手敲复现了一下文档的代码
python
import torch
torch.cuda
if torch.cuda.is_available():
print("CUDA可用!")
device_count=torch.cuda.device_count()
print(f"可用的CUDA设备数量:{device_count}")
current_device=torch.cuda.current_device()
print(f"当前使用的CUDA设备索引:{current_device}")
device_name=torch.cuda.get_device_name(current_device)
print(f"当前CUDA设备的名称:{device_name}")
cuda_version=torch.cuda.get_device_name(current_device)
print(f"当前CUDA设备的名称:{device_name}")
cuda_version=torch.version.cuda
print(f"CUDA版本:{cuda_version}")
else:
print("CUDA不可用。")
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
iris=load_iris()
X=iris.data
y=iris.target
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=42)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
python
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
X_train=scaler.fit_transform(X_train)
X_test=scaler.transform(X_test)
X_train=torch.FloatTensor(X_train)
y_train=torch.LongTensor(y_train)
X_test=torch.FloatTensor(X_test)
y_test=torch.LongTensor(y_test)
import torch
import torch.nn as nn
import torch.optim
class MLP(nn.Module):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.fc1=nn.Linear(4,10)
self.relu=nn.ReLU()
self.fc2=nn.Linear(10,3)
def forward(self,x):
out=self.fc1(x)
out=self.relu(out)
out=self.fc2(out)
return out
model=MLP()
criterion=nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
python
num_epochs=20000
losses=[]
for epoch in range(num_epochs):
outputs=model.forward(X_train)
loss=criterion(outputs,y_train)# 预测损失
# 反向传播和优化
optimizer.zero_grad()
loss.backward() # 反向传播计算梯度
optimizer.step()
losses.append(loss.item())
if(epoch+1)%100==0:
print(f'Epoch[{epoch+1}/{num_epochs}],Loss:{loss.item():.4f}')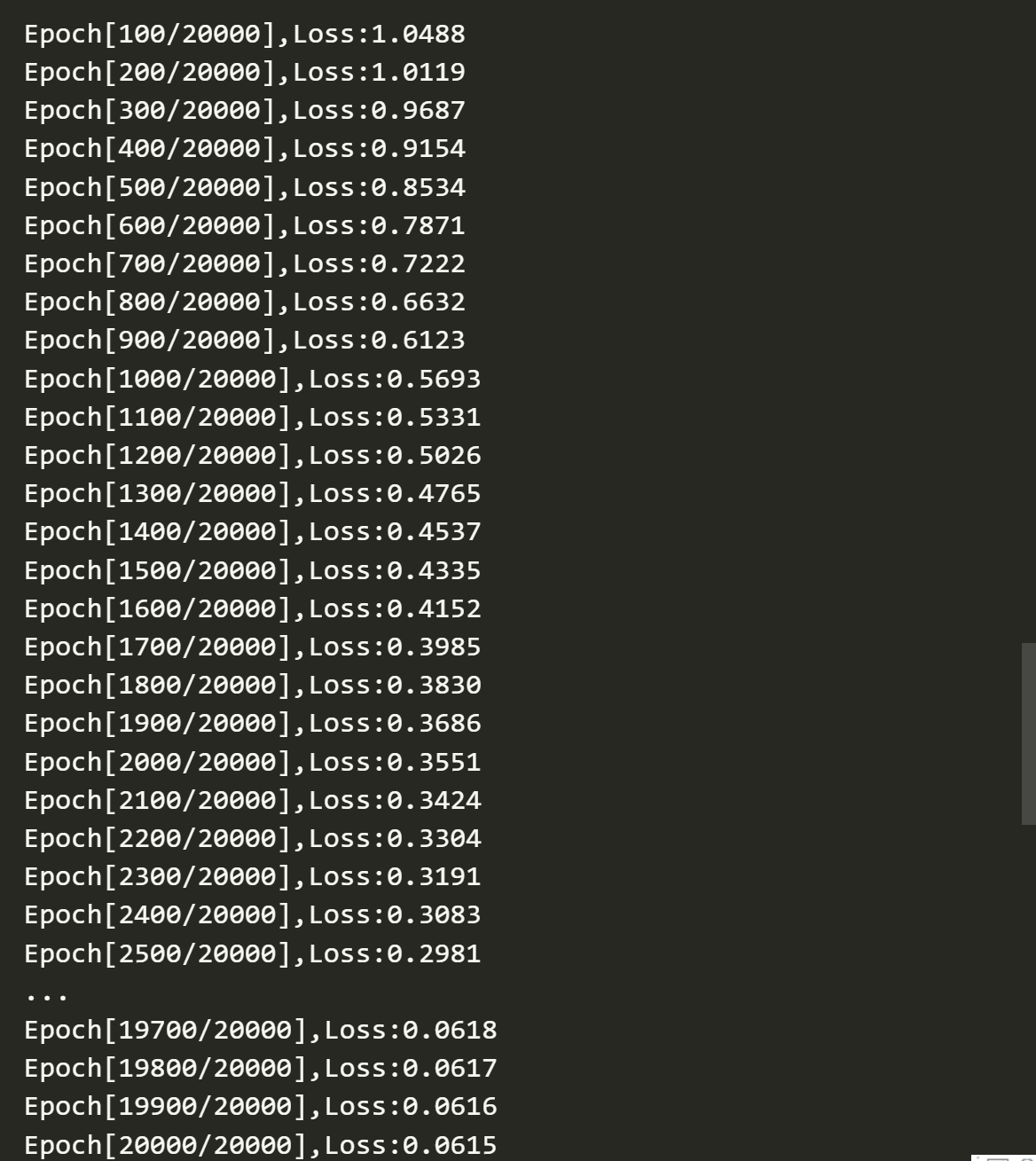
python
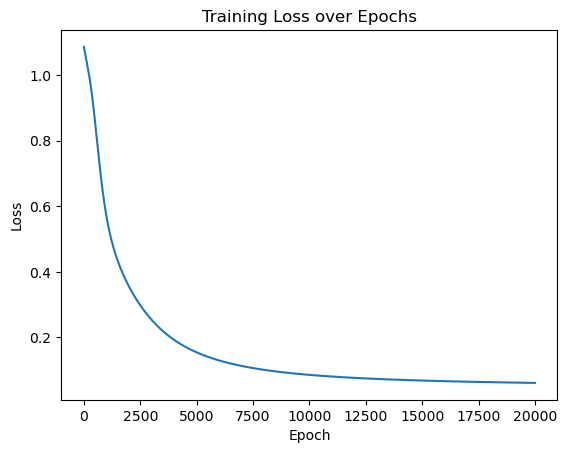
import matplotlib.pyplot as plt
plt.plot(range(num_epochs),losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()