一、selenium库
selenium库是一种用Web应用程序测试的工具,可以驱动浏览器执行特定的操作,自动按照脚本代码做出单击、输入、打开、验证等操作,支持的浏览器有IE、Firefox,Safari,Chrome,Opera等
与requests库不同的是,selenium库是基于浏览器的驱动程序来执行操作的。且浏览器可以实现网页源代码的渲染,因此通过selenium库还可以轻松获取网页中渲染后的数据信息
1、使用selenium库前的准备
1)了解selenium库驱动浏览器的原理
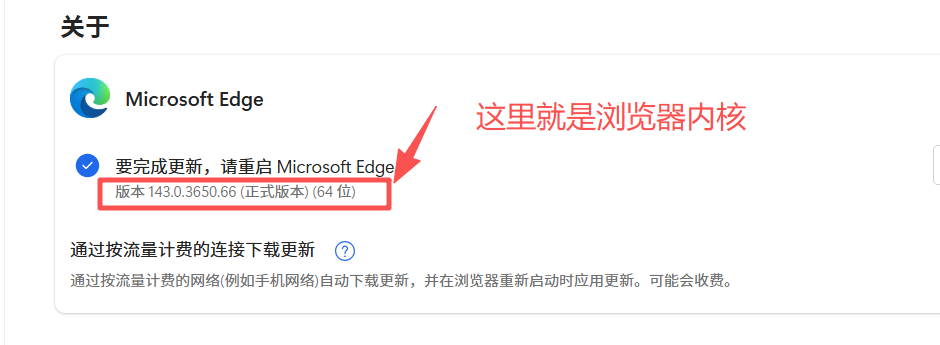
浏览器是在浏览器内核的基础上开发的,浏览器内核主要负责对网页语法进行解释并渲染网页,可以从浏览器设置的关于选项打开查看,这里以edge浏览器为例
2)安装WebDriver
以edge为例,想查看自己电脑的浏览器内核,上面已经查看过是140.0.3650.66(64位)
edge驱动下载地址:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?ch=1\&form=MA13LH
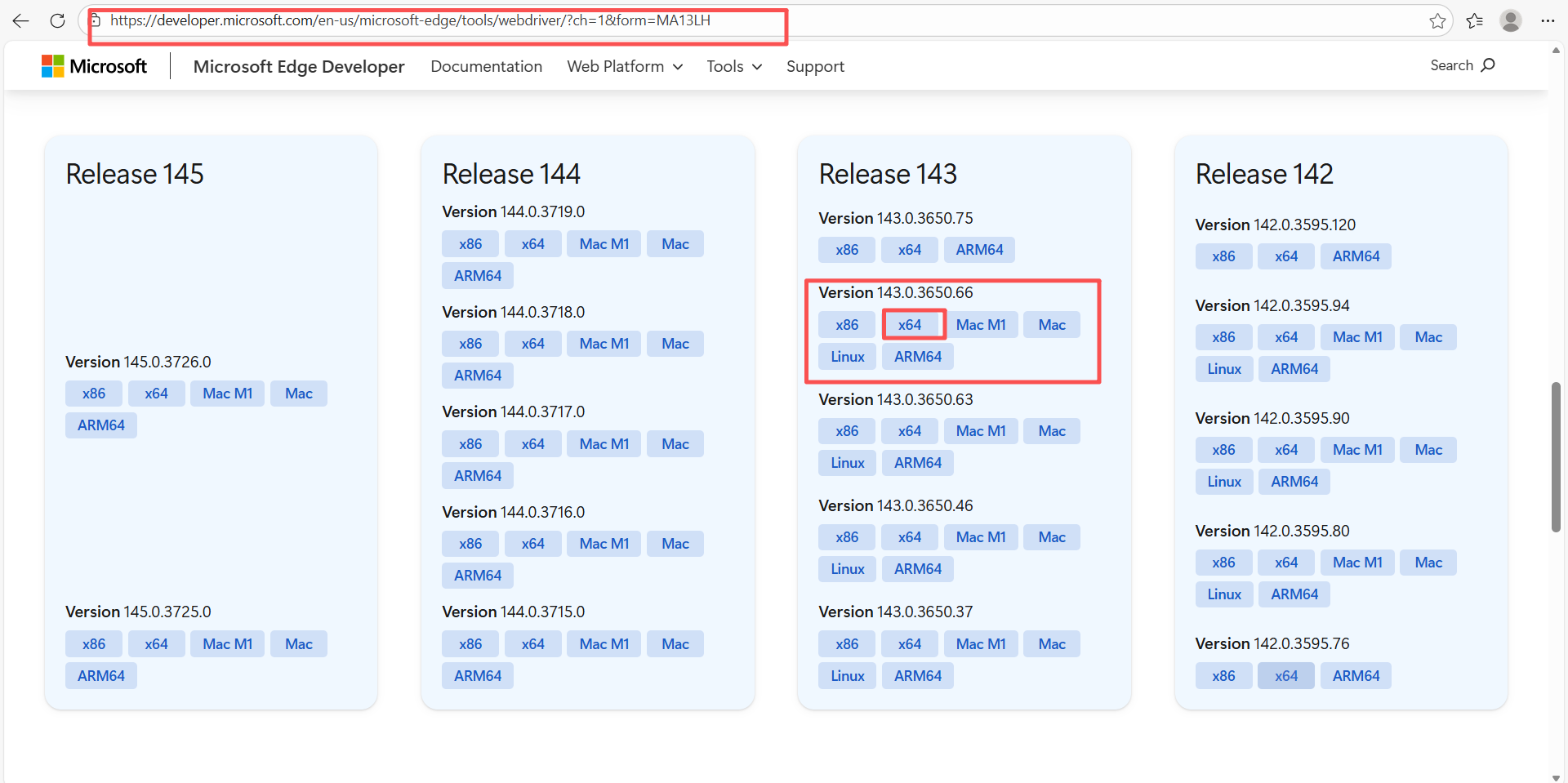
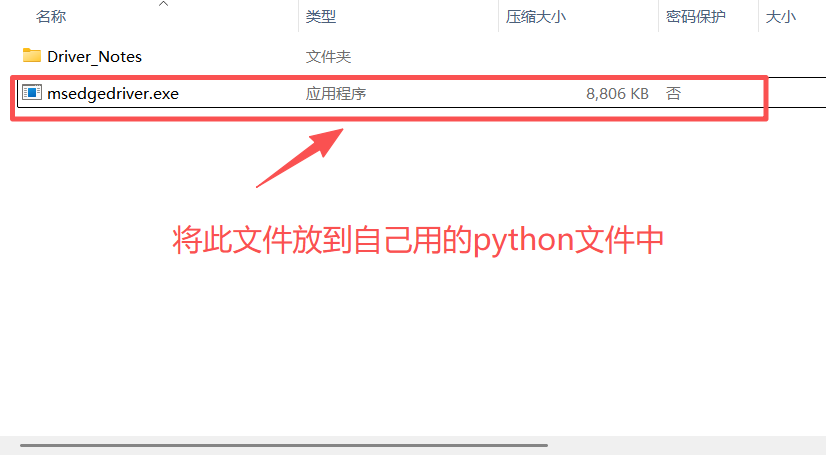
下载后解压得到下面的文件,将图中圈起来的文件放到python安装目录路径下的Scripts文件夹中
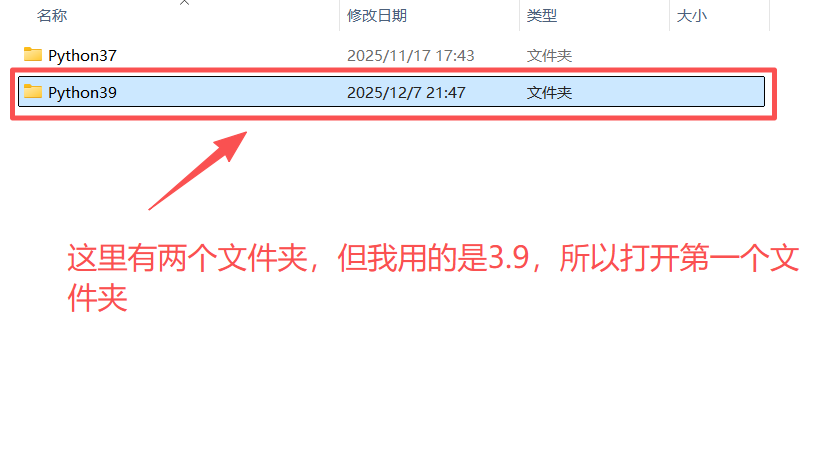
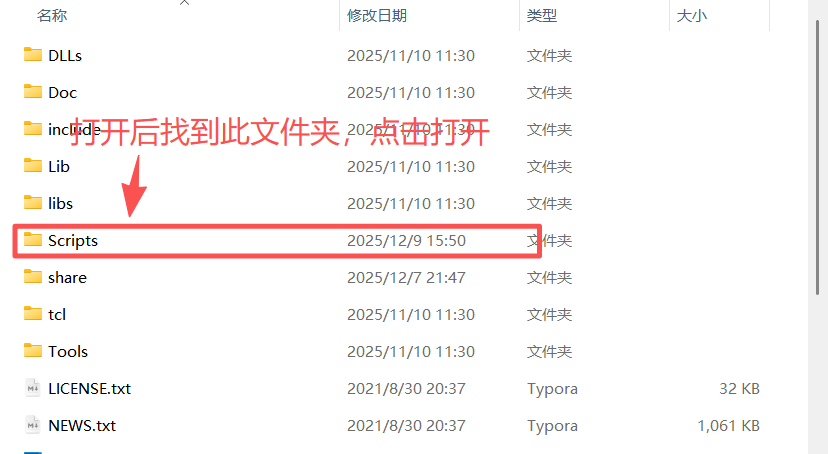
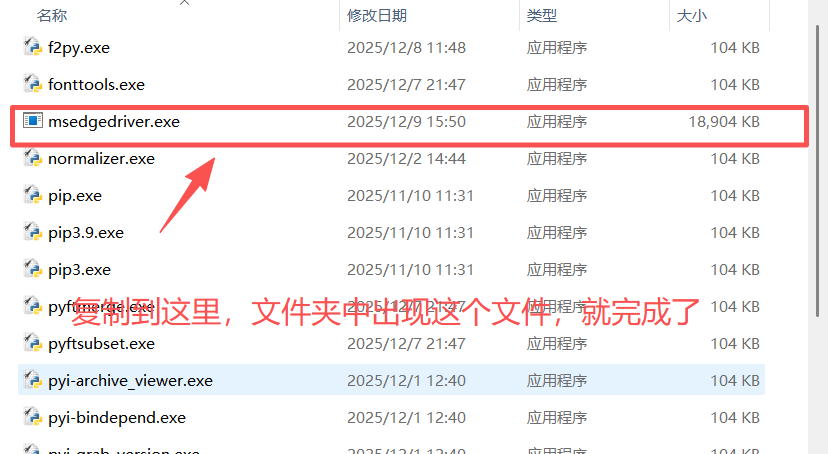
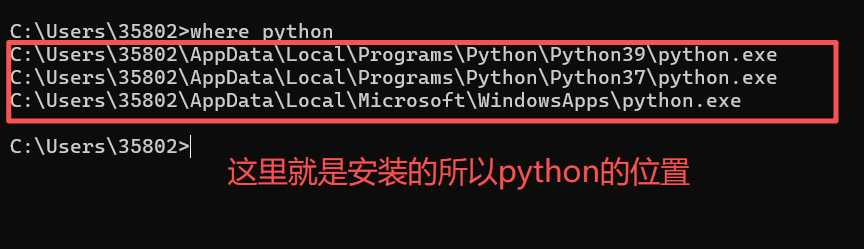
如果不知道自己的python安装到哪里了,可以在命令提示符中输入where python查看
chrome驱动下载地址:https://chromedriver.storage.googleapis.com/index.html
firefox驱动下载地址:https://github.com/mozilla/geckodriver/releases
2、安装selenium库
直接在命令提示符中输入pip install selenium==4.11.0即可

想要知道有没有安装好,可以pip list 查看一下
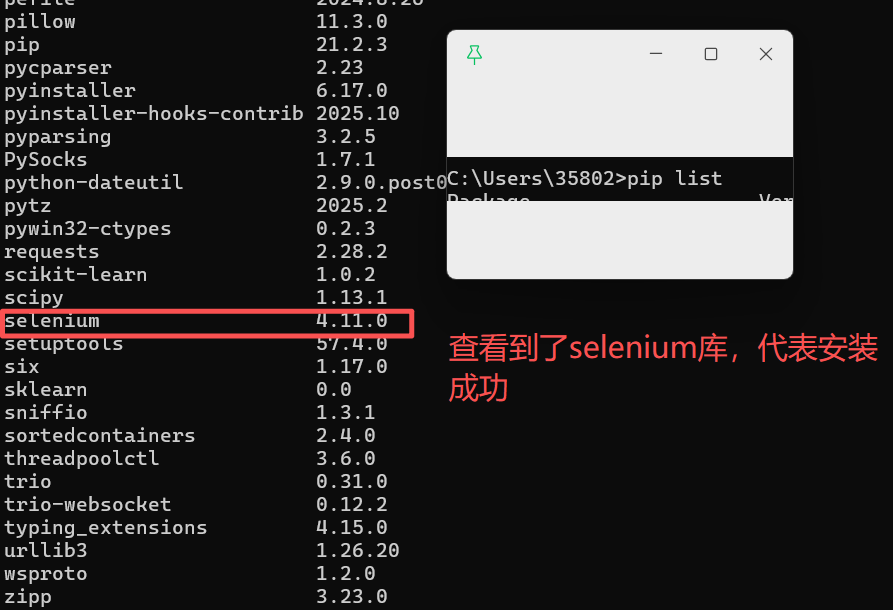
3、驱动浏览器
在selenium库源代码文件下的webdriver中查看所有支持的浏览器类型
webdriver.浏览器类型名()
浏览器类型名与前面下载的浏览器类型的文件夹名称想同,例如,我下载的是edge,所以使用webdriver.edge(),当要调用webdriver.edge()时,会默认调用文件中的类WebDriver,使用形式如下:
webdriver.edge(executable_path="edgedriver",port=0,options-None)
功能:创建一个新的edge浏览器驱动程序
参数executable_path:表示浏览器的驱动路径,默认为环境变量中的path,通常计算机可能存在多个浏览器软件,当没有在环境变量中设置浏览器path时,可以使用参数options
参数port:表明希望服务运行的端口,如果保留为0,驱动程序将会找到一个空闲端口
参数options:表示由类Options创建的对象,用于实现浏览器的绑定
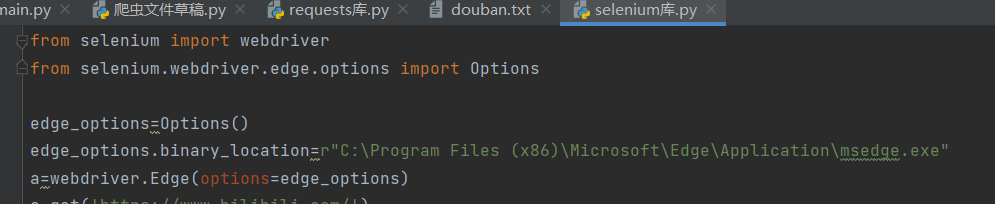
第三、四行使用类Options创建了一个对象edge_options,使用binary_location()方法绑定了浏览器
第五行使用webdriver.edge()设置options参数值为绑定edge浏览器的对象edge_options
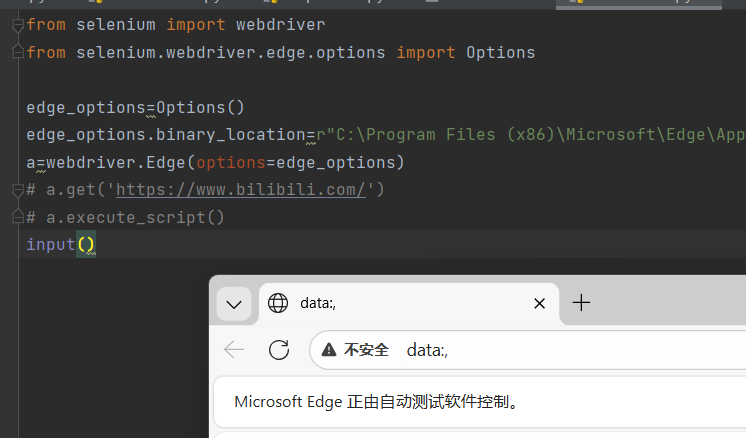
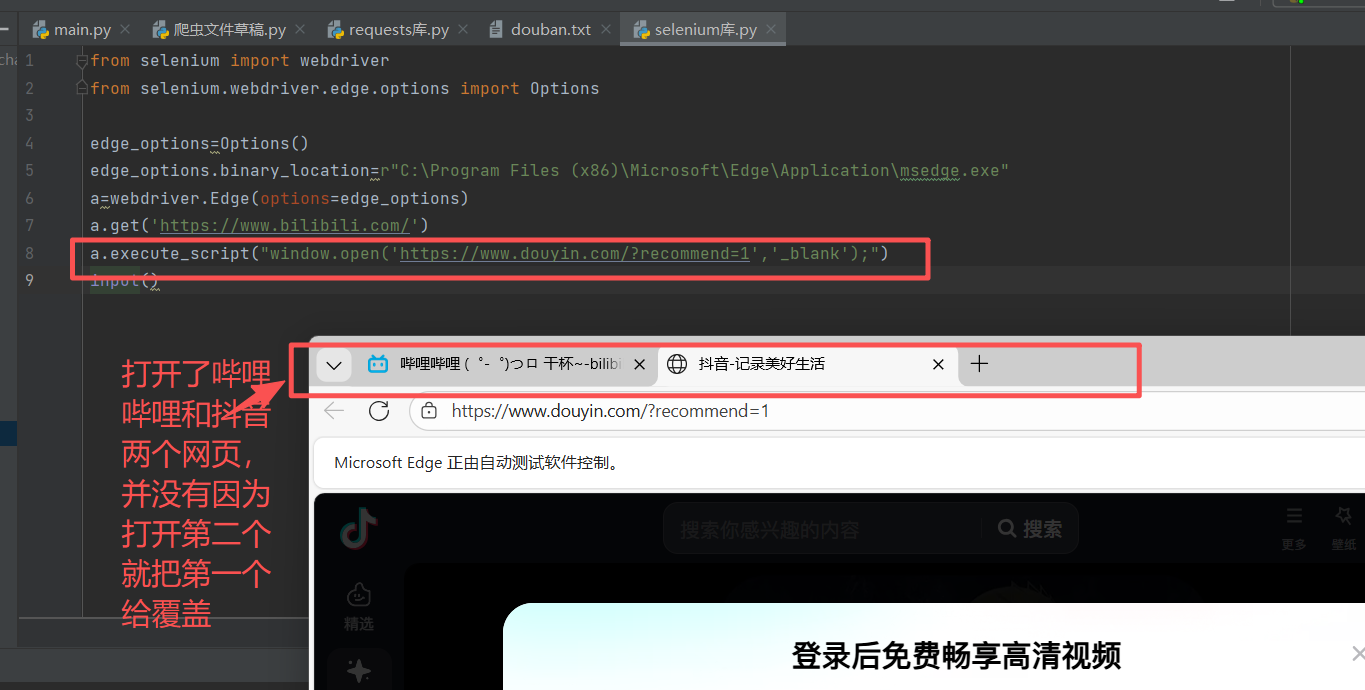
执行代码后会自动打开edge浏览器,但打开就会关闭,但如加个input()方法,由于一直没有输入信息,代码就会一直运行,网页就会一直存在
2、加载网页
1)get()方法
get()方法用于打开指定的网页,形式如下:
get(url)
功能:在当前浏览器会话中加载url指向的网页
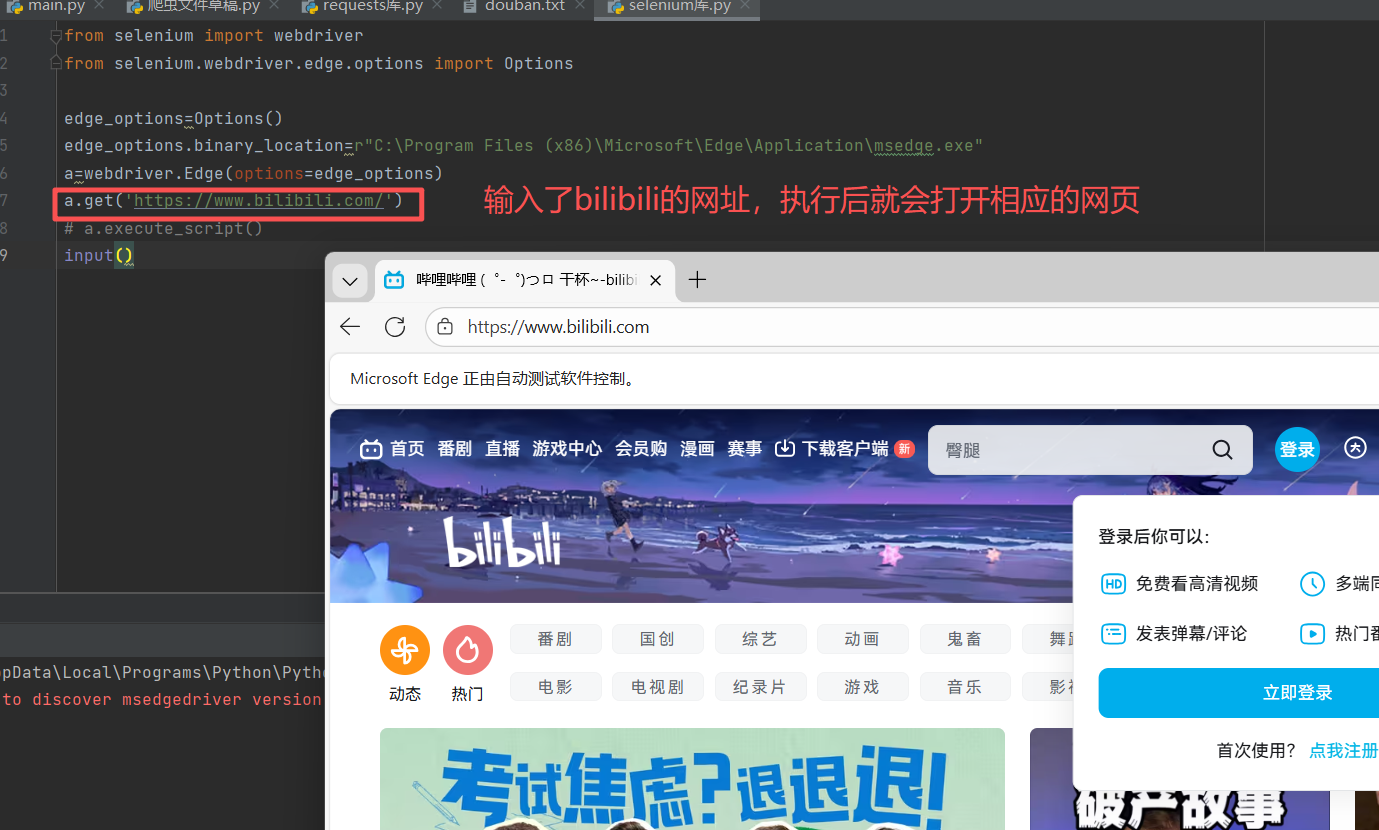
注:若使用多个get()方法,则最后只会保留最后一个get(),其他的都会被覆盖
2)execute_script(script,*args)
功能:打开标签页,同步执行当前页面中的JavaScript脚本。JavaScript是网页中的一种编程语言
参数script:表示将要执行的脚本内容,数据类型为字符串类型
二、requests库的使用
案例1
爬取**https://10wallpaper.com/List_wallpapers/page/1**网站中某一页或多页的图片,并把这些图片保存到zhaopian4.txt文件中
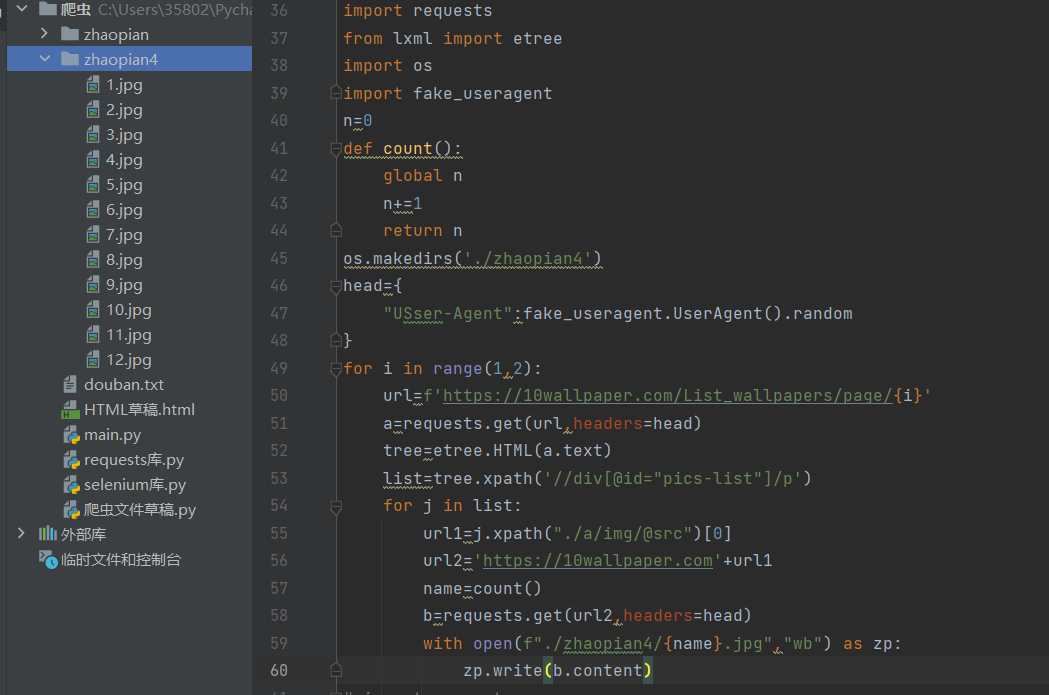
用到了四个库,分别是requests库、lxml库、os库、fake_useragent库,里面除了os库其他都是第三方库,所以都需要使用pip install 库名 进行下载,
代码中用到了for循环,因为通过网站每一页的网址,可以看到每一页的网址只有最后的一位数不同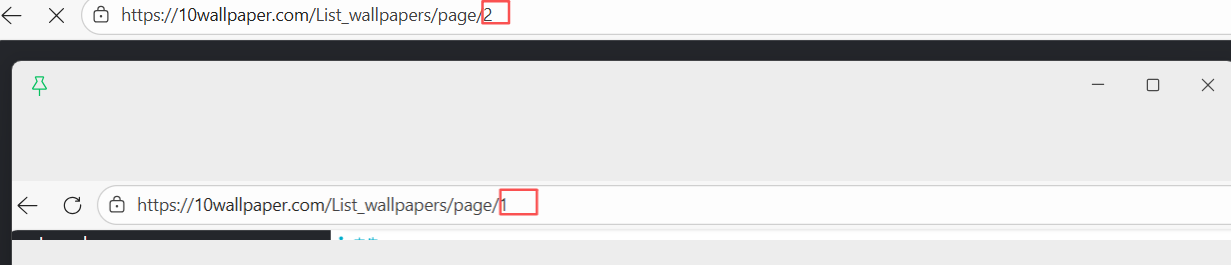
图中就是第一页和第二页的网址
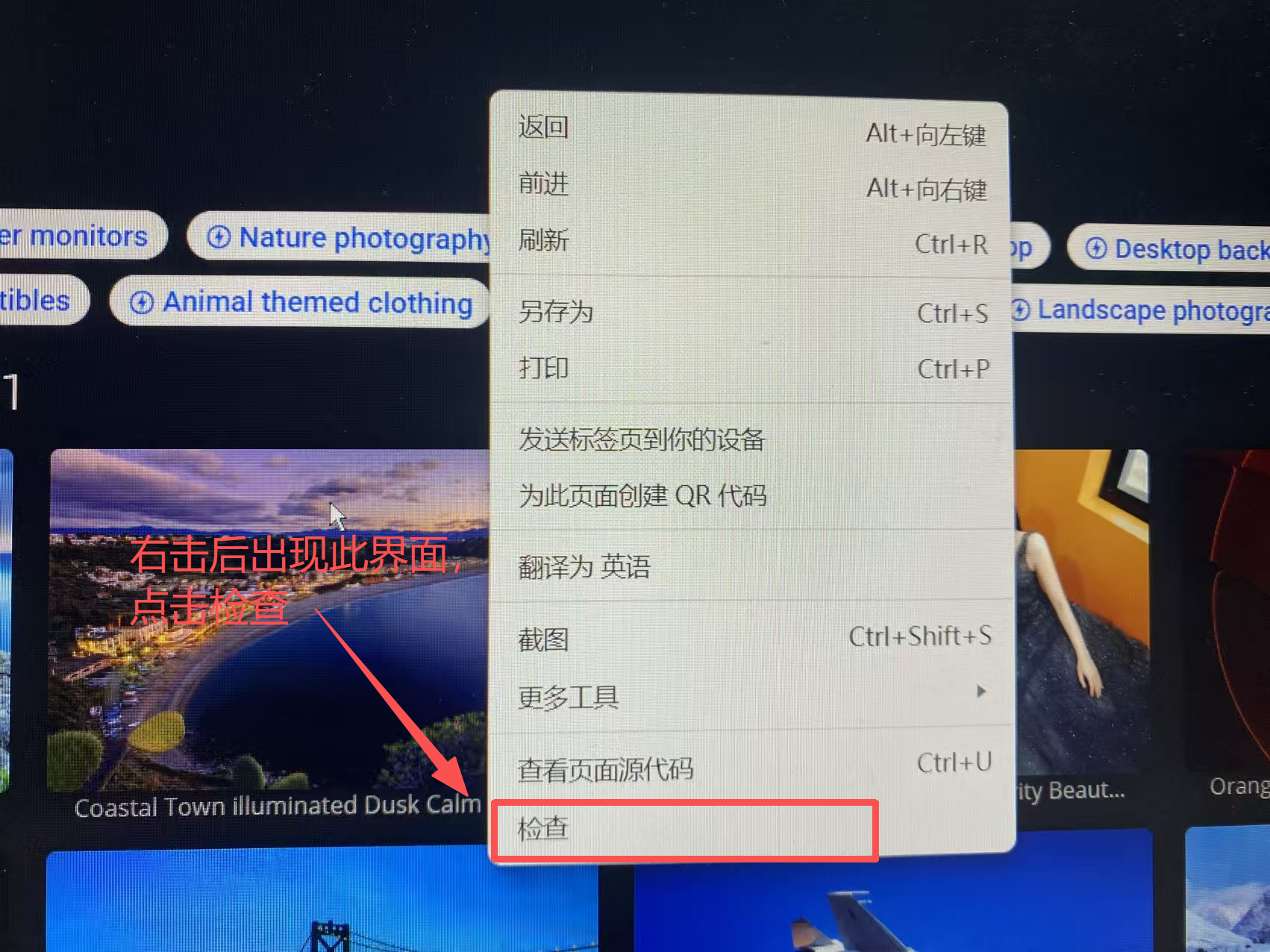
代码中的xpath中的信息都是想要获取的图片的网页源代码的信息,可以进行以下操作获得
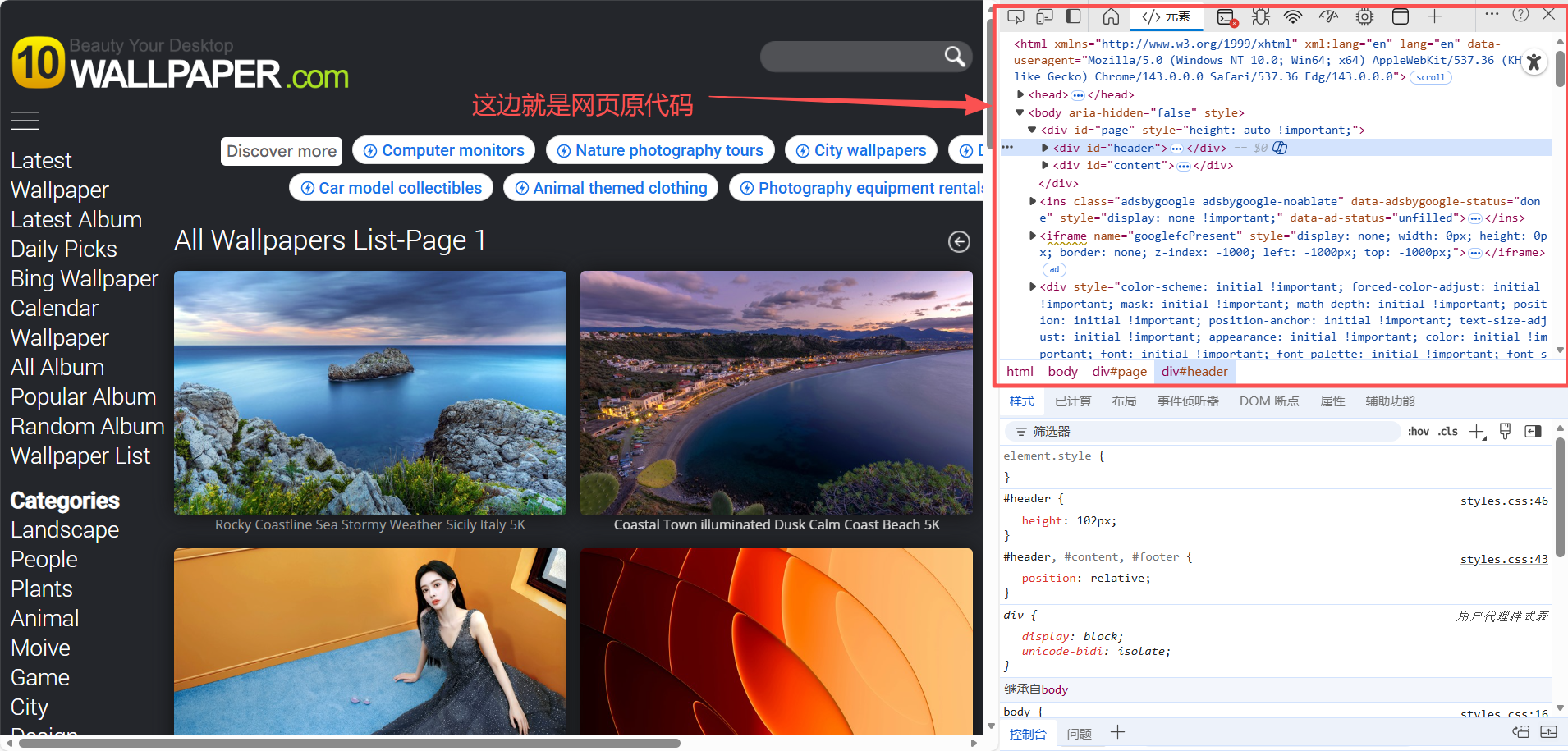
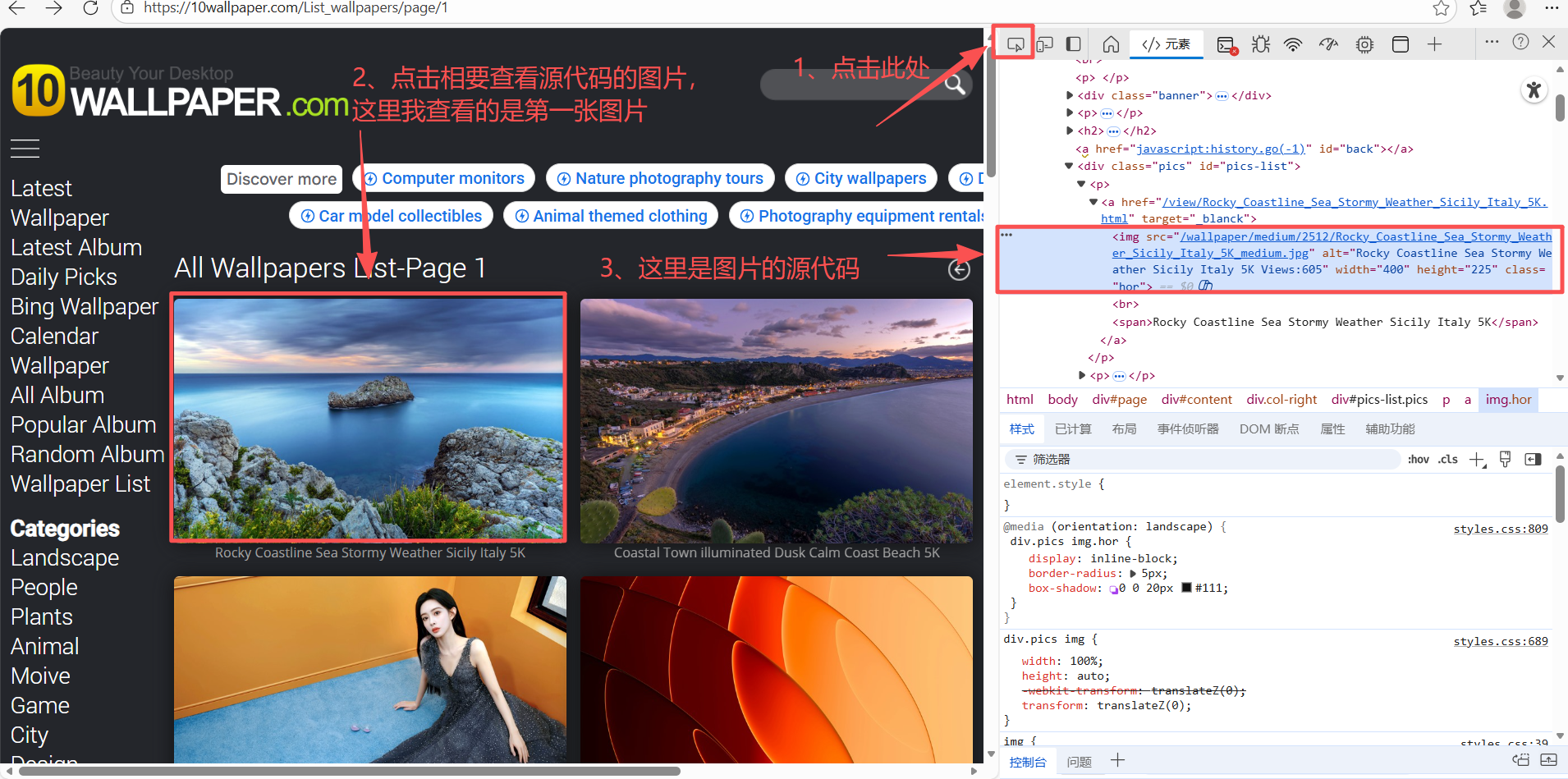
案例2
爬取**https://movie.douban.com/top250**一些电影相关信息,并把爬取到的信息存到douban.txt文件中
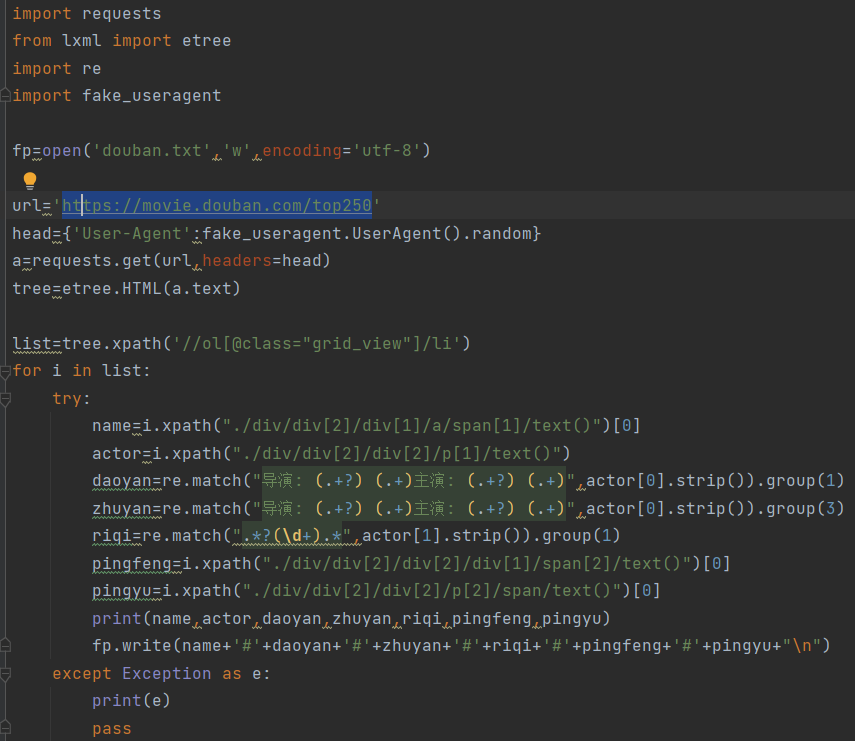
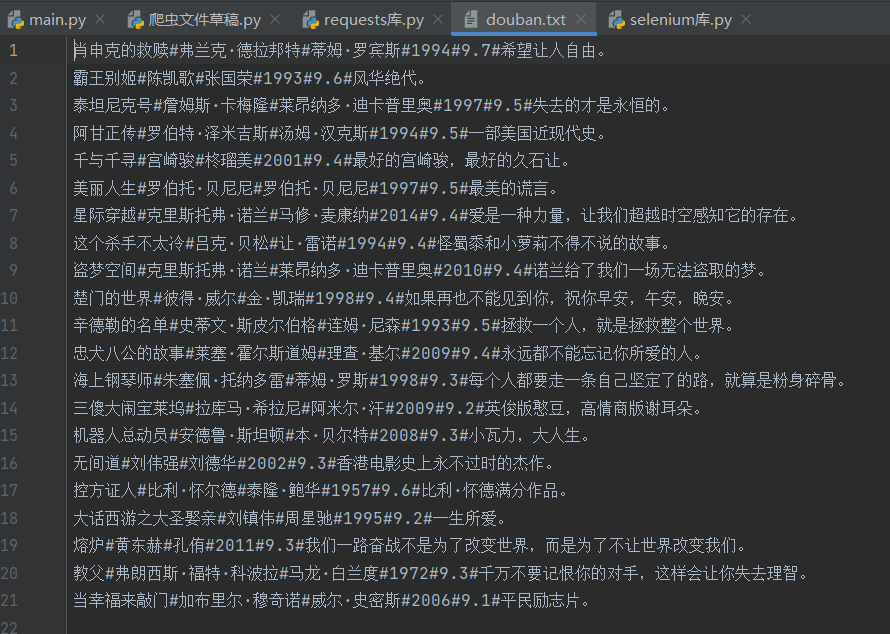
获取信息,以及代码编写方式和案例1差不多,就是这里用到了re库,来找对应的一些数据