FPGA教程系列-Vivado Aurora 8B/10B 协议解析
简介
Aurora 8B/10B 协议是一种可扩展的轻量级链路层协议,可用于在一条或多条高速串行通道上进行点对点数据传输。
该协议本身独立于上层协议,既能承载以太网、TCP/IP 等标准协议,也能承载专有协议,从而让下一代通信与计算系统的设计者在保留现有软件投入的同时,获得更高的互连性能。虽然主要面向芯片间和板间应用,但只要增加标准的光接口组件,Aurora 8B/10B 协议也可用于机箱间的互连。
《Aurora 8B/10B 协议规范》定义了以下内容:
- 物理层接口:包括电气电平、时钟编码与符号编码。
- 初始化与差错处理:规定了在单通道和多通道场景下,通信双方为建立链路所需执行的步骤,并描述了当信道出现比特错误时双方应采取的应对行为。
- 数据条带化:说明数据如何在多条串行通道组成的链路上进行映射。
- 链路层:描述用户协议数据单元(用户 PDU)在传输过程中如何标记起止,如何在数据流中插入暂停,以及如何处理收发双方时钟速率差异。
- 流量控制:Aurora 8B/10B 协议定义了链路层流量控制机制,并提供一种加速机制,用于转发更高层用户的流量控制报文。
Aurora 8B/10B 协议未对以下内容作出定义------假定这些功能由更高层协议负责:
- 差错检测与恢复:该协议未提供检测用户 PDU 差错的机制,也未规定除 8B/10B 编码本身以外的任何恢复手段。
- 数据交换:该协议未定义寻址方案,因此不支持链路层的复用或交换。
Aurora 8B/10B 协议描述了用户数据在 Aurora 8B/10B 通道上的传输方式。一条 Aurora 8B/10B 通道由一条或多条 Aurora 8B/10B 通道(lane)组成;每条 lane 都是一条全双工串行数据连接。在该通道上进行通信的设备称为"通道伙伴(channel partners)"。
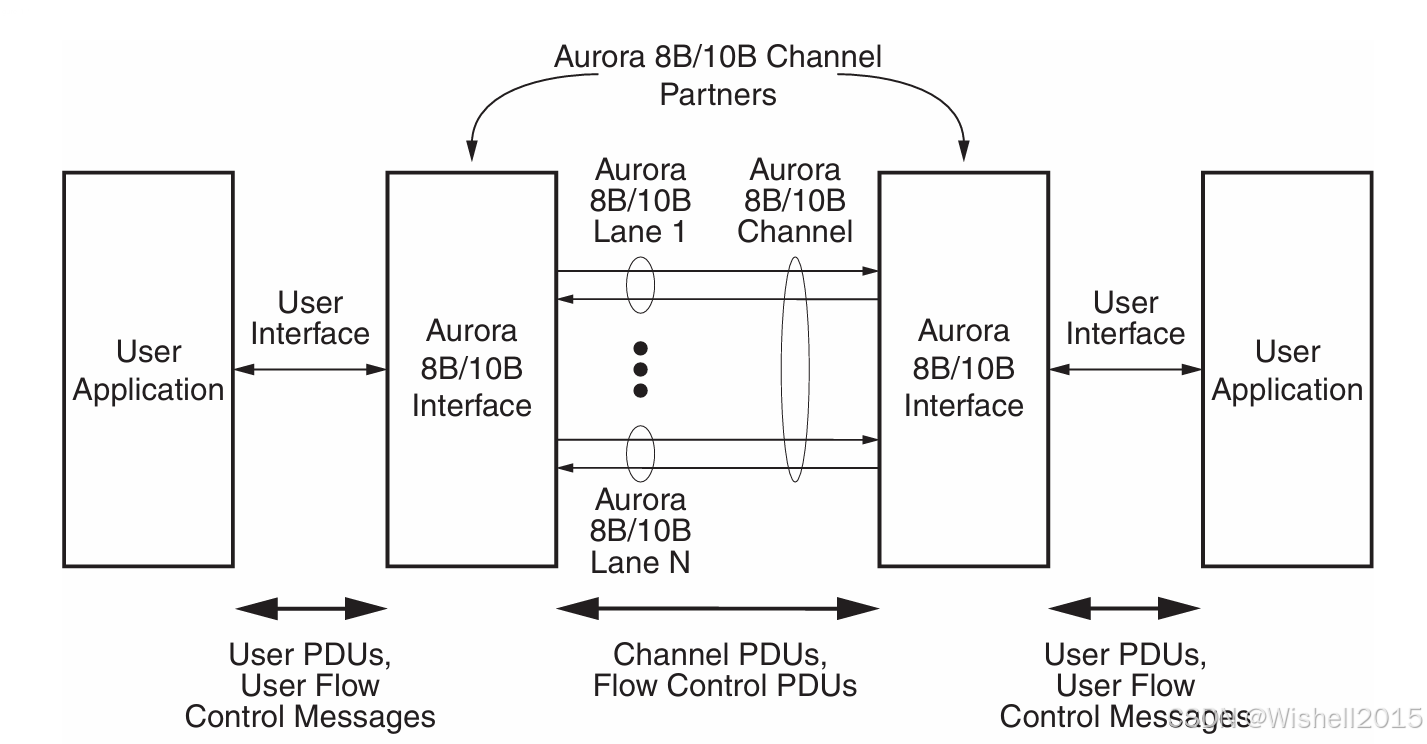
Aurora 8B/10B 协议通过"用户接口"与用户应用之间收发数据和控制信息,并未对该用户接口做出定义。
数据流包括:
- 在用户应用与 Aurora 8B/10B 接口之间传递用户 PDU 以及用户流量控制消息;
- 在 Aurora 8B/10B 通道上传输通道 PDU 和流量控制 PDU。
User Application(用户应用程序) :
- 位于图的最左侧和最右侧,代表用户自己的逻辑设计(例如在 FPGA 中的自定义逻辑)。
- 左侧 通常作为发送方(Source),生成数据;右侧作为接收方(Destination),处理数据(反之亦然,因为 Aurora 是全双工的)。
Aurora 8B/10B Interface(Aurora 8B/10B 接口/核心) :这是 Aurora 协议的核心逻辑模块(即 IP 核)。它的作用是将用户端的并行数据转换成适合在高速串行线路上传输的格式。负责执行协议中的内容,8B/10B 编码/解码、数据条带化(分发到多条 Lane)、时钟校正、流控等。
Channel Partners(通道伙伴) :"Aurora 8B/10B Channel Partners" 指的是通信链路两端的两个 Aurora 接口。它们互为"伙伴",必须配置相同的参数(如链路速率、位宽等)才能正常通信。
Aurora 8B/10B Channel(Aurora 通道) :两个接口之间的物理连接总称。
-
Lane 1 ... Lane N(多链路) :
- Lane(链路) :一对差分信号线(TX/RX),是物理传输的基本单位。
- 从 Lane 1 到 Lane N,意味着 Aurora 支持将多条物理链路捆绑在一起,逻辑上形成一个高带宽的大通道。
-
双向箭头 :表示数据是全双工传输的(可以同时发送和接收)。
数据的发送与接收
发送过程:
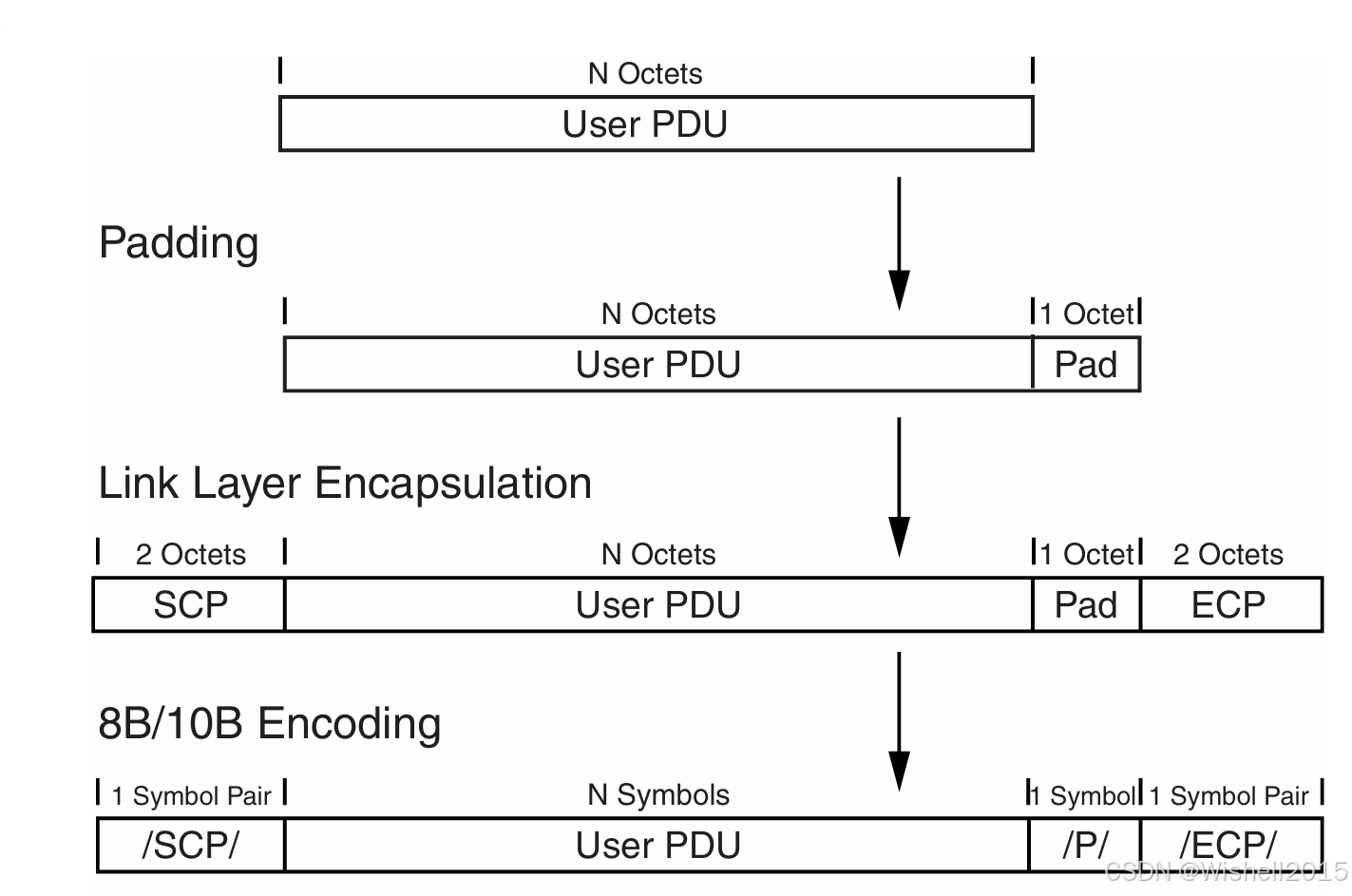
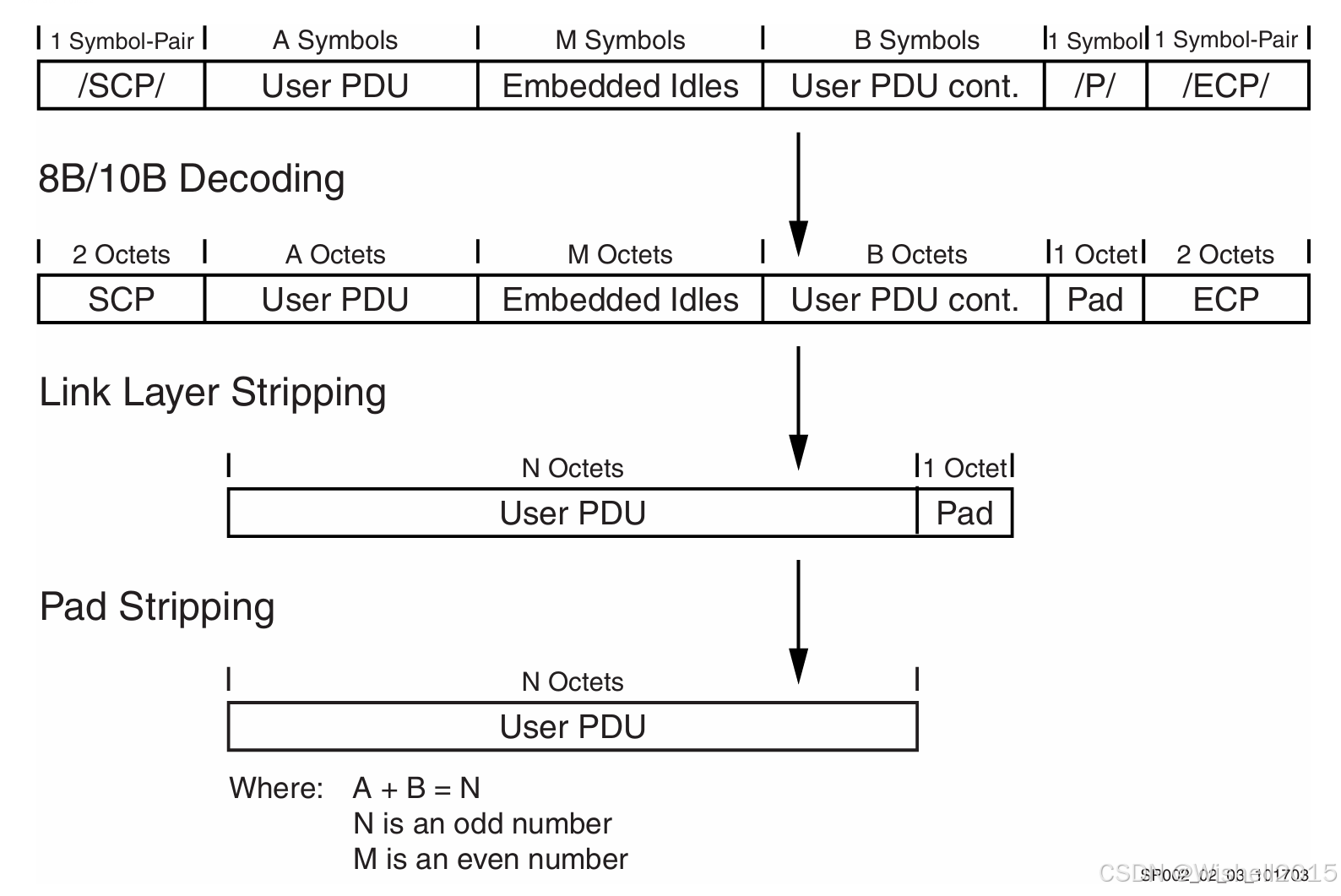
1、填充: Aurora 8B/10B 通道要求所有传输的符号数量必须为偶数。为满足这一条件,凡用户 PDU 字节数为奇数时,必须在末尾插入 1 个字节的填充,其值为 0x9C,并紧接在用户 PDU 之后。
2、链路层封装 :用户 PDU 需用称为"有序集合"的控制符号序列进行封装,形成完整的通道 PDU。这些有序集合在串行数据流中标示通道 PDU 的起止位置。
Aurora 8B/10B 协议使用
- /SCP/(/K28.2/K27.7/)有序集合标记通道 PDU 的开始;
- /ECP/(/K29.7/K30.7/)有序集合标记通道 PDU 的结束。
有序序列的详细定义:
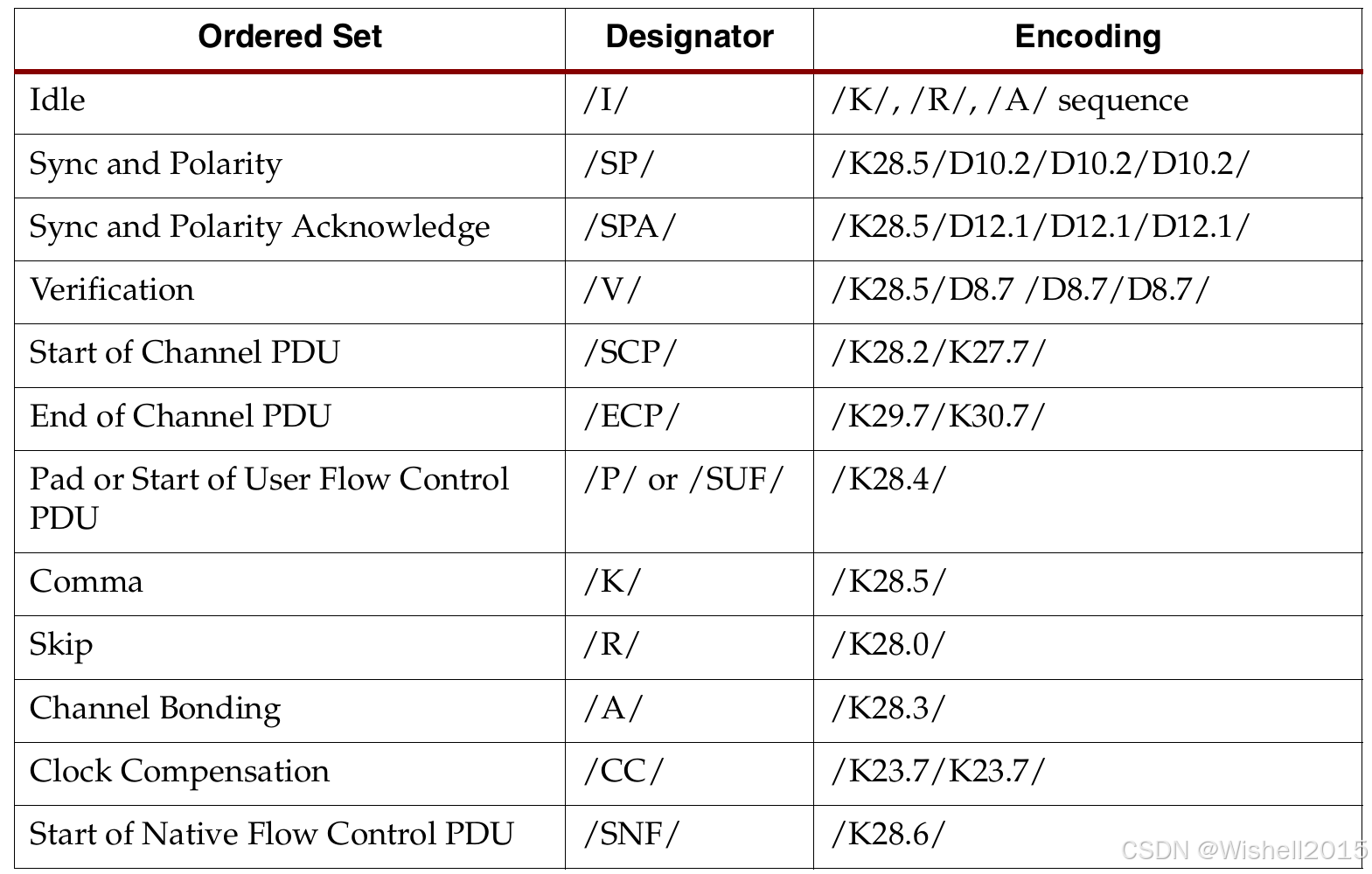
链路初始化与同步 (Link Initialization) :这部分用于连接刚刚建立时,双方"握手"并确认对方在线。
- Sync and Polarity (/SP/) : K28.5 + D10.2...:同步与极性校准。发送方告诉接收方:"我要开始建立连接了,请校准你的接收器。"
- Sync and Polarity Acknowledge (/SPA/) : K28.5 + D12.1...:同步确认。接收方收到 /SP/ 后回复这个信号,意思是:"我收到你的同步请求了,我准备好了。"
- Verification (/V/) : K28.5 + D8.7...:验证。通常用于测试模式,验证链路传输是否无误。
数据包定界 (Framing): 这部分用于告诉接收方数据包哪里开始,哪里结束。
- Start of Channel PDU (/SCP/) : /K28.2/K27.7/:用户数据包开始。PDU (Protocol Data Unit) 是协议数据单元。这标志着一段用户数据的开头。
- End of Channel PDU (/ECP/) : /K29.7/K30.7/:用户数据包结束。
- Start of Native Flow Control PDU (/SNF/) : /K28.6/:流控数据包开始。用于传输协议内部的控制信息(比如"暂停发送"指令),而不是用户数据。
时钟与对齐 (Clock & Alignment): 高速串行通信中,发送方和接收方的时钟频率可能会有微小差异,需要机制来补偿。
- Idle (/I/) : /K/, /R/, /A/ 序列:空闲。当没有数据需要发送时,链路上不能什么都不发(否则接收方以为断线了),必须一直发送 Idle 序列来维持连接活跃。
- Comma (/K/) : /K28.5/:逗号符。这是最重要的字符。它的二进制位模式在数据流中是独一无二的,接收方利用它来找到字节的边界(即从哪里开始切分 8 个 bit 为一个字节)。
- Skip (/R/) : /K28.0/:跳过/填充。用于时钟修正。如果接收方时钟比发送方快或慢,接收方可以通过丢弃或插入这个字符来调整缓冲区,防止数据溢出或下溢。
- Channel Bonding (/A/) : /K28.3/:通道绑定(对齐)。当使用多条物理线路(Lane)传输同一个逻辑信号时,由于线缆长度不同,数据到达时间有快慢。这个符号用于把所有通道的数据"对齐"。
- Clock Compensation (/CC/) : /K23.7/K23.7/:时钟补偿。与 Skip 类似,用于解决收发双方时钟频率不一致的问题。
其他:
- Pad or Start of User Flow Control PDU (/P/ or /SUF/) : /K28.4/:填充字符,或者用户流控包的开始。
3、8B/10B 编码: 完成填充后的数据结构称为"链路层载荷"。在发送前,物理编码子层(PCS)对其进行 8B/10B 编码。除填充字节外,所有字节均按数据符号编码;填充字节则编码为 /P/(/K28.4/)控制符号,以便接收端识别并剔除。编码的说明可以参考其他文章。
4、串行化与时钟编码: 通道 PDU 组装并编码完成后,即进行串行化以供发送。串行后的数据流以差分非归零(NRZ)格式在线路上传输。具体过程如下图:
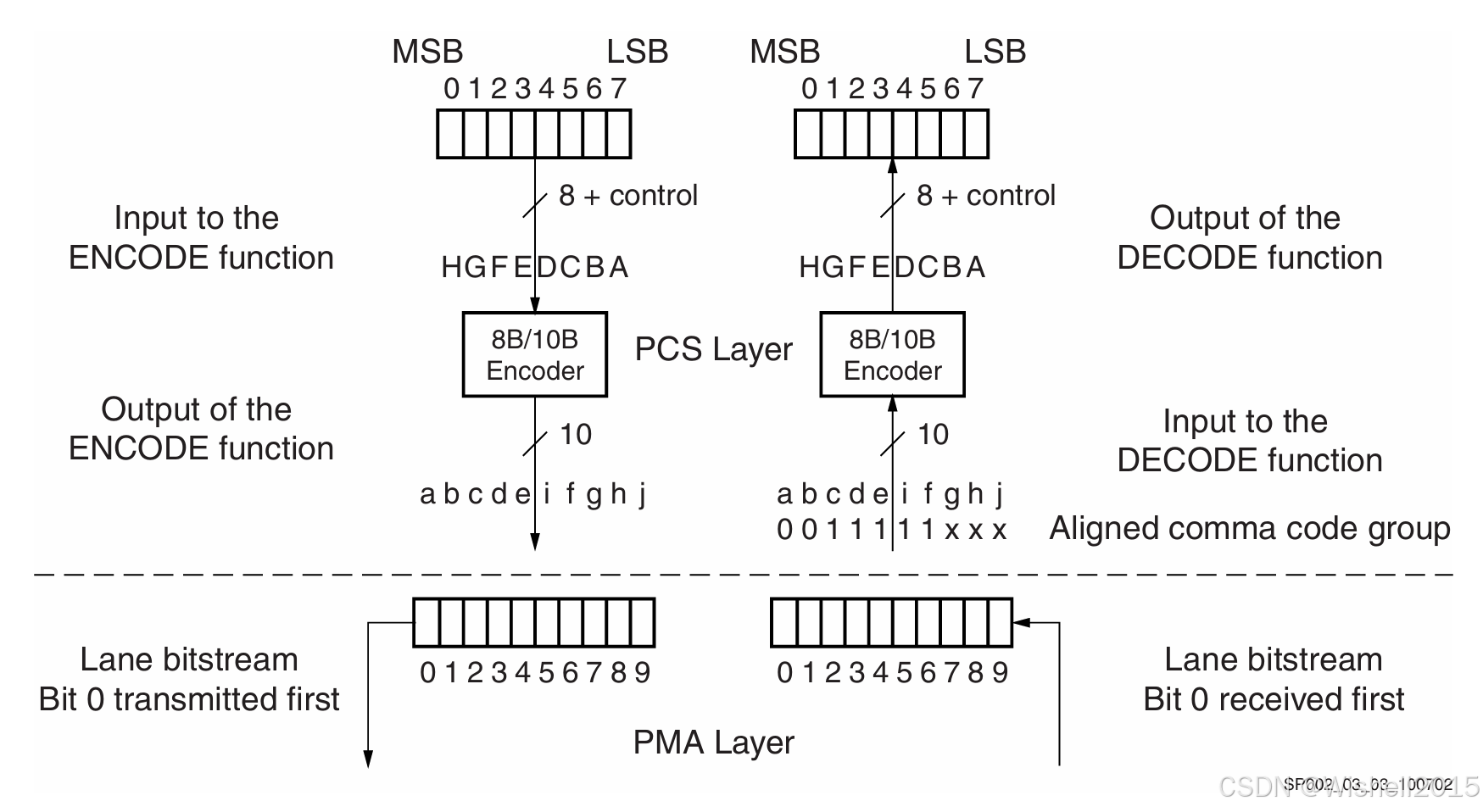
发送端流程:位序是关键 (The Transmit Process)
-
PCS 层编码(Encoder Output) :
- 当 8-bit 数据(HGFEDCBA)经过 8B/10B 编码器后,生成的 10-bit 代码组并不是随意排列的,文字明确规定了其内部命名为:
abcdei fghj。 - 注意顺序 :这里的顺序不是字母表的 aaa 到 jjj,而是 abcdeabcdeabcde 后面插了一个 iii,然后是 fghfghfgh,最后是 jjj。这是 8b/10b 标准算法中将数据分为 5b/6b(对应 abcdei)和 3b/4b(对应 fghj)两部分的体现。
- 当 8-bit 数据(HGFEDCBA)经过 8B/10B 编码器后,生成的 10-bit 代码组并不是随意排列的,文字明确规定了其内部命名为:
-
PMA 层串行化(Serialization) :发送顺序严格遵循 a→b→c→d→e→i→f→g→h→ja \rightarrow b \rightarrow c \rightarrow d \rightarrow e \rightarrow i \rightarrow f \rightarrow g \rightarrow h \rightarrow ja→b→c→d→e→i→f→g→h→j 的顺序进入物理线路。
层的物理界限 (Functional Separation)
- 虚线之上 (PCS Layer) :物理编码子层 。这里处理的是逻辑上的 10-bit 代码组 (Code Groups) 。在这里,数据还是并行存在的,是逻辑符号。
- 虚线之下 (PMA Layer) :物理介质适配层 。这里处理的是物理上的 比特流 (Bitstream) 。它的工作是将逻辑符号转换成可以在电缆上高速传输的电信号序列。
接收端与同步机制 (Receive Side & Synchronization)
- Comma Pattern (逗号模式) :在 8b/10b 编码中,
0011111(或反相的1100000)这种连续 5 个 1 或 5 个 0 的情况,在正常的"数据"中是绝对不会跨字节出现的。 - 边界同步 (Code-boundary Synchronization) :接收器收到的是源源不断的水流(比特流),没有任何分隔符。接收器一直在"盯着"看,一旦它在流中发现了
0011111这一串独特的指纹,它就立刻知道:"啊!这里是一个 10-bit 符号的特定位置(通常是 K28.5 控制符)!",于是接收器就以这个位置为基准,每隔 10 个比特切一刀,从而正确地恢复出原本的并行数据。
接收过程:
接收过程其实是发射的逆过程。
1、解串行化:串行数据流以差分 NRZ 格式接收,接收逻辑将其解串为 10-bit 的码组(数据或控制符号)。码组边界在 lane 初始化阶段完成,此后正常通信期间不再重新对齐。
2、 8B/10B 解码: 解串后,链路层载荷被解码成字节流。解码过程中若检测到 /P/(/K28.4/)控制符号后紧跟 /ECP/(/K29.7/K30.7/),需做标记,以便后续剥离填充字节。
3、链路层解封装: 该步骤去掉通道 PDU 的封装以及传输期间可能插入的空闲有序集合。
- 去掉 /SCP/(/K28.2/K27.7/)和 /ECP/(/K29.7/K30.7/)有序集合;
- 去掉空闲符号 /K/(/K28.5/)、/R/(/K28.0/)、/A/(/K28.3/)。
限制条件:插入的空闲符号总数必须为偶数;空闲序列必须从通道 PDU 的偶数符号位置开始。
4、填充剥离: 若在解码阶段检测到 /P/ + /ECP/,说明发送端为满足偶数符号对齐曾在用户 PDU 末尾追加 1 字节填充。该字节解码后值为 0x9C,必须在交给用户应用前从数据流末尾剔除。
流控
Aurora 8B/10B 协议的可选流量控制机制,用来在数据源与接收端速率不匹配时防止丢包,同时保持低延迟。由于流量控制 PDU 可直接嵌入通道 PDU 内发送,因而延迟极低。
Aurora 8B/10B 支持两种流量控制方式:
- 本地流量控制(Native Flow Control)
链路层机制,由 Aurora 接口自己生成、识别,用于在接收端弹性缓存即将耗尽时立即抑制对端发送。 - 用户流量控制(User Flow Control)
由用户应用自定义并解释,Aurora 接口仅负责将其封装成用户流量控制 PDU 并低延迟透传到对端,不参与语义解析。
要点:
- 本地流量控制生效时,不会阻断用户流量控制 PDU 的转发。
- 用户流量控制 PDU 一旦开始发送,不能被任何序列中断。
简单来说,当接收方处理不过来数据时,需要有一种方式告诉发送方"慢点发"或者"暂停发送"。这就是流控。Aurora 协议提供了两套机制来实现这一点:Native Flow Control(原生流控) 和 User Flow Control(用户流控) 。
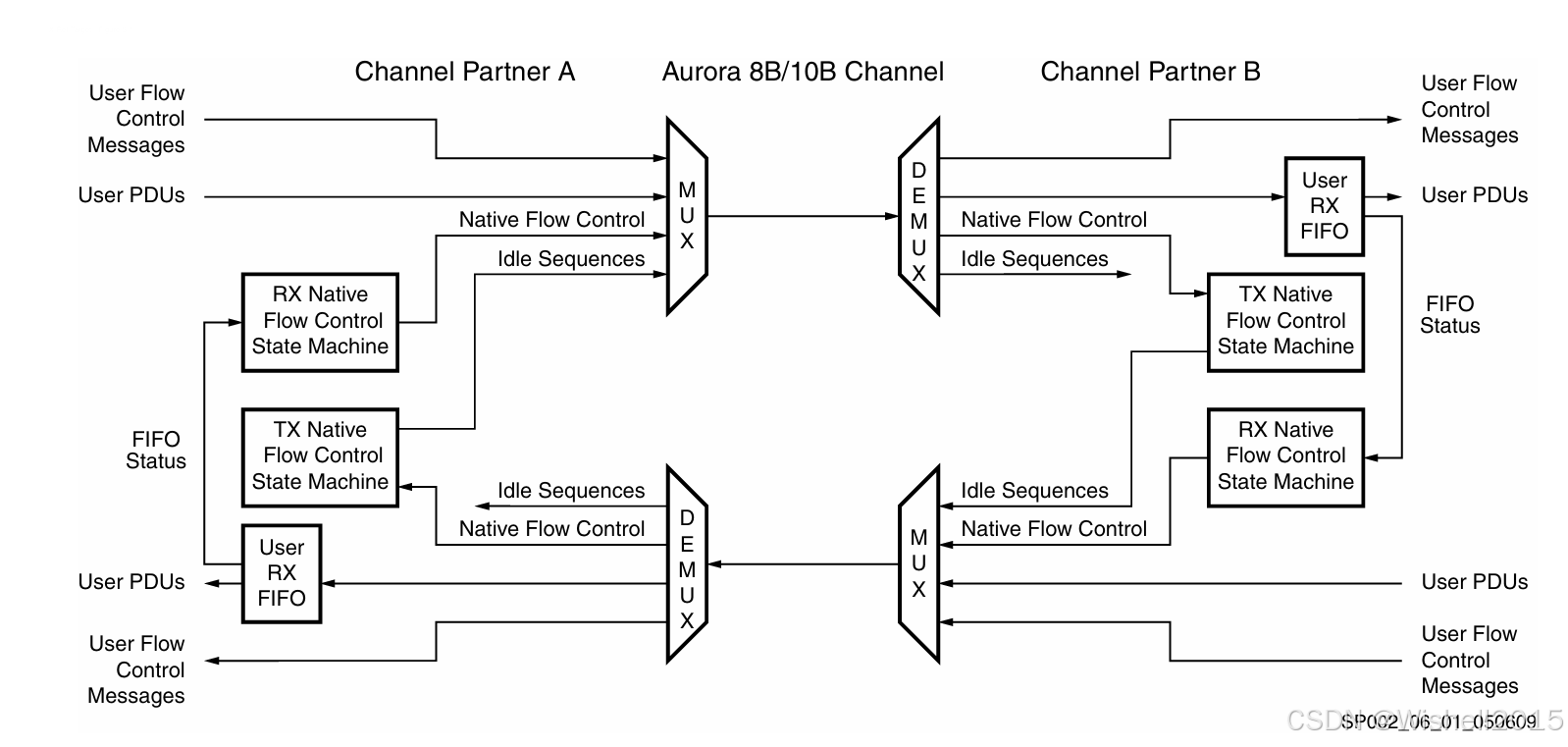
整体架构
图中有两个通信伙伴:Channel Partner A (左)和 Channel Partner B (右)。中间是 Aurora 8B/10B Channel(物理链路)。
通信是全双工的:
-
上方路径:A 发送数据给 B。
-
下方路径:B 发送数据给 A(同时也是 B 发送流控指令给 A 的路径)。
-
MUX (多路复用器) :负责把普通数据(User PDUs)、流控指令、空闲序列(Idles)打包进同一条物理线路发送。
-
DEMUX (解复用器) :接收端负责把这些混合的数据流拆分开。
Native Flow Control (原生流控)
这是由 Aurora 接口自动管理的硬件级流控,目的是防止接收端的缓冲区溢出。
工作流程(以 B 控制 A 为例):
- 检测 (FIFO Status) :看右侧 Partner B。当 B 的 User RX FIFO (接收缓冲区)快满了,它会发出一个 FIFO Status 信号。
- 生成指令 (TX Native State Machine) :这个状态信号传输给 B 的 TX Native Flow Control State Machine 。状态机决定:"不行,必须叫停了",于是生成一个 Native Flow Control 指令(即 NFC PDU)。
- 发送 (Feedback) :这个 NFC 指令通过 B 的 MUX,沿着下方的路径发送回 Partner A。
- 接收与执行 (RX Native State Machine) :Partner A 的 RX Native Flow Control State Machine 收到这个指令。
- 暂停发送 :A 的状态机控制上方的 MUX ,暂停发送 User PDUs(用户数据)。此时 A 可能会发送 Idle 序列或者 User Flow Control 消息,但不会发普通数据,从而给了 B 处理积压数据的时间。
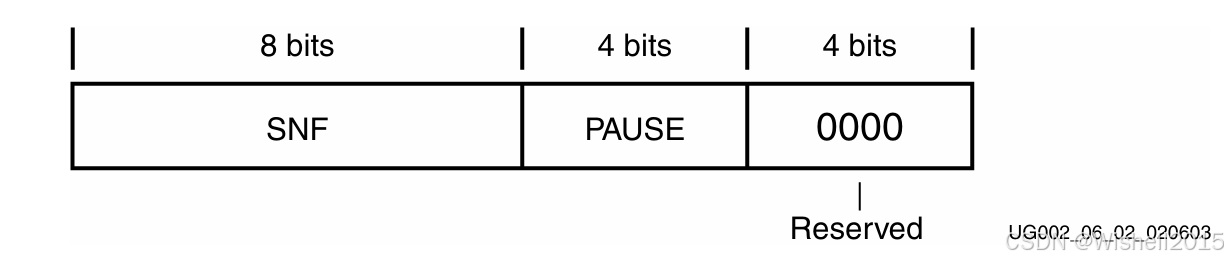
RX状态机监控用于RX FIFO的数据量,一旦其具备溢出风险时,即生成流控数据,用以代替用户数据。TX方接收到这些流控数据后,会根据数据内容暂停一段时间的发送,以便RX方有充足的时间处理数据。
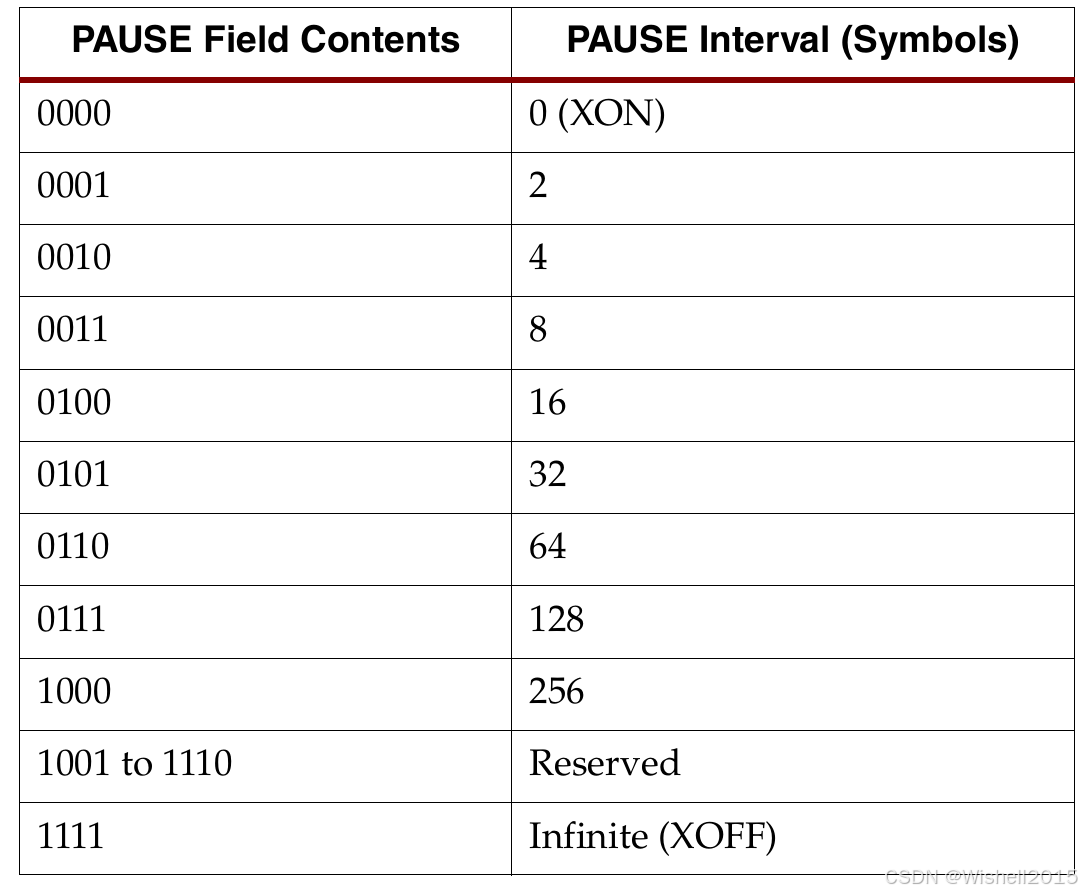
本地流控数据的格式如下:首字节为SNF符号(start of native flow control);第二个字节的前4bit表示需要暂停的间隔(以传输单个symbol为单位),后4个bit保留。
暂停时的两种可选行为
- 完成模式(Completion Mode) :先把当前正在发送的用户 PDU 发完再暂停。
- 立即模式(Immediate Mode) :立即中断当前用户 PDU 的发送并进入暂停。
User Flow Control (用户流控)
这是由用户应用程序控制的高层流控。Aurora 只是充当一个"快递员"。
工作流程:
- 生成 :Partner A 的用户逻辑决定发送一条 User Flow Control Message(比如应用层的"暂停"或"心跳"指令)。
- 传输 :该消息进入 A 的 MUX。文字提到,Aurora 接口会将这些消息封装成 User Flow Control PDUs。
- 接收:通过 Channel 到达 Partner B 的 DEMUX。
- 递交 :Aurora 接口直接把消息解包并交给 B 的用户应用层。Aurora 接口本身不解释、不理解这些消息的内容。
用户流控操作实际上与用户传递数据类似,区别在于其传递的为流控信息,此种流控方式的主动权掌控在发送方手中。本质上是用户需要进行流控时,不暂停发送,而直接发送流控信息(流控信息实际上就是无效信息)。用户流控 PDU 一旦开始发送,不能被时钟补偿序列、本地流控 PDU 或空闲序列打断。
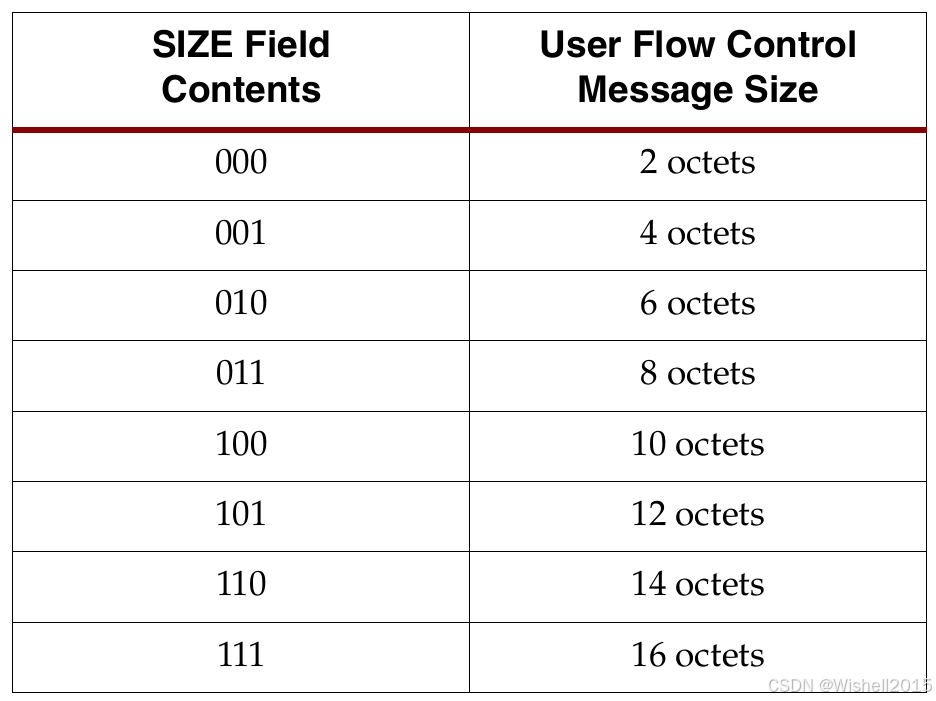
用户流控数据的格式如下:首字节为SUF符号(start of user flow control);第二个字节的前3bit表示后面的流控信息的字节长度,后5个bit保留;后面跟符合前面定义长度的流控字节。
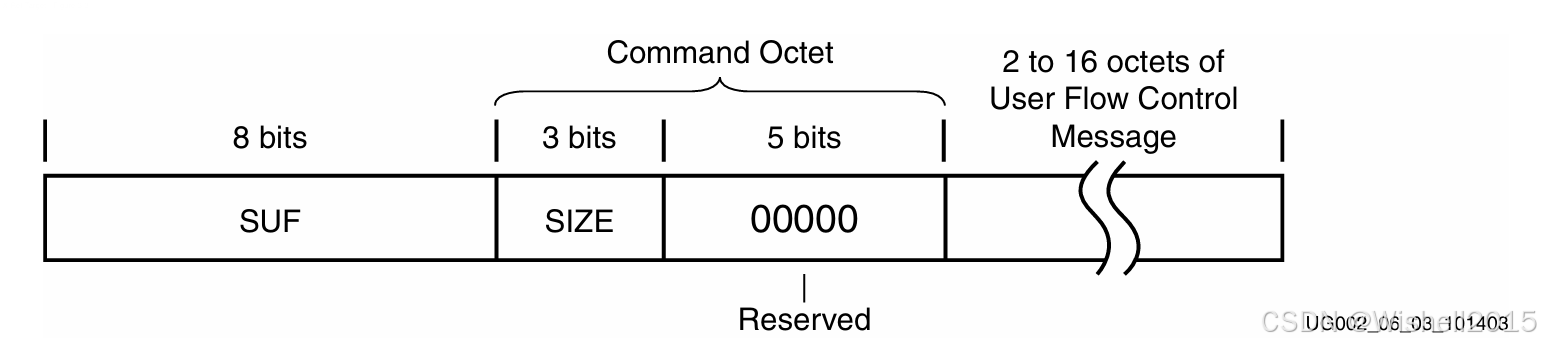
初始化与数据处理
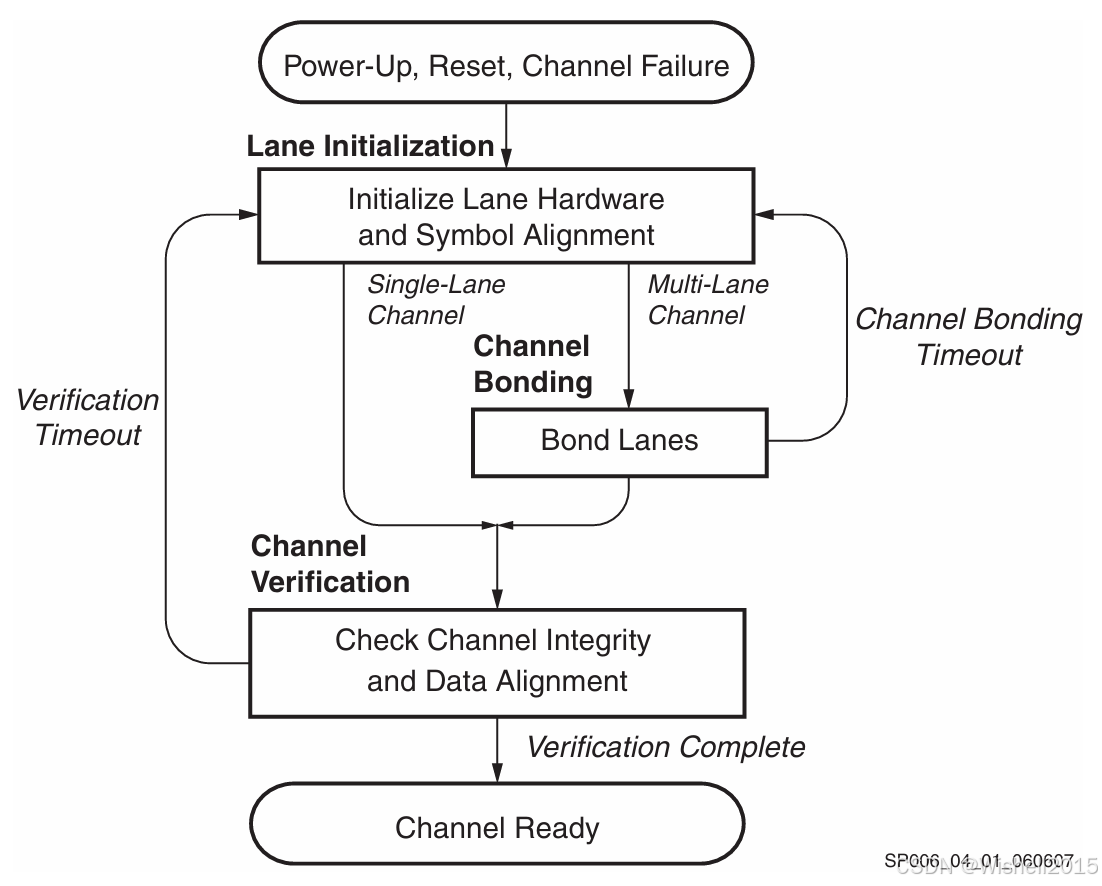
简单来说,这是通信链路从"断电/复位/故障"状态,变成"可以正常发送数据"状态所必须经历的"三步走"流程。
1. 起点:触发条件 (Start)
无论是因为刚上电、用户手动复位,还是之前的连接突然断了(故障),系统都会强制回到这个起点,重新开始初始化。
2.第一阶段:单链路初始化 (Lane Initialization)
协议会单独(Individually) 唤醒每一条物理线路(Lane)。接收端要在比特流中寻找 Comma (/K/) 字符,完成字节对齐(Symbol Alignment) 。此时,每一条线都只管自己能不能听懂对方说话,还不管别的线。
3. 分支判断:一条路还是多条路?
- Single-Lane Channel(单链路通道) :如果你的物理接口只有一根线,直接跳过第二阶段,去第三阶段。
- Multi-Lane Channel(多链路通道) :如果你是用多根线捆绑传输(比如 4 根线组成一个 10Gbps 接口),则必须进入第二阶段。
4. 第二阶段:通道绑定 (Channel Bonding)
核心任务 :消除偏斜(Skew) 。在电路板上,不同线路的走线长度可能不同,或者芯片内部的处理速度有微小差异,导致数据到达接收端的时间有早有晚。接收端会利用 Channel Bonding 字符(/A/) 来对齐所有通道,把它们"粘"成一个逻辑上的大通道,确保数据齐头并进。
异常处理Channel Bonding Timeout :如果等了半天还没对齐(超时),说明链路质量太差或连接有问题,箭头指回第一步,重头再来。
每条 lane 必须先完成各自的 lane 初始化流程(lane initialization),才能进入通道绑定阶段。
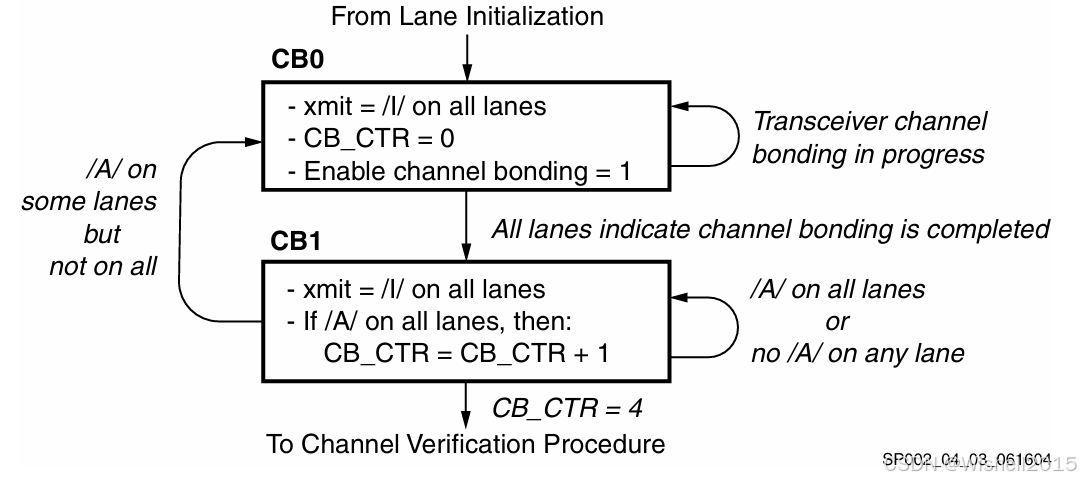
通道绑定分两步完成(状态 CB0 与 CB1):
- CB0 -- 收发器专用对齐
各 lane 的收发器完成自身内部的数据对齐(如弹性缓冲、字边界调整等),属于厂商实现相关的阶段。 - CB1 -- 多 lane 同步验证
检查所有 lane 是否已同时、同步地在/I/空闲序列里输出/A/对齐有序集合,确认跨 lane 的边界一致,至此整条通道完成绑定。
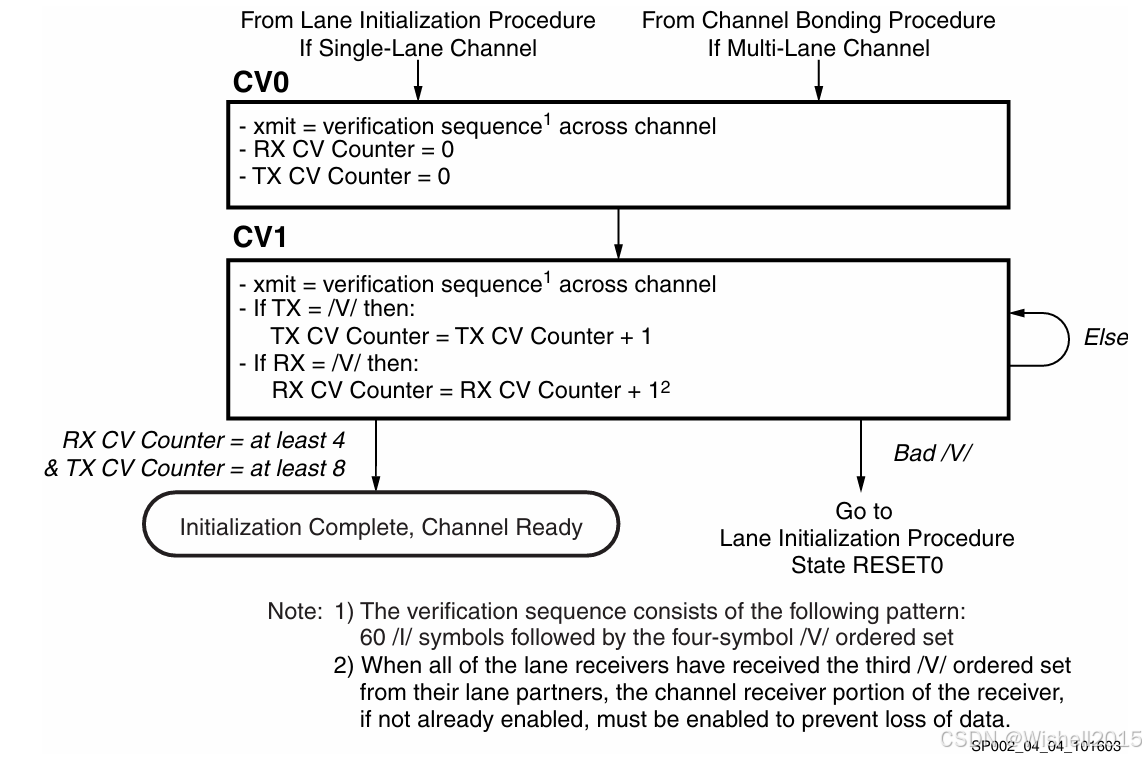
5. 第三阶段:通道验证 (Channel Verification)
验证链路的完整性,确保"用户接口"能正确收到数据。通常会发送特定的 Verification 序列(/V/) 。只有所有链路都通过了验证,才算合格。
Verification Timeout :如果验证一直不通过(超时),箭头同样指回第一步,重头再来。
具体做法:
在所有 lane 上双向同时发送 已知的"通道验证序列"(channel verification sequence)。接收端利用这一固定模式,把各 lane 的数据在用户接口处对齐,并检查通道是否完好。流程框图见下图。
6. 终点:通道就绪 (Channel Ready)
初始化完成。此时 Aurora 接口会拉高 CHANNEL_UP 信号,用户现在可以立即(Immediately) 开始发送真正的数据了。
单看理论比较枯燥,还是需要结合实际的应用来看, 当然应用可能也是IP核的应用,但是理解下简单的原理,后续如果出现问题,就可以反过来看看是哪里出错。