1.Intruction
Kimi K2 是一个具有1000B 参数规模的MOE架构的LLM,每次激活32B参数。该模型的主要贡献:
- Muon Clip,基于Muon算法改进的一个优化器算法,替代了常用的AdamW。
- 提出了一个大规模合成agentic data的pipeline
- 设计了一个通用的RL框架,使得模型不仅能从任务中学习,还可以从评价自身输出中学习
2. Pre-training
pre-trained data : 15.5T high-quality tokens
2.1 MuonClip
问题: 在使用Muon的时候,作者发现Attention层的输出值(Attention Logits),数值会变大,导致softmax计算溢出,Loss飙升,出现Loss Spike。
现有解决方法:
- Logit soft-capping(软截断):直接将Attention Logits数值截断,但是内部的Query和Key的点积依旧巨大
- QK-Norm(层归一化) :对Query、Key进行归一化,但Kimi K2使用的是MLA,无法使用QK-Norm
QK-Clip
做法是直接去缩小权重矩阵WQ,WKW_Q,W_KWQ,WK
在当前Batch B 中,计算每个注意力头(Head)产生的最大 Logit 值 (SmaxS_{max}Smax):
Smaxh=1dmaxX∈Bmaxi,jQihKjh⊤S_{\max}^h = \frac{1}{\sqrt{d}} \max_{\mathbf{X} \in B} \max_{i, j} \mathbf{Q}_i^h \mathbf{K}_j^{h\top}Smaxh=d 1X∈Bmaxi,jmaxQihKjh⊤
设定一个阈值 τ\tauτ(论文中设为 100):
- 如果Smax≤100S_{max}\le 100Smax≤100,什么也不做
- 否则说明权重过大,需要缩小
计算比例: γ=阈值最大值=100500=0.2\gamma = \frac{阈值}{最大值} = \frac{100}{500} = 0.2γ=最大值阈值=500100=0.2 8。
缩小权重: 直接修改 Query 的投影权重 (WqW_qWq) 和 Key 的投影权重 (WkW_kWk) 。Wq←Wq⋅γW_q \leftarrow W_q \cdot \sqrt{\gamma}Wq←Wq⋅γ Wk←Wk⋅γW_k \leftarrow W_k \cdot \sqrt{\gamma}Wk←Wk⋅γ
为什么是乘以 γ\sqrt{\gamma}γ (根号 gamma)?
因为 Attention 的计算公式是 Q⋅KQ \cdot KQ⋅K。
如果你把 QQQ 缩小 0.2\sqrt{0.2}0.2 倍,把 KKK 也缩小 0.2\sqrt{0.2}0.2 倍,那么它们相乘的结果就会正好缩小 0.20.20.2 倍。
上述是对于MHA架构的方法,如果是MLA架构:

2.2 Pre-training Data: Improving Token Utility with Rephrasing
Knowledge Data Rephrasing :
因为Pre-train的数据非常庞大,如果只训练一个epoch的话,可能会导致学习不充分,没有完全吸收知识;如果训练多个epoch的话,又会产生过拟合的风险。为了提升高质量数据的利用率,Kimi K2提出了一个系统的rephrasing框架:
- 精心设计了一系列的prompt,引导模型以不同的风格和视角对同一段话进行重新描述
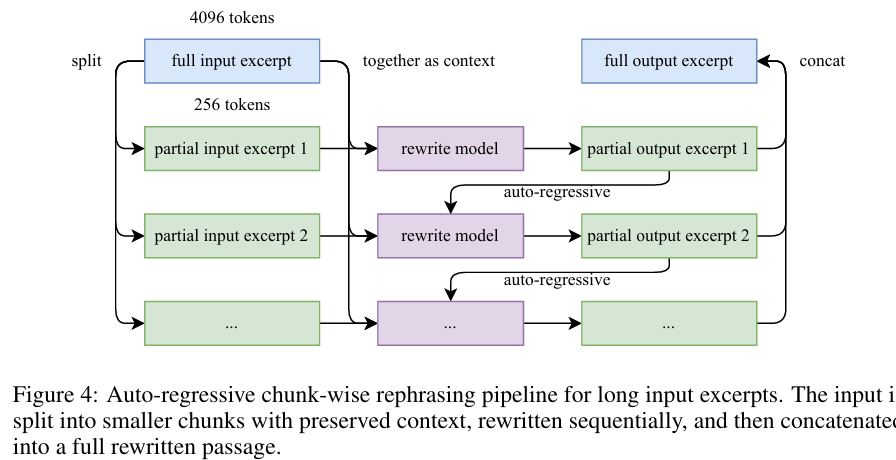
- Chunk-wise autogressive generation : 为了保持一段话的全局连贯性和避免丢失信息,将文本分成一段一段,分别进行语义重述。
模型在重写第 NNN 个片段时,实际上接收了三部分信息作为输入(Context):
- 全局上下文 (Global Context)
- 当前的原文片段
- 上一段的重写结果
同时,作者做了个对比实验在SimpleQA数据集上:
1.对数据不进行重述,训练10epochs
2.对每个数据重述1次,训练10epochs
3.对每个数据重述10次,训练1epochs

最后在大规模的知识语料中,作者选择对每个数据最多重述2次。
Model Architecture
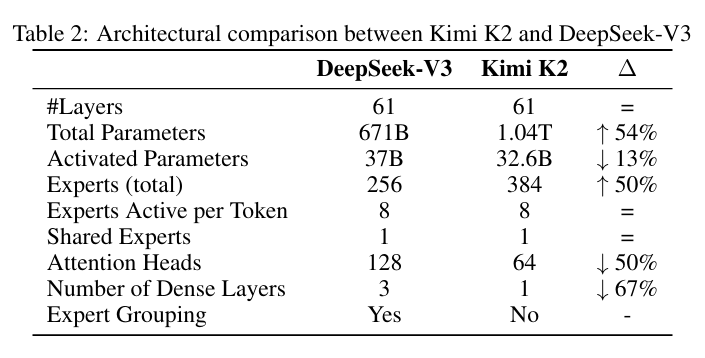
Sparsity Scaling Law
论文提出了针对MOE架构的 sparsity scaling law。
稀疏性(sparisty)定义为专家总数和激活专家数量的比率。
作者在小规模的实验下发现:在固定激活参数量的情况下, 提升总的专家数量会持续奖励训练和验证loss。最后作者选择了稀疏性为48。
Number of Attention Heads
提升注意力头的数量会提升推理时的计算量。
deepseek v3中将其设置为接近模型层数的两倍,作者明确指出,在128K长文本下,将注意力头数从64增大到128(在固定专家总数为384的情况下),推理的计算量会增大83%。为此,作者设计了对比实验,在不同的训练浮点次数下比较,发现验证损失仅有微小的提升。鉴于Kimi采用的稀疏性48的配置,因此就设置为64.
3.Post-Training
3.1.1 Large-Scale Agentic Data Synthesis for Tool Use Learning
该阶段主要对于agentic data,设计了一个数据生成pipeline,去教会模型学习使用工具的能力。
流程主要包括三阶段:
第一阶段:构建工具库
这一步的目标是建立一个庞大且多样化的工具集合,涵盖各种功能领域。Kimi K2 采用了"真实获取 + 合成演化"的双重策略:
- 真实工具获取 (Real-world Tools):
直接从 GitHub 等开源社区抓取了 3000+ 个符合 MCP (Model Context Protocol) 标准的真实工具。这些工具通常具有高质量的现有规范(Specs)。 - 合成工具演化 (Synthetic Tool Evolution):为了扩展工具的多样性,团队利用 LLM 进行**"分层领域演化" (Hierarchical Domain Evolution)** 。
- 演化逻辑: 从宏观的关键类别(如金融交易、软件应用、机器人控制)出发 →\rightarrow→ 演化出具体的细分应用领域 →\rightarrow→ 为每个细分领域合成专用的工具。生成内容: 每个合成工具都包含清晰的接口定义、功能描述和操作语义。规模: 通过这种方法生成了超过 20,000 个合成工具,极大地补充了真实工具未覆盖的领域 。
第二阶段:智能体与任务生成 (Agent & Task Generation)
有了工具库后,下一步是定义"谁来用工具"以及"用工具做什么"。
智能体多样化 (Agent Diversification):
- 通过合成各种系统提示词 (System Prompts),并为它们配备不同的工具组合,生成了成千上万个具有不同能力、专长和行为模式的 Agent(例如"资深运维工程师"、"金融分析师")。
基于评分标准的任务生成 (Rubric-Based Task Generation):
-
针对每个 Agent 的配置,生成从简单到复杂的各种任务。
-
核心创新: 每个任务都配有一个明确的评分标准 (Rubric)。这个标准详细规定了任务的成功条件、预期的工具使用模式以及关键检查点。这为后续的自动化质量评估提供了客观依据 。
第三阶段:轨迹生成与过滤 (Trajectory Generation & Filtering)
这是数据生成的执行阶段,通过模拟交互来生产具体的训练数据(即"轨迹")。
用户模拟 (User Simulation):
- 利用 LLM 生成具有特定沟通风格和偏好的"虚拟用户",与 Agent 进行多轮自然对话,提出需求并回应 Agent 的提问 。
混合执行环境 (Hybrid Execution Environment):
- 工具模拟器 (Tool Simulator): 对于大多数任务,使用一个功能等同于"世界模型"的模拟器。它可以执行工具调用,维护并更新环境状态,还能引入受控的随机性(模拟成功、失败或边缘情况),提供逼真的反馈 。
真实沙盒 (Real Sandbox): 对于编程和软件工程等对真实性要求极高的任务,使用真实的执行沙盒(基于 Kubernetes)。它能运行实际代码,并基于测试用例的通过率(Test Suite Pass Rates)提供"真值"反馈 。
质量评估与过滤 (Quality Evaluation and Filtering):
- 裁判模型 (Judge Agent): 交互结束后,使用另一个 LLM 作为裁判,严格对照第二阶段生成的评分标准 (Rubrics) 来评估整个轨迹。
- 筛选机制: 只有完全满足成功标准的轨迹才会被保留。这种机制本质上是一种大规模的 Rejection Sampling(拒绝采样),确保了最终进入训练集的数据都是高质量的成功范例 。
3.2 RL
3.2.1 Verifiable Rewards Gym (可验证奖励训练场) 总结
这一章节详细介绍了 Kimi K2 在强化学习(RL)阶段的基础设施建设。为了解决 RL 中奖励信号稀疏或不准确的问题,K2 团队针对不同领域的任务,构建了一套基于"真值验证"的自动化奖励体系。
该体系主要覆盖以下四个核心领域:
1. 数学、STEM 与逻辑任务 (Math, STEM and Logical Tasks)
这一领域的 RL 数据构建遵循两个核心原则:覆盖多样性 和难度适中。
-
多样化覆盖 (Diverse Coverage)
- 数据来源:结合了专家标注、内部自动化提取流水线以及公开数据集。
- 补短板:利用标签系统(Tagging System)识别覆盖率不足的领域并进行专门补充 cite: 546-547。
- 逻辑任务扩展:不仅包含传统的问答,还引入了结构化数据任务(如多跳表格推理)和逻辑谜题(如数独、24点游戏、密码算术、摩尔斯电码解码)cite: 548。
-
适度难度 (Moderate Difficulty)
- 原则:题目太简单(全都会)或太难(全瞎蒙)都无法提供有效的梯度信号。
- 筛选机制 :使用 SFT 模型计算 pass@k 准确率,仅保留那些处于"中等难度区间"的题目用于 RL 训练 cite: 549-550。
2. 复杂指令遵循 (Complex Instruction Following)
为了让模型学会处理隐含约束、边缘情况及长对话中的一致性,K2 设计了一套**"混合验证 + 多源生成"**的框架。
-
混合规则验证 (Hybrid Rule Verification)
- 确定性验证 (Deterministic) :对于字数限制、格式要求等可量化的约束,直接使用代码解释器进行验证 cite: 554。
- LLM 裁判 (LLM-as-judge):对于需要微妙理解的约束(如风格、语气),使用 LLM 进行评判 cite: 554。
- 防作弊层 (Hack-check Layer):专门引入检测层,防止模型通过输出欺骗性文本(如"我已经完成了")来骗取奖励 cite: 555。
-
多源指令生成 (Multi-Source Instruction Generation)
- 专家生成:由数据团队手工编写的复杂条件提示词 cite: 556。
- Agent 增强:受 AutoIF 启发的智能体自动化增强数据 cite: 560。
- 针对性微调:专门微调一个模型来生成针对特定失败模式(Failure Modes)或边缘情况的指令 cite: 560。
-
忠实度 (Faithfulness)
- 训练了一个句子级别的裁判模型,专门用于检测模型是否在没有上下文证据的情况下做出事实性声明(Factually unsupported claims),以此作为惩罚信号 cite: 563-565。
3. 代码与软件工程 (Coding & Software Engineering)
这一部分的重点是引入**"真实执行环境"**,以获取最客观的反馈。
-
数据构建
- 竞赛题 :收集开源及合成题目。为保证合成数据的质量,强制要求配备从预训练数据中检索到的高质量人类编写的单元测试(Unit Tests) cite: 566-567。
- 软件工程 (SWE):从 GitHub 收集大量的 Pull Requests (PRs) 和 Issues,构建包含"用户需求 + 现有代码库 + 可执行测试"的完整开发环境 cite: 568。
-
基础设施 (Sandbox Infrastructure)
- 基于 Kubernetes 构建了高并发沙盒。
- 支持同时运行超过 10,000 个 独立的沙盒实例,确保了在大规模 RL 训练中的吞吐量和安全性 cite: 569-570。
4. 安全性 (Safety)
为了提升模型的安全性,K2 使用了一套自动化的**"攻防演练"**流水线。
- 种子数据:始于人类专家编写的包含暴力、欺诈、歧视等风险类别的种子提示词 cite: 571。
- 自动化演化 (Automated Prompt Evolution) :
- 模拟复杂的越狱攻击(如角色扮演、学术探讨伪装)。
- 包含三个组件的闭环:
- 攻击模型 (Attack Model):迭代生成试图绕过防御的对抗性 Prompt cite: 573。
- 目标模型 (Target Model):即正在训练的 K2,对攻击做出反应 cite: 574。
- 裁判模型 (Judge Model):根据特定标准判断攻击是否成功,提供二分类(成功/失败)标签作为 RL 信号。
总结核心思想 :
Verifiable Rewards Gym 的核心在于**"去主观化"。通过将数学验证器、代码沙盒、规则检查器集成到 RL 环境中,Kimi K2 能够在数万亿次交互中获得确定性强、噪声低**的高质量反馈信号,从而在理科、代码及安全性等硬核能力上实现突破。
3.2.2 Beyond Verification: Self-Critique Rubric Reward 总结
对于无法直接通过程序验证的任务(如写作、建议、角色扮演),Kimi K2 采用了自我批判准则奖励机制,核心逻辑如下:
- 自动化准则生成 (Rubric Generation) :
- 为每个任务利用 LLM 生成一套详细的评分维度(如:逻辑严密性、语气友好度、指令对齐度)。
- 模型自我评估 (Self-Evaluation) :
- 训练模型在完成任务后,扮演"裁判"角色对自己的输出进行多维度打分。
- 优势 :
- 可扩展性:不再受限于人工标注的奖励模型(RM),可以针对海量主观任务快速生成奖励信号。
- 细粒度反馈:准则(Rubric)提供了比单一分数更丰富的反馈信息,有助于模型理解"好在哪里,坏在哪里"。
3.2.3 RL Algorithm (强化学习算法) 总结
Kimi K2 的强化学习算法旨在实现超大规模参数下的高效、稳定训练:
1. 核心公式与架构
- Group Relative 机制 :采用组内相对比较。通过对同一 Prompt 采样 KKK 个结果并取奖励平均值作为 Baseline,消除了对独立 Critic 模型的依赖,极大地节省了显存开销。
- 优化目标 :使用回归式 Loss 函数,将策略更新视为拟合奖励优势的过程。
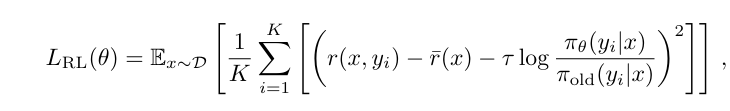
2. 训练约束与辅助目标
- 辅助损失 (PTX Loss):在 RL 梯度中混合原始预训练语料的交叉熵损失。这保证了模型在进化 Agent 能力时,依然维持强大的通用语言理解和知识储备。
- KL 散度约束:引入 KL 惩罚项,防止模型在强化学习过程中偏离原始 SFT 模型太远。
3. 策略效率优化
- Token 预算 (Token Budgeting):针对不同任务设置不同的 Token 阈值。若模型产生不必要的冗长输出,会受到惩罚或被强制截断,从而训练出更简洁高效的思维链。
- MuonClip 驱动:配合 MuonClip 优化器,利用其正交化更新的特性,使模型在 RL 阶段的收敛速度和稳定性远超传统的 AdamW。
核心思想总结 :
Kimi K2 通过 Self-Critique 解决了主观任务"没法判分"的问题,通过 MSE-based RL Algorithm 解决了"训练太贵、易崩"的问题,最终实现全场景下的智能进化。