一、Apache Doris 简介
首先来简单讲讲Apache Doris是什么,能做什么?
Apache Doris 采用列式存储引擎、MPP架构、成本优化的查询优化器和向量化执行引擎是一款专为实时数据分析设计的高性能数据库。Doris 3.1 引入了稀疏列和 VARIANT 数据类型的模式模板,使其能更高效地存储和查询具有动态字段的大型数据集,例如日志和 JSON 数据。
二、存算分离架构:计算与存储的完美分工
接下来讲讲Apache Doris的具体技术原理
2.1 架构设计原理
从 3.X 版本开始,Apache Doris 除了支持存算一体模式外,还支持存算分离模式进行集群部署。这是一个重要的架构演进。
想象一个图书馆的运作模式:
-
存算一体 就像传统的小型书店,书籍(数据)和阅读区(计算资源)紧密结合在一起。想读什么书,直接在店里找到就能立刻阅读,速度很快,但如果书越来越多,你就必须同时扩大书架和阅读空间。下图为存算一体架构图。
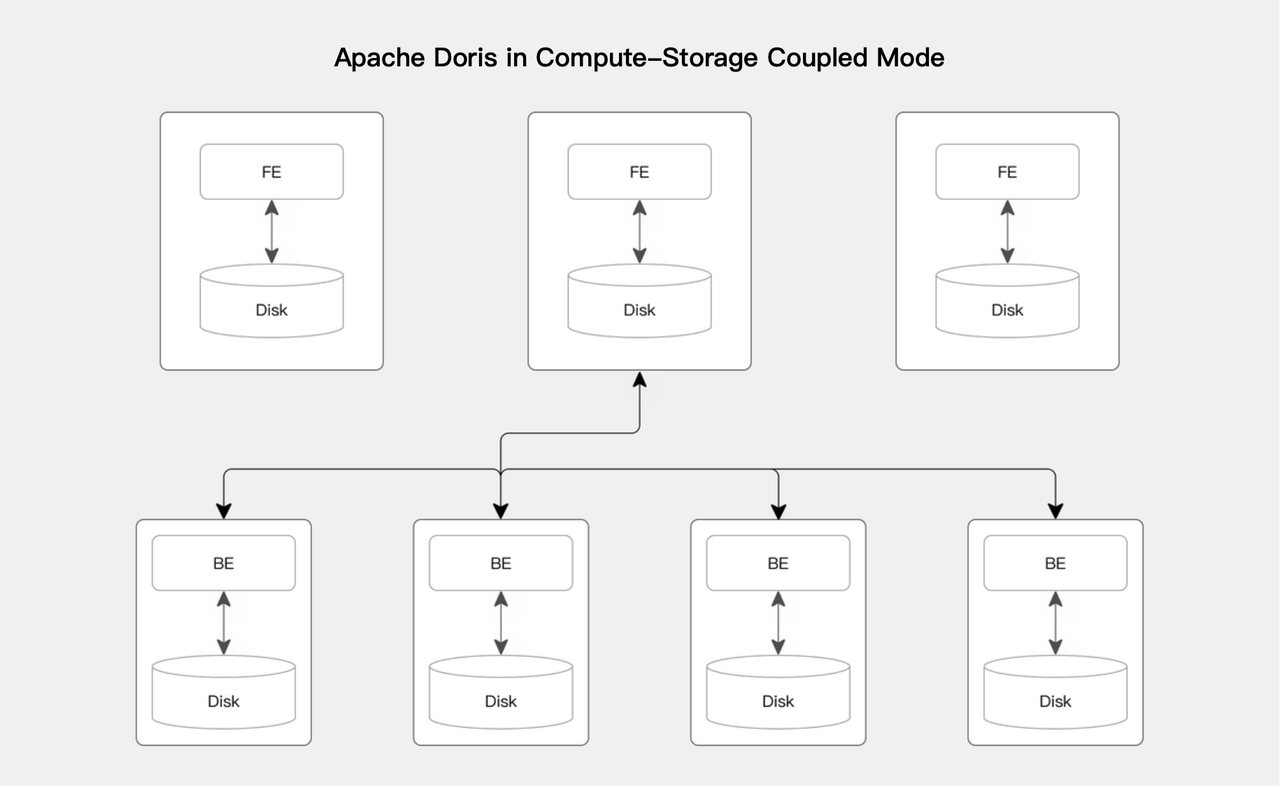
-
存算分离 则像现代化的图书馆系统,有一个巨大的中央仓库(共享存储)存放所有书籍,而各个分馆(计算集群)只保留热门书籍的副本。读者需要某本书时,如果分馆有就直接借阅(缓存命中),没有则从中央仓库调取(从对象存储读取)。这样每个分馆可以根据客流量灵活调整大小,而不必担心书库容量。下图存算分离模式架构图。
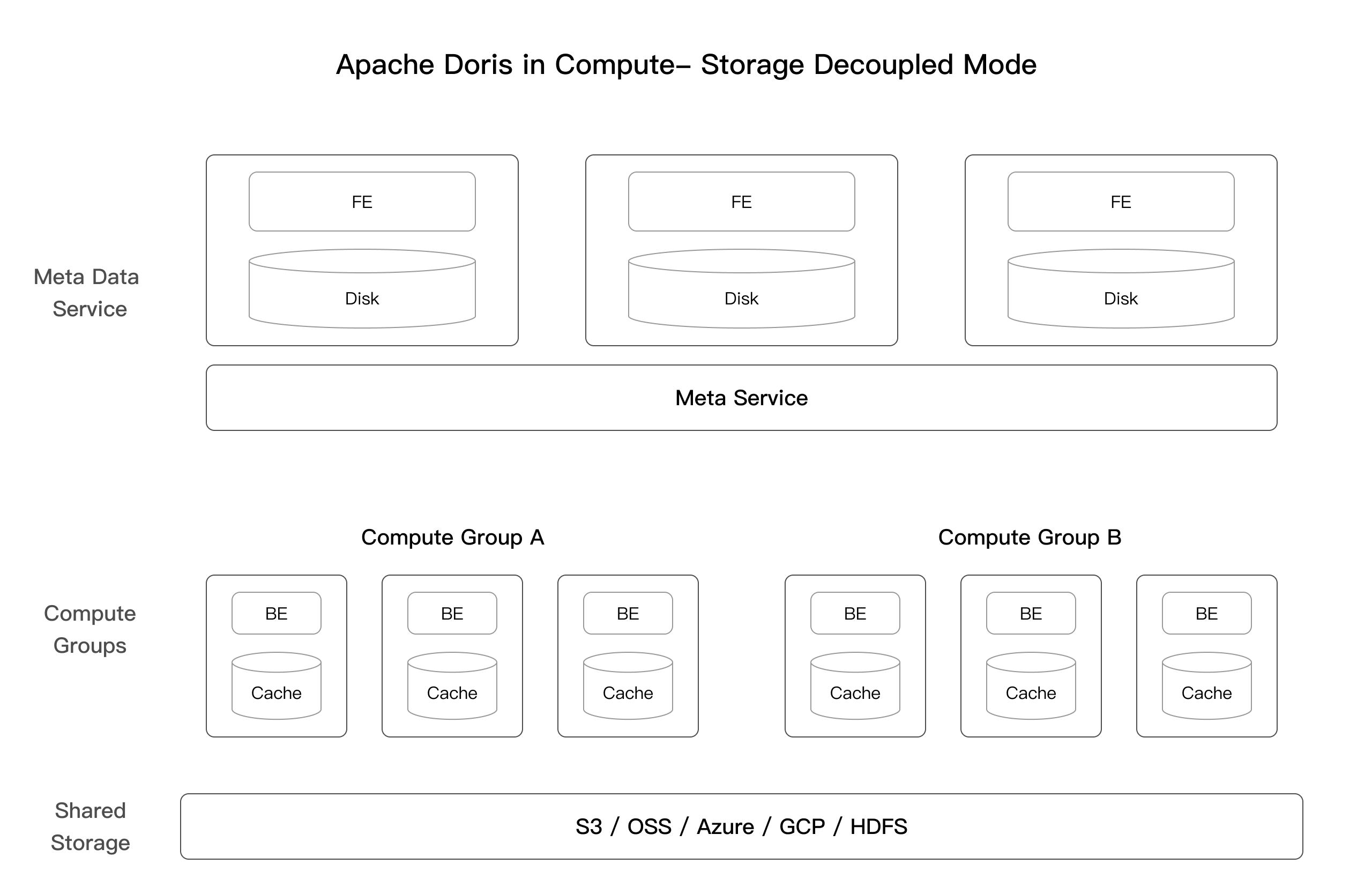
2.2 核心组件
FE 存储元数据、作业信息、权限等数据。Meta Service 是 Doris 存算分离模式下的元数据服务,负责数据导入事务处理、tablet meta、rowset meta 以及集群资源管理。它是一个可以横向扩展的无状态服务。
在存算分离模式下,BE 节点是无状态的。它们缓存部分 tablet 元数据和数据以提高查询性能。计算集群是无状态 BE 节点的集合,作为计算资源使用。具体流程可以看下图。
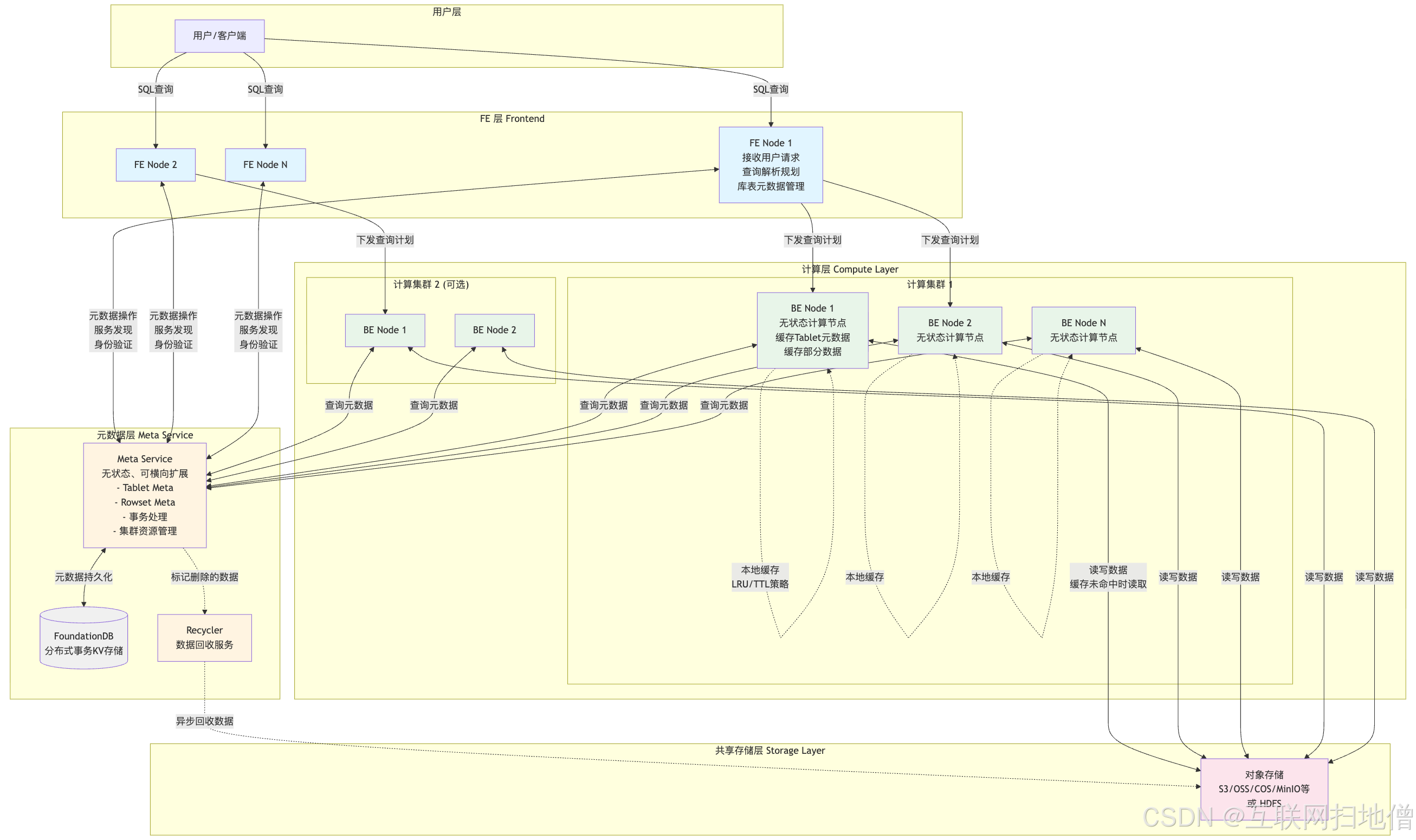
2.3 高速缓存机制:性能的关键
为了克服底层对象存储系统的限制和网络传输开销带来的性能损失,Doris 在本地计算节点上引入了高速缓存。
Apache Doris 实现了基于本地磁盘的高速缓存机制,提供 LRU 和 TTL 两种高效的缓存管理策略。新导入的数据将异步写入缓存中,以加速最新数据的首次访问。
性能表现:
完全命中缓存时,存算分离模式与存算一体模式查询性能完全持平;完全未命中任何缓存时,性能损耗约 35%。
三、VARIANT 数据类型与稀疏列:处理动态数据的利器
3.1 VARIANT 类型的设计思想
在 Doris 2.1 中引入了新的数据类型 VARIANT,它可以存储半结构化 JSON 数据,允许存储包含不同数据类型的复杂数据结构,而无需在表结构中提前定义具体的列。
想象你在整理家庭成员的信息:
-
传统方式(静态列):就像提前打印好的表格,每个人都必须填写姓名、年龄、职业这些固定栏目。如果某个家庭成员有特殊信息(比如某人是运动员,需要记录运动项目),你就得重新设计整张表格。
-
VARIANT 方式:就像使用可扩展的电子表格,每个人的基本信息固定,但可以根据个人特点动态添加字段。运动员可以有"运动项目"字段,学生可以有"就读学校"字段,系统会自动识别并高效存储这些差异化信息。
3.2 存储原理
VARIANT 写入涉及类型推断和 Memtable 内相同 JSON 键的数据合并,生成前缀树。该树保存每个 JSON 字段的类型和列信息,并将同一列的所有类型信息合并为最小公共类型,生成列,编码为 Doris 存储格式,并追加到 segment。
存储数据为 Variant 列所需的存储空间与存储为预定义静态列相似。与 JSON 类型相比,Variant 类型减少了 65% 的空间。换句话说,Variant 类型只占用 JSON 三分之一的存储空间。可谓是非常的带派!
3.3 稀疏列优化
3.1 版本在 VARIANT 类型上新增了稀疏列能力,使得 VARIANT 可以轻松应对数万子列的场景。
稀疏列(Sparse Subcolumns)按 JSON Key 频次排序,只提取 Top-N 高频子列入"真列式";长尾保持在稀疏列存储,避免无序扩张。
这就像超市的商品陈列策略:
- 热门商品(高频子列):可乐、面包等畅销品放在货架上,方便顾客快速拿取(列式存储,查询快)
- 冷门商品(低频子列):特殊调料、小众进口食品放在仓库,需要时再调取(稀疏存储,节省空间)
这样既保证了常用数据的查询效率,又避免了元数据爆炸。
四、MPP 架构与向量化执行引擎:极速查询的秘密
4.1 MPP 大规模并行处理架构
Apache Doris 基于 MPP(Massively Parallel Processing)架构,采用分布式执行查询计划。
MPP 架构就像快递分拣中心的工作方式:
一个大订单(复杂查询)到来时,不是由一个人从头处理到尾,而是:
- 任务分解:将包裹按地区分成多份(数据分片)
- 并行处理:每个分拣员同时处理自己负责的区域(多个 BE 节点并行计算)
- 结果汇总:各区域处理完毕后,统一汇总装车发送(结果聚合返回)
这样 100 个包裹,10 个人并行处理可能只需要原来 1/10 的时间。
4.2 向量化执行引擎
Doris 查询引擎是向量化的查询引擎,所有的内存结构能够按照列式布局,能够达到大幅减少虚函数调用、提升 Cache 命中率,高效利用 SIMD(单指令多数据流)指令的效果。在宽表聚合场景下性能是非向量化引擎的 5-10 倍。
这里用一个形象的例子比喻。小王经营了一家果汁店,每次他都会从篮子里拿出一个苹果放到榨汁机内等待出汁。如果有 8 个客户,每个客户都点了一杯苹果汁,那么小胡需要重复循环 8 次榨汁流程,需要 40 分钟。
为了提升制作速度,小胡将榨汁机数量从 1 台增加到 8 台,一次性拿出 8 个苹果,分别放入 8 台榨汁机同时榨汁。此时,小胡只需要 5 分钟就能够制作出 8 杯苹果汁。
- 非向量化:一次处理一行数据,就像一次榨一个苹果
- 向量化:一次处理一批数据,就像同时榨多个苹果
4.3 SIMD 指令加速
SIMD 的全称是 Single Instruction Multiple Data,即用单条指令操作多条数据。它的原理是在 CPU 寄存器层面实现数据的并行操作。
这就像工厂流水线上的多工位操作台,一个指令下达,多个工位同时执行相同操作,大幅提升效率。
五、存算分离模式下的高并发导入优化
5.1 存算分离的挑战
在存算分离场景下,MOW 表更新 Delete Bitmap 需要获取分布式锁 delete_bitmap_update_lock。原有实现中,导入、Compaction 和 Schema Change 会竞争该锁,容易在高并发导入场景下导致长时间等待甚至失败。
5.2 优化策略
通过引入新的 mow_tablet_compaction_key,避免多个 Compaction/Schema Change 任务在更新 initiators 列表时产生不必要的事务冲突。
这就像银行柜台办业务的优化:
- 原来:存款、取款、转账都要排同一个队,互相影响,高峰期等待时间很长
- 优化后:按业务类型分流,存款和取款不再互相干扰,只有真正冲突的操作(比如同一账户的并发操作)才需要等待
六、智能查询优化器
6.1 基于数据特征的优化
3.1 版本在优化器中全面引入了基于数据特征的优化手段,在特定场景下可以获得超过 10 倍的性能提升。
Apache Doris 采用了内置的 Data Trait 分析机制。通过揭示数据中的统计特征和语义约束,Data Trait 为查询优化提供了基础支持。
6.2 Runtime Filter 动态优化
Doris 采用了 Adaptive Query Execution(自适应查询执行)技术,可以根据 Runtime Statistics 来动态调整执行计划。通过 Runtime Filter 技术能够在运行时生成 Filter 推到 Probe 侧,并且能够将 Filter 自动穿透到 Probe 侧最底层的 Scan 节点,从而大幅减少 Probe 的数据量,加速 Join 性能。
这就像导航软件的实时路线调整:
出发前(查询规划阶段)制定了一条路线,但行驶过程中(查询执行阶段)发现前方道路拥堵(某些条件可以过滤大量数据),导航会立即重新规划更优路线(动态调整执行计划),甚至提前告诉你避开拥堵路段(Filter 下推),而不是傻傻地按原计划走。
七、数据分区与分桶:高效的数据组织
7.1 分桶策略
Doris 支持哈希分桶和随机分桶两种方法。在同一分区内,系统根据分桶键和分桶数量执行哈希计算。具有相同哈希值的数据将被分配到同一个桶中。
这就像学校按班级(分区)和小组(分桶)管理学生:
- 分区:按年级划分,高一、高二、高三各自独立管理
- 哈希分桶:在班级内,按学号尾数分组,尾数为 1 的在第一组,尾数为 2 的在第二组,这样查找某个学生时,可以快速定位到具体小组
- 随机分桶:随机分配,适合数据分布均匀的场景
7.2 自动分桶
从 2.0 版本开始,Doris 支持根据机器资源和集群信息自动设置分区中的桶数量。
建议 tablet 大小在 1-10GB 范围内。过小的 tablet 可能导致聚合效果不佳并增加元数据管理压力;过大的 tablet 不利于副本迁移和补充,并会增加 Schema Change 操作的重试成本。
八、总结
Apache Doris 3.1 版本通过以下核心技术实现了卓越性能:
- 存算分离架构:实现计算与存储资源的独立弹性伸缩,通过高速缓存机制保证性能
- VARIANT 类型与稀疏列:灵活处理半结构化数据,存储效率提升 65%
- MPP + 向量化引擎:并行计算 + 批量处理,性能提升 5-10 倍
- 智能查询优化:基于数据特征和运行时统计信息动态调整执行计划
- 高并发优化:通过锁优化和分流策略,大幅降低高并发场景的延迟
这些技术创新使 Apache Doris 成为实时数据分析领域的领先解决方案,无论是日志分析、用户行为分析,还是实时报表,都能提供卓越的性能表现。最近4.x版本也随之进行了发布,感兴趣的同学可以去了解下。