Markdown-it 解析流程与架构分析
一、核心架构与解析流程(Mermaid 图 + 解析)
1. 整体架构与数据流向
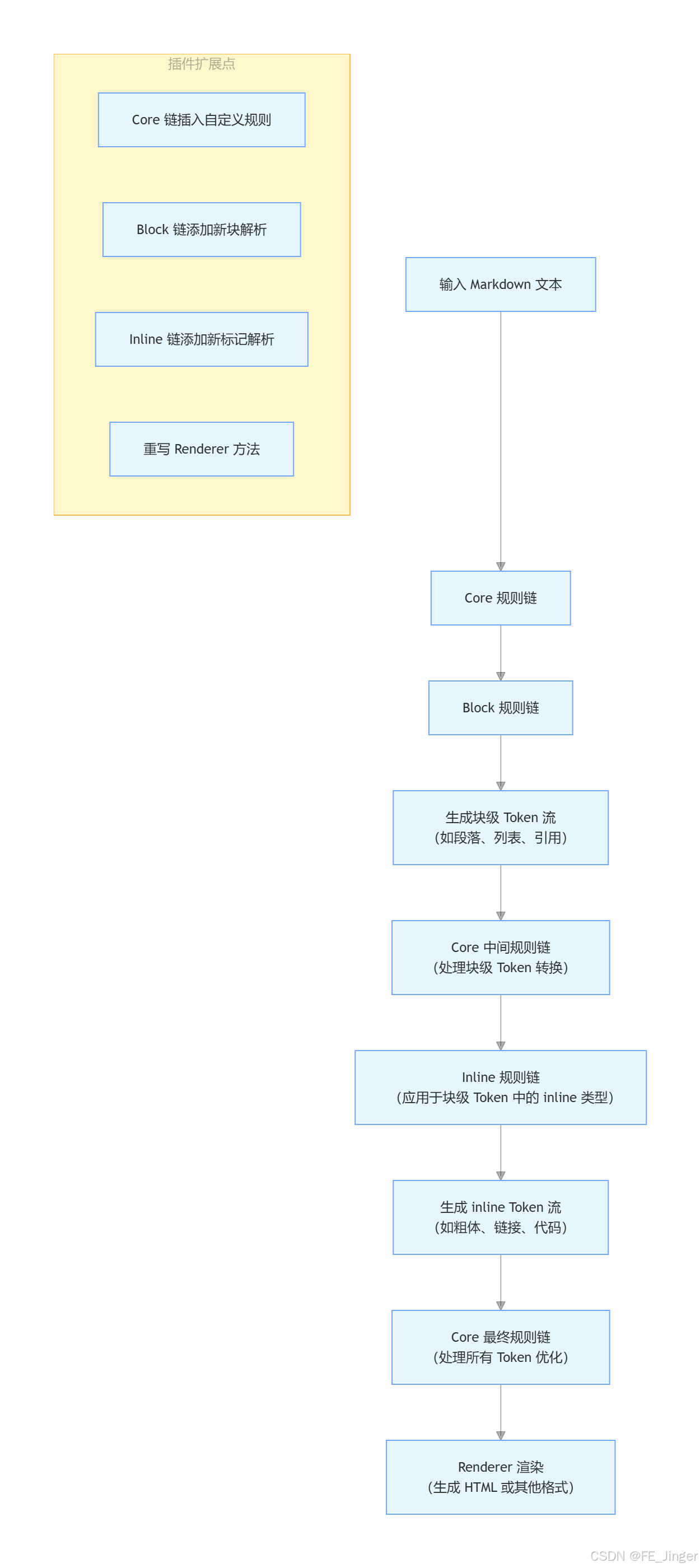
2. 解析流程详解
Markdown-it 的解析流程基于 三层嵌套规则链(Core/Block/Inline) 和 Token 流 实现,核心设计思想是"分阶段处理、规则解耦、可插拔扩展"。
-
Block 规则链 :负责解析块级结构(如段落、列表、块引用、标题)。
输入文本被按行消费,生成顶级 Token 流(如
paragraph_open/paragraph_close、list_open/list_close),每个块级 Token 可能标记为"inline 容器"(如段落需要进一步解析内部文本)。 -
Inline 规则链 :负责解析块级容器内的 inline 内容(如粗体、斜体、链接、代码块)。
仅作用于标记为"inline 类型"的块级 Token,解析其文本内容并生成嵌套的
childrenToken 流(如strong_open/strong_close、em_open/em_close)。 -
Core 规则链:贯穿整个流程的"胶水层",分为三个阶段:
- 前置阶段:预处理(如规范化输入);
- 中间阶段:Block 解析后、Inline 解析前处理块级 Token;
- 后置阶段:Inline 解析后优化 Token 流(如脚注、缩写处理)。
-
State 对象 :每个规则链(Core/Block/Inline)有独立的
state对象,存储当前解析状态(如位置、已生成的 Token、临时变量),确保各阶段解析独立,可随时禁用/启用。
二、插件化架构:如何通过规则链实现可插拔扩展
Markdown-it 的插件化核心是 规则管理机制(Ruler),允许开发者在任意规则链中插入、替换或移除规则。
- 规则(Rule) :是独立的函数,接收
state对象并修改 Token 流(如识别# 标题并生成heading_openToken)。 - Ruler :管理规则的容器,支持按名称启用/禁用规则(如
md.block.ruler.disable('heading')可关闭标题解析)。 - 扩展方式 :
- 新增 Block/Inline 规则:例如添加自定义块(如警告框)或 inline 标记(如
==高亮==); - 修改 Core 规则:在 Token 流生成后进行二次处理(如为链接添加
target="_blank"); - 重写 Renderer:自定义 Token 到 HTML 的转换逻辑(如将
heading渲染为自定义组件)。
- 新增 Block/Inline 规则:例如添加自定义块(如警告框)或 inline 标记(如
三、Token 流的高效处理
Markdown-it 没有采用传统 AST(抽象语法树),而是使用 轻量 Token 流,核心优势是"结构简单、处理高效"。
-
Token 结构:
- 块级 Token:顶级数组,包含
open/close成对标记(如blockquote_open和blockquote_close)和独立标记(如hr); - Inline Token:块级 Token 的
children属性,存储嵌套的 inline 标记(如strong_open→text→strong_close)。
- 块级 Token:顶级数组,包含
-
高效性原因:
- 线性数组结构:避免 AST 的树状遍历开销,适合流式处理;
- 读写分离:Block/Inline 解析阶段仅"写入"Token 流,后续处理(如插件)仅"读取或修改",无复杂状态依赖;
- 最小化冗余:Token 仅包含必要信息(如类型、属性、文本),体积远小于 AST。
四、嵌套与冲突处理(如 粗体 斜体 粗体)
Markdown-it 通过 两阶段 Inline 解析 和 分隔符栈(Delimiter Stack) 处理嵌套和语法冲突。
1. 两阶段 Inline 解析
- Tokenization 阶段 :识别所有 inline 标记(如
*、**、[),生成"分隔符 Token"(不处理匹配); - Post-processing 阶段:通过分隔符栈处理匹配,解决嵌套和冲突。
2. 分隔符栈(Delimiter Stack)工作机制
以 **粗体 *斜体* 粗体** 为例:
- Tokenization 阶段生成分隔符序列:
**→text(粗体 )→*→text(斜体)→*→text( 粗体)→**; - Post-processing 阶段:
- 遇到
**(strong 开始),入栈; - 遇到
*(em 开始),入栈(栈内现在有**、*); - 遇到
*(em 结束),与栈顶*匹配,生成em_open/em_close,弹出*; - 遇到
**(strong 结束),与栈内**匹配,生成strong_open/strong_close,弹出**; - 最终生成嵌套 Token:
strong_open→text(粗体 )→em_open→text(斜体)→em_close→text( 粗体)→strong_close。
- 遇到
3. 冲突处理原则
当语法冲突(如 [链接**粗体**])时,遵循以下规则(来自 CommonMark 规范):
- 优先级 :inline 代码块、链接、图片等"硬结构"优先级高于强调(如
[链接**粗体**]中,**被视为普通文本,因为链接的[和]已形成硬边界); - 最小嵌套 :优先形成最短匹配(如
***a***解析为strong包含em,而非em包含strong); - 左结合 :重叠标记时,左侧先匹配(如
*a _b* c_解析为em(a _b)+ 文本c_)。
总结:现代 Markdown 解析器的设计模式
- 分阶段解析:通过 Block/Inline/Core 规则链拆分复杂任务,降低耦合;
- 轻量数据结构:用 Token 流替代 AST,平衡灵活性与性能;
- 可插拔规则:基于 Ruler 实现规则的动态管理,支持高度定制;
- 上下文感知匹配:通过分隔符栈处理嵌套和冲突,确保语法解析的准确性。
这些设计使 Markdown-it 既能遵循 CommonMark 规范,又能通过插件轻松扩展(如支持数学公式、图表等),成为高性能且灵活的 Markdown 解析器典范。
Markdown-it 的插件化架构是其核心优势之一,通过灵活的规则管理机制和明确的扩展点,允许开发者轻松扩展语法解析能力或修改渲染行为。其具体实现方式可从 插件注册机制 、规则链扩展 、渲染器定制 三个核心维度展开说明,结合代码片段中的设计细节如下:
一、插件注册机制:use 方法与插件接口规范
Markdown-it 通过实例方法 use 统一管理插件注册,所有插件均通过该方法接入解析器,形成标准化的扩展入口。
1. use 方法的核心逻辑
解析器实例(markdown-it 类的实例)的 use 方法接收插件函数作为参数,并将实例本身及可选参数传递给插件,使插件能直接操作解析器内部结构。代码示例如下(来自 README.md 及相关片段):
javascript
import markdownit from 'markdown-it';
const md = markdownit()
.use(plugin1) // 加载插件1
.use(plugin2, opts) // 加载插件2并传递配置
.use(plugin3); // 加载插件3- 插件函数的标准接口为:
(md, opts, ...args) => void,其中md是解析器实例,opts是插件配置。 - 插件无需将
markdown-it作为依赖(来自docs/development.md),而是通过md实例访问内部 API(如规则链、渲染器等),避免版本冲突。
二、规则链扩展:基于 Ruler 的可插拔规则管理
Markdown-it 的解析流程依赖 三层规则链(Core/Block/Inline) ,每层规则链由 Ruler 实例管理。插件通过操作 Ruler 实现规则的添加、修改或移除,从而扩展解析能力。
1. Ruler 核心功能
Ruler 是规则的容器,提供了丰富的 API 用于管理规则的顺序和启用状态,核心方法包括:
push(name, fn):添加新规则到链尾;before(existingName, name, fn):在指定规则前插入新规则;after(existingName, name, fn):在指定规则后插入新规则;disable(names):禁用一个或多个规则;enable(names):启用一个或多个规则。
这些方法允许插件精细控制规则执行顺序,避免冲突(例如确保自定义语法解析在内置规则之前/之后执行)。
2. 扩展点:三层规则链的具体接入方式
插件可针对不同解析阶段(块级、行内、全局)扩展规则,对应三个核心 Ruler 实例:
| 规则链类型 | 管理实例 | 作用范围 | 示例插件场景 |
|---|---|---|---|
| Block | md.block.ruler |
解析块级元素(段落、列表、引用等) | 添加自定义块(如警告框 ::: warning) |
| Inline | md.inline.ruler |
解析行内元素(粗体、链接、代码等) | 添加新标记(如 ==高亮==) |
| Core | md.core.ruler |
全局解析流程(预处理、后处理等) | 处理脚注、缩写等跨阶段逻辑 |
示例:添加行内规则(如 markdown-it-mark 插件)
markdown-it-mark 插件通过 md.inline.ruler 添加规则,解析 == 标记为 <mark> 标签:
javascript
// 插件核心逻辑(简化)
function markPlugin(md) {
// 在 "emphasis" 规则前插入 "mark" 规则,确保优先级
md.inline.ruler.before('emphasis', 'mark', function (state, silent) {
// 匹配 ==...== 语法
if (state.src.charCodeAt(state.pos) !== 0x3D /* = */) return false;
// 生成 mark_open/mark_close Token
// ...(省略匹配和Token生成逻辑)
return true;
});
// 同时扩展渲染器,定义 mark 类型 Token 的 HTML 输出
md.renderer.rules.mark_open = () => '<mark>';
md.renderer.rules.mark_close = () => '</mark>';
}三、渲染器定制:重写 Token 到 HTML 的转换逻辑
除了解析规则,插件还可通过修改 Renderer 定制 Token 的渲染行为(如修改标签样式、添加属性等),无需触碰解析逻辑。
1. Renderer 的规则映射
Renderer 通过 md.renderer.rules 对象管理 Token 渲染逻辑,该对象以 Token 类型为键,对应的值为渲染函数。例如:
md.renderer.rules.strong_open控制<strong>标签的输出;md.renderer.rules.link_open控制链接标签的输出。
插件可直接重写这些函数,示例如下(来自 docs/development.md 建议):
javascript
// 插件:为所有链接添加 target="_blank"
function linkTargetPlugin(md) {
const defaultLinkOpen = md.renderer.rules.link_open || function (tokens, idx, options, env, self) {
return self.renderToken(tokens, idx, options);
};
// 重写 link_open 渲染规则
md.renderer.rules.link_open = function (tokens, idx, options, env, self) {
tokens[idx].attrPush(['target', '_blank']); // 添加属性
return defaultLinkOpen(tokens, idx, options, env, self); // 调用默认逻辑
};
}2. 非侵入式扩展
Renderer 的设计允许插件在不破坏原有逻辑的前提下扩展功能(如上述示例中保留默认渲染并添加新属性),符合"开放-封闭原则"。
四、插件开发的最佳实践(来自 docs/development.md)
-
选择合适的扩展点:
- 若无需新增语法(仅处理现有 Token),优先修改 Core 规则链或 Renderer(更简单);
- 若需新增语法,根据是块级还是行内元素,分别扩展 Block 或 Inline 规则链(性能更优)。
-
避免冲突:
- 通过
before/after明确规则优先级(如确保自定义标记解析在粗体/斜体之前); - 遵循 CommonMark 规范,避免破坏现有语法解析(如不随意覆盖核心规则)。
- 通过
-
复用现有逻辑 :
优先参考现有插件(如
markdown-it-ins、markdown-it-footnote)或内置规则的实现,避免重复开发。
总结:插件化架构的核心设计思想
Markdown-it 的插件化架构通过 "规则链解耦 + 标准化扩展点 + 轻量 Token 流" 实现高灵活性:
- 规则链(Block/Inline/Core)将解析流程拆分为独立阶段,插件可按需接入;
Ruler机制允许精确控制规则顺序和启用状态,解决冲突;- Renderer 提供 Token 渲染的定制入口,覆盖从解析到输出的全流程。
这种设计使 Markdown-it 既能严格遵循 CommonMark 规范,又能通过插件轻松扩展(如支持数学公式、图表等),成为生态最丰富的 Markdown 解析器之一。
确保 Markdown-it 插件之间的兼容性,核心是解决 规则冲突、Token 污染、状态干扰、渲染覆盖 四大问题。其本质是让多个插件在"共享解析流程(规则链/Token 流/Renderer)"的同时,保持各自的独立性和可组合性。以下结合 Markdown-it 的架构设计,从 冲突场景、解决方案、最佳实践 三方面详细说明:
一、插件兼容性的核心冲突场景
在多插件共存时,常见冲突源于:
- 规则链优先级冲突:两个插件扩展同一规则链(如 Inline),规则执行顺序不当导致语法解析异常(如 A 插件的标记被 B 插件误匹配);
- Token 命名冲突 :不同插件定义同名 Token 类型(如都用
custom),导致渲染逻辑混淆; - Renderer 规则覆盖 :多个插件重写同一 Token 的渲染函数(如
link_open),后加载的插件覆盖前一个,导致部分功能失效; - State 状态污染 :插件修改解析器的
State对象(如全局属性、临时变量),未清理导致后续插件解析出错; - 语法规范冲突 :插件自定义语法与 CommonMark 规范或其他插件语法重叠(如 A 插件用
:::表示警告框,B 插件用:::表示代码块)。
二、确保兼容性的具体实现方法
1. 规则链冲突:用 Ruler API 明确规则优先级
Markdown-it 的 Ruler 实例(md.block.ruler/md.inline.ruler/md.core.ruler)提供了精确控制规则顺序的能力,这是解决规则冲突的核心手段。
关键操作:
-
避免"盲插"规则 :不使用
push(默认插入链尾),而是用before(existingRuleName, newRuleName, fn)或after(existingRuleName, newRuleName, fn),将自定义规则锚定到内置规则或其他插件的规则上,明确执行顺序。-
示例:
markdown-it-mark插件需在"强调(emphasis)"规则前解析==标记,避免被*/**误匹配:javascript// 正确:锚定到内置 "emphasis" 规则前 md.inline.ruler.before('emphasis', 'mark', markRuleFn); // 错误:直接 push 可能导致顺序混乱 md.inline.ruler.push('mark', markRuleFn); // 若其他插件也 push,顺序不可控
-
-
禁用冲突规则 :若两个插件功能重叠(如都解析表格),可通过
ruler.disable(ruleName)禁用其中一个的规则,避免重复解析:javascript// 禁用插件 A 的表格规则,使用插件 B 的增强表格 md.block.ruler.disable('table_plugin_a'); -
规则命名规范 :自定义规则名添加插件前缀(如
my-plugin-highlight),避免与内置规则(如emphasis、link)或其他插件规则重名。
内置规则名参考(锚定的核心依据):
- Block 规则链:
paragraph、heading、list、blockquote、fence(代码块); - Inline 规则链:
link、image、emphasis(粗体/斜体)、code、html_inline; - Core 规则链:
normalize(预处理)、replacements(替换)、smartquotes(智能引号)。
2. Token 冲突:使用命名空间隔离 Token 类型
Token 是解析流程的"数据载体",插件自定义的 Token 类型(如 mark_open、warning_block)需避免与内置 Token 或其他插件的 Token 重名。
解决方案:
- Token 类型加插件前缀 :自定义 Token 命名格式为
[插件名]-[功能],例如:- 插件
markdown-it-warning定义 Token:warning_open/warning_close(而非alert_open); - 插件
markdown-it-highlight定义 Token:highlight_open/highlight_close(而非mark_open,避免与markdown-it-mark冲突)。
- 插件
- 避免修改内置 Token 属性 :不直接修改内置 Token 的
tag、attrs等属性(如强行给link_open加class),而是通过 Renderer 规则扩展(见下文 3),避免污染原生 Token 结构。
示例:安全定义自定义 Token
javascript
// 插件 my-plugin-alert:定义带前缀的 Token
function alertPlugin(md) {
md.block.ruler.before('paragraph', 'my-plugin-alert', function (state) {
const startPos = state.pos;
// 匹配 ::alert 语法
if (state.src.slice(startPos, startPos + 7) === '::alert') {
// 生成带插件前缀的 Token
const token = state.push('my-plugin-alert_open', 'div', 1);
token.attrs = [['class', 'my-alert']];
// ... 后续解析逻辑
return true;
}
return false;
});
// 渲染时也使用带前缀的 Token 名
md.renderer.rules['my-plugin-alert_open'] = () => '<div class="my-alert">';
md.renderer.rules['my-plugin-alert_close'] = () => '</div>';
}3. Renderer 冲突:包装默认渲染逻辑,避免直接覆盖
多个插件可能重写同一 Token 的渲染函数(如 link_open、strong_open),直接赋值会导致"后加载插件覆盖前插件"的问题。例如:
javascript
// 插件 A:给链接加 target="_blank"
md.renderer.rules.link_open = (tokens) => `<a target="_blank" href="${tokens[0].attrGet('href')}">`;
// 插件 B:给链接加 class="link"
md.renderer.rules.link_open = (tokens) => `<a class="link" href="${tokens[0].attrGet('href')}">`;
// 结果:插件 A 的 target 属性丢失,冲突!解决方案:"包装式"重写,保留原有逻辑
核心思路:先保存默认渲染函数(或前一个插件的渲染函数),再在新函数中调用,叠加自定义逻辑,而非直接替换。
javascript
// 插件 A:安全重写 link_open(保留默认逻辑)
function linkTargetPlugin(md) {
// 保存原有渲染函数(可能是内置默认值,或其他插件已重写的函数)
const originalLinkOpen = md.renderer.rules.link_open || function (tokens, idx, options, env, self) {
return self.renderToken(tokens, idx, options); // 内置默认渲染
};
// 包装原有逻辑,添加自定义属性
md.renderer.rules.link_open = function (tokens, idx, options, env, self) {
const token = tokens[idx];
// 新增属性(不覆盖已有属性)
token.attrPush(['target', '_blank']); // 而非直接修改 token.attrs
// 调用原有渲染函数,确保其他插件的逻辑不丢失
return originalLinkOpen(tokens, idx, options, env, self);
};
}
// 插件 B:同样用包装式重写,叠加 class
function linkClassPlugin(md) {
const originalLinkOpen = md.renderer.rules.link_open || function (tokens, idx, options, env, self) {
return self.renderToken(tokens, idx, options);
};
md.renderer.rules.link_open = function (tokens, idx, options, env, self) {
const token = tokens[idx];
token.attrPush(['class', 'link']);
return originalLinkOpen(tokens, idx, options, env, self);
};
}
// 最终效果:链接同时有 target="_blank" 和 class="link",无冲突关键原则:
- 始终先获取
md.renderer.rules[tokenType]的当前值(可能已被其他插件修改); - 用
token.attrPush(添加属性)而非直接赋值token.attrs(覆盖属性); - 调用原有渲染函数,确保渲染逻辑的"叠加性"而非"替换性"。
4. State 状态污染:仅使用公共 API,隔离临时状态
State 对象是解析过程的"上下文载体",存储了当前解析位置、Token 流、临时变量等信息。插件若不当修改 State,会导致后续插件解析出错(如篡改 state.pos、新增全局属性未清理)。
安全操作 State 的规范:
-
仅使用公共 API :
State的公共方法/属性包括:- 读取:
state.src(输入文本)、state.pos(当前位置)、state.tokens(Token 流); - 写入:
state.push(tokenType, tag, nesting)(生成 Token)、state.setPos(newPos)(更新位置)、state.skip(n)(跳过字符);
- 读取:
-
不修改私有属性 :避免操作
state.__proto__、state._tmp(内置临时对象)等下划线开头的属性; -
临时状态隔离 :若需存储临时数据(如解析过程中的中间结果),使用
state.temp(Markdown-it 预留的临时对象),并在插件逻辑结束后清理,避免残留:javascriptfunction myPlugin(md) { md.inline.ruler.before('emphasis', 'my-plugin', function (state) { // 存储临时数据到 state.temp,添加插件前缀 state.temp['my-plugin-tmp'] = '临时数据'; // ... 解析逻辑 // 结束后清理临时数据 delete state.temp['my-plugin-tmp']; return true; }); } -
不跨阶段修改 State :Block 规则仅操作
md.block.state,Inline 规则仅操作md.inline.state,避免在 Block 阶段修改 Inline 相关的 State 属性。
5. 语法规范冲突:遵循 CommonMark,明确语法边界
当插件自定义语法与其他插件或 CommonMark 规范冲突时(如 ::: 同时被多个插件用作标记),需通过"语法优先级"和"边界限制"解决。
解决方案:
-
遵循 CommonMark 优先级 :CommonMark 定义了语法优先级(从高到低):代码块 > 链接/图片 > 强调(粗体/斜体)> 普通文本。插件自定义语法需避让高优先级语法,例如:
- 不使用 ````` 作为自定义标记(代码块优先级最高,会导致插件语法被误解析为代码);
- 自定义标记长度≥2(如
==、:::),避免与单个字符的内置标记(如*、_)冲突。
-
明确语法边界 :自定义语法需有清晰的开始/结束标记,且不可嵌套高优先级语法。例如:
- 警告框插件用
:::warning开始、:::结束,且内部不允许嵌套代码块(若需支持,需在插件内显式处理代码块解析);
- 警告框插件用
-
提供语法开关 :插件允许用户通过配置禁用冲突语法,例如:
javascript// 插件支持关闭默认标记,避免与其他插件冲突 function myPlugin(md, opts = {}) { const mark = opts.mark || '=='; // 默认标记,允许用户修改 // ... 解析逻辑使用 opts.mark 而非硬编码 }
三、插件兼容性的最佳实践
1. 插件开发侧:从源头避免冲突
- 声明依赖与兼容性 :在
package.json中明确peerDependencies(如markdown-it: ^13.0.0),说明支持的 Markdown-it 版本; - 提供配置选项 :允许用户自定义关键参数(如标记符号、规则优先级、Token 类名),例如
markdown-it-container允许用户指定容器标记; - 参考官方插件模板 :遵循
markdown-it官方推荐的插件结构(如markdown-it-sub、markdown-it-footnote),优先使用公共 API,不依赖内部实现; - 编写兼容性测试 :测试用例包含"单插件运行"和"多插件共存"场景(如与
markdown-it-mark、markdown-it-link-attributes同时加载)。
2. 用户使用侧:合理配置插件
-
控制加载顺序 :功能相关的插件,按"先基础后增强"的顺序加载(如先加载
markdown-it-link-attributes,再加载markdown-it-target-blank); -
禁用冲突规则 :通过
md.[chain].ruler.disable(ruleName)禁用重复或冲突的规则; -
使用调试工具 :开启 Markdown-it 的 debug 模式,查看 Token 流和规则执行顺序,定位冲突来源:
javascriptconst md = markdownit({ debug: true }); // 打印解析过程日志
四、总结:兼容性的核心原则
Markdown-it 插件兼容性的本质是 "隔离性"和"可组合性",其实现依赖于:
- 规则链的优先级可控 :通过
Ruler的before/after明确规则顺序,避免解析冲突; - Token 的命名空间隔离:自定义 Token 加插件前缀,避免命名冲突;
- Renderer 的包装式扩展:保留原有渲染逻辑,实现功能叠加而非替换;
- State 的安全操作:仅使用公共 API,隔离临时状态,不污染上下文;
- 语法的规范遵循:避让高优先级语法,提供灵活配置。
遵循这些原则,即可让多个插件在 Markdown-it 中"和平共存",同时保持解析流程的高效性和稳定性。