一、预训练的数据选择
模型影响力驱动(Influence / Importance-based Selection)
MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models
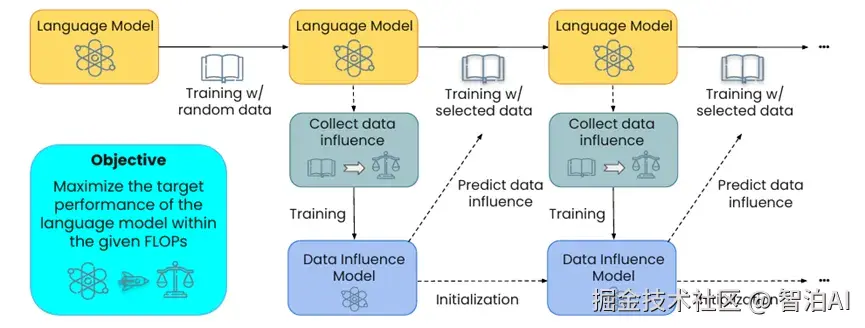
MATES创新性地设计了一种动态适应模型需求的数据筛选机制。
区别于传统静态过滤方法,该研究指出模型在训练进程中会持续改变对不同数据特征的"偏好倾向",因此数据筛选策略需实现与训练进度的同步动态优化。
其方法论核心在于建立"数据价值评估模型"。
实施流程包含:训练周期内通过周期性探测(probe)量化各数据样本对模型性能的实际贡献度,利用该评估结果训练轻量级预测模型,进而预判海量语料中每项数据的潜在价值权重。
在后续训练阶段中,系统将优先采用预测价值较高的数据样本。
跨多种规模语言模型的验证实验显示,相较于随机采样或静态规则过滤,MATES在多项任务中实现平均性能的显著提升,且达成同等性能所需的计算资源可降低约50%。
该成果证实:基于模型实时状态的动态数据筛选机制,相比固定规则策略具有显著优势,代表了预训练数据管理技术的重要发展方向。
更多AI大模型学习视频及资源,都在智泊AI。
质量 + 多样性平衡(Quality--Diversity Joint Methods)
Harnessing Diversity for Important Data Selection in Pretraining Large Language Models
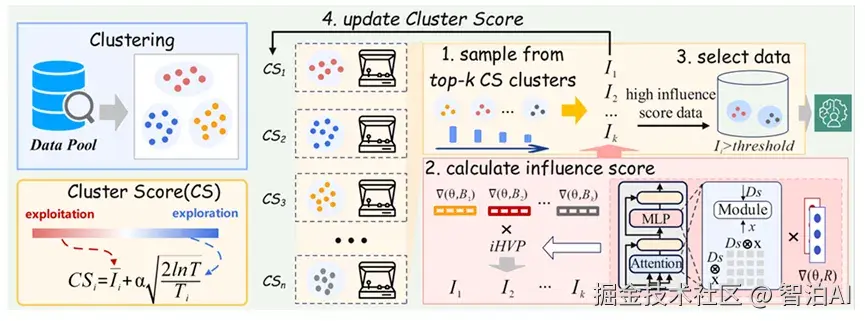
这篇论文聚焦于一个经典却易被忽略的挑战:仅依据"重要性"(如影响力或质量)筛选数据,往往会导致所选数据在语言风格、知识领域和语义分布上呈现高度同质化,进而削弱模型的泛化性能。
研究者提出的Quad方法创新性地通过同步优化数据的重要性和多样性来应对这一难题。
该方法首先采用高效的反向Hessian计算技术,量化每条数据对模型训练的影响权重。随后将语料库基于语义表示划分为多个簇,每个簇被建模为多臂赌博机问题中的一个独立"臂"。
在数据选择过程中,算法不仅优先筛选高影响力数据,还会主动挖掘那些被低频选择却具备潜在价值的簇,从而确保数据集的整体多样性。
实验验证显示,Quad在多个基准测试中均优于传统数据选择方法,并能显著增强模型的零样本学习能力。
该研究有力证明了在预训练数据筛选中,多样性与质量具有同等关键价值,同时提供了一个兼具可扩展性和实用性的解决方案。
QuaDMix: Quality--Diversity Balanced Data Selection for Efficient LLM Pretraining
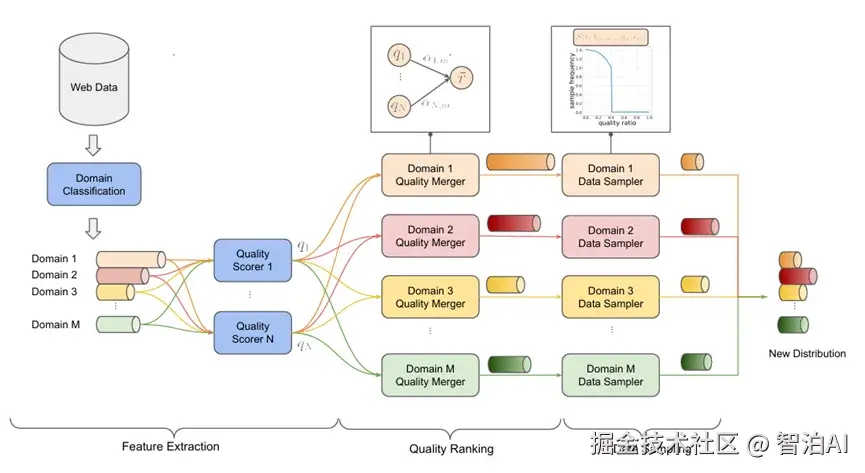
QuaDMix 的研究表明,在预训练数据选择中,"质量"与"多样性"的传统独立处理方式会导致显著失衡,典型表现为高质量数据在特定领域的过度集中。
针对这一问题,QuaDMix 创新性地开发了一个集成框架,通过参数化采样分布同步整合两个关键维度。
该方法实施包含三个核心步骤:
多维质量评估:对每项数据实施语言流畅性、文本复杂度及数据清洁度等多元指标量化
领域特征标注:采用分类算法明确数据所属领域类别
动态采样机制:基于"质量向量+领域标签"的复合函数计算采样概率,并通过小规模实验优化参数配置
实验数据证实,相较于单一优化质量或多样性的基准方法,QuaDMix 的协同优化策略在跨任务测试中实现了7%以上的性能增益。
这一成果验证了质量-多样性统一框架在数据筛选中的优越性。
Learning from the Best, Differently: A Diversity-Driven Rethinking on Data Selection

这篇论文对数据筛选的常规方法------"按评分排序并选取前k名(最高分数据)"------提出了质疑。
作者指出,该方法的局限性在于:评分体系往往融合了多个关联维度(如语言质量、知识密度、语义复杂度等),导致高分数据虽然在综合评分上表现优异,却容易在多个维度上呈现高度趋同,造成数据多样性的显著不足。
尤为严重的是,这种单一化的筛选策略甚至可能损害下游任务的表现。
针对这一问题,研究团队创新性地提出了ODiS(正交多样性感知选择框架)。其核心流程包括:
1)对数据进行多维度评估,涵盖语言质量(language quality)、知识/事实质量(knowledge quality)、语义理解难度(comprehension difficulty)等关键指标;
2)通过主成分分析(PCA)实现维度正交化处理,消除各维度间的相关性,确保特征独立性;
3)为每个正交维度训练独立评分模型,将PCA投影得分回归到数据层面,实现大规模语料的快速评分。
在构建训练集时,该方法并非简单选取总体评分最高的数据,而是从每个正交维度分别筛选高分数据(或按比例采样),从而既保证多维覆盖又维持数据多样性(因不同维度的最优数据通常具有差异性)。
实验结果表明,采用ODiS筛选的数据训练的模型,在多个下游任务中均显著优于传统单一评分基准。研究特别发现,当维度间重叠率被控制在2%以下时,模型性能表现更为稳定优异。
该研究的理论价值在于:颠覆了"高分即优质训练数据"的传统认知,系统论证了通过细分质量指标和主动引入多样性来提升模型泛化能力的重要性,而非盲目追求总分最高的数据。
多策略集成驱动(Collaborative / Ensemble Methods)
Efficient Pretraining Data Selection via Multi-Actor Collaboration
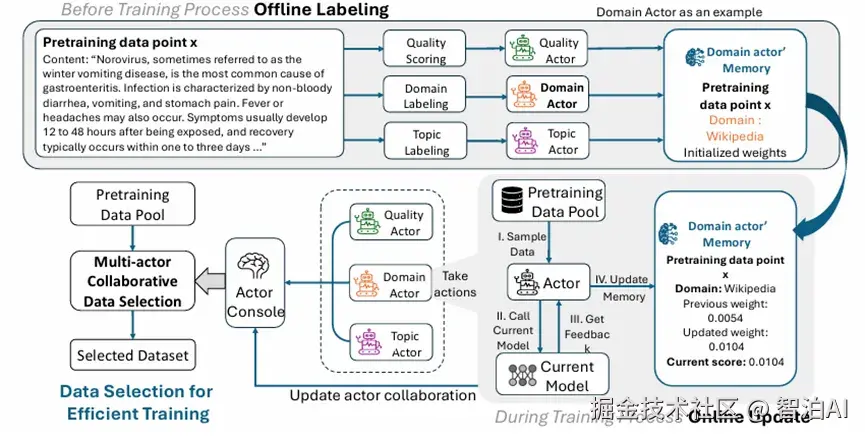
当前数据选择领域已发展出多种先进方法论(质量导向/影响力导向/多样性感知/领域混合等),如何通过协同整合这些方法以最大化优势并规避潜在矛盾?
研究团队创新性地设计了多智能体协同的数据筛选框架。
将各类数据选择策略视为独立运行的"智能体":例如,质量过滤智能体(quality filtering)专注数据纯度,多样性智能体(diversity)维护样本分布均衡。
影响力智能体(influence)评估数据对模型的关键作用,领域混合智能体(domain mixing)优化跨领域数据配比。
在预训练过程中,各智能体会基于实时模型状态动态更新其优先级规则(即根据当前模型性能自适应调整数据偏好)。
中央调度器则通过动态分配各智能体权重(决定不同训练阶段的主导策略),实现多维度信号的有效融合。
实验验证表明,相较于单一方法或固定组合策略,该多智能体协同机制不仅能显著提升预训练收敛速度,更在数据利用率上实现突破性改进。
这项工作为数据选择提供了更具适应性的系统化方案:无需局限于特定策略的取舍,而是将多元策略构建为专家协作网络,使系统能够自主选择与模型状态最优匹配的方法组合。
结构化知识/技能驱动(Skill- or Structure-aware Selection)
MASS: Mathematical Data Selection via Skill Graphs
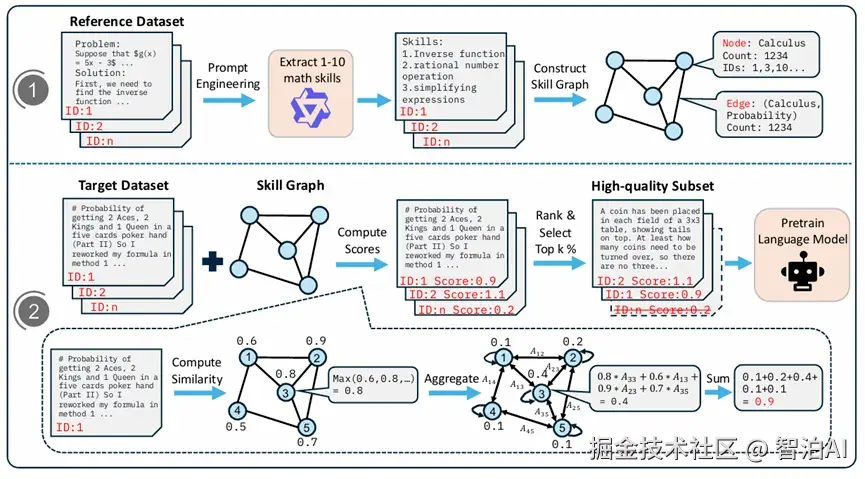
MASS 的核心创新在于数学与推理领域预训练数据的筛选机制。
研究团队指出,数学文本蕴含独特的结构特征与技能关联性,传统通用过滤方法难以精准识别这些特性。
为此,MASS 创新性地引入"技能图谱"(skill graph)框架,通过可视化数学能力间的拓扑关系实现数据价值量化评估。
该方法实施分为三个关键步骤:
1)从权威数学资源中提取基础数学技能(如代数、几何、微积分、证明推理等),建立以技能为节点、依赖关系为边的知识图谱;
2)对候选数学文本进行技能成分分析,将其与图谱进行匹配,综合计算覆盖技能的数量、层级权重和关键性指标;
3)依据多维评分体系对数据排序,筛选出对模型数学能力提升最具针对性的数据子集。
实验结果表明,采用MASS筛选数据的模型在数学推理任务中表现全面超越基准模型,尤其在数据规模缩减50%-70%的条件下,仍能实现4%-6%的性能提升。
这一验证充分证明,基于领域知识构建结构化技能图谱并指导数据选择,是优化模型专业能力的有效范式。
任务相关性驱动(Task-aware Data Selection)
Language Models Improve When Pretraining Data Matches Target Tasks
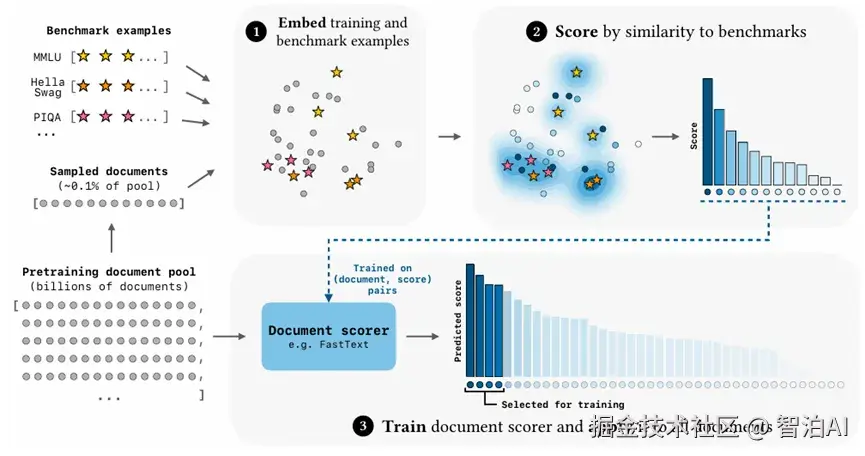
该研究聚焦于预训练语言模型的核心问题:当训练数据分布与目标任务高度一致时,模型性能能否实现显著优化。
研究者创新性地提出了一种高效数据筛选框架BETR(Benchmark-Targeted Ranking)
其核心机制包含三个步骤:首先将目标任务样本与预训练数据子集进行向量空间对齐,通过相似度计算建立初始排序;
继而借助轻量分类器将排序策略泛化至全量语料库;最终筛选出与目标任务分布匹配度最高的训练数据。
通过构建数百个实验模型并验证不同数据规模下的scaling law,研究发现BETR筛选的数据可使计算效率提升2倍以上,且模型表现显著优于原始数据或基础过滤方法。
在目标benchmark与下游任务存在分布偏移的场景中,BETR仍能保持与基准数据相当甚至更优的性能。
研究明确证实:预训练数据与任务需求的分布匹配度较数据规模更具决定性影响。采用可扩展的轻量级任务相关性排序方法,能够在维持计算成本的前提下显著提升模型质量。
二、后训练的数据选择
在线和离线数据选择结合
Towards High Data Efficiency in Reinforcement Learning with Verifiable Reward
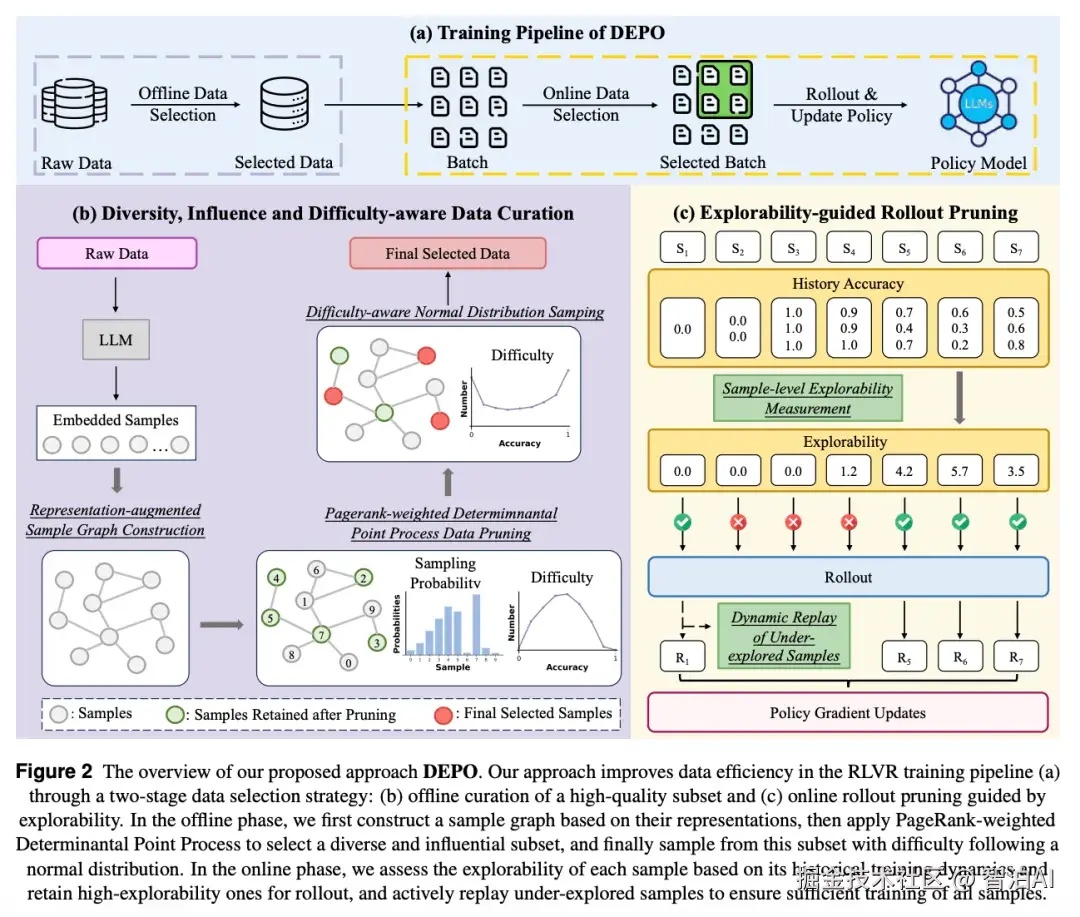
动机
当前RLVR方法依赖增加训练数据规模与rollout数量来增强模型推理能力,但这一方式显著提升了训练成本(计算资源消耗、时间投入)并降低了数据利用效率。
离线数据选择的局限性体现在:传统方法需在全量数据集上训练以评估数据选择指标(如奖励趋势分析、梯度对齐),计算负担沉重;或仅关注单一维度(如样本难度过滤),忽视样本间的关联性。
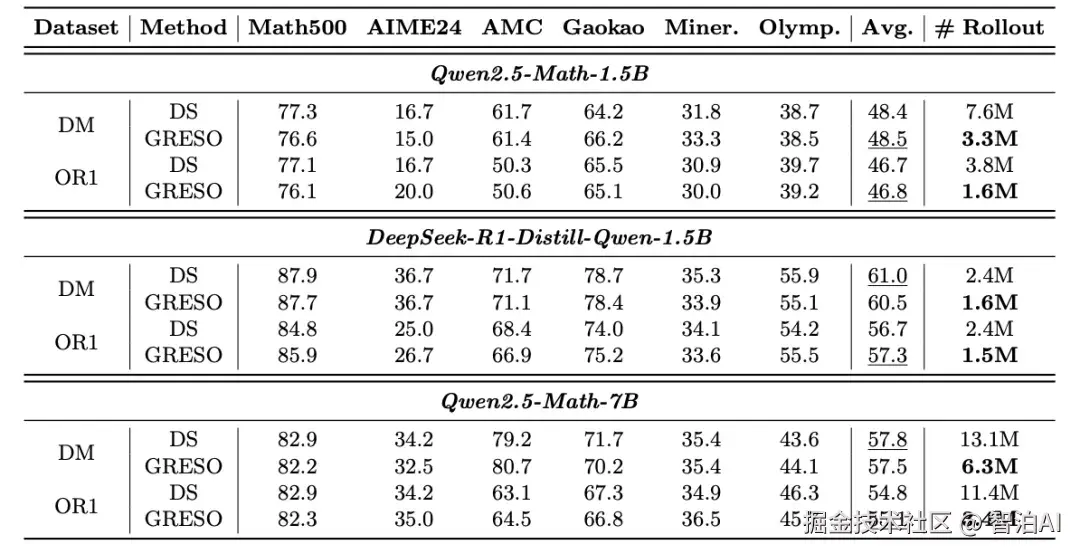
在线rollout效率问题:现有方法(以GRESO为例)仅能对零方差样本进行粗略筛选,无法有效识别具有高探索潜力的样本,导致大量计算资源被低贡献样本占用。
方法
多维度离线数据筛选框架
1.1 采用LLM最终层token嵌入构建样本表征空间,基于余弦相似度建立相似度图网络。
1.2 通过PageRank权重与行列式点过程协同优化,实现子集多样性与影响力的联合最大化。
1.3 对初步筛选后的子集执行策略离线rollout,以样本准确率量化难度指标,并按正态分布优先选取中等难度样本。
基于熵的在线rollout优化机制
2.1 设计滑动窗口内历史熵与优势函数的动态加权指标,精准识别高探索潜力样本进行在线rollout。
2.2 实施动态样本重放策略,确保训练覆盖所有样本的充分学习。
实验验证
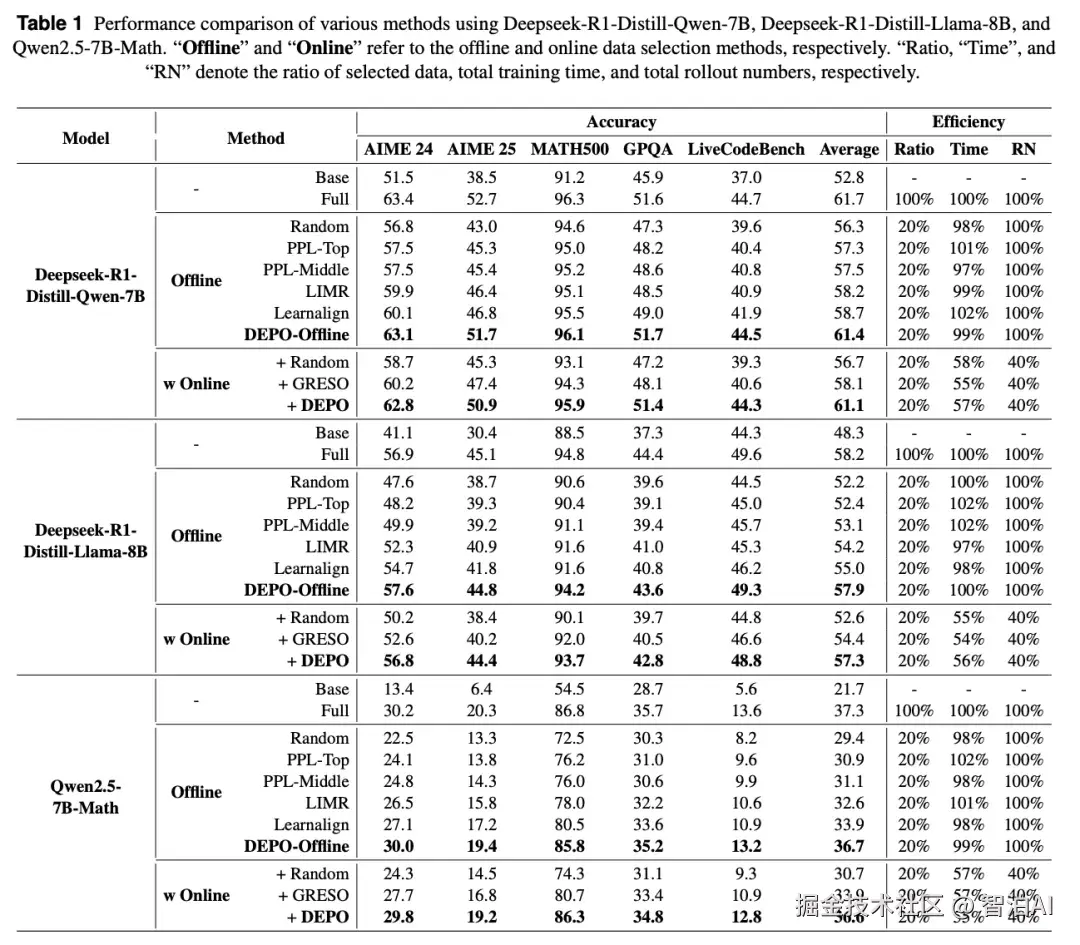
该方法仅需20%数据即可达到全量训练性能,同时实现训练耗时降低40%、rollout数量减少60%的优化效果。
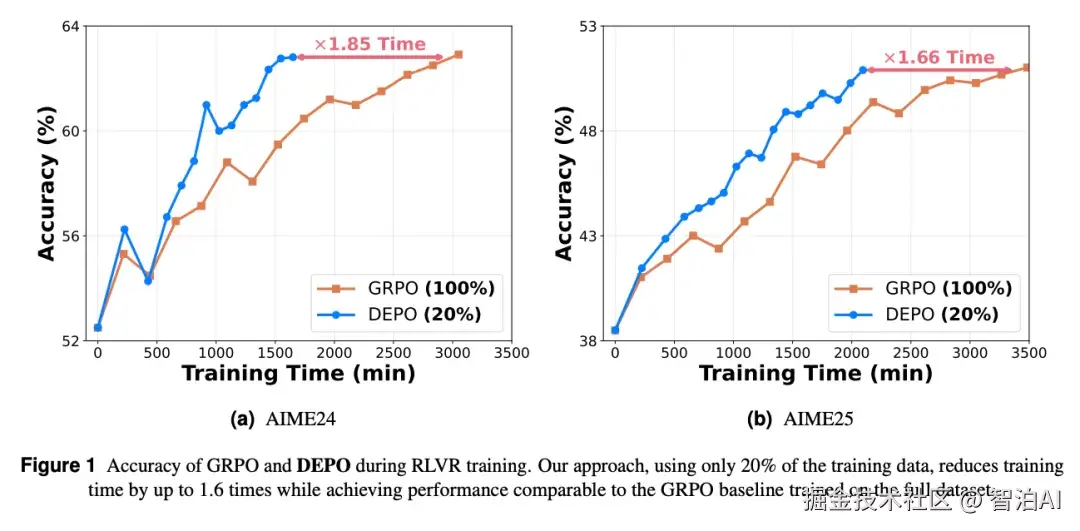
本文在三个模型和五个推理数据集上都进行了详细的实验,实验结果表明 DEPO 在各个数据集上都展现出强大的性能和效率优势。
在线数据选择
Act Only When It Pays: Efficient Reinforcement Learning for LLM Reasoning via Selective Rollouts
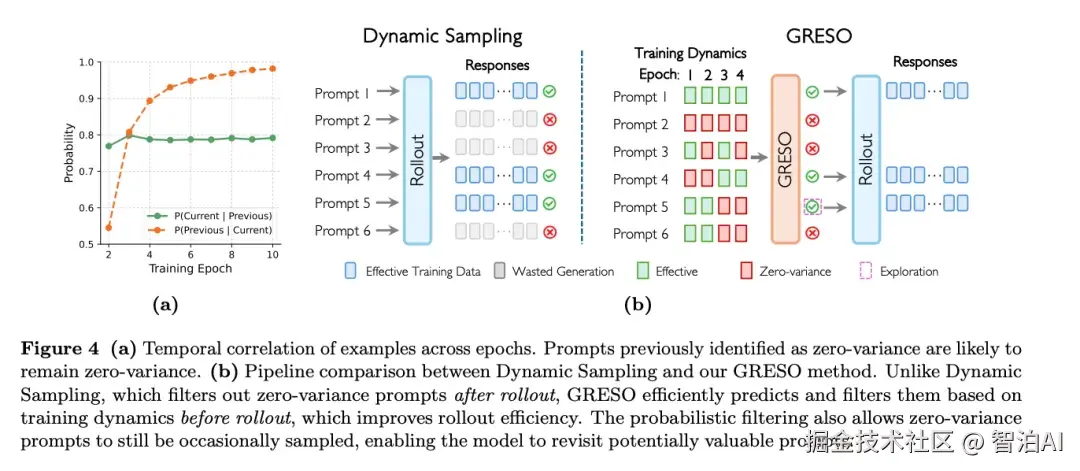
论文分析了提示在不同训练epoch中的奖励动态,发现零方差提示(即所有响应的奖励都相同的提示)在训练过程中具有很强的时间一致性。
自适应调整探索概率:采用了一种自适应机制来自动调整探索概率,根据目标零方差比例和实际观察到的零方差比例动态调整探索概率。
自适应采样批次大小:如果当前批次中有效提示的数量不足,算法会根据需要动态调整采样批次大小。
离线数据选择
LearnAlign: Reasoning Data Selection for Reinforcement Learning in Large Language Models Based on Improved Gradient Alignment
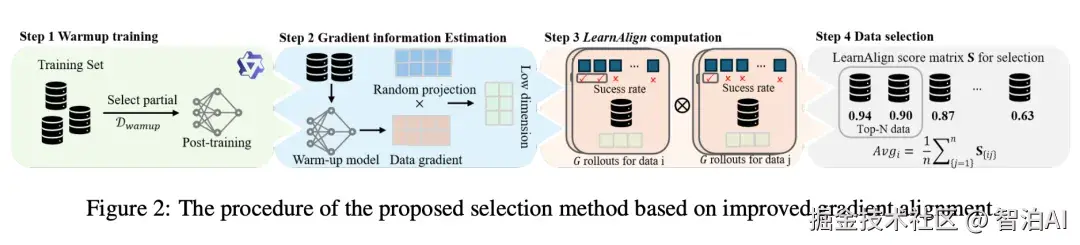
梯度对齐:研究通过一阶泰勒展开近似模型参数更新对损失函数的作用,将数据点间的影响力量化为两者梯度的内积值。
可学性:采用成功概率作为评估指标,表征数据点对模型性能优化的潜在贡献度。
LearnAlign分数:综合数据可学性与梯度对齐结果,生成该分数以量化数据点间的相似性及学习价值。
数据筛选流程
预热训练:随机抽取训练数据的小规模子集进行初始训练,为梯度估计提供稳定基础。
梯度信息处理:在预热阶段计算各数据点梯度,并通过随机投影实现降维。
分数矩阵构建:基于降维梯度数据,计算所有数据点对的LearnAlign分数,形成完整矩阵。
最终筛选:依据矩阵均值排序,选取得分最高的前N个数据点作为最优子集。
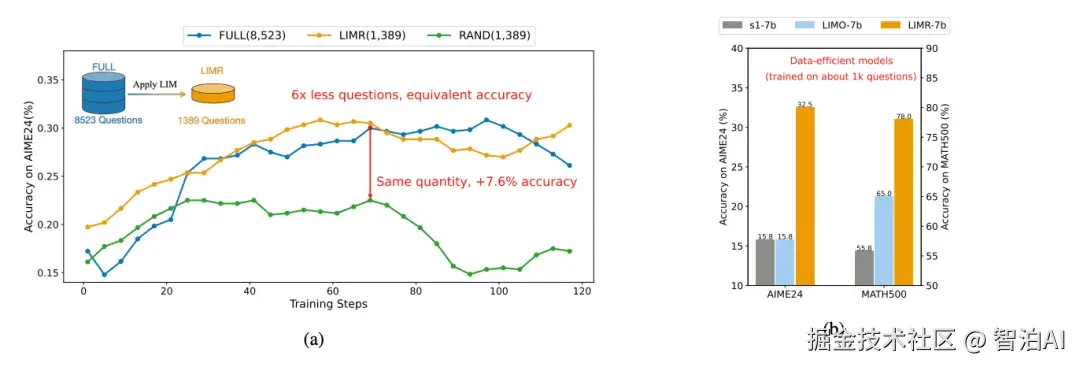
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
论文提出了"1-shot RLVR"的概念,旨在探究仅使用一个训练样本是否能够实现与使用大规模数据集相当的性能提升。
通过分析训练样本的历史方差得分,选择具有最高方差的样本作为训练数据。这种方法基于假设高方差样本在训练过程中可能提供更丰富的信息。
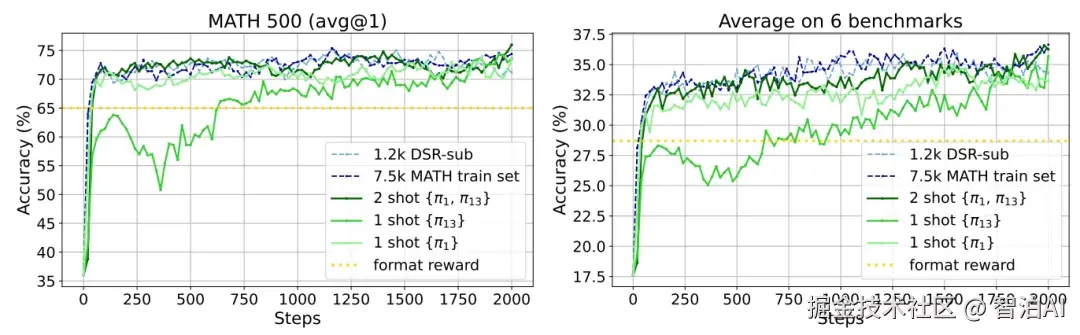
LIMR: Less is More for RL Scaling
以模型平均奖励曲线为基准,衡量单个样本学习轨迹与整体学习轨迹的匹配度。
通过归一化对齐分数评估样本对模型学习的贡献值,分数越高表明样本与模型学习路径的一致性越强,其对模型优化的促进作用也越显著。
Data-Efficient RLVR via Off-Policy Influence Guidance
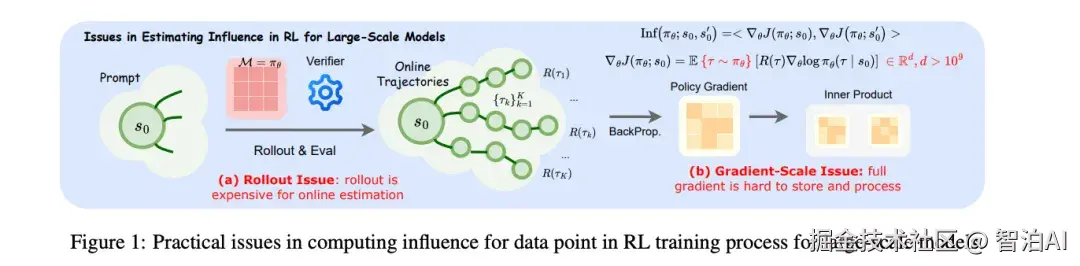
理论扩展与方法创新
将监督学习的影响函数理论推广至RLVR领域,建立训练样本对策略性能影响的一阶近似量化模型。
通过离策略估计技术,利用行为策略生成的离线轨迹替代实时策略梯度计算,实现完全离线化的高效训练流程。
计算优化技术
采用稀疏随机投影方法,在梯度运算前通过随机维度丢弃与低维变换,显著减少存储需求与计算复杂度,同时实验表明该方法能有效保持向量内积的排序特性。
框架设计与应用
基于上述理论构建多阶段课程学习系统CROPI,框架通过动态筛选验证集影响力最大的数据子集,分阶段实施GRPO算法更新策略,实现高效渐进式学习。
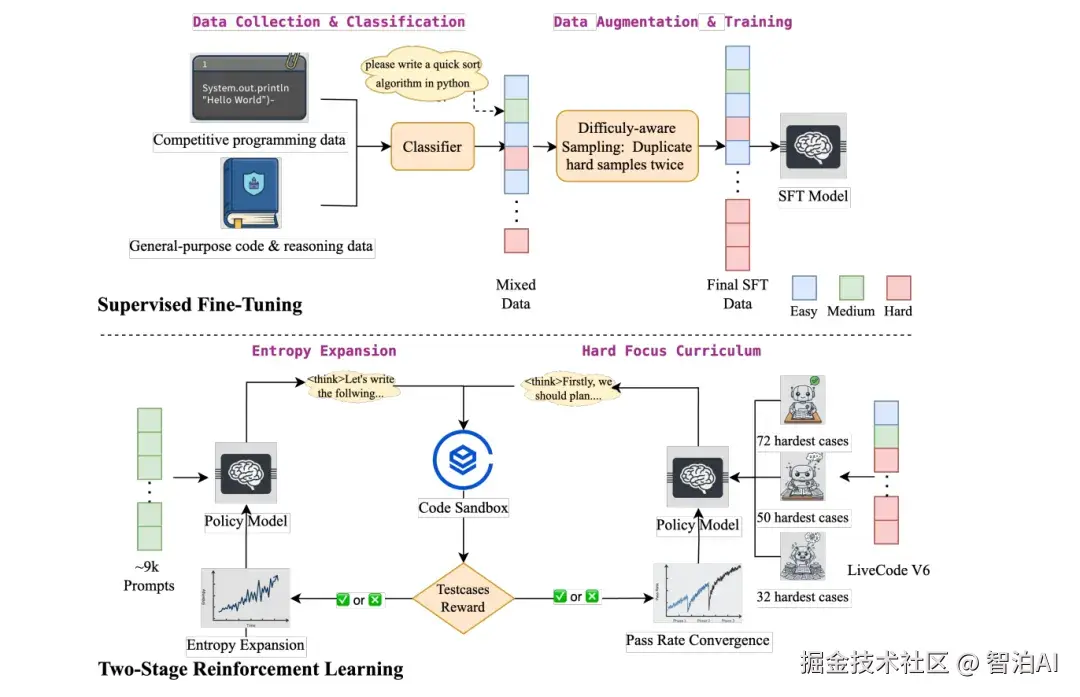
第一阶段:采用9k道均衡难度题目,每道题执行8次rollout训练,总序列长度24k,有效避免模型陷入模式固化;
第二阶段:筛选极端困难样本,通过64次rollout的阶梯式训练(分三阶段逐步强化),不断推动模型突破性能极限。
更多AI大模型学习视频及资源,都在智泊AI。