FPGA教程系列-Vivado Aurora 8B/10B IP核接口解析
IP核组成:
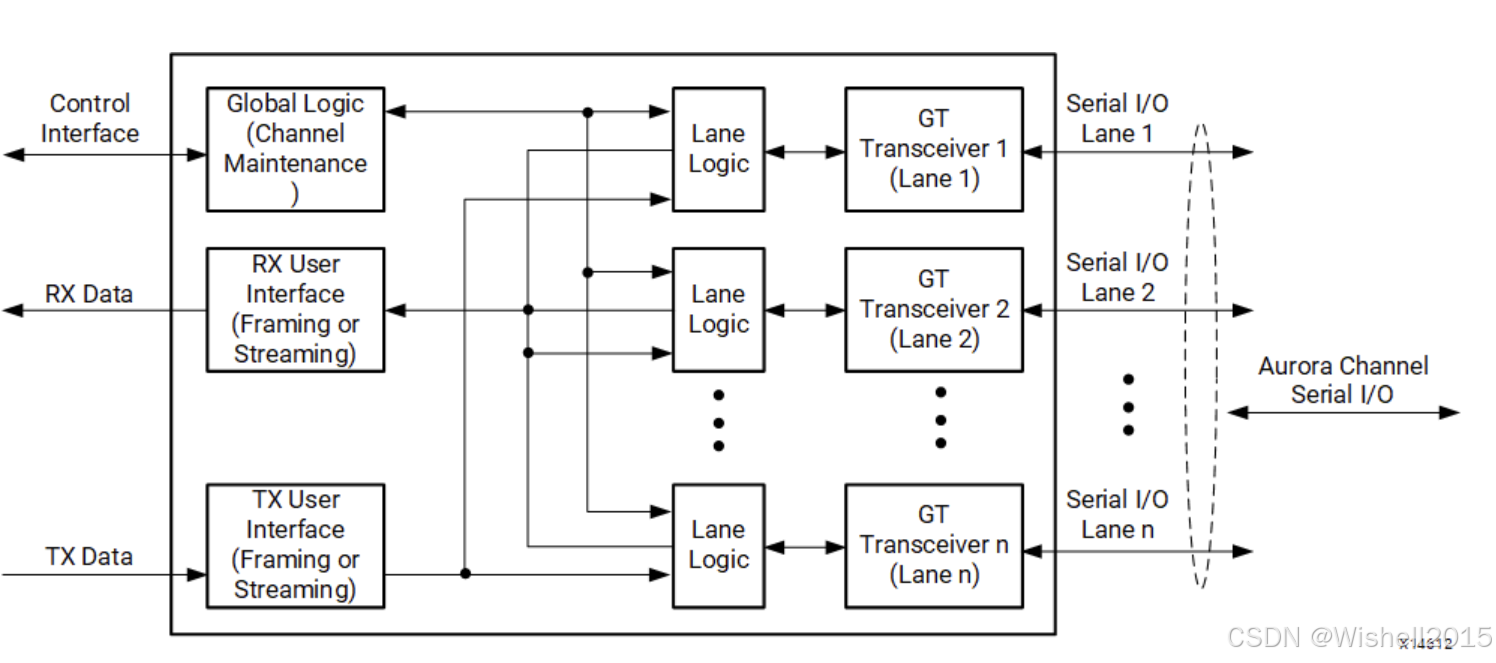
Lane Logic:每个GTP、GTX或GTH收发器均由一个通道逻辑模块实例驱动,该模块负责初始化各个收发器,并处理控制字符的编解码及错误检测。
Global Logic:全局逻辑模块完成通道初始化的绑定与验证阶段。在运行期间,该模块生成Aurora协议所需的随机空闲字符,并监控所有通道逻辑模块是否出现错误。
RX User Interface:AXI4-Stream接收(RX)用户接口将数据从通道传送到应用层,并执行流控功能。
TX user interface:AXI4-Stream发送(TX)用户接口将数据从应用层传送到通道,并执行发送端的流控功能。标准的时钟补偿模块内嵌于核内,该模块控制时钟补偿(CC)字符的周期性发送。
延迟
下图为默认配置下数据通路的延迟。延迟会根据设计中使用的收发器和 IP 配置而变化。

在默认内核配置的功能仿真中,一个双字节成帧设计从 s_axi_tx_tvalid 到 m_axi_rx_tvalid 的最小延迟约为 37 user_clk 个周期(见下图)。
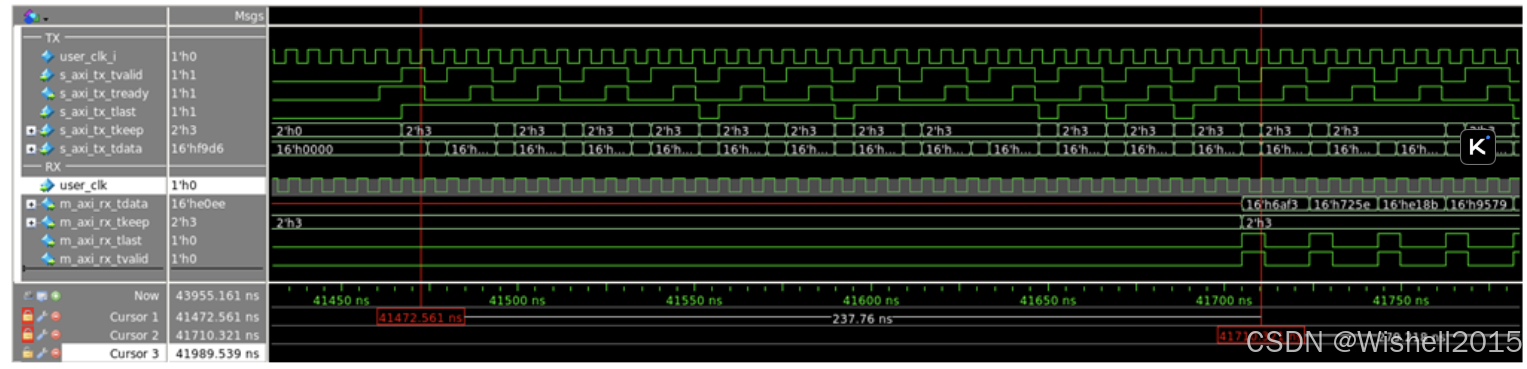
在功能仿真中,默认四字节成帧设计从 s_axi_tx_tvalid 到 m_axi_rx_tvalid 的最小延迟约为 41 user_clk 个周期。设计流水线延迟是为了保持时钟速度。如果不存在依赖性,请检查是否可以通过其他可选功能来增加延迟。
吞吐率
Aurora 8B/10B IP核吞吐率取决于GT收发器的数量和线速率。 单通道设计到16通道设计的吞吐率分别为0.4Gb/s到84.48Gb/s。 通过Aurora 8B/10B协议编码和0.5Gb/s至6.6 Gb/s线路速率范围的20%开销来计算吞吐率。
也就是说,使用的GT高速收发器的通道越多、且其支持的线速率越高,则整个Aurora 8B/10B IP核的吞吐率越高,但是要注意乘以80%,因为8B/10B编码存在20%的开销。
用户接口

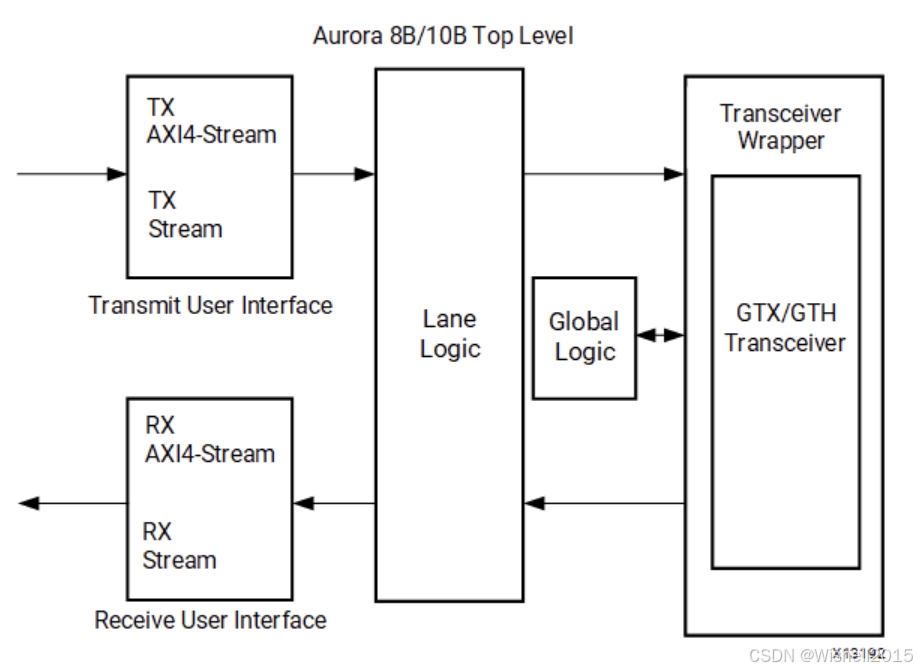
Aurora 8B/10B 内核可通过成帧或流式用户数据接口生成。该接口包括流式或成帧数据传输所需的所有端口。成帧用户接口符合 AMBA AXI4-Stream 协议规范 AMBA AXI4-Stream 协议规范(v1.0),包括传输和接收成帧用户数据所需的信号。与成帧接口相比,流接口允许在没有帧分隔符的情况下发送数据,操作更简单,使用的资源也更少。数据端口宽度取决于所选的通道宽度和通道数。
Aurora 8B/10B 内核顶层(块级)文件实例化了线路逻辑模块、TX 和 RX AXI4-Stream 模块、全局逻辑模块和收发器封装器。同时实例化的还有示例设计中的时钟、复位电路、帧发生器和校验器模块。
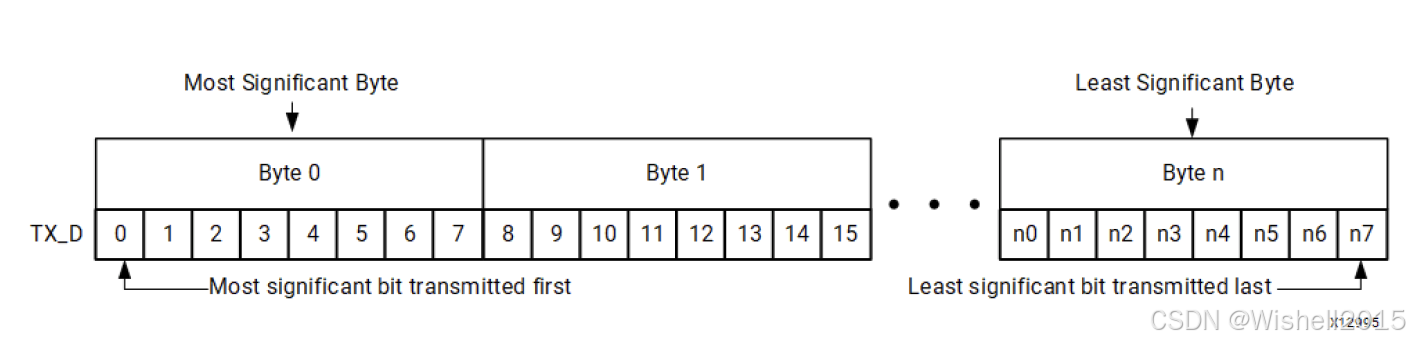
Aurora 8B/10B核心的AXI4-Stream位序规则
采用 "升序排列" 原则,具体表现为:
- 字节级:先传输最高有效字节(MSB),后传输最低有效字节(LSB)
- 位级:每个字节内先传输最高有效位(MSB),后传输最低有效位(LSB)
TX接口:
| 名称 | 方向 | 时钟域 | 描述 |
|---|---|---|---|
| USER_DATA_S_AXI_TX | |||
| s_axi_tx_tdata0:(8n-1) 或 s_axi_tx_tdata(8n-1):0 | 输入 | user_clk | 出站数据。n 是通过"通道数 × 通道宽度"计算得到的字节数。 |
| s_axi_tx_tready | 输出 | user_clk | 当源信号被接收且出站数据准备好发送时置位。 |
| s_axi_tx_tlast¹ | 输入 | user_clk | 标识帧的结束。 |
| s_axi_tx_tkeep0:(n-1) 或 s_axi_tx_tkeep(n-1):0 ¹ | 输入 | user_clk | 指定最后一个数据节拍中有效字节数;仅当 s_axi_tx_tlast 置位时有效。s_axi_tx_tkeep 是字节限定符,用于指示关联的 s_axi_tx_tdata 字节内容是否有效。Aurora 8 B/10 B 内核期望数据从 LSB 到 MSB 连续填充。有效 s_axi_tx_tdata 总线上不能交错无效字节。 |
| s_axi_tx_tvalid | 输入 | user_clk | 当出站的 AXI4 - Stream 信号或源信号有效时置位。 |
RX接口:
| 名称 | 方向 | 时钟域 | 描述 |
|---|---|---|---|
| USER_DATA_M_AXI_RX | |||
| m_axi_rx_tdata0:8(n-1) 或 m_axi_rx_tdata8(n-1):0 | 输出 | user_clk | 来自通道伙伴的传入数据(升序位顺序)。 |
| m_axi_rx_tlast¹ | 输出 | user_clk | 表示传入帧的结束(在一个用户时钟周期内断言)。 |
| m_axi_rx_tkeep0:(n-1) 或 m_axi_rx_tkeep(n-1):0¹ | 输出 | user_clk | 指定最后一个数据节拍中有效字节数。 |
| m_axi_rx_tvalid | 输出 | user_clk | 当来自 Aurora 8B/10B 核心的传出数据和控制信号或数据和控制信号有效时断言。 |
Framing 接口
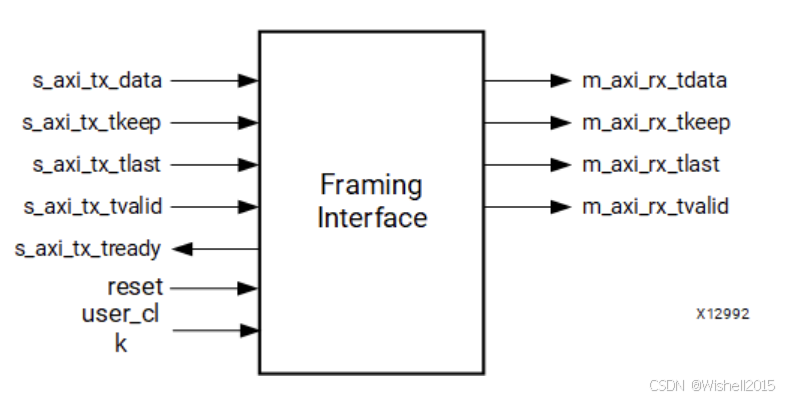
发送数据 :
要发送数据,用户应用通过操纵控制信号,使核完成以下操作:
- 当
s_axi_tx_tvalid和s_axi_tx_tready信号同时有效时,从用户接口的s_axi_tx_tdata总线上取走数据。 - 将数据按 Aurora 8B/10B 通道的通道条带化(stripe)方式分发到各条 lane。
- 利用
s_axi_tx_tvalid信号来发送数据。用户应用可随时拉低s_axi_tx_tvalid,在线路上插入空闲字符(即产生停顿或暂停)。 - 暂停数据(即插入空闲字符)时,
s_axi_tx_tvalid被拉低。
当核接收到数据时,会执行以下动作:
- 检测并丢弃控制字节(空闲字符、时钟补偿字符、通道 PDU 起始符 SCP、通道 PDU 结束符 ECPDU 以及 PAD)。
- 拉高帧结束信号
m_axi_rx_tlast,并通过m_axi_rx_tkeep指明最后一拍数据中有效字节数。 - 从各条 lane 中恢复数据。
- 通过拉高
m_axi_rx_tvalid信号,把重组后的数据呈现在m_axi_rx_tdata总线上,供用户接口读取。
Aurora 8B/10B 核只在 s_axi_tx_tready 与 s_axi_tx_tvalid 同时有效(高电平)时才采样数据。
AXI4-Stream 数据仅在"帧内"才有效;帧外数据会被忽略。
启动帧:当第一拍数据出现在 s_axi_tx_tdata 端口时,拉高 s_axi_tx_tvalid。
结束帧:当最后一拍(或部分拍)数据出现在 s_axi_tx_tdata 端口时,拉高 s_axi_tx_tlast,并用 s_axi_tx_tkeep 指明最后一拍的有效字节数。
若帧长度仅为单拍或更短,则 s_axi_tx_tvalid 与 s_axi_tx_tlast 同时拉高。
帧结构
TX子模块将每个接收的用户帧通过TX接口转换为Aurora 8B / 10B帧。 帧开始(SOF)通过在帧开始处添加2字节的SCP代码组来指示。 帧结束(EOF)是通过在帧的末尾添加一个2字节的信道结束通道协议(ECP)码组来确定。 数据不可用时插入空闲代码组。 代码组是8B / 10B编码字节对,所有数据都作为代码对发送,因此具有奇数个字节的用户帧具有称为PAD的控制字符,附加到帧的末尾以填写最终的代码组。 下图显示了具有偶数数据字节的典型Aurora 8B / 10B帧。

通过操纵 s_axi_tx_tvalid 与 s_axi_tx_tlast 信号来决定每帧长度;Aurora 8B/10B 核自动在物理层插入 /SCP/ 和 /ECP/ 有序集。
发送案例
A、Simple Data Transfer
下图给出了一个 n 字节宽 AXI4-Stream 接口上的简单数据传输示例。本次共发送 3n 字节数据,因此需要 3 个数据拍(beat)。信号 s_axi_tx_tready 为高,表明接口已准备好发送数据。
- 用户应用在第一个 n 字节期间拉高
s_axi_tx_tvalid,启动传输。 - 通道的头 2 字节首先放入
/SCP/有序集,标示帧开始;随后放入前 n--2 个有效数据字节。 - 由于
/SCP/占了 2 字节偏移,每一拍最后 2 字节都会被推迟一个时钟周期,并在下一拍的头 2 字节位置发出。
结束传输时:
- 用户应用拉高
s_axi_tx_tlast,同时给出最后的数据字节,并在s_axi_tx_tkeep上给出有效字节掩码。本例波形中s_axi_tx_tkeep设为 N,表示最后一拍全部字节有效。 - 当
s_axi_tx_tlast被置位后,核在下一时钟周期拉低s_axi_tx_tready,利用这段数据流空隙发出剩余的偏移数据字节以及/ECP/有序集,标示帧结束。 - 再下一周期,
s_axi_tx_tready重新拉高,允许新的数据传输继续。
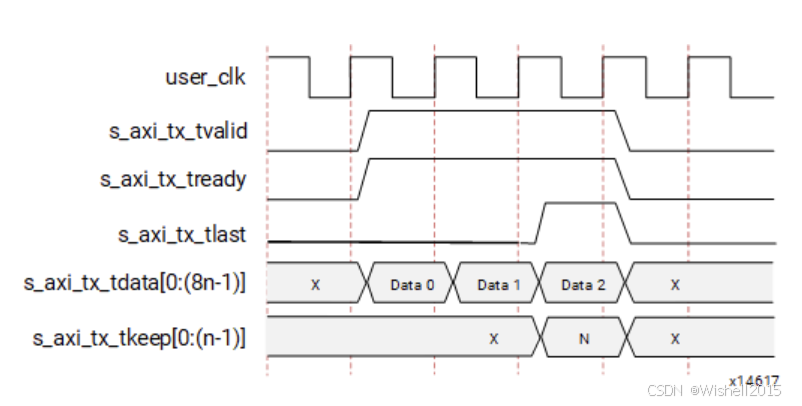
举例说明:总线宽度 n=4n = 4n=4 字节 (32-bit)。要发送 :一个完整的包,总共 12 个字节 。数据拆分:因为总线宽 4 字节,所以 12 字节正好拆分成 3 次传输(Data 0, Data 1, Data 2)。
- 启动传输 (Data 0)
准备好数据,将 s_axi_tx_tvalid 拉高(置 1) ,并把 Data 0 放在总线上。Aurora 核心也是空闲的,它把 s_axi_tx_tready 拉高(置 1) 。tvalid 和 tready 同时为高,握手成功。
信号细节 :此时 tlast 是 0,因为这才刚开始,后面还有数据。
- 中间传输 (Data 1)
在下一个时钟上升沿,把数据切换为 Data 1。tvalid 保持为 1(还有数据),tready 保持为 1(核心还能收)。
信号细节 :tlast 依然是 0。
- 结束传输 (Data 2) ------ 关键帧
发送最后 4 个字节 Data 2。
-
s_axi_tx_tlast 拉高(置 1) :这非常重要。你告诉核心:"这是这个数据包的最后一块了,发完这个就结束这帧。" -
s_axi_tx_tkeep 显示为 N :这里的N代表"满的"。因为我们发送的是 12 字节,正好是 4 的倍数,所以最后一个周期 4 个字节全部有效。不需要处理无效字节。
后续 :在 Data 2 传输完成后,tvalid 被拉低,传输结束。
B、Data Transfer with Pad
以下示例展示了一次长度为 3n -- 1 字节 的数据传输,由于字节数为奇数,根据 Aurora 8B/10B 协议要求,需要填充一个 PAD 字符。
-
总数据量为 3n -- 1 字节 ,因此需要:两个完整的 n 字节 数据拍(beat);一个 部分有效 的最后一拍,仅包含 n -- 1 字节 有效数据。
-
用户通过在最后一拍设置
s_axi_tx_tkeep = N--1,向核心指明最后一拍只有前 n -- 1 字节有效。 -
Aurora 8B/10B 核心在内部自动完成:
- 在最后一拍后追加 1 个 PAD 控制字符,凑成完整的 2 字节码组;
- 随后正常插入 /ECP/ 有序集,标示帧结束。
这样,即使原始数据长度为奇数,最终在线路上仍以完整的码组形式完成帧封装。
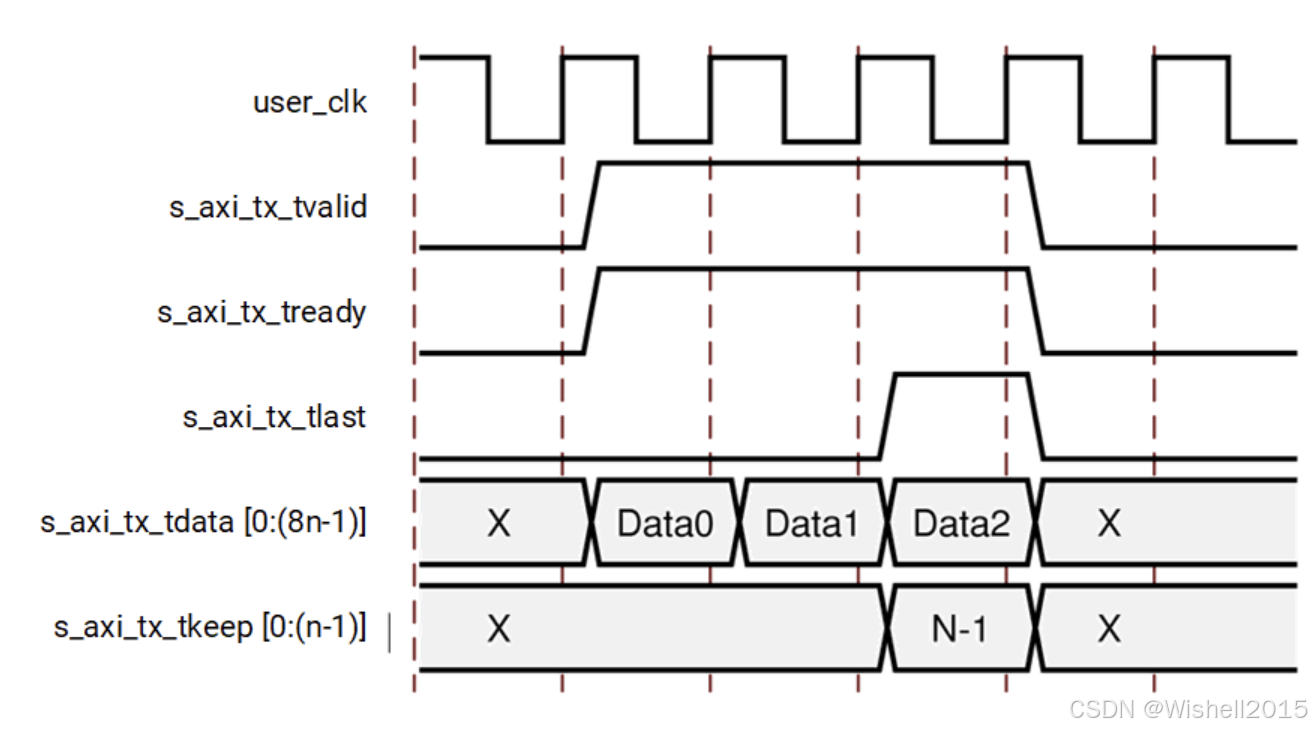
举例再说明一下:假设数据总线宽度 n=4n = 4n=4 字节 (即 32-bit 位宽)。这是一个 (3n−1)(3n - 1)(3n−1) 字节的数据传输。n=4n = 4n=4 ,总数据量 = 3×4−1=113 \times 4 - 1 = 113×4−1=11 个字节。11 是一个奇数,这很重要,因为 Aurora 8B/10B 协议要求帧的字节数如果是奇数,必须在末尾补一个 Pad 字符来凑成偶数(为了符号对齐)。
这个传输过程分成了三个时钟周期:
- 第一个周期 (Data0) - 完整字,传输内容:前 4 个字节(字节 0, 1, 2, 3)。
信号状态:
tvalid= 1,tready= 1:握手成功,数据传输。tlast= 0:这不是最后一包数据。tkeep:全为 1(表示这 4 个字节都有效)。
- 第二个周期 (Data1) - 完整字,传输内容:中间 4 个字节(字节 4, 5, 6, 7)。
信号状态:
tvalid= 1,tready= 1。tlast= 0:还不是最后一包。tkeep:全为 1。
- 第三个周期 (Data2) - 部分字 (关键点)传输内容 :剩下的 3 个字节 (字节 8, 9, 10)。总计 :4+4+3=114 + 4 + 3 = 114+4+3=11 字节。
信号状态:
-
tvalid = 1,tready= 1。 -
tlast = 1:拉高了,表示这是当前数据包的最后一个传输周期。 -
tkeep = N-1:- n=4n=4n=4,所以 n−1=3n-1=3n−1=3。
- 这意味着
tkeep信号会指示只有前 3 个字节是有效的,第 4 个字节是无效数据(垃圾数据)。 - 例如,如果
tkeep是二进制位掩码,它可能是0111(二进制),表示最低的3个字节有效。
关于 "Pad" (填充字符) 的解释
- 图里展示的是用户接口 (AXI 接口) :用户只需要告诉核心,"我给你发了 11 个字节的数据"。这是通过
tlast和tkeep来实现的。 - Aurora 核心的内部操作 :Aurora 核心收到这 11 个字节后,发现总数是奇数。为了符合物理层传输协议(通常要求双字节对齐),Aurora 核心会自动在第 12 个字节的位置补一个特殊的控制字符(PAD) ,然后再发送到光纤/网线上。
以上是具体过程,而在实际操作中,只需要进行如下操作:
- 拉高
tlast。 - 设置
tkeep信号,将其值设为有效字节数(在图中写作 N−1N-1N−1),以此告诉核心:"最后一个周期里,最后一个字节是无效的,别发它"。 - 核心会心领神会,发送这 3n−13n-13n−1 个字节,并自动在末尾补一个 Pad。
C、Data Transfer with Pause
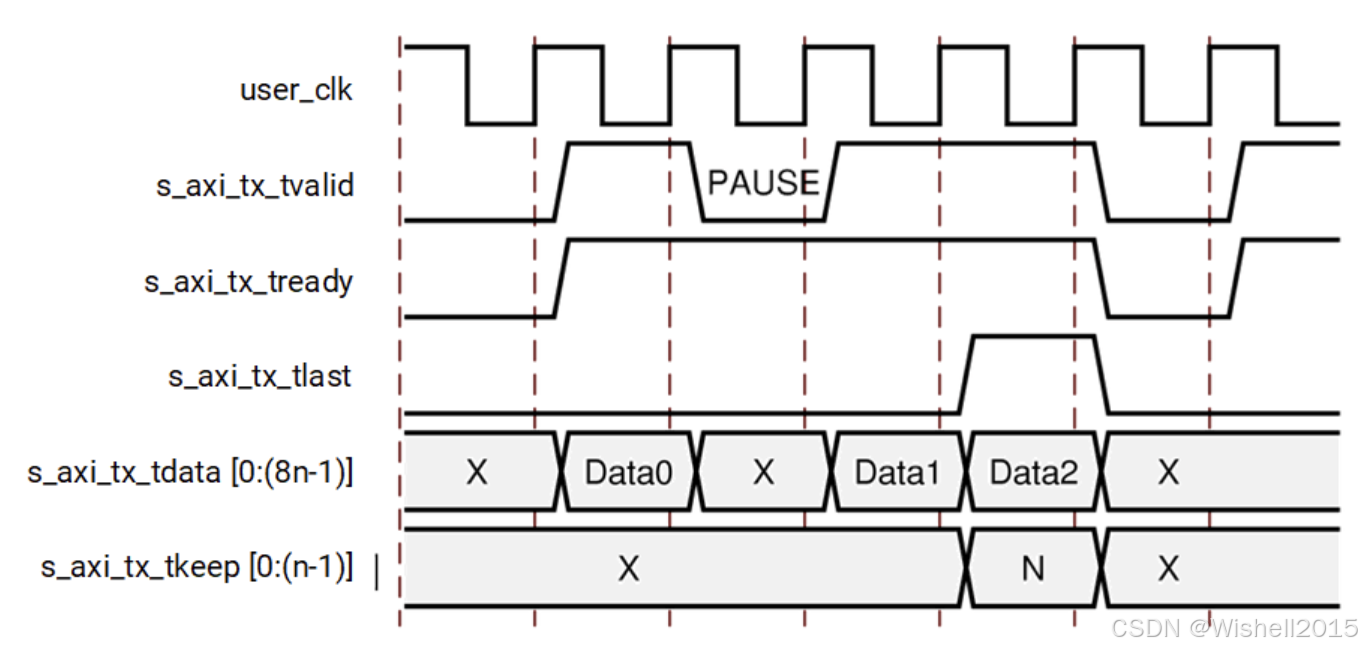
这张图展示了 Aurora 8B/10B 在传输过程中遇到的另一种常见情况:发送端暂停(Pause) 。
这种情况通常发生在你的用户逻辑(发送端)数据没准备好,比如你正在从 FIFO 或内存里读数据,但是读空了,需要等一个时钟周期数据才能跟上。
继续使用之前的场景设定:
- 总线宽度 n=4n = 4n=4 字节(32-bit)。
- 你要发送:3 个数据包(Data0, Data1, Data2)。
- 突发状况:在发完 Data0 之后,逻辑突然"卡"了一下(比如缓存空了),导致 Data1 还没准备好,所以需要暂停一下,等准备好了再发 Data1 和 Data2。
将过程分为 4 个关键时刻:
- 正常传输 Data0 (发送开始)
把 s_axi_tx_tvalid 拉高(置 1),同时把 Data0 放上数据总线。由于 Aurora 核心也是准备好的(tready 为 1),握手成功。Data0 被成功发送出去。
- 暂停阶段 PAUSE (关键点)
在下一个时钟周期,你的数据 Data1 还没准备好。此时,必须把 s_axi_tx_tvalid 拉低(置 0) 。tready 依然是 1(表示 Aurora 核心说:"我准备好了,你发吧"),但是因为 tvalid 是 0,握手失败 ,AXI 协议规定此时不传输有效数据。图中的数据线上写着 X,表示此时数据总线上的内容是无效的,核心不会去读取它。
底层发生了什么? :虽然 AXI 接口暂停了,但光纤/网线不能"空着"。Aurora 核心会在这个空档期自动向物理链路发送 Idle 字符(空闲码) ,以保持链路的同步和活跃,直到你有新数据为止。
- 恢复传输 Data1
暂停结束后, Data1 准备好了。重新把 s_axi_tx_tvalid 拉高(置 1) ,并把 Data1 放上总线。握手再次成功,Data1 被发送出去。
- 结束传输 Data2 (帧结束)
紧接着发送 Data2。tvalid = 1,tlast = 1 :告诉核心这是当前这一帧(Frame)的最后一个数据包。tkeep:根据图示,这里假设是满的(N个字节都有效)。Data2 发送完毕,整个传输过程结束。
D:Data Transfer with Clock Compensation
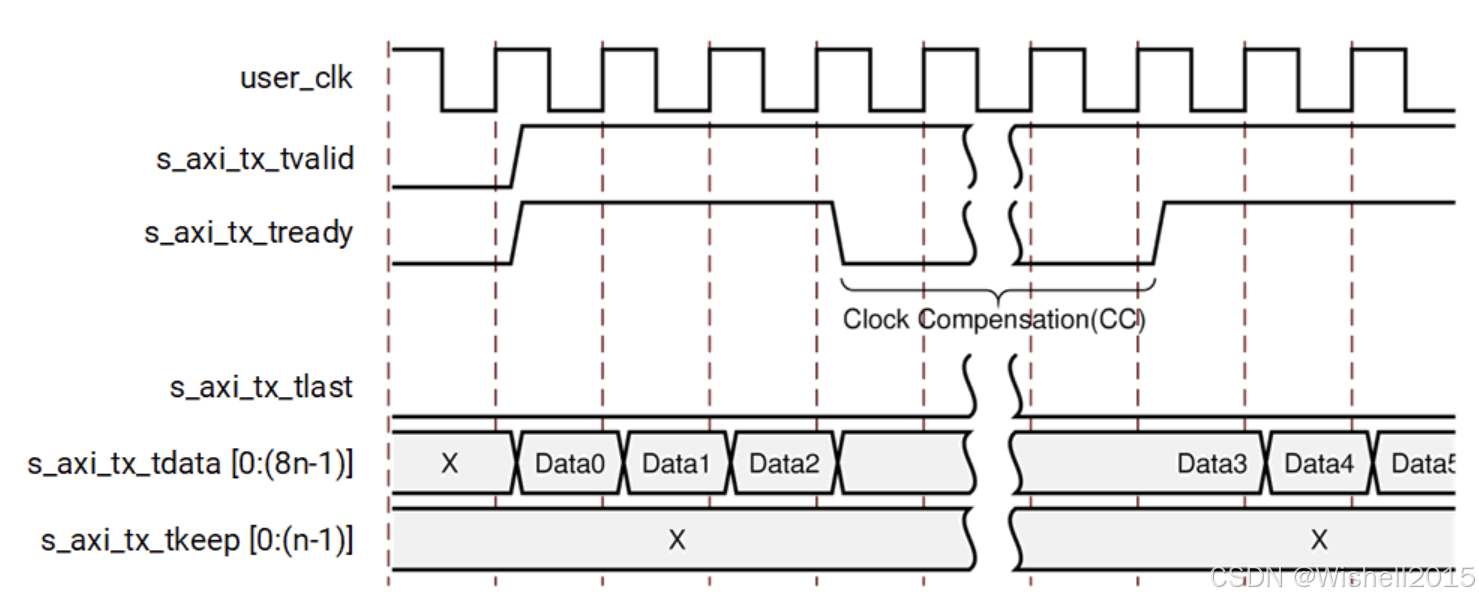
时钟补偿 (Clock Compensation, 简称 CC) 导致的数据传输暂停。
这与上一情况完全相反:上一情况用户不想发了;而这一情况是还想发,但 Aurora 核心(Core)命令你必须停下来。
为什么要有时钟补偿?
在高速串行通信中,发送端的晶振和接收端的晶振频率不可能完全一样(比如一个跑在 156.250 MHz,另一个可能是 156.251 MHz)。时间久了,接收端的缓存(Elastic Buffer)就会溢出或者读空。
为了解决这个问题,Aurora 协议规定:每发送一定数量的数据(比如每 10,000 字节),必须插入一组特殊的"时钟补偿字符" 。接收端收到这些字符时,不会把它们当做数据,而是利用这个间隙调整自己的缓存指针,从而消除频率误差。
举例说明一下,用户正在疯狂地连续发送大量数据(比如传输一个高清视频流)。 s_axi_tx_tvalid 一直拉高(=1),表示一直有数据要发。突发事件:Aurora 核心内部计数器发现:"哎呀,已经连续发了 10,000 个字节了,根据协议,我必须插入时钟补偿序列了!"
- 正常传输阶段 (Data0, Data1, Data2)
提供数据,tvalid = 1。核心也准备好了,tready = 1。Data0, Data1, Data2 顺畅地发了出去。
- 核心强制暂停 (Clock Compensation 期间)
就在发完 Data2 之后,核心决定插入时钟补偿序列。Aurora 核心突然把 s_axi_tx_tready 拉低(置 0) 。注意看 s_axi_tx_tvalid,它依然是高电平 (High) 。这意味着你并没有想停,你手里拿着 Data3 正准备发。因为 tready 变低了,握手失败。Data3 被卡住了,发不出去。必须保持 Data3 在总线上,等待核心重新准备好。
底层发生了什么? :在这段"波浪线"省略的时间里(通常是 3 或 6 个时钟周期),Aurora 核心正在光纤/网线上发送特殊的 CC 序列。这些数据用户是看不见的,属于协议层的开销。
- 恢复传输 (Data3, Data4...)
时钟补偿序列发送完毕。Aurora 核心重新把 s_axi_tx_tready 拉高(置 1)。握手恢复成功。一直在这个周期等待的 Data3 终于被发了出去,紧接着 Data4, Data5 继续发送。
Aurora 核心(Core) 的主动控制被称为 反压 (Backpressure) 。
接收案例
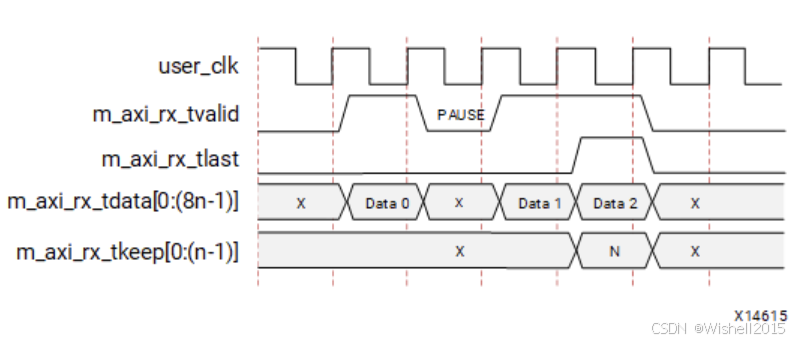
与发送端(TX)相比,接收端有一个非常关键且危险的区别,需要特别注意。
核心区别:没有 tready 信号(霸道的"强推"模式)
Aurora 核心接收到数据后,会直接推给用户逻辑。不能说"慢点、我处理不过来了"。必须无条件地在每个时钟周期时刻准备好接收数据。
RX 子模块没有内置给用户数据的"弹性缓存"(Elastic Buffer)。所以唯一的流控方式是使用 Aurora 协议层面的流控(那是另一个复杂的话题),但在 AXI 接口这一层,数据来了你就得收。
案例展示了一个 3n 字节(3 个数据字)的接收过程,但在接收过程中,Aurora 核心内部"卡"了一下,导致中间出现了一个暂停(Pause)。
- 第一个周期 (Data 0) - 接收开始
m_axi_rx_tvalid 拉高(置 1)。Aurora 核心把解包后的第一组数据 Data 0 放在总线上。
用户逻辑必须在这个时钟沿捕获 Data 0。
- 第二个周期 (PAUSE) - 核心暂停输出
m_axi_rx_tvalid 突然拉低(置 0) 。
发生了什么? :
- 不是 因为光纤上没数据了。通常是因为 Aurora 核心内部正在进行 "帧字符剥离" (Framing Character Stripping) 和 "左对齐" (Left Alignment) 。比如光纤上传输的数据流是
[数据] [数据] [控制字符] [数据]。Aurora 核心把那个"控制字符"剔除掉后,为了保证输出给用户的全是纯净数据,内部流水线需要停顿一个周期来把后面的数据"挪"上来(对齐)。
用户检测到 tvalid 为 0,逻辑应该什么都不做(不要把总线上的 X 当作数据读进去)。
- 第三个周期 (Data 1) - 恢复接收
tvalid 重新拉高。Aurora 核心输出了第二组数据 Data 1。
- 第四个周期 (Data 2) - 帧结束
tvalid = 1。m_axi_rx_tlast = 1 :表示这是这一帧的最后一包数据。m_axi_rx_tkeep = N :tkeep 信号只有在 tlast 拉高时才有效。这里 NNN 表示这最后一包数据全是有效的(没有填充 Pad)。
接收完 Data 2,一整帧数据接收完毕。
设计需注意的点:
-
被动接收 :
在 RX 端,你是被动的一方。
tvalid 什么时候拉高、什么时候拉低,完全由 Aurora 核心决定。核心可能会把本来连续发送的一帧数据,拆得稀碎(中间插入很多 Pause),你的逻辑必须能适应这种断断续续的输入。 -
必须够快 :
因为没有
tready 信号,如果你的后续处理逻辑(比如写入 DDR 或进行 DSP 计算)速度跟不上 Aurora 接收的速度,数据就会丢失。- 推荐做法 :通常在
m_axi_rx接口后面紧接着挂一个 FIFO(先进先出队列)。只要这个 FIFO 写不修,你就先把数据存进去,然后再以你自己的慢速时钟慢慢读出来处理。
- 推荐做法 :通常在
-
关于 Pause 的原因 :
不要觉得 Pause 是错误的。正如文档所说,这是"framing character stripping"(剥离帧头帧尾或填充字符)的正常副作用。你的状态机只需简单地判断
if (tvalid == 1) take_data;即可。
Streaming接口
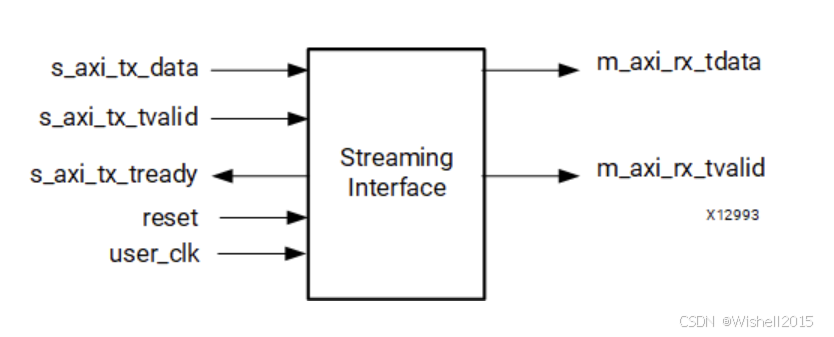
流式接口让 Aurora 8B/10B 通道可以像"管道"一样使用。初始化完成后,通道始终可写,仅在发送时钟补偿序列时短暂不可用。所有数据传输均符合 AXI4-Stream 协议规范。
- 当
s_axi_tx_tvalid被拉低时,会在字与字之间保留空隙,这些空隙会被原样送到线路上(正在发时钟补偿字符时除外)。 - 数据到达 RX 侧后,内核立即将其送上
m_axi_rx_tdata总线,并拉高m_axi_rx_tvalid。必须当下就读走,否则数据将被覆盖而丢失。若应用无法做到实时读取,则必须在 RX 接口外接缓冲器,先把数据暂存起来再后续处理。
发送案例
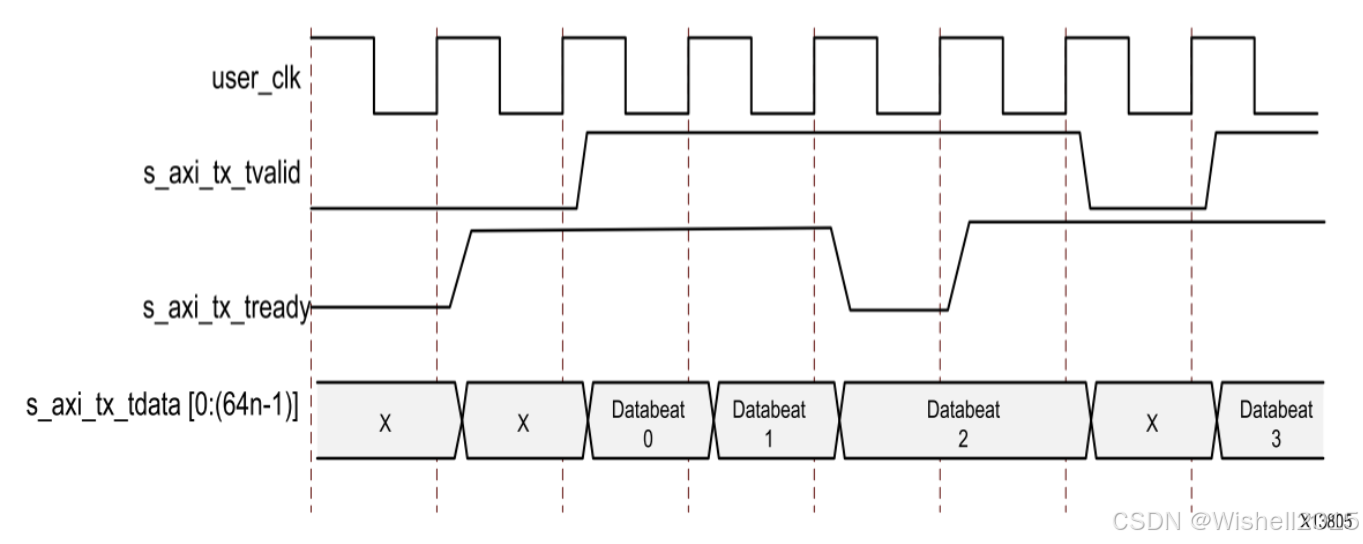
- 启动与顺畅传输 (Databeat 0, 1)
在第 3 个时钟周期 : ( tvalid ) :拉高为 1,拿出了 Databeat 0 。 ( tready ) :也是 1,表示准备好了。握手成功,Databeat 0 发送成功。
第 4 个时钟周期 :双方都保持为 1。Databeat 1 紧接着顺畅发送。
- 核心发起"反压" (关键点:Databeat 2 被卡住了)
第 5 个时钟周期 (问题出现) : ( tvalid ) :依然是 1,已经准备好 Databeat 2 并且放在总线上了,迫切想发出去。 ( tready ) :突然变低(0)了 !这可能是核心内部缓存满了,或者正在进行时钟补偿,或者正在处理其他协议开销。AXI 协议规定,只有 tvalid 和 tready 同时为 1 时,数据才算传过去。因为握手失败,必须 Hold 住! 不能撤回 Databeat 2,也不能换成 Databeat 3。必须保持 Databeat 2 在总线上不动,死等核心。
第 6 个时钟周期 (传输完成) : ( tready ) :恢复为 1。终于,tvalid (1) 和 tready (1) 再次相遇。Databeat 2 在等待了一个周期后,终于在这个周期被传走了。
- 用户发起"暂停" (空闲周期)
第 7 个时钟周期 : ( tready ) :是 1,核心说"我空了,来吧"。 ( tvalid ) :变低(0)了。可能是 FIFO 读空了,或者在计算数据还没算完。握手失败,没有有效数据传输。总线上的数据(标记为 X)被忽略。
- 恢复传输 (Databeat 3)
第 8 个时钟周期 :准备好了,把 tvalid 拉高。核心也准备好了。Databeat 3 成功发送。
接收案例
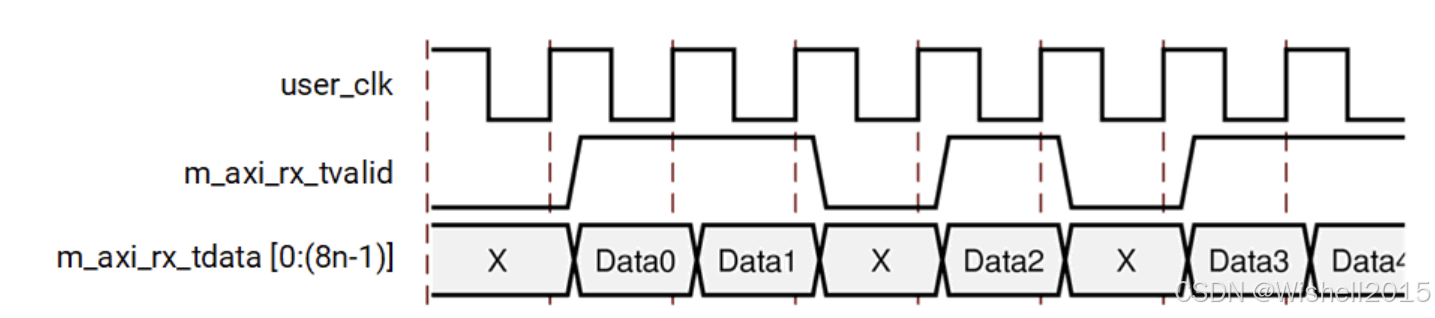
发送端(TX)发生的任何卡顿、暂停或反压,最终都会体现为接收端(RX)的数据流断断续续。
- 正常接收 (Data0, Data1)
时钟周期 2 & 3 :m_axi_rx_tvalid 拉高(置 1),先后输出 Data0 和 Data1。必须在这两个周期将数据存下来。
- 第一个间隙 (Cycle 4 - Gap)
tvalid 变低(0),数据线上是无效数据(X)。
- 接收 Data2 (Cycle 5)
tvalid 再次拉高,输出 Data2 。注意:Data2 就像孤岛一样,前后都有空隙。这是流式传输中非常常见的形态。
- 第二个间隙 (Cycle 6 - Gap)
tvalid 再次拉低。
- 恢复连续接收 (Data3, Data4)
时钟周期 7 & 8 :数据流恢复连续,输出 Data3 和 Data4。
-
发送端的因,接收端的果 :
如果发送端(TX)因为时钟补偿停了 3 个周期,或者用户 FIFO 空了停了 5 个周期,那么在接收端(RX)你就会看到相应长度的
tvalid = 0的间隙。 -
接收端逻辑必须"耐得住寂寞"也"经得起轰炸" :
-
你的接收逻辑(状态机)不能假设数据是连续的(1, 2, 3, 4)。
-
它必须能够处理:
1, 2, (空), (空), 3, (空), 4, 5...这种断断续续的节奏。 -
代码写法通常是:
verilogalways @(posedge user_clk) begin if (m_axi_rx_tvalid) begin // 只有当 tvalid 为 1 时,才把数据写进 FIFO 或进行处理 my_fifo_write_en <= 1; my_fifo_data_in <= m_axi_rx_tdata; end else begin // tvalid 为 0 时,什么都不做,保持静默 my_fifo_write_en <= 0; end end
-
-
AXI Stream 的灵活性 :
虽然数据断断续续,但依靠 AXI Stream 的
tvalid信号,数据的完整性和顺序是完全不会乱的。Data0 后面一定是 Data1,绝对不会跳变或丢失,只是时间上拉长了而已。
暂时就记这么多吧,这个ip还是比较复杂的,但是一项一项了解以后,需要实际的操作去实现。