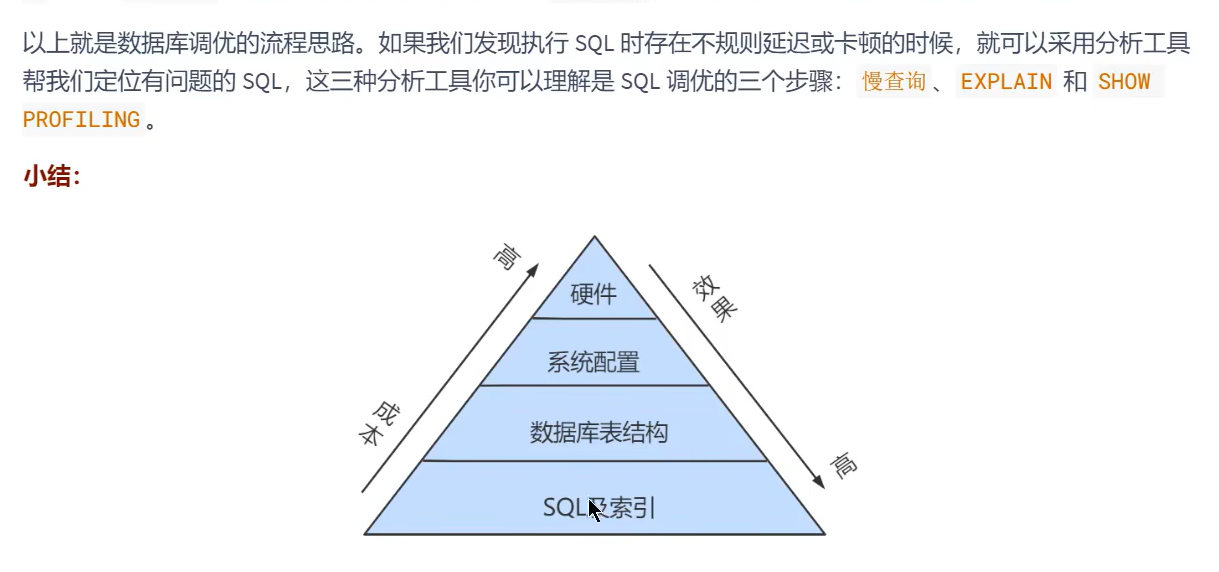
1.SQL调优的3个步骤:观察和行动

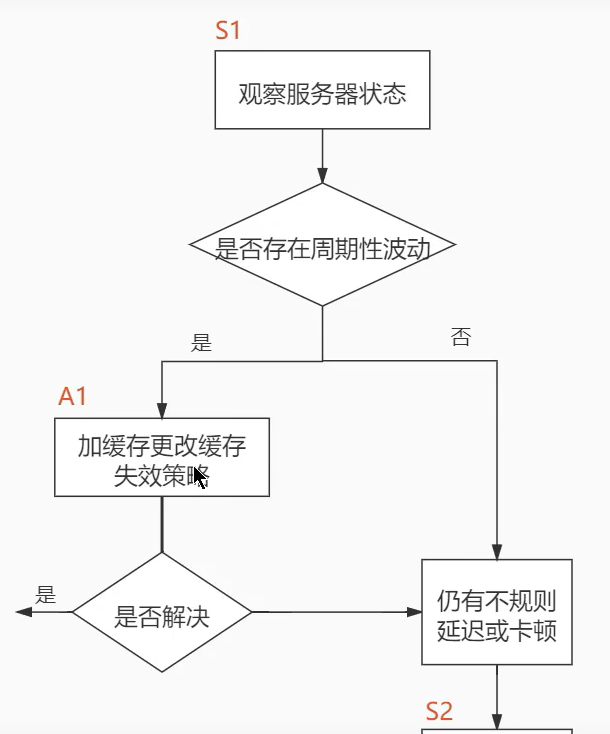
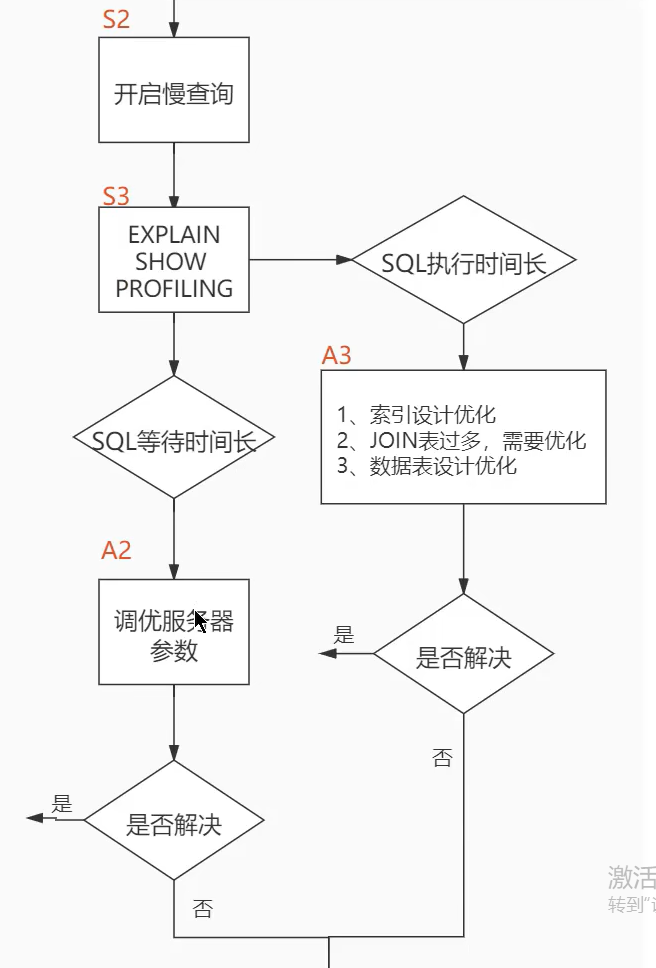
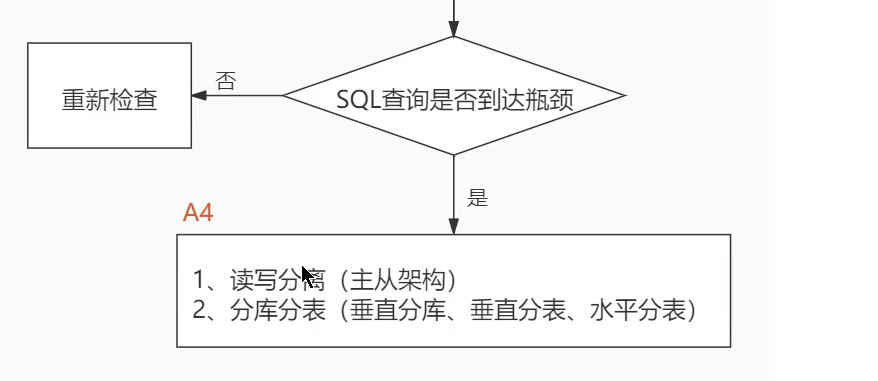
- SQL调优的三个步骤:
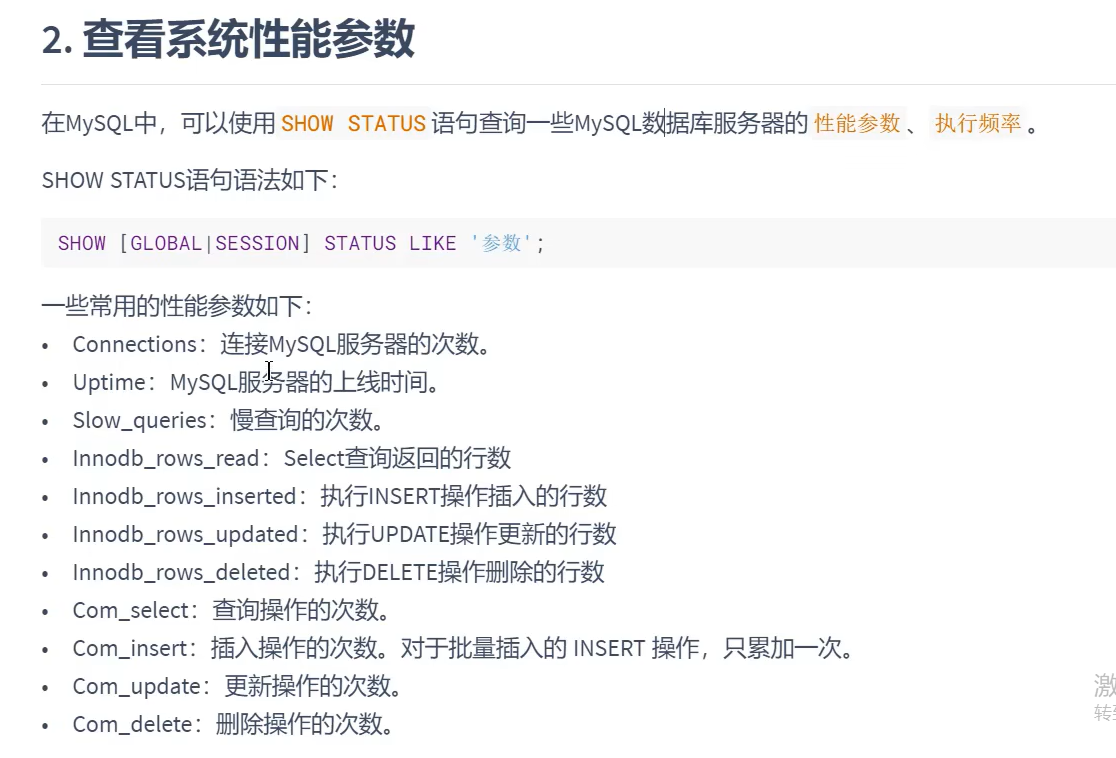
2.查看系统性能参数

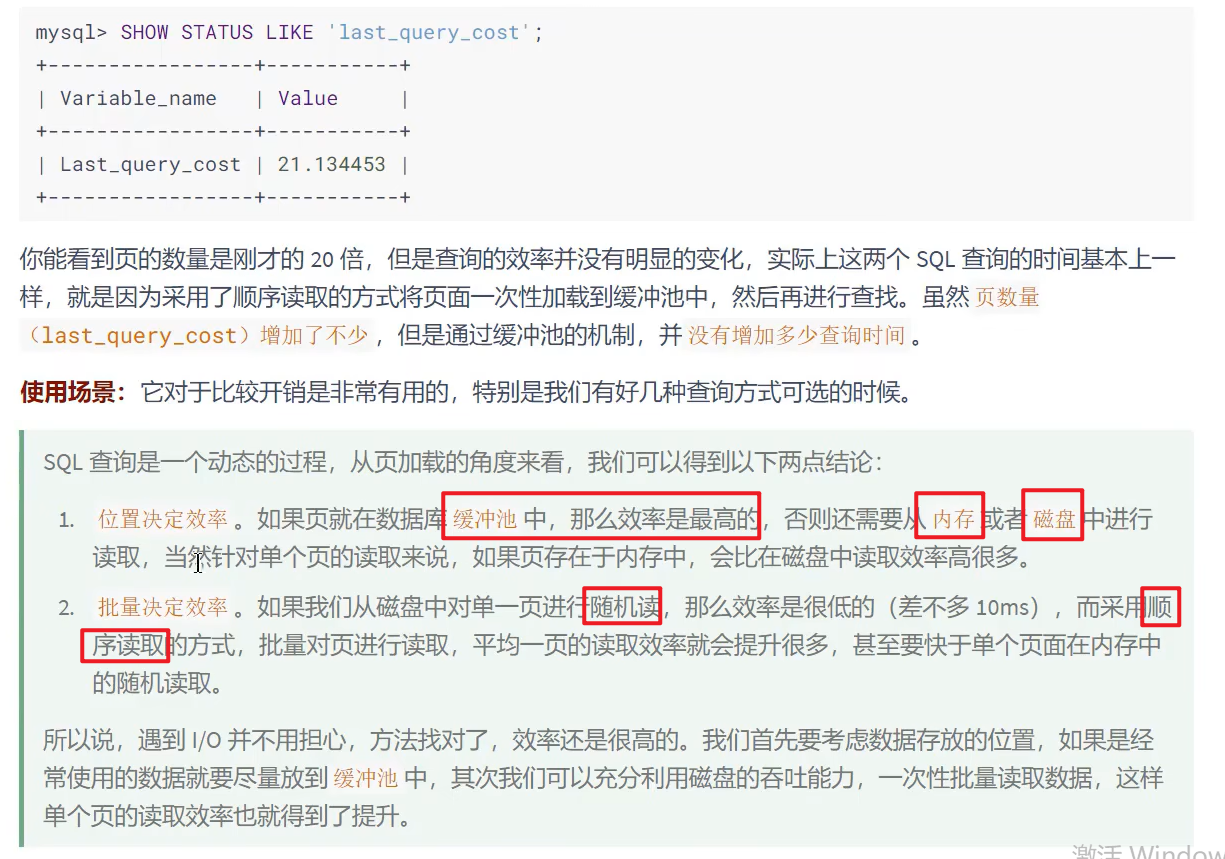
3.统计SQL的查询成本:last_query_cost 页数量

慢查询日志
- long_query_time 的值是判断是否为慢查询的标准

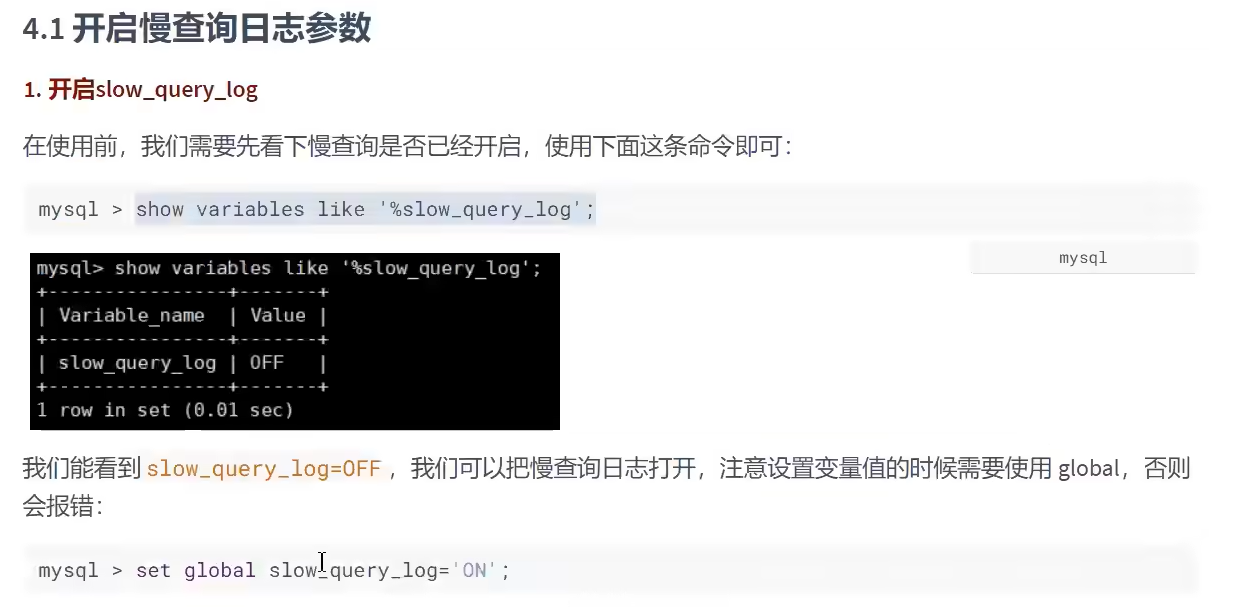
- 默认慢查询日志不开启,手动开启慢查询日志
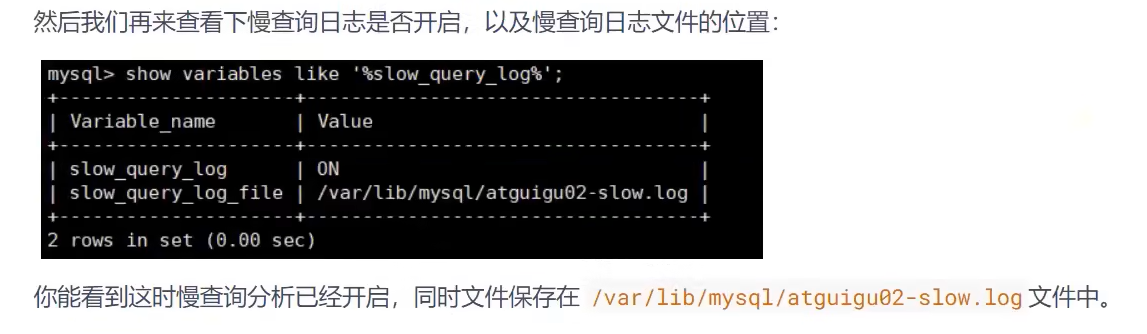
- 开启慢查询日志后
- 修改long_query_time的阈值,设置为1秒
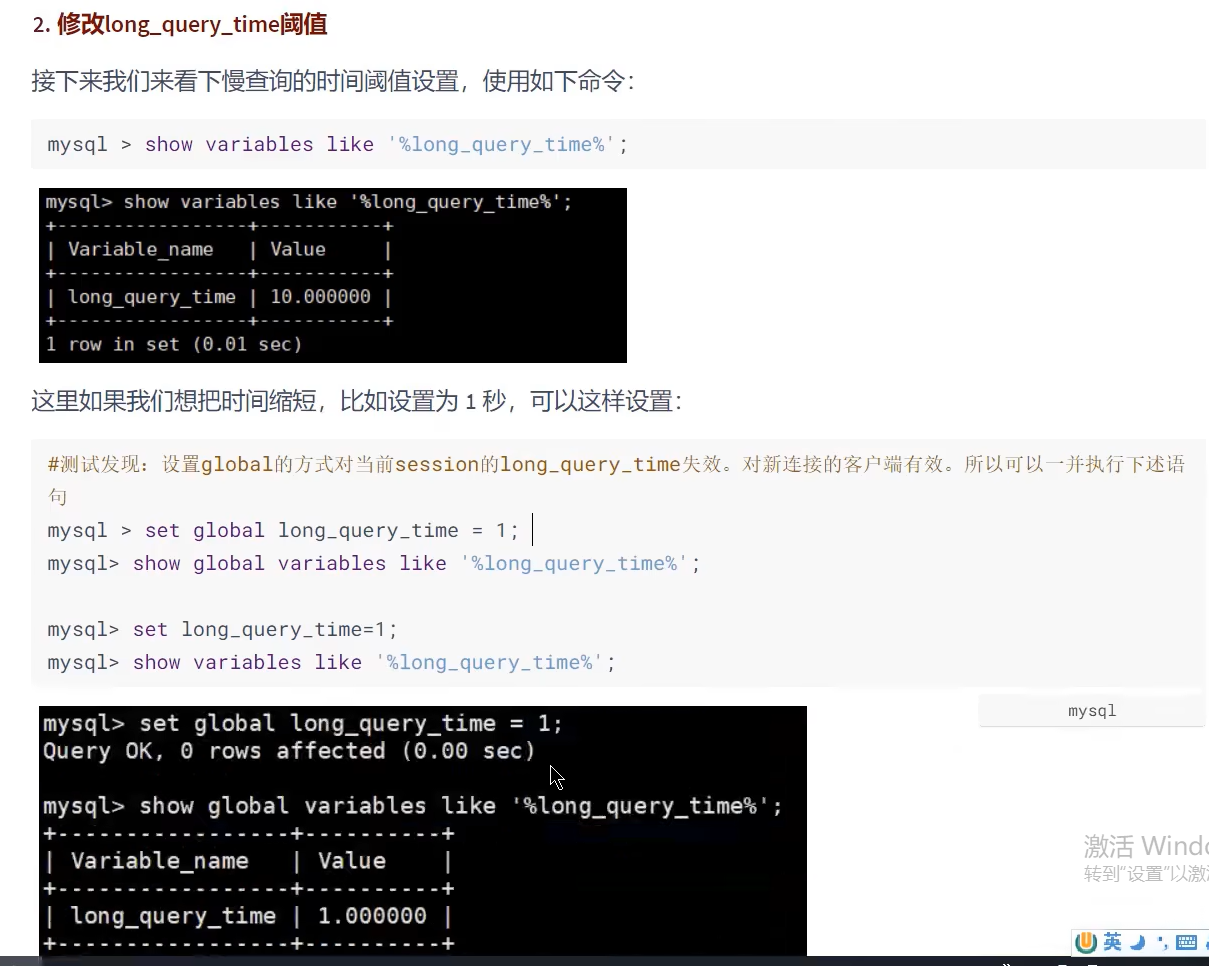
- 在配置文件中直接设置好之前的所有配置;
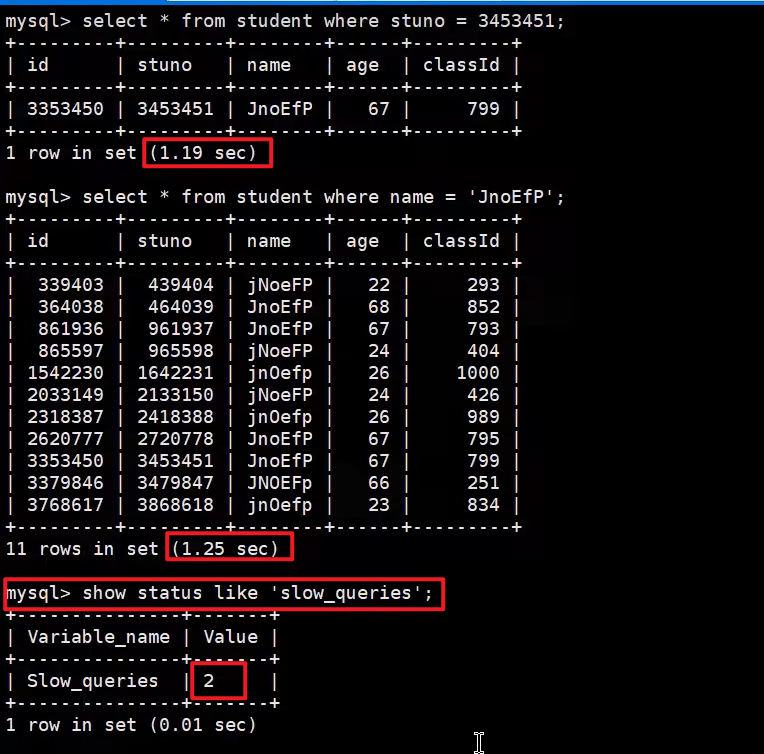
- 查看超过阈值的慢查询记录有多少条

- 查出有2条慢查询SQL
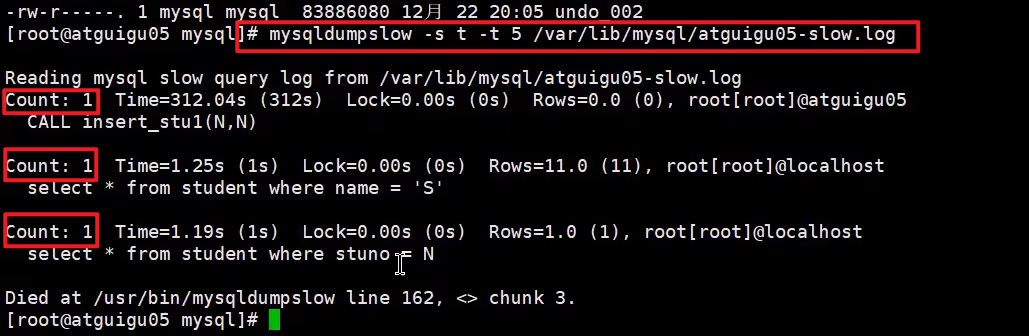
找出慢查询的语句
- 查询次数min_examined_row_limit,如果设置为3,就是3次超过设置的long_query_time阈值,就记录到慢查询日志中,而不是某一次偶发性超过阈值。
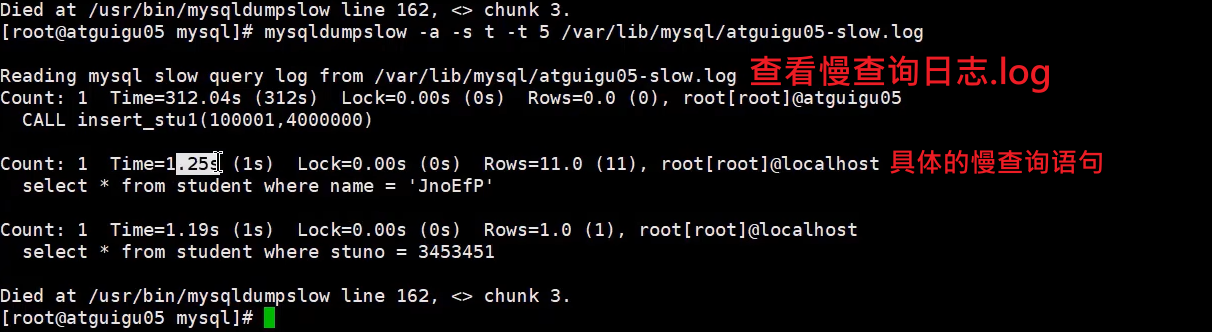
慢查询日志分析工具:mysqldumpslow
- 是在根目录环境下执行,而不是mysql的命令环境中
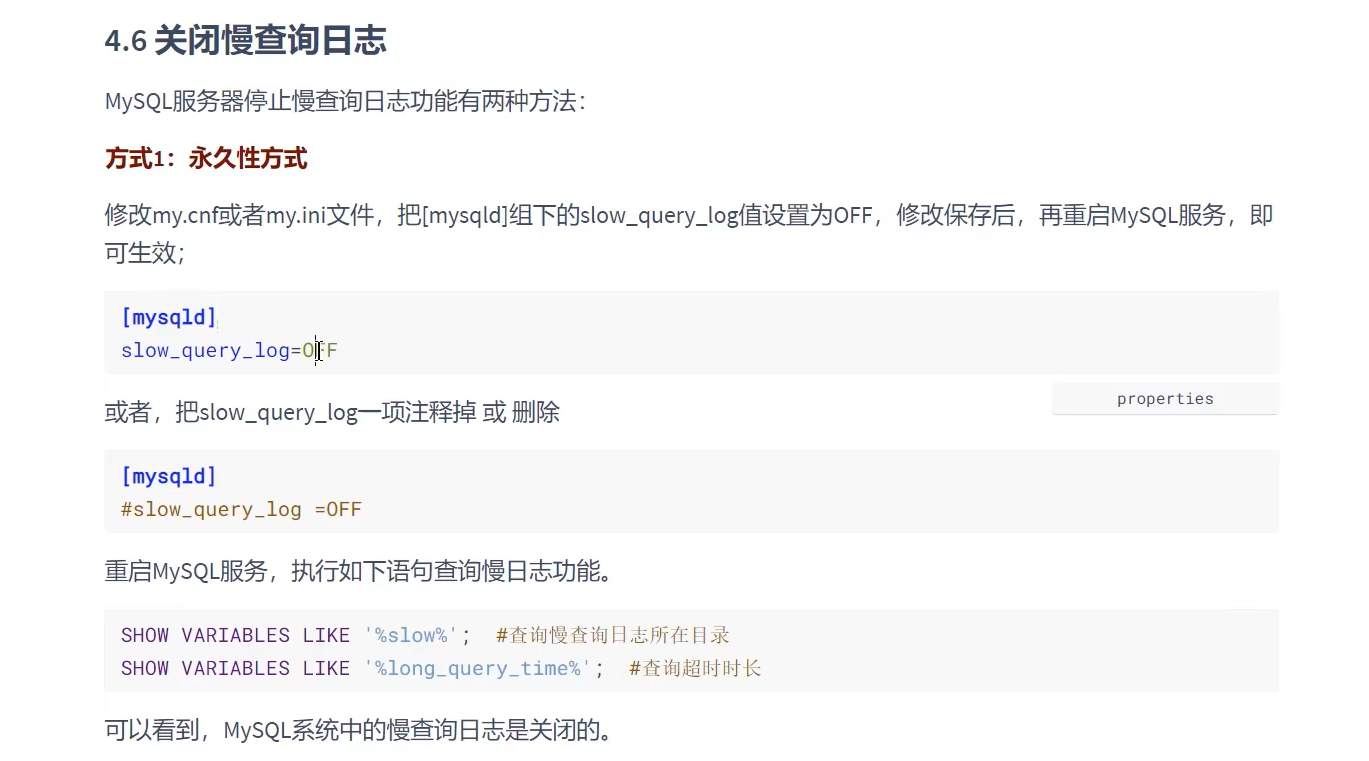
- 使用完就关闭慢查询日志
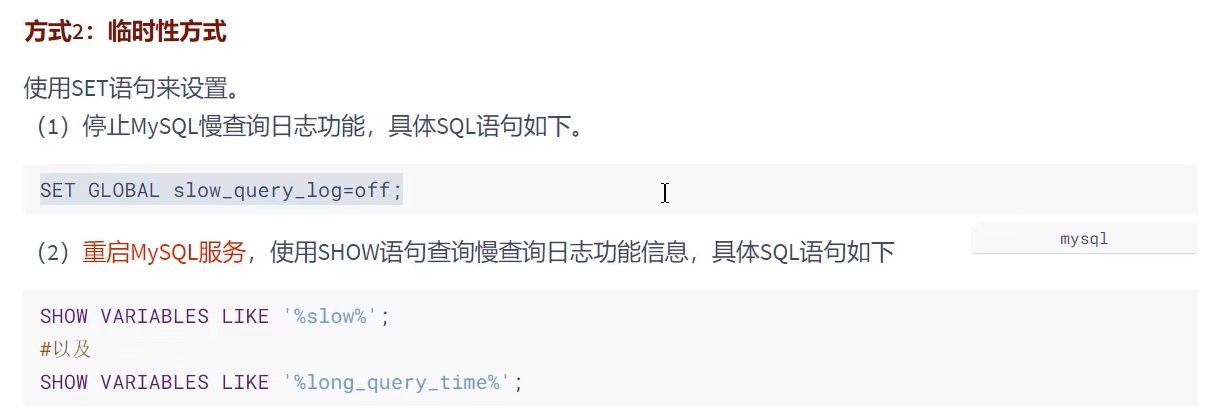
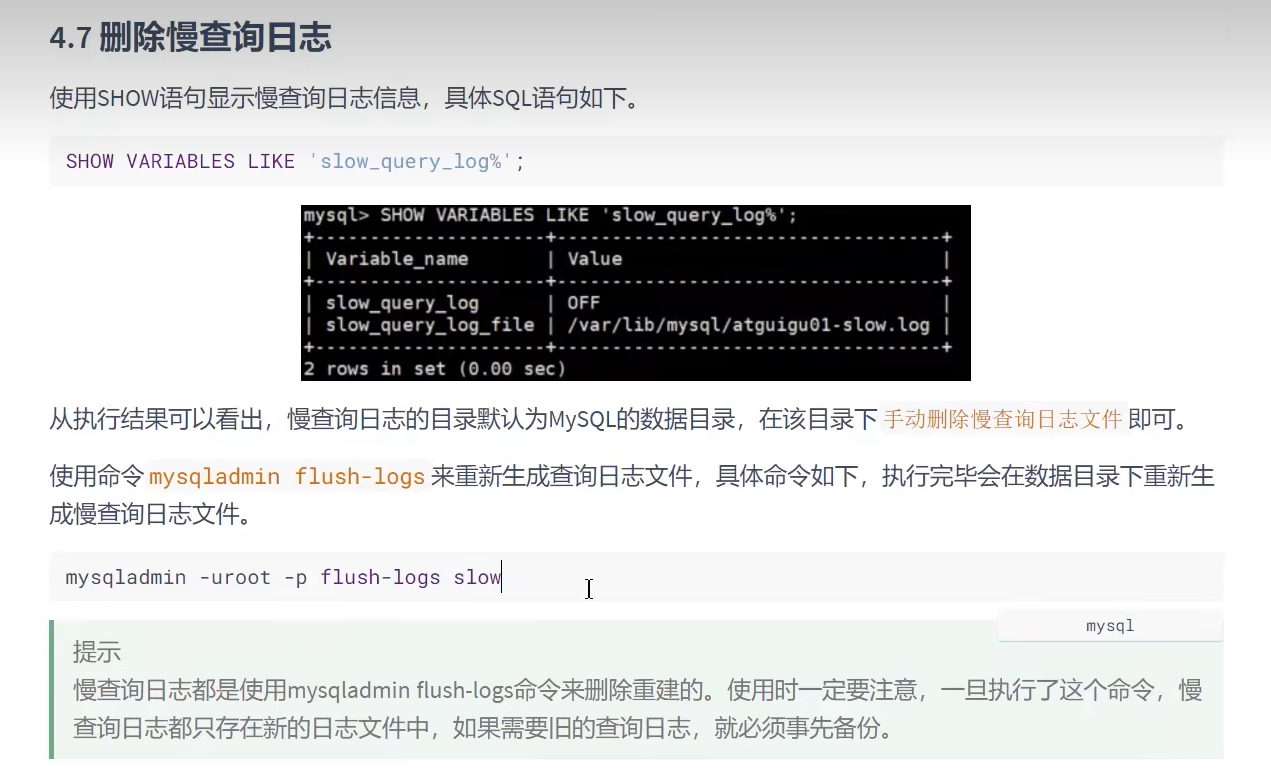
- 删除慢查询日志
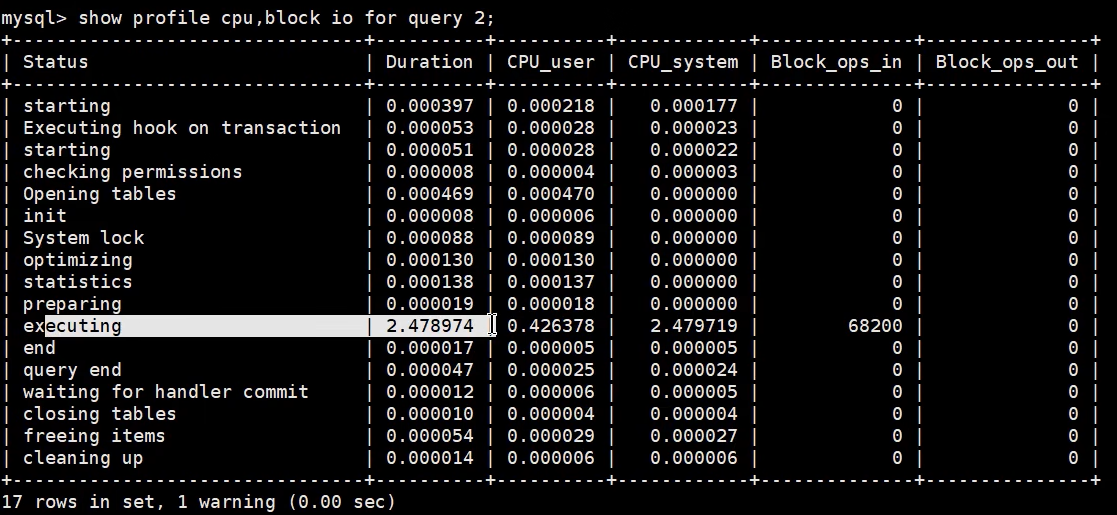
- 查询SQL执行成本
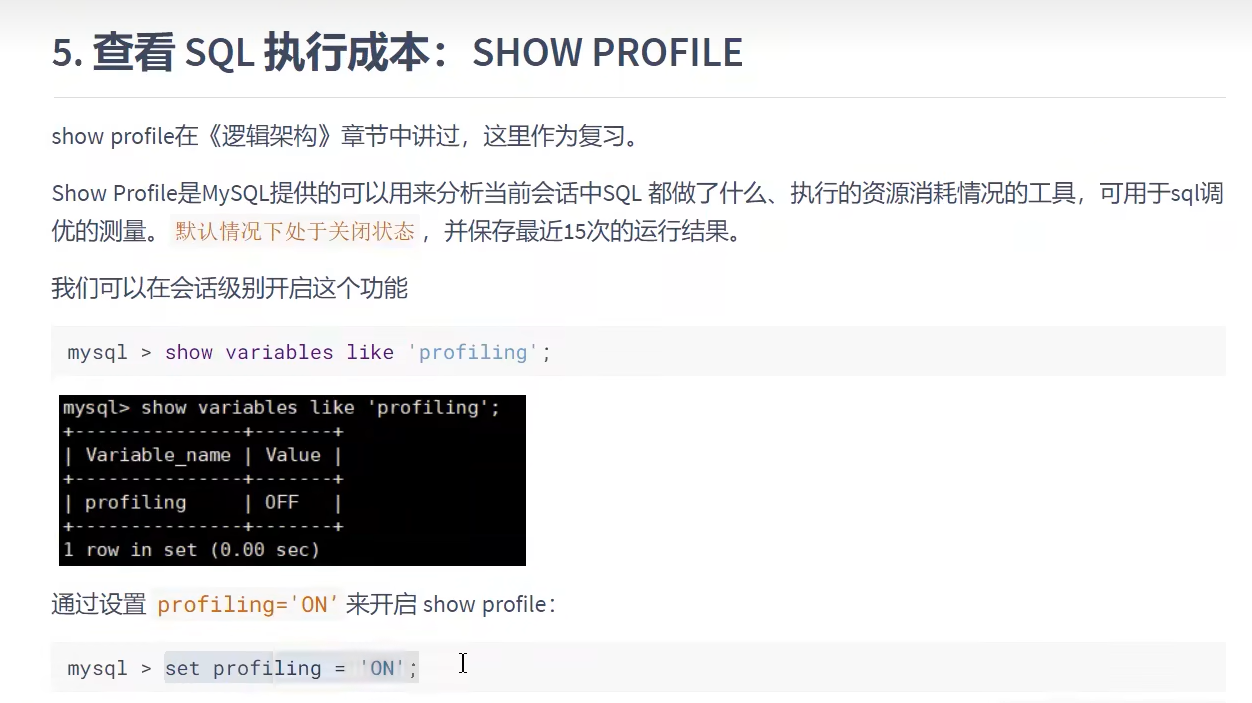
- 开启show profile
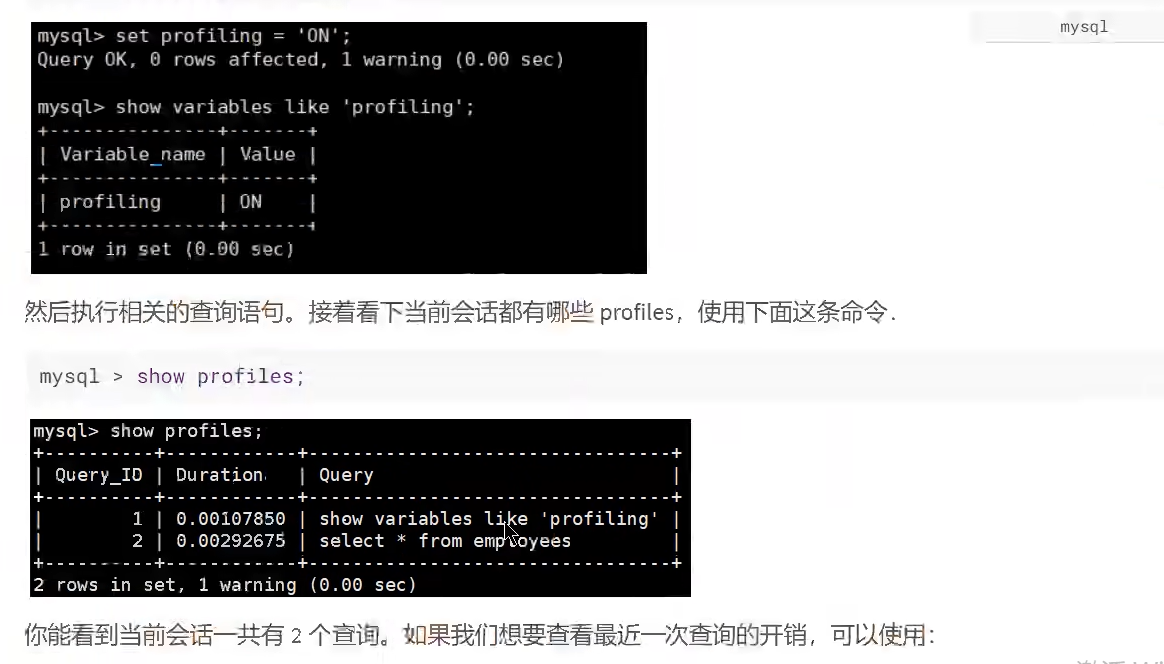
- 查询最近一次的开销
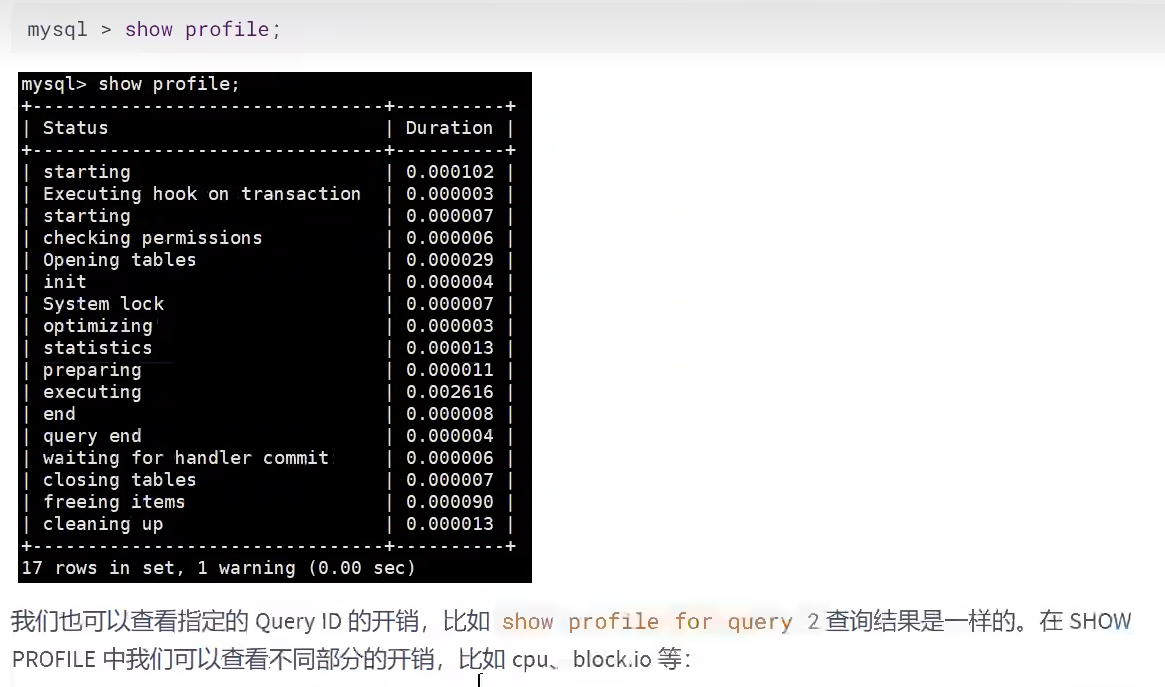
- 查询后发现,executing特别慢

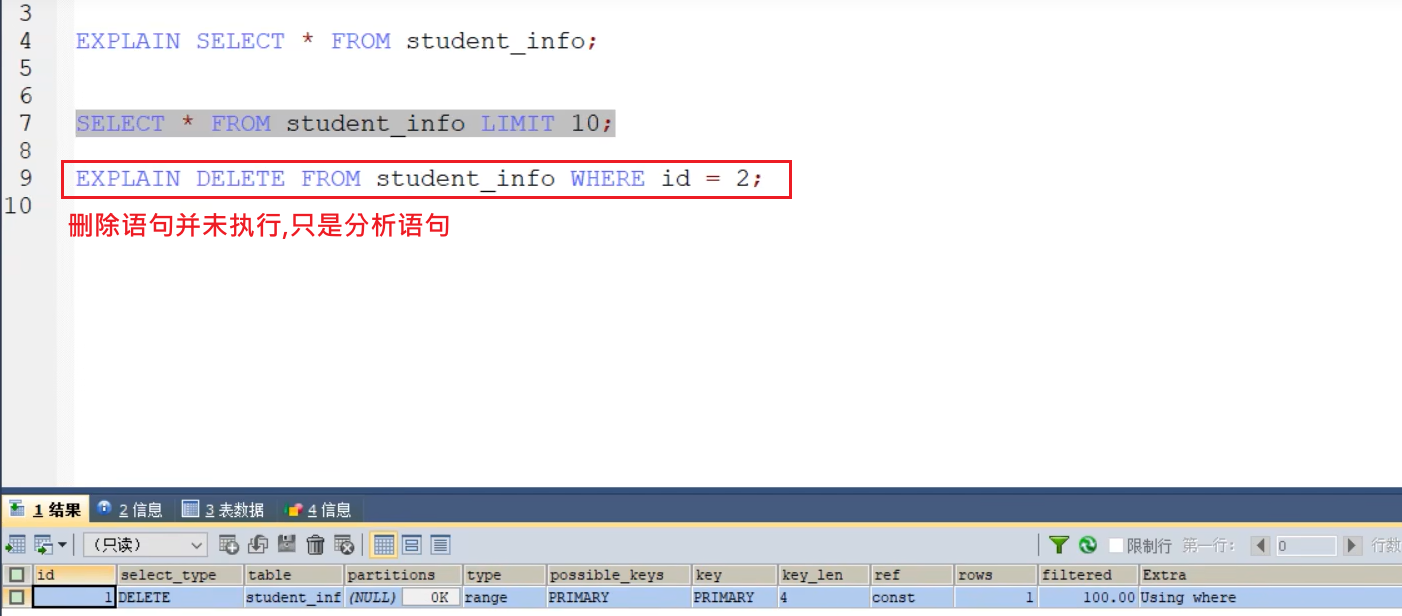
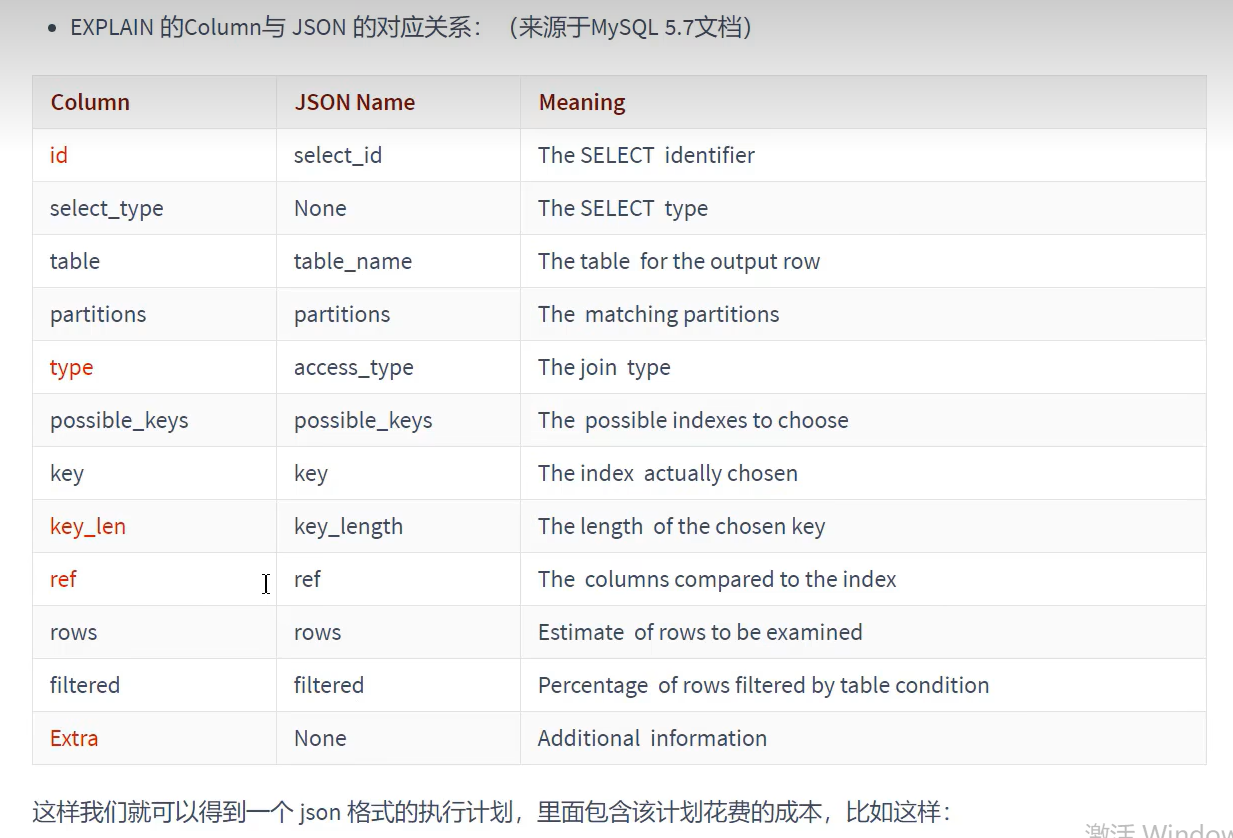
分析慢查询的语句 EXPLAIN

- EXPLAIN的作用

- 书写格式和基本语法

- 主要还是SELECT
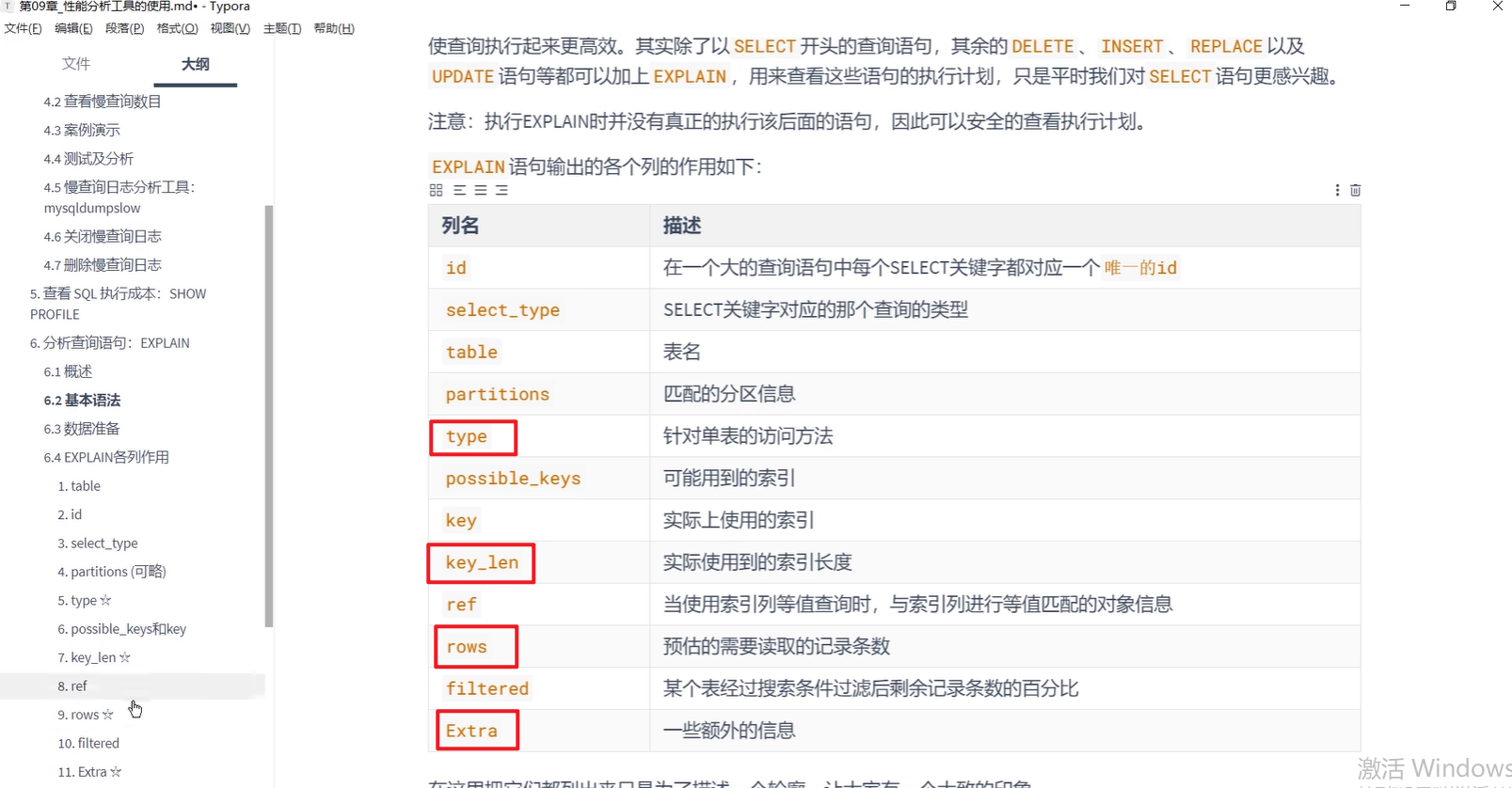
- table 表名

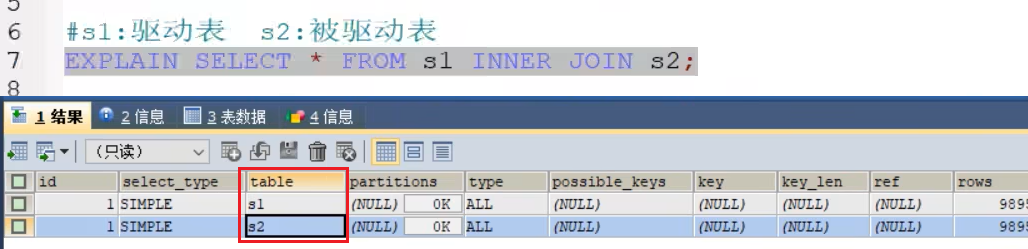
- id,有几个select就有几个id;
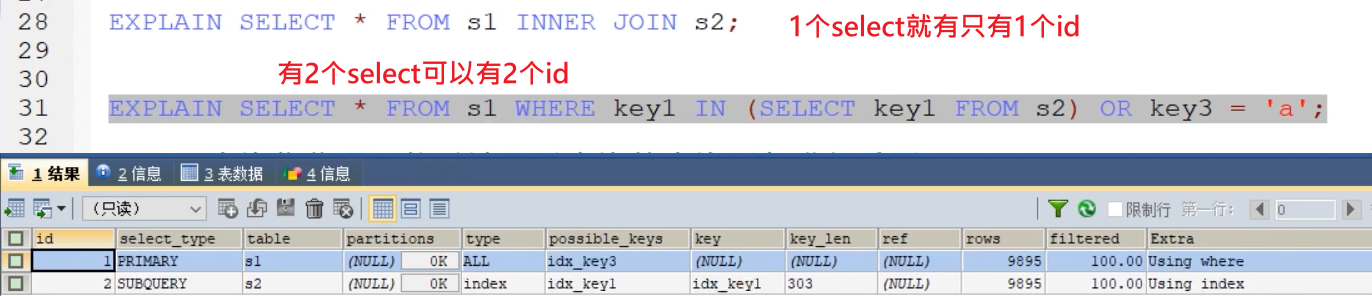
- 注意,可能会进行重写

- Union


- select_type

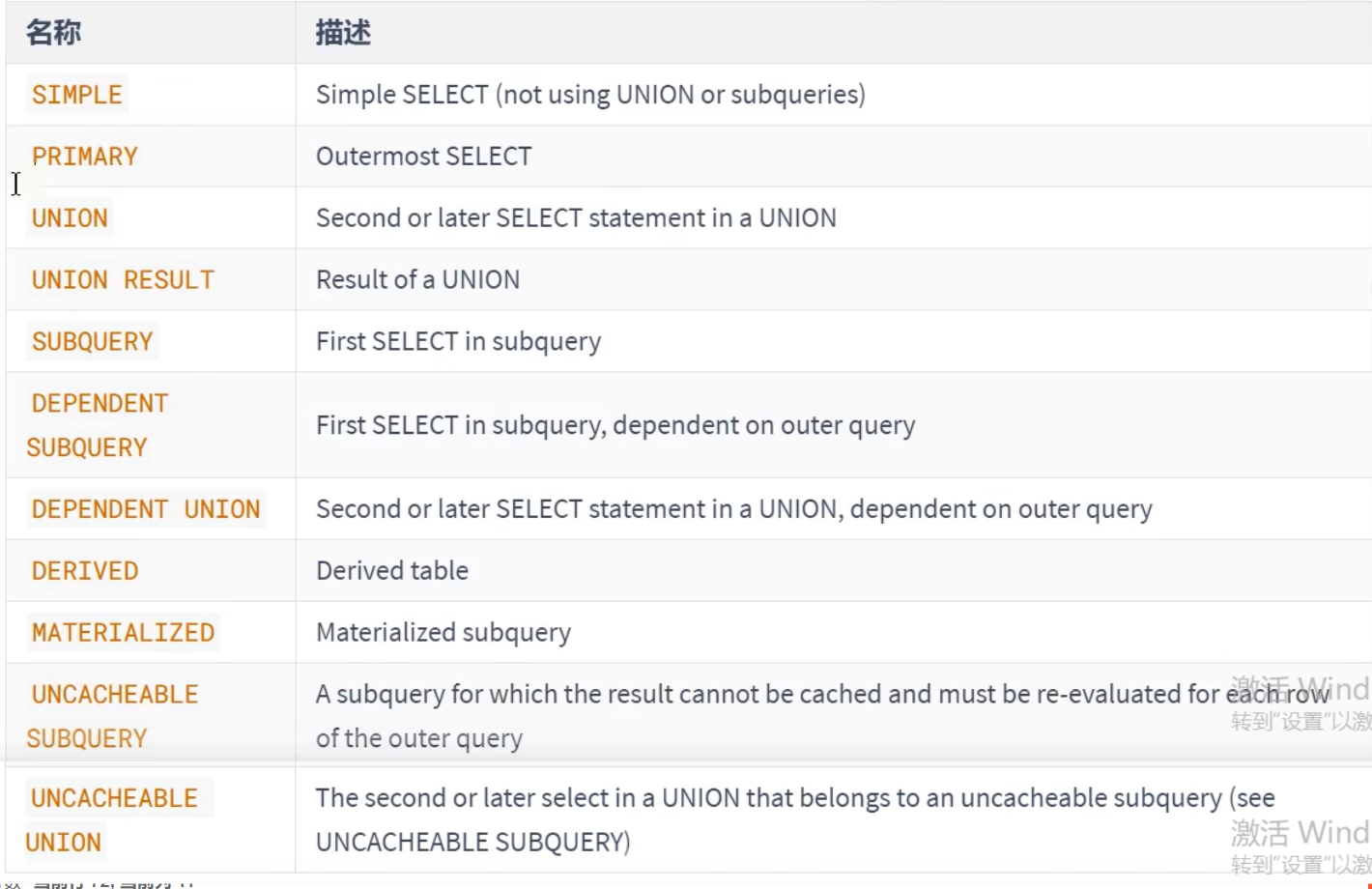
- select_type的SIMPLE

- select_type的PRIMARY和Union

- 最左边的是S1,所以是PRIMARY
- 其余的是S2,所以是Union
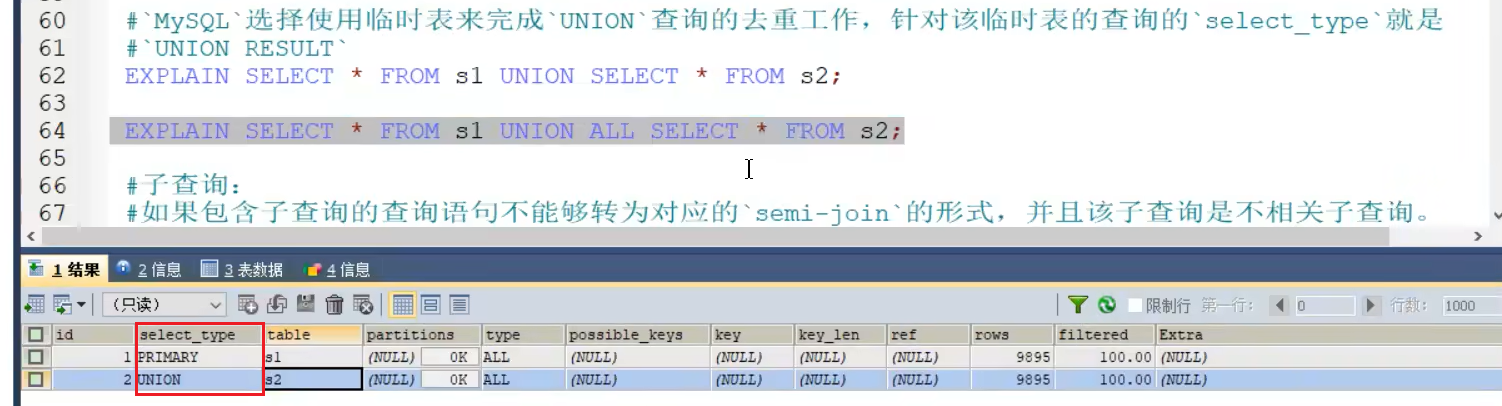
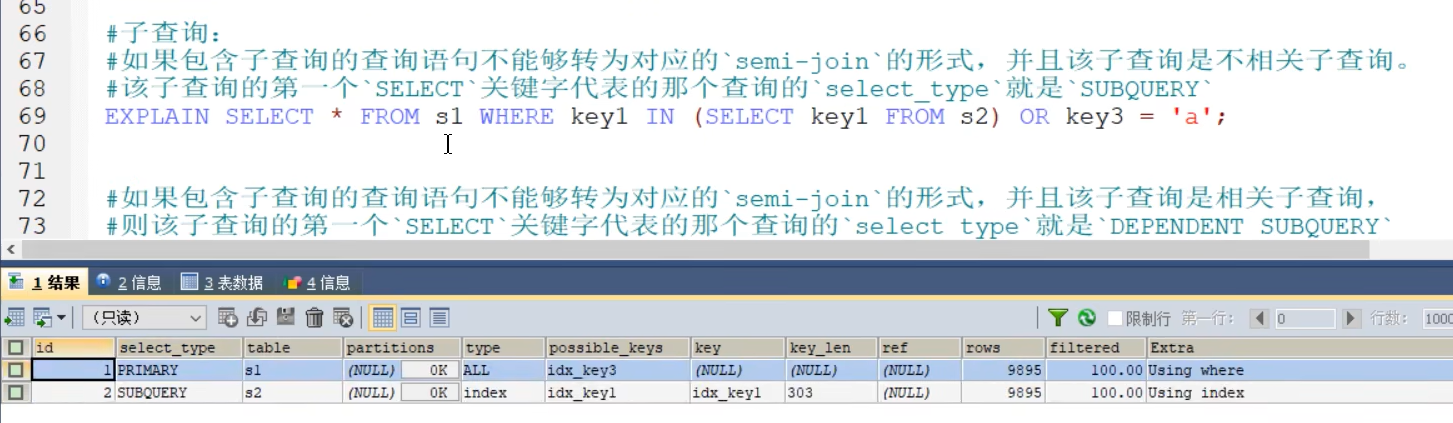
- select_type SUBQUERY
- 在外层的是PRIMARY,在内层的子查询是SUBQUERY
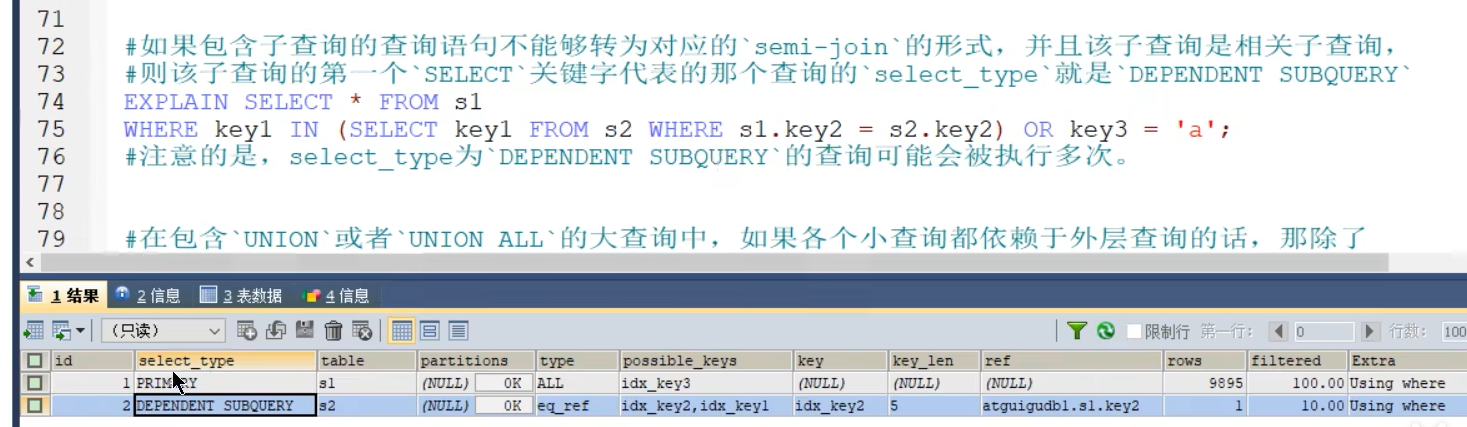
- DEPENDENT_SUBQUERY
- DEPENDENT_UNION
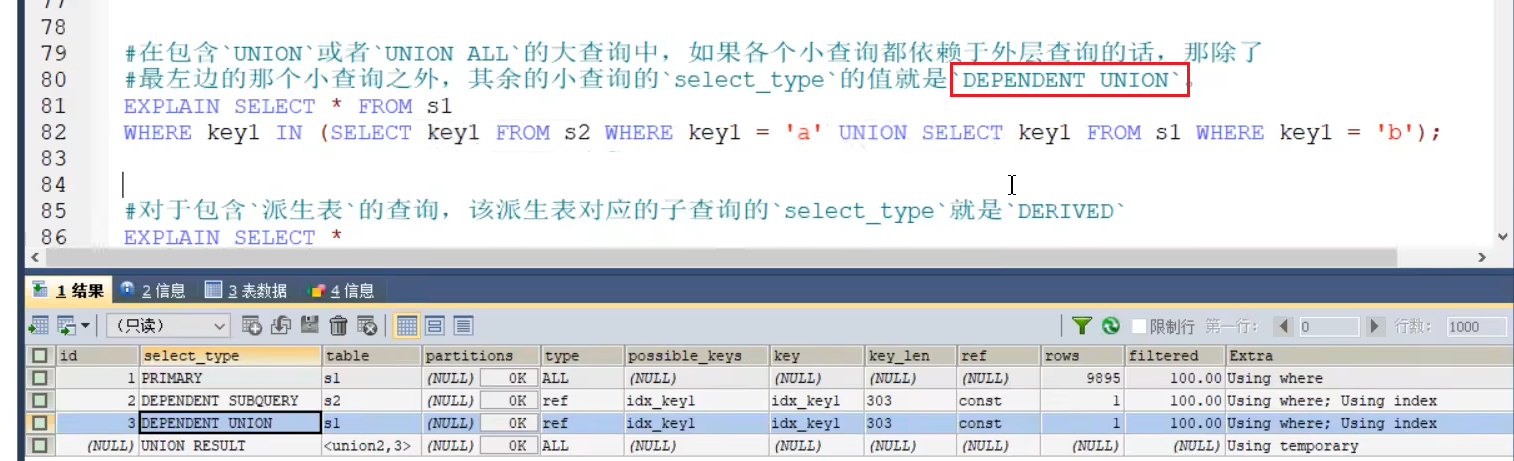
- DERIVED

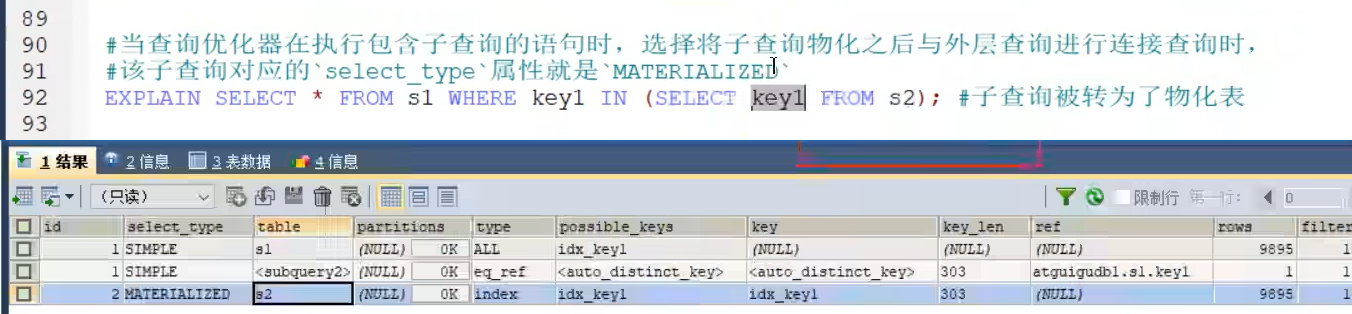
- MATERIALIZED
- partitions

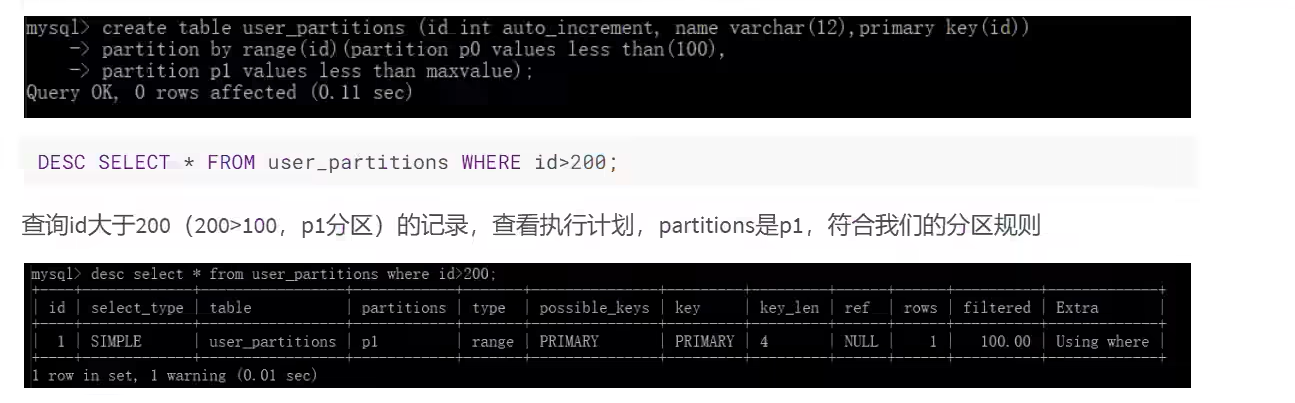
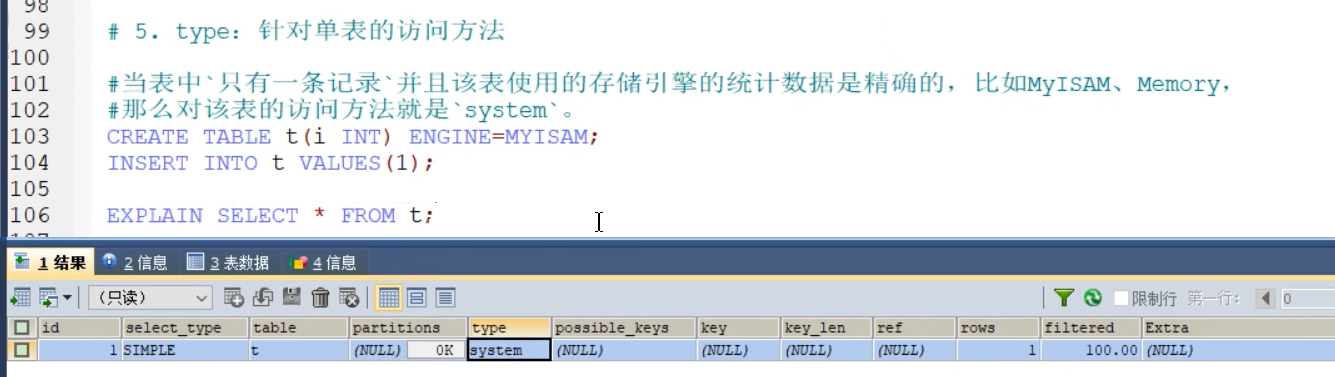
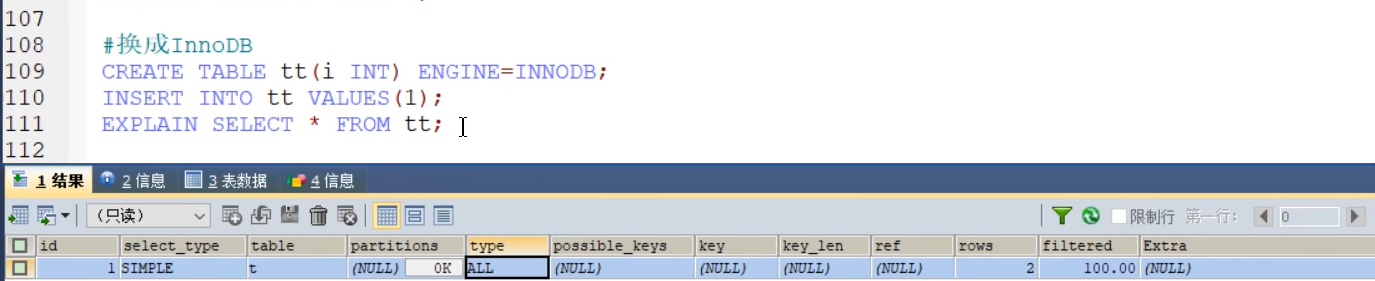
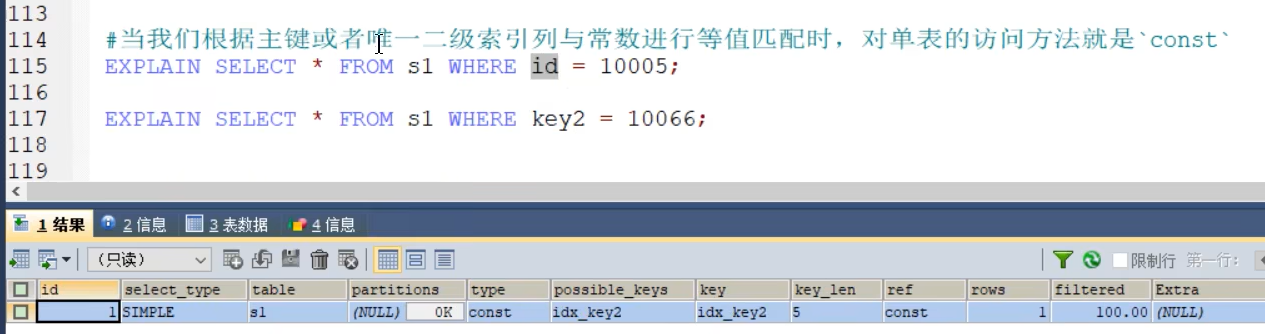
- type(重点)

- SYSTEM MyISAM统计是精确的
- ALL InnoDB统计是不精确的

- CONST
- EQ_REF
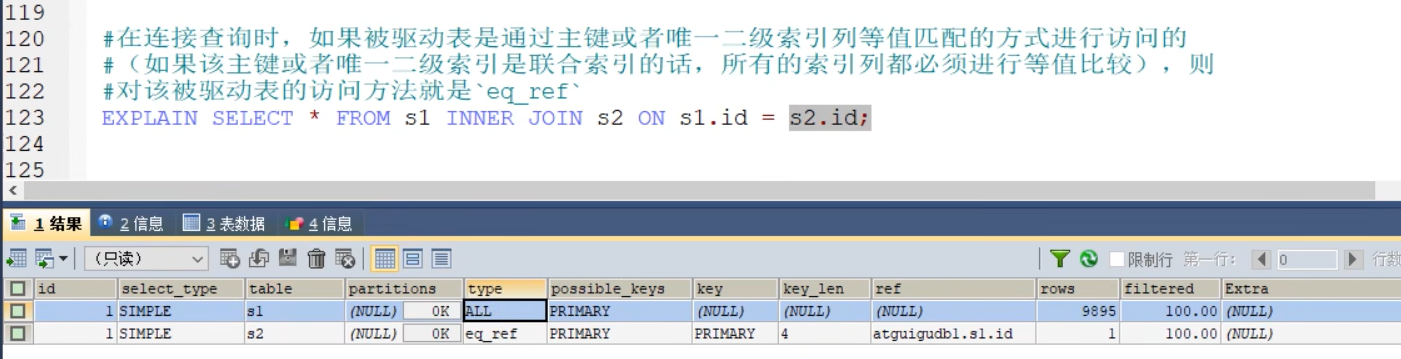
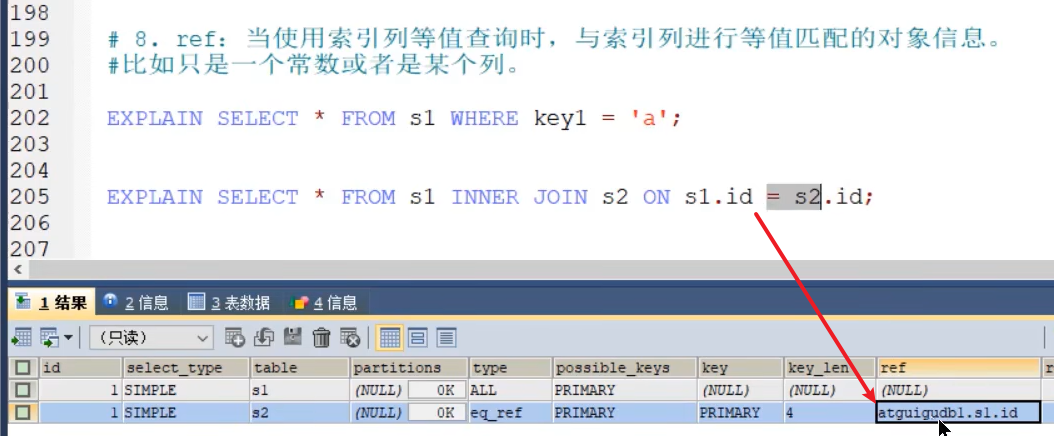
- ref

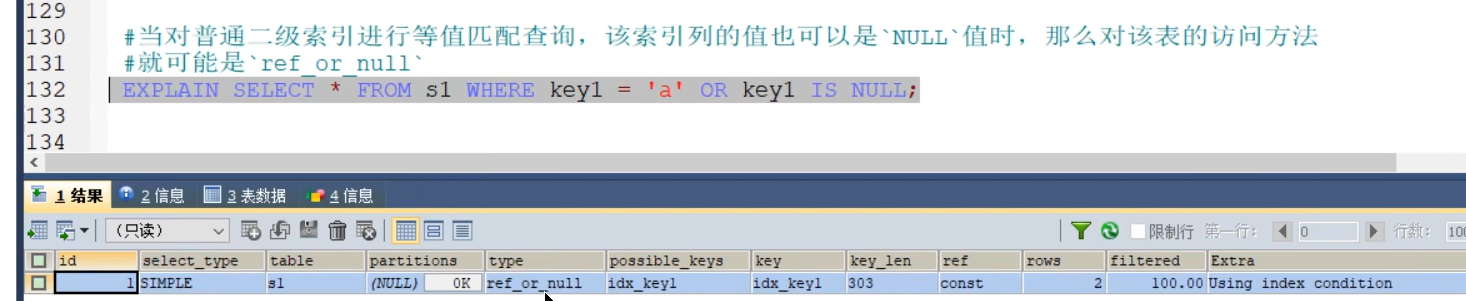
- ref or null
- index_merge

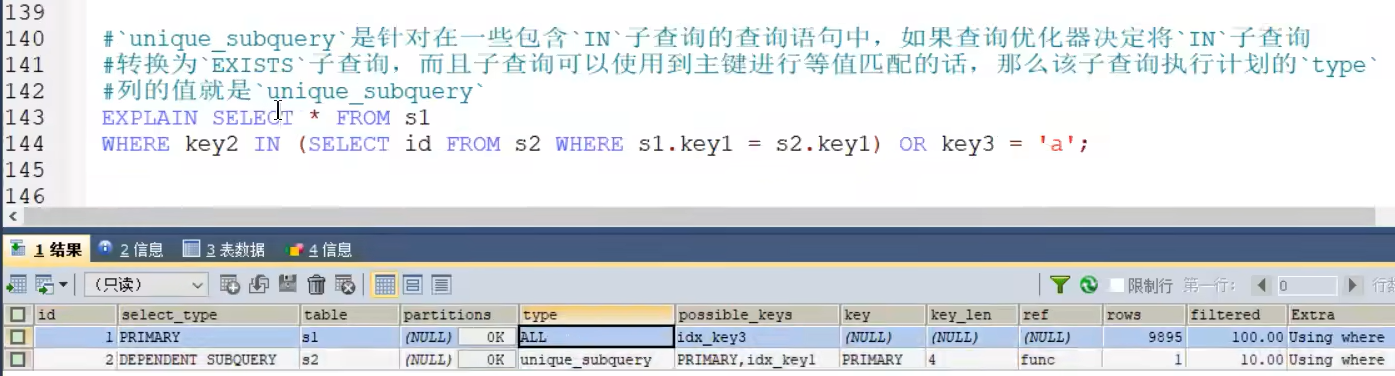
- UNIQUE_SUBQUERY
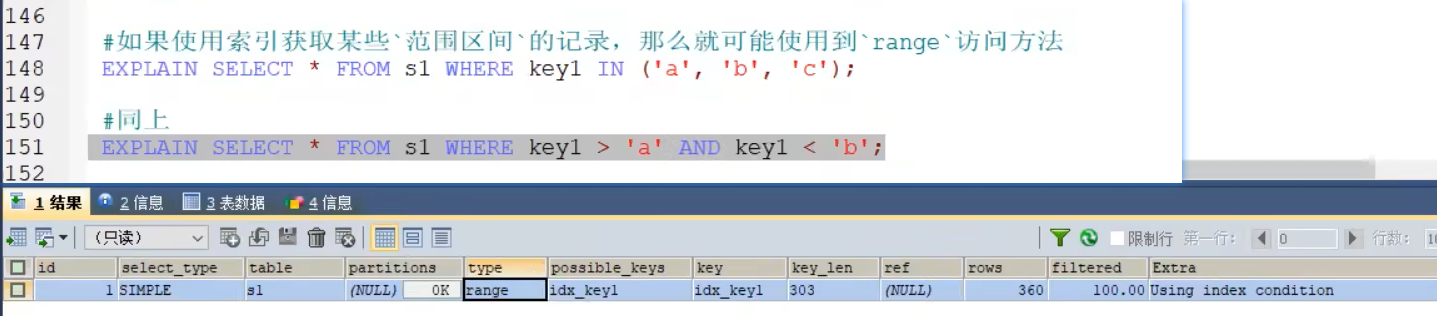
- RANGE
- INDEX

- 慢查询级别从好到坏

6.possible_key和key,可能用到的索引和实际用到的索引


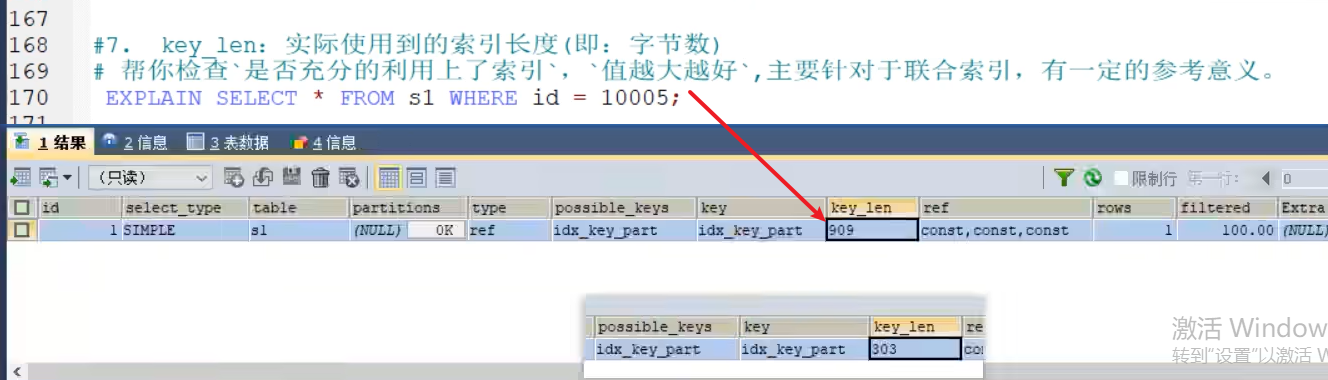
- key_len(重点)
- ref
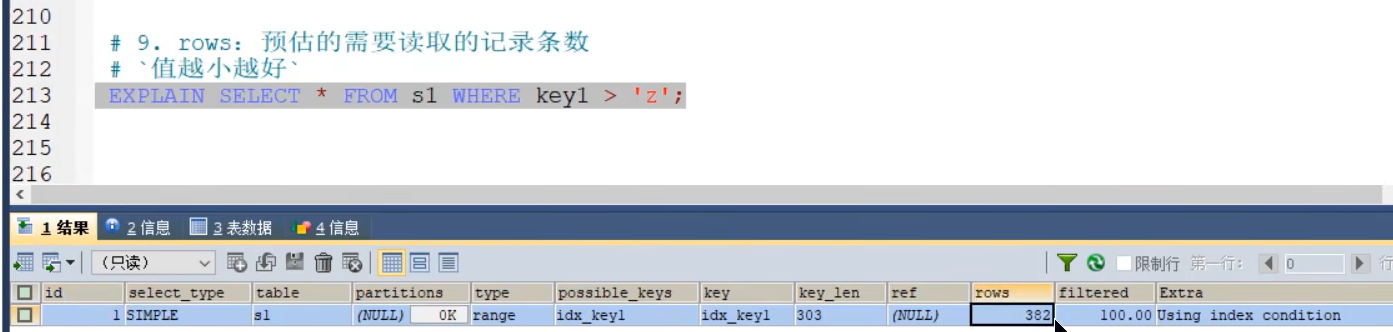
- rows(重点)预估的需要读取的记录条数
- filtered


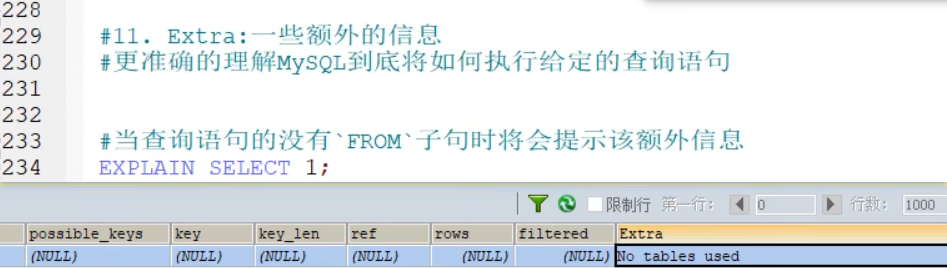
- Extra(重点)
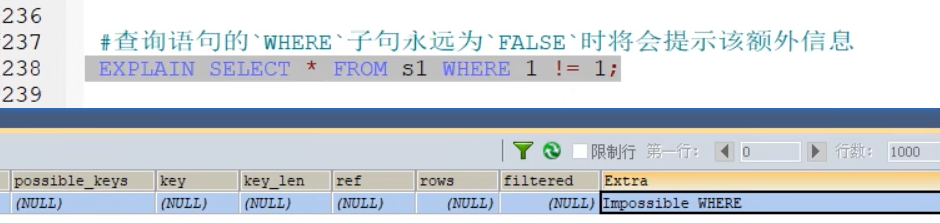
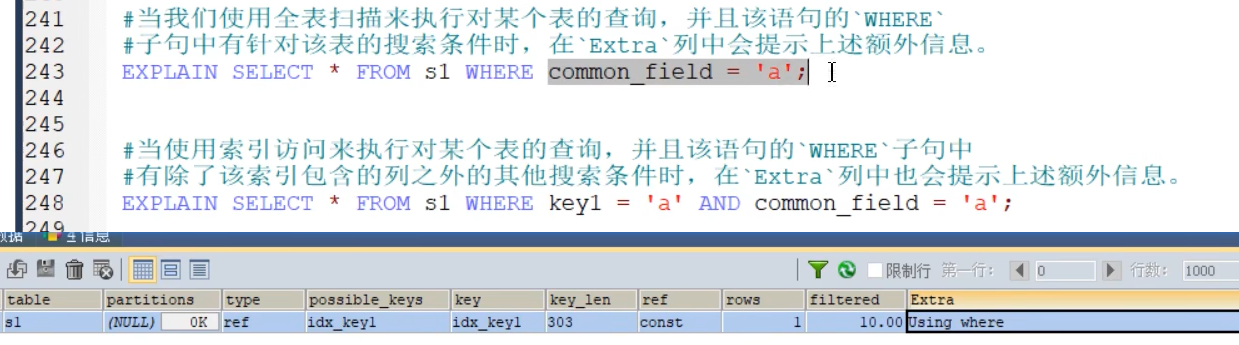









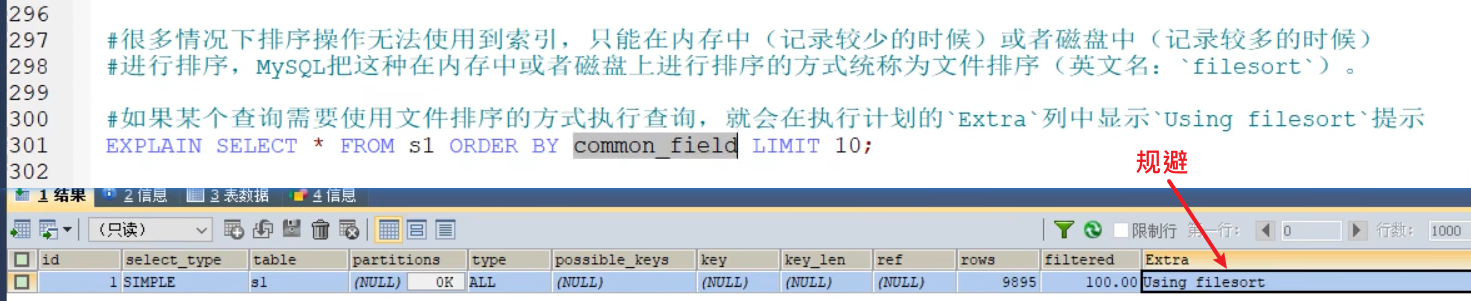
规避临时表

EXPLAIN的进一步使用
1.传统格式

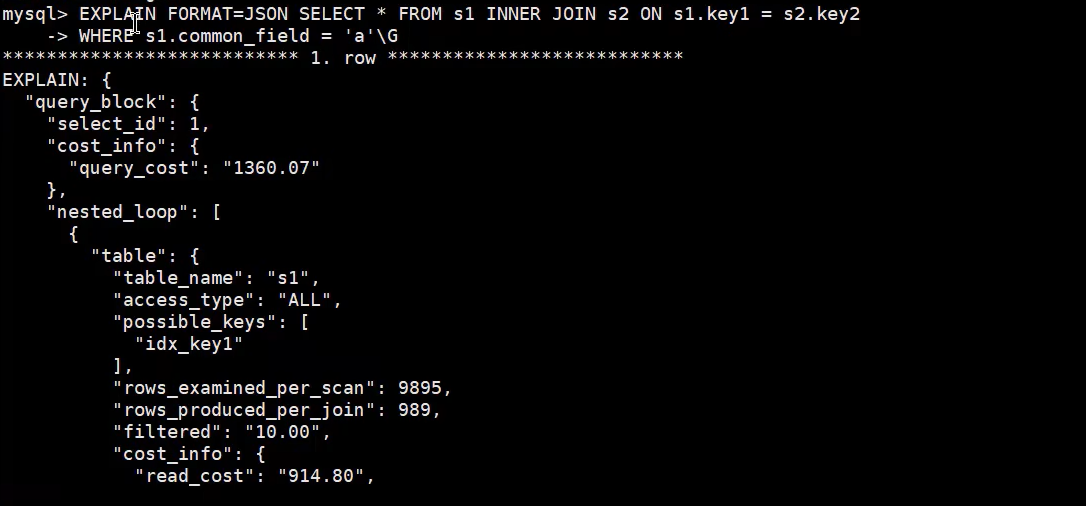
2.JSON格式
- TREE格式
