面,Gazebo与Webots存在类似限制,不支持基于吸力的抓取、可变形物体和流体动力学。Webots和Gazebo均与ROS紧密集成,可在ROS生态系统中无缝测试和验证机器人算法。不过,它们原生不支持并行执行或强化学习工作流。
MuJoCo(多关节动力学与接触)16 是由华盛顿大学Emo Todorov教授团队于2012年开发的物理引擎,后于2021年被谷歌DeepMind收购。该引擎专为模拟关节系统中的复杂接触动力学而设计,提供高精度物理计算、优化的广义坐标公式以及原生生物力学建模支持。
MuJoCo将接触约束建模为凸优化问题,从而能够精确模拟复杂交互,包括软接触、摩擦行为和肌腱驱动运动。同时,它缓解了传统引擎的常见限制,如穿透和不稳定性,即使在较大的仿真时间步长下仍能保持数值精度和计算效率。该引擎支持轻量级XML建模格式(MJCF/URDF),并提供Python、C++等多语言API,便于快速构建和迭代模型。这些特性使其在机器人学和强化学习研究中被广泛采用。总体而言,MuJoCo在接触动力学和强化学习应用中表现优异,且支持ROS集成,但由于其OpenGL后端,渲染能力有限,同时缺乏对流体、离散元(DEM)和LiDAR仿真的支持。
随着机器人技术和人工智能的快速发展,对高效仿真工具的需求不断增加。作为Bullet物理引擎的原始开发者,Erwin Coumans于2017年推出了PyBullet 240。PyBullet将Bullet的强大功能封装为Python接口,旨在为研究人员和开发者提供轻量级且易于集成的仿真平台。尽管PyBullet在仿真保真度和功能丰富性方面略逊于一些主流仿真工具,但凭借其开源特性、轻量级设计、用户友好的Python接口以及易用性,已在学术界获得广泛应用。随着时间的推移,它已培育出一个庞大且活跃的用户社区。
CoppeliaSim 241,曾名为V-REP(虚拟机器人实验平台),于2010年左右由东芝公司发布,是一款面向开发者、研究人员和教育工作者的通用机器人仿真软件。自2019年起,由瑞士公司Coppelia Robotics进一步开发和维护。CoppeliaSim的核心优势在于其分布式控制架构,允许Python、Lua脚本或C/C++插件作为独立的同步控制器运行。此外,异步控制器可通过16种中间件解决方案(例如ROS、远程API)执行,并支持与C/C++、Python、Java和MATLAB在不同进程、线程或机器间的集成。CoppeliaSim的教育版是开源且免费的,因此在学术和教育领域被广泛应用。
随着机器人技术、强化学习与照片级真实感仿真的日益融合,可扩展的GPU加速仿真平台需求激增。NVIDIA Isaac系列通过构建面向机器人开发和具身AI研究的闭环技术生态系统来满足这一需求。其演进反映了从孤立的加速工具向全面全栈仿真基础设施的转变。Isaac Gym 242于2021年推出,开创了大规模GPU加速物理仿真的先河,支持数千个环境的并行训练。基于NVIDIA PhysX引擎,它显著提升了步态控制和足式机器人策略学习等任务的样本效率。然而,由于缺乏光线追踪支持,Isaac Gym的渲染保真度受限,且不支持流体或LiDAR仿真。
NVIDIA随后推出Isaac Sim 243,集成了Omniverse平台244,这是一个基于Omniverse构建的全功能数字孪生模拟器。它集成了PhysX 5物理引擎和基于RTX的实时光线追踪,可实现毫米级精度的高保真LiDAR模拟。通过采用USD(通用场景描述)245标准,Isaac Sim支持多模态传感器的物理精确模拟,包括RGB-D相机和IMU。2025年发布的Isaac Sim 5.0进一步改进了刚体动量守恒,新增关节可视化工具,并引入仿真数据分析模块,使机械臂抓取精度达到0.1毫米以内。
Isaac Lab 246 是一个基于Isaac Sim构建的模块化RL框架,旨在简化和优化机器人学习流程。它采用平铺渲染技术高效处理多摄像头输入,将训练吞吐量提升约1.2倍。Isaac Lab 支持IL和RL两种范式,能够从HDF5格式的演示数据集中快速构建策略。Isaac Gym的并行计算能力现已深度集成到Isaac Sim的底层架构中。基于Isaac Sim,Isaac Lab采用模块化设计,将仿真环境抽象为可配置的任务单元。该软件栈正逐步支持异构物理引擎(包括刚体和软体动力学)、Sim-to-Real Transfer以及生成式AI驱动的场景合成(例如Cosmos世界模型),从而为具身智能研究提供统一的基础设施------从底层物理到高层行为学习。然而,它继承了Isaac Sim的高硬件需求,可能限制资源受限用户的使用。Isaac Sim和Isaac Lab均已发布早期开发者预览版,并预计逐步开源。
SAPIEN(Simulated Part-based Interactive Environment,由加州大学圣地亚哥分校及合作机构的研究人员于2020年提出247)是一个仿真平台,专为复杂部件级交互对象的物理真实建模而设计,超越传统刚体动力学。为支持关节式物体操作的研究,作者发布了PartNet-Mobility247数据集,该数据集包含运动标注的关节式3D物体。基于SAPIEN引擎,研究团队随后推出了ManiSkill248和ManiSkill3249基准测试,提供多样化的操作任务、高质量演示以及高效并行化的数据采集流程。该生态系统已成为评估基于真实物理环境的操作策略和具身智能算法的广泛使用的基准套件。SAPIEN提供交互式可视化,支持RGB和IMU传感器,并与ManiSkill基准紧密集成。然而,它不支持软体和流体动力学、光线追踪、LiDAR、GPS及ROS集成,这限制了其在更广泛机器人仿真场景中的应用。
Genesis 250于2024年发布,是一个由全球研究者联盟开发的通用物理仿真平台。其核心目标是在高保真框架中整合多种物理求解器,包括刚体动力学、材料点法(MPM)、光滑粒子流体动力学(SPH)、有限元法(FEM)、基于位置的动力学(PBD)和稳定流体求解器,以最大限度地还原复杂物理现象。Genesis的关键创新在于其生成式数据引擎,该引擎允许用户通过自然语言提示指定仿真场景并生成多模态数据集。该平台以可微分性作为基础设计原则,适用于具身智能、物理推理和可微分仿真等领域。根据公开基准测试,在批量大小为512至32,768个环境时,Genesis的吞吐量比Isaac Gym高2.70至11.79倍。目前,该平台正在进行分阶段开源发布。尽管具备诸多优势,Genesis尚不支持LiDAR或GPS仿真,也未提供ROS集成。
此外,NVIDIA Newton 251 是由NVIDIA、Google DeepMind和Disney Research于2025年联合开发的开源物理引擎。面向高保真仿真和机器人学习,Newton提供了一个从基础物理建模到复杂多物理场交互的全栈框架。基于NVIDIA Warp框架,它通过GPU加速实现了超过70倍的仿真速度提升,并支持刚体/软体动力学、接触与摩擦建模以及自定义求解器集成。Newton设计为与MuJoCo Playground和Isaac Lab等现有机器人学习平台深度兼容,从而无缝复用现有机器人模型和训练流程。凭借可微分物理引擎,Newton能够通过仿真进行梯度反向传播,为基于学习的控制优化提供了坚实的数学基础。此外,其基于OpenUSD的场景构建能力可在细粒度层面将物理规律与虚拟环境对齐。尽管仍处于早期开发阶段,Newton生态系统正在快速发展,旨在填补工业 17 操控和人形机器人运动规划等领域的仿真到现实差距。
4.2 模拟器的物理属性
智能机器人需要在复杂动态环境中执行抓取、行走和协作等类人行为。在此背景下,模拟器的物理建模能力直接决定了生成数据的真实性和策略迁移的有效性。高保真物理属性仿真不仅能增强环境交互的真实性(例如软体变形、流体动力学引起的质心偏移),还能通过引入随机扰动以防止策略在模拟环境中过拟合,从而提升算法的泛化能力。这反过来拓宽了人形机器人算法在更广泛场景中的适用性。本节对上述讨论的模拟器进行对比分析,重点考察其在各类物理属性仿真方面的能力。根据文献21的分类,本小节选取了对人形机器人和世界模型尤为重要的物理属性,并比较不同模拟器对它们的支持情况。表2总结了不同模拟器对各类物理仿真的支持情况。
4.2.1 吸附
在机器人仿真中,吸附建模主要指接触界面处的非刚性附着行为,例如模拟真空吸附以实现物体抓取。该技术广泛应用于工业自动化和仓库拣选领域。
目前,主流机器人仿真平台在吸附效果的实现方式上存在差异。MuJoCo依赖用户自定义逻辑通过检测接触并施加外力或创建虚拟连接来模拟吸附,但精度和控制性有限。Gazebo通过插件动态创建基于接触的关节来实现吸附,可实现更灵活的机械行为控制。相比之下,Webots、CoppeliaSim和Isaac Sim提供原生吸附支持,使用更为便捷。
4.2.2 随机外力
随机外力旨在模拟环境中的不确定性,例如物体碰撞、风力等。将随机外力应用于类人机器人能够更好地提升其平衡能力和抗干扰能力,从而防止训练策略在稳定环境中的过拟合。
主流机器人仿真平台均支持随机外力的仿真,但其实现方式各异。MuJoCo、PyBullet、SAPIEN、CoppeliaSim和Isaac Gym主要通过脚本或API的用户自定义方法施加此类扰动。值得注意的是,Isaac Gym提供并行控制接口,可在大规模场景中高效添加随机扰动。相比之下,Webots、Gazebo、Isaac Sim和Isaac Lab提供完善的接口,可通过随机速度直接施加随机力或扰动。
4.2.3 可变形物体
可变形物体是指在外力作用下发生形变的材料,广泛用于模拟布料、绳索和软体机器人等柔性材料的物理行为。主流机器人仿真平台对可变形物体的仿真支持从基础到高保真不等。MuJoCo 和 PyBullet 等平台提供基础的软体模拟功能,适用于布料或弹性材料等简单可变形实体。相比之下,Isaac Gym、Isaac Sim 和 Isaac Lab 提供更先进的解决方案。它们利用 GPU 加速或基于 PhysX 252 的有限元方法,实现更精细的控制和更高的真实感。Genesis 通过集成最先进的物理求解器进一步扩展了这些功能,能够对复杂可变形材料进行详细且高精度的仿真。
4.2.4 软体接触
与可变形物体不同,软体接触是指软质材料(如布料、橡胶等)之间相互作用的模拟。这些模拟涉及复杂的形变响应和力传递过程,广泛应用于可变形材料的操作、碰撞和接触力学研究中。
当前主流仿真器在软体接触模拟方面主要支持两种级别:基础支持和高精度建模。Webots、Gazebo、MuJoCo、CoppeliaSim 和 PyBullet 通过软接触参数、简化接触模型或关节体结构提供基础仿真能力,适用于通用场景。相比之下,Isaac Gym、Isaac Sim、Isaac Lab 和 Genesis 利用 GPU 加速或有限元建模(FEM)等方法提供更高级、更精确的模拟,更适合复杂物理交互场景。
4.2.5 流体机制
流体机制仿真是指对液体和气体等流体的运动和相互作用进行计算建模。这类仿真广泛应用于工程和机器人领域,使研究人员和工程师能够预测和分析不同条件下的流体行为,优化系统设计,提高效率并降低成本。
主流仿真器在流体机制支持方面存在显著差异。Webots 和 Gazebo 提供基础的流体仿真能力,适用于模拟浮力和阻力等简单交互,但精度有限。Isaac Sim 基于 Omniverse 和 PhysX 构建,通过基于粒子的方法支持更复杂的流体行为。Genesis 集成高级物理求解器,提供原生高保真流体仿真支持,是目前最全面且精确的平台之一。其他主流仿真器目前缺乏对流体机制的原生支持,但存在有限的社区驱动扩展,例如在 Isaac Lab 中。
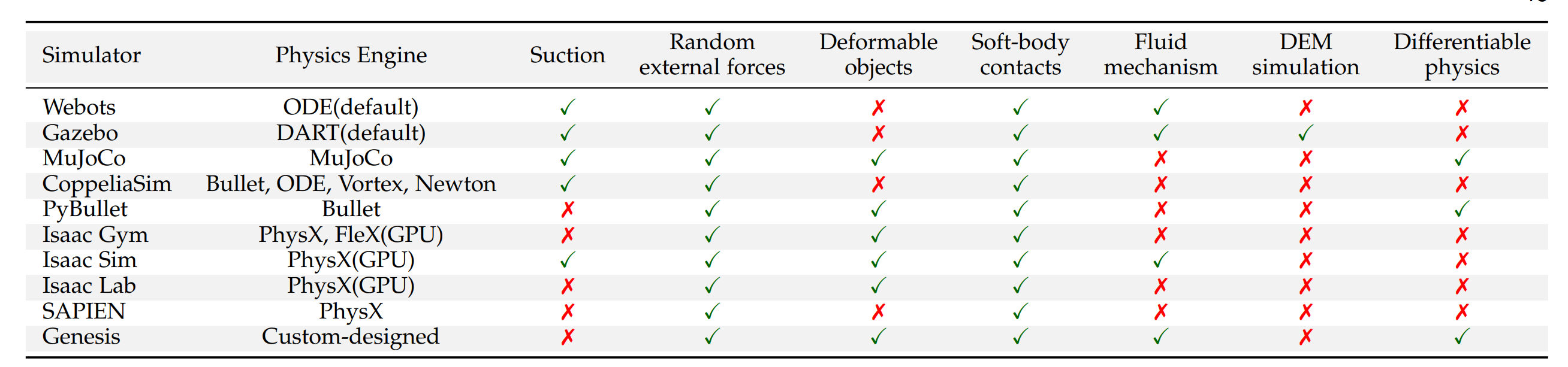
表2:不同模拟器物理仿真对比(✓:支持,✗:不支持)
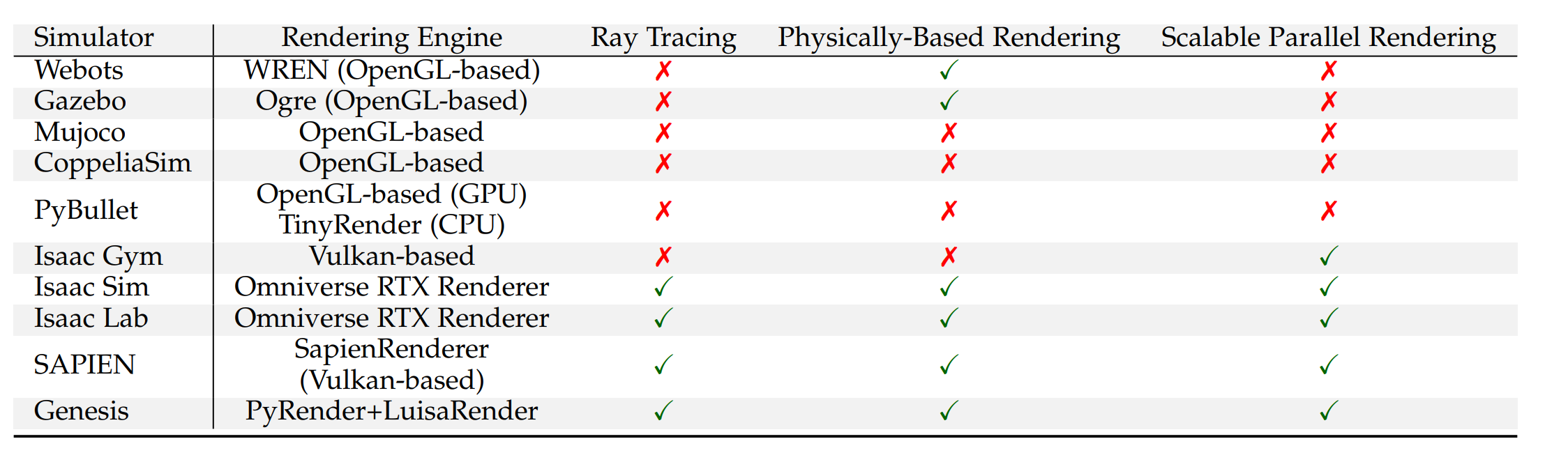
表3:各模拟器渲染特性对比(✓:支持,✗:不支持)
4.2.6 离散元法(DEM)仿真
离散元法(DEM)是一种数值仿真技术,将物体建模为刚性粒子的集合体,模拟粒子间的接触、碰撞和摩擦等相互作用。该方法广泛用于模拟颗粒材料和粉末的物理行为。DEM能够准确表征粒子系统的微观力学特性,但计算成本较高,通常通过并行计算或GPU加速来缓解。在机器人仿真中,DEM可用于模拟机器人与颗粒材料之间的相互作用,例如抓取和操作。
然而,当前主流的仿真器并不原生支持DEM。虽然MuJoCo和Isaac系列等平台能够模拟颗粒材料,但其接触模型并未针对颗粒间的微观相互作用进行专门优化。值得注意的是,Gazebo通过插件支持功能扩展,NASA的OceanWATERS项目253将DEM仿真与Gazebo集成,以实现对颗粒材料行为的间接仿真。该方法主要用于挖掘等任务中的力反馈,而非实时的颗粒级仿真。
4.2.7 可微分物理
在仿真领域中,可微分物理指模拟器计算物理状态关于输入参数(如控制信号、物体位姿和物理属性)梯度的能力。该能力使端到端优化与学习成为可能,并支持与机器学习模型(特别是强化学习和优化算法)的无缝集成,从而实现高效的自学习和任务性能提升。
近年来,多个模拟平台在可微分物理领域取得快速进展。MuJoCo的XLA分支(MuJoCo XLA)通过JAX实现可微分仿真,支持梯度计算和优化任务。PyBullet通过其子项目Tiny Differentiable Simulator提供可微分接口,适用于基于梯度的学习和优化。Genesis从底层设计中融入可微分性,已在MPM求解器中实现可微分物理,并计划扩展至刚体和关节系统求解器。总体而言,这些平台正日益将高保真物理建模与自动微分相结合,加速可微分仿真在具身智能和机器人学习中的部署。
4.3 渲染能力
仿真渲染能力在现代机器人研究与开发中至关重要。它们不仅为研究人员提供了高效的虚拟实验环境,还确保了机器人外观和行为的预测更加真实准确。高保真渲染在缩小sim-to-real gap方面发挥着关键作用。这对于机器人开发的各个阶段,包括设计、验证和优化至关重要,并显著提升了感知、控制及同步定位与地图构建(SLAM)算法在实际部署过程中的鲁棒性和可靠性。
本小节对上述模拟器的渲染能力进行比较分析,重点考察以下四个关键技术方面:底层渲染引擎、光线追踪支持、PBR实现以及并行渲染能力。结果如表3所示。
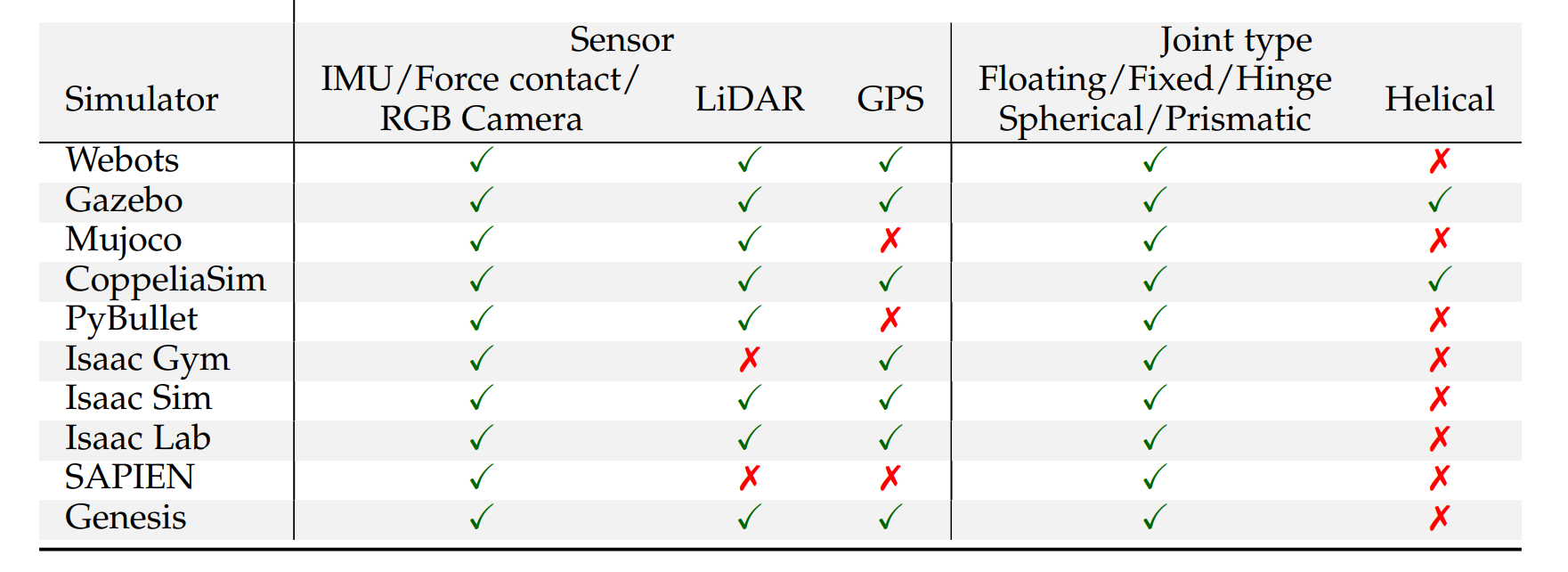
表4:各类仿真器中传感器与关节组件的支持情况。✓:支持,✗:不支持。
4.3.1 渲染引擎
渲染引擎是用于从3D场景描述生成2D图像的核心软件。其任务包括处理几何数据、应用纹理、计算来自各种光源的光照,以及执行着色模型以确定表面的最终外观。
OpenGL 254 是一个历史悠久的跨平台图形API,被广泛采用。Webots采用其专有的Webots渲染引擎(WREN),该引擎基于OpenGL 3.3构建,针对GPU硬件专门优化,并适配Webots仿真平台,集成了抗锯齿、分辨率增强、环境光遮蔽和完整的PBR管线等功能。MuJoCo内置了基于固定功能OpenGL的集成渲染器,通过预加载GPU资源提升效率,但仅支持基础视觉效果。CoppeliaSim使用内置的基于OpenGL的渲染引擎进行实时光栅化。PyBullet通过GPU上的OpenGL提供基础渲染,并包含TinyRender------一个基于CPU的软件渲染器,用于无头或非GPU场景。
随着OpenGL的能力逐渐无法满足实际需求,后续渲染引擎采用了更通用的图形API,以更好地利用GPU资源并实现更高的渲染性能。Isaac Gym使用Vulkan 255进行轻量级GUI可视化。该Vulkan驱动的查看器并不追求高保真渲染,而是为调试和仿真工作流程提供高效、实时的视觉反馈。随后的NVIDIA Isaac套件采用了更先进的方法。Isaac Sim和Isaac Lab深度集成到NVIDIA Omniverse生态系统中,采用Omniverse RTX渲染器与Hydra渲染代理 256,并利用NVIDIA的RTX技术实现高保真图形。SAPIEN采用基于Vulkan图形API构建的自定义高性能渲染引擎,名为SapienRenderer。Genesis采用原生渲染管线,集成了PyRender 257和LuisaRender 258等前沿框架。
4.3.2 光线追踪
光线追踪是一种渲染技术,通过追踪光线在3D场景中与表面相互作用的路径来模拟光的物理行为。在机器人领域,该技术相比传统光栅化的主要优势在于能够生成高度精确的阴影、反射、折射、全局光照,以及关键的是,更真实地模拟LiDAR和深度相机等传感器的物理特性。而光栅化通常难以处理非线性光学传感器和复杂的光交互。
在评估过的仿真器中,Webots、MuJoCo 和 PyBullet 不支持原生实时光线追踪,其主要视觉输出依赖光栅化技术。CoppeliaSim 集成了 POV-Ray,可生成高质量静态图像,但不支持动态模拟的实时光线追踪。Isaac Gym 的渲染功能较为基础,既不支持光线追踪,也不支持 Omniverse 中更高级的合成数据传感器。相比之下,专为高保真视觉输出设计的仿真器越来越多地集成光线追踪技术。Isaac Sim 和 Isaac Lab 通过 Omniverse RTX 渲染器提供强大的实时光线追踪,支持全局光照、反射和折射等效果。
SAPIEN 同样提供显著的光线追踪支持;其 SapienRenderer(基于 Vulkan)支持光栅化和光线追踪两种渲染管线,可通过着色器包切换。Gazebo 虽然主要基于光栅化,但其 gz-rendering 库通过实验性的 NVIDIA OptiX 259 支持正朝着光线追踪方向发展。Genesis 旨在实现照片级真实感,采用最先进的高性能渲染器 "LuisaRender"。
4.3.3 基于物理的渲染(PBR)
PBR是一种根据材料的物理属性(如粗糙度和金属度)模拟光线与材质交互的方法,能够在不同光照条件下呈现更真实、一致的视觉效果,提升材质定义的准确性和视觉保真度,这对基于视觉的机器人学习方法的训练至关重要。
Webots的WREN引擎实现了PBR管线,集成了先进的光照模型和非颜色纹理,实现与现代游戏引擎相媲美的真实感。新版Gazebo通过Ignition Rendering支持PBR,其Ogre后端具备PBR能力。相比之下,MuJoCo专注于基础视觉效果,CoppeliaSim和PyBullet则专注于基本渲染,均不支持PBR。Isaac Gym使用基于Vulkan的基础管线,同样不支持PBR。
高保真模拟器采用PBR。基于NVIDIA Omniverse构建的Isaac Sim和Isaac Lab通过Omniverse RTX渲染器原生支持PBR,并利用材质定义语言(MDL)定义真实、基于物理的材质。SAPIEN和Genesis同样支持PBR。它们的高级渲染能力,包括光线追踪和精确的材质属性表示,是PBR系统的关键组成部分。
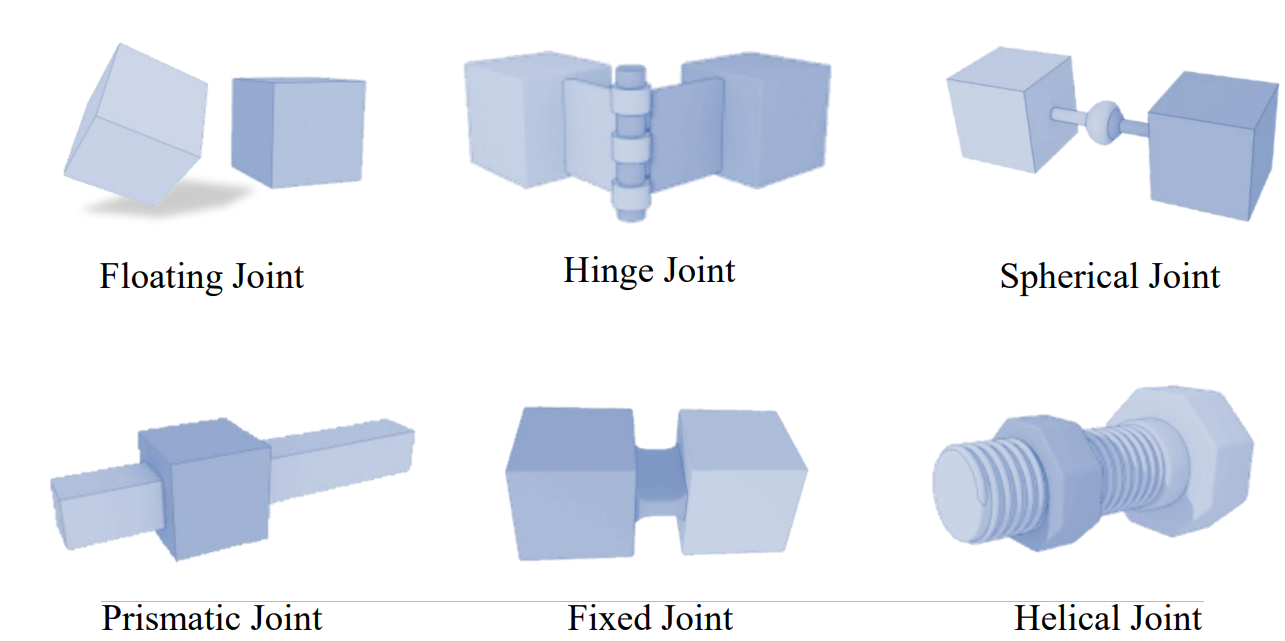
图15:模拟器中的主要接头类型260
4.3.4 并行渲染
机器人仿真中的并行渲染能够同时渲染多个独立的仿真环境,用于大规模RL或数据收集。其优势在于显著加速RL智能体训练,并能高效生成大规模合成数据集。
像 Isaac Gym、Isaac Sim/Lab、SAPIEN(尤其是 ManiSkill)和 Genesis 这样的模拟器,其核心架构均具备强大的并行渲染能力。Isaac Gym 能够在单GPU上并行模拟和渲染数千个环境,包括相机传感器。Isaac Sim 和 Isaac Lab 将此扩展到多GPU训练,每个进程可在专用GPU上运行独立的 Isaac Sim 实例,而 Isaac Sim 本身也支持多GPU渲染以处理复杂场景或多摄像头。SAPIEN(尤其是 ManiSkill3)提供GPU并行化的视觉数据采集系统,可实现极高的 FPS(例如在高端GPU上渲染时可达30,000+ FPS),并支持异构模拟,每个并行环境可以不同。
像 Webots、Gazebo、MuJoCo、CoppeliaSim 和 PyBullet 这类较旧或通用型仿真器可能支持运行多个实例或具备某种形式的物理并行化,但通常缺乏专业平台所具备的集成式高吞吐量并行视觉渲染管线。Webots 支持通过 Docker 等方式运行多个实例,并可禁用渲染以提升速度,但并行视觉输出并非其主要优势。Gazebo 的物理引擎支持并行化,但不适用于 RL 的大规模并行视觉输出。MuJoCo 能以每个实例的基础或离屏渲染方式运行并行仿真线程。CoppeliaSim 支持多场景,但仅渲染当前激活场景,不适合并行数据收集。PyBullet 支持多个物理服务器,并通过 CPU 渲染器实现无头图像捕获,Bullet 物理引擎中具备一定的多线程能力,但缺乏高吞吐量的 GPU 并行视觉渲染能力。
4.4 传感器与关节组件类型
传感器是机器人感知中的关键组件,通过捕获视觉、力和惯性等多模态信息,为运动控制和环境理解提供基础。在仿真平台中,真实可靠的传感器模型为机器人感知算法的调试、验证和数据采集提供了高效、安全且可重复的测试基础。我们调研了主流仿真平台对各类传感器的支持情况,具体包括惯性测量单元(IMU)、接触力传感器、RGB相机、LiDAR和GPS。
如表4所示,主流仿真平台通常提供对常用传感器的标准支持,包括视觉(RGB)、IMU和接触力传感。例如,Isaac Sim和Isaac Lab提供全面的高保真传感器仿真。Isaac Gym支持IMU状态和接触信息输出,但其视觉能力在运行效率和并行处理方面相对有限。实际应用中,常与Isaac Sim或Omniverse配合使用,以实现高质量的视觉传感和处理。Genesis提供全面的多模态传感器支持,适用于复杂的感知任务。此外,其他传感器的支持情况因平台而异。具体而言,Isaac Gym和SAPIEN对LiDAR传感器不提供原生支持,而MuJoCo、PyBullet和SAPIEN不支持GPS。
除了传感器建模外,精确模拟各种关节类型(如浮动、铰链、球形、移动、固定和螺旋)对于在仿真平台中复现机器人的结构和运动特性至关重要。这些关节的组合决定了机器人的自由度(DOF)和灵活性,进而影响其在复杂任务中的表现。通过在仿真中精确建模这些关节,开发人员可以在虚拟环境中测试和优化机器人设计及控制策略,从而提升系统性能和可靠性。
如图15所示,这些平台中关节组件的仿真通常基于物理引擎提供的运动约束机制,通过定义两刚体之间的DOF来实现关节运动。浮动关节允许在所有方向上自由运动和旋转。固定关节完全约束两刚体的相对运动,铰链(旋转)关节允许绕特定轴旋转,移动关节允许沿特定轴的线性运动,球形关节提供三个旋转DOF。
模拟平台通常允许用户设置关节的范围限制、阻尼和弹簧刚度等参数,以模拟实际机械系统的物理特性。部分平台还支持更复杂的关节类型,例如螺旋关节(可实现旋转和平移的耦合运动)。螺旋关节允许两个连接的刚体沿同一轴同步旋转和线性移动,类似于螺钉在螺母中的旋进,具有单个DOF和螺旋运动轨迹。表4还总结了主流模拟平台对各种关节类型的支持情况。大多数模拟器支持浮动、固定、铰链、球形和移动等常见关节类型。然而,螺旋关节的支持较少,仅在Gazebo和CoppeliaSim中原生实现。
4.5 讨论与未来展望
模拟器是设计用于模拟现实世界过程或系统的计算模型,已成为科学与工程各学科中不可或缺的工具。其主要目的是提供受控环境,用于实验、分析和预测,无需昂贵或高风险的物理试验。尽管应用广泛,模拟器既具有显著优势,也存在明显局限性,这凸显了对更先进建模方法(如world models)的需求。
4.5.1 模拟器的优势
模拟器在研究和实际应用中具有多项关键优势:
**成本效益:**通过减少或消除对物理实验的需求,模拟器可以显著降低测试和开发相关的经济负担。
**安全性:**模拟器能够模拟高风险场景(e.g., 核反应堆故障或极端天气条件),而不会带来现实中的风险。
**控制:**模拟器提供对变量和实验条件的精确控制,使研究人员能够隔离特定因素并研究其影响。
**可重复性:**在模拟器中进行的实验可以精确重复,确保一致性并便于验证结果。
4.5.2 模拟器的挑战
然而,模拟器并非没有挑战,这些限制通常会制约其有效性:
**准确性:**模拟器可能无法完全捕捉现实系统的复杂性,导致预测不准确。模型设计中的简化或近似可能导致模拟结果与实际情况存在差异。
**复杂性:**现实系统通常极为复杂,包含众多相互作用的组件和变量。创建能准确反映这种复杂性的模拟器计算成本高昂,有时甚至不可行。
**数据依赖:**高效的模拟器通常需要大量高质量数据来校准和验证模型。在数据稀缺或难以获取的情况下,模拟器的性能会严重受损。
**过拟合:**模拟器可能对特定场景或数据集过度拟合,导致泛化能力下降,无法应对新情况或未知条件,从而限制其在动态或不断变化的环境中的适用性。
4.5.3 未来展望
精度、复杂性和数据依赖性的局限性凸显了对更先进、更灵活的建模框架的需求。这推动了世界模型的发展,旨在提供一种更全面、更灵活的方法来理解和预测现实世界的动态。与传统模拟器不同,世界模型利用机器学习和人工智能的进步,创建能够适应新数据、更高效地处理复杂系统并减少对大量数据集依赖的表征。因此,世界模型的研究代表了在追求更稳健、更通用的现实现象建模工具过程中的自然演进。
5 World Models
"World models 是生成式AI模型,能够理解真实世界的动态,包括物理和空间特性。"
------NVIDIA的World Foundation Models 17
受人脑形成世界内部表征能力的启发,World models已成为AI领域中的关键框架。这些模型使智能体能够预测未来状态并规划动作,模仿人类导航和与环境交互的认知过程。2018年,David Ha和Jurgen Schmidhuber提出了World models的概念 18,展示了AI能够学习环境的压缩生成模型,并用其模拟体验,从而在无需与真实世界直接交互的情况下促进强化学习。
随着该领域的发展,视频生成模型的进步显著提升了世界模型的能力。自2024年初以来,视频生成模型如Sora 263和Kling 264因其高保真视频合成和对物理世界的逼真建模,在学术界和工业界引起了广泛关注。Sora的技术报告《Video Generation Models as World Simulators》263强调了将视频生成模型作为模拟物理世界的强大引擎的潜力。导航世界模型(NWM)265采用条件扩散Transformer(CDiT),基于过去的经验和导航动作预测未来的视觉观测,使智能体能够通过模拟潜在路径并评估其结果来规划导航轨迹。
杨立昆也强调了基于视频的世界模型的重要性,指出人类通过视觉经验,尤其是双眼视觉,来发展对世界的内部模型。他认为,人工智能要达到人类水平的认知,必须以类似人类的方式学习,主要通过视觉感知。这一观点强调了将视频数据整合到世界模型中的重要性,以捕捉空间和时间信息的丰富性。他还提出了视频联合嵌入预测架构(V-JEPA)模型266,该模型通过预测视频的缺失部分来学习视频的抽象表示,为构建更强大的视觉世界模型提供了新思路。
基于这些见解,视频生成模型的最新进展旨在创建更复杂的世界模型,以表征和理解动态环境。通过利用大规模视频数据集和先进的神经网络架构,这些模型致力于复制人类感知和交互世界的方式,为更先进、更适应性强的人工智能系统铺平道路。
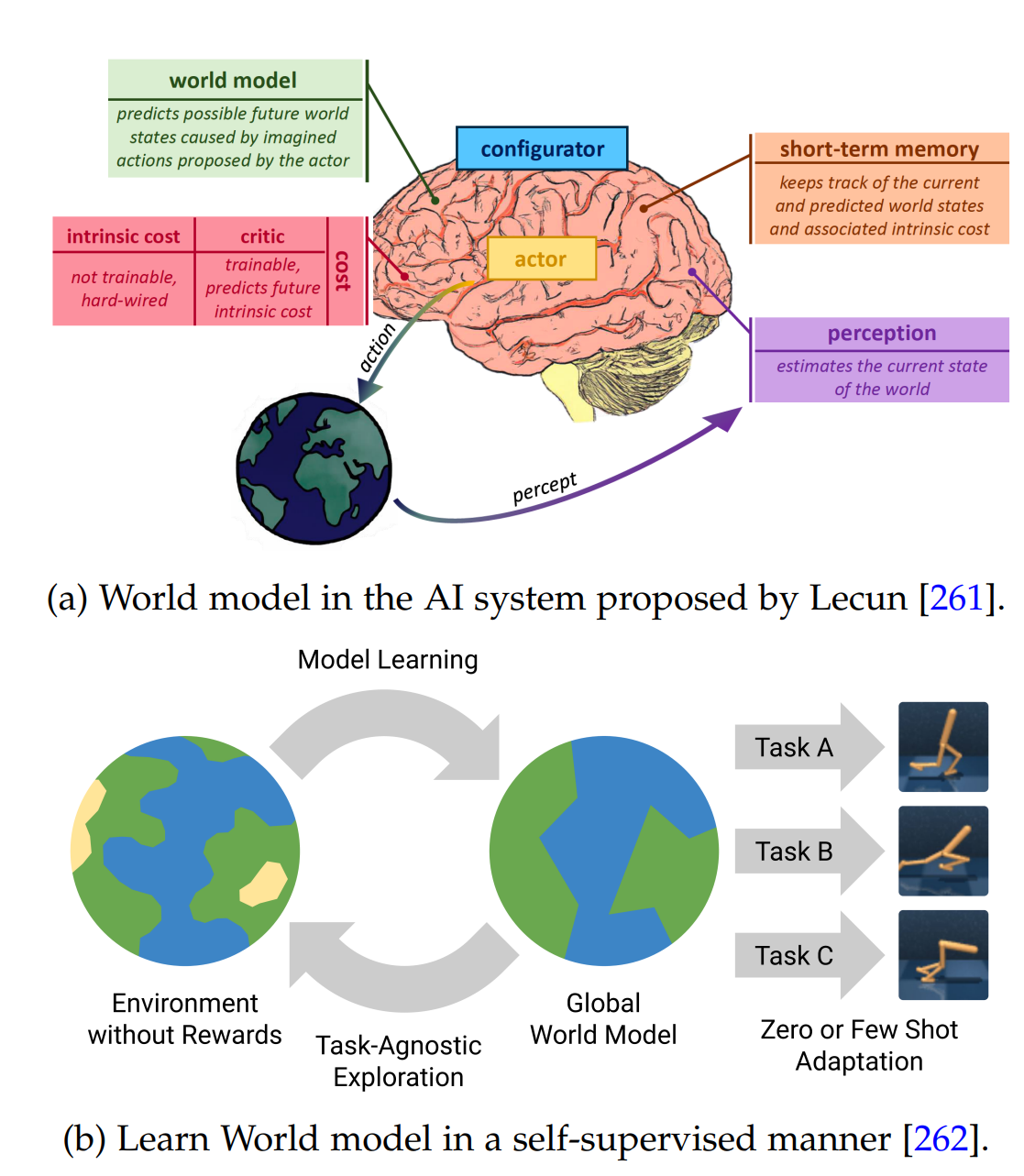
图16:世界模型在AI系统中的作用与训练示意图
本节首先回顾视频生成模型的架构演进,追溯其技术进步,为后续讨论其作为世界模型的角色奠定基础。随后重点阐述生成式模型作为世界模型在各领域应用的关键进展,包括其作为可控数据生成器的功能,以及在model-based RL中进行动态与奖励建模。
5.1 世界模型的代表性架构
为有效捕捉复杂环境的动态特性,世界模型已演变为多样化的架构范式,每种范式均体现了不同的世界表征与预测视角。从早期的紧凑潜动力学模型到近期强大的生成式架构,这些模型在状态编码、时序依赖处理及未来观测建模等方面存在差异。部分方法侧重于潜空间中的高效状态抽象与预测学习,而另一些则专注于视频或3D场景等未来感知输入的高保真生成。同时,序列建模、自监督学习及生成建模(尤其是Transformer和扩散模型)的进展深刻影响了现代世界模型的设计。本节将回顾广泛采用或近期提出的代表性架构类别,重点阐述其核心建模原理。架构演进概览如图17所示。
**循环状态空间模型。**循环状态空间模型(RSSMs)是最早且最广泛采用的用于学习世界模型的架构之一。其核心思想是使用紧凑的潜在空间来编码环境的演化状态,并通过循环结构建模其时序动态。该设计通过在潜在空间中模拟可能的未来,而非直接预测原始观测,从而实现长周期预测和决策。RSSM框架由Dreamer系列267--271推广,该系列证明了规划和强化学习可以在学习到的潜在动态中有效进行。对潜在状态转移的循环建模仍是连续环境中学习预测性和决策感知表征的核心机制。
联合嵌入预测架构(JEPAs)。与RSSM类似,联合嵌入预测架构(JEPAs)也在抽象潜在空间中对世界建模,但学习目标不同。JEPA模型不是重建视觉观测,而是通过纯粹的自监督方式预测缺失内容的抽象层级表示。JEPA由Yann Lecun在自主机器智能更广泛框架中首次提出272,通过将预测表述为表示匹配问题,消除了对显式生成解码器的需求。I-JEPA(图像JEPA)273和V-JEPA(视频JEPA)274275分别在静态和时域领域实现了这一思想。I-JEPA直接在潜在空间中预测掩码图像区域,而V-JEPA将其扩展到时空结构,从而无需帧级重建即可从视频中进行表示学习。该架构在大规模预训练中尤其适用,此时优先考虑语义抽象和数据效率而非精确的观测合成。
基于Transformer的状态空间模型。随着世界模型处理更复杂的环境和更长的时间跨度,循环架构在建模长程依赖方面的局限性愈发明显。基于Transformer的模型通过用基于注意力的序列建模替代RNNs,提供了更高的表达能力和并行性。在潜在动力学建模中,这一转变的典型代表包括TransDreamer 276、TWM 277和谷歌DeepMind的Genie 278,其中Transformer用于在扩展的时间窗口内对潜在状态空间中的状态转移进行建模。这些模型保留了RSSMs的潜在空间预测理念,同时受益于Transformer捕捉跨时间全局上下文的能力,从而提升了长期一致性与规划性能。
**自回归生成式世界模型。**受NLP最新突破的启发,自回归生成模型将世界建模视为对标记化视觉观测的序列预测任务。这些模型利用Transformer架构,基于过去上下文生成未来观测结果,通常整合动作或语言等多模态输入。早期视频生成框架如CogVideo 279、NUWA 280和VideoPoet 281通过展示可扩展的自回归真实视频合成技术奠定了基础。在此基础上,近期用于自动驾驶和3D场景生成的生成式世界模型,如GAIA-1 282、OccWorld 283,采用自回归Transformer来建模具有多模态输入和输出的复杂环境动态。然而,离散标记量化常导致高频细节丢失,对生成视频的视觉质量产生不利影响。
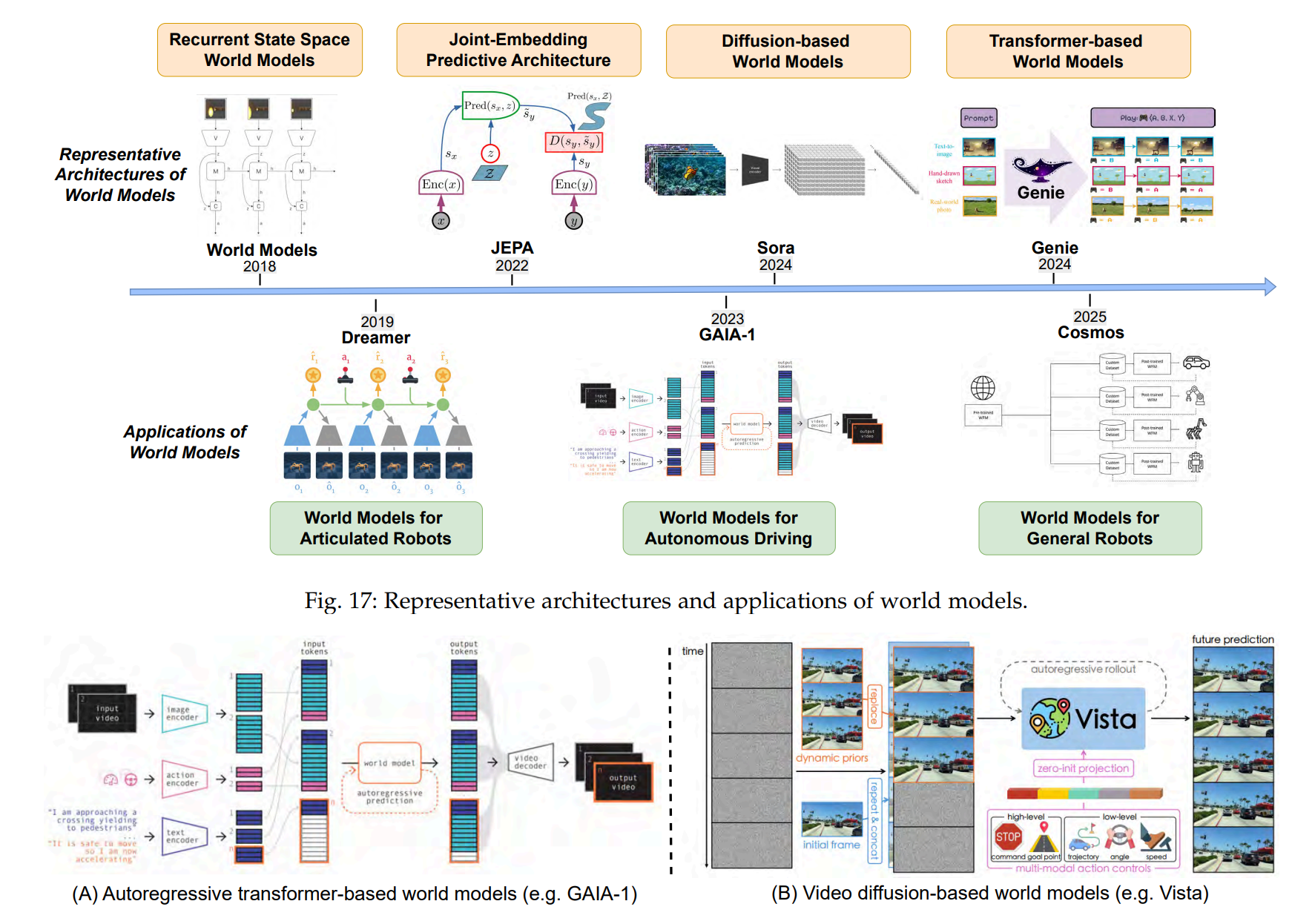
图18:自回归Transformer世界模型与视频扩散世界模型的对比
**基于扩散的生成式世界模型。**近年来,扩散模型迅速成为视频生成的核心,在生成时间一致的视觉序列方面表现出稳定的训练和卓越的保真度。通过从噪声中迭代去噪,这些模型能够捕捉具有高表达能力的复杂数据分布。为降低计算成本,近期研究从像素空间扩散(如VDM 284)转向基于预训练自编码器的潜空间建模,从而实现长时长、高分辨率视频的高效级联生成(如Imagen Video 285、VideoLDM 286、SVD 287)。随着OpenAI的Sora 263和Google DeepMind的Veo3 288等大规模预训练模型的出现,扩散模型不仅展现了视觉真实感,还具备建模3D结构和物理动力学的能力,这些特性与世界模型的目标高度契合。
因此,基于扩散的架构如今在生成式世界模型中被越来越多地采用,其目标是在真实且可控的环境中模拟未来的观测结果。DriveDreamer 289、Vista 290 和 GAIA-2 291 等模型利用扩散模型生成基于动作或其他模态的视频或3D场景。与自回归模型相比,扩散模型具有更强的时空一致性与更高的视觉质量,使其成为构建高保真、预测性神经世界模拟器的有力基础。
尽管基于扩散模型的视频世界模型已取得显著进展,但在采样速度、长时长生成以及因果时序动态建模能力方面仍存在挑战。因此,新兴研究如Vid2World 292和Epona 293正在探索将扩散模型的视觉表现力与自回归模型的时序建模优势相结合,以实现真实且交互式的视频世界建模。
5.2 世界模型的核心角色
除架构设计外,理解世界模型在智能系统中的作用同样重要。作为环境的通用表征,世界模型在多个领域中发挥关键作用。其抽象和预测环境动态的能力使它们能够支持远超简单重建任务的下游应用。在本节中,我们重点阐述世界模型的三个核心角色:1)作为神经模拟器,生成可控、高保真的合成体验;2)作为动态模型,支持基于模型的强化学习中的规划与决策;3)作为奖励模型,在缺乏密集或明确定义的奖励时帮助提取有意义的训练信号。这些视角不仅体现了世界模型的实际应用价值,也为未来利用世界建模技术发展智能体的研究方向提供了指导。
5.2.1 世界模型作为神经模拟器
生成式世界模型的兴起解锁了在视觉和动作领域模拟复杂可控环境的潜力。这些模型能够基于文本、图像和轨迹等多样化输入,生成时间连贯且语义合理的视频,从而支持自动驾驶、机器人和虚拟智能体的可扩展训练与评估。
NVIDIA的Cosmos系列是这一方向的典范。Cosmos 294 提出了一种统一平台,用于构建基础视频模型作为通用世界模拟器,可通过微调适配机器人和自动驾驶等特定领域。该平台提供全栈流水线,涵盖视频过滤与标记化、预训练及下游任务适配,专为高效开源世界模型开发而设计。
在此基础上,Cosmos-Transfer1 295 引入了一个空间条件化的多模态视频生成器。通过自适应融合控制,它整合了分割图、深度图和边缘图等结构化输入以引导视频合成。其空间加权机制增强了生成的可控性和多样性,支持 sim-to-real transfer、data augmentation 和机器人感知等应用的细粒度控制。
除通用模型外,领域特定模拟器如 Wayve 的 GAIA 系列专注于真实且可控的交通模拟。GAIA-1 282 通过多模态输入(语言、视觉和动作)对驾驶视频进行无监督序列建模,生成离散视频标记。GAIA-2 291 通过将结构化先验(车辆状态、道路布局、场景语义)与潜在扩散骨干网络结合,提升了生成保真度和控制能力,实现不同交通场景下的高分辨率、多摄像头一致的视频合成。
除了基于图像的模型外,新兴研究探索了显式建模物理 occupancy 或场景几何的 3D 结构化神经模拟器。DriveWorld 296 构建了城市规模的交通模拟器,具备智能体间的因果交互,为具身规划提供了结构丰富的环境。同样,DOME 297 提出了一种基于扩散的世界模型,预测未来的 3D occupancy 帧而非 RGB 像素,实现了高保真和长程预测,同时具备细粒度的可控性。AETHER 298 引入了一个几何感知框架,同时保持场景几何一致性并确保生成内容的可推断性,从而为统一的世界模型奠定了几何基础。此外,DeepVerse 299 将世界建模重新定义为 4D 自回归视频生成任务,生成既连贯又可控的未来预测。这些方法表明,神经模拟器无需生成 RGB 视频:结构化的 3D/4D 世界表示同样可以作为控制密集型领域的模拟骨干。

图19:基于模型的强化学习的通用框架。智能体学习动态模型f: (st, at) → st+1和奖励模型r: (st, at) → rt,用于模拟交互并改进策略学习。
总体而言,作为神经模拟器的视频和 3D 生成模型能够实现可控、高保真且结构丰富的世界合成,为训练智能体提供了可扩展的替代方案。随着模型表达能力和控制能力的提升,它们在仿真、稀有事件合成和数据驱动决策等领域的应用将日益广泛,涵盖自动驾驶、人形机器人等多个领域。
5.2.2 世界模型作为动态模型
在基于模型的强化学习(MBRL)中,智能体构建环境的内部模型。该模型通常包括动态模型、奖励模型和策略模型。智能体利用该模型模拟与环境的交互,从而帮助其做出更优决策,如图19所示。智能体不单纯依赖现实世界的交互,而是从收集的经验中学习动态模型和奖励模型,随后在模拟环境中进行规划或策略学习。这种环境建模与策略优化的解耦显著提升了样本效率,尤其在数据收集成本高、速度慢或高风险的场景中价值显著。
世界模型可以作为MBRL中的通用动态模型,通过学习基于过去交互来预测未来状态或观测值。与依赖手工设计的符号规则或低维物理模拟器不同,世界模型直接从数据中学习环境动力学的内部表征。这些模型使智能体能够模拟假想的未来、执行rollout进行规划,并通过想象的经验优化行为。根据设计,世界模型可在像素空间、潜在空间或结构化表示中运行,但其共同目标是捕获环境的时序演化,以支持高效的策略学习。这种建模灵活性使世界模型能够跨任务泛化、整合丰富的感知输入,并作为复杂领域决策的可扩展基础。
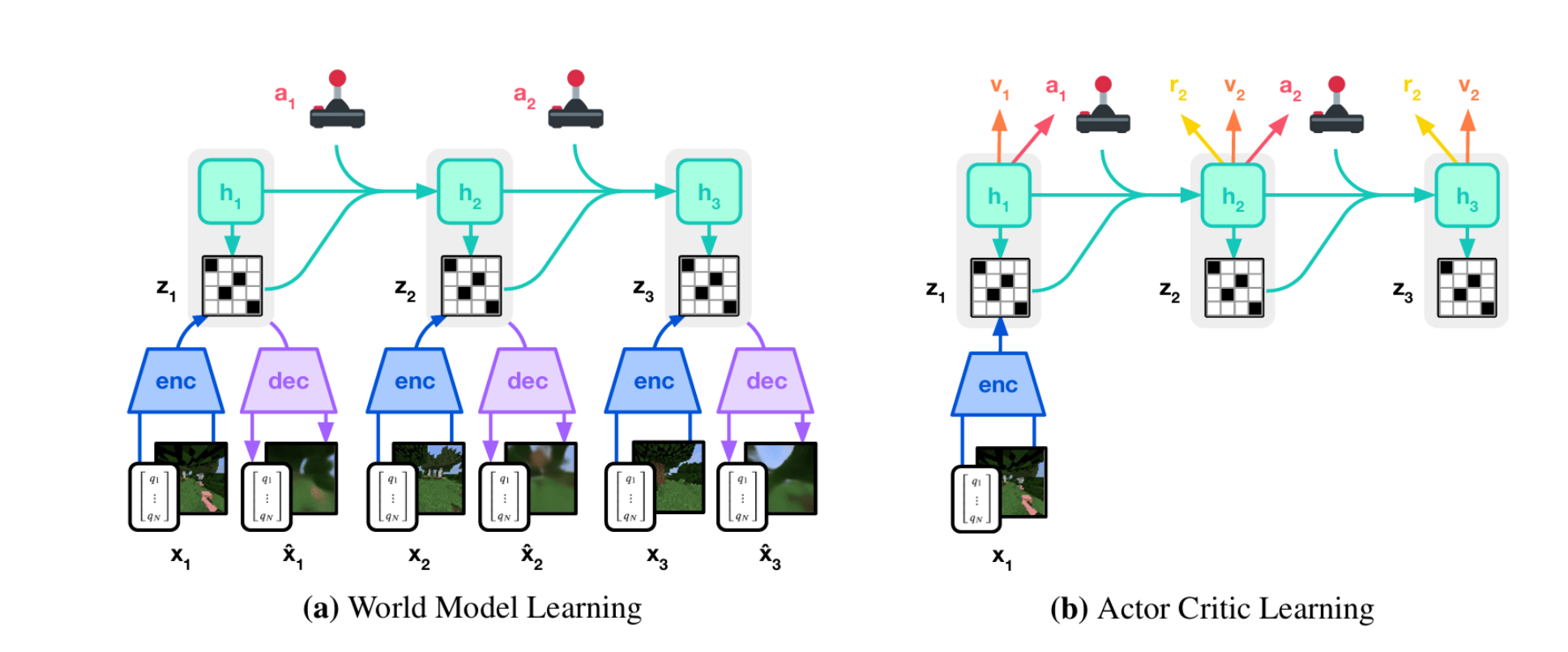
图20:Dreamer系列的核心思想300:将潜在世界模型作为动力学模型进行学习,并通过基于模型的RL优化策略
Dreamer系列系统性地探索基于视觉输入的环境动力学潜在空间建模。如图20所示,其核心思想是通过变分自编码和状态空间建模将高维观测编码为紧凑、可预测的潜在轨迹,从而利用想象的rollout高效学习策略。DreamerV1 268 引入了循环状态空间模型(RSSM),在DMC等基于像素的控制基准测试中表现优异。DreamerV2 269 通过引入离散潜在变量扩展该框架,提升建模能力与泛化性,在Atari上达到人类水平的表现。DreamerV3 270 进一步整合归一化与训练稳定机制,成为首个在广泛视觉控制任务中达到顶尖性能的通用世界模型。DayDreamer 271 通过在物理机器人上部署Dreamer风格的模型,验证了该方法在现实世界中的适用性。
为提升模型的泛化与迁移能力,近期研究探索了在真实世界视频数据上预训练世界模型的方法。ContextWM 301 通过自然视频以无监督方式学习可泛化的视觉动态。通过引入上下文调制机制,该模型有选择地关注可预测的时空区域,从而在下游机器人与驾驶任务中实现更高效的样本微调。这些结果表明,高质量的视觉预训练能够赋予世界模型跨域可迁移的先验。
超越潜在建模,基于token的方法直接在离散视频空间中建模视觉动态。iVideoGPT 302 是该方向的典型代表,使用VQ-VAE 303将视频、动作和奖励token化为多模态序列。随后训练Transformer,基于过去上下文自回归预测未来token。与Dreamer风格的方法不同,iVideoGPT绕过显式状态构建,转而采样完整的视频rollout,通过标准的actor-critic方法304增强离线策略学习。这种直接建模方法提供了更大的灵活性,并在复杂的多步规划任务中展现出强大的泛化能力。
总之,世界模型作为动态模型,使智能体能够基于环境动态进行学习、模拟和规划。无论是在潜在空间还是高维视觉空间中实现,它们都通过将感知、预测和决策统一到单一生成框架中,成为现代MBRL系统的核心。
5.2.3 世界模型作为奖励模型
在RL中,设计有效的奖励信号仍然是一个根本性挑战,特别是在开放或复杂环境中。传统方法通常依赖于手工设计的奖励函数,这些函数定义成本高,且可能无法捕捉有意义的行为线索。这一限制推动了能够从弱监督或无标签数据(如原始视频)中自动推断奖励的方法的发展。
近年来,生成式世界模型的最新进展,尤其是用于视频预测训练的模型,为奖励推理提供了有前景的方向。这些模型能够学习捕捉专家演示中的潜在动态和结构,从而作为隐式奖励模型。关键洞察在于,若智能体的行为生成了模型更易预测的轨迹,则其很可能与训练数据中隐含的偏好一致。因此,模型的预测置信度可被视作一种学习到的奖励信号。
VIPER 305 是这一方法的典型代表。它在专家演示上训练自回归视频世界模型,并将模型在智能体在线行为中的预测似然作为奖励。当智能体的行为生成高度可预测轨迹时,会获得更高奖励。这使得无需手动定义奖励即可学习高质量策略。VIPER在DMC、Atari和RLBench等视觉控制基准测试中表现出色。此外,由于所学世界模型的泛化能力,VIPER能够将奖励推理迁移到不同形态和环境,例如机械臂的变化或场景布局的差异。
展望未来,随着长期建模和多模态条件生成的持续进步,生成式世界模型有望在奖励建模中发挥核心作用,例如人形控制、多智能体协作和具身交互。将动态建模和奖励推断整合到单一生成式框架中,有望推动能够直接从原始视觉体验中学习的通用智能体的发展。
6 智能体的世界模型
自动驾驶和关节机器人(包括机械臂、四足机器人和人形机器人)是人工智能和具身智能的两个关键应用。自动驾驶车辆可视为四轮智能机器人,动作空间比人形机器人更小。此外,自动驾驶作为人工智能的关键应用,对世界模型提出了严格要求。此外,自动驾驶系统需要实时理解和预测复杂动态的道路环境。如前文所述,作为世界模型的视频生成模型已展现出捕捉物理规律和动态交互的能力,使其非常适合自动驾驶这种高度动态且高风险的场景。关节机器人(包括机械臂、四足机器人和人形机器人)作为具身智能的核心载体,对世界模型提出了独特且严格的要求。与自动驾驶类似,机器人系统也需要预测和理解周围环境,以在以人为中心的环境中执行复杂的运动与操作任务。
自动驾驶和关节机器人在应用过程中需要与真实世界进行丰富、长期且安全的交互,这对真实世界的精确且可预测的建模提出了高要求。本节探讨了世界模型在自动驾驶和关节机器人中的应用与挑战,尤其是在视频生成模型方面。
6.1 自动驾驶中的世界模型
传统自动驾驶架构采用模块化设计,包含独立的感知、预测、规划和控制模块 306, 307。尽管该设计有助于开发和测试,但存在关键局限性:感知模块中的错误在处理过程中会累积并放大 308,长期依赖关系的时间建模仍具挑战性 309,且在陌生场景中性能显著下降,例如2018年Uber自动驾驶车辆事故中,系统在撞击前5.6秒检测到行人却多次未能正确识别 310。
特斯拉在自动驾驶和机器人研发中采用相似的视觉编码架构 311,反映了感知技术的共通性。基于视频生成的世界模型已成为自动驾驶研究的关键领域,从早期的基础模型发展到能够实现场景生成、多视角一致性、闭环仿真和推理等重大进展的复杂系统。与之前讨论的通用视频生成世界模型不同,专为自动驾驶设计的模型优先考虑交通场景的独特特性和安全需求,从而发展出几种显著的技术方法和应用范式。
我们遵循第5.2节的先前分类,将自动驾驶世界模型分为三大类,如图21所示:Neural Simulator、Dynamic Model 和 Reward Model。图22展示了自动驾驶世界模型的三个代表性流程。
6.1.1 WMs 作为自动驾驶的神经模拟器
神经模拟器专注于生成逼真的驾驶场景,用于训练和测试自动驾驶系统。这些模型通常接收多模态输入(图像、文本、动作、轨迹),并生成高保真视频序列,模拟多样化的驾驶条件,用于数据增强和安全验证。
GAIA-1 282 首次将世界建模视为自动驾驶中的序列预测问题,通过自回归Transformer架构整合视频、文本和动作输入,生成逼真的驾驶场景。该模型采用90亿参数的Transformer,在4700小时专有驾驶数据上训练,展现出涌现行为,如从同一上下文预测多样化的未来场景,并对动态智能体间的交互进行推理。其关键创新在于仅凭学习到的理解生成长且多样的驾驶场景,并通过动作条件和文本提示实现可控生成,从而影响天气、时间等环境因素。
在此基础上,GAIA-2 312 通过从自回归方法转向扩散模型方法,并结合结构化条件控制,进一步提升了对自驾车动力学、多智能体交互及环境因素的可控生成能力。该模型整合了结构化条件输入和专有驾驶模型的外部潜在嵌入,在英国、美国、德国等多样地理环境中实现了对天气、光照及场景几何结构的细粒度控制。这种增强的可控性通过高分辨率、时空一致的多摄像头视频生成,使得常见与罕见的安全关键驾驶场景的可扩展模拟成为可能。
DriveDreamer 313 也引入了基于扩散的生成方法,结合结构化交通约束,代表了驾驶场景生成的重大突破。该模型通过学习真实驾驶场景而非模拟环境,在真实数据上表现优异,采用两阶段训练流程:第一阶段学习结构化交通约束,第二阶段实现未来状态预测。该方法能够生成精确且可控的视频,准确捕捉真实交通的结构约束。
DriveDreamer-2 314 通过整合大型语言模型(LLMs)增强了DriveDreamer框架,以实现自然语言驱动的场景生成。系统通过LLM接口将文本用户查询转换为智能体轨迹,随后生成符合交通规则的HDMap,最后使用统一多视角模型(UniMVM)生成具有增强时空一致性的驾驶视频。这是首个能够根据用户描述生成定制化驾驶视频的世界模型,在提升质量的同时,还能生成多样且罕见的驾驶场景,这对鲁棒的自动驾驶训练至关重要。
DriveDreamer4D 315 通过利用世界模型先验进一步提升4D驾驶场景表示,合成具有显式时空一致性控制的新颖轨迹视频。该框架将现有世界模型作为"数据机器",在结构化条件下合成具有显式交通元素时空一致性控制的新颖轨迹视频。一项关键创新是"cousin data training strategy",该策略有效整合真实与合成数据以优化4D高斯泼溅重建,显著提升新轨迹视角的生成质量及时空一致性。
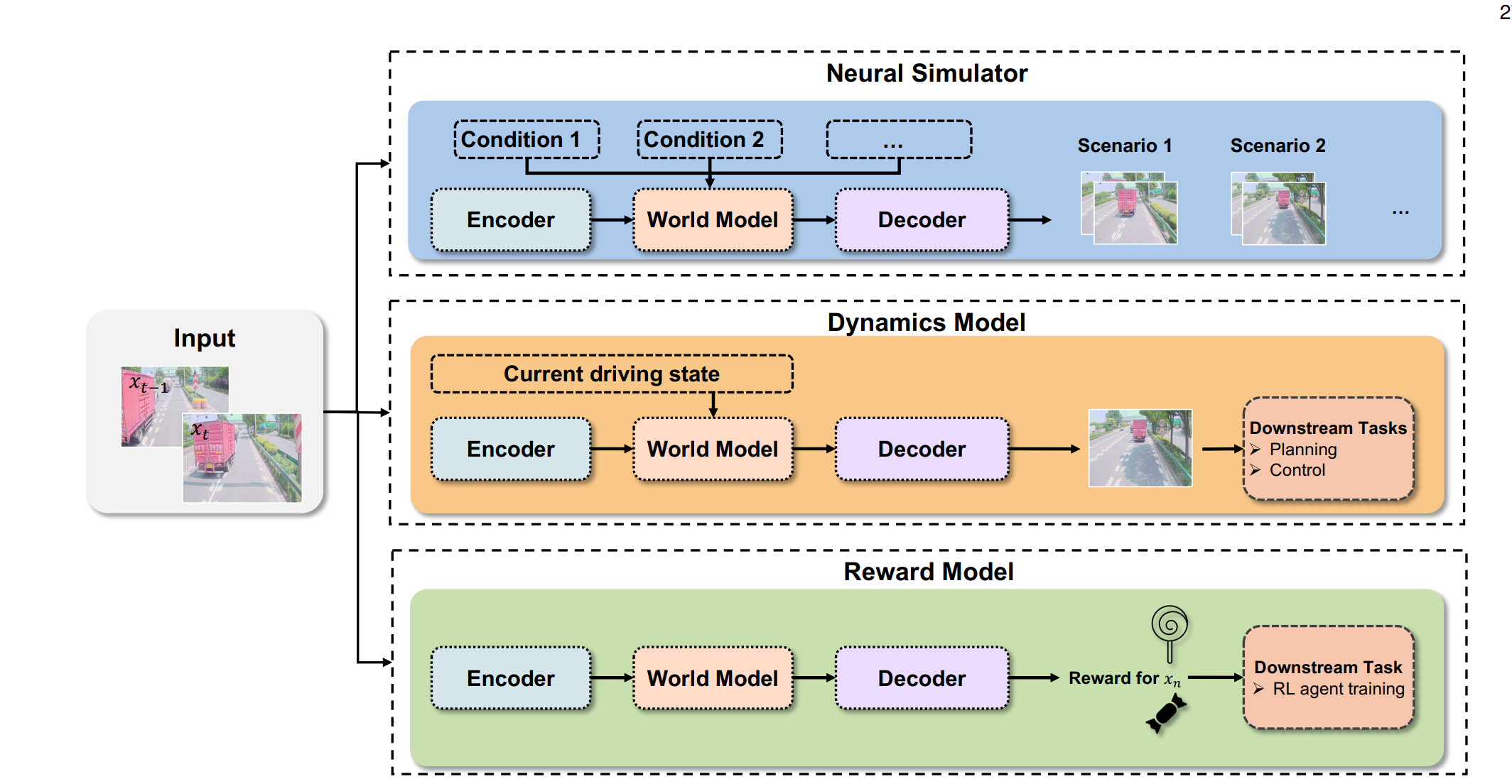
图21:世界模型在自动驾驶中的三个角色:Neural Simulator、Dynamics Model和Reward Model
目标是解决3D几何控制的挑战,MagicDrive 316 提出了一种新型街景生成框架,支持多种输入,包括相机位姿、道路地图、3D边界框和文本描述。该系统针对不同输入采用定制化编码策略,并引入跨视图注意力模块以确保多视角一致性,从而实现高保真街景合成,精准捕捉精细的3D几何结构及光照、天气等多样场景特性。
MagicDrive3D 317 通过创新的"先生成后重建"两步流程,扩展了该能力以支持任意视角的可控3D生成。该框架首先训练条件多视图视频生成模型,然后利用Deformable Gaussian Splatting结合单目深度初始化和外观建模,从生成的视频数据中重建3D场景。这是首个有效整合几何无关的视图合成与几何导向的重建的框架,适用于使用常见驾驶数据集进行可控3D街景生成。MagicDrive-V2 318 采用集成3D VAE的Diffusion Transformer架构,将框架扩展至高分辨率、长时长视频。
系统集成了MVDiT模块用于多视图视频生成、新型时空条件编码以实现精确几何控制,以及三阶段渐进式引导训练策略,支持生成高达848×1600分辨率、241帧的视频,显著提升了自主驾驶应用中的输出分辨率、帧数和控制精度。Panacea 319 专注于具有多视图一致性机制和超分辨率能力的全景视频生成,采用两阶段视频生成模型:先合成多视图图像,再基于这些图像构建多视图视频,整合多视图外观噪声先验机制和超分辨率模块,以生成高质量、高分辨率的360度视频。
专注于多摄像头一致性,WoVoGen 320 引入了显式的4D世界体积作为基础元素,通过两阶段操作来构想未来的4D时序世界体积并生成具有传感器互连性的多摄像头视频。该模型通过整合4D世界体积,巧妙地将时间与空间数据结合,解决了维持世界内部一致性和传感器间一致性的挑战。生成的4D世界特征经过几何变换,为每个摄像头采样3D图像体积,从而实现高质量的街景视频生成,该视频能够响应车辆控制输入,并在各传感器间保持一致性。
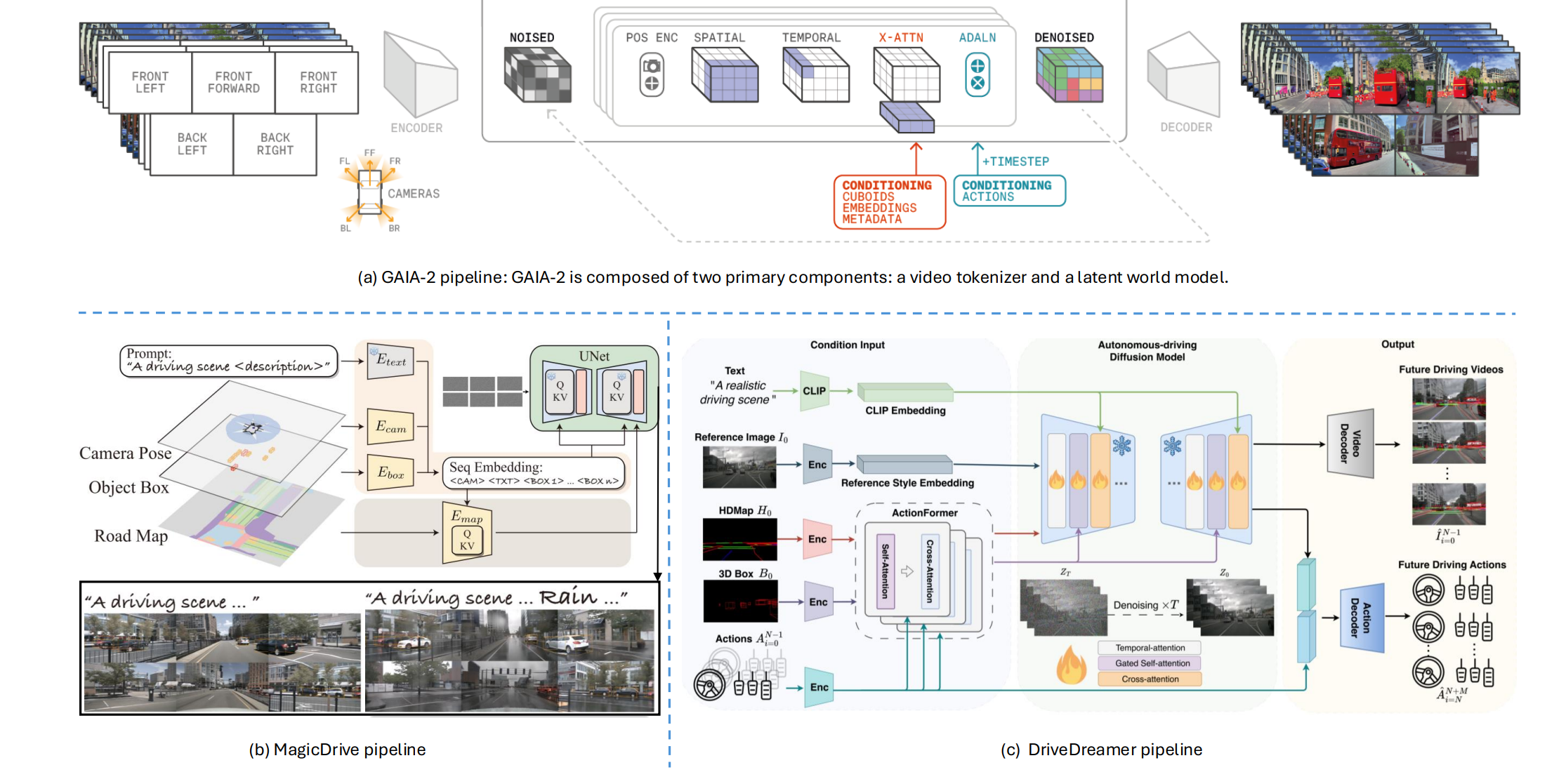
图22:世界模型的代表性流水线示意图:GAIA-2 312、MagicDrive 316 和 DriveDreamer 313
近期研究也探索了占据表示,以实现更结构化的场景理解。Occ-Sora 321 采用基于扩散的4D占据生成模型来模拟3D世界的发展,生成具有真实3D布局和时间一致性的16秒视频。该框架使用4D场景分词器从4D占据输入中获取紧凑、离散的时空表示,随后使用在这些表示上训练的扩散变换器进行轨迹条件下的4D占据生成。Drive-World 322 采用基于占据的内存状态空间模型(MSSM),通过学习多摄像头驾驶视频来实现4D场景理解。该框架包含用于时序感知潜在动态的动态记忆库和用于空间感知潜在静态的静态场景传播模块。
该方法实现了全面的4D场景理解,助力多样化的视觉感知、预测和规划任务,并在多个自动驾驶基准测试中展现出显著改进。Drive-OccWorld 323 通过语义和运动条件归一化技术将占据预测与端到端规划相结合。该框架包含一个记忆模块,从历史BEV嵌入中积累语义和动态信息,通过灵活的动作条件实现对未来状态的可控生成。这种将预测能力与端到端规划相结合的方式,为驾驶场景生成和集成规划系统开辟了新途径。
针对生成结果的时间范围挑战,InfinityDrive 324 通过能够维持长期连贯性的生成模型,实现了无限长驾驶序列的生成。该框架解决了采样速度、长时间生成和时间一致性方面的挑战,旨在实现可控、高效且真实的基于视频的世界建模,用于自动驾驶应用。
ReconDreamer 325 通过在线修复和渐进式数据更新策略,增强了闭环模拟中的驾驶场景重建能力。该框架引入了"DriveRestorer",一个基于世界模型的组件,通过在线修复缓解鬼影伪影,并结合渐进式数据更新,以确保高质量渲染,特别是在大范围复杂机动中。这是首个能够有效渲染大范围复杂机动(如跨度达6米的多车道变道)的方法。
6.1.2 WMs作为自动驾驶的动态模型
动态模型专注于学习驾驶环境中的基础物理原理和运动模式,主要服务于感知、预测和规划任务,而非高保真生成。这些模型学习环境动力学,以实现更好的决策和长期规划。
MILE 350 首创了用于城市驾驶的基于模型的模仿学习方法,通过从专家演示中联合学习预测性世界模型和驾驶策略。该框架通过将高分辨率视频输入和3D几何作为归纳偏置,显著提升了驾驶评分,展示了世界模型如何作为复杂城市环境中策略学习的有效基础。联合学习方法使模型能够同时捕捉环境动态和合适的驾驶行为。
1 几何表示包括:3D体素占用、3D边界框、3D深度、3D分割和3D点云。
2 代码可用性: " " 表示代码未在论文中宣布发布,或已宣布发布但完整代码(训练和推理)尚未可用; "✓" 表示代码已发布。
TrafficBots 352 提出了一种基于条件变分自编码器的多智能体交通仿真方法,通过可配置的智能体个性实现可扩展的多样化驾驶行为模拟。该系统引入了基于目的地的导航和时不变个性潜在变量,以控制智能体从激进到谨慎的行为风格,提供了一个全面的框架用于模拟交通场景中的真实多智能体交互。
基于占据表示以提升3D理解,UniWorld 353 将4D几何占据预测作为基础预训练任务,在运动预测、3D目标检测和语义场景补全方面取得了显著提升。该框架表明,4D占据预测可作为统一的预训练目标,通过全面的时空场景理解,有效提升多个下游自动驾驶任务的性能。OccWorld 283 采用向量量化变分自编码器从3D占据数据中学习离散场景标记,实现了类GPT的时空生成建模。该方法将场景理解转化为序列建模问题,能够在长时序中保持空间和时间一致性的同时,高效地进行未来占据状态的自回归预测。GaussianWorld 368 将3D占据预测重新定义为4D占据预测,利用高斯世界模型推断场景演化,综合考虑自车运动、动态物体及新观测区域。该框架通过高斯表示建模不确定性和时间动态,从而在多移动目标与动态环境条件的复杂驾驶场景中实现更稳健的预测。
DFIT-OccWorld 369 提出了一种基于解耦动态流的高效占用世界模型,以图像辅助训练范式将占用预测重构为体素形变过程。该方法通过分离静态和动态场景元素,在保持预测精度的同时提升了计算效率,从而实现实时自动驾驶系统中更可扩展的部署。
MUVO 356 针对传感器融合与几何理解问题,采用空间体素表示,从相机和LiDAR数据中学习传感器无关的几何理解。该框架通过将多模态传感器输入整合为统一的3D表示,弥补了现有世界模型中物理和几何属性被忽视的问题,从而实现更全面的场景理解,弥合不同传感器模态间的差距。ViDAR 357 将视觉点云预测作为预训练任务,仅基于历史视觉输入预测未来的LiDAR点云,以促进语义、3D结构和时序动态的协同学习。这种跨模态方法展示了世界模型如何在保持时空一致性和语义理解的同时,学习不同传感器模态间的转换。
LAW 360 提出了一种无需感知标注的自监督学习方法,通过基于当前观测和自车动作预测未来潜在特征。该方法大幅减少了对昂贵人工标注的依赖,同时通过潜在特征预测有效学习环境动态。该框架展示了如何高效训练世界模型,无需密集监督,使其更适用于大规模部署。Think2Drive 358 通过在紧凑的潜在世界模型中训练神经规划器,实现了潜在空间中的高效强化学习,在复杂城市场景中达到专家级水平。该框架表明,潜在世界模型可通过将复杂的高维观测抽象为可管理的潜在表示,同时保留控制所需的关键信息,从而实现高效的规划与决策。HERMES 373 在单一框架内统一了3D场景理解和生成,采用BEV表示和world queries,通过因果注意力机制融入世界知识。该框架展示了世界模型如何整合理解与生成能力,在统一架构中实现感知与模拟,并利用因果注意力机制改进时序建模。
Cosmos-Reason1 351 代表了在融合物理常识与具身推理方面的前沿探索,能够在推理可能的物理交互时生成更符合物理规律的场景。该研究通过将物理推理能力整合到世界模型中,推动了该领域的发展,使复杂驾驶场景中的物理交互模拟更加真实。Doe-1367 将自动驾驶问题形式化为基于多模态token(观测、描述和动作)的下一个token生成问题,通过自回归生成实现感知、预测和规划的统一。
该方法展示了如何通过将所有模态视为统一序列中的token来调整语言模型架构以适用于自动驾驶,从而实现感知与控制任务的端到端学习。DrivingGPT 370 采用多模态自回归Transformer将驾驶世界建模与轨迹规划相结合,将交错的离散视觉与动作token视为统一的"驾驶语言"。该框架展示了如何将驾驶问题形式化为语言建模问题,使大规模语言模型技术能够应用于自动驾驶,同时保持对视觉输入和控制输出的推理能力。
6.1.3 WMs 作为自动驾驶的奖励模型
奖励模型评估驾驶行为的质量与安全性,通常与强化学习结合用于策略优化。这些模型利用世界模型预测来评估轨迹安全性并指导决策,无需人工设计奖励函数。
Vista376 利用模型自身的模拟能力展示了可泛化的奖励函数,建立了一种新方法:世界模型自身通过模拟结果评估潜在驾驶机动的质量或安全性。该系统支持从高层意图到底层机动的多样化动作控制能力。这种自我评估能力使模型能够为安全驾驶行为提供内在动机,无需人工设计奖励函数。
WoTE 379 专注于使用BEV世界模型进行轨迹评估,以实现在端到端自动驾驶系统中的实时安全评估。该框架利用BEV世界模型预测未来状态,并比图像级方法更高效地评估轨迹安全性,在NAVISIM和Bench2Drive基准测试中展现了最先进的性能。该方法支持实时自动驾驶应用中的持续安全监控和轨迹评估。
Drive-WM 378 通过联合时空建模与视图分解,实现了基于图像奖励评估的多轨迹未来探索。该系统能够根据不同的驾驶操作模拟多种可能的未来情景,并通过图像奖励评估想象中的未来来确定最优轨迹。此功能支持基于世界模型的"what-if"推理进行安全驾驶规划,使系统能够在执行前探索和评估多种潜在动作。
Iso-Dream375 解决了驾驶环境中可控动力学与不可控动力学分离的挑战。该方法通过分离可控动力学(自车动作)与不可控动力学(其他车辆、环境变化),提升了基于模型的强化学习,使复杂交通场景中的长时域规划和决策更加有效。这种分离使模型能够更专注于可控部分的学习,同时准确建模环境不确定性。
6.1.4 技术趋势与影响
自动驾驶世界模型的演进揭示了四大技术趋势,正在重塑车辆仿真与测试的方式:
**生成式架构从自回归到扩散模型的演进:**早期的自动驾驶世界模型如GAIA-1采用自回归Transformer架构,通过顺序标记生成预测未来驾驶场景。尽管这些方法在学习高层场景结构方面表现优异,但受制于标记预测的顺序性,在生成长时间、高保真驾驶视频时面临显著计算挑战。此后,该领域已转向基于扩散模型的范式转变,以DriveDreamer系列、GAIA-2和WoVoGen为代表,这些模型在生成质量控制上更具优势。现代混合架构开始涌现,将自回归与基于扩散的场景生成相结合。MagicDrive-V2等模型中集成扩散Transformer(DiT)代表了最新进展,融合了Transformer注意力机制与扩散生成的优势。
**多模态集成与可控场景生成:**近年来,自动驾驶世界模型已从简单的图像到图像生成,发展为能够整合多种输入类型的先进多模态系统,包括摄像头图像、LiDAR点云、文本描述、车辆轨迹和高清地图。这一演变解决了自动驾驶测试中的根本挑战:需要生成特定且可控的驾驶场景,以在精确设定的条件下对驾驶系统的不同方面进行压力测试。GAIA-2和DriveDreamer-2等模型通过接受结构化输入(如自车动力学、多智能体配置、环境因素(天气、时段)和道路语义)来实现对生成场景的精细控制,体现了这一趋势。这种多模态方法还支持生成同步的多摄像头视图,实现360度覆盖。这些进展已将世界模型转变为能够主动探索各种可能驾驶场景的仿真工具,从而更高效地验证自动驾驶系统。
**3D时空理解与占用表示:**在自动驾驶世界模型领域,一个基础性的发展方向是构建全面的3D时空建模,从而更精准地反映驾驶环境的真实特性。早期模型主要聚焦于生成逼真的摄像头图像,但这种方法无法提供训练鲁棒感知系统所需的几何一致性与3D理解能力,而这些能力对于在真实驾驶场景中推理物体深度、遮挡及空间关系至关重要。3D感知建模的转型体现在OccSora、Drive-OccWorld和OccWorld等框架中,它们通过4D占用网格来表征驾驶场景,将空间结构与时间动态统一编码。这种3D感知建模能力使世界模型不仅能作为数据生成器,还能作为全面的模拟器,预测自车动作如何影响驾驶场景的演变。在GaussianWorld和MagicDrive3D等模型中集成Gaussian Splatting等技术,进一步提升了生成场景的几何保真度,支持新型视图合成,并推动更鲁棒的感知算法的发展。
**自动驾驶的端到端集成流水线:**现代自动驾驶世界模型不再作为独立的仿真工具,而是被设计为模块化端到端自动驾驶系统的预测组件。MILE、LAW、Think2Drive和WoTE等模型通过联合学习世界动态和驾驶策略,展示了这种集成方法,实现了端到端优化,从而最小化不同系统组件间的误差累积。这种集成还延伸至奖励建模能力,例如Vista和Drive-WM等框架利用自身仿真能力评估轨迹安全性并指导策略学习,无需手动设计奖励函数。Doe-1和DrivingGPT等高级集成系统展示了世界模型如何在单一神经架构中统一感知(场景理解)、预测(未来状态预测)和规划(动作生成),将所有模态视为统一序列建模问题中的标记。这种集成趋势的最终目标是构建能够在统一学习表征中对环境进行推理、预测未来状态并规划安全动作的自动驾驶系统。
6.2 关节型机器人的世界模型
关节型机器人(包括机械臂、四足机器人和人形机器人)作为具身智能的核心载体,对世界建模提出了独特而严格的要求。本节系统探讨了世界模型在关节型机器人控制领域的应用与挑战,重点关注基于机器人仿真和多模态学习的方法如何推动机器人技术的范式转变。
6.2.1 WMs作为关节式机器人的神经模拟器
世界模型作为神经模拟器,通过学习多模态输入(如文本、图像、轨迹)生成时间连贯且语义丰富的物理环境表征。这些生成式模型为传统物理模拟器提供了可扩展、数据驱动的替代方案,能够高效训练和评估自主智能体。
一个典型案例是NVIDIA的Cosmos 世界基础模型平台294,它建立了一个统一的框架,用于构建能够通过扩散和自回归架构生成物理准确的3D视频预测的基础世界模型。Cosmos通过从结构化输入(如分割图、深度图)合成逼真且可控的环境,促进仿真到现实迁移、数据增强和机器人感知训练。图23展示了Cosmos-Predict世界基础模型。该平台的模块化设计支持通过专用数据集的后训练实现任务特定微调,显著降低数据需求,这得益于大规模预训练的迁移学习。这种方法弥合了仿真与现实之间的差距,提升了机器人在自动驾驶和机器人操作等动态环境中的学习能力。未来神经仿真保真度和控制技术的进步将进一步扩大其在具身AI系统中的应用。
WHALE 381 提出了一种具有 behavior-conditioning 和 retracing-rollout 的可泛化世界模型框架,用于 OOD 泛化和不确定性估计。Whale-ST(时空Transformer)和 Whale-X 428(414M参数模型)在仿真和真实世界操作任务中展现出增强的可扩展性和性能。
RoboDreamer 382 提出了一种用于机器人决策的组合式世界模型,通过将视频生成分解为基本原语。该模型利用语言组合性,能够泛化到未见过的对象-动作组合和多模态目标,在RT-X中为新任务生成计划,并在仿真中优于单体基线模型。
DreMa 383 提出了一种组合式世界模型,该模型结合Gaussian Splatting和物理模拟以显式复现真实世界动态,通过等变变换实现逼真的未来预测和数据高效的模仿学习,并在Franka机器人上实现了一次性策略学习,精度和泛化能力得到提升。
DreamGen 384 提出了一种四阶段流水线,通过神经轨迹训练可泛化机器人策略,利用视频世界模型跨行为与环境合成逼真数据。该方法从生成视频中提取伪动作,仅需少量真实数据即可实现零样本泛化,经DreamGen Bench基准验证。
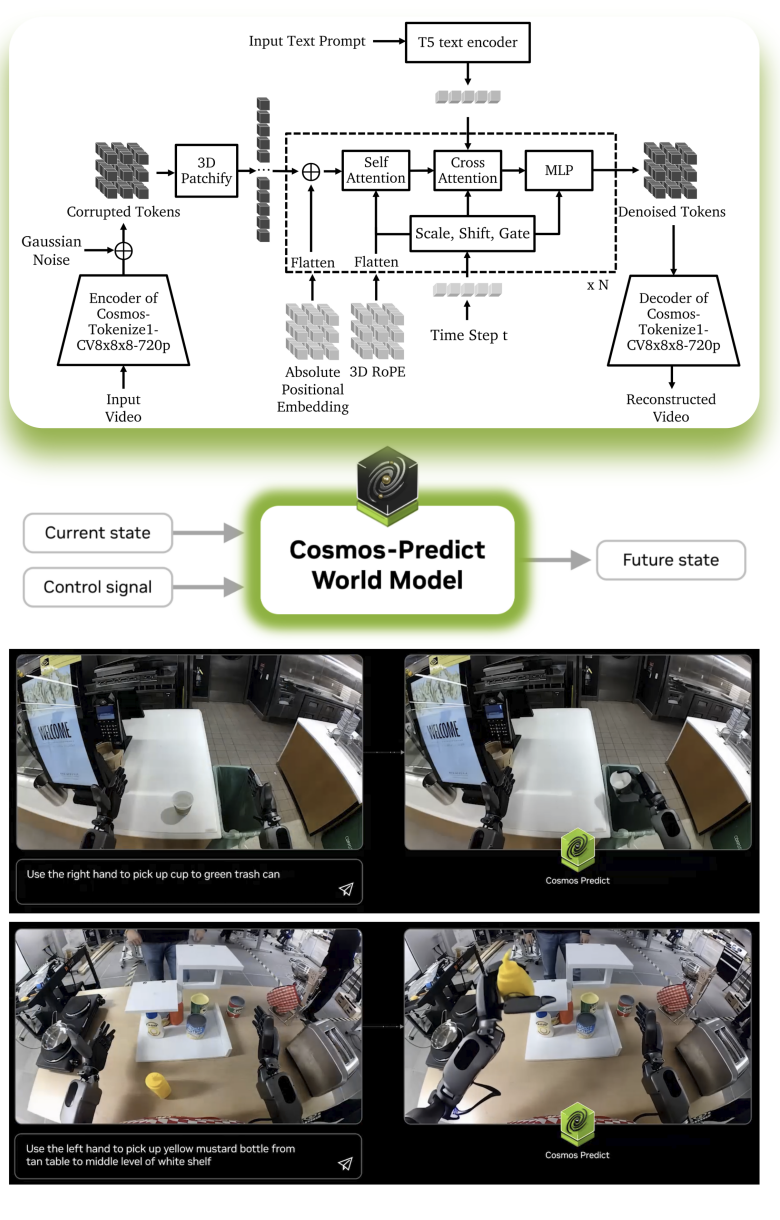
图23:Cosmos-Predict World Foundation Model通过Cosmos-Tokenize1-CV8×8×8-720p处理输入视频,将其编码为受高斯噪声扰动的潜在表示。3D分块步骤对这些潜在表示进行结构化,随后是迭代的自注意力、文本条件交叉注意力和MLP块,由自适应层归一化调节。最后,解码器从精炼后的潜在空间重建高保真视频输出。该架构支持多样化的物理AI应用中的鲁棒时空建模 294。
EnerVerse 385 提出了一种用于机器人操作的生成式基础模型,采用自回归视频扩散和自由锚点视图(FAVs)进行3D世界建模。该框架在EnerVerse-D中整合4D高斯泼溅以减少仿真到现实的差距,而EnerVerse-A将4D表示转换为动作,在仿真和现实世界的ta中实现最先进的性能。
WorldEval 386 提出了一种基于世界模型的在线机器人策略评估流程,使用Policy2Vec通过潜在动作条件化生成动作跟随视频。该方法实现了可扩展、可复现的策略排名与安全检测,展示了与现实世界的强相关性,并超越real-to-sim方法。
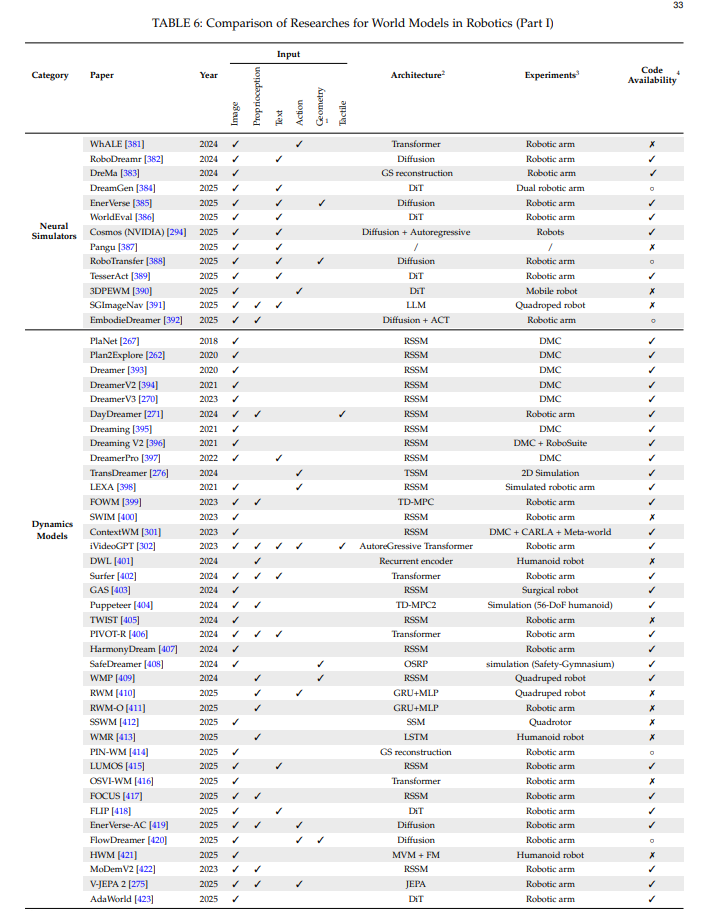
1 几何指3D几何表示,包括:3D体素占用、3D边界框、3D深度、3D分割和3D点云。
2 DiT = 扩散Transformer;RSSM = 循环状态空间模型;TSSM = Transformer状态空间模型;SSM = 状态空间模型;TD-MPC = 时序差分模型预测控制;OSRP = 在线安全奖励规划;GRU = 门控循环单元;MLP = 多层感知机;LSTM = 长短期记忆;GS = 高斯泼溅;MVM = 掩码视频建模;FM = 流匹配;JEPA = 联合嵌入预测架构。
3 DMC = DeepMind控制套件(模拟)。
4 代码可用性:"✗"表示论文中未宣布发布代码,"✓"表示代码已发布,"◦"表示论文中宣布将发布代码,但完整代码(训练和推理)尚未可用。
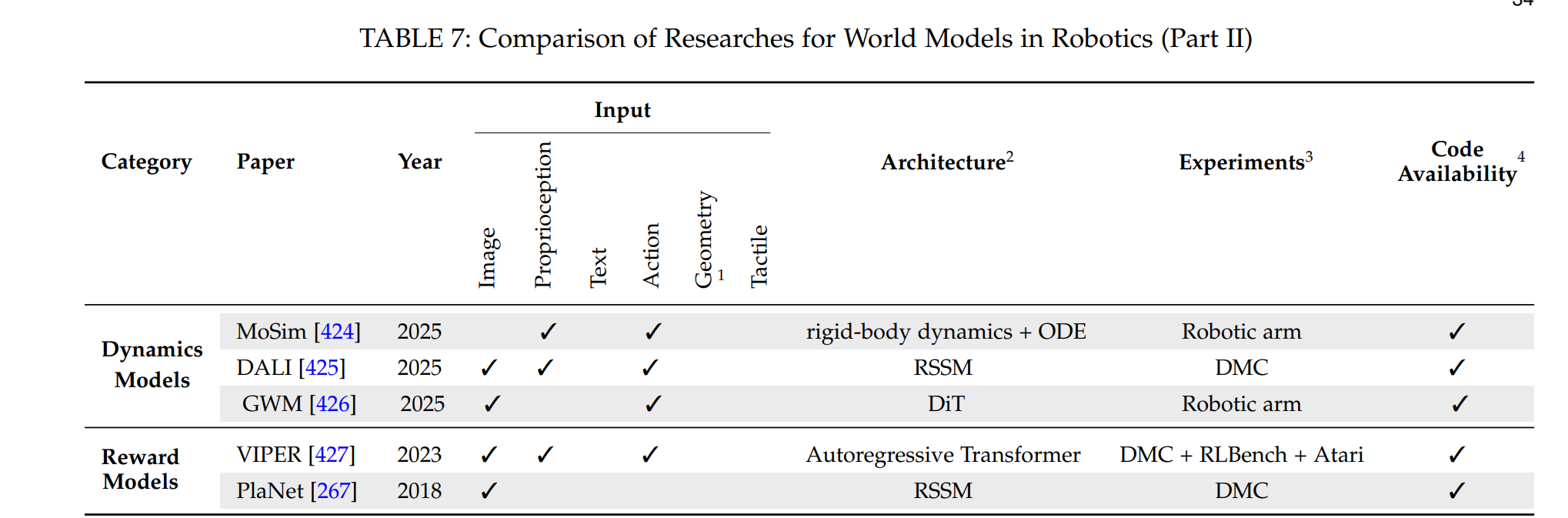
1 几何指3D几何表示,包括:3D体素占用、3D边界框、3D深度、3D分割和3D点云。
2 DiT = Diffusion Transformers; RSSM = Recurrent State-Space Model; TSSM = Transformer State-Space Model; SSM = State-Space Model; TD-MPC = Temporal Difference learning for Model Predictive Control; OSRP = online safety-reward planning; GRU = Gated Recurrent Unit; MLP = Multilayer Percentron; LSTM = Long Short-Term Memory; GS = Gaussian Splatting; MVM = Masked Video Modelling; FM = Flow Matching; JEPA = Joint Embedding-Predictive Architecture.
3 DMC = DeepMind Control suite (Simulation).
4 代码可用性:"✗"表示论文中未宣布发布代码,"✓"表示代码已发布,"◦"表示论文中宣布将发布代码,但完整代码(训练和推理)尚未可用。
华为云盘古世界模型387是一种神经模拟器,可生成高保真数字环境(例如相机视频、激光雷达点云),用于训练智能驾驶和具身AI系统。通过建模物理动力学和多模态传感器数据,无需进行昂贵的现实世界数据采集。与广汽集团合作,可快速生成corner-case和2D-to-3D像素映射。CloudRobo平台进一步扩展了具身AI模型(生成、规划、执行)和R2C协议标准化,旨在通过云端仿真和部署统一机器人开发。
RoboTransfer 388 提出了一种融合多视角几何与显式场景控制的几何一致性视频扩散框架,用于机器人视觉策略迁移。通过约束跨视角特征交互与深度/法线条件,该方法生成几何一致的多视角视频,提升sim-to-real策略性能。该方法支持细粒度场景编辑,同时保持视觉保真度。
6.2.2 WMs 作为关节机器人的动态模型
世界模型通过从观测数据中学习环境动态的预测表示,在基于模型的强化学习(MBRL)中充当动态模型。无需依赖手工设计的物理引擎或稀疏奖励信号,这些模型使智能体能够通过想象的 rollout 来模拟未来状态并规划动作。PlaNet 是最早采用 RSSM 架构的模型之一,如图 24 所示。Dreamer 系列通过使用变分自编码器和 RSSM 从高维观测中学习潜在状态动力学,很好地诠释了这一方法。扩展模型如 TransDreamer 用 Transformer 替代 RNN 以更好地捕捉长程依赖关系,而 ContextWM 和 iVideoGPT 则分别探索在真实视频上的预训练和离散标记建模。这些改进提升了模型的泛化能力、长时程预测能力以及跨任务迁移性。通过解耦感知与规划,世界模型降低了样本复杂度,并提升了复杂高维环境中的决策能力。近期研究进一步证明了其在现实世界中的适用性,验证了其在机器人学和自主系统中的潜力。
PlaNet 429 提出了一种像素级规划的潜变量动态模型,结合确定性与随机性转移及潜变量超调进行多步预测,在未知环境中以比无模型方法更少的episode解决复杂连续控制任务,展现出高样本效率。
Plan2Explore 262 介绍了一种自监督强化学习智能体,该智能体利用基于模型的规划在探索过程中主动寻求未来的新颖性,从而实现对未见任务的零样本或少样本适应;在无需任务特定监督的情况下,其在高维图像控制任务上优于先前方法,接近 oracle 级性能。
Dreamer系列在世界模型方面做了大量工作,并在第5.2.2节中进行了详细讨论。例如,DreamerV3 300提出了一种通用强化学习算法,通过学习世界模型来模拟未来场景,在单一配置下于150多种不同任务上实现了最先进的性能。其鲁棒性技术实现了稳定的跨领域学习,具体体现在无需人类数据或课程学习即可在Minecraft中首次完成钻石收集。
Dreaming 395 移除Dreamer的解码器以缓解物体消失问题,采用无似然性InfoMax对比目标,结合线性动力学和数据增强,在5项机器人任务中取得顶尖性能。
DreamingV2 396 在此基础上融合DreamerV2的离散潜状态与Dreaming的无重建学习,构建混合世界模型,该模型利用分类状态表示处理复杂环境,并结合对比视觉建模,在3D机械臂任务中无需重建即可表现出色。
DreamerPro 397 通过将原型表征整合到Dreamer的世界模型中并从循环状态中提炼时间结构,提升了MBRL对视觉干扰的鲁棒性。该方法在复杂背景的DeepMind Control任务上表现更优,在标准训练设置下优于对比方法。
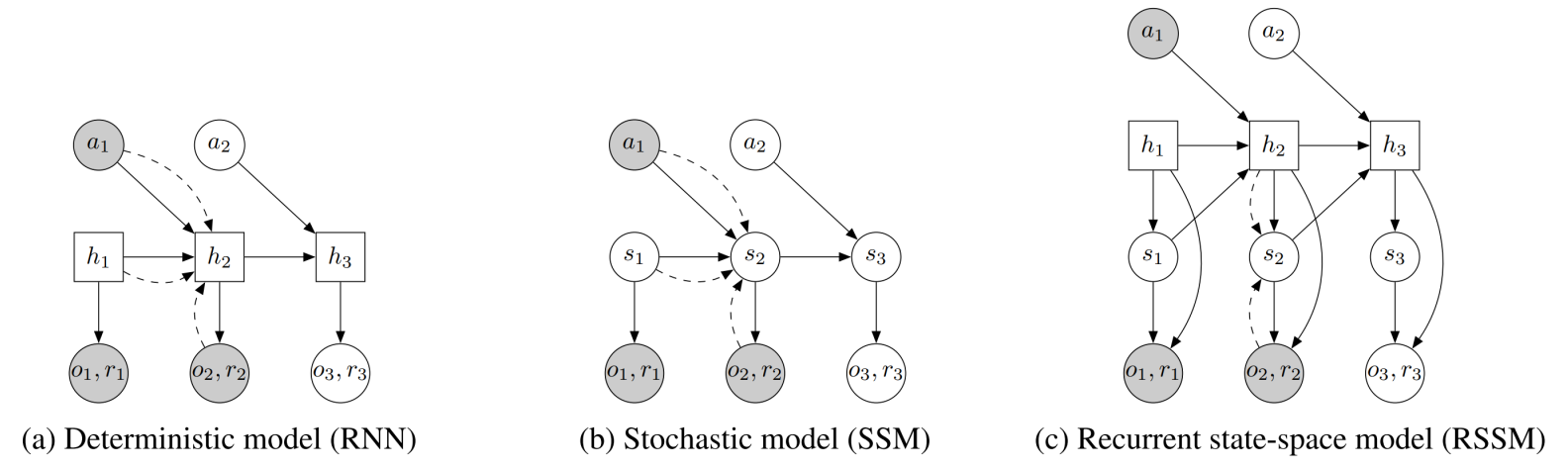
图24:潜在动态模型采用不同的过渡机制进行时间预测。(a) RNN模型使用确定性过渡,限制多模态未来预测,同时便于规划器利用。(b) 状态空间模型(SSM)仅依赖随机过渡,阻碍长期记忆保持。(c) RSSM结合随机和确定性状态分量,平衡多路径预测与时间连贯性。这种混合方法在学习多样化未来的同时保持序列一致性,从而提升鲁棒性,如429所示。
LEXA 398 提出了一种统一的无监督目标达成框架,结合基于世界模型的想象rollouts与前瞻性驱动的探索,以发现新状态并完成多样化任务。该方法在40项具有挑战性的机器人任务上优于先前方法,展示了零样本泛化和多环境下的可扩展性。
FOWM 399 提出了一种结合离线世界模型预训练与在线微调的框架,通过认知不确定性正则化来缓解外推误差。该框架能够在有限的离线数据下,对已见和未见的视觉-运动任务实现少样本适应,并在仿真和真实世界机器人控制基准上得到验证。
SWIM 400 提出了一种适用于机器人操作的可供性空间世界模型,该模型基于人类视频训练并通过少量机器人数据微调,能从人与物体交互中学习结构化动作表示,无需特定任务监督即可在多样任务和机器人上快速掌握技能(<30分钟)。
DWL 401 是一个端到端RL框架,用于人形机器人运动。世界模型实现了零样本Sim-to-Real迁移,仅需单一策略即可掌握雪地、楼梯、不平地面等多种复杂地形。该方法无需环境特定调优即可展现出鲁棒性和泛化能力。
Surfer402 提出了一种基于世界模型的机器人操作框架,通过解耦动作与场景预测来提升多模态任务的泛化能力。该框架显式建模世界知识,并在SeaWave基准测试中达到54.74%的成功率,通过建模基于物理的状态转移超越了基线方法。
GAS 403提出了一种面向手术机器人操作的基于世界模型的深度强化学习框架,采用像素级视觉运动策略,结合不确定性感知深度估计与紧凑的3通道图像编码。该框架在真实手术环境中处理未见物体和干扰的成功率达69%,在临床环境中展现出比先前方法更优越的鲁棒性与泛化能力。
Puppeteer 404 提出了一种用于视觉全身人形控制的层次化世界模型,其中高层视觉策略生成命令供底层执行策略使用,两者均通过强化学习训练。该方法在无需简化假设或奖励工程的情况下,实现了56-DoF人形机器人在8项任务上的高性能运动合成。
TWIST 405 提出了一种师生世界模型蒸馏框架,用于基于视觉的模型强化学习中的高效的 sim-to-real 迁移。该框架利用状态特权教师模型来监督基于图像的学生模型,通过域随机化蒸馏加速适应并弥合 sim-to-real 差距,在样本效率和任务性能上优于朴素方法。
PIVOT-R 406 提出了一种原语驱动的航点感知世界模型(WAWM),用于语言引导的机器人操作,通过异步分层执行器(AHE)将航点预测与动作执行解耦。该模型在Sea-Wave基准测试中实现19.45%的相对提升,效率提升28倍,且性能损失极小。
HarmonyDream 407 提出了一种针对世界模型的任务协调框架,通过动态平衡观测损失与奖励建模损失,提升MBRL的样本效率。该方法在视觉机器人任务上实现了10%-69%的性能提升,并通过解决世界模型学习中的任务主导问题,刷新了Atari 100K基准记录。
SafeDreamer 408 将基于拉格朗日的方法与世界模型规划融入Dreamer框架,以增强安全强化学习。该方法在Safety-Gymnasium任务中实现了接近零成本的性能,通过提升模型精度和样本效率,在低维和纯视觉输入下有效平衡了性能与安全。
WMP 409 提出了一种基于世界模型的足式运动感知框架,通过从模拟世界模型预测中学习策略,消除了对特权信息的依赖。该框架通过跨域泛化,在仿真和物理环境中验证,实现了最先进的实际环境通行能力与鲁棒性。
RWM 410 提出了一种基于神经网络的机器人世界模型,采用双自回归机制进行长时序动力学预测。该框架通过想象环境实现自监督训练和鲁棒策略优化,解决了部分可观测性和sim-to-real迁移的挑战,且无领域特定偏差。
RWM-O 411 提出一种离线机器人世界模型,具备显式的认知不确定性估计,通过惩罚不可靠的状态转移来增强策略的稳定性和泛化能力。该模型在真实数据环境中验证,无需物理仿真器即可缩小仿真到现实的差距并提升安全性,优于传统MBRL方法。
SSWM 430(状态空间世界模型)用于加速基于模型的强化学习(MBRL)。该方法通过并行化动态模型训练并利用特权信息,使世界模型训练提速最高达10倍、整体MBRL加速4倍,同时在部分可观测的复杂四旋翼飞行任务中保持性能。
WMR 413 提出了一种端到端的世界模型重建框架,用于无视觉辅助的人形运动,通过显式重建世界状态提升策略鲁棒性。梯度截断确保状态重建的独立性,使机器人能够在复杂地形上自适应运动,并通过冰面、雪地及可变形表面3.2公里徒步测试验证。
PIN-WM 414 提出了一种面向非抓取操作的物理信息世界模型,通过可微分仿真实现基于少样本视觉轨迹的端到端3D刚体动力学学习,利用基于高斯泼溅的观测损失消除状态估计,并通过物理感知的数字孪生体弥合Sim2Real差距,实现鲁棒的策略迁移。
LUMOS 415 提出了一种语言条件模仿学习框架,利用世界模型进行潜在空间技能训练。该方法将潜在规划、事后目标重标记与内在奖励相结合,从而实现零样本迁移至真实机器人。它在长时序任务中表现出优异性能,同时缓解了离线设置中的策略导致的分布偏移。
OSVI-WM 432 提出了一种基于世界模型引导轨迹生成的单次视觉模仿学习框架。学习到的世界模型从演示中预测潜在状态和动作,并解码为物理路点用于执行。在模拟和真实机器人平台上评估,该方法相比先前方法性能提升超过30%。
FOCUS 417 提出了一种用于机器人操作的对象中心世界模型,通过结构化对象交互表征场景。该框架支持对象中心的探索,并通过更准确的场景预测提升操作技能。在使用Franka Emika机械臂进行的机器人任务评估中,该模型展示了高效学习和适应稀疏奖励场景的能力。
FLIP 418 提出了一种以流为中心的基于模型的规划框架,用于语言-视觉操作,整合多模态流生成、流条件视频动力学和视觉-语言表征模块。该框架通过图像流生成长期规划,利用交互式世界模型特性指导底层策略训练,并在多种基准测试中验证。
EnerVerse-AC 419 提出了一种面向机器人评估的动作条件世界模型,采用多级动作条件与射线图编码技术生成动态多视角观测。该模型兼具数据引擎与评估器的功能,能够基于人类轨迹合成逼真的动作条件视频,从而实现无需物理机器人或复杂模拟的低成本策略测试。
FlowDreamer 420 提出一种基于显式3D场景流表示的RGB-D世界模型,用于视觉预测与规划,该模型将运动估计(U-Net)和帧合成(扩散模型)解耦,同时保持端到端训练,在操作基准测试中语义质量和成功率均超过基线7-11%。
HWM 421 提出轻量级基于视频的世界模型,用于人形机器人,采用Masked Transformers和FlowMatching来预测动作条件下的自我中心观测。该框架展示了高效的参数共享策略,将模型规模缩减33%-53%的同时保持性能,实现在资源受限的学术环境中的实际部署。
MoDem-V2 422 通过集成演示引导与安全感知探索策略(探索中心化、控制权移交、演员-评论家集成)的基于模型的强化学习框架,实现了真实世界接触丰富的操作学习,并首次在无需仪器的情况下成功实现了基于视觉的MBRL系统在真实世界中的直接训练。
V-JEPA 2 275 是一个拥有12亿参数的世界模型,采用联合嵌入预测架构,用于视频理解、预测及零样本规划。该模型采用两阶段训练:在超过100万小时视频数据上进行无动作数据的预训练以建立物理直觉,随后进行动作条件微调,仅需62小时的机器人数据。V-JEPA 2在动作识别与预测任务中表现优异,并通过视觉子目标规划实现机器人任务的模型预测控制,新环境中成功率65%-80%。该框架还包含三个新基准测试,用于评估物理推理能力。
6.2.3 WMs 作为关节型机器人的奖励模型
世界模型作为奖励模型,利用其学习到的动力学特性,通过衡量智能体行为与模型预测的匹配度来隐式推断奖励。例如,当轨迹高度可预测(即符合世界模型的预期)时,给予更高奖励,从而无需手动设计奖励。
与Dreamer不同,PlaNet使用显式学习的奖励预测器,而Dreamer通过价值函数隐式替换奖励信号。其奖励预测器作为动力学模型的一部分,负责从压缩的潜在状态中预测环境奖励,通过最小化预测奖励与真实奖励之间的误差进行训练,并在在线规划阶段为潜在空间中的多步轨迹展开提供即时奖励信号,从而替代手工设计的奖励函数。

图25:自监督学习架构采用不同方法建模输入兼容性:(a) 联合嵌入对齐兼容输入的嵌入;(b) 生成式方法通过潜变量条件解码器重构信号;(c) 联合嵌入预测使用潜变量条件预测器预测嵌入。各框架优化能量分配------兼容输入能量低,不兼容输入能量高 431。
此类方法统一环境模拟与奖励生成,实现基于原始观测的可扩展RL。该范式在迁移学习中尤其强大,如VIPER的跨具身泛化所示。
VIPER 427 提出使用预训练视频预测模型作为强化学习的奖励信号。该方法在专家视频上训练自回归Transformer,并利用预测似然作为奖励,能够在DMC、Atari和RLBench任务中实现无需任务特定奖励的专家级控制,同时支持桌面操作场景中的跨实体泛化。
6.2.4 技术趋势
世界模型未来具有广阔的发展前景,但在机器人领域,它可能具有以下发展潜力:
**触觉增强型世界模型用于灵巧操作。**触觉整合型世界模型的演进正在推动机器人灵巧性的突破性进展,尤其在多指手领域。前沿方法将高分辨率接触建模与视觉触觉融合技术相结合,通过神经网络实时预测打滑、形变及最优抓取力。自监督触觉编码器通过自主学习材料与形状表征,无需人工标注;图网络/变换器架构处理动态时空触觉信号。这些创新使机器人能够以类人适应性处理新型物体,克服了精细操作任务中的传统sim-to-real挑战。
**统一世界模型,跨硬件与跨任务泛化。**未来机器人世界模型将聚焦于硬件无关的动力学编码和任务自适应的潜在空间,以实现对多样化的实体(如单臂/双臂、腿式/轮式机器人)和任务(如夹持器与灵巧手操作)的泛化。关键方向包括:具有共享物理先验的模块化架构以实现可迁移的动力学学习;元强化学习以快速适应新的硬件/任务组合;以物体为中心的表征实现跨场景的技能复用;以及通过残差物理建模构建仿真到现实的桥梁。这些进展旨在为可扩展的机器人智能创建"one model fits all"解决方案。
**面向长时程任务的层次化世界模型。**未来机器人世界模型将聚焦于层次化规划与时序抽象,以处理复杂多阶段任务。关键进展包括:用于动态子任务链的目标条件化潜在空间、用于捕捉长期依赖关系的记忆增强Transformer、用于可复用基元的自监督技能发现,以及用于实时计划调整的交互式人类反馈。这些创新旨在弥合高层推理与底层控制之间的差距,从而在开放环境中实现稳健自主性。
6.3 挑战与未来展望
**高维与部分可观测性。**自主系统处理高维感知输入,例如相机图像、LiDAR点云和雷达信号。基于这些数据建模世界需要大量计算资源。此外,这些观测本质上是部分的;智能体无法感知环境的完整状态。这种部分可观测性引入了不确定性,需要鲁棒的状态估计技术或维护信念状态以指导决策。
**因果推理与相关性学习。**当前许多世界模型的根本性局限在于其擅长学习相关性而非因果关系。例如,模型可以学习到刹车灯与减速之间的相关性,但可能缺乏对底层物理原理和驾驶员意图的深入理解。这一缺陷阻碍了真正的泛化能力,因为它使模型无法进行反事实推理------评估偏离训练分布的"what if"场景。在新情境中实现稳健表现需要从相关性模式匹配转向对环境的真正因果理解。
**抽象与语义理解。**有效的世界模型必须超越低层次的信号预测,实现更高层次的语义和抽象理解。一个稳健的模型不仅应预测未来的像素或LiDAR点,还应能够对抽象概念进行推理。一个主要的开放性问题在于将细粒度的物理预测与对交通法规、行人意图和物体可供性(例如,椅子是用来坐的)等概念的抽象推理进行融合。整合这些不同层次的抽象对于智能和上下文感知行为至关重要。
**系统评估与基准测试。**世界模型的客观评估与比较是一项重大研究挑战。传统指标如未来预测的MSE往往不够充分,因为它们可能与下游任务的性能无关。生成视觉上更清晰预测的模型未必能带来更安全或更高效的控制策略。需要开发新的评估框架,其指标应评估模型在规划中的实用性、安全关键场景中的鲁棒性,以及捕捉环境因果相关方面的能力。
**记忆架构与长期依赖关系。**准确的长期预测极具挑战性,因为预测误差的累积和现实世界的随机性。关键挑战在于设计能够长时间保留和检索相关信息的记忆架构,例如记住几分钟前看到的"Road Work Ahead"标志。开发高效且有效的记忆系统,利用Transformer或状态空间模型(SSMs)等架构来管理这些长期依赖关系,仍然是一个活跃且存在争议的研究领域。
**人机交互与可预测性。**在以人为中心的环境中运行的智能体,其世界模型的作用不仅限于环境预测,还需使智能体的行为具有可理解性、可预测性并符合社会规范。技术上最优但表现不稳定或反直觉的行为可能让其他司机或行人感到困惑,进而导致不安全的互动。这一社交智能层是功能性世界模型中微妙但关键的组成部分。
**可解释性与可验证性。**基于深度学习的世界模型常被视为"黑箱",难以厘清其预测背后的逻辑。在自动驾驶等安全关键型应用中,审计和理解模型内部决策过程的能力不可或缺,尤其是在事后分析阶段。此外,这些模型的形式化验证是一项艰巨的理论和工程挑战------即通过数学方法证明其在庞大的输入空间中满足关键安全属性(例如,不会产生危险障碍物的幻觉)。
**组合泛化与抽象。**尽管 sim-to-real gap 是一个广为人知的泛化问题,但更深层次的挑战是组合泛化。人类能够学习"杯子"和"桌子"等离散概念,并立即对新组合(如"杯子放在桌子上")进行泛化。相比之下,当前模型通常需要大量特定组合示例的接触。理想的世界模型应学习实体、其关系和物理属性的解耦抽象表示,从而能够通过组合已知概念来理解和预测新场景,而非依赖整个场景的端到端模式匹配。
**数据整理与偏差。**世界模型的性能从根本上取决于其训练数据的质量和组成。模型不可避免地继承数据集中存在的偏差,甚至可能放大这些偏差。例如,主要基于某一地理区域数据训练的模型在具有不同道路规则或环境条件的地区可能表现不佳。数据整理的关键方面之一是处理"长尾"中的罕见但安全关键的事件。系统性地识别、收集这些罕见场景并确保模型有效学习,对于构建稳健可靠的系统至关重要。
7 结论
本综述全面探讨了物理模拟器和世界模型在推进具身人工智能中的关键作用,揭示了向真正智能机器人系统转变的范式变革。通过分析,我们提出了五级分类框架(IR-L0至IR-L4)以评估机器人自主性,对主流模拟平台进行了广泛比较研究,并探讨了世界模型从简单循环架构到复杂的大规模基础模型系统的演变过程。本研究展示了现代模拟器如Isaac Gym、Genesis和新兴的Newton平台如何通过GPU加速的物理模拟和照片级真实感渲染革新机器人学习,而先进的世界模型则为自动驾驶和关节式机器人带来了前所未有的能力。
这些技术不仅缓解了Sim2Real差距,还在多样化环境中解锁了样本高效学习、长时程规划和鲁棒泛化的新可能性。随着我们向IR-L4级全自主系统的实现迈进,物理模拟器与世界模型的融合构成了下一代具身智能的基础,有望将机器人技术从任务特定自动化转变为可无缝融入人类社会的通用智能。